Coma geléia sem cuspir a casca de geléia2023-07-29 12:22Publicado em Sichuan
Recomendação do editor:
Este artigo descreve os princípios e detalhes do LoRA em detalhes; ao mesmo tempo, faz uma interpretação detalhada dos experimentos no papel.
O seguinte artigo vem de Brief Notes on Moving Bricks of the Great Ape, autor Meng Yuan

Breves notas de grandes símios movendo tijolos.
Um code farmer com formação em contabilidade, aprendendo com todos.
【Clique】Junte-se ao grande grupo de troca de tecnologia de modelos
Em relação à explicação da parte LORA, iremos dividi-la em "artigos principais" e "artigos de código-fonte" .
No capítulo principal, analisaremos em detalhes as questões centrais, como como usar LoRA, por que funciona e quais vantagens e desvantagens existem por meio de diagramas . Especialmente quando você está aprendendo LoRA, se estiver confuso sobre a definição e a função de "classificação", este artigo pode fornecer algumas interpretações concretas.
No capítulo do código-fonte, analisaremos o código-fonte do Microsoft LoRA juntos e ajudaremos todos a usar a GPU gratuita na plataforma google colab para criar um ambiente de ajuste fino do LoRA , para que todos possam executar o código LoRA original por conta própria e aprofundar a compreensão do mecanismo operacional do LoRA (Felicidade sem dinheiro é a verdadeira felicidade).

1. Ajuste fino de parâmetros completos
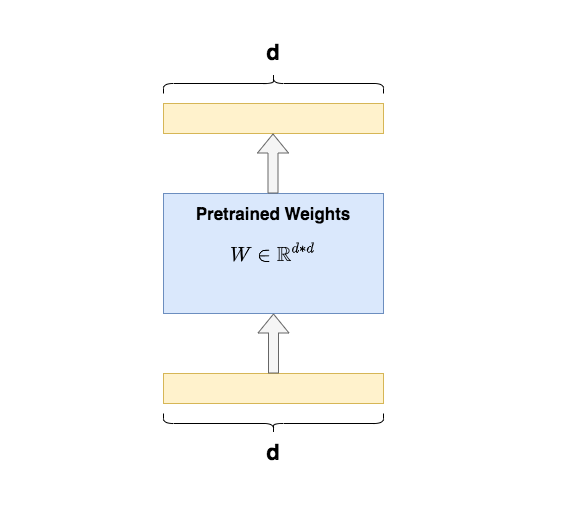
Sabemos que o significado do ajuste fino é pegar o modelo pré-treinado e fornecer a ele dados de tarefa downstream específicos, para que o modelo continue treinando nos pesos pré-treinados até atender aos padrões de desempenho da tarefa downstream. O modelo de pré-treinamento é como um extrator de recursos , que pode extrair recursos eficazes para nós com base na experiência aprendida com os dados de treinamento anteriores , melhorando muito o efeito do treinamento e a velocidade de convergência das tarefas a jusante.
O ajuste fino completo refere-se à atualização de cada parâmetro do modelo pré-treinado durante o treinamento de tarefas downstream . Por exemplo, na figura, é dado um exemplo de ajuste fino completo da matriz Q/K/V do Transformer . Para cada matriz, seus parâmetros devem participar da atualização durante o ajuste fino .d*d
Uma desvantagem significativa do ajuste fino completo é que é caro treinar . Por exemplo, o volume do parâmetro GPT3 é 175B , e só posso ficar longe dos nobres de cartão único, sem mencionar a sobrecarga quando um bug é encontrado no ajuste fino. Ao mesmo tempo, como o modelo comeu dados suficientes e ganhou experiência suficiente no estágio de pré-treinamento, só preciso encontrar uma maneira de adicionar um módulo de conhecimento adicional ao modelo , para que este pequeno módulo possa se adaptar ao meu downstream tarefas, e o corpo principal do modelo permanece. Basta deixá-lo inalterado (congelar) .
Como adicionar um módulo de conhecimento tão pequeno?
2. Ajuste do Adaptador e Ajuste do Prefixo
Vejamos dois métodos de ajuste fino locais convencionais antes do surgimento do LoRA: Ajuste do Adaptador e Ajuste do Prefixo. Esses também são os dois métodos de ajuste fino para comparações importantes no artigo original de LoRA.
2.1 Ajuste do Adaptador
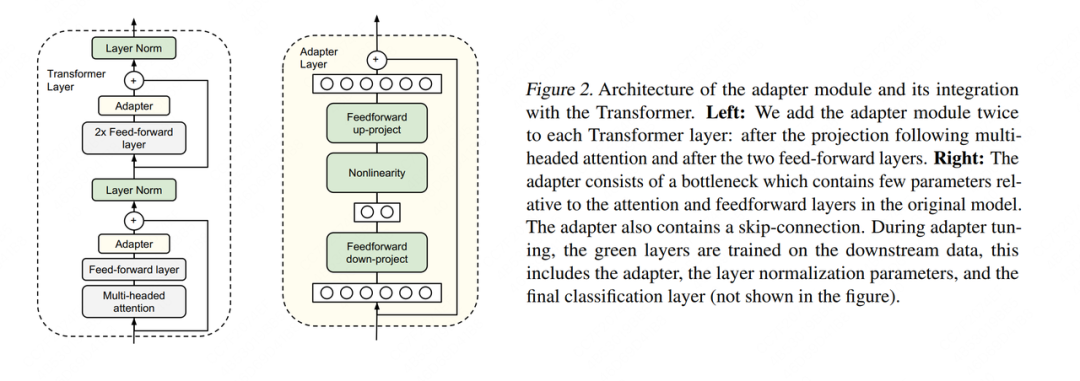
Existem muitos métodos de Adapter Tuning. Aqui citamos o método proposto por Houlsby et al., 2019, que também é o primeiro artigo citado quando esta tecnologia é mencionada no artigo LoRA.
O lado esquerdo da legenda é uma camada da estrutura do Transformer Layer, o Adapter é o que chamamos de “módulo de conhecimento extra”; o lado direito é a estrutura específica do Adatper. Ao ajustar, exceto a parte do adaptador, o restante dos parâmetros é congelado (congelar) , para que possamos reduzir efetivamente o custo do treinamento. A arquitetura interna do Adapter não é o foco deste artigo, portanto não a apresentaremos aqui.
