Diretório de artigos
Prefácio
O algoritmo de classificação é um dos algoritmos mais básicos em "Estruturas e Algoritmos de Dados".
Os algoritmos de classificação podem ser divididos em classificação interna e classificação externa. A classificação interna serve para classificar os registros de dados na memória, enquanto a classificação externa ocorre porque os dados classificados são muito grandes e não podem acomodar todos os registros classificados de uma vez. Durante o processo de classificação, os algoritmos externos a memória precisa ser acessada. Algoritmos de classificação comuns incluem: classificação por inserção, classificação Hill, classificação por seleção, classificação por bolha, classificação por mesclagem, classificação rápida, classificação por heap, classificação técnica, etc.
1. Resumo dos dez principais algoritmos de classificação comuns
A seguir estão a complexidade de tempo média e a complexidade de tempo de melhor caso de algoritmos de classificação comuns: classificação por bolha, classificação por seleção, classificação por inserção, classificação por colina, classificação por mesclagem, classificação rápida, classificação por heap, classificação por contagem, classificação por balde e classificação por raiz. , complexidade de tempo de pior caso, complexidade de espaço, método de classificação e resumo de estabilidade.
1. Explicação dos termos
- n: tamanho dos dados
- k: o número de "baldes"
- In-Place: Ocupa memória constante, não ocupa memória adicional
- Out-Place: ocupa memória extra
- Estabilidade: a ordem de 2 valores-chave iguais após a classificação é igual à ordem antes da classificação
Algoritmos de classificação estável incluem: classificação por bolha, classificação por inserção, classificação por mesclagem e classificação por raiz.
Algoritmos de classificação instáveis incluem: classificação por seleção, classificação rápida, classificação Hill e classificação heap.
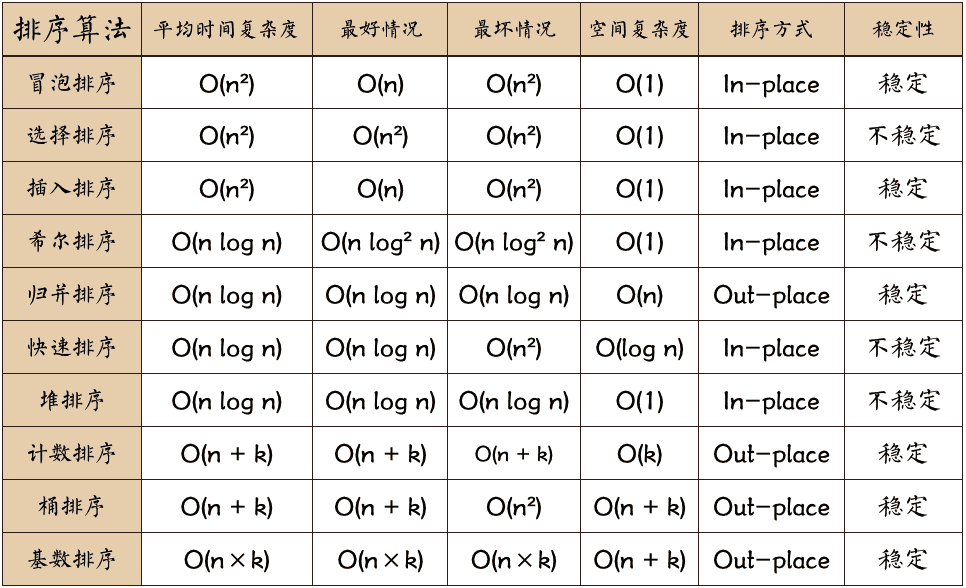
Clique na imagem abaixo para ampliá-la:
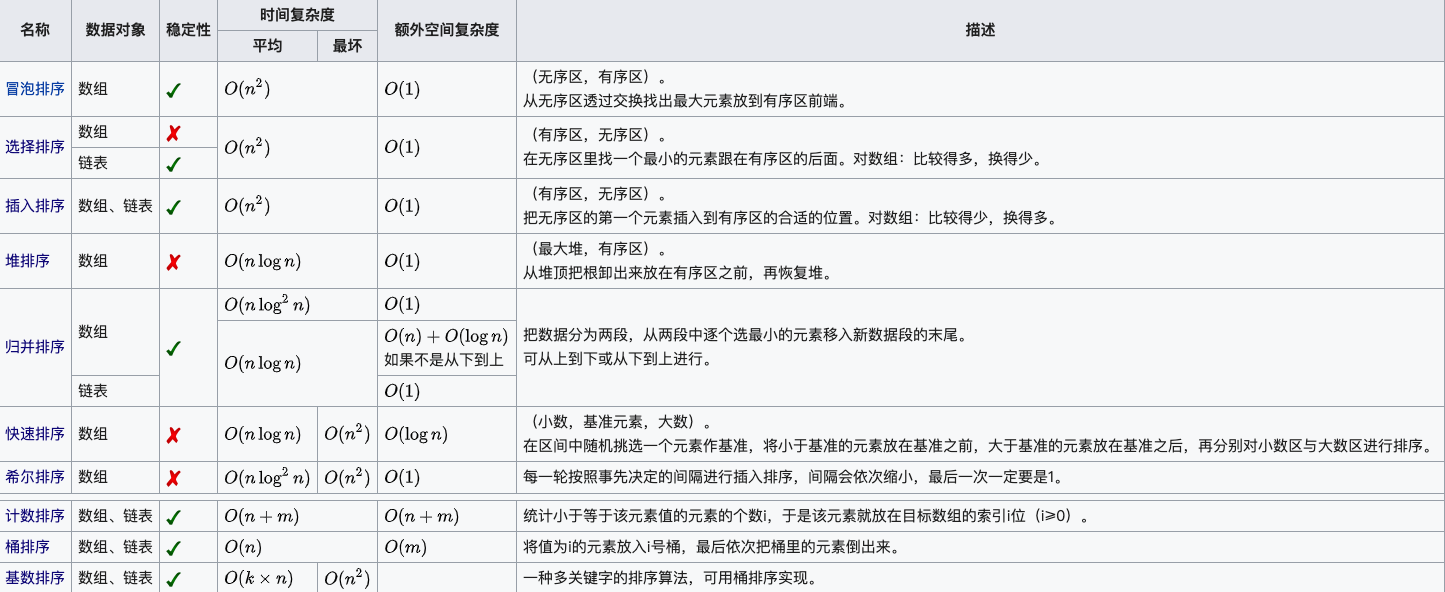
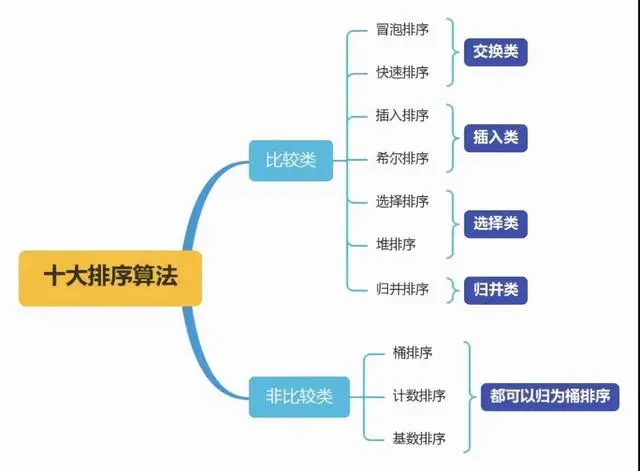
2. Complexidade de tempo
- Ordem quadrada O (n2): todos os tipos de classificação simples, inserção direta, seleção direta, classificação por bolha;
- Ordem logarítmica linear O (nlog2n): classificação rápida, classificação por mesclagem, classificação por heap;
- O(n1+ζ): ζ é uma constante entre 0 e 1, classificação Hill;
- Ordem linear O(n): classificação por cardinalidade, classificação por balde, classificação por caixa;
2. Algoritmo de classificação e implementação da linguagem C
1. Classificação por bolha
Bubble Sort é um algoritmo de classificação simples e intuitivo. Compare-se, o maior é sempre classificado em último lugar e, em seguida, continue a comparar com os números seguintes até que o maior número seja classificado em último lugar e, em seguida, continue a repetir o processo na sequência antes do último número até que todos os números sejam classificados. bom.
