Este artigo se aprofunda nos princípios e recursos básicos do Autograd no PyTorch. Desde os conceitos básicos, interação do Tensor com o Autograd, até a construção e gerenciamento de gráficos computacionais, até os detalhes de retropropagação e cálculo de gradiente e, por fim, abrangendo os recursos avançados do Autograd.
Siga o TechLead e compartilhe conhecimento abrangente de IA. O autor tem mais de 10 anos de arquitetura de serviços de Internet, experiência em desenvolvimento de produtos de IA e experiência em gerenciamento de equipes. Ele possui mestrado pela Universidade Tongji na Universidade Fudan, membro do Fudan Robot Intelligence Laboratory, arquiteto sênior certificado pela Alibaba Cloud, um profissional de gerenciamento de projetos e pesquisa e desenvolvimento de produtos de IA com receita de centenas de milhões.

1. Pytorch e diferenciação automática Autograd
A Diferenciação Automática (abreviadamente Autograd) é uma das principais tecnologias no campo da aprendizagem profunda e da computação científica. Ele não apenas desempenha um papel vital no processo de treinamento de redes neurais, mas também desempenha um papel fundamental em soluções numéricas para vários problemas científicos e de engenharia.
1.1 Princípios básicos de diferenciação automática
Em matemática, o cálculo diferencial é um método de cálculo da taxa local de variação de uma função e é amplamente utilizado em física, engenharia, economia e outros campos. A diferenciação automática é uma tecnologia que calcula automaticamente a derivada ou gradiente de uma função por meio de um programa de computador.
A chave para a diferenciação automática é decompor uma função complexa em uma série de combinações de funções simples e, em seguida, aplicar a Regra da Cadeia para derivar a derivação. Este processo difere da diferenciação numérica (que usa aproximação de diferenças finitas) e da diferenciação simbólica (que realiza derivação simbólica) porque pode calcular derivadas com precisão, evitando o problema de expansão de expressão da diferenciação simbólica e a perda de precisão da diferenciação numérica.
import torch
# 示例:简单的自动微分
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2 + 3 * x + 1
y.backward()
# 打印梯度
print(x.grad) # 输出应为 2*x + 3 在 x=2 时的值,即 7
1.2 Aplicação de diferenciação automática em aprendizagem profunda
No aprendizado profundo, o núcleo do treinamento de uma rede neural é otimizar a função de perda, ou seja, ajustar os parâmetros da rede para minimizar a perda. Este processo requer o cálculo do gradiente da função de perda em relação aos parâmetros da rede, e a diferenciação automática desempenha um papel fundamental aqui.
Tomando como exemplo um modelo de regressão linear simples, o objetivo do modelo é encontrar um conjunto de parâmetros que tornem as previsões do modelo o mais próximas possível dos dados reais. Neste processo, a diferenciação automática nos ajuda a calcular efetivamente o gradiente da função de perda em relação aos parâmetros e, em seguida, atualizar os parâmetros através do método de gradiente descendente.
# 示例:线性回归中的梯度计算
x_data = torch.tensor([1.0, 2.0, 3.0])
y_data = torch.tensor([2.0, 4.0, 6.0])
# 模型参数
weight = torch.tensor([1.0], requires_grad=True)
# 前向传播
def forward(x):
return x * weight
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 计算梯度
l = loss(x_data, y_data)
l.backward()
print(weight.grad) # 打印梯度
1.3 A importância e o impacto da diferenciação automática
A introdução da tecnologia de diferenciação automática simplifica muito o processo de cálculo do gradiente, permitindo que os pesquisadores se concentrem no projeto e no treinamento do modelo sem ter que calcular manualmente derivadas complexas. Isso contribuiu para o rápido desenvolvimento do aprendizado profundo, especialmente no treinamento de grandes redes neurais.
Além disso, a diferenciação automática também mostrou o seu forte potencial em campos de aprendizagem não profunda, como aplicações em simulação física, engenharia financeira e bioinformática.