Mas tal arquitetura de design tem uma desvantagem significativa: depois de adicionar o Adaptador, o número total de camadas do modelo se tornará mais profundo, o que aumentará a velocidade de treinamento e a velocidade de raciocínio . Os motivos são:
-
Necessidade de gastar poder de computação extra no Adaptador
-
Quando usamos treinamento paralelo (por exemplo: paralelismo de modelo tensor comumente usado na arquitetura do Transformer), a camada do adaptador gerará tráfego de comunicação adicional e aumentará o tempo de comunicação
2.2 Ajuste de prefixo

Existem também muitos métodos de ajuste de prefixo. Aqui escolhemos Li&Liang, 2021 para uma breve introdução. Neste artigo, o autor faz um ajuste fino adicionando um prefixo aos dados de entrada. Claro, o prefixo pode não apenas carregar a camada de entrada, mas também pode ser adicionado à saída da camada intermediária pela Camada do Transformador. Amigos interessados podem procurar artigos e fazer suas próprias pesquisas.
Conforme mostrado na figura, para um modelo generativo como GPT , um token de prefixo é adicionado na frente da sequência de entrada e dois tokens de prefixo são adicionados à legenda. Em aplicações práticas, o número de tokens de prefixo é um hiperparâmetro, que pode ser ajustado de acordo com o modelo real O efeito é ajustado. Para o modelo de arquitetura Codificador-Decodificador como BART , o token de prefixo é adicionado na frente de x e y ao mesmo tempo. No ajuste fino subsequente, precisamos apenas congelar o restante do modelo e treinar os parâmetros relacionados ao token de prefixo separadamente. Cada tarefa downstream pode treinar um conjunto de tokens de prefixo separadamente.
Então, qual é o significado do prefixo ? A função do prefixo é orientar o modelo a extrair informações relacionadas a x, para então gerar y melhor. Por exemplo, se quisermos fazer uma tarefa de resumo , após o ajuste fino, o prefixo pode perceber que o que estamos fazendo é uma tarefa de "formulário de resumo" e, em seguida, guiar o modelo para extrair informações importantes de x; se quisermos fazer uma tarefa de classificação de sentimento , o prefixo pode guiar o modelo para extrair as informações semânticas relacionadas à emoção em x, e assim por diante. Essa explicação pode não ser tão rigorosa, mas você pode entender aproximadamente o papel do prefixo.
Embora o Prefix Tuning pareça conveniente, ele também apresenta as duas desvantagens significativas a seguir :
-
É difícil de treinar e o efeito do modelo não aumenta estritamente com o aumento do parâmetro prefixo, o que também é apontado no artigo original
-
Isso reduzirá o comprimento efetivo da informação da camada de entrada. Para economizar memória de cálculo e vídeo, geralmente fixamos o comprimento dos dados de entrada. Depois de adicionar o prefixo, sobra menos espaço para os dados do texto original, portanto, a capacidade expressiva do prompt no texto original pode ser reduzida.
3. O que é LoRA
Para resumir, o ajuste fino completo do parâmetro é muito caro, o ajuste do adaptador tem atrasos de treinamento e inferência, o ajuste do prefixo é difícil de treinar e reduzirá o comprimento efetivo do texto nos dados de treinamento originais, então existe um método de ajuste fino que pode melhorar essas deficiências?
Impulsionado por tal motivação, o autor propôs um método de ajuste fino como o LoRA (Low-Rank Adaptation, adaptador de baixo escalão) . Vamos deixar de lado a explicação de palavras abstratas como "low rank" e "adaptador" Vamos primeiro ver como LoRA se parece e como usá-lo. Na próxima seção, explicaremos em detalhes o princípio do efeito de "classificação baixa".
3.1 Arquitetura geral do LoRA
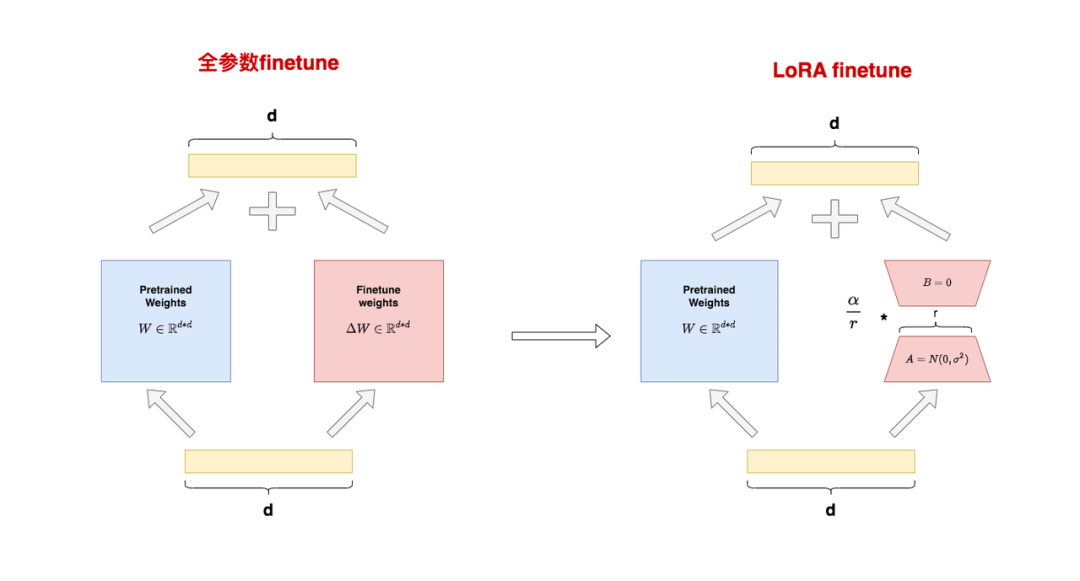
O lado esquerdo da figura mostra o cenário de "ajuste fino de parâmetro completo" . Dividimos os parâmetros em duas partes:
-
: pesos pré-treinados
-
: ajuste fino do peso incremental
A razão para esta divisão é que o ajuste fino completo do parâmetro pode ser entendido como "pesos pré-treinamento congelados" + "quantidade de atualização de peso gerada durante o ajuste fino" . Se a entrada for e a saída for, então:
O lado direito da figura representa a cena de "LoRA finetune" . No LoRA, usamos as matrizes A e B para aproximar a expressão:
-
: Uma matriz de posto baixo, onde é chamada de "posto", inicializada com um gaussiano para .