-
Etapas do algoritmo
Compare os elementos adjacentes, se o primeiro for maior que o segundo, troque e organize o maior atrás.
A mesma comparação é realizada para cada par de elementos adjacentes, e o último elemento será o maior número.
Faça o mesmo para todos os elementos até que o primeiro número seja o menor. -
Demonstração de animação

-
Quando é mais rápido
Quando os dados de entrada já estão em ordem. -
Quando é o mais lento
Quando os dados de entrada estão na ordem inversa, todas as etapas precisam ser movidas e trocadas. -
Linguagem C para implementar classificação por bolha
#include <stdio.h>
void bubble_sort(int arr[], int len) {
int i, j, temp;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
int main() {
int arr[] = {
22, 34, 3, 32, 82, 55, 89, 50, 37, 5, 64, 35, 9, 70 };
int len = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
return 0;
}
2. Selecione a classificação
A classificação por seleção é um algoritmo de classificação simples e intuitivo; não importa quais dados entrem, ele tem uma complexidade de tempo de O (n2). Portanto, quando for usado, quanto menor o tamanho dos dados, melhor.
- Etapas do algoritmo
Primeiro, encontre o menor (maior) elemento na sequência não classificada e armazene-o na posição inicial da sequência classificada.
Em seguida, continue a encontrar o menor (maior) elemento entre os elementos não classificados restantes e coloque-o no final da sequência classificada.
Repita a etapa dois até que todos os elementos estejam classificados.
-
Demonstração de animação

-
Implementação em linguagem C de classificação por seleção
void swap(int *a,int *b) //交換兩個變數
{
int temp = *a;
*a = *b;
*b = temp;
}
void selection_sort(int arr[], int len)
{
int i,j;
for (i = 0 ; i < len - 1 ; i++)
{
int min = i;
for (j = i + 1; j < len; j++) //走訪未排序的元素
if (arr[j] < arr[min]) //找到目前最小值
min = j; //紀錄最小值
swap(&arr[min], &arr[i]); //做交換
}
}
3. Classificação por inserção
Embora a implementação do código da classificação por inserção não seja tão simples e grosseira quanto a classificação por bolha e a classificação por seleção, seu princípio deve ser o mais fácil de entender, porque qualquer pessoa que tenha jogado pôquer deve ser capaz de entendê-lo em segundos. A classificação por inserção é o algoritmo de classificação mais simples e intuitivo. Seu princípio de funcionamento é construir uma sequência ordenada, em relação aos dados não classificados, varrer de trás para frente na sequência classificada, encontrar a posição correspondente e inseri-la.
- Etapas do algoritmo
Trate o primeiro elemento da sequência a ser classificada como uma sequência ordenada e o segundo elemento até o último elemento como uma sequência não classificada.