2. O mecanismo central do PyTorch Autograd
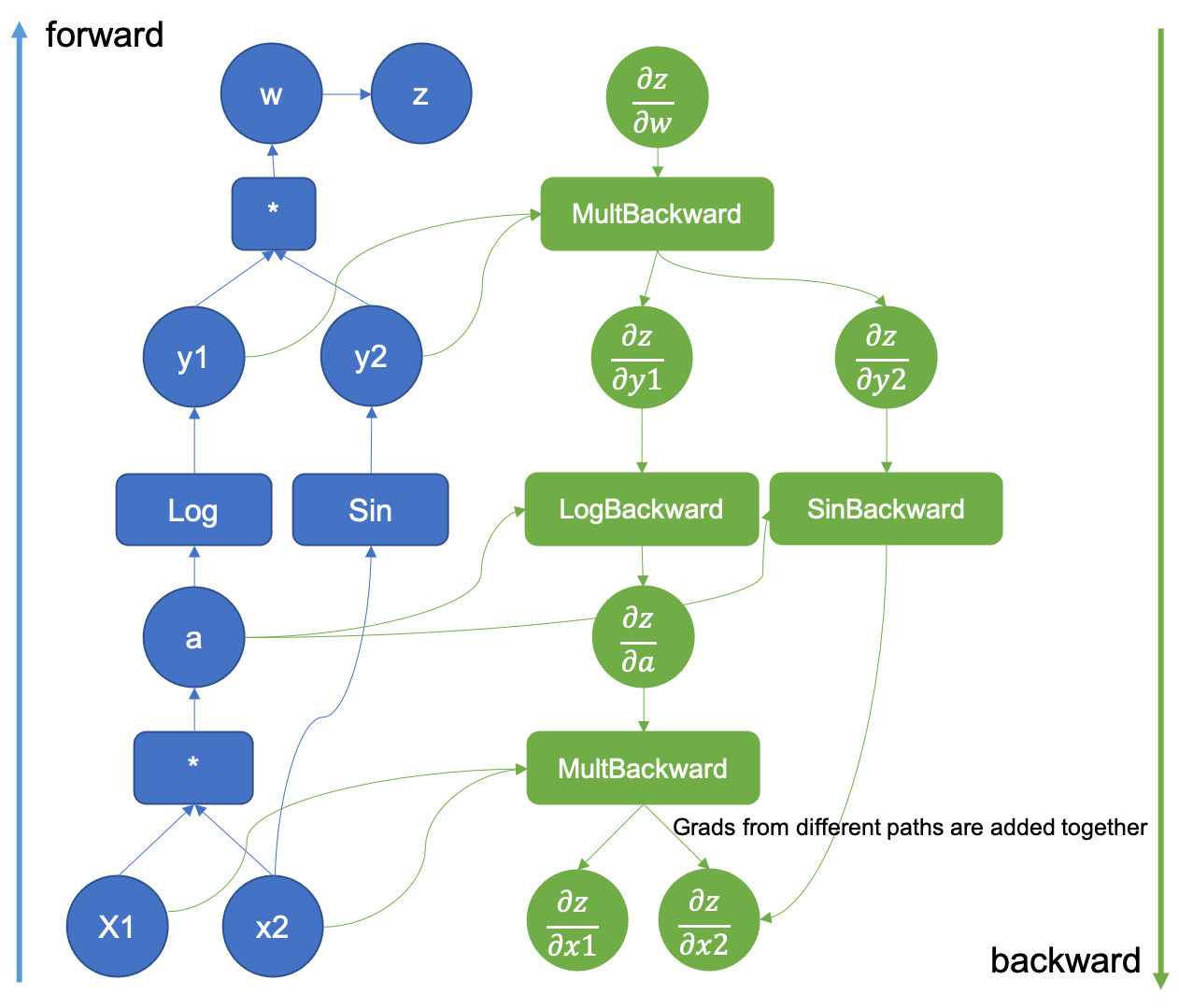
PyTorch Autograd é uma ferramenta poderosa que permite que pesquisadores e engenheiros calculem derivadas de maneira eficiente com intervenção manual mínima. Compreender seu mecanismo central não apenas ajudará você a fazer melhor uso dessa ferramenta, mas também ajudará os desenvolvedores a evitar erros comuns e a melhorar o desempenho e a eficiência do modelo.