-
: Matriz de classificação baixa, inicializada com zero para B.
Após tal divisão, reescreveremos o formulário para d*dreduzir a quantidade de parâmetros de ajuste fino de para 2*r*d, sem alterar a dimensão dos dados de saída, ou seja, sob LoRA temos:
Além disso, foi mencionado no artigo original que, para duas matrizes de posto baixo, um hiperparâmetro (uma constante) será usado para fazer ajustes, mas não explica o papel desse hiperparâmetro. Depois de ler o código-fonte do LoRA, descobri que esse hiperparâmetro é multiplicado diretamente pela matriz de classificação baixa como a taxa de escala, ou seja, a saída final é :
Na prática, geralmente é usado, por exemplo, quando o código-fonte LoRA é ajustado para GPT2 e ao executar tarefas NLG, é usado. Apresentaremos o papel dessa taxa de escalonamento em detalhes posteriormente, bem como o significado específico de "classificação".
Métodos de inicialização para A e B
Deve-se observar que o objetivo de usar a inicialização gaussiana e a inicialização zero aqui é tornar o valor no início do treinamento 0, para que não traga ruído adicional ao modelo. Então você pode querer perguntar, posso fazer inicialização zero e inicialização gaussiana? Enfim, parece que é só deixar a inicialização ser 0?
Em resposta a esse problema, encontrei uma resposta do LoRA no problema do github:
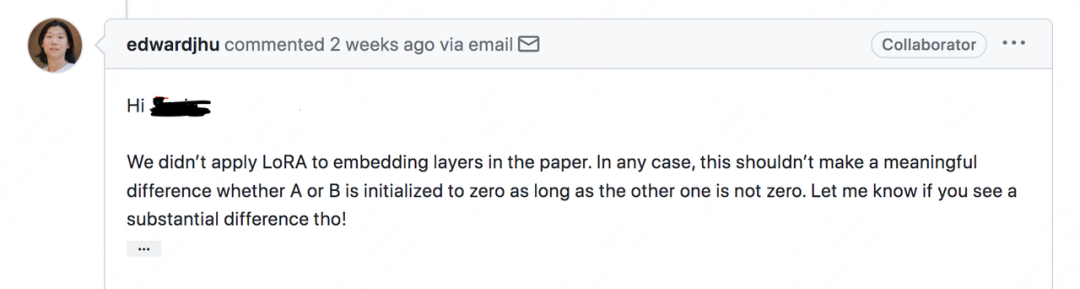
Resumindo, o autor atual não encontrou uma diferença significativa no método de inicialização da conversão, desde que um dos dois seja 0 e o outro não seja 0 .
Coma geléia sem cuspir pele de geléia
Visão de longo prazo, com foco na implementação de engenharia de IA (LLM/MLOps).
3.2 Treinamento LoRA e processo de raciocínio
Em 3.1, introduzimos a arquitetura geral do LoRA : as matrizes A e B de classificação baixa são usadas para aproximar as atualizações incrementais no caminho de desvio da matriz pré-treinada original. Você pode fazer isso na camada do modelo que desejar, como o peso da camada MLP no Transformer ou até mesmo o peso da parte Embedding. No papel original do LoRA, apenas a adaptação de baixo escalão é feita para os parâmetros da parte Atenção, mas na operação real, podemos definir de forma flexível o plano experimental de acordo com as necessidades e encontrar o melhor plano de adaptação.
3.2.1 Treinamento
Durante o treinamento , fixamos os pesos pré-treinados e treinamos apenas na soma da matriz de classificação baixa. Ao salvar pesos, precisamos salvar apenas partes da matriz de classificação baixa . De acordo com as estatísticas do artigo LoRA, essa operação reduz o consumo de memória de 1,2 TB para 350 GB ao ajustar o GPT3 175B; quando r = 4, o modelo final salvo cai de 350 GB para 35 MB, o que reduz bastante a sobrecarga de treinamento.
Em relação à parte do treinamento, vejamos outra questão interessante: No geral, LoRA economiza memória de vídeo significativamente, mas LoRA pode salvar memória de vídeo a cada momento do treinamento ?
Ao considerar para trás, para o cálculo do gradiente, conforme (para comodidade de digitação da fórmula, um item é temporariamente ignorado), temos:
Preste atenção a este item e você descobrirá que ele tem exatamente a mesma dimensão do peso pré-treinado d*d , ou seja, para o gradiente calculado, precisamos usar o mesmo resultado de valor intermediário de tamanho que no ajuste fino do parâmetro completo processo. Portanto, para LoRA, o pico de memória dessa camada é basicamente o mesmo do ajuste fino completo (se um item for contado, ele é maior do que o ajuste fino completo).
Mas por que LoRA pode reduzir o uso geral de memória , porque:
-
O LoRA não atua em todas as camadas do modelo, por exemplo, o LoRA no papel atua apenas na parte da atenção.
-
Embora o LoRA faça com que a memória de pico de uma determinada camada seja maior do que a quantidade total de ajuste fino, depois que o gradiente é calculado, o resultado intermediário pode ser limpo e não será salvo para sempre
-
Quando o peso a ser treinado
d*dé reduzido de2*r*d, os estados do otimizador que precisam ser salvos também são reduzidos (ou seja, fp32).
3.2.2 Raciocínio
No processo de inferência , mesclamos a matriz de classificação baixa e os pesos pré-treinados de acordo com o método e, em seguida, fazemos a inferência direta normalmente. Dessa forma, não mudaremos em nada a arquitetura do modelo, portanto, não haverá atraso de raciocínio como o Adapter Tuning . A figura abaixo mostra os resultados experimentais no artigo. A unidade de tempo de raciocínio é milissegundos. Pode-se constatar que a velocidade de raciocínio do LoRA é significativamente maior do que a do Adapter Tuning.