Verifica uma sequência não classificada do início ao fim, inserindo cada elemento encontrado na sequência em sua posição adequada. (Se o elemento a ser inserido for igual a um elemento da sequência ordenada, o elemento a ser inserido será inserido após o elemento igual)
- Demonstração de animação

- Implementação da linguagem C
void insertion_sort(int arr[], int len){
int i,j,key;
for (i=1;i<len;i++){
key = arr[i];
j=i-1;
while((j>=0) && (arr[j]>key)) {
arr[j+1] = arr[j];
j--;
}
arr[j+1] = key;
}
}
4. Classificação de colina
A classificação Hill, também conhecida como algoritmo de classificação incremental descendente, é uma versão mais eficiente e aprimorada da classificação por inserção. Mas a classificação de Hill é um algoritmo de classificação instável.
A classificação por colina é um método aprimorado baseado nas duas propriedades a seguir da classificação por inserção:
- A ordenação por inserção é altamente eficiente quando opera em dados quase organizados, ou seja, pode atingir a eficiência da ordenação linear;
- Mas a classificação por inserção geralmente é ineficiente porque a classificação por inserção só pode mover dados um bit por vez;
A ideia básica da classificação de Hill é: primeiro divida toda a sequência de registros a serem classificados em várias sequências para classificação por inserção direta (troca de acordo com o tamanho do passo).Quando os registros em toda a sequência estão "basicamente em ordem", então todos os registros executam a classificação por inserção direta.
- Etapas do algoritmo
Pegue a sequência: {8, 9, 1, 7, 2, 3, 5, 6, 4, 0} como exemplo!
1. O intervalo de tamanho do passo inicial = comprimento/2 = 5, o que significa que toda a matriz é dividida em 5 grupos, nomeadamente [8, 3], [9, 5], [1, 6], [7, 4] , [2, 0], insira e classifique cada grupo para obter a sequência: {3, 5, 1, 4, 0, 8, 9, 6, 7, 2}, você pode ver: 3, 5, 4, 0 todos esses pequenos elementos foram mencionados antes.
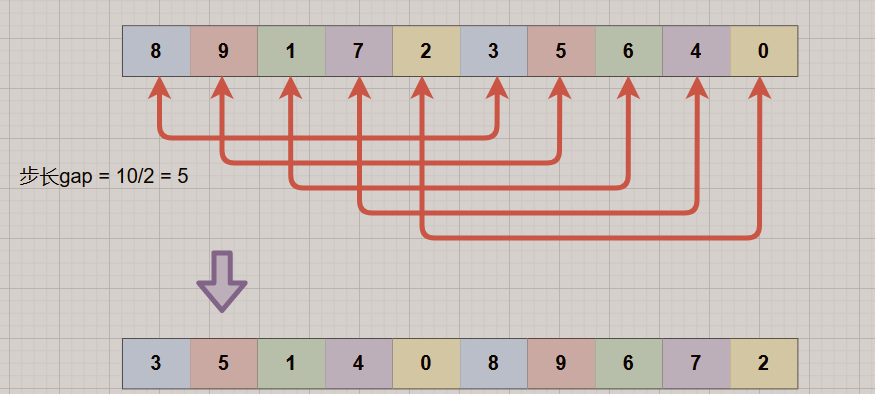
2. Reduza a lacuna de incremento = 5/2 = 2. A matriz é dividida em dois grupos, nomeadamente [3, 1, 0, 9, 7], [5, 4, 8, 6, 2]. Para esses dois grupos respectivamente Executando a classificação por inserção direta, você pode ver que todo o array está ainda mais ordenado.
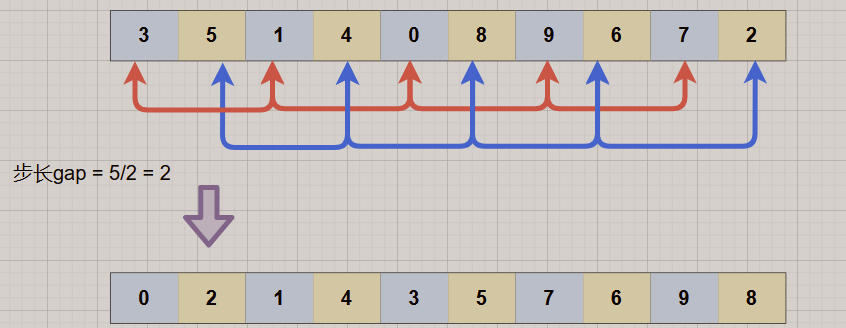
3. Reduza o incremento novamente, gap = 2/2 = 1. Neste momento, a matriz inteira é [0, 2, 1, 4, 3, 5, 7, 6, 9, 8]. Execute uma classificação por inserção para classificação de matrizes (requer apenas ajustes simples e não operações de movimentação extensas).