2.1 Interação entre Tensor e Autograd

No PyTorch, o Tensor é a base para a construção de redes neurais e o Autograd é a chave para a implementação do treinamento de redes neurais. Compreender como o Tensor e o Autograd funcionam juntos é fundamental para uma compreensão profunda e um uso eficaz do PyTorch.
Tensor: o núcleo do PyTorch
Os tensores no PyTorch são semelhantes aos arrays NumPy, mas têm um superpoder adicional - a capacidade de calcular gradientes automaticamente no sistema Autograd.
- Propriedades do tensor: Cada tensor possui uma propriedade
requires_grad. Quando definido comoTrue, o PyTorch rastreará todas as operações neste Tensor e calculará automaticamente os gradientes.
Autograd: um motor para diferenciação automática
Autograd é o mecanismo de diferenciação automática do PyTorch, responsável por rastrear as operações importantes para o cálculo de gradientes.
- Gráfico computacional: Nos bastidores, o Autograd monitora as operações criando um gráfico computacional. Este gráfico é um gráfico acíclico direcionado (DAG) que registra todas as operações envolvidas na criação do Tensor de saída final.
Tensor e Autograd trabalhando juntos
Quando um Tensor é operado e um novo Tensor é gerado, o PyTorch constrói automaticamente um nó gráfico computacional que representa a operação.
-
Exemplo: Rastreamento de operações simples
import torch # 创建一个 Tensor,设置 requires_grad=True 来跟踪与它相关的操作 x = torch.tensor([2.0], requires_grad=True) # 执行一个操作 y = x * x # 查看 y 的 grad_fn 属性 print(y.grad_fn) # 这显示了 y 是通过哪种操作得到的Aqui
yé obtido através de uma operação de multiplicação. PyTorch rastreia automaticamente esta operação e a torna parte do gráfico computacional. -
Retropropagação e cálculo de gradiente
Quando chamamos o método
.backward()no Tensor de saída, o PyTorch calculará automaticamente o gradiente e o armazenará no atributo.gradde cada Tensor.# 反向传播,计算梯度 y.backward() # 查看 x 的梯度 print(x.grad) # 应输出 4.0,因为 dy/dx = 2 * x,在 x=2 时值为 4