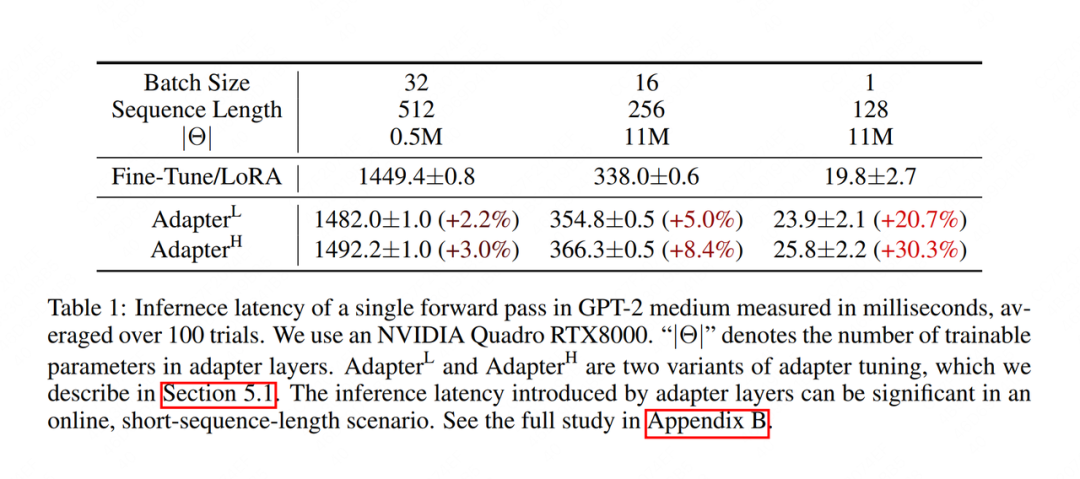
Ao alternar entre diferentes tarefas a jusante , podemos remover com flexibilidade partes de pesos de classificação baixa. Por exemplo, fazemos primeiro a tarefa downstream A, depois combinamos os pesos e mantemos os pesos de nível inferior separadamente. Quando mudamos para a tarefa downstream B, podemos ajustar subtraindo a parte de baixo peso dela e, em seguida, ativar o novo LoRA. Ou seja, cada tarefa downstream pode ter seu próprio conjunto de pesos de classificação baixa.
Você pode perguntar, após cada ajuste fino, devo combinar os pesos de classificação baixa no meio ? Posso armazenar "pesos pré-treinados" e "pesos de classificação baixa" separadamente? Claro, sem problemas, LoRA é muito flexível, você pode reescrever o código de acordo com suas próprias necessidades, decidir como economizar peso, desde que domine um princípio básico: se é adequado ou não, você sempre pode distinguir entre parte pré-treino e LoRA, em jogo. No capítulo de interpretação do código-fonte, veremos esse ponto em detalhes.
Parabéns! Neste ponto, você domina a estrutura do LoRA. Não é muito simples, você está ansioso para experimentar? No entanto, como um alquimista qualificado, para melhor depurar o processo de treinamento, precisamos estudar o princípio do LoRA mais profundamente.
4. O princípio da adaptação LoRA de baixo escalão
No artigo anterior, mencionamos repetidamente o conceito de "classificação" e explicamos que a classificação de LoRA é o hiperparâmetro. Ao mesmo tempo, também enfatizamos constantemente a aproximação de sim. Nesta seção, vamos dar uma olhada concreta em "rank" e explicar por que é "aproximado". Depois de entendê-los, podemos interpretar o papel dos hiperparâmetros e captar um certo sentimento de alquimia .
4.1 O que é classificação
Vamos primeiro olhar para uma matriz A:
A = [[1, 2, 3],
[2, 4, 6],
[3, 6, 9]]
Nesta matriz, linha2 = linha1 * 2, linha3 = linha1*3, ou seja, cada linha da matriz pode ser representada linearmente pela primeira linha .
Vejamos outra matriz B:
B = [[1, 2, 3],
[7, 11, 5],
[8, 13, 8]]
Nessa matriz, qualquer linha sempre pode ser representada por uma combinação linear das outras duas linhas .
Vamos finalmente olhar para uma matriz C:
C = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
Nesta matriz, nenhuma linha pode ser derivada de uma combinação linear das linhas restantes.
Chamando np.linalg.matrix_ranka função, podemos calcular o posto de qualquer matriz. Os postos das três matrizes acima são:
A = np.array(A)
B = np.array(B)
C = np.array(C)
print("Rank of A:", np.linalg.matrix_rank(A)) # 1
print("Rank of B:", np.linalg.matrix_rank(B)) # 2
print("Rank of C:", np.linalg.matrix_rank(C)) # 3
Para a matriz A, a classificação de A é 1 porque, desde que qualquer linha seja dominada, o restante das linhas pode ser derivado linearmente a partir dessa linha.
Para a matriz B, a classificação de B é 2 porque, desde que quaisquer duas linhas sejam dominadas, o restante das linhas pode ser derivado da combinação linear dessas duas linhas.
Para a matriz C, o posto de C é 3 porque três linhas devem ser totalmente dominadas para obter um C completo.
Vendo isso, você já tem uma compreensão perceptiva de classificação? Rank representa a quantidade de informação em uma matriz . Se uma determinada dimensão na matriz sempre pode ser derivada linearmente através das outras dimensões, então, para o modelo, a informação desta dimensão é redundante e repetidamente expressa. Para o caso de A e B, chamamos de rank deficiente , e para o caso de C, chamamos de rank completo . Para uma definição matemática mais rigorosa, você pode consultar "Álgebra Linear" (狗头).
Com esse entendimento de classificação, naturalmente pensamos que o peso incremental no ajuste fino do parâmetro completo também pode ter informações redundantes, portanto, não precisamos representá d*d-lo em tamanho real. Então, como descobrimos a dimensão de recurso realmente útil em ? A decomposição SVD (Singular Value Decomposition) pode nos ajudar a resolver este problema
4.2 decomposição SVD
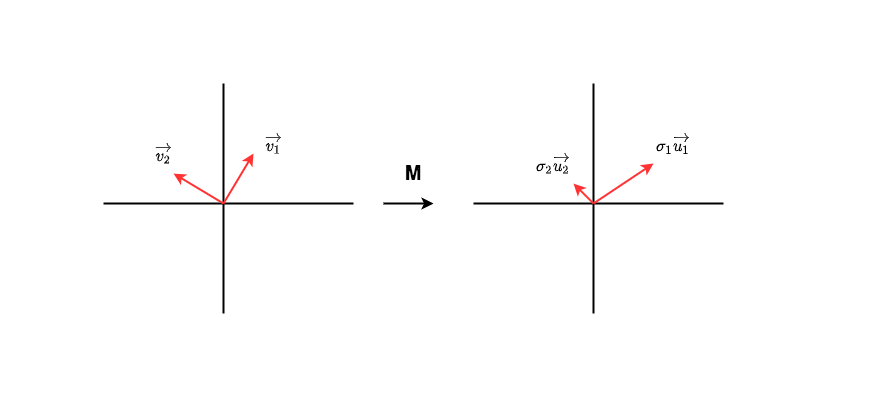
Conforme mostra a figura, a matriz é a matriz que precisamos para verificar a quantidade de informações. Assuma que no espaço de características dos dados de entrada existe um conjunto de vetores unitários ortogonais . Após a transformação, eles se tornam outro conjunto de vetores ortogonais, que também são um conjunto de vetores unitários ortogonais , respectivamente representando o módulo na direção correspondente . A alteração acima pode ser escrita como:
Com uma pequena reescrita, há:
Não é difícil descobrir que há um indício de "volume de informação" implícito em . Neste caso, as transformações transformadas são projetadas em , enfatizando as informações implícitas na direção 1.
