Algoritmo de classificação
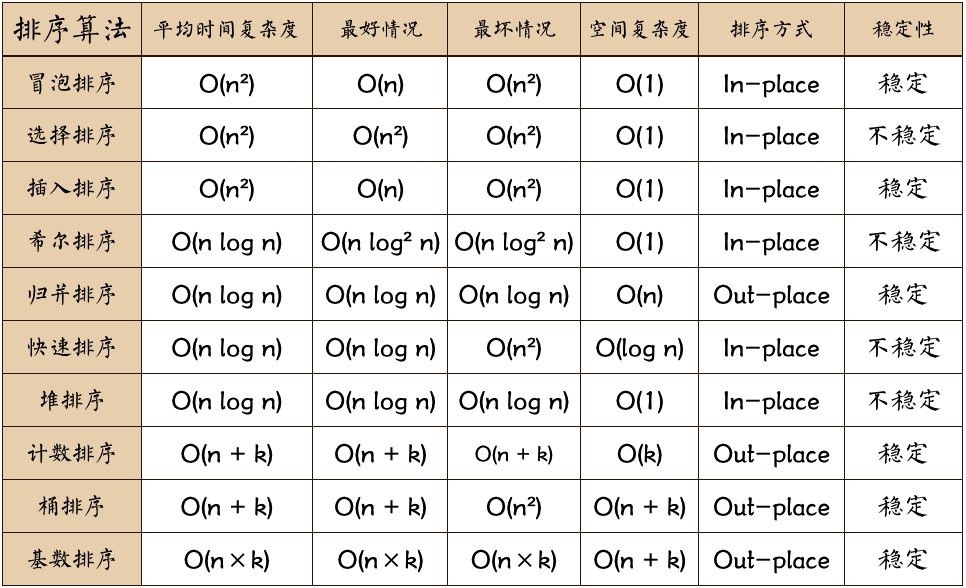
Os algoritmos de ordenação podem ser divididos em ordenação interna e ordenação externa. A ordenação interna é feita na memória e não requer espaço adicional; também pode ser dividida em ordenação comparativa e ordenação não comparativa. A figura a seguir é uma comparação de desempenho de dez algoritmos de classificação comuns. A estabilidade é baseada em se a classificação altera as posições relativas dos elementos originais.
1. Classificação de bolhas
A classificação por bolha usa comparações de elementos adjacentes aos pares e, se a ordem estiver errada, troca sua ordem, de modo que, em uma rodada, o maior ou o menor elemento seja trocado para o topo. Como a forma é muito semelhante a borbulhar repetidas vezes, chamamos isso de classificação de bolhas. O seguinte demonstra o caso de classificação de pequeno para grande:
/**
* 冒泡排序:优化:如果一趟排序中没有发生冒泡,说明数组已经有序即可退出循环
* @param arr
*/
public static int[] bubbleSort(int[] arr) {
boolean flag = false;
for (int i = 0; i < arr.length - 1; i++) {
//每冒泡一次,最大的都会冒泡到最顶端
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
flag = true;
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
//优化代码
if (!flag) {
break;
} else {
System.out.println("第" + (i + 1) + "次冒泡" + Arrays.toString(arr));
flag = false;
}
}
return arr;
}
2, tipo de seleção
Ou seja, em cada rodada de comparação, o elemento atual é selecionado como o valor máximo possível da rodada, e se o tamanho estiver errado, o valor máximo é atualizado e trocado. Desta forma, a posição de um número pode ser determinada a cada rodada.
/**
* 选择排序
* @param arr
* @return
*/
public static int[] selectSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int min = arr[i]; //选择一个作为最小值
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < min) {
arr[j] = arr[j] + arr[i];
arr[i] = arr[j] - arr[i];
arr[j] = arr[j] - arr[i];
}
min = arr[i];
}
}
return arr;
}
3. Ordenação por inserção
A partir do segundo elemento, compare com o primeiro elemento um por um, se apropriado, insira o elemento na primeira posição; encontre o elemento apropriado por sua vez e insira-o na segunda e terceira posições. .
Semelhante à maneira de inserir cartas de baralho: a partir da segunda carta, compare com as cartas na primeira posição, e a ordem é adequada, ou seja, insira o elemento na primeira posição e não compare o elemento é equivalente a retroceder.
Durante a comparação, os elementos frontais são ordenados e os elementos traseiros não ordenados.
/**
* 插入排序
* @param arr
* @return
*/
public static int[] insertSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
//当前需要插入的元素
int current = arr[i];
//被插入的位置,即当前数的前一个
int preIndex = i - 1;
while (preIndex >= 0 && current < arr[preIndex]) {
//被插入位置的元素后移
arr[preIndex +1] = arr[preIndex];
//索引向前移动
preIndex--;
}
//当前值插入的位置
arr[preIndex + 1] = current;
}
return arr;
}
4, classificação Hill
A classificação de colina é uma melhoria na classificação por inserção simples original, também conhecida como classificação incremental de redução. Por exemplo, para uma sequência já ordenada, ao inserir, pode ser desnecessário realizar vários movimentos, o que afeta a eficiência.
Ideia: Divida a sequência em grupos de acordo com um certo intervalo incremental (geralmente comprimento/2) e execute uma classificação de inserção simples em cada grupo de dados; depois continue agrupando de acordo com o método intervalo/=2 e repita o método acima . Até gap=1, ou seja, quando sobrar um grupo, o efeito da ordenação de Hill foi alcançado, neste momento, a seqüência é ordenada principalmente, e então uma ordenação simples pode ser realizada.
O objetivo do agrupamento é tornar o grupo ordenado e o todo o mais ordenado possível.
