1. Introdução
O Flume é um sistema massivo de coleta, agregação e transmissão de logs altamente disponível, altamente confiável e distribuído. O Flume oferece suporte à personalização de vários remetentes de dados no sistema de log para coletar dados; ao mesmo tempo, o Flume fornece a capacidade de simplesmente processar dados e gravar em vários receptores de dados (personalizáveis). Entre eles, o Flume-NG é uma ramificação do Flume. Seu objetivo é ser significativamente mais simples, menor em tamanho e mais fácil de implantar. Sua arquitetura mais básica é mostrada na figura a seguir: Flume-NG consiste em Agentes, e cada Agente consiste
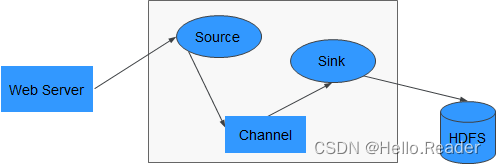
em Source, Channel e Sink são compostos por três módulos: Source é responsável por receber dados, Channel é responsável pela transmissão de dados e Sink é responsável por enviar dados para a próxima extremidade.
2. Descrição do módulo
| nome | ilustrar |
|---|---|
| Fonte | A Origem é responsável por receber dados ou gerar dados por meio de um mecanismo especial e agrupar dados em um ou mais Canais. Existem dois tipos de Fonte: baseada em dados e pesquisa. Os tipos típicos de fontes são os seguintes: 1. Fontes integradas ao sistema: Syslog, Netcat. 2. Fontes de eventos gerados automaticamente: Exec, SEQ. 3. IPC Fontes para comunicação entre Agente e Agente: Avro. 4. A Fonte deve estar associada a pelo menos um Canal. |
| Canal | O canal está localizado entre a origem e o coletor e é usado para armazenar dados em cache da origem. Quando o coletor envia os dados com sucesso para o canal do próximo salto ou para o destino final, os dados são removidos do canal. O nível de persistência fornecido pelo Canal está relacionado ao tipo de Canal, e existem três tipos: 1. Canal de Memória: não persistente. 2. File Channel: Implementação de persistência baseada em WAL (Write-Ahead Logging). 3. Canal JDBC: Implementação de persistência baseada em Banco de Dados embarcado. O canal oferece suporte a transações, fornece garantias de pedido fracas e pode trabalhar com qualquer número de fontes e coletores. |
| Afundar | O Sink é responsável por transmitir os dados para o próximo salto ou destino final, removendo os dados do Canal após a conclusão bem-sucedida. Os tipos de coletores típicos são os seguintes: 1. Armazenar dados no coletor do terminal de destino final, como: HDFS, HBase. 2. Sink que é consumido automaticamente, como: Null Sink. 3. Coletor IPC para comunicação entre Agentes: Avro. Sink deve atuar em um canal exato. |
O Flume também pode ser configurado como várias Fontes, Canais e Sinks, conforme a figura a seguir:
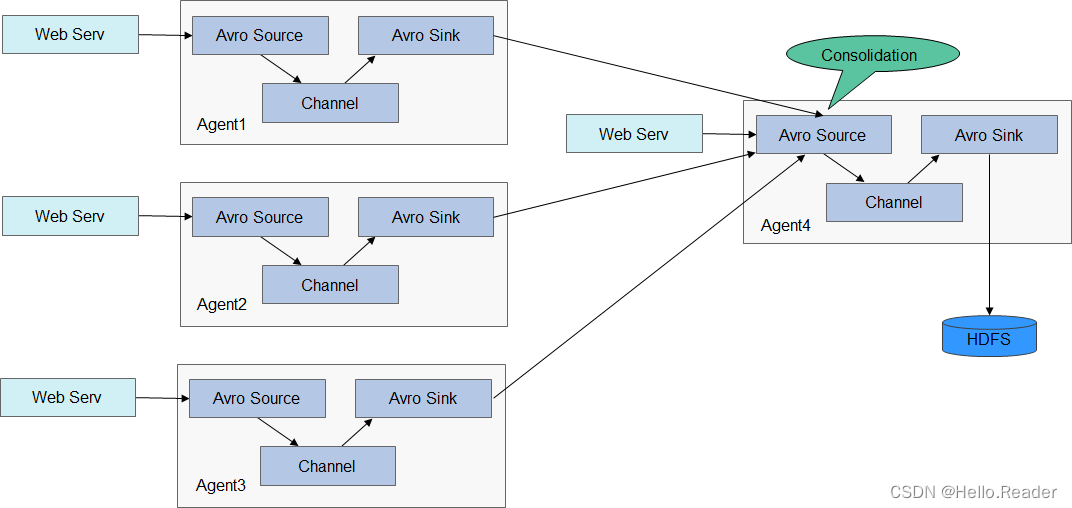