- implementação da linguagem java
import java.util.Arrays;
/**
* @author 兴趣使然黄小黄
* @version 1.0
* 希尔排序
*/
public class ShellSort {
public static void main(String[] args) {
int[] arr = {
8, 9, 1, 7, 2, 3, 5, 6, 4, 0};
System.out.println("排序前: " + Arrays.toString(arr));
shellSort(arr);
System.out.println("排序后: " + Arrays.toString(arr));
}
//希尔排序
public static void shellSort(int[] arr){
//设定步长
for (int gap = arr.length / 2; gap > 0; gap /= 2){
//将数据分为arr.length/gap组,逐个对其所在的组进行插入排序
for (int i = gap; i < arr.length; i++) {
//遍历各组中的所有元素,步长为gap
int j = i;
int temp = arr[j]; //记录待插入的值
while (j - gap >= 0 && temp < arr[j-gap]){
//移动
arr[j] = arr[j-gap];
j -= gap;
}
//找到位置,进行插入
arr[j] = temp;
}
System.out.println(Arrays.toString(arr));
}
}
}
5. Mesclar classificação
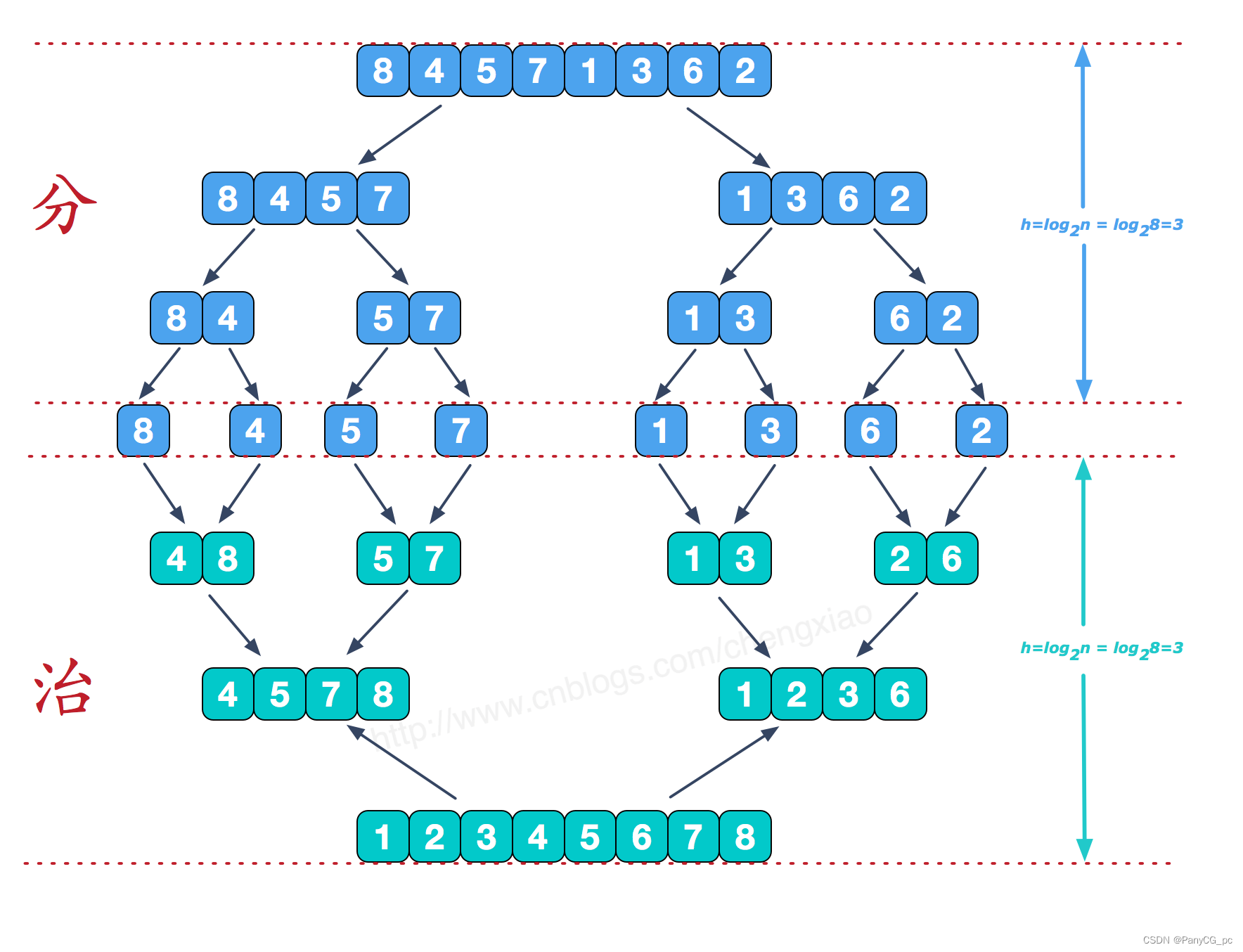
Merge Sort é um algoritmo de classificação eficaz e estável baseado em operações de mesclagem.Este algoritmo é uma aplicação muito típica do método de divisão e conquista. Mesclar as subsequências já ordenadas para obter uma sequência completamente ordenada; isto é, primeiro torne cada subsequência ordenada e depois ordene os segmentos da subsequência.
-
Etapa do algoritmo
Etapa 1 - Determinar o ponto de divisão intermediário (três métodos comumente usados): q[l], q[(l+r)/2], q[r], ou determinar aleatoriamente; Etapa 2 - Ajustar a coluna a ser classificada
Formulário duas subsequências de esquerda e direita, classifique recursivamente esquerda e direita;
Etapa 3 - mesclar (combinar dois em um), Concluir! -
Demonstração

-
Implementação C
int min(int x, int y) {
return x < y ? x : y;
}
void merge_sort(int arr[], int len) {
int *a = arr;
int *b = (int *) malloc(len * sizeof(int));
int seg, start;
for (seg = 1; seg < len; seg += seg) {
for (start = 0; start < len; start += seg * 2) {
int low = start, mid = min(start + seg, len), high = min(start + seg * 2, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int *temp = a;
a = b;
b = temp;
}
if (a != arr) {
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}
6. Classificação rápida
Quick Sort é uma melhoria na classificação por bolha. Proposta por CAR Hoare em 1962, a ideia básica é selecionar um registro como pivô, e após um processo de ordenação, dividir toda a sequência em duas partes, sendo que uma parte possui valores menores que o pivô, e a outra parte tem valores maiores que o pivô. Em seguida, continue a classificar essas duas partes para que toda a sequência fique em ordem.
