1. Notação O grande
Grande notação O:
- O uso de medidas aproximadas em computadores para descrever a eficiência dos algoritmos de computador é conhecido como notação "big O"
- Quando o número de itens de dados muda, a eficiência do algoritmo também muda. Portanto, não faz sentido dizer que o Algoritmo A é duas vezes mais rápido que o Algoritmo B.
- Portanto, geralmente usamos como a velocidade do algoritmo mudará com a alteração da quantidade de dados para expressar a eficiência do algoritmo, e a grande notação O é uma das maneiras.
Notação O grande comum

Complexidade de tempo de diferentes formas grandes de O:

Pode-se ver que a eficiência de grande para pequeno é: O(1) > O(logn) > O(n) > O(nlog(n)) > O(n²) > O(2n)
Três regras para derivar a notação Big O:
- Regra 1 : Substitua todas as constantes aditivas em tempo de execução pela constante 1. Por exemplo, 7 + 8 = 15, 1 é usado para representar o resultado da operação 15 e a grande notação O é expressa como O(1);
- Regra 2 : Apenas o termo de maior ordem é mantido na operação. Tal como N^3 + 3n +1, a grande notação O é expressa como: O(N3);
- Regra 3 : Se a constante do termo de ordem mais alta não for 1, ela pode ser omitida. Tal como 4N2, a grande notação O é expressa como: O(N2);
2. Algoritmo de classificação
Aqui estão várias classificações simples e avançadas:
- Classificação simples: classificação por bolha, classificação por seleção, classificação por inserção;
- Classificação avançada: classificação de colina, classificação rápida;
Crie uma classe de lista ArrayList aqui e adicione algumas propriedades e métodos para armazenar esses métodos de classificação:
//创建列表类
function ArrayList() {
//属性
this.array = []
//方法
//封装将数据插入到数组中方法
ArrayList.prototype.insert = function(item){
this.array.push(item)
}
//toString方法
ArrayList.prototype.toString = function(){
return this.array.join('-')
}
//交换两个位置的数据
ArrayList.prototype.swap = function(m, n){
let temp = this.array[m]
this.array[m] = this.array[n]
this.array[n] = temp
}
1. Classificação de bolhas
Ideia de classificação de bolhas:
- Para cada elemento não classificado, compare a relação de tamanho dos dois elementos adjacentes do começo ao fim ;
- Se o elemento à esquerda for maior , as posições serão trocadas . Por exemplo, 1 é menor que 2, não troque de posição;
- Mova um bit para a direita , continue comparando 2 e 3 e, finalmente, compare os dois dados de comprimento - 1 e comprimento - 2;
- Ao chegar à extrema direita , a pessoa mais alta deve ser colocada à extrema direita ;
- De acordo com essa ideia, ao reiniciar da extremidade esquerda, basta ir até a penúltima posição ;
Ideias de implementação:
Duas voltas:
-
O loop externo controla o número de vezes de borbulhamento:
- A primeira vez: j = comprimento - 1, em comparação com a primeira última posição;
- A segunda vez: j = comprimento - 2, em comparação com a penúltima posição;
-
O loop interno controla o número de comparações por passagem:
- A primeira comparação: i = 0, compara dois dados nas posições 0 e 1;
- A última comparação: i = comprimento - 2, comparar comprimento - 2 e comprimento - 1 dois dados;
O processo detalhado é mostrado na figura abaixo:
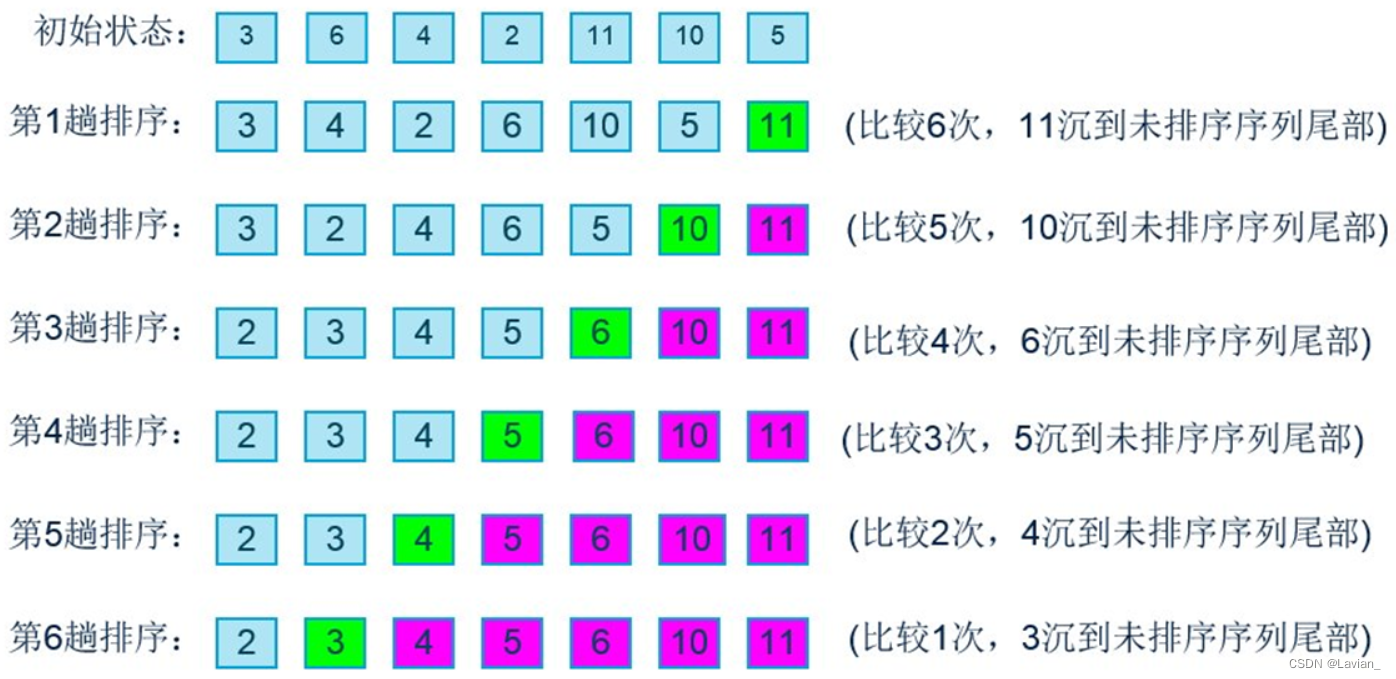
Código:
//冒泡排序
ArrayList.prototype.bubblesor = function(){
