1. Classificação por inserção direta
1. Princípio da
classificação por inserção direta. Toda a matriz é dividida em dois intervalos, ou seja, o intervalo não ordenado e o intervalo ordenado
. Cada vez que você selecionar o primeiro elemento do intervalo não ordenado, selecione a posição apropriada para inserir no intervalo ordenado . Não há muito a dizer, vamos ver sua implementação de código abaixo:
2. A implementação de código 
analisará o desempenho dessa classificação. A pior complexidade de tempo é o (N), a melhor complexidade de tempo é o (N ^ 2), então a complexidade média O grau é o (N ^ 2). Sua complexidade de espaço é 0 (1) e não precisa abrir espaço adicional. Pode-se ver que esta ordenação não inverte a posição relativa do mesmo número, ao ordenar escolhemos maior ou igual à direita do número. Portanto, é um tipo estável. Se um grupo de números estiver basicamente em ordem, o algoritmo de ordenação por inserção será mais eficiente.
II. Classificação de Hill
1. A classificação de Hill Principle
é baseada na classificação de inserção. Ela divide a matriz inteira em grupos de lacunas, classifica cada grupo e, em seguida, sintetiza uma matriz após a classificação e continua a se dividir em grupos de lacunas / 2 Grupo, repita as etapas acima até gap = 1; em seguida, insira a matriz inteira para obter a matriz ordenada final.
2. Implementação do código 

Vamos analisar o desempenho dessa classificação. Ela é otimizada com base na classificação por inserção, então sua complexidade de tempo é menor do que a classificação por inserção. A pior complexidade de tempo é o (N ^ 2), o melhor É o (N), a complexidade média é o (N ^ 1,3), e a complexidade do espaço é o (1), o que não é uma classificação estável, pois a posição relativa do mesmo número não pode ser garantida durante o processo de agrupamento.
3. Seleção e Classificação
1. Princípio
Cada vez, o maior elemento é selecionado do intervalo não ordenado e armazenado no final do intervalo não ordenado até que todos os dados a serem ordenados sejam organizados.
2. Implementação do código 
A seguinte análise de desempenho de classificação, pior complexidade de tempo o (N ^ 2), melhor complexidade de tempo o (N), complexidade de tempo média o (N ^ 2), complexidade de espaço o (1), É um tipo instável.
Quatro, tipo de pilha
1. A
classificação do heap de princípio também é baseada na classificação de seleção, exceto que seleciona o maior elemento construindo um grande heap, troca o elemento superior do heap pelo último elemento do heap e, em seguida, o coloca em outra matriz e, em seguida, Ajuste a pilha para baixo.
2. Implementação do código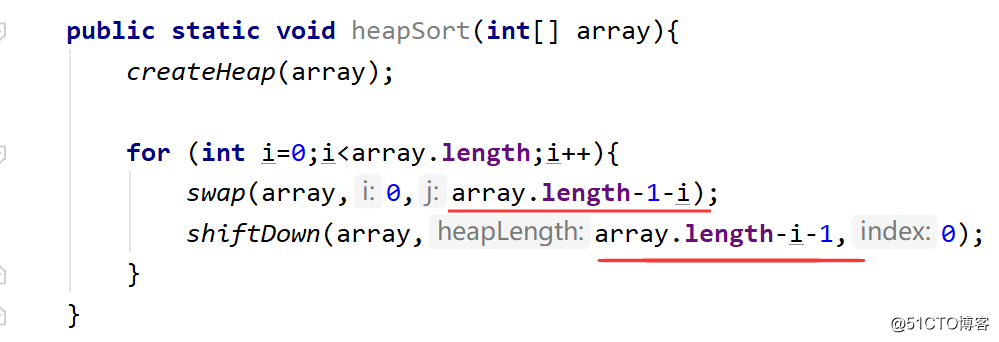
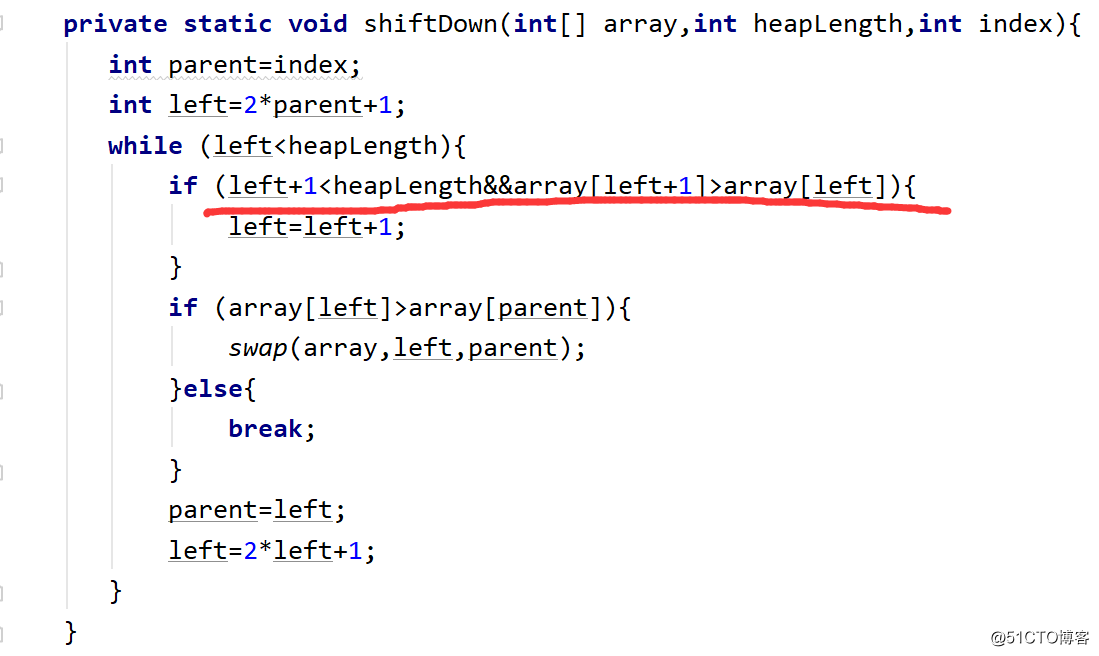