- Etapas do algoritmo
- 1. Ideia básica:
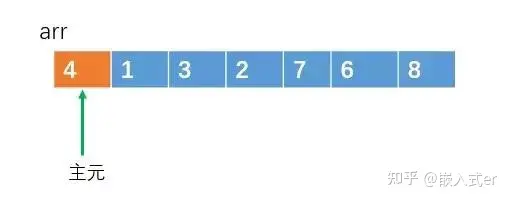
por exemplo, para que um array de origem seja classificado como arr = {4, 1, 3, 2, 7, 6, 8}.

Podemos selecionar um elemento à vontade. Se selecionarmos o primeiro elemento do array, vamos chamar esse elemento de "pivô".
Em seguida, coloque os elementos que são maiores ou iguais ao pivô à direita e coloque os elementos que são menores ou iguais ao pivô à esquerda.
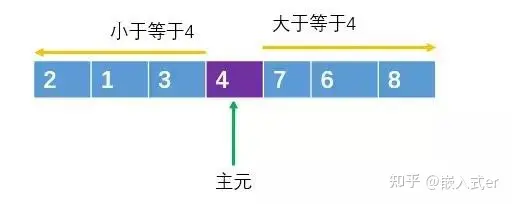
Depois de ajustar esta regra, os elementos à esquerda são todos menores ou iguais ao pivô, e os elementos à direita são maiores ou iguais ao pivô. Obviamente, a posição do pivô neste momento é uma posição ordenada, isto é, o pivô já está na posição classificada.
O pivô divide a matriz em duas metades. A operação de dividir uma matriz grande em duas partes pequenas por meio do pivô também é chamada de operação de partição.
A seguir, usamos o mesmo método para as partes esquerda e direita por meio de recursão, selecionando um elemento principal de cada vez para colocá-lo em uma posição ordenada. Obviamente, a recursão termina quando o subarray possui apenas um elemento ou 0 elementos.

Código: quick_sort é um algoritmo de classificação rápida e a função de partição é uma operação de divisão para uma matriz.Existem muitos métodos para operações de divisão.
Existem muitos métodos para operação de divisão de classificação rápida, o mais básico está listado aqui.
-
Demonstração de animação

-
Implementação em linguagem C de classificação por seleção
void QuickSort(int array[], int low, int high) {
int i = low;
int j = high;
if(i >= j) {
return;
}
int temp = array[low];
while(i != j) {
while(array[j] >= temp && i < j) {
j--;
}
while(array[i] <= temp && i < j) {
i++;
}
if(i < j) {
swap(array[i], array[j]);
}
}
//将基准temp放于自己的位置,(第i个位置)
swap(array[low], array[i]);
QuickSort(array, low, i - 1);
