Conta oficial: EDPJ
Deixe-me falar primeiro sobre a conclusão: este é o resultado da obtenção da parte real do número complexo no algoritmo e tem pouco efeito no FID.
FID é uma medida da similaridade entre dois conjuntos de imagens dos aspectos estatísticos dos recursos de visão computacional da imagem original e é uma medida da distância entre a imagem real e o vetor de recursos da imagem gerada.
Esse recurso visual é extraído e calculado usando o modelo de classificação de imagem Inception v3. O FID tem uma pontuação de 0,0 no melhor caso, indicando que os dois conjuntos de imagens são idênticos. Quanto menor a pontuação, mais semelhantes são os dois conjuntos de imagens ou mais semelhantes as estatísticas dos dois
A fórmula de cálculo do FID é a seguinte:
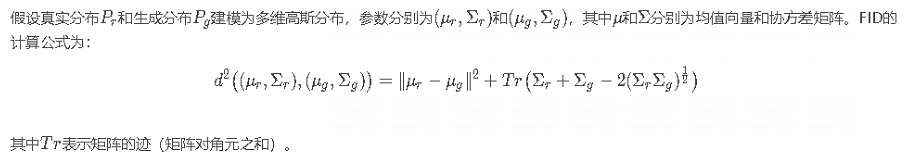
A matriz de covariância é calculada da seguinte forma:
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
if np.iscomplexobj(covmean):
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
m = np.max(np.abs(covmean.imag))
raise ValueError('Imaginary component {}'.format(m))
covmean = covmean.realQuando data_size = 1, FID = 0
Quando data_size = 100: a diferença entre a matriz de variância e a matriz de covariância é muito pequena

Quando data_size = 1000: essa diferença é ainda mais reduzida

Quando data_size = 5000: esta diferença é ainda mais reduzida
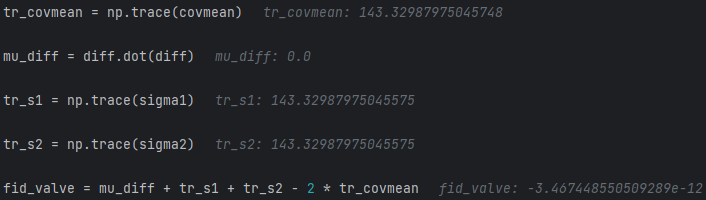
Conclusão: números negativos realmente têm pouco efeito sobre os resultados