Agora, um pouco mais amplamente, se pudermos encontrar esse conjunto de somas e organizar os valores da matriz de grande para pequeno, podemos desmontá-la e, ao mesmo tempo, descobrir os destacados durante o processo de desmontagem orientação do recurso? Quer dizer:
Quando encontramos essa matriz, retiramos as r linhas (ou colunas) superiores correspondentes das três, o que equivale a prestar atenção aos recursos de poucas dimensões mais enfatizados e, em seguida, podemos usar matrizes de dimensão inferior. a uma expressão aproximada ? O método de desmontar M de acordo com esse tipo de pensamento é chamado de decomposição SVD (decomposição de valor singular) . Não descreveremos seu método específico neste artigo, amigos interessados, ei, você também pode consultar "Álgebra Linear".
Vamos usar outro exemplo de código para sentir essa aproximação de forma mais intuitiva. Preste atenção aos comentários (exemplo adaptado de: https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first -principle- 7e1adec71541)
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
A saída é:
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40
O número de parâmetros é reduzido, mas não afeta o resultado final da saída . Por meio deste exemplo, todos podem entender melhor o papel das matrizes de baixo escalão~
4.3 Adaptação LoRA de baixo escalão
Bem, como a decomposição SVD é tão eficaz, posso fazer SVD diretamente e encontrar a matriz correspondente de baixo escalão, não é?
Embora a ideia seja boa, a dificuldade é óbvia: a premissa de poder fazer SVD diretamente é certa , mas na realidade, como o incremento de peso no ajuste fino do parâmetro completo, se você não ajustar os parâmetros completos novamente, como você pode saber o que parece? E se você fez o ajuste fino completo, o que precisa fazer com a adaptação de baixo escalão?
Ei, você pode pensar novamente: posso fazer SVD nos pesos pré-treinados, porque é certo.
Embora a ideia seja boa, a lógica é irracional: dissemos que o objetivo do ajuste fino é injetar no modelo um novo conhecimento de domínio relacionado a tarefas downstream . Ou seja, o significado da expressão e é diferente, o primeiro é conhecimento novo e o segundo é conhecimento antigo . Nosso objetivo é desmontar a dimensão rica em informação em conhecimento novo.
Bem, como não é viável fazer SVD diretamente por métodos matemáticos, deixe o modelo aprender a fazer SVD sozinho ! Portanto, a estratégia final de adaptação de baixo escalão do LoRA é: eu tomo o ranque como um hiperparâmetro e, em seguida, deixo o modelo aprender a matriz de baixo escalão sozinho. Isso não é simples e sem problemas!
Ok, aqui temos uma compreensão concreta do princípio da adaptação LoRA de baixo escalão, e também sabemos a diferença do significado expresso.Agora, podemos olhar para as perguntas que sobraram do artigo anterior: O que significa hiperparâmetro ?
4.4 Hiperparâmetros
Vejamos primeiro a explicação do par de papel:

Essa passagem significa aproximadamente que, quando usamos Adam como otimizador, o ajuste é equivalente a ajustar a taxa de aprendizado. De um modo geral, definimos as configurações para as que definimos quando experimentamos pela primeira vez, depois as corrigimos e depois apenas as ajustamos. A vantagem disso é que, quando tentamos diferentes, não precisamos ajustar outras É muito alto .
Não sei como você se sentiu quando leu esta passagem pela primeira vez, mas mesmo assim não entendi. O Google procurou novamente, mas não encontrou uma explicação específica. Até passar pelas ideias de design da adaptação de baixo escalão do LoRA, parecia entender algo. Deixe-me falar sobre minha opinião pessoal abaixo.
Primeiro, revise nosso método de cálculo de saída como:
onde , denota os pesos pré-treinados (antigo conhecimento), e denota a aproximação dos pesos incrementais (novo conhecimento). Teoricamente falando, quando é menor, extraímos a dimensão com mais informações no meio, e a informação é refinada, mas não abrangente; quando é maior, nossa aproximação de baixo escalão é mais próxima , e a informação é mais abrangente neste tempo, mas com mais ruído vem (contém muita informação redundante e inválida).
Com base nessa conjectura, quando fizermos o experimento pela primeira vez, tentaremos ajustá-lo o maior possível, por exemplo: 32, 64, e assumiremos que sob esse posto, os pesos de posto baixo já são muito semelhantes, portanto, definimos neste momento, o que significa Então, assumimos que o efeito do ajuste fino de baixa classificação de LoRA é igual ao do ajuste fino de parâmetro completo.
Então, a seguir, definitivamente tentaremos ir para o pequeno. Neste momento, nós o corrigimos, o que significa que, à medida que diminui, ele se tornará cada vez maior. O motivo pelo qual fazemos isso é:
-
Quando o valor é menor, a informação representada pela matriz de baixo escalão é refinada, mas não abrangente. Ampliamos a influência de novos conhecimentos no modelo no processo de encaminhamento ajustando o tamanho.
-
Quando é menor, a informação representada pela matriz de classificação baixa é refinada e há menos ruído/informação redundante. Neste momento, a direção da descida do gradiente é mais certa. Portanto, podemos aumentar o ritmo do gradiente descida aumentando-a, o que equivale a ajustar a taxa de aprendizado .
Bem, aqui, aprendemos juntos a ideia central da adaptação de baixo escalão de LoRA. Como dissemos antes, como SVD não pode ser usado para decomposição direta, o autor espera que LoRA possa "aprender" a matriz de decomposição real de baixo escalão, mas como provar que o que LoRA aprende está relacionado ao que SVD decompõe? A seguir, vamos interpretar juntos o experimento do autor.