QuickSort(array, i + 1, high);
}
7. Classificação de pilha
Heapsort refere-se a um algoritmo de classificação projetado usando uma estrutura de dados como um heap.Ele empilha uma estrutura que é aproximadamente uma árvore binária completa e satisfaz as propriedades de empilhamento: o valor-chave ou índice de um nó filho é sempre menor que (ou maior do que) o nó pai de it.
É dividido em dois métodos:
big top heap: o nó pai é maior ou igual ao nó filho, que pertence ao algoritmo de ordem crescente;
small top heap: o nó pai é menor ou igual ao nó filho, que pertence ao algoritmo de ordem decrescente;
a complexidade média de tempo da classificação de heap é O (nlogn)
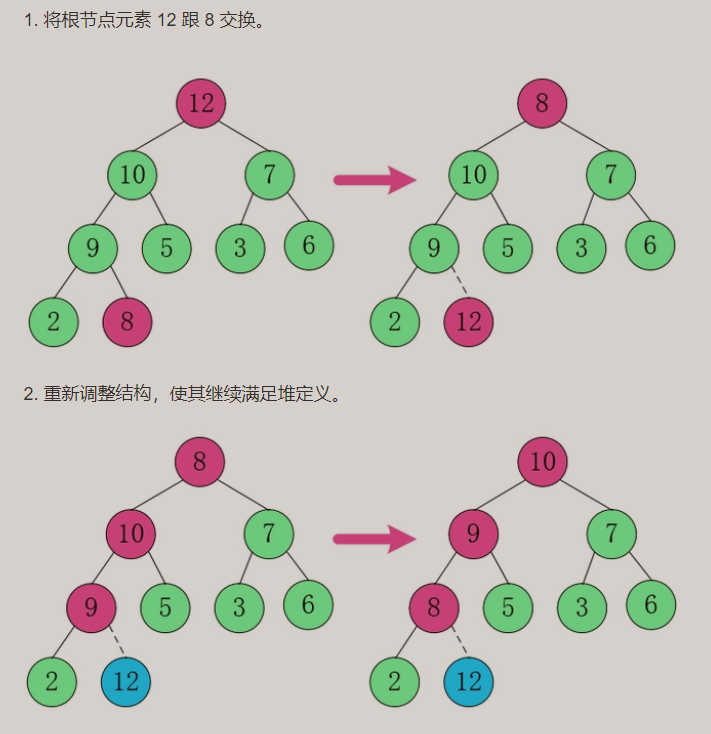
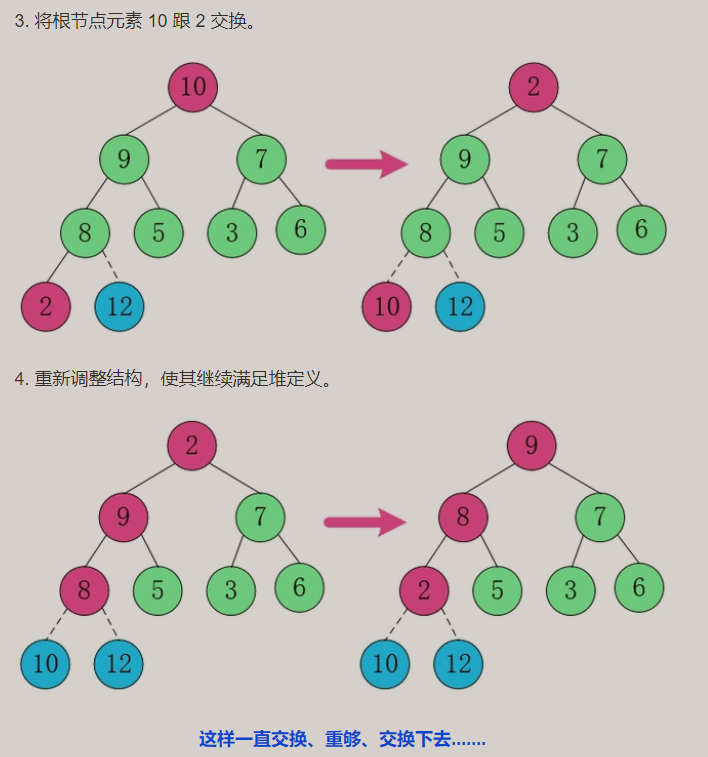
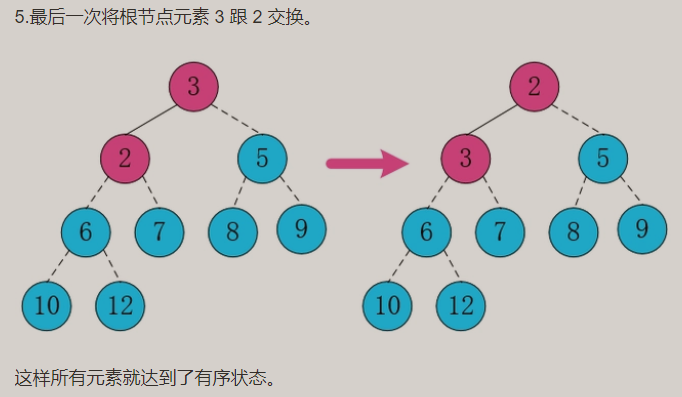
O heap é geralmente usado para encontrar os N maiores ou os N menores dados em uma grande quantidade de dados.
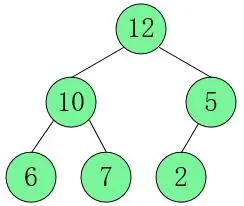
Pilha superior grande: ordem decrescente (Desc) 12 do grande para o pequeno...
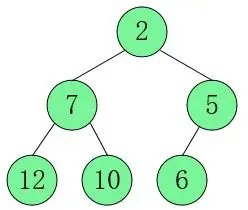
Pilha superior pequena: ordem crescente (Asc) 2 do pequeno para o grande...
- Etapas do algoritmo
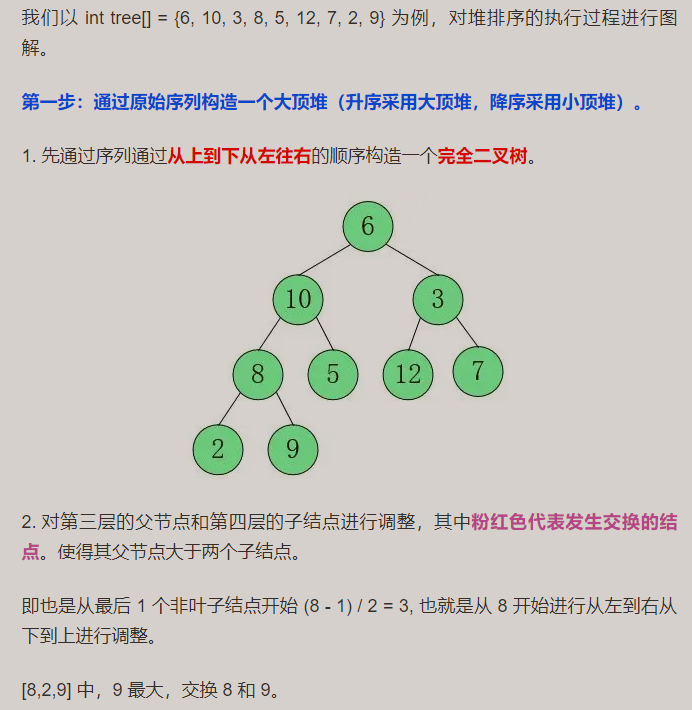
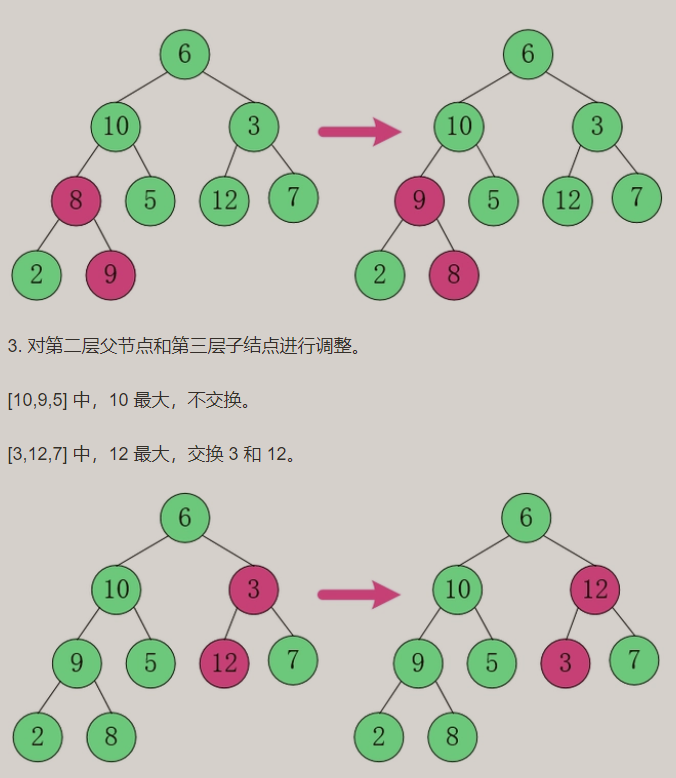
para construir um grande heap superior:
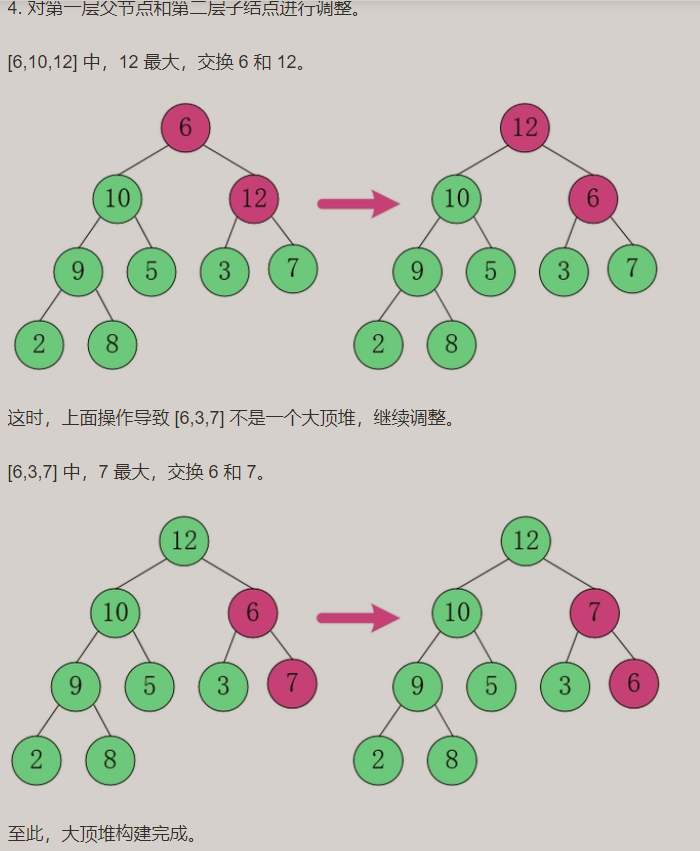
Construa uma pequena pilha superior:
- Demonstração de animação


- A linguagem C implementa a classificação por seleção
. Código grande:
#include <stdio.h>
void swap(int arr[], int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void heapify(int tree[], int n, int i){
if (i >= n){
return;
}
int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
int max = i;
if (c1 < n && tree[c1] > tree[max]){
max = c1;
}
if (c2 < n && tree[c2] > tree[max]){
max = c2;
}
if (max != i){
swap(tree, max ,i);
heapify(tree, n, max);
}
}
void build_heap(int tree[], int n){
int last_node = n - 1;