//1.获取数组的长度
let length = this.array.length
//外层循环控制冒泡趟数
for(let j = length - 1; j >= 0; j--){
//内层循环控制每趟比较的次数
for(let i = 0; i < j; i++){
if (this.array[i] > this.array[i+1]) {
//交换两个数据
let temp = this.array[i]
this.array[i] = this.array[i+1]
this.array[i+1] = temp
}
}
}
}
Eficiência do tipo de bolha:
- Para os 7 itens de dados mencionados acima, o número de comparações é: 6 + 5 + 4 + 3 + 2 + 1;
- Para N itens de dados, o número de comparações é: (N - 1) + (N - 2) + (N - 3) + ... + 1 = N * (N - 1) / 2; se duas comparações forem trocadas uma vez , então o número de trocas é: N * (N - 1) / 4;
- Use a notação O grande para representar o número de comparações e o número de trocas respectivamente: O( N * (N - 1) / 2) e O( N * (N - 1) / 4), de acordo com as três regras de a grande notação O Abreviação de: O(N^2) ;
2. Classificação de seleção
A classificação por seleção melhora a classificação por bolhas:
- Reduzir o número de trocas de O(N^2) para O(N) ;
- Mas o número de comparações ainda é O(N^2) ;
A ideia de classificação por seleção:
- Selecione a posição do primeiro índice, como 1, e compare-o com os seguintes elementos sucessivamente ;
- Se o elemento seguinte for menor que o elemento no índice 1, troque a posição para o índice 1;
- Após uma rodada de comparação, pode-se determinar que o elemento no índice 1 especificado no início é o menor ;
- Em seguida, use o mesmo método para comparar os elementos restantes, um por um, exceto o índice 1 ;
- Pode-se observar que na ordenação por seleção, o valor mínimo será selecionado na primeira rodada , e o segundo menor valor será selecionado na segunda rodada até que a ordenação seja concluída.
Ideias de implementação:
Duas voltas:
-
O loop externo controla o índice especificado:
- A primeira vez: j = 0, especificando o primeiro elemento;
- Última vez: j = comprimento - 1, especifique o último elemento;
-
O loop interno é responsável por comparar o elemento no índice especificado (i) com o elemento restante (i - 1);
//选择排序
ArrayList.prototype.selectionSort = function(){
//1.获取数组的长度
let length = this.array.length
//2.外层循环:从0开始获取元素
for(let j = 0; j < length - 1; j++){
let min = j
//内层循环:从i+1位置开始,和后面的元素进行比较
for(let i = min + 1; i < length; i++){
if (this.array[min] > this.array[i]) {
min = i
}
}
this.swap(min, j)
}
}
Eficiência da ordenação por seleção:
- O número de comparações para classificação por seleção é: N * (N - 1) / 2, expresso em notação O grande como: O(N^2) ;
- O número de trocas para ordenação por seleção é: (N - 1) / 2, expresso em notação O grande como: O(N) ;
- Portanto, a eficiência da ordenação por seleção é maior do que a ordenação por bolhas;
3. Classificação por inserção
A classificação por inserção é a classificação mais eficiente na classificação simples .
A ideia de classificação por inserção:
- O núcleo da ideia de ordenação por inserção é a ordem local . Conforme mostrado na figura, a pessoa à esquerda de X é chamada de ordem local ;
- Primeiro, especifique um dado X (começando do primeiro dado) e altere o lado esquerdo do dado X para um estado local ordenado;
- Em seguida, mova X um bit para a direita e, após atingir a ordem local novamente, continue movendo um bit para a direita e repita a operação anterior até que X se mova para o último elemento.

