Próximo: Visual SLAM: Quais são as tendências atuais e o que esperar?
Endereço: Revisão da Pesquisa Visual SLAM e Discussão de Tendências Futuras
Traduzido por: Dong Yawei
Lembrete especial: Este artigo tem um total de 24.000 palavras, incluindo todos os aspectos do SLAM visual. Se precisar ler em detalhes, a resposta de fundo [ 221101 ] , você pode baixar os documentos originais e traduzidos

Resumo: Nos últimos anos, sensores baseados em visão têm demonstrado desempenho, precisão e eficiência notáveis em sistemas de localização e mapeamento simultâneos (SLAM). Aqui, os métodos de localização e mapeamento visual simultâneo (VSLAM) referem-se aos métodos SLAM que usam câmeras para estimativa de pose e geração de mapas.
Podemos ver que muitos estudos mostraram que apesar do menor custo do SLAM visual, o VSLAM pode superar os métodos tradicionais que dependem apenas de sensores específicos. Os métodos VSLAM utilizam diferentes tipos de câmeras (por exemplo, monocular, estéreo e RGB-D), são realizados em vários conjuntos de dados (por exemplo, KITTI, TUM RGB-D e EuRoC) e em diferentes ambientes (por exemplo, internos e externos). é testado e emprega vários algoritmos e métodos para compreender melhor o ambiente.
As mudanças acima fizeram com que este tópico de pesquisa fosse amplamente preocupado pelos pesquisadores, e muitos métodos VSLAM foram produzidos. Com base nisso, o principal objetivo deste artigo é apresentar os últimos avanços nos sistemas VSLAM e discutir os desafios e tendências existentes. Conduzimos uma pesquisa bibliográfica aprofundada em 45 artigos influentes publicados na área de VSLAM e classificamos esses artigos de acordo com diferentes características, incluindo inovação de método, novidade de aplicação de domínio, otimização de algoritmo e nível semântico, e também discutimos tendências atuais e direções futuras são identificados, o que pode auxiliar os pesquisadores em seus estudos.
01 Introdução
Localização e Mapeamento Simultâneo (SLAM) refere-se ao processo de construção de um mapa de um ambiente desconhecido enquanto localiza a localização de um agente [1]. Aqui, o agente pode ser um robô doméstico [2], um veículo autônomo [3], um rover planetário [4], ou mesmo um veículo aéreo não tripulado (UAV) [5], [6] ou um veículo não tripulado (UGV). [7]. Em ambientes onde os mapas não estão disponíveis ou onde a posição do robô é desconhecida, o SLAM tem uma ampla gama de aplicações. Nos últimos anos, com a melhoria contínua da aplicação da tecnologia robótica, o SLAM ganhou grande atenção na indústria e nos círculos de pesquisa científica [8], [9].
Os sistemas SLAM podem coletar dados do ambiente usando uma variedade de sensores, baseados em laser, acústicos e visuais [10]. Há uma variedade de sensores baseados em visão, incluindo câmeras monoculares, estéreo, baseadas em eventos, omnidirecionais e de profundidade RGB (RGB-D). Robôs com sensores de visão utilizam os dados visuais fornecidos pelas câmeras para estimar a posição e orientação do robô em relação ao seu entorno [11]. O processo de utilização de sensores visuais para SLAM é o SLAM visual (VSLAM).
O uso de dados visuais no SLAM tem as vantagens de hardware mais barato, detecção e rastreamento de objetos mais intuitivos e a capacidade de fornecer informações visuais e semânticas ricas [12]. Suas imagens capturadas (ou quadros de vídeo) também podem ser usadas em aplicações baseadas em visão, incluindo segmentação semântica e detecção de objetos. As características acima tornam o VSLAM uma direção popular na robótica e geraram muitas pesquisas e pesquisas por especialistas em robótica e visão computacional (CV) nas últimas décadas. Portanto, o VSLAM já existe em diversas aplicações que requerem a reconstrução de modelos 3D do ambiente, tais como: direção autônoma, realidade aumentada (AR) e robótica de serviço [13].
Como método geral introduzido em [14] para resolver o alto custo computacional, o método SLAM inclui principalmente dois threads paralelos, nomeadamente rastreamento e mapeamento. Portanto, a taxonomia de algoritmos utilizados no VSLAM é representar como os pesquisadores utilizam diferentes métodos e estratégias em cada thread. De acordo com o tipo de dados utilizados pelo sistema SLAM, os métodos SLAM podem ser divididos em duas categorias: métodos diretos e métodos indiretos (baseados em recursos) [15].
Em cenários de uso, os métodos indiretos extraem pontos característicos (ou seja, pontos-chave) de texturas de objetos e os rastreiam combinando descritores em quadros consecutivos. Apesar do custo computacional das etapas de extração e correspondência de características, esses métodos são precisos e robustos às mudanças na intensidade da luz em cada quadro. Por outro lado, os métodos diretos estimam o movimento da câmera diretamente a partir de dados em nível de pixel e otimizam para minimizar erros fotométricos. Baseando-se em técnicas de fotogrametria, esses métodos exploram todos os pixels de saída da câmera e rastreiam o que eles substituem em quadros sucessivos de acordo com seus aspectos restritos, como brilho e cor. Esses recursos permitem que o método direto modele mais informações da imagem do que o método indireto e obtenha uma reconstrução 3D de maior precisão. No entanto, embora os métodos diretos funcionem melhor em ambientes menos texturizados e não exijam mais computação para extração de características, eles frequentemente enfrentam problemas de otimização em grande escala [16]. Os prós e contras de cada abordagem incentivam os pesquisadores a considerar o desenvolvimento de soluções híbridas, considerando combinações de ambas as abordagens. Os métodos híbridos geralmente combinam estágios de detecção indireta e direta, onde um inicializa e corrige o outro.

Além disso, como o VSLAM inclui principalmente um front-end de odometria visual (VO) (para estimar localmente a trajetória da câmera) e um back-end SLAM (para otimizar o mapa criado), a diversidade de módulos usados em cada parte leva a diferenças percebidas. . VO fornece uma estimativa inicial da pose do robô com base na consistência local, que é enviada ao backend para otimização. Portanto, a principal diferença entre VSLAM e VO é considerar a consistência global dos mapas e das trajetórias previstas. Algumas aplicações VSLAM de última geração também incluem dois módulos adicionais: detecção e mapeamento de fechamento de loop [15]. Eles são responsáveis por detectar locais visitados anteriormente para rastreamento e mapeamento mais precisos com base na pose da câmera.
A Figura 1 mostra a arquitetura geral da abordagem VSLAM padrão. Assim, a entrada do sistema também pode ser integrada a outros dados de sensores, como unidades de medição inercial (IMUs) e lidar, para fornecer mais informações do que apenas dados visuais. Além disso, em relação ao método direto ou indireto utilizado no VSLAM Pipeline, a função do módulo de processamento de recursos visuais pode ser alterada ou ignorada. Por exemplo, o estágio de Processamento de Recursos utiliza apenas métodos indiretos. Outro fator é a utilização de módulos específicos, como detecção de fechamento de loop e ajuste de bundle, para melhorar a execução.
Este artigo resume 45 artigos VSLAM e os classifica em diferentes categorias de acordo com diferentes aspectos. Esperamos que nosso trabalho sirva de referência para pesquisadores de robótica que trabalham na otimização de técnicas VSLAM.
O restante deste artigo está estruturado da seguinte forma:
A Seção II analisa a evolução dos algoritmos VSLAM.
A Seção III apresenta e discute outras pesquisas na área de VSLAM.
A Seção IV apresenta brevemente cada módulo do VSLAM.
A Seção V discute a classificação do VSLAM com base em diferentes objetivos de aplicação.
A Seção VI discute questões não resolvidas e possíveis tendências de pesquisa nesta área.
02 Evolução do Visual SLAM
Os sistemas VSLAM amadureceram ao longo dos últimos anos e vários frameworks desempenharam um papel importante neste processo de desenvolvimento. Para apresentar claramente a situação geral, a Figura 2 apresenta os métodos VSLAM amplamente utilizados que influenciaram o desenvolvimento do círculo SLAM e são usados como referências padrão para outras estruturas.