2.2 Construção e gerenciamento de gráficos computacionais
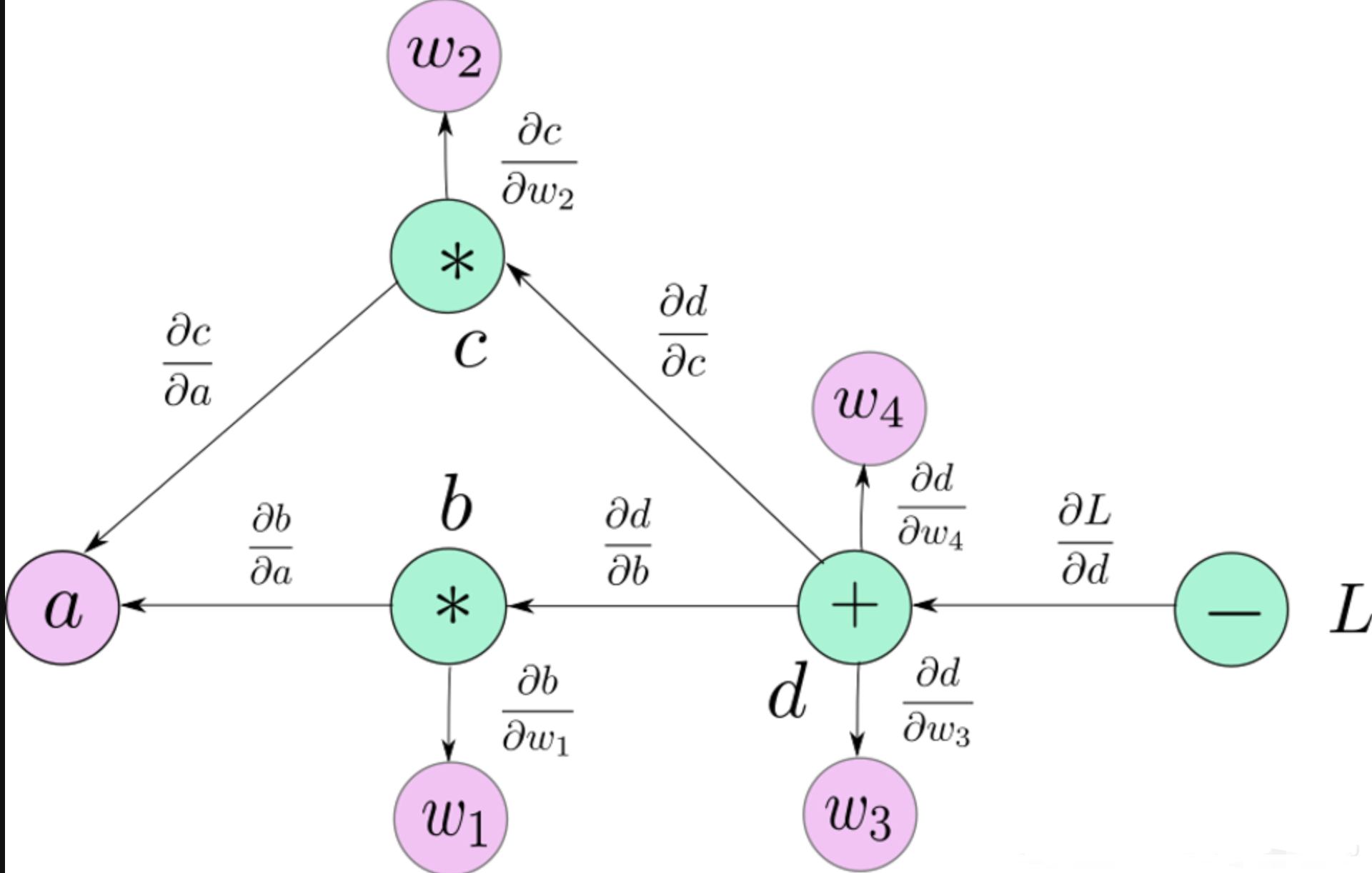
No aprendizado profundo, compreender a construção e o gerenciamento de gráficos computacionais é fundamental para compreender a diferenciação automática e o processo de treinamento da rede neural. PyTorch utiliza gráficos computacionais dinâmicos, um de seus principais recursos, que oferece grande flexibilidade e intuitividade.
Conceitos básicos de gráficos computacionais
Gráfico computacional é um método de representação gráfica usado para descrever a operação (como adição, multiplicação) de relacionamento entre dados (Tensor). No PyTorch, sempre que uma operação é realizada em um Tensor, é criado um nó que representa a operação e os Tensores de entrada e saída da operação são conectados.
- Nó: representa operações de dados, como adição e multiplicação.
- Edge: representa o fluxo de dados, ou seja, Tensor.
Características dos gráficos de computação dinâmica
O gráfico computacional do PyTorch é dinâmico, ou seja, a construção do gráfico ocorre em tempo de execução. Isso significa que o gráfico é construído em tempo real à medida que o código é executado, resultando potencialmente em um novo gráfico para cada iteração.
-
Exemplo: Criação de gráficos dinâmicos
import torch x = torch.tensor(1.0, requires_grad=True) y = torch.tensor(2.0, requires_grad=True) # 一个简单的运算 z = x * y # 此时,一个计算图已经形成,其中 z 是由 x 和 y 通过乘法操作得到的
Retropropagação e gráficos computacionais
Durante o processo de treinamento de aprendizagem profunda, a retropropagação é realizada por meio de gráficos computacionais. Quando o método .backward() é chamado, o PyTorch começará a partir desse ponto e se propagará para trás ao longo do gráfico, calculando o gradiente de cada nó.
