
Autor: Lu Yufeng Fonte: Zhihu
Resumo
O desenvolvimento do MindNLP já dura cerca de um ano. No geral, ele enfrenta muitos problemas e também é acompanhado por uma série de impactos e desafios trazidos pelo LLM. Como uma estrutura de PNL recém-chegada que depende do MindSpore para seu crescimento ascendente, ela realmente precisa considerar como expandir sua ecologia.
Como diz o ditado: se você não pode vencer, junte-se. Mas para o mundo do código aberto, não há necessidade de falar em aderir. É normal que você me tenha e faça parte de mim. Além disso, no momento em que Pytorch2.1+Ascend foi anunciado oficialmente há dois dias. a enxertia ecológica é sem dúvida a melhor solução. Chega de fofoca e vamos direto ao ponto.
01
Conjuntos de dados MindNLP
Desde o início do design do MindNLP, esperamos aproveitar ao máximo todas as vantagens e recursos do MindSpore, incluindo programação de fusão funcional, funções gráficas dinâmicas, mecanismos de processamento de dados, etc. Aqui, o mecanismo de processamento de dados é retirado separadamente e discutido em detalhes.
1.1 Mecanismo de processamento de dados MindSpore
Figura 1: Diagrama esquemático do pipeline do mecanismo de dados MindSpore
Conforme mostrado na figura, o design do mecanismo de dados é o pipeline [1], que é muito semelhante ao conjunto de dados do Tensorflow e aos conjuntos de dados estilo mapa do Pytorch, e visa principalmente o processamento de dados de alto desempenho.
Em uma época em que todos ainda estão fazendo pequenas modificações de modelo e pequenos conjuntos de dados para atualizar as classificações, o pré-processamento de dados geralmente é feito offline, para que Python possa ser usado para processá-los da maneira mais flexível possível, e geralmente a grande memória do servidor pode acomodá-lo. Todos irão inserir todos os dados de uma vez e depois abrir vários processos para processá-los. Depois disso, carregue-o no Tensor e envie-o para a rede para treinamento. Mas mesmo assim, se o conjunto de dados for um pouco maior, poderá levar horas ou até dias para pré-processar o conjunto de dados.
O método Pipeline concentra-se em vários recursos:
1. Carregue sob demanda
2. Processamento assíncrono
3. Paralelo
Entre eles, 1 e 2 podem ser discutidos detalhadamente. Tomando dados de texto como exemplo, se a lógica de pré-processamento de carregamento Python mais simples (ou seja, Pytorch Dataloader) for usada, o fluxo geral de execução será o seguinte:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
O método de carregamento do Pipeline é
Uma descrição mais vívida é: Agora há um ponteiro apontando para o início do arquivo do conjunto de dados. Buscamos um tamanho de lote de dados a cada vez, e o ponteiro avança pelo tamanho do lote até que seja buscado.
Obviamente, buscar apenas uma quantidade apropriada de dados de cada vez pode reduzir bastante o consumo de memória, e as variáveis intermediárias geradas durante o processo de pré-processamento também podem ser compactadas em um tamanho pequeno. Além disso, este método pode converter o pré-processamento de dados offline em online:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Figura 2: Processamento de dados e pipeline de computação em rede
O pipeline de processamento de dados processa continuamente os dados e envia os dados processados para o cache do lado do Dispositivo; após a execução de uma Etapa, os dados da próxima Etapa são lidos diretamente do cache do Dispositivo; Enquanto a rede treina, os dados também são processados, cada um desempenhando suas próprias funções.
É claro que esse método também é uma faca de dois gumes. Ao mesmo tempo que melhora a utilização e o desempenho da memória, também apresenta problemas de facilidade de uso. O mapa da Figura 1 é um processamento assíncrono. Depois de configurar cada operação de pré-processamento de dados, ele não executará e retornará os resultados diretamente. Isso não é amigável para dados que requerem controle preciso e têm muitas condições especiais, e é muito provável que a execução do pipeline ocorra. . Uma anormalidade é desencadeada repentinamente.