//插入排序
ArrayList.prototype.insertionSort = function(){
//1.获取数组的长度
let length = this.array.length
//2.外层循环:从第二个数据开始,向左边的已经局部有序数据进行插入
for(let i = 1; i < length; i++){
//3.内层循环:获取i位置的元素,使用while循环(重点)与左边的局部有序数据依次进行比较
let temp = this.array[i]
let j = i
while(this.array[j - 1] > temp && j > 0){
this.array[j] = this.array[j - 1]//大的数据右移
j--
}
//4.while循环结束后,index = j左边的数据变为局部有序且array[j]最大。此时将array[j]重置为排序前的数据array[i],方便下一次for循环
this.array[j] = temp
}
}
A eficiência da ordenação por inserção:
-
Número de comparações: Na primeira passagem, o número máximo de vezes necessário é 1; na segunda vez, o número máximo é 2; e assim por diante, a última passagem é até N-1; portanto, o número total de comparações para classificação por inserção é N * (N - 1 ) / 2; No entanto, na verdade, apenas metade de todos os itens de dados precisam ser comparados em média antes que o ponto de inserção seja encontrado a cada vez, então o número de comparações é: N * ( N - 1) / 4 ;
-
Número de trocas: Quando o primeiro dado é especificado como X, ele precisa ser trocado 0 vezes, e quando o segundo dado é especificado como X, ele precisa ser trocado no máximo uma vez, e assim por diante. Quando o N-ésimo dado é especificado como X, precisa ser trocado no máximo N - 1 vezes, então o total Necessidade de troca N*(N-1)/2 vezes, e o número de empates é N*(N-1)/ 2 ;
-
Embora a eficiência da classificação por inserção seja O(N^2) na notação O grande , o número total de operações de classificação por inserção é menor. Portanto, na classificação simples, a classificação por inserção é a mais eficiente ;
4. Tipo de colina
Hill sort é uma versão melhorada e eficiente da classificação por inserção , que é mais eficiente do que a classificação por inserção .
Antecedentes históricos da família Hill:
- A classificação de Hill recebeu o nome de seu criador Hill (Donald Shell), e o algoritmo foi publicado em 1959 ;
- Pela primeira vez , o algoritmo de Hill ultrapassou a complexidade de tempo do algoritmo que a indústria de computadores sempre acreditou ser O(N^2) .
Problema de ordenação por inserção:
- Suponha que um pequeno item de dados esteja localizado muito próximo à extremidade direita , que deveria ser a posição de um item de dados maior ;
- Para mover este pequeno item de dados para a posição correta à esquerda, todos os itens de dados intermediários devem ser deslocados um bit para a direita , o que é muito ineficiente;
- Se houvesse alguma maneira de mover os itens de dados menores para a esquerda sem mover todos os itens de dados do meio, um por um, a velocidade do algoritmo seria muito melhorada.
A ideia de implementação da classificação de Hill:
- A classificação de colina realiza principalmente a classificação rápida agrupando dados ;
- Divida os dados em grupos de lacunas de acordo com o incremento definido (gap) ( o número de grupos é igual a gap ) e, em seguida, execute a classificação parcial em cada grupo;
Se houver 10 dados em uma matriz, o primeiro dado é preto e o incremento é 5. Em seguida, o segundo índice de dados pretos = 5 e o terceiro índice de dados pretos = 10 (não existe). Portanto, existem apenas 2 dados pretos em cada grupo e 10/2 = 5 podem ser divididos em 5 grupos no total, ou seja, o número de grupos é igual ao intervalo incremental .
- Após a classificação, reduza o incremento, continue agrupando e execute a classificação local novamente até que o intervalo de incremento seja igual a 1. A classificação da matriz pode então ser concluída com apenas pequenos ajustes;
O processo específico é o seguinte:
- Antes da classificação, a matriz original que armazena 10 dados é:

- Defina o intervalo de incremento inicial = comprimento / 2 = 5, ou seja, a matriz é dividida em 5 grupos, conforme mostrado na figura: [8, 3], [9, 5], [1, 4], [7, 6], [2, 0]:

- Em seguida, classifique os dados localmente em cada grupo, a ordem dos cinco grupos é mostrada na figura, que se torna: [3, 8], [5, 9], [1, 4], [6, 7], [0 , 2]:

- Em seguida, reduza o intervalo de incremento = 5 / 2 = 2, ou seja, a matriz é dividida em 2 grupos, conforme mostrado na figura: [3, 1, 0, 9, 7], [5, 6, 8, 4, 2] :
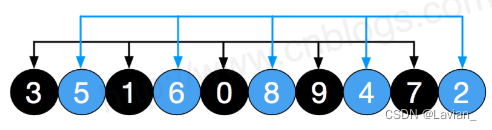
- Os dados são então classificados localmente em cada grupo, e a ordem dos dois grupos é mostrada na figura, que se torna: [0, 1, 3, 7, 9], [2, 4, 5, 6, 8]:

- Em seguida, reduza o intervalo de incremento = 2 / 1 = 1, ou seja, a matriz é dividida em 1 grupo, conforme mostrado na figura: [0, 2, 1, 4, 3, 5, 7, 6, 9, 8] :

- Por fim, você só precisa executar a classificação por inserção no conjunto de dados para concluir a classificação de todo o array:

Opções incrementais:
- O espaçamento inicial sugerido por Hill no manuscrito original é N / 2. Por exemplo, para uma matriz de N = 100, a sequência de incremento é: 50, 25, 12, 6, 3, 1. Pode-se descobrir que é arredondado para baixo quando não é divisível.
- Sequência incremental de Hibbard: O algoritmo da sequência incremental é: 2^k - 1, ou seja, 1, 3, 5, 7... etc.; a pior complexidade neste caso é O(N3/2)** , a média a complexidade é **O(N5/4) mas não comprovada;
- Sequência de incremento de Sedgewcik:

A implementação de código a seguir adota o incremento sugerido no manuscrito de classificação de Hill, que é N/2 .
Código:
//希尔排序
ArrayList.prototype.shellSort = function(){
//1.获取数组的长度
let length = this.array.length
//2.初始化增量
let gap = Math.floor(length / 2)
//3.第一层循环:while循环(使gap不断减小)
while(gap >= 1 ){
//4.第二层循环:以gap为增量,进行分组,对分组进行插入排序
//重点为:将index = gap作为选中的第一个数据
for(let i = gap; i < length; i++){
let temp = this.array[i]
let j = i
//5.第三层循环:寻找正确的插入位置
while(this.array[j - gap] > temp && j > gap - 1){
this.array[j] = this.array[j - gap]
j -= gap
}
//6.将j位置的元素设置为temp
this.array[j] = temp
}
gap = Math.floor(gap / 2)
}
}
Aqui está uma explicação do loop de três camadas no código acima:
- A primeira camada do loop: while loop, o gap de controle é decrementado para 1;
- A segunda camada do loop: Retire os dados do grupo gap divididos de acordo com o incremento g gap: pegue os dados com índice = gap como os primeiros dados selecionados, conforme mostrado na figura abaixo, se gap=5, então os dados com índice = intervalo é 3, os dados com índice = intervalo - 1 são 8 e os dois dados são um grupo. Em seguida, o intervalo é continuamente aumentado em 1 e movido para a direita até que o intervalo <comprimento. Neste momento, a matriz é dividida em 5 grupos.

- A terceira camada do loop: insira e classifique cada conjunto de dados;
A eficiência da ordenação de Hill:
- A eficiência da ordenação de Hill está diretamente relacionada ao incremento, mesmo que seja utilizada a eficiência incremental do manuscrito original, ela é superior à da ordenação simples.
5. Classificação rápida
Introdução à ordenação rápida:
-
A ordenação rápida pode ser considerada o algoritmo de ordenação mais rápido entre todos os algoritmos de ordenação atualmente . Claro, nenhum algoritmo é ótimo em todas as situações. No entanto, o quicksort é uma escolha melhor na maioria dos casos.
-
A classificação rápida é, na verdade , uma versão atualizada da classificação por bolha ;
A ideia central da classificação rápida é dividir e conquistar , primeiro selecione um dado (como 65), coloque os dados menores que ele no lado esquerdo dele e coloque os dados maiores que ele no lado direito dele . Esses dados são chamados de pivô
Ao contrário do tipo de bolha:
- O 65 que escolhemos pode colocá-lo na posição mais correta de uma só vez, não sendo necessário fazer nenhum movimento depois;
- Mesmo que o tipo de bolha tenha encontrado o valor máximo, ele precisa continuar a mover o valor máximo até que seja movido para a extrema direita;
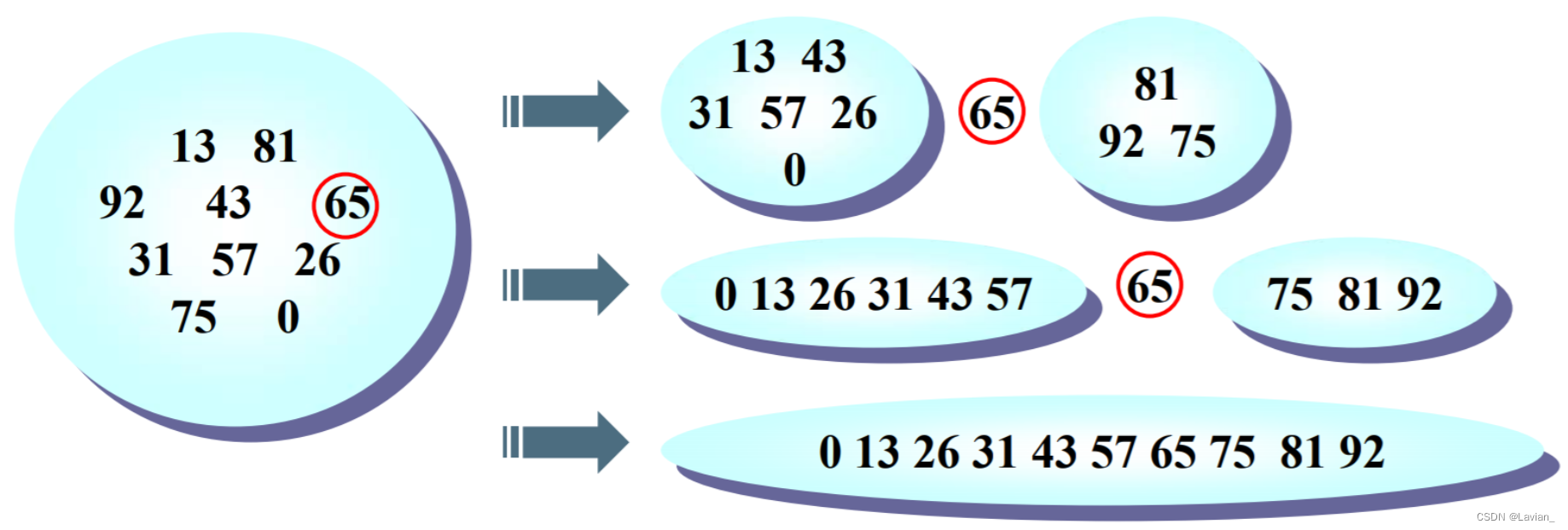
Hub de classificação rápida:
- A primeira solução: selecione diretamente o primeiro elemento como hub. Porém, quando o primeiro elemento é o valor mínimo, a eficiência não é alta;
- A segunda opção: use números aleatórios. O próprio número aleatório consome muito desempenho e não é recomendado;
- Excelente solução: tome o índice como o número do meio após classificar os três dados de cabeça, meio e bit; conforme mostrado na figura abaixo, os três dados retirados pelo valor subscrito são: 92, 31, 0, que se tornam após a classificação: 0, 31, 92, tome o número do meio 31 como pivô (quando (comprimento-1)/2 não é divisível, pode ser arredondado para baixo ou para cima):