Pensando: Por que o agrupamento é adequado para ordenação por inserção? Você pode ver que o agrupamento aqui não é uma simples dicotomia, mas é dividido de acordo com o espaçamento. Na ordenação por inserção anterior, as duas posições são trocadas, e os elementos na posição o espaçamento será movido Ordenando de acordo com o agrupamento, apenas uma vez Basta mover a distância.
/**
* 希尔排序
*
* @param arr
* @return
*/
public static int[] shellSort(int[] arr) {
//控制每次的步长
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
//按照步长分组
for (int i = gap; i < arr.length; i++) {
//对每次分组的元素进行比较
int preIndex = i - gap; //组内的前一个元素位置
int current = arr[i]; //当前值
//比较组内的所以元素,并移动位置
while (preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex + gap] = arr[preIndex];
preIndex -= gap;
}
//退出循环后,位置找到插入
arr[preIndex + gap] = current;
}
}
return arr;
}
5. Classificação rápida
O princípio da ordenação rápida: encontre um elemento como valor de referência (geralmente selecione o primeiro elemento), coloque os elementos menores que ele à direita e coloque os elementos maiores que ele à esquerda . Em seguida, execute isso recursivamente nas sequências esquerda e direita até que haja um elemento em cada sequência esquerda e direita, ponto em que toda a sequência está em ordem.
Ideia: Divida a sequência em partes relativamente ordenadas esquerda e direita com base no valor de referência, até que cada sequência tenha 1 comprimento.
Prática : Em cada agrupamento, compare o valor de referência com o último elemento, de trás para frente, até encontrar um elemento menor que o valor de referência, e troque de posição; depois, de frente para trás, até que um elemento maior que o valor de referência seja elementos encontrados, trocar posições. Até que as posições relativas dos índices dianteiro e traseiro mudem, indicando que uma rodada acabou, uma sequência de valores de referência pode ser determinada neste momento. Em seguida, execute o quicksort em cada sequência esquerda e direita.
/**
* 交换数组内的两个元素
* @param a
* @param n
* @param m
*/
private void swap(int[] arr, int a, int b) {
// 异或交换,可能存在相等时的零值情况
if(a==b){
return;
}else{
arr[a] = arr[a] ^ arr[b];
arr[b] = arr[a] ^ arr[b];
arr[a] = arr[a] ^ arr[b];
}
}
/**
* 快速排序
* @param arr
* @param start 起始位置
* @param end 终点位置
* @return
*/
public static void quickSort(int[] arr,int start,int end){
//标记索引,记录当前位置
int low = start;
int high = end;
int key = arr[low]; //基准值一般选择序列第一个元素
while(start<end){
//从后往前遍历,直到找到较小值
while(start<end && arr[end]>=key){
end--;
}
//退出时如果找到,即交换位置
if(arr[end]<=key){
swap(arr,start,end);
}
//从前往后遍历,直到找到较大值
while(start<end && arr[start]<=key){
start++;
}
if(arr[start]>=key){
swap(arr,start,end);
}
}
//一遍排序结束,基准值位置就确定了,即左边均小于它,右边均大于它
//如果当前起始位置大于标记,说明左边序列仍有元素,对左序列递归进行快速排序
if(start>low){
quickSort(arr,low,start-1);
}
//如果当前终点位置小于标记,说明右边序列仍有元素,对右序列递归进行快速排序
if(end<high){
quickSort(arr,end+1,high);
}
}
6. Mesclar classificação
De acordo com a ideia do método de dividir e conquistar, divide : divide a sequência em duas sequências, e mescle e ordene-as respectivamente até que o comprimento da subsequência seja 1; regra : mescle cada subsequência, aqui uma sequência adicional é adicionada para armazenar o resultado mesclado. Regra de mesclagem: compare a partir da posição inicial da sequência, a menor é preenchida no conjunto de resultados; se uma sequência for percorrida, outra sequência será preenchida diretamente no conjunto de resultados.
/**
* 归并排序:分治思想,先分再治
* @param arr
* @return
*/
public static int[] mergeSort(int[] arr) {
//“分”结束的条件
if (arr.length < 2) {
return arr;
}
int mid = arr.length / 2;
//均分成两个数组序列
int[] left = Arrays.copyOfRange(arr, 0, mid);
int[] right = Arrays.copyOfRange(arr, mid, arr.length);
return merge(mergeSort(left), mergeSort(right));
}
/**
* “治”:将"分"好的数组序列组合起来
* @param left
* @param right
* @return
*/
public static int[] merge(int[] left, int[] right) {
//返回拼装好的结果数组
int[] result = new int[left.length + right.length];
//i,j,分别为左右序列的索引,index为结果集的索引
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= left.length) //当序列的索引超过其长度时说明序列已经排完,只需将另一序加入结果集中即可
result[index] = right[j++];
else if (j >= right.length)
result[index] = left[i++];
else if (left[i] > right[j]) //左右序列的数据依次进行比较,小的加入到结果集中
result[index] = right[j++];
else
result[index] = left[i++];
}
return result;
}
Resumir:
Como o nome sugere:
Bubble sort: Os elementos em posições adjacentes são comparados e trocados, e o maior valor será trocado para o topo para formar uma bolha;
Ordenação por seleção: duas rodadas de for, selecione um valor alvo em cada rodada, compare e troque;
Ordenação por inserção: Selecione os elementos apropriados da primeira posição para inserir e trocar, e a frente da sequência é ordenada;
Hill sort: ordenação por inserção para agrupamento, ordenação por inserção dentro de cada sequência;
Merge sort: Divida a sequência igualmente para torná-la ordenada internamente; em seguida, combine para tornar a sequência totalmente ordenada.
Classificação Rápida: Divida a sequência em duas partes que são ordenadas em relação à esquerda e à direita com base no valor de referência, até que cada sequência tenha um comprimento de 1.