No entanto, o LLM mudou esta situação. Todas as tarefas se tornaram Next Token Prediction, e todo o processamento de dados também se tornou limpeza + Tokenize. A quantidade de dados é enorme e muitas vezes o streaming de dados em cenários de negócios torna-se naturalmente a solução ideal. provavelmente a principal razão pela qual Pytorch começou a fazer pipelines e os conjuntos de dados HuggingFace também são pipelines).
1.2 Problemas de suporte do conjunto de dados MindNLP
Conforme mencionado anteriormente, o processamento de dados do MindNLP usa completamente o mecanismo de processamento de dados MindSpore e suportou mais de 20 conjuntos de dados em um ano (comparados por torchtext). No entanto, no uso real, é óbvio que várias tarefas de PNL exigem mais do que esses conjuntos de dados e é difícil adaptar-se continuamente a um domínio aberto.
Além disso, o Dataset do Shengsi MindSpore também causou alguns problemas. O principal problema é que o MindSpore Dataset projetou três tipos de carregadores, a saber:
1. Carregador de conjunto de dados específico: como IMDBDataset, EnWik9Dataset, etc.
2. Carregador abstrato de texto: TextFileDataset
3. Carregador definido pelo usuário: GeneratorDataset
Se você usar 1, significa que precisará adicionar adaptações continuamente; se usar 2, precisará pré-processar formatos como xml, json, etc., antes de carregar. ainda enfrentamos a necessidade de adaptação manual A quantidade de desenvolvimento usando 3 significa que o primeiro passo na Figura 1 retorna à carga total, o que obviamente não é o que queremos. Porém, devido à necessidade de suporte rápido ao conjunto de dados, ainda escolhemos o método 1+3 para suporte.
Isto não é eficiente e requer uma adaptação separada de cada vez. Então, existe alguma solução permanente?
02
Enxertia ecológica HuggingFace
O carregamento do conjunto de dados do MindNLP não deseja alcançar nada mais do que duas coisas:
1. Suporta grandes conjuntos de dados sem adaptação
2. Use um pipeline eficiente
Já que você não pode fazer isso sozinho, vamos contar com o poder da ecologia. Além do armazém do Transformers, o HuggingFace desenvolveu bibliotecas para vários processos de treinamento de IA. Os conjuntos de dados foram acumulados por vários anos e suportam um grande número de conjuntos de dados. E como o HuggingFace fornece serviços de hospedagem, muitos novos conjuntos de dados também estão diretamente no. Hub de conjuntos de dados. Usando conjuntos de dados para resolver o problema 1, vejamos o segundo problema.
Na verdade, a maioria das pessoas que usam o MindSpore Dataset escolhe basicamente dois métodos de processamento:
1. Pré-processamento offline para MindRecord e, em seguida, carregamento usando MindDataset
2. Carregue o conjunto de dados na memória e, em seguida, carregue-o usando um carregador de conjunto de dados específico/GeneratorDataset
Para poder fazer o pré-processamento online, o método 1 obviamente não é aconselhável, então a ideia de enxertar conjuntos de dados HuggingFace também é muito simples. Considerei duas ideias e as discutirei a seguir.