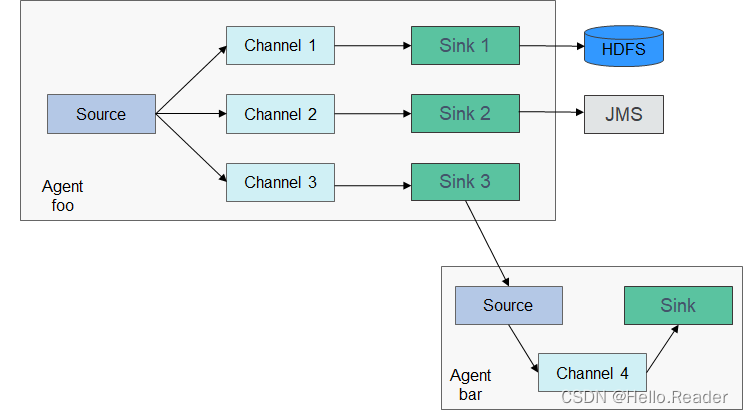 A confiabilidade do Flume é baseada na troca de transações entre os Agentes. Quando o próximo Agente cair, o Canal pode persistir os dados e o Agente irá transmiti-lo após a recuperação. A disponibilidade do Flume é baseada nos mecanismos integrados de balanceamento de carga e failover. Tanto o Canal quanto o Agente podem ser configurados com várias entidades, e estratégias como compartilhamento de carga podem ser usadas entre as entidades. Cada Agente é um processo JVM e o mesmo servidor pode ter vários Agentes. Os nós de coleta (Agent1, 2, 3) são responsáveis pelo processamento de logs e o nó de agregação (Agent4) é responsável por gravar no HDFS. O Agente de cada nó de coleta pode selecionar vários nós de agregação, que podem alcançar o balanceamento de carga.
A confiabilidade do Flume é baseada na troca de transações entre os Agentes. Quando o próximo Agente cair, o Canal pode persistir os dados e o Agente irá transmiti-lo após a recuperação. A disponibilidade do Flume é baseada nos mecanismos integrados de balanceamento de carga e failover. Tanto o Canal quanto o Agente podem ser configurados com várias entidades, e estratégias como compartilhamento de carga podem ser usadas entre as entidades. Cada Agente é um processo JVM e o mesmo servidor pode ter vários Agentes. Os nós de coleta (Agent1, 2, 3) são responsáveis pelo processamento de logs e o nó de agregação (Agent4) é responsável por gravar no HDFS. O Agente de cada nó de coleta pode selecionar vários nós de agregação, que podem alcançar o balanceamento de carga.
Para obter a arquitetura e os princípios detalhados do Flume, consulte: https://flume.apache.org/releases/1.9.0.html .
3. Princípio do Flume
Confiabilidade entre Agentes
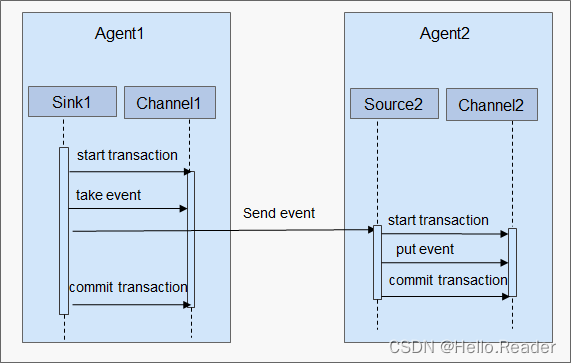
O fluxo de troca de dados entre Agentes é mostrado na figura abaixo.
-
O Flume adota um método baseado em Transações para garantir a confiabilidade da transmissão de dados. Quando os dados fluem de um Agente para outro, duas Transações já começaram a ser efetivadas. O Sink que envia o Agente primeiro busca uma mensagem do Canal, e envia a mensagem para outro Agente. Se o Agente receptor da mensagem aceitar e processar a mensagem com sucesso, o Agente remetente enviará Transações, indicando que uma transmissão de dados foi concluída com sucesso e confiabilidade.
-
Quando o Agente receptor recebe a mensagem enviada pelo Agente remetente, ele inicia uma nova Transação. Quando os dados são processados (escritos no Canal) com sucesso, o Agente receptor submete as Transações e envia uma resposta de sucesso ao Agente remetente.
-
Se a transmissão de dados falhar antes de um determinado commit (commit), as últimas Transações serão iniciadas novamente, e os dados que falharam no envio da última vez serão retransmitidos. Como a operação de confirmação já gravou as transações no disco, depois que o processo falhar e sair e retomar o negócio, as últimas transações ainda poderão ser continuadas.
4. A relação entre Flume e HDFS
Quando o usuário configura o HDFS como o Sink of Flume, o HDFS atua como o sistema de armazenamento de dados final do Flume, e o Flume grava todos os dados transmitidos no HDFS de acordo com a configuração.
5. A relação entre Flume e HBase
Quando o usuário configura o HBase como o Sink do Flume, o HBase serve como o sistema de armazenamento de dados final do Flume, e o Flume grava todos os dados transmitidos no HBase de acordo com a configuração.