5. Experimento LoRA: verificar a eficácia da matriz de classificação baixa
5.1 Efeito geral
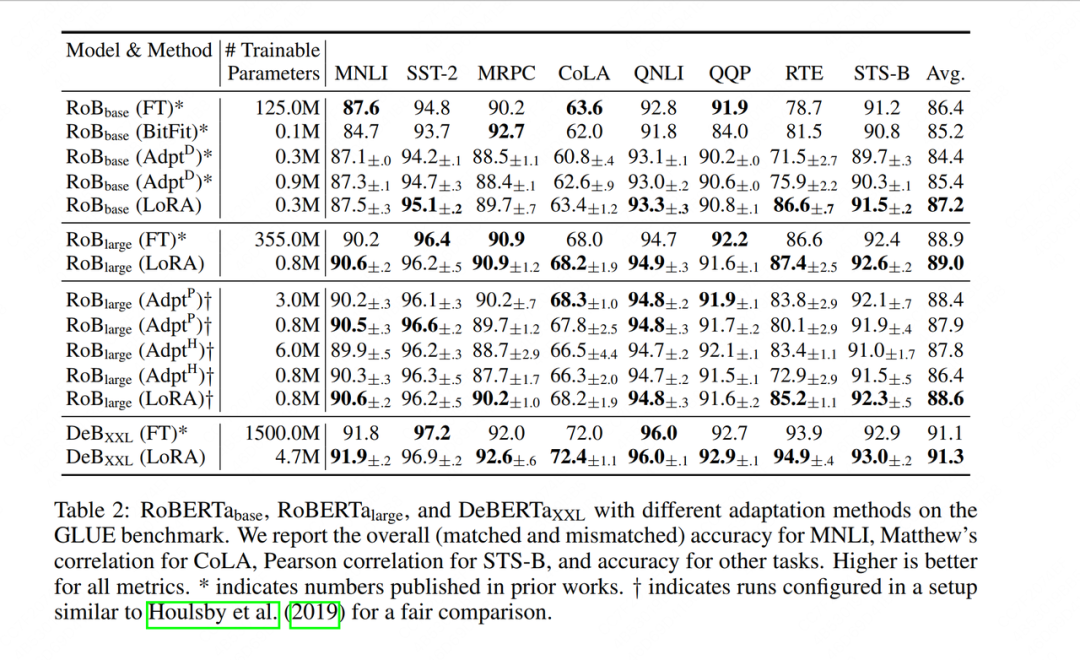
Primeiro, o autor comparou LoRA com outros métodos de ajuste fino (ajuste completo de parâmetros, ajuste de adaptador, etc.). As colunas verticais representam diferentes modelos de ajuste fino, as colunas horizontais representam diferentes conjuntos de dados e as partes em negrito representam os melhores indicadores de desempenho. Pode-se constatar que o LoRA obteve bom desempenho tanto no índice de precisão de ajuste fino de cada conjunto de dados quanto no índice de precisão de ajuste fino médio final (Avg.), e o número de parâmetros que ele pode treinar também é muito pequeno.
5.2 Verificação do conteúdo das informações da matriz de baixo escalão
Como dissemos antes, quanto menor o valor, mais refinada é a informação contida na matriz de baixo escalão, mas ao mesmo tempo pode ser menos abrangente. Então, quanto é apropriado?
5.2.1 Verifique diretamente o efeito de ajuste fino sob diferentes valores de r
Embora em teoria possamos incorporar adaptadores de baixo escalão (como Incorporação, Atenção, MLP etc.) paper também encoraja os leitores a fazer mais outras tentativas), vejamos os resultados experimentais da camada Atenção:
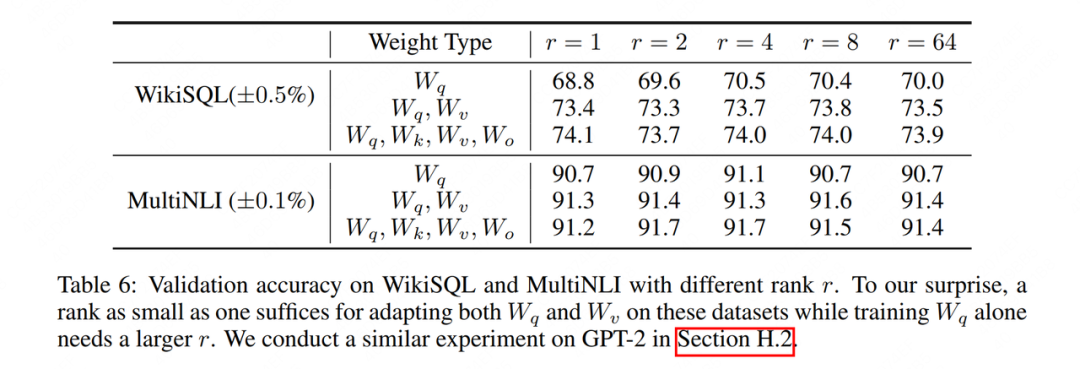
WikiSQLe MultiNLIé o conjunto de dados usado para ajuste fino, e o Tipo de Peso indica qual parte da Atenção é usada para adaptação de classificação baixa. Pode-se descobrir que o efeito de Yu é quase o mesmo, ou até um pouco melhor. Isso ilustra ainda mais a eficácia da "classificação baixa". Para verificar isso mais visualmente, examinamos ainda o grau de interseção com esses dois espaços de classificação baixa.
5.2.2 Grau de interseção de diferentes espaços de classificação baixa
Assumindo que e são matrizes de baixo escalão treinadas sob e respectivamente, agora queremos fazer algo assim:
-
Pegue a dimensão mais informativa (da qual)
-
Pegue a dimensão mais informativa (da qual)
-
Calcule o grau de interseção entre esta dimensão e uma dimensão para determinar o grau de coincidência de informações entre duas matrizes de classificação baixa
Bem, como descubro a dimensão superior com mais informações? Não se esqueça, temos o método SVD , e desta vez a soma é determinística. Portanto, podemos realizar a decomposição SVD na matriz de classificação baixa e, em seguida, obter a matriz singular correta das duas (isto é, a mencionada acima), mas no artigo LoRA, ela é usada para representar a matriz singular correta, então fazemos como os romanos, fazemos:
-
A matriz singular direita representada pela matriz singular direita representa a dimensão mais informativa da matriz singular direita (reveja o artigo anterior e julgue o conteúdo da informação)
-
A matriz singular direita representada por é a dimensão mais informativa da matriz singular direita.