Vejamos o desempenho do algoritmo abaixo: A complexidade do tempo é o (N * logN), a complexidade do espaço é o (1) e a classificação do heap ainda é instável.
5. Classificação por bolha
1. Princípio A
classificação por bolha também divide a matriz em dois intervalos, o intervalo não ordenado [0, array.length-i-1] e o intervalo ordenado [array.length-i-1, array.length] , Retire um número do intervalo não ordenado em ordem a cada vez, compare-o com os seguintes números um por um e coloque os números grandes atrás até que todos os números sejam percorridos. O número de bolhas é array.length e o número de comparações é array.length-i-1.
2. Implementação do código 
Vejamos o desempenho do algoritmo. A pior complexidade de tempo é o (N ^ 2), a melhor complexidade de tempo é o (N), a complexidade de tempo média é o (N ^ 2) e a complexidade do espaço é o (1). A classificação por bolha é uma classificação estável. Porque no processo de comparação, o número maior do que é colocado para trás.
6. Classificação rápida
1. Princípio
Escolha um valor do intervalo a ser classificado como o valor de referência, percorra todo o intervalo a ser classificado e coloque o valor menor do que o valor de referência no lado esquerdo dele e o valor menor do que no lado direito e nas células esquerda e direita Processe da mesma maneira até que o comprimento da célula seja 1 ou 0, o que significa que todas as células foram classificadas.
2. 

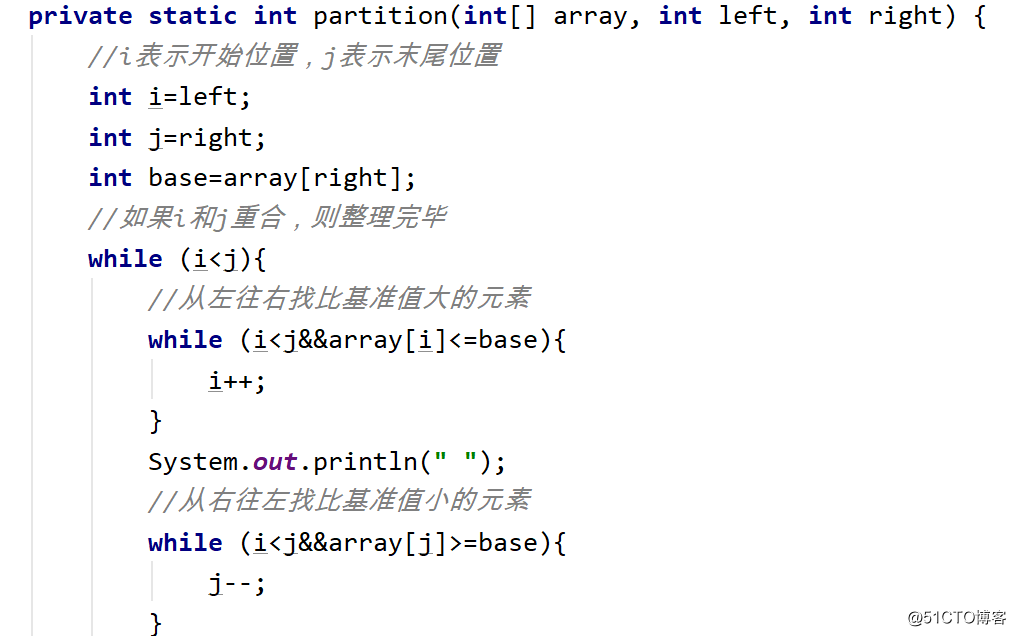

A pior complexidade de tempo do código para implementá- lo é 0 (N ^ 2), a melhor complexidade de tempo é o (N logN), a complexidade de tempo média é o (N logN) e a complexidade do espaço é o (N logN). Instável, pode-se ver que é muito mais eficiente do que os tipos anteriores.
7. Mesclar e classificar
1. Princípio:
O método dividir e conquistar é usado para mesclar as subsequências que foram ordenadas, primeiro faça cada subsequência em ordem, depois faça cada sequência em ordem e, finalmente, mescle em um array ordenado.
2. 


A complexidade de tempo do código para implementar o algoritmo de classificação é o (N logN), a complexidade do espaço é o (N) e a classificação é estável.