paper:PP-LCNet: Uma Rede Neural Convolucional de CPU Leve
implementação oficial: PaddleClas/pp_lcnet.py no release/2.5 · PaddlePaddle/PaddleClas · GitHub
implementação de terceiros: pytorch-image-models/mobilenetv3.py at main · huggingface/pytorch-image-models · GitHub
A inovação deste artigo
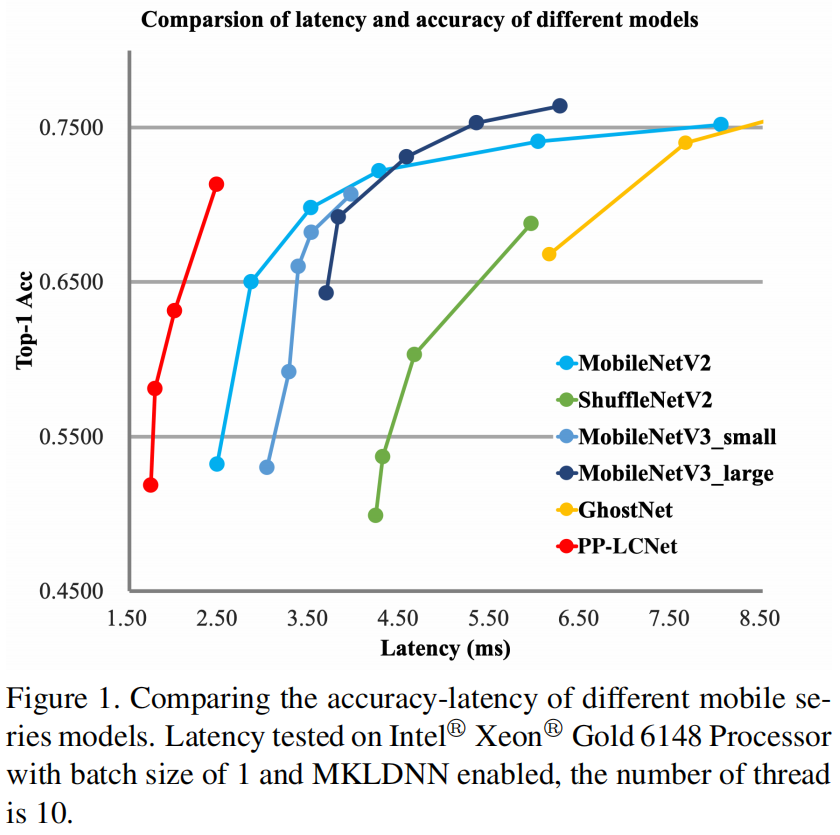
Embora existam muitas redes leves, a velocidade dessas redes não é ideal em CPUs Intel usando MKLDNN devido às limitações do MKLDNN. Este artigo projeta uma rede PP-LCNet para Inter-CPU, que supera a maioria dos modelos SOTA leves.
introdução do método
Embora existam muitos modelos leves que inferem rapidamente em dispositivos baseados em arquitetura ARM, poucas redes levam em consideração a velocidade em Inter-CPUs, especialmente quando estratégias de aceleração como MKLDNN são habilitadas. Muitos métodos que podem melhorar a precisão sem aumentar o tempo de inferência quando em dispositivos ARM, mas quando migrados para dispositivos Inter-CPU, os resultados podem ser diferentes. Este artigo resume algumas maneiras de melhorar a precisão do modelo com pouco aumento no tempo de inferência. Usamos o DepthSepConv no MobileNet v1 como o bloco básico, que não contém atalhos, para que não haja operações como concat ou elementwise-add, que não apenas diminuem a velocidade de inferência do modelo, mas também não melhoram a precisão de pequenos modelos. Além disso, esse bloco é profundamente otimizado pela biblioteca acelerada da Intel e a velocidade de inferência é mais rápida do que outros módulos leves, como bloco invertido ou bloco shufflenet. Empilhamos esses blocos em uma rede básica e, em seguida, combinamos algumas tecnologias existentes para obter o PP-LCNet.