2. 1 Download do conjunto de dados de enxerto
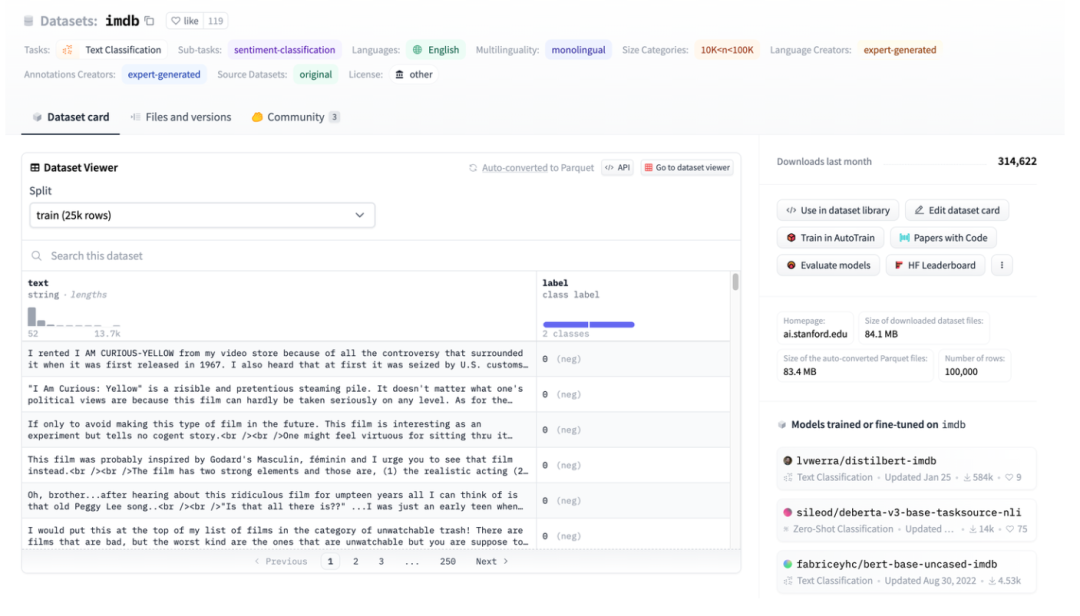 Figura 3: Ilustração do conjunto de dados HuggingFace, tomando o IMDB como exemplo
Figura 3: Ilustração do conjunto de dados HuggingFace, tomando o IMDB como exemplo
A Figura 3 é uma captura de tela da página imdb. Você pode ver que os dados foram bem estruturados. Em seguida, use os conjuntos de dados HuggingFace para fazer download diretamente e, em seguida, use diretamente o carregador de dados abstrato TextFileDataset para ler os arquivos processados diretamente para uso.
Figura 4: Interface TextFileDataset
Você pode ver que TextFileDataset só precisa passar o caminho do arquivo ou lista de caminhos para carregar. No entanto, encontrei um problema durante a operação prática: HuggingFace Datasets usa arquivos Apache Arrow.
Figura 5: Introdução ao formato Arrow dos conjuntos de dados HuggingFace
Apache Arrow[2] é um padrão de formato de troca de dados de alto desempenho, multissistema, independente de linguagem e que não pode ser copiado. Isso significa que o conjunto de dados do MindSpore não pode ser lido de forma direta e simples. Embora também possa ser operado usando a biblioteca pyarrow, isso aumenta a complexidade e retorna a um estado que requer pré-processamento antes do carregamento. No entanto, verifica-se que as características dos arquivos Arrow são mais adequadas para o conjunto de dados do MindSpore.
2. 2 Vantagens do formato Arrow
No ambiente Multiwalker, robôs bípedes tentam carregar sua carga e caminhar para a direita. Vários robôs transportam uma carga grande e precisam trabalhar juntos, como mostra a figura abaixo.
HuggingFace usa o formato Apache Arrow, que tem várias vantagens óbvias:
1. O formato padrão do Arrow permite leituras de cópia zero, o que praticamente elimina toda a sobrecarga de serialização.
2. A seta é orientada a colunas, portanto, a consulta e o processamento de fatias de dados ou colunas de dados são mais rápidos.
3. Arrow trata cada conjunto de dados como um arquivo mapeado na memória. Ao acessar dados parciais em um arquivo grande, não é necessário carregar o arquivo inteiro e vários processos podem compartilhar memória. O mapeamento de memória permite o uso de grandes conjuntos de dados em máquinas com memória de dispositivo relativamente pequena; o carregamento do conjunto de dados completo da Wikipédia em inglês requer apenas alguns MB de RAM.