int parent = (last_node - 1) / 2;
for (int i = parent; i >= 0; i--){
heapify(tree, n, i);
}
}
void heap_sort(int tree[], int n){
build_heap(tree, n);
for (int i = n - 1; i >= 0; i--){
swap(tree, i, 0);
heapify(tree, i, 0);
}
}
int main(){
int tree[] = {
6, 10, 3, 9, 5, 12, 7, 2, 8};
int n = 9;
build_heap(tree, 9);
// heap_sort(tree, 9);
for(int i = 0; i < n; i++){
printf("%d\n",tree[i]);
}
return 0;
}
Resultados de heap superior grande: De grande a pequeno, os resultados estão em ordem decrescente (Desc)
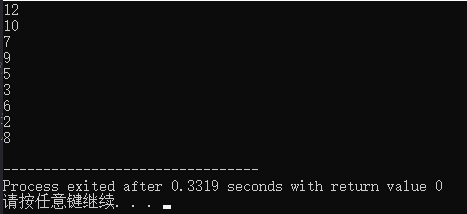
.Código de heap superior pequeno:
#include <stdio.h>
void swap(int arr[], int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void heapify(int tree[], int n, int i){
if (i >= n){
return;
}
int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
int max = i;
if (c1 < n && tree[c1] > tree[max]){
max = c1;
}
if (c2 < n && tree[c2] > tree[max]){
max = c2;
}
if (max != i){
swap(tree, max ,i);
heapify(tree, n, max);
}
}
void build_heap(int tree[], int n){
int last_node = n - 1;
int parent = (last_node - 1) / 2;
for (int i = parent; i >= 0; i--){
heapify(tree, n, i);
}
}
void heap_sort(int tree[], int n){
build_heap(tree, n);
for (int i = n - 1; i >= 0; i--){
swap(tree, i, 0);
heapify(tree, i, 0);
}
}
int main(){
int tree[] = {
6, 10, 3, 9, 5, 12, 7, 2, 8};
int n = 9;
// build_heap(tree, 9);
heap_sort(tree, 9);
for(int i = 0; i < n; i++){
printf("%d\n",tree[i]);
}
return 0;
}
Resultado do heap superior pequeno: ordem crescente de pequeno para grande (Asc)
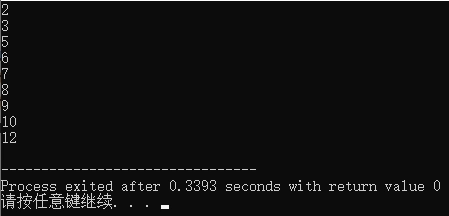
8. Contagem e classificação
O núcleo da classificação por contagem é converter o valor dos dados de entrada em uma chave e armazená-lo no espaço adicional da matriz. Como uma classificação linear por complexidade de tempo, a classificação por contagem exige que os dados de entrada sejam inteiros dentro de um determinado intervalo.