-
Exemplo: processo de retropropagação
# 继续上面的例子 z.backward() # 查看梯度 print(x.grad) # dz/dx,在 x=1, y=2 时应为 2 print(y.grad) # dz/dy,在 x=1, y=2 时应为 1
Gerenciamento de gráficos computacionais
Em aplicações práticas, o gerenciamento de gráficos computacionais é um aspecto importante para otimizar a memória e a eficiência computacional.
-
Limpar o gráfico: por padrão, o PyTorch limpará automaticamente o gráfico de cálculo após chamar
.backward(). Isto significa que cada chamada.backward()é um cálculo independente. Isso ajuda a economizar memória para tarefas que envolvem múltiplas iterações. -
Desativar rastreamento de gradiente: em alguns casos, como durante a avaliação do modelo ou fases de inferência, os gradientes não precisam ser calculados. Use
torch.no_grad()para desativar temporariamente os cálculos de gradiente, melhorando a eficiência computacional e reduzindo o uso de memória.with torch.no_grad(): # 在这个块内,所有计算都不会跟踪梯度 y = x * 2 # 这里 y 的 grad_fn 为 None
2.3 Detalhes de retropropagação e cálculo de gradiente
Backpropagation é o algoritmo principal usado em aprendizado profundo para treinar redes neurais. No PyTorch, esse processo depende do sistema Autograd para calcular gradientes automaticamente. Compreender os detalhes da retropropagação e do cálculo do gradiente é crucial, não apenas para nos ajudar a entender melhor como as redes neurais aprendem, mas também para nos guiar no design e na depuração de modelos mais eficazes.
Noções básicas de retropropagação
O objetivo do algoritmo de retropropagação é calcular o gradiente da função de perda em relação aos parâmetros da rede. No PyTorch, isso normalmente é feito chamando o método .backward() na função de perda.
- Regra da cadeia: A retropropagação é baseada na regra da cadeia, que é usada para calcular as derivadas de funções compostas. Em um gráfico de computação, percorra para trás da saída para a entrada, multiplicando pelas derivadas ao longo do caminho.
Implementação PyTorch de retropropagação
Aqui está um exemplo simples do PyTorch que ilustra o processo básico de retropropagação:
import torch
# 创建 Tensor
x = torch.tensor(1.0, requires_grad=True)
w = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
# 构建一个简单的线性函数
y = w * x + b
# 计算损失
loss = y - 5
# 反向传播
loss.backward()
# 检查梯度
print(x.grad) # dy/dx
print(w.grad) # dy/dw
print(b.grad) # dy/db
Neste exemplo, a chamada loss.backward() aciona o processo de retropropagação de todo o gráfico de cálculo, calculando loss relativo a x, w e b gradientes.
acumulação de gradiente
No PyTorch, os gradientes são cumulativos por padrão. Isso significa que toda vez que .backward() for chamado, o gradiente será adicionado ao valor anterior em vez de ser substituído.
- Limpeza de gradiente: Na maioria dos loops de treinamento, precisamos limpar o gradiente antes de cada etapa de iteração para evitar que o acúmulo de gradiente afete o cálculo do gradiente da etapa atual.
# 清零梯度
x.grad.zero_()
w.grad.zero_()
b.grad.zero_()
# 再次进行前向和反向传播
y = w * x + b
loss = y - 5
loss.backward()
# 检查梯度
print(x.grad) # dy/dx
print(w.grad) # dy/dw
print(b.grad) # dy/db
gradiente de alto nível
PyTorch também oferece suporte a cálculos de gradiente de ordem superior, onde o próprio gradiente é diferenciado novamente. Isso é útil em alguns algoritmos de otimização avançados e aplicações de derivadas secundárias.