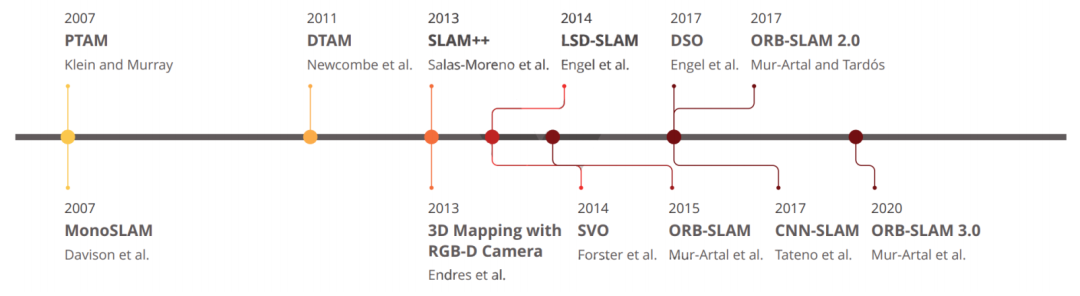
A primeira tentativa na literatura de implementar um sistema VSLAM monocular em tempo real foi desenvolvida por Davison et al., em 2007, que introduziu uma estrutura chamada Mono-SLAM [17]. A estrutura de seu método indireto pode estimar o movimento da câmera do mundo real e objetos 3D usando o algoritmo Extended Kalman Filter (EKF) [18]. Apesar da falta de módulos de otimização global e detecção de fechamento de loop, o Mono-SLAM começa a desempenhar um papel importante no domínio VSLAM. No entanto, os mapas reconstruídos desta forma incluíam apenas pontos de referência e não forneciam mais detalhes sobre a área.
Klein et al.[14] propuseram rastreamento e mapeamento paralelo (PTAM) no mesmo ano e dividiram todo o sistema VSLAM em dois segmentos principais: rastreamento e mapeamento. Este padrão multithreading foi endossado por muitos trabalhos subsequentes, que são discutidos neste artigo. A ideia principal de sua abordagem é reduzir custos computacionais e aplicar processamento paralelo para obter desempenho em tempo real. Enquanto o thread de rastreamento estima o movimento da câmera em tempo real, o thread de mapeamento prevê as localizações 3D dos pontos característicos. O PTAM também é o primeiro a otimizar conjuntamente as poses da câmera e criar mapas 3D usando ajuste de pacote (BA). Ele usa o algoritmo detector de canto FAST [19] para correspondência e rastreamento de pontos-chave. Embora o desempenho deste algoritmo seja melhor que o do Mono-SLAM, seu design é complexo e requer configuração manual pelo usuário no primeiro estágio.
Em 2011, Newcombe et al., introduziram um método direto para medir valores de profundidade e parâmetros de movimento para construir mapas, nomeadamente Dense Tracking and Mapping (DTAM). DTAM é uma estrutura em tempo real equipada com módulos densos de mapeamento e rastreamento, que podem determinar a pose da câmera alinhando todo o quadro com um determinado mapa de profundidade. Para construir o mapa ambiental, as etapas acima estimam os parâmetros de profundidade e movimento da cena separadamente. Embora o DTAM possa fornecer uma representação detalhada dos mapas, a execução em tempo real requer alto custo computacional.
Como outra abordagem indireta ao campo de mapeamento 3D e otimização baseada em pixels, Endres et al.propuseram uma abordagem baseada em câmera RGB-D em 2013. Sua abordagem funciona em tempo real e se concentra em sistemas embarcados de baixo custo e pequenos robôs, mas não consegue produzir resultados precisos em cenários desafiadores ou sem recursos. No mesmo ano, Salas Moreno et al.[22] propuseram a primeira tentativa de explorar informações semânticas em um framework SLAM em tempo real, denominado SLAM++. Seu sistema obtém a saída do sensor RGB-D e executa estimativa e rastreamento de pose de câmera 3D para formar um gráfico de pose. Os nós em um gráfico de pose representam estimativas de pose e são conectados por arestas que representam poses relativas entre nós com incerteza de medição [23]. Em seguida, a pose prevista será refinada incorporando poses 3D relativas obtidas de objetos semânticos na cena.
À medida que a estrutura básica do VSLAM amadureceu, os pesquisadores se concentraram em melhorar o desempenho e a precisão desses sistemas. Nesse sentido, Forster et al.propuseram uma abordagem híbrida de VO em 2014 como parte da arquitetura VSLAM, chamada odometria visual semidireta (SVO) [24]. Sua abordagem pode combinar métodos diretos e baseados em recursos para estimativa de movimento baseada em sensores e tarefas de mapeamento. O SVO pode funcionar com câmeras monoculares e estéreo e está equipado com um módulo de refinamento de pose que minimiza erros de reprojeção. No entanto, a principal desvantagem do SVO é que ele adota associação de dados de curto prazo e não pode realizar detecção de fechamento de loop e otimização global.
LSD-SLAM [25] é outro método VSLAM influente introduzido por Engel et al. em 2014, que inclui rastreamento, estimativa de mapa de profundidade e otimização de mapa. O método pode reconstruir mapas em grande escala usando seu módulo de estimativa de gráfico de pose, com otimização global e detecção de fechamento de loop. O ponto fraco do LSD-SLAM é que sua fase de inicialização é desafiadora, exigindo todos os pontos do plano, tornando-o um método computacionalmente intensivo.
Mur Artal et al.propuseram dois métodos VSLAM indiretos precisos que atraíram a atenção de muitos pesquisadores até agora: ORB-SLAM [26] e ORB-SLAM 2.0 [27]. Esses métodos podem realizar localização e mapeamento em sequências bem texturizadas e realizar detecção de pose de alto desempenho usando recursos Oriented FAST e Rotated BRIEF (ORB). A primeira versão do ORB-SLAM foi capaz de usar quadros-chave coletados das posições da câmera para calcular a posição da câmera e a estrutura do ambiente. A segunda versão é uma extensão do ORB-SLAM com três threads paralelos, incluindo rastreamento para encontrar correspondências de recursos, mapeamento local para operações de gerenciamento de mapas e fechamento de loop para detectar novos loops e corrigir erros de desvio. Embora o ORB-SLAM 2.0 possa ser usado com configurações de câmera monocular e estéreo, ele não pode ser usado diretamente para navegação autônoma devido à escala desconhecida dos dados do mapa reconstruído. Outra desvantagem desse método é que ele não funciona em áreas sem textura ou em ambientes com padrões repetidos. A versão mais recente deste framework, denominada ORB-SLAM 3.0, foi proposta em 2021 [28]. Ele funciona com vários tipos de câmeras, como visão monocular, RGB-D e estéreo, e fornece resultados aprimorados de estimativa de pose.
Nos últimos anos, com o notável impacto da aprendizagem profunda em vários campos, métodos baseados em redes neurais profundas podem resolver muitos problemas, proporcionando maiores taxas de reconhecimento e correspondência. Da mesma forma, substituir recursos artesanais por recursos aprendidos em VSLAM é uma das soluções propostas por muitos métodos recentes baseados em aprendizagem profunda.
Nesse sentido, Tateno et al.propuseram uma abordagem baseada em rede neural convolucional (CNN) que processa quadros de entrada para estimativa de pose de câmera e usa quadros-chave para estimativa de profundidade, denominada CNN-SLAM [29]. Segmentar os quadros da câmera em partes menores para entender melhor o ambiente é uma das ideias do CNN-SLAM para fornecer processamento paralelo e desempenho em tempo real.
Como uma abordagem diferente, Engel et al., também introduziram uma nova tendência no algoritmo VSLAM direto chamado Direct Sparse Odometry (DSO) [30], que combina o método direto e a reconstrução esparsa para extrair o ponto de maior intensidade. Ele leva em consideração os parâmetros de formação da imagem e usa um método de rastreamento indireto, rastreando um conjunto esparso de pixels. Deve-se notar que o DSO só consegue obter precisão perfeita ao calibrar a câmera fotometricamente, e não pode obter resultados de alta precisão com câmeras convencionais.
Em resumo, durante a evolução dos sistemas VSLAM, abordagens recentes concentraram-se no paralelismo de múltiplos módulos especializados. Esses módulos formam uma tecnologia e estrutura comuns compatíveis com uma ampla variedade de sensores e ambientes. As propriedades acima permitem que sejam executados em tempo real e sejam mais flexíveis em termos de melhoria de desempenho.
03 visão geral relacionada
Existem vários artigos de revisão na área de VSLAM que fornecem uma análise abrangente dos diferentes métodos existentes. Cada artigo analisa as principais vantagens e desvantagens da adoção de uma abordagem VSLAM.
Macario Barros et al.31 categorizam esquemas SLAM visuais em três categorias distintas: visão pura (monocular), visual-inercial (estereoscópica) e RGB-D. Também propuseram vários critérios para simplificar a análise do VSLAM. No entanto, eles não incluem outros sensores de visão, como sensores baseados em eventos, que discutiremos mais adiante na Seção 1 do Capítulo 4.
Chen et al.[32] reuniram uma grande quantidade de literatura VSLAM tradicional e semântica. Eles dividiram a era de desenvolvimento do SLAM em estágios clássicos, de análise de algoritmos e de percepção robusta, e introduziram os problemas quentes da época. Eles também resumem estruturas clássicas com abordagens diretas/indiretas e investigam o impacto de algoritmos de aprendizagem profunda na segmentação semântica. Embora seu trabalho forneça uma exposição abrangente de soluções de alto nível neste campo, a taxonomia dos métodos é limitada aos tipos de recursos usados no VSLAM baseado em recursos.