- Características da ordenação por contagem
Quando os elementos de entrada são n inteiros entre 0 e k, seu tempo de execução é Θ(n + k). A classificação por contagem não é uma classificação por comparação e a classificação é mais rápida do que qualquer algoritmo de classificação por comparação.
Como o comprimento do array C usado para contagem depende do intervalo de dados no array a ser classificado (igual à diferença entre o valor máximo e o valor mínimo do array a ser classificado mais 1), isso torna a classificação da contagem requerem uma grande quantidade de dados para matrizes com um grande intervalo de dados, tempo e memória. Por exemplo: a classificação por contagem é o melhor algoritmo para classificar números entre 0 e 100, mas não é adequado para classificar nomes em ordem alfabética. No entanto, a classificação por contagem pode ser usada para classificar matrizes com grandes intervalos de dados usando o algoritmo usado na classificação radix.
Para entender em termos leigos, por exemplo, existem 10 pessoas de idades diferentes, e as estatísticas mostram que 8 pessoas são mais jovens que A, então a idade de A é classificada em 9. Usando este método, a posição de cada uma das outras pessoas pode ser obtido e a classificação é concluída. É claro que é necessário um tratamento especial quando as idades são repetidas (para garantir a estabilidade), razão pela qual a matriz alvo é preenchida no final e as estatísticas de cada número são subtraídas por 1.
-
Etapas do algoritmo
(1) Encontre os maiores e menores elementos no array a ser classificado
(2) Conte o número de ocorrências de cada elemento com valor i no array e armazene-o no i-ésimo item do array C
(3) Acumule todas as contagens (começando do primeiro elemento em C, cada item é adicionado ao item anterior)
(4) Preencha a matriz de destino ao contrário: coloque cada elemento i no C(i)-ésimo item da nova matriz e coloque cada elemento i O elemento subtrairá 1 de C(i) -
Demonstração de animação

-
Implementação em linguagem C de classificação por seleção
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void print_arr(int *arr, int n) {
int i;
printf("%d", arr[0]);
for (i = 1; i < n; i++)
printf(" %d", arr[i]);
printf("\n");
}
void counting_sort(int *ini_arr, int *sorted_arr, int n) {
int *count_arr = (int *) malloc(sizeof(int) * 100);
int i, j, k;
for (k = 0; k < 100; k++)
count_arr[k] = 0;
for (i = 0; i < n; i++)
count_arr[ini_arr[i]]++;
for (k = 1; k < 100; k++)
count_arr[k] += count_arr[k - 1];
for (j = n; j > 0; j--)
sorted_arr[--count_arr[ini_arr[j - 1]]] = ini_arr[j - 1];
free(count_arr);
}
int main(int argc, char **argv) {
int n = 10;
int i;
int *arr = (int *) malloc(sizeof(int) * n);
int *sorted_arr = (int *) malloc(sizeof(int) * n);
srand(time(0));
for (i = 0; i < n; i++)
arr[i] = rand() % 100;
printf("ini_array: ");
print_arr(arr, n);
counting_sort(arr, sorted_arr, n);
printf("sorted_array: ");
print_arr(sorted_arr, n);
free(arr);
free(sorted_arr);
return 0;
}
9. Classificação de balde

- Linguagem C++ para implementar classificação por seleção
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){
}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}
10. Classificação de raiz

- Demonstração de animação LSD radix sort

- Implementação em linguagem C de classificação por seleção
#include<stdio.h>
#define MAX 20
//#define SHOWPASS
#define BASE 10
void print(int *a, int n) {
int i;
for (i = 0; i < n; i++) {
printf("%d\t", a[i]);
}
}
void radixsort(int *a, int n) {
int i, b[MAX], m = a[0], exp = 1;
for (i = 1; i < n; i++) {
if (a[i] > m) {
m = a[i];
}
}
while (m / exp > 0) {
int bucket[BASE] = {
0 };
for (i = 0; i < n; i++) {
bucket[(a[i] / exp) % BASE]++;
}
for (i = 1; i < BASE; i++) {
bucket[i] += bucket[i - 1];
}
for (i = n - 1; i >= 0; i--) {
b[--bucket[(a[i] / exp) % BASE]] = a[i];
}
for (i = 0; i < n; i++) {
a[i] = b[i];
}
exp *= BASE;
#ifdef SHOWPASS
printf("\nPASS : ");
print(a, n);
#endif
}
}
int main() {
int arr[MAX];
int i, n;
printf("Enter total elements (n <= %d) : ", MAX);
scanf("%d", &n);
n = n < MAX ? n : MAX;
printf("Enter %d Elements : ", n);
for (i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
printf("\nARRAY : ");
print(&arr[0], n);
radixsort(&arr[0], n);
printf("\nSORTED : ");
print(&arr[0], n);
printf("\n");
return 0;
}