Bem, depois de esclarecer essas definições, podemos olhar para a dimensão do recurso e calcular o grau de interseção com a dimensão do recurso. Esse índice de interseção também é chamado de " distância de Grassmann ".
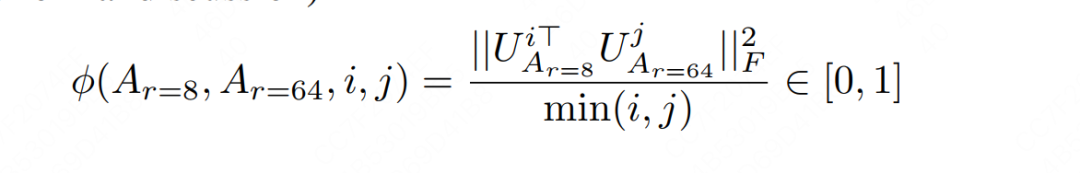
Pode ser visto na fórmula acima que o grau de interseção (distância de Grassmann) está entre e quanto maior o valor, mais semelhantes são os dois subespaços correspondentes. Amigos interessados podem consultar as provas relevantes no apêndice G do artigo. Nós nos concentramos apenas na conclusão aqui.
Ok, depois de calcular esse indicador, vamos visualizá-lo, então o autor continua dando as quatro fotos a seguir:
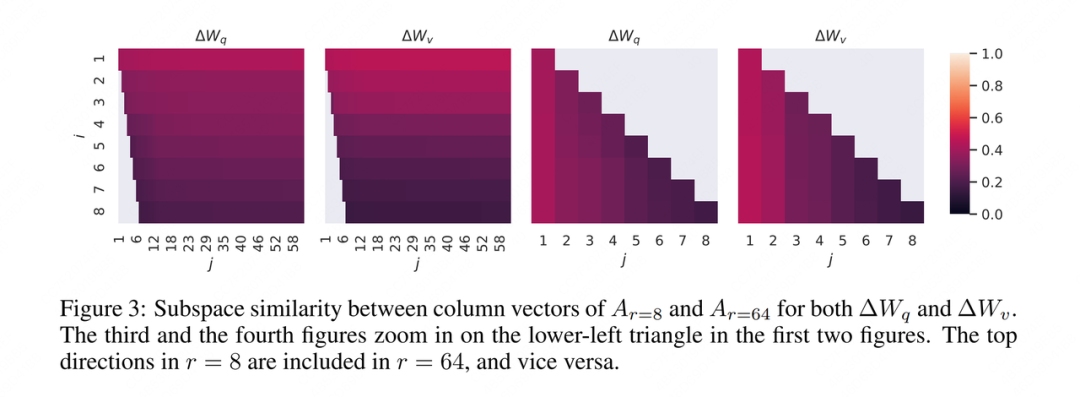
Não sei como você se sentiu quando viu essa foto pela primeira vez, enfim, não entendi (ei, parece que já ouvi isso antes). Então aqui está minha interpretação (irresponsável) novamente.
Em primeiro lugar, o autor fez uma decomposição de baixo escalão acima, então as fotos 1 e 3 e as fotos 2 e 4 são respectivamente um grupo, vamos escolher as fotos 1 e 3 para ver.
Em segundo lugar, o objetivo do experimento do autor é ver quanta informação do espaço de baixo escalão está contida no espaço de alto escalão, de modo a explicar por que o efeito da soma é basicamente o mesmo .
Portanto, a lógica do autor ao calcular a distância de Grassmann e desenhar o gráfico é:
-
Sim, naquela época, eu queria calcular a similaridade com , para saber quanto da informação unidimensional mais abundante contida em .
-
Sim, naquela época, eu queria calcular a similaridade com , para saber quanto da informação bidimensional mais abundante contida em .
-
Por analogia, porque o que eu quero verificar é o grau de inclusão do espaço de fila grande () ao espaço de fila pequena (), então eu só desenho a parte, e o resto não é desenhado. É por isso que há um espaço em branco no canto inferior esquerdo da Figura 1.
-
Essa parte, ou seja, a medida em que o espaço de fila pequena inclui a dimensão superior no espaço de fila grande, embora eu não a tenha desenhado na Figura 1, posso desenhá-la separadamente na Figura 3. Portanto, a Figura 3 é, na verdade, o preenchimento da parte que falta no canto inferior esquerdo da Figura 1.
Ok, agora que isso está explicado, vamos ver a legenda em detalhes. Quanto mais clara a cor, maior a semelhança . Na Figura 1, não é difícil perceber que a cor dessa linha é a mais clara, e a cor fica gradativamente mais escura com o aumento de . Isso mostra que no espaço de posto pequeno, as feições dimensionais com maior conteúdo de informação têm um maior grau de interseção com o espaço de posto grande, então elas também são a principal razão pela qual o desempenho do espaço de posto pequeno pode ser igual a a do espaço de grande classificação .Disse validade de "baixa classificação".
Vendo a conclusão deste gráfico, você pode ter uma dúvida: Não significa que as 8 dimensões com mais informações são tomadas, mas as 64 dimensões com mais informações são tomadas? Então suas primeiras 8 dimensões devem ser as mesmas! Assim, com o aumento de , a coincidência espacial não deveria estar ficando cada vez maior? Como o resultado do gráfico está ficando cada vez menor?
Isso ocorre porque o fenômeno de "pegar as 8 dimensões com mais informações e pegar as 64 dimensões com mais informações" é o nosso ideal, mas não é o caso quando o modelo é realmente aprendido. O modelo aprenderá com a dimensão mais informativa o máximo possível, mas não há garantia de quanto será necessário. O objetivo top r deve ser aprendido no final . Pode-se dizer apenas que quando r é relativamente pequeno, o é mais provável que o modelo esteja próximo do topo real r ; Quando r é relativamente grande, o modelo aprende algumas informações valiosas e algum ruído , e esse experimento apenas demonstra esse ponto.
Se entendermos isso, podemos interpretar melhor o próximo experimento: como definir o r de diferentes camadas do modelo?
5.2.3 configurações de valor r para diferentes camadas
Vimos anteriormente que LoRA atua sobre e , portanto, para essas duas matrizes diferentes, há alguma diferença na definição de valor?