Jia et al.[33] pesquisaram um grande número de artigos e fizeram uma comparação simples entre métodos baseados em otimização de gráficos e métodos que utilizam aprendizagem profunda. No entanto, apesar das comparações apropriadas, as suas conclusões não podem ser generalizadas adequadamente devido ao número limitado de artigos pesquisados.
Em outro trabalho, Abaspur Kazerouni et al.[34] cobriram vários métodos VSLAM, exploraram dispositivos sensoriais, conjuntos de dados e módulos, e simularam vários métodos indiretos para comparação e análise. No entanto, eles abordam apenas algoritmos baseados em recursos, como HOG, Scale-Invariant Feature Transform (SIFT), Speeded Up Robust Features (SURF) e soluções baseadas em aprendizagem profunda. Bavle et al.[35] analisam aspectos da percepção de pose em diversas aplicações SLAM e VSLAM e discutem suas deficiências. Eles podem concluir que a manipulação de recursos que carecem de cenas semânticas pode melhorar os resultados do trabalho de pesquisa atual.
Outras pesquisas estudaram métodos VSLAM de última geração para tópicos ou tendências específicas. Por exemplo, Duan et al.[15] estudaram o progresso do aprendizado profundo em sistemas SLAM visuais para robôs de transporte. No artigo, os autores resumem as vantagens e desvantagens do uso de vários métodos baseados em aprendizagem profunda em tarefas de detecção de VO e fechamento de loop. Uma vantagem significativa do uso de métodos de aprendizagem profunda em VSLAM é a extração precisa de recursos na estimativa de pose e no cálculo de desempenho geral.
Em outro trabalho na mesma área, Arshad e Kim [36] focaram no impacto de algoritmos de aprendizagem profunda na detecção de fechamento de loop usando dados visuais. Eles revisaram vários artigos do VSLAM e analisaram a autonomia de longo prazo do robô sob diferentes condições.
Singandhupe e La [37] resumiram o impacto do VO e do VSLAM em veículos não tripulados. Eles reuniram os métodos avaliados no conjunto de dados KITTI, permitindo-lhes descrever brevemente os pontos fortes e fracos de cada sistema.
Em um artigo semelhante, Cheng et al.[32] revisaram sistemas de direção autônoma baseados em VSLAM e propuseram tendências futuras de desenvolvimento para tais sistemas.
Vários outros pesquisadores investigaram a capacidade do VSLAM de funcionar em condições do mundo real. Por exemplo, Saputra et al.[38] discutem a reconstrução, divisão, rastreamento e execução paralela de threads para variações de técnicas VSLAM operando em ambientes dinâmicos e hostis.
Esta revisão difere de outras até à data por fornecer uma análise abrangente do VSLAM em diferentes locais. Em comparação com outras pesquisas VSLAM, as principais contribuições deste artigo são:
-
Categorizar diversas publicações recentes em VSLAM de acordo com as principais contribuições, critérios e objetivos dos pesquisadores que propõem novas soluções
-
Analise as tendências atuais em VSLAM investigando diferentes abordagens em diferentes aspectos
-
Introduzir possíveis problemas de VSLAM
04 Cada módulo de SLAM visual
Combinando vários métodos visuais de SLAM, dividimos os requisitos das diferentes etapas nos seguintes módulos:
4.1 Sensores e aquisição de dados
As primeiras implementações do algoritmo VSLAM introduzidas por Davison et al.[17] foram equipadas com uma câmera monocular para recuperação de trajetória. Câmeras monoculares também são os sensores de visão mais comuns usados para diversas tarefas, como detecção e rastreamento de objetos [39]. Por outro lado, uma câmera estéreo contém dois ou mais sensores de imagem, permitindo-lhe perceber informações de profundidade nas imagens capturadas, obtendo assim melhor desempenho em aplicações VSLAM. Essas configurações de câmera valem a pena por fornecerem percepção de informações para requisitos de maior precisão. Câmeras RGB-D são outras variantes de sensores de visão usados em VSLAM que podem fornecer informações de profundidade e cor em uma cena. Dada a iluminação adequada e a velocidade de movimento, os sensores de visão acima mencionados podem fornecer informações ricas sobre o ambiente num ambiente intuitivo, mas muitas vezes enfrentam condições de iluminação deficientes ou cenas com uma grande faixa dinâmica.
Nos últimos anos, câmeras de eventos também têm sido utilizadas em diversas aplicações VSLAM. Quando o movimento é detectado, esses sensores de visão bioinspirados de baixa latência podem produzir alterações de brilho no nível de pixel em vez de quadros de intensidade padrão, permitindo saída de alta faixa dinâmica sem efeitos de desfoque de movimento [40]. Em comparação com câmeras padrão, os sensores baseados em eventos podem fornecer informações visuais precisas em movimentos de alta velocidade e cenas dinâmicas de grande escala, mas não podem fornecer informações suficientes quando a taxa de movimento é baixa. Embora as câmeras de eventos possam superar os sensores de visão padrão em condições de iluminação severa e faixa dinâmica, elas fornecem principalmente informações assíncronas sobre o ambiente. Isso torna os algoritmos de visão tradicionais incapazes de processar a saída desses sensores [41]. Além disso, o uso de janelas espaço-temporais de eventos juntamente com dados obtidos de outros sensores pode fornecer estimativas de pose ricas e informações de rastreamento.
Além disso, alguns métodos usam configurações de múltiplas câmeras para resolver problemas comuns de trabalho em ambientes reais para melhorar a precisão da localização. A utilização de vários sensores de visão pode ajudar a resolver problemas complexos, como oclusão, camuflagem, falha do sensor ou texturas rastreáveis esparsas, fornecendo câmeras com campos de visão sobrepostos. Embora as configurações de múltiplas câmeras possam resolver alguns problemas de aquisição de dados, o VSLAM somente de câmera pode enfrentar vários problemas, como desfoque de movimento ao encontrar objetos em movimento rápido, incompatibilidade de recursos com pouca ou muita luz, mudança de cena em alta velocidade, etc. omissão, etc Portanto, algumas aplicações VSLAM podem ser equipadas com múltiplos sensores próximos à câmera. A fusão de eventos e frames padrão [42] ou a integração de outros sensores como LiDAR [43] e IMU em VSLAM são algumas soluções existentes.
4.2 Cenários de aplicação
Uma forte suposição em muitas práticas tradicionais de VSLAM é que os robôs trabalham em um mundo relativamente estático, sem mudanças inesperadas. Portanto, embora muitos sistemas possam ser aplicados com sucesso em ambientes específicos, algumas mudanças inesperadas no ambiente (por exemplo, a presença de objetos em movimento) podem complicar o sistema e degradar em grande medida a qualidade da estimativa do estado. Sistemas que trabalham em ambientes dinâmicos normalmente usam algoritmos como fluxo óptico ou Random Sampling Consensus (RANSAC) [44] para detectar movimento na cena, classificar objetos em movimento como outliers e ignorá-los. Tais sistemas exploram informações geométricas, informações semânticas ou uma combinação de ambas, para melhorar os esquemas de localização [45].
Além disso, podemos dividir os ambientes em categorias internas e externas como uma classificação geral. Os ambientes externos podem ser áreas urbanas com marcos estruturais e mudanças de movimento em grande escala (como edifícios e texturas de estradas), ou áreas off-road com estados de movimento fracos (como nuvens e vegetação em movimento, texturas de areia, etc.), que melhoram o O risco de localização e detecção de loop. Os ambientes internos, por outro lado, contêm cenas com propriedades espaciais globais completamente diferentes, como corredores, paredes e salas. Podemos imaginar que embora um sistema VSLAM possa funcionar bem em uma das regiões mencionadas acima, pode não apresentar o mesmo desempenho em outros ambientes.
4.3 Processamento de recursos visuais
Conforme mencionado no Capítulo 1, detectar características visuais e explorar informações do descritor de características para estimativa de pose é um estágio inevitável dos métodos VSLAM indiretos. Esses métodos usam vários algoritmos de extração de recursos para compreender melhor o ambiente e rastrear pontos de recursos em quadros consecutivos. Existem muitos algoritmos no estágio de extração de recursos, incluindo SIFT[46], SURF[47], FAST[19], BRIEF[48], ORB[49], etc. Entre eles, comparados com SIFT e SURF [50], os recursos ORB têm a vantagem de extração e correspondência rápida sem perder muita precisão.
O problema com alguns dos métodos acima é que eles não podem ser adaptados de forma eficaz a várias situações complexas e imprevistas. Portanto, muitos pesquisadores usam a CNN para extrair recursos profundos de imagens em diferentes estágios, incluindo VO, estimativa de pose e detecção de fechamento de loop. Dependendo das características de design destes métodos, estas técnicas podem representar estruturas supervisionadas ou não supervisionadas.