4. Ao carregar dados, você pode definir os parâmetros de streaming para carregamento de streaming.
Neste momento, vamos voltar e dar uma olhada no design do mecanismo de dados MindSpore: carregamento sob demanda, processamento online e conjuntos de dados HuggingFace são uma combinação perfeita.
2.3 Adaptação MindNLP
Como o arquivo de seta carregado pelo próprio HuggingFace Datasets é um arquivo mapeado na memória, não há necessidade de copiá-lo para a memória e usar o índice não o carregará totalmente, portanto, pode ser usado diretamente como fonte de carregamento de dados e enviado diretamente para o GeneratorDataset para uso.
Figura 6: Interface GeneratorDataset
A construção do GeneratorDataset requer principalmente dados de origem e o nome da coluna correspondente a cada coluna de dados. Olhando novamente para a Figura 3, você pode ver que o HuggingFace Datasets nomeou todas as colunas. A seguir está o código principal interceptado:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
As etapas de processamento também são muito simples:
1. Carregar usando load_dataset de conjuntos de dados HuggingFace
2. Use classes de trânsito encapsuladas para encapsulamento
3. Passe GeneratorDataset
Para facilitar o uso, mantemos as configurações dos parâmetros da interface load_dataset exatamente iguais aos conjuntos de dados HuggingFace, mas o que é retornado é uma classe ou Dict que pode ser processada pelo mecanismo de dados MindSpore, para que a conexão perfeita do as capacidades de processamento de dados do Shengsi MindSpore podem ser concluídas.
Vamos falar brevemente sobre a estrutura da classe de trânsito.
Os tipos de dados dos conjuntos de dados HuggingFace incluem Dataset e IterableDataset:
Existem dois tipos de objetos de conjunto de dados, um Dataset e um IterableDataset. Qualquer tipo de conjunto de dados que você escolher usar ou criar depende do tamanho do conjunto de dados. Em geral, umIterableDataseé ideal para grandes conjuntos de dados (pense em centenas de GBs!) devido ao seu comportamento preguiçoso e vantagens de velocidade, enquanto o Dataseé ótimo para todo o resto. Esta página irá comparar as diferenças entre Dataset e umIterableDataspara ajudá-lo a escolher o objeto de conjunto de dados certo para você.[3]
Ao percorrer esses dois tipos de conjuntos de dados, é retornado um dict, que não é suportado pelo mecanismo de processamento de dados do MindSpore. Portanto, duas classes de transferência são feitas para ler os dados no dict sem adicionar outras operações adicionais. Para Dataset, construa uma classe TransferDataset e leia-a no método __getitem__.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
Para streaming de dados IterableDataset, você precisa lê-los no método __iter__ e construir TransferIterableDataset como um objeto iterável.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
Neste ponto, um plano que requer pouco esforço e pode enxertar completamente os conjuntos de dados HuggingFace foi concluído. Comparada com o Paddle NLP, a estratégia de enxerto é simples e elegante.
03
para concluir
Como uma estrutura de código aberto, há, na verdade, um grande número de recursos de código aberto que podem ser usados. A chamada expansão contínua do ecossistema norte-sul não significa necessariamente adaptação, eu uso, você usa, você me usa. , e você está feliz e sem preocupações. Desta vez, os conjuntos de dados HuggingFace são enxertados no compartilhamento prático Shengsi MindSpore, que fornecerá uma compreensão mais profunda do Shengsi MindNLP e também ajudará a expandir o ecossistema Shengsi MindSpore.
referências
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Google confirmou demissões, envolvendo a "maldição de 35 anos" dos programadores chineses nas equipes Flutter, Dart e . Python Arc Browser para Windows 1.0 em 3 meses oficialmente GA A participação de mercado do Windows 10 atinge 70%, Windows 11 GitHub continua a diminuir a ferramenta de desenvolvimento nativa de IA GitHub Copilot Workspace JAVA. é a única consulta de tipo forte que pode lidar com OLTP + OLAP. Este é o melhor ORM. Nos encontramos tarde demais.