Para responder a esse ponto, o autor projetou outro experimento: para três matrizes, defina duas sementes aleatórias diferentes para cada matriz, execute duas matrizes diferentes de posto baixo e calcule a distância de Grassmann dessas duas matrizes de posto baixo. O resultado é do seguinte modo:
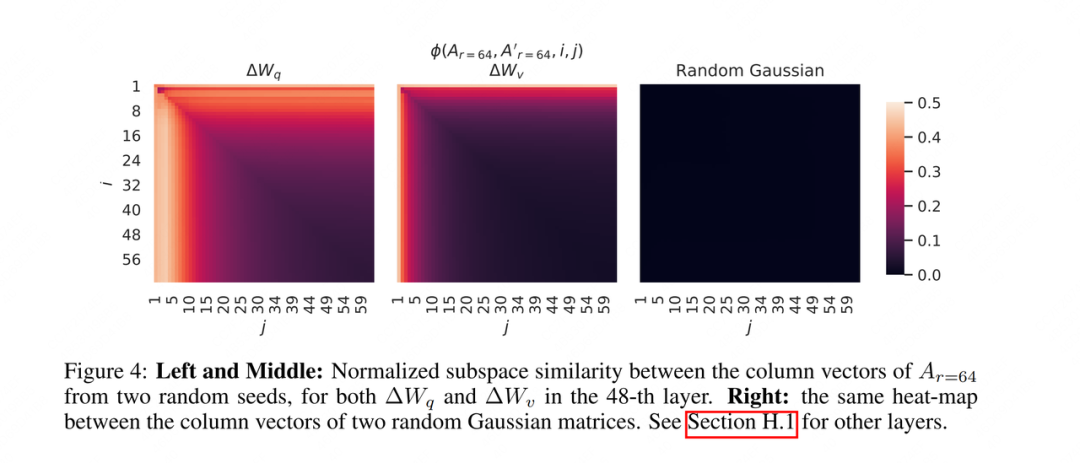
Como explicamos antes, os dois grupos não aprenderam perfeitamente as informações mais objetivas de 64 dimensões, mas "informações parcialmente válidas + algum ruído". Com base nisso, não é difícil imaginar que ambos os grupos possam aprender A informação é provável ser uma informação útil. Portanto, também calculamos a similaridade desses dois grupos.Na figura à esquerda, podemos ver que os 10 primeiros têm a cor mais clara e as informações contidas nela podem ser informações mais eficazes. Dependendo dos resultados dessa análise, também podemos usar diferentes classificações para diferentes partes do modelo.
5.2.4 Pesos pré-treino VS pesos de ajuste fino
Dissemos antes que pesos pré-treino são conhecimento antigo e pesos de ajuste fino são conhecimento novo. Portanto, normalmente, deve haver algumas partes que não receberam atenção. Portanto, também precisamos demonstrar se a matriz de posto baixo que treinamos atende a esse ponto. Os resultados experimentais projetados pelo autor são os seguintes:

Entre eles, significa que o resultado aproximado pela matriz de posto baixo após o treinamento não é a existência objetiva mencionada acima.
Vamos interpretar este experimento:
-
Primeiro, observe a linha inferior da tabela e calcule as normas para os pesos pré-treinamento e pesos incrementais, respectivamente. Podemos entender esse indicador como a quantidade total de informações contidas nele.
-
Em seguida, encontramos o índice.Aqui temos 6 conjuntos de valores: os 3 primeiros são do resultado da decomposição de valor singular da matriz de tempo, e os três últimos são deduzidos por analogia. Portanto, significa: projetar os pesos pré-treinamento nos espaços de recursos aproximados de baixo escalão dos três e calcular a quantidade de informações no espaço de recursos correspondente após a projeção. Se for mais semelhante ao espaço de recursos correspondente, o valor será maior.
Apenas olhar para o conceito não é um pouco confuso, vamos encontrar um indicador específico para interpretá-lo:
-
Primeiro olhe para o grupo de 61,95 e 21,67. 61,95 representa a quantidade de informação que o próprio peso pré-treinamento possui e 21,67 representa a quantidade de informação projetada em seu próprio espaço de classificação inferior (a projeção para o espaço de classificação inferior resultará inevitavelmente em perda de informações).
-
Vejamos o grupo de 0,32 e 0,02. 0,32 indica a quantidade de informação após o peso pré-treinamento ser projetado no espaço de classificação inferior do peso incremental e 0,02 é o mesmo. Pode-se observar que, em comparação com pesos aleatórios, os pesos incrementais contendo novos conhecimentos ainda apresentam certa correlação com os pesos pré-treinados.
-
Finalmente, vamos olhar para 6,91 e 0,32. Após os pesos pré-treinamento serem projetados no espaço de baixo escalão dos pesos incrementais, a quantidade de informação diminui de 61,95 para 0,32, indicando que ainda existe uma diferença significativa entre as distribuições dos pesos pré-treinamento (antigo conhecimento) e pesos incrementais (novos conhecimentos). 6,91 representa a quantidade de informação no próprio peso incremental. Portanto, o valor de 21,95 = 6,91/0,32 pode representar apenas o grau em que o peso incremental amplifica a informação não enfatizada no peso pré-treinamento. Quanto menor a classificação, mais óbvio é o grau de amplificação.
bom! Com relação à introdução do princípio do LoRA, aprenderemos aqui juntos. Você pode achar que este artigo gasta muito espaço na introdução do experimento. Por um lado, por meio do experimento, ele pode nos ajudar a entender melhor o significado e o papel do baixo escalão; por outro lado, eu pessoalmente acho que os resultados do experimento LoRA não são muito fáceis de ler. , então quero passar algum tempo investigando isso. Então, no próximo artigo, vamos interpretar a implementação do LoRA novamente!

Coma geléia sem cuspir pele de geléia
Visão de longo prazo, com foco na implementação de engenharia de IA (LLM/MLOps).
67 conteúdo original
Sem público
6. Referência
1、https://arxiv.org/pdf/2106.09685.pdf
2、https://github.com/microsoft/LoRA
3、https://medium.com/@Shrishml/lora-low-rank-adaptation-from -the-first-principle-7e1adec71541
4、https://blog.sciencenet.cn/blog-696950-699432.html
5、https://kexue.fm/archives/9590/comment-page-1