# 启用高阶梯度计算
z = y * y
z.backward(create_graph=True)
# 计算二阶导数
x_grad = x.grad
x_grad2 = torch.autograd.grad(outputs=x_grad, inputs=x)[0]
print(x_grad2) # d^2y/dx^2
3. Solução completa para recursos do Autograd
O sistema Autograd do PyTorch fornece um conjunto de recursos poderosos que o tornam uma ferramenta importante no aprendizado profundo e na diferenciação automática. Esses recursos não apenas aumentam a flexibilidade e a eficiência da programação, mas também viabilizam cálculos e otimizações complexas.
Gráfico Dinâmico
O sistema Autograd em PyTorch é baseado em gráficos de computação dinâmicos. Isso significa que o gráfico computacional é construído dinamicamente a cada execução, o que proporciona maior flexibilidade em comparação aos gráficos estáticos.
-
Exemplo: Adaptabilidade de Gráficos Dinâmicos
import torch x = torch.tensor(1.0, requires_grad=True) if x > 0: y = x * 2 else: y = x / 2 y.backward()Este código demonstra os recursos gráficos dinâmicos do PyTorch. Dependendo do valor de
x, o caminho de cálculo pode mudar, o que é difícil de conseguir em uma estrutura gráfica estática.
Função de diferenciação automática personalizada
O PyTorch permite que os usuários criem funções de diferenciação automática personalizadas herdando torch.autograd.Function, o que oferece a possibilidade de propagação direta e retroativa complexa ou especial.
-
Exemplo: função de diferenciação automática personalizada
class MyReLU(torch.autograd.Function): @staticmethod def forward(ctx, input): ctx.save_for_backward(input) return input.clamp(min=0) @staticmethod def backward(ctx, grad_output): input, = ctx.saved_tensors grad_input = grad_output.clone() grad_input[input < 0] = 0 return grad_input x = torch.tensor([-1.0, 1.0, 2.0], requires_grad=True) y = MyReLU.apply(x) y.backward(torch.tensor([1.0, 1.0, 1.0])) print(x.grad) # 输出梯度Este exemplo mostra como definir uma função ReLU personalizada e seu cálculo de gradiente.
requires_gradeno_grad
No PyTorch, requires_grad o atributo é usado para especificar se o gradiente de um determinado Tensor precisa ser calculado. torch.no_grad() O gerenciador de contexto é usado para desabilitar temporariamente a construção de todos os gráficos computacionais.
-
Exemplo: use
requires_gradSomano_gradx = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) with torch.no_grad(): y = x * 2 # 在这里不会追踪 y 的梯度计算 z = x * 3 z.backward(torch.tensor([1.0, 1.0, 1.0])) print(x.grad) # 只有 z 的梯度被计算Neste exemplo, o cálculo de
ynão afetará o gradiente porque ele está no blocotorch.no_grad().
Otimização de desempenho e gerenciamento de memória
O sistema Autograd do PyTorch também inclui recursos para otimização de desempenho e gerenciamento de memória, como checkpoint de gradiente (para reduzir o uso de memória) e execução atrasada (para otimizar o desempenho).
-
Exemplo: ponto de verificação de gradiente
Use
torch.utils.checkpointpara reduzir o uso de memória em redes grandes.import torch.utils.checkpoint as checkpoint def run_fn(x): return x * 2 x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) y = checkpoint.checkpoint(run_fn, x) y.backward(torch.tensor([1.0, 1.0, 1.0]))Este exemplo mostra como usar pontos de verificação de gradiente para otimizar o uso de memória.
Siga o TechLead e compartilhe conhecimento abrangente de IA. O autor tem mais de 10 anos de arquitetura de serviços de Internet, experiência em desenvolvimento de produtos de IA e experiência em gerenciamento de equipes. Ele possui mestrado pela Universidade Tongji na Universidade Fudan, membro do Fudan Robot Intelligence Laboratory, arquiteto sênior certificado pela Alibaba Cloud, um profissional de gerenciamento de projetos e pesquisa e desenvolvimento de produtos de IA com receita de centenas de milhões.