Melhor função de ativação
O desempenho da função de ativação geralmente determina o desempenho da rede.De Sigmoid a ReLU, o desempenho da rede melhorou bastante. Recentemente, mais funções de ativação foram propostas. Depois de usar a função de ativação Swish no EfficientNet para obter melhor desempenho, o autor do MobileNet v3 atualizou para H-Swish para evitar um grande número de operações exponenciais. Este artigo também substitui o ReLU na rede básica por H-Swish, o desempenho foi muito melhorado e o tempo de raciocínio quase não aumentou.
Módulos SE em posições apropriadas
O módulo SE tem sido utilizado por um grande número de redes desde que foi proposto, mas no Inter-CPU, o módulo SE aumentará o tempo de inferência, portanto não pode ser utilizado em toda a rede. Através de vários experimentos, o autor descobriu que quando o módulo SE é usado no final da rede, ele pode desempenhar um papel melhor. Portanto, este trabalho usa apenas o módulo SE no bloco no final da rede para obter um melhor equilíbrio entre precisão e velocidade. Assim como o MobileNet v3, as funções de ativação das duas camadas do módulo SE são ReLU e H-Sigmoid, respectivamente.
Kernels de convolução maiores
O tamanho do kernel de convolução também afeta o desempenho da rede. No MixNet, o autor analisou o impacto de diferentes tamanhos de kernels de convolução no desempenho da rede e, finalmente, usou kernels de convolução de tamanhos diferentes na mesma camada da rede. Mas esse tipo de mistura reduz a velocidade de inferência da rede, portanto, este artigo usa apenas um tamanho de kernel de convolução na mesma camada e garante que kernels de convolução grandes sejam usados apenas sob a premissa de baixa latência e alta precisão. Por meio de experimentos, o autor constatou que utilizando a mesma posição do módulo SE, substituindo apenas a convolução 3x3 pela convolução 5x5 no final da rede obteve desempenho semelhante ao uso da convolução 5x5 em toda a rede, portanto no final apenas 5x5 a convolução foi usada no final da rede.
Camada conv 1x1 dimensional maior após GAP