4.4 Avaliação do Programa
Embora alguns métodos VSLAM, especialmente aqueles capazes de funcionar em ambientes dinâmicos e desafiadores, tenham sido testados em robôs em condições do mundo real, muitos trabalhos de investigação utilizaram conjuntos de dados disponíveis publicamente para demonstrar a sua aplicabilidade.
O conjunto de dados RAWSEEDS de Bonarini et al. [51] é uma ferramenta de teste padrão multissensor bem conhecida que contém trajetória de robôs internos, externos e mistos e dados reais. É uma das primeiras ferramentas de teste padrão disponíveis publicamente para fins de robótica e SLAM.
Scenenet RGB-D de McCormac et al.[52] é outro conjunto de dados popular para problemas de compreensão de cena, como segmentação semântica e detecção de objetos, que contém 5 milhões de imagens RGB-D renderizadas em grande escala. O conjunto de dados também contém rótulos de verdade completos em pixels e dados precisos de pose e profundidade da câmera, o que o torna uma ferramenta poderosa para aplicações VSLAM.
Muitos trabalhos recentes na área de VSLAM e VO testaram seus métodos no conjunto de dados TUM RGB-D [53]. O conjunto de dados mencionado acima e o equipamento de teste de benchmark contêm imagens coloridas e de profundidade capturadas por um sensor Microsoft Kinect e suas trilhas de sensor de verdade terrestre correspondentes.
Alternativamente, NTU VIRAL de Nguyen et al.[54] é um conjunto de dados coletado por um drone equipado com lidar 3D, câmera, IMU e banda ultralarga múltipla (UWB). Este conjunto de dados contém instâncias internas e externas e foi projetado para avaliar a direção autônoma e o desempenho de manipulação aérea.
Além disso, o EuRoC MAV [55], de Burri et al., é outro conjunto de dados popular que contém imagens capturadas por uma câmera estéreo junto com medições sincronizadas de IMU e dados reais de movimento. De acordo com as condições ambientais, os dados recolhidos no EuRoC MAV são divididos em três categorias: fácil, médio e difícil.
OpenLORIS Scene [56] de Shi et al.é outro conjunto de dados disponível publicamente para trabalho VSLAM, contendo uma grande quantidade de dados coletados por robôs com rodas equipados com vários sensores. Ele fornece dados apropriados para algoritmos monoculares e RGB-D, bem como dados de odometria de codificadores de roda.
Como um conjunto de dados mais geral usado em VSLAM, KITTI [57] é um conjunto de dados capturado por duas câmeras RGB e em escala de cinza de alta resolução em um veículo em movimento. KITTI usa sensores GPS e laser para fornecer informações precisas do solo, tornando-o um conjunto de dados muito popular em robótica móvel e direção autônoma.
TartanAir [58] é outro conjunto de dados padrão para avaliar algoritmos SLAM em cenas complexas.
Além disso, o conjunto de dados do Imperial College London e da National University of Ireland Maynooth (ICL-NUIM) [59] é outro conjunto de dados VO contendo sequências de câmeras RGB-D portáteis, que tem sido usado como benchmark para muitos SLAMs.
Ao contrário dos conjuntos de dados anteriores, alguns outros conjuntos de dados contêm dados adquiridos com câmeras específicas em vez de câmeras normais. Por exemplo, o conjunto de dados Event Camera introduzido por Mueggler et al. [60] é um conjunto de dados que usa amostras coletadas de câmeras baseadas em eventos para avaliação de robôs de alta velocidade. A instância do conjunto de dados contém medições inerciais e imagens de intensidade capturadas por um sistema de captura de movimento, tornando-o uma referência adequada para VSLAM equipado com câmeras de eventos.
Os conjuntos de dados acima são usados em vários métodos VSLAM, dependendo da configuração do sensor, aplicação e ambiente alvo. Esses conjuntos de dados contêm principalmente parâmetros de calibração de câmeras, bem como dados reais. A Tabela 1 e a Figura 3 mostram as características resumidas dos conjuntos de dados e alguns exemplos de cada conjunto de dados, respectivamente.


4.5 Camada semântica
Os robôs precisam de informações semânticas para compreender a cena circundante e tomar decisões mais favoráveis. Em muitos trabalhos recentes de VSLAM, adicionar informações semânticas a dados baseados em geometria é melhor do que abordagens puramente baseadas em geometria, permitindo fornecer mais informações sobre o ambiente circundante [61]. Nesse sentido, módulos de reconhecimento de objetos pré-treinados podem adicionar informações semânticas aos modelos VSLAM [62]. Uma das abordagens mais recentes é usar CNNs em aplicações VSLAM. Em geral, os métodos VSLAM semânticos consistem nos seguintes quatro componentes principais [43]:
Rastreamento: usa pontos característicos 2D extraídos de quadros de vídeo consecutivos para estimar a pose da câmera e construir uma nuvem de pontos do mapa 3D. O cálculo da pose da câmera e a construção da nuvem de pontos do mapa 3D estabelecem os dados de referência para o processo de localização e mapeamento, respectivamente.
Mapeamento local: Ao processar dois quadros de vídeo consecutivos, é criado um novo ponto de mapeamento 3D, que é usado em conjunto com o módulo BA para otimizar a pose da câmera.
Detecção de fechamento de loop: ajusta a pose da câmera e otimiza o mapa construído comparando quadros-chave com recursos visuais extraídos e avaliando a semelhança entre eles.
Culling de contexto não rígido (NRCC): O principal objetivo do uso do NRCC é filtrar objetos temporais de quadros de vídeo para reduzir seus efeitos adversos nos estágios de localização e mapeamento. Consiste principalmente em um processo de mascaramento/segmentação para separar várias instâncias instáveis em frames, como pessoas. Como o NRCC pode reduzir o número de pontos característicos a serem processados, a parte do cálculo é simplificada e um desempenho mais robusto é obtido.
Portanto, a exploração de camadas semânticas em métodos VSLAM pode otimizar a incerteza da estimativa de pose e da construção do mapa. No entanto, agora é um desafio utilizar corretamente a informação semântica extraída sem afetar grandemente o custo computacional.
05 Classificação dos métodos VSLAM com base nos objetivos da aplicação
A fim de encontrar com precisão os métodos VSLAM que podem alcançar excelentes resultados e ter uma arquitetura estável, coletamos e selecionamos publicações altamente citadas publicadas nos principais sites nos últimos anos do Google Scholar e das famosas bases de dados bibliográficas de ciência da computação Scopus e DBLP. Também estudamos os artigos mencionados nas publicações acima e selecionamos os mais relevantes para a área de VSLAM. Depois de pesquisar os artigos, podemos categorizar os artigos coletados de acordo com os problemas específicos que abordam principalmente, como segue:
5.1 Objetivo 1: Processamento Multissensor
Esta categoria abrange métodos VSLAM que utilizam vários sensores para compreender melhor o ambiente. Enquanto algumas tecnologias simplesmente usam câmeras como sensores, outras combinam vários sensores para melhorar a precisão dos algoritmos.
1) Usando múltiplas câmeras:
Como é difícil reconstruir a trajetória 3D de um objeto em movimento com uma câmera, alguns pesquisadores sugerem o uso de múltiplas câmeras. Por exemplo, CoSLAM 4 é um sistema VSLAM introduzido por Zou e Tan [63] que utiliza câmeras individuais implantadas em diferentes plataformas para reconstruir mapas robustos. Seu sistema integra múltiplas câmeras movendo-se independentemente em um ambiente dinâmico e reconstrói um mapa a partir de seus campos de visão sobrepostos. Esse processo facilita a reconstrução de nuvens de pontos dinâmicas em 3D, integrando estimativa e mapeamento de pose na câmera e entre câmeras. CoSLAM usa o algoritmo KanadeLucas-Tomasi (KLT) para rastrear recursos visuais e opera em ambientes internos/externos estáticos e dinâmicos onde as posições e orientações relativas podem mudar ao longo do tempo. A principal desvantagem desta abordagem é que é necessário hardware complexo para analisar a saída de dados por um grande número de câmeras, e o custo computacional aumenta devido à adição de mais câmeras.
Para cenários desafiadores na natureza, Yang et al.[64] desenvolveram um método VSLAM panorâmico colaborativo multicâmera. Sua abordagem exige que cada câmera seja independente para melhorar o desempenho dos sistemas VSLAM em condições difíceis, como oclusões e ambientes com textura esparsa. Para determinar o intervalo correspondente, eles extraem recursos ORB dos campos de visão sobrepostos das câmeras. Além disso, eles adotaram técnicas de aprendizagem profunda baseadas em CNN para identificar recursos semelhantes para detecção de fechamento de loop. Nos experimentos, os autores utilizaram um conjunto de dados gerado por uma câmera panorâmica e um sistema de navegação integrado.