Implementar seleção de hub:
//交换两个位置的数据
let swap = function(arr, m, n){
let temp = arr[m]
arr[m] = arr[n]
arr[n] = temp
}
//快速排序
//1.选择枢纽
let median = function(arr){
//1.取出中间的位置
let center = Math.floor(arr.length / 2)
let right = arr.length - 1
let left = 0
//2.判断大小并进行交换
if (arr[left] > arr[center]) {
swap(arr, left, center)
}
if (arr[center] > arr[right]){
swap(arr, center, right)
}
if (arr[left] > arr[right]) {
swap(arr, left, right)
}
//3.返回枢纽
return center
}
Depois que a matriz é operada pela função pivô de aquisição, as posições de dados correspondentes aos três valores subscritos selecionados tornam-se:

Implementação rápida do código de classificação:
//2.快速排序
let QuickSort = function(arr){
if (arr.length == 0) {
return []
}
let center = median(arr)
let c = arr.splice(center, 1)
let l = []
let r = []
for (let i = 0; i < arr.length; i++) {
if (arr[i] < c) {
l.push(arr[i])
}else{
r.push(arr[i])
}
}
return QuickSort(l).concat(c, QuickSort(r))
}
Eficiência de classificação rápida:
- Eficiência no pior caso de classificação rápida: o hub selecionado a cada vez é o dado mais à esquerda ou mais à direita. Neste momento, a eficiência é equivalente à classificação de bolhas e a complexidade de tempo é O(n2 ) . Isso pode ser evitado dependendo das opções de hub;
- A eficiência média da ordenação rápida: O(N*logN) , embora a eficiência de outros algoritmos também possa chegar a O(N*logN), dentre eles, a ordenação rápida é a melhor .