No PP-LCNet, a dimensão de saída após o GAP é muito pequena e adicionar a camada de classificação diretamente posteriormente perderá a combinação de recursos. Para aumentar a capacidade de ajuste da rede, o autor adicionou uma convolução 1x1 de 1280 dimensões após o GAP, o que aumentou a capacidade do modelo e aumentou desprezivelmente o tempo de raciocínio.
Resultados experimentais
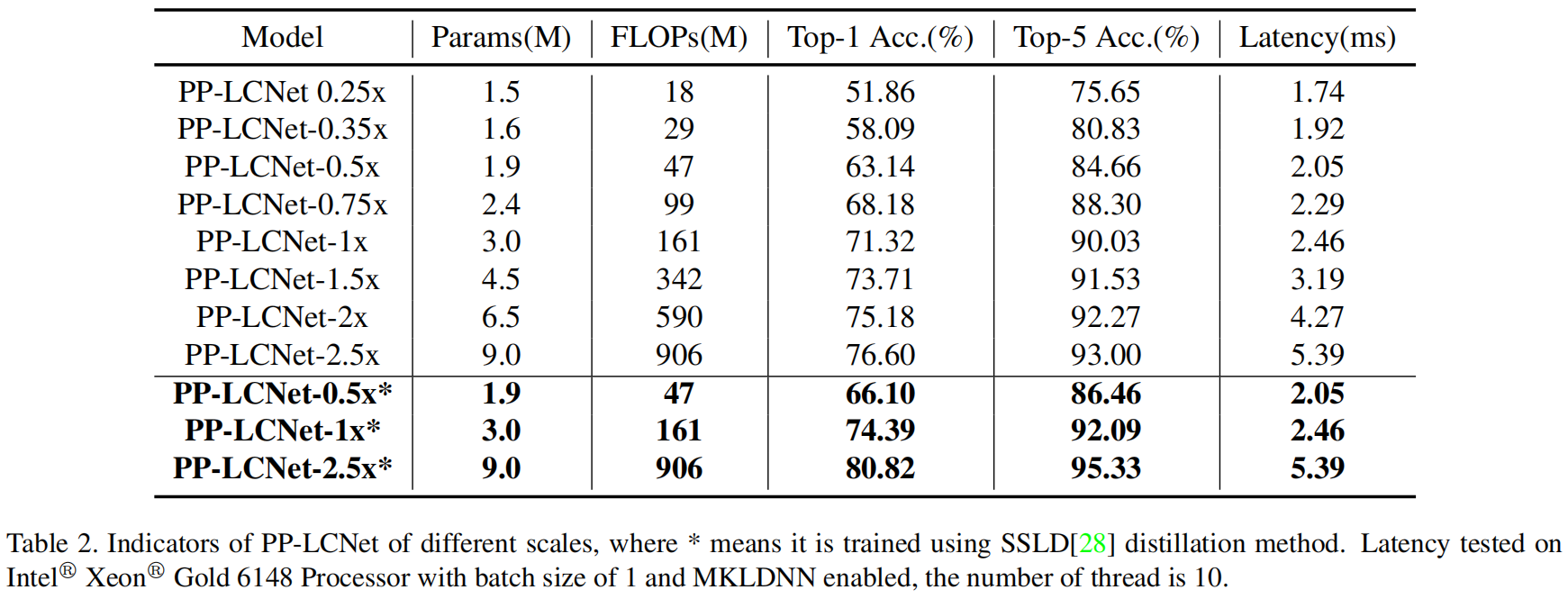
A precisão e o atraso do PP-LCNet em diferentes escalas no ImageNet são mostrados na Tabela 2
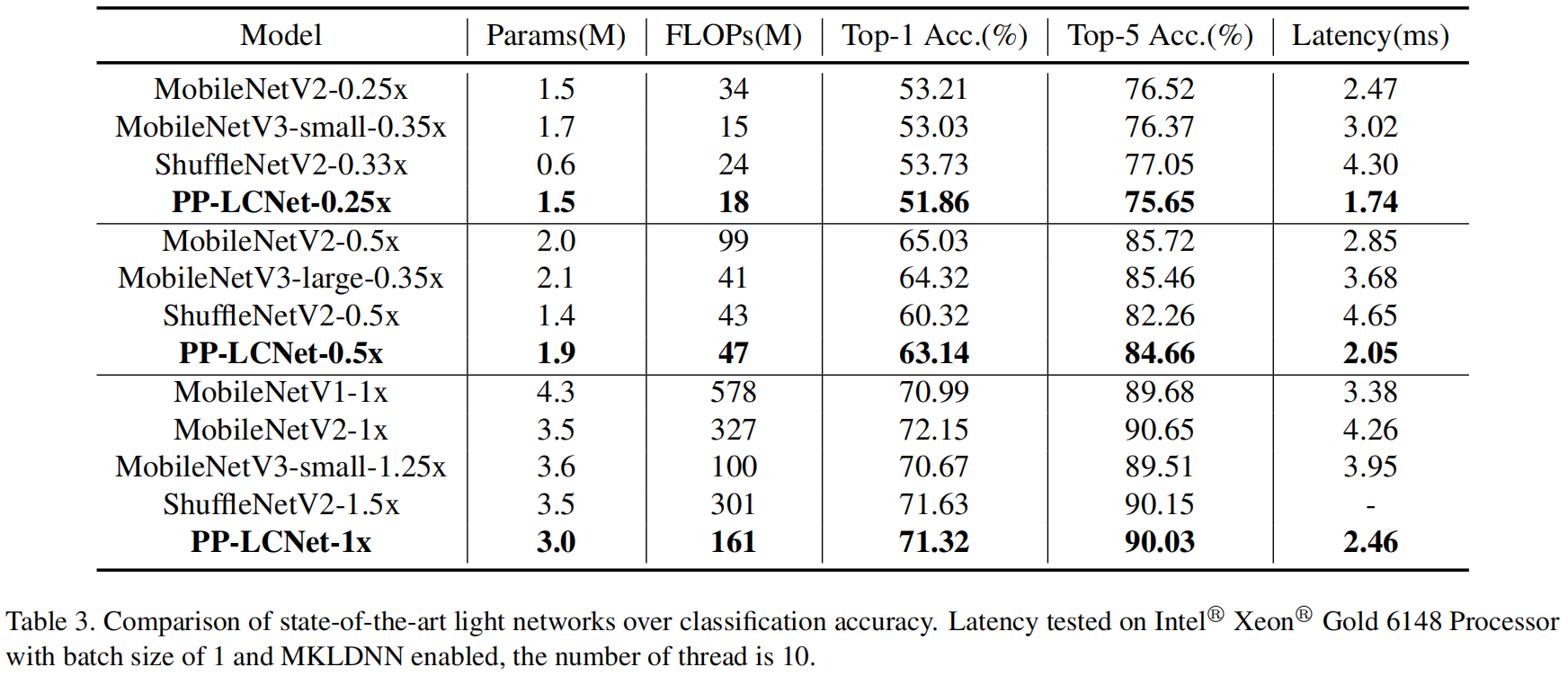
A comparação com outros modelos leves é mostrada na Tabela 3
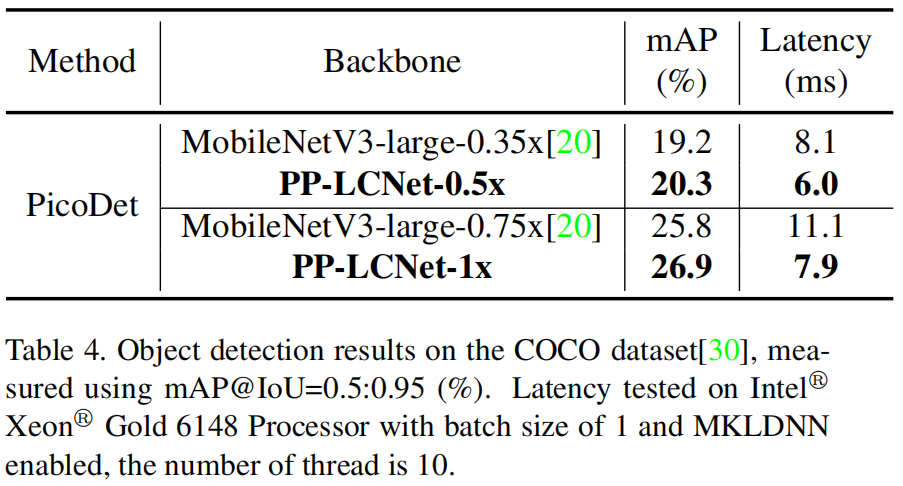
No modelo de detecção de alvo, PicoDet, PP-LCNet e MobileNet v3 são usados como backbone, e a comparação de mAP e atraso do modelo é mostrada na Tabela 4
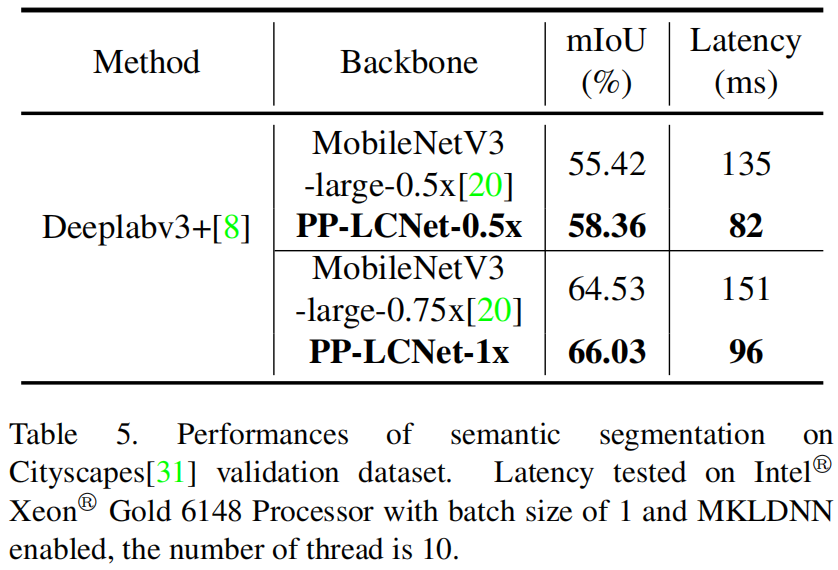
No modelo de segmentação semântica, Deeplabv3+, PP-LCNet e MobileNet v3 são usados como backbone, e a comparação de mIoU e atraso do modelo é mostrada na Tabela 5