MultiCol SLAM é outra estrutura VSLAM de código aberto de Urban e Hinz que usa uma configuração de múltiplas câmeras [65]. Usando seu modelo criado anteriormente, MultiCol, eles ampliam o ORB-SLAM com um processo baseado em quadro-chave que suporta múltiplas câmeras fisheye. Eles adicionaram um módulo de processamento multi-quadro-chave (MKF) ao ORB-SLAM, que coleta imagens que convertem imagens em quadros-chave. O autor também propõe a ideia de fechamento de loop multicâmera, onde o fechamento de loop é detectado no MKF. Embora seu método seja executado em tempo real, ele requer muito poder de computação, pois vários threads precisam ser executados simultaneamente.
2) Empregando vários sensores (usando vários sensores)
Algumas outras abordagens recomendam a fusão de vários sensores e o uso de saídas de sensores baseadas em visão e inerciais para melhor desempenho. A esse respeito, Zhu et al.[66] propuseram um VSLAM indireto assistido por lidar de baixo custo chamado CamVox 5 e demonstraram seu desempenho confiável e precisão. Sua abordagem usa ORB-SLAM 2.0, combinando Livox lidar como um sensor de profundidade avançado com a saída de uma câmera RGB-D. Os autores usaram uma IMU para sincronizar e corrigir posições de varredura não repetitivas. Sua contribuição é um método para calibração autônoma de câmeras lidar operando em um ambiente não controlado. Testes reais em plataformas robóticas mostraram que o CamVox opera em tempo real enquanto processa seu ambiente.
Os autores em [67] propuseram um sistema multimodal denominado VIRAL (Visual Inertial Ranging LiDAR) SLAM, que acopla uma câmera, LiDAR, IMU e UWB. Eles também propuseram um esquema de marginalização de correspondência de mapa de características visuais baseado em mapas locais construídos a partir de nuvens de pontos lidar. Os componentes visuais são extraídos e rastreados usando o algoritmo BRIEF. A estrutura também contém esquemas de sincronização e gatilhos para os sensores utilizados. Eles testaram seu método em um ambiente simulado e em um conjunto de dados gerado chamado NTU VIRAL [54], que contém dados capturados por câmeras, sensores LiDAR, IMU e UWB. No entanto, seu método é computacionalmente caro devido a lidar com sincronização, multithreading e conflitos de sensor.
Vidal et al.[42] propõem integrar câmeras de eventos, quadros de câmeras e IMUs em uma configuração paralela para estimativa confiável de pose em configurações de alta velocidade. Seu sistema Ultimate SLAM 6 é baseado em câmeras de eventos e em um thread de otimização não linear baseado em quadros-chave introduzido em [68]. Eles usam o detector de cantos FAST e o algoritmo de rastreamento Lucas Kanade para detecção e rastreamento de recursos, respectivamente. O Ultimate SLAM evita problemas de desfoque de movimento que acompanham atividades de alta velocidade e opera em ambientes dinâmicos com condições de iluminação variadas. A eficiência desta técnica no “Event Camera Dataset” é evidente quando comparada com outras configurações de câmeras de eventos puros e câmeras regulares. Os autores também testaram o Ultimate SLAM em um drone quadrotor autônomo equipado com uma câmera de evento para demonstrar como seu sistema lida com condições de voo que não podem ser tratadas por plataformas VO convencionais. O principal problema enfrentado pelo Ultimate SLAM é a sincronização de eventos e a saída de quadros padrão.
Nguyen et al. [69] propuseram uma abordagem de câmera monocular fortemente acoplada e sensor de distância UWB para VSLAM. Eles criam mapas usando uma combinação de pontos de referência baseados em recursos (visíveis) e sem recursos (UWB). Ele pode funcionar de forma eficaz quando o UWB sofre efeitos de múltiplos caminhos em ambientes lotados. Eles construíram um método indireto com base no ORB-SLAM e usaram recursos do ORB para estimativa de pose. Eles testaram seu sistema em um conjunto de dados que simula a coleta de dados por um robô aéreo usando meios manuais. A sincronização da câmera e do sensor UWB é uma grande dificuldade neste caso, mas isso foi superado usando uma nova pose de câmera com um timestamp associado para cada nova imagem.
5.2 Meta 2: Estimativa de pose
Este tipo de método concentra-se em como otimizar a estimativa de pose do VSLAM usando vários algoritmos.
1) Usando dados de linha/ponto:
Nesse sentido, Zhou et al.[70] propõem usar linhas de estrutura de construção como recursos úteis para determinar a pose da câmera. As linhas estruturais estão associadas a direções dominantes e codificam informações de direção global, melhorando as trajetórias previstas. O StructSLAM mencionado acima é uma tecnologia VSLAM de 6 graus de liberdade (DoF) que pode operar em condições baixas e sem recursos. Ele usa EKF para estimar variáveis com base na orientação atual da cena. Para avaliação, são usados o conjunto de dados de cenas internas do RAWSEEDS 2009 e um conjunto de conjuntos de dados de imagens sequenciais gerados.
Point and Line SLAM (PL-SLAM) é um sistema VSLAM baseado em ORB-SLAM proposto por Pumarola et al.[71], que é otimizado para cenas não dinâmicas e de baixa textura. O sistema combina recursos de linha e ponto simultaneamente para melhorar a estimativa de pose e ajudar a operar com menos pontos de recursos. Os autores testaram o PL-SLAM no conjunto de dados gerado e no TUM RGB-D. A desvantagem de sua abordagem é que ela é computacionalmente cara, enquanto outros elementos geométricos, como planos, são usados para maior precisão.
Gomez-Ojeda et al. [72] introduziram o PL-SLAM (diferente da estrutura de mesmo nome em Pumarola et al. [71]), uma técnica VSLAM indireta que utiliza pontos e linhas de câmeras de visão estéreo para reconstruir mapas invisíveis. Eles mesclam segmentos obtidos de ponto e linha em todos os módulos VSLAM com informações visuais obtidas de quadros consecutivos em seu método. Pontos e linhas são recuperados e rastreados em quadros estéreo subsequentes em PL-SLAM usando algoritmos ORB e Detector de Linha (LSD). Os autores testaram o PL-SLAM nos conjuntos de dados EuRoC e KITTI, que podem superar a versão estéreo do ORB-SLAM 2.0 em termos de desempenho. Uma das principais desvantagens do PL-SLAM é o tempo de cálculo exigido pelo módulo de rastreamento de características, e para extrair mais informações sobre o ambiente, quase todas as linhas da estrutura precisam ser percorridas.
Lim e outros [73] introduziram uma técnica de prevenção de degradação para VSLAM baseado em linha pontual de propósito único. Um poderoso módulo de rastreamento de linha baseado em fluxo óptico para extrair características de linha, filtrar linhas curtas em cada quadro e combinar características de linha previamente identificadas é outra contribuição de seu método. Para demonstrar a eficácia da sua técnica e demonstrar a sua superioridade sobre os métodos baseados em pontos estabelecidos, eles testaram o seu sistema no conjunto de dados EuRoC MAV. Apesar das inúmeras descobertas, este sistema carece de um método adaptativo para identificar os parâmetros de otimização corretos.
2) Use outras características:
Uma estrutura para câmeras de visão estéreo é proposta em [74]: Dual Quaternion Visual SLAM (DQV-SLAM), que usa uma estrutura Bayesiana para estimativa de pose 6-DoF. Para evitar a linearização de grupos de transformações espaciais não lineares, seu método utiliza atualização bayesiana progressiva. Para nuvens de pontos de mapas e fluxo óptico, o DQVSLAM usa recursos ORB para obter associação confiável de dados em ambientes dinâmicos. Nos conjuntos de dados KITTI e EuRoC, o método pode estimar com segurança os resultados experimentais. No entanto, falta-lhe uma interpretação probabilística para modelagem estocástica de poses e é computacionalmente exigente para filtragem baseada em aproximações de amostragem.
[75] desenvolveram uma técnica para reconstruir mapas de ambientes internos em grande escala usando marcadores planares quadrados artificiais. Seu sistema SPM-SLAM em tempo real pode usar os marcadores para resolver ambiguidades na estimativa de pose se pelo menos dois marcadores forem observáveis em cada quadro de vídeo. Eles criaram um conjunto de dados contendo sequências de vídeos de marcadores colocados em duas salas ligadas por uma porta. Embora o SPM-SLAM seja de bom valor, ele só é eficaz quando vários marcadores planares estão espalhados pela região e pelo menos dois marcadores estão disponíveis para reconhecimento de conexão de marcadores. Além disso, a capacidade da sua estrutura para lidar com mudanças dinâmicas na cena não é julgada.
3) Método de aprendizagem profunda
Bruno e Colombini [76] propuseram o LIFT-SLAM, que combina descritores de recursos baseados em aprendizagem profunda com sistemas tradicionais baseados em geometria. Eles estenderam o pipeline do sistema ORB-SLAM e usaram a CNN para extrair recursos de imagens, usando os recursos aprendidos para fornecer correspondências mais densas e precisas. Para detecção, descrição e estimativa de orientação, o LIFT-SLAM ajusta a rede neural profunda LIFT. Estudos usando instâncias internas e externas de conjuntos de dados KITTI e EuRoC MAV mostram que o LIFT-SLAM supera os esquemas VSLAM tradicionais baseados em recursos e em aprendizagem profunda em termos de precisão. No entanto, a desvantagem deste método é o seu threading computacionalmente intensivo e o design CNN não otimizado, o que obviamente também contribui para o seu desempenho quase em tempo real.
Naveed et al.[77] propuseram um esquema VSLAM baseado em aprendizagem profunda com módulos confiáveis e consistentes mesmo em problemas extremamente complexos. Seu método supera vários VSLAMs e usa redes de aprendizado por reforço profundo treinadas em simuladores reais. Além disso, eles fornecem uma base para avaliação ativa do VSLAM e podem ser generalizados adequadamente em ambientes reais internos e externos. O planejador de caminho de rede fornece dados de caminho ideal, que são recebidos por seu sistema subjacente ORB-SLAM. Eles produziram um conjunto de dados contendo problemas de navegação do mundo real em ambientes desafiadores e sem textura para avaliação.
RWT-SLAM é um framework VSLAM baseado na correspondência profunda de características proposta pelo autor em [78] para situações de textura fraca. Sua abordagem é baseada em ORB-SLAM, usando máscaras de recursos do algoritmo LoFTR aprimorado [79] para correspondência de recursos de imagens locais. Os descritores de nível grosseiro e de nível fino na cena são extraídos usando a arquitetura CNN e o algoritmo LoFTR, respectivamente. RWT-SLAM é testado em conjuntos de dados de cena TUM RGB-D e OpenLORIS, bem como em conjuntos de dados do mundo real coletados pelos autores. No entanto, apesar dos resultados robustos de correspondência de recursos e desempenho, seu sistema ainda é computacionalmente intensivo.
5.3 Objectivo Três: Viabilidade no Mundo Real
O principal objetivo de tais métodos é ser utilizado em diversos ambientes e funcionar em diversos cenários. Observamos que todos os métodos mencionados integram altamente as informações semânticas do ambiente e apresentam um VSLAM ponta a ponta.
1) Ambiente dinâmico
Nesse sentido, Yu et al.[61] introduziram um sistema VSLAM denominado DS-SLAM, que pode ser usado em ambientes dinâmicos e fornece informações semânticas para construção de mapas. O sistema é baseado em ORB-SLAM 2.0 e inclui cinco threads: rastreamento, segmentação semântica, mapeamento local, fechamento de loop e construção de mapa semântico denso. Para excluir itens dinâmicos e melhorar a precisão da localização antes do processo de estimativa de pose, o DS-SLAM emprega o algoritmo de fluxo óptico [80] com uma rede de segmentação semântica em tempo real SegNet. O DS-SLAM foi testado em ambientes reais, câmeras RGB-D e no conjunto de dados TUM RGB-D. Porém, apesar de sua alta precisão de localização, ainda enfrenta a limitação da segmentação semântica e as características de computação pesada.
O Semantic Optical Flow SLAM (SOF-SLAM) é um sistema VSLAM indireto baseado no modo RGB-D do ORBSLAM 2.0, que é outro método para ambientes altamente dinâmicos proposto por Cui e Ma [45]. Seu método usa um módulo de detecção de recursos dinâmicos de fluxo óptico semântico que extrai e ignora recursos dinâmicos ocultos nas informações semânticas e geométricas fornecidas pela extração de recursos ORB. Para fornecer informações precisas sobre a pose da câmera e o ambiente, o SOF-SLAM usa o módulo de segmentação semântica em nível de pixel do SegNet. Em situações altamente dinâmicas, os resultados experimentais no conjunto de dados TUM RGB-D e em ambientes reais mostram que o SOF-SLAM supera o ORB-SLAM 2.0. No entanto, métodos ineficazes para reconhecimento de características não estáticas e métodos que dependem apenas de dois quadros consecutivos são os pontos fracos do SOF-SLAM.
Cheng et al.[81] propuseram um sistema VSLAM para ambientes dinâmicos usando métodos de fluxo óptico para separar e eliminar pontos de características dinâmicas. Eles exploram a estrutura do ORB-SLAM e fornecem pontos de recursos fixos gerados a partir da saída típica de uma câmera monocular para uma estimativa precisa da pose. Na ausência de recursos, o sistema funciona classificando os valores do fluxo óptico e utilizando-os para reconhecimento de recursos. De acordo com os resultados experimentais do conjunto de dados TUM RGB-D, o sistema funciona bem em ambientes internos dinâmicos.
Yang et al.[82] publicaram outro esquema VSLAM que utiliza dados de rede semanticamente segmentados, técnicas de detecção de consistência de movimento e restrições geométricas para reconstruir mapas ambientais. Seu método, baseado na variante RGB-D do ORB-SLAM 2.0, funciona bem em ambientes dinâmicos e internos. Use a técnica aprimorada de extração de recursos ORB para manter apenas os recursos estáveis na cena, ignorando os recursos dinâmicos. O recurso e os dados semânticos são então combinados para criar um mapa semântico estático. Os resultados da avaliação nos conjuntos de dados Oxford e TUM RGB-D demonstram a eficácia de seu método na melhoria da precisão da localização e na criação de mapas semânticos com grandes quantidades de dados. Porém, seu sistema pode apresentar problemas em corredores ou locais com menos informações.
2) Soluções baseadas em aprendizagem profunda
Em outro trabalho chamado DXSLAM de Li et al.[83], o aprendizado profundo é usado para encontrar pontos-chave semelhantes aos SuperPoints e gerar descritores genéricos e pontos-chave para imagens. Eles treinaram uma CNN HF-NET mais forte para extrair informações locais e globais de cada quadro e gerar informações descritivas baseadas em quadros e pontos-chave. Eles também usam o método offline bag-of-words (BoW) para treinar um dicionário visual de recursos locais (vocabulário visual) para obter uma detecção precisa de fechamento de loop. O DXSLAM pode ser executado em tempo real sem o uso de unidades de processamento gráfico (GPUs) e é compatível com CPUs. Embora não seja particularmente enfatizado, tem uma forte capacidade de resistir a mudanças dinâmicas em ambientes dinâmicos. O DXSLAM foi testado em conjuntos de dados de cena TUM RGB-D e OpenLORIS, bem como em imagens internas e externas, e pode obter resultados mais precisos do que ORBSLAM 2.0 e DS-SLAM. No entanto, as principais desvantagens desta abordagem são a complicada arquitetura de extração de recursos e o problema de mesclar recursos profundos com estruturas SLAM antigas.
Li et al.[84] desenvolveram uma técnica VSLAM em tempo real para extrair pontos característicos com base em aprendizagem profunda em situações complexas. O método é uma CNN multitarefa auto-supervisionada para extração de recursos que pode ser executada em uma GPU e suporta a criação de mapas densos em 3D. A saída da CNN é uma string de código binário com comprimento fixo de 256, que permite que ela seja substituída por detectores de pontos de recurso mais tradicionais, como o ORB. Inclui três threads para desempenho preciso e oportuno em cenas dinâmicas: rastreamento, mapeamento local e detecção de fechamento de loop. Este esquema suporta ORB-SLAM 2.0 usando câmeras monoculares e RGB-D como linha de base. Os autores testaram-no no conjunto de dados TUM e em dois conjuntos de dados coletados por eles próprios (conjuntos de dados de corredor e escritório coletados com câmeras Kinect).
Steenbeek e Nex em [85] introduziram uma técnica VSLAM em tempo real que usa CNNs para análise precisa de cenas e reconstrução de mapas. A solução utiliza o fluxo da câmera monocular do drone durante o vôo, empregando uma rede neural de estimativa de profundidade para desempenho estável. O método acima é baseado no ORB-SLAM 2.0 e utiliza informações visuais coletadas do ambiente interno. Além disso, a CNN é treinada em mais de 48.000 casos internos e manipula pose, profundidade espacial e entradas RGB para estimar escala e profundidade. A avaliação do sistema usando o conjunto de dados TUM RGB-D e testes no mundo real com drones demonstra maior precisão na estimativa de pose. No entanto, o sistema teria dificuldades sem texturas, exigindo recursos de CPU e GPU para desempenho em tempo real.
3) Usando marcos artificiais
e Medina Carnicer desenvolveram uma técnica chamada UcoSLAM11] que supera os sistemas VSLAM tradicionais, combinando pontos de referência naturais e artificiais e usando marcadores fiduciais para calcular automaticamente a escala do ambiente circundante. O principal objetivo do UcoSLAM é resolver a instabilidade, repetibilidade e baixa qualidade de rastreamento de marcos naturais. Ele pode ser executado em ambientes sem sinalizadores de recurso, pois pode ser executado em modos somente chaves, somente sinalizadores ou mistos. Para descobrir a correspondência do mapa, otimizar o erro de reprojeção e realocar quando o rastreamento falhar, o UcoSLAM define o modo de rastreamento. Além disso, possui um sistema de detecção de fechamento de loop baseado em marcadores que pode ser caracterizado usando qualquer descritor, incluindo ORB e FAST. Embora o UcoSLAM tenha muitas vantagens, o sistema executa muitos threads, o que o torna um método demorado.
4) Ampla variedade de configurações
Outra estratégia VSLAM para ambientes internos e externos dinâmicos é o DMS-SLAM [87], que suporta sensores de visão monoculares, estéreo e RGB-D. O sistema emprega uma janela deslizante e um método de correspondência de recursos de estatísticas de movimento baseado em grade (GMS) [88] para encontrar locais de recursos estáticos. Baseado no sistema ORB-SLAM 2.0, o DMS-SLAM rastreia os recursos estáticos identificados pelo algoritmo ORB. Os autores testaram o método proposto nos conjuntos de dados TUM RGB-D e KITTI, e os resultados foram melhores que o algoritmo VSLAM, que sempre funcionou bem. Além disso, o DMS-SLAM tem um desempenho mais rápido que o ORB-SLAM 2.0 original devido à remoção de pontos característicos em objetos dinâmicos na etapa de rastreamento. Apesar das vantagens acima, este esquema sofre de dificuldades em ambientes menos texturizados, de movimento rápido e altamente dinâmicos.
5.4 Objetivo 4: Restrição de Recursos
Alguns métodos VSLAM são construídos para dispositivos com recursos computacionais limitados em comparação com dispositivos com condições ideais. É o caso, por exemplo, do VSLAM projetado para dispositivos móveis e robôs com sistemas embarcados.
1) Dispositivos com poder computacional limitado:
EdgeSLAM é um sistema VSLAM semântico assistido por borda em tempo real para dispositivos móveis e com recursos limitados, proposto por Xu et al.[89]. Ele emprega uma série de módulos refinados que são usados por servidores de borda e dispositivos móveis relacionados sem threads complexos. EdgeSLAM também inclui um módulo de segmentação semântica baseado na tecnologia de máscara RCNN para otimizar o efeito da segmentação e rastreamento de alvos. Os autores colocaram seu método em prática instalando alguns dispositivos móveis disponíveis comercialmente, como telefones celulares e placas de desenvolvimento, em um servidor de borda. Ao reutilizar os resultados da segmentação de objetos, eles adaptam os parâmetros do sistema a diferentes situações de largura de banda e latência da rede para evitar processamento repetido. EdgeSLAM foi avaliado em TUM RGB-D, instância de visão monocular do KITTI e conjuntos de dados criados para a configuração experimental.
Para câmeras estéreo, Schlegel, Colosi e Grisetti [90] propuseram uma estrutura VSLAM leve baseada em recursos, chamada ProSLAM, com resultados comparáveis a estruturas bem recebidas. Sua abordagem consiste em quatro módulos: um módulo de triangulação, que cria uma nuvem de pontos 3D e descritores de recursos associados; um módulo de estimativa de movimento incremental, que processa dois quadros para determinar a posição atual; um módulo de gerenciamento de mapas, que cria um mapa local; O O módulo de localização atualiza o mapa global com base na semelhança dos mapas locais. O ProSLAM recupera a pose 3D de um ponto usando um único thread e aproveita um pequeno número de bibliotecas conhecidas para criar um sistema simples. De acordo com experimentos em conjuntos de dados KITTI e EuRoC, seu método pode alcançar bons resultados. No entanto, é fraco na estimativa de rotação e não contém nenhum módulo BA.
Bavle et al.[91] propuseram o VPS-SLAM, uma estrutura VSLAM leve baseada em gráficos para robôs aéreos. Seu sistema em tempo real integra dados geométricos, técnicas de detecção de múltiplos objetos e VO/VIO para facilitar a estimativa de pose e construir um mapa semântico do ambiente. O VPS-SLAM usa recursos de baixo nível, medições IMU e informações planares de alto nível para reconstruir mapas semânticos esparsos e estimar estados do robô. O sistema utiliza You Only Look Once v2.0 (YOLO2) [92], uma versão leve baseada no conjunto de dados COCO [93], para detecção de objetos devido à sua eficiência computacional e em tempo real. Eles usaram uma câmera portátil e um robô aéreo equipado com uma câmera RGB-D para testes. Exemplos internos do conjunto de dados TUM RGB-D foram usados para testar seu método e foram capazes de fornecer os mesmos resultados que os métodos VSLAM conhecidos. No entanto, o seu sistema VSLAM só pode usar um pequeno número de objetos (como cadeiras, livros e laptops) para construir um mapa semântico da área circundante.
Tseng et al.[94] propuseram outro método VSLAM interno em tempo real que satisfaz a condição de baixa alocação. Os autores também propõem uma técnica para estimar o número de quadros e elementos visuais necessários para uma precisão de localização plausível. Seu esquema é baseado no framework OpenVSLAM [95] e o utiliza para situações emergentes que surgem no mundo real, como acessar objetos específicos. O sistema adquire mapas de recursos da cena aplicando algoritmos Efficient Perspective Point (EPnP) e RANSAC para estimativa precisa de pose. De acordo com os resultados dos testes internos, seu dispositivo pode obter resultados precisos em condições de pouca iluminação.
2) Descarregamento de computação
Ben Ali e outros [96] propuseram usar a computação de ponta para migrar operações com uso intensivo de recursos para a nuvem, a fim de reduzir a carga computacional sobre os robôs. Eles modificaram a arquitetura do ORB-SLAM 2.0 na estrutura indireta Edge SLAM 14, executaram o módulo de rastreamento no robô e migraram o restante para o dispositivo de computação de ponta. Ao dividir o pipeline VSLAM entre robôs e dispositivos de borda, o sistema pode manter mapas locais e globais. Com menos recursos, eles ainda podem funcionar corretamente sem sacrificar a precisão. Eles realizaram avaliações usando o conjunto de dados TUM RGB-D e dois conjuntos de dados específicos de ambiente interno coletados usando diferentes dispositivos móveis equipados com câmeras RGB-D. No entanto, uma das desvantagens da sua abordagem é o aumento da complexidade arquitectónica devido ao desacoplamento de vários módulos SLAM. Outro problema é que seus sistemas funcionam bem apenas por curtos períodos de tempo, enquanto o uso do Edge SLAM em cenários de longo prazo (por exemplo, vários dias) degrada o desempenho.
5.5 Objetivo Cinco: Versatilidade
O trabalho do VSLAM nesta categoria centra-se na exploração, aproveitamento, adaptação e extensão simples.
Sumikura et al.[95] propuseram o OpenVSLAM, que é uma estrutura VSLAM de código aberto adaptável, usada principalmente para desenvolvimento rápido e também pode ser chamada por programas de terceiros. Sua abordagem baseada em recursos é compatível com vários tipos de câmeras, incluindo monocular, estéreo e RGB-D, e os mapas reconstruídos podem ser armazenados ou reutilizados para uso posterior. Devido ao seu poderoso módulo extrator de recursos ORB, OpenVSLAM supera ORB-SLAM e ORB-SLAM2.0 em termos de precisão e eficiência de rastreamento. No entanto, o código aberto do sistema foi descontinuado devido a preocupações sobre a similaridade de código que infringe o ORB-SLAM 2.0.
Para preencher a lacuna entre tempo real, precisão e elasticidade, Ferrera et al.[97] desenvolveram um método que funciona com câmeras de visão monocular e estéreo. Isso reduz a computação, restringindo a extração de recursos a quadros-chave e monitorando-os em quadros subsequentes, eliminando erros fotométricos. Neste sentido, trata-se de um esquema híbrido que combina as vantagens do método direto e do método indireto do algoritmo VSLAM. Usando conjuntos de dados de referência bem conhecidos, incluindo EuRoC, KITTI e TartanAir em experimentos internos e externos, foi demonstrado que ele supera vários esquemas convencionais em termos de desempenho e precisão.
Teed e Deng propuseram outro método chamado DROID-SLAM, que é um SLAM visual baseado em aprendizado profundo para câmeras monoculares, estéreo e RGB-D [98]. Eles podem alcançar maior precisão e robustez do que os métodos bem conhecidos de rastreamento monocular e estéreo. Seu esquema pode ser executado em tempo real, incluindo threads de backend (para BA) e frontend (para coleta de quadros-chave e otimização de gráficos). O DROID-SLAM já foi treinado com instâncias de câmera monocular, portanto não há necessidade de treinar novamente com entradas estéreo e RGB-D. Assim como o método indireto, este método minimiza erros de projeção enquanto não requer nenhum pré-processamento para reconhecimento e correspondência de recursos. Uma rede de extração de recursos, incluindo camadas de redução da resolução e blocos residuais, processa cada imagem de entrada para criar recursos densos. O DROID-SLAM foi testado em conjuntos de dados bem conhecidos, incluindo TartanAir, EuRoC e TUM RGB-D, e alcançou resultados aceitáveis.
Bonetto et al. [99] propuseram o iRotate, uma técnica ativa para robôs omnidirecionais baseada em câmeras RGB-D. Além disso, um módulo é configurado em seu método para localizar obstáculos dentro do campo de visão da câmera. O principal objetivo do iRotate é reduzir a distância necessária para os robôs mapearem seus ambientes, fornecendo resultados de pesquisas de locais inexplorados, bem como de locais visitados anteriormente. O método acima usa uma estrutura VSLAM com recursos gráficos como backend. Ao comparar robôs omnidirecionais de três rodas simulados e reais, os autores podem obter os mesmos resultados que os métodos VSLAM convencionais. A principal desvantagem desta abordagem é que o robô pode enfrentar uma situação start-stop para replanejamento parcial do caminho.
5.6 Meta Seis: Odômetro Visual
Tais métodos visam obter a maior precisão possível na determinação da pose do robô.
1) Rede neural profunda
Uma estrutura SLAM dinâmica foi proposta em [100], que utiliza aprendizado profundo para estimativa precisa de pose e compreensão adequada do ambiente. Como parte da otimização do módulo de nível semântico do VO, os autores usam a CNN para reconhecer objetos em movimento no ambiente, o que os ajuda a reduzir o erro de estimativa de pose causado pela correspondência incorreta de recursos. Além disso, o Dynamic SLAM usa um módulo de rastreamento seletivo para ignorar posições dinâmicas na cena e um algoritmo de correção de recursos ausentes para obter invariância de velocidade em quadros adjacentes. Embora os resultados sejam bons, devido ao número limitado de classes semânticas definidas, o sistema requer um enorme custo computacional e corre o risco de classificar erroneamente objetos dinâmicos/estáticos.
Bloesch et al.[101] propuseram a técnica direta Code-SLAM, que fornece uma representação condensada e densa da geometria da cena. Seu sistema VSLAM é uma versão aprimorada do PTAM [14], que depende apenas de uma câmera monocular para funcionar. Eles dividiram a imagem de intensidade em recursos convolucionais e a alimentaram em um autoencoder profundo usando uma CNN treinada em imagens de intensidade do conjunto de dados SceneNet RGB-D. Instâncias internas do conjunto de dados EuRoC foram usadas para testar o Code-SLAM e os resultados são promissores em termos de precisão e desempenho.
Wang et al.propuseram DeepVO, uma estrutura VO ponta a ponta usando uma arquitetura de rede neural convolucional recorrente profunda (RCNN) para a configuração monocular. Seu método usa aprendizado profundo para aprender automaticamente recursos apropriados, modelar dinâmicas e relacionamentos sequenciais e inferir poses diretamente de quadros coloridos. A arquitetura DeepVO consiste em uma CNN chamada FlowNet (que pode calcular o fluxo óptico em quadros sucessivos) e duas camadas de Long Short-Term Memory (LSTM) (usadas para estimar mudanças temporais com base nos feeds fornecidos pela CNN). Esta estrutura pode extrair simultaneamente recursos visuais e realizar modelagem sequencial combinando CNN e rede neural recorrente (RNN). DeepVO pode combinar informações geométricas com modelos de conhecimento aprendidos para VO aprimorado. No entanto, não pode ser usado para substituir os métodos tradicionais de VO baseados em geometria.
Parisotto et al.[103] propuseram um sistema ponta a ponta semelhante ao DeepVO, usando uma etapa de Otimização de Gráfico Neural (NGO) em vez de LSTM. Sua abordagem realiza detecção e correção de fechamento de loop com base em diferentes poses em um tempo uniforme. A ONG usa dois métodos de otimização de atenção para otimizar conjuntamente as estimativas agregadas feitas pelas camadas convolucionais do módulo de estimativa de pose local e fornecer uma estimativa de pose global. Eles experimentaram sua técnica em labirintos 2D e 3D e superaram os níveis de desempenho e precisão do DeepVO. O método acima precisa estar conectado à estrutura SLAM para fornecer o sinal de relocalização.
Em outro trabalho, Czarnowski et al.[104] introduziram a estrutura VSLAM mais comum chamada DeepFactors, que é usada principalmente para reconstrução densa de mapas ambientais a partir de câmeras monoculares. Para reconstruir o mapa de forma mais estável, sua solução em tempo real usa dados probabilísticos combinados com aprendizagem e métodos baseados em modelos para otimização conjunta de pose e profundidade. Os autores modificaram a estrutura CodeSLAM e adicionaram componentes ausentes, como detecção de fechamento de loop local/global. Após o treinamento em cerca de 1,4 milhão de imagens ScanNet [105], o sistema é avaliado nos conjuntos de dados ICL-NUIM e TUM RGB-D. DeepFactors aprimora a ideia do framework CodeSLAM e foca na otimização de código no SLAM Pipeline tradicional. Porém, devido ao custo computacional dos módulos, esta abordagem requer o uso de GPUs para garantir desempenho em tempo real.
2) Processamento profundo entre quadros
Em outro trabalho, os autores de [106] desenvolveram um método SLAM denso em tempo real para câmeras RGB-D, reduzindo erros fotométricos e geométricos entre duas imagens para detecção de movimento da câmera, melhorando seus métodos existentes. Sua solução baseada em quadros-chave aumenta o Pose SLAM (que retém apenas poses não redundantes para gerar mapas densos), adiciona recursos de odometria visual densos e utiliza com eficiência informações dos quadros da câmera para estimativa estável do movimento da câmera. Os autores também empregam uma técnica baseada em entropia para calcular a similaridade de quadros-chave para detecção de fechamento de loop e prevenção de desvios. No entanto, sua abordagem ainda precisa de trabalho na detecção de fechamento de loop e na qualidade da seleção de quadros-chave.
Em outro trabalho apresentado por Li et al., um método VSLAM baseado em recursos (chamado DP-SLAM) é usado para obter a remoção dinâmica de objetos em tempo real. O método usa um modelo de propagação Bayesiano que se baseia na probabilidade de pontos-chave derivados de objetos em movimento. DP-SLAM pode usar algoritmo de propagação de probabilidade móvel e atualização iterativa de probabilidade para superar restrições geométricas e alterações semânticas de dados. Ele é integrado ao ORB-SLAM 2.0 e testado no conjunto de dados TUM RGB-D. Apesar dos resultados precisos, o sistema funciona apenas em VSLAM esparso e enfrenta alto custo computacional devido aos módulos iterativos de atualização probabilística.
O sistema de navegação indoor Pair Navi proposto por Dong et al., reutiliza os caminhos previamente rastreados por um agente para uso futuro por outros agentes. Assim, o robô móvel anterior, denominado líder, captura informações de rastreamento, como curvas e informações específicas do ambiente, e as fornece ao próximo robô móvel (seguidor) que precisa ir para o mesmo destino. Enquanto o seguidor utiliza o módulo de relocalização para determinar sua posição em relação à trajetória de referência, o líder combina os módulos de odometria visual e de criação de trajetória. Para identificar e remover objetos dinâmicos do conjunto de recursos de vídeo, o sistema emprega uma CNN baseada em região mascarada (Mask R-CNN). Eles testaram o Pair-Navi em um conjunto de dados coletados de vários smartphones.
3) Processamento de vários recursos
Outra abordagem nesta categoria é um sistema VSLAM baseado em texto denominado TextSLAM, proposto por Li et al. Ele incorpora itens de texto recuperados da cena usando a técnica de detecção de canto FAST no SLAM Pipeline. Os itens de texto incluem várias texturas, padrões e semânticas, fazendo com que o método os utilize de forma mais eficaz para criar mapas de texto 3D de alta qualidade. TextSLAM usa itens de texto como marcadores visuais estáveis, parametriza-os após o primeiro quadro onde os itens de texto são encontrados e, em seguida, projeta os objetos de texto 3D na imagem de destino para localização novamente. Eles também propõem uma nova técnica de parametrização de três variáveis para inicializar recursos instantâneos de itens de texto. Usando uma câmera monocular e um conjunto de dados criado pelos autores, foram realizados experimentos em ambientes internos e externos, e os resultados foram muito precisos. Operar em um ambiente sem texto, interpretar cartas curtas e precisar armazenar grandes dicionários de texto são os três desafios fundamentais do TextSLAM.
Xu et al.[43] propuseram um sistema VSLAM indireto baseado em ORB-SLAM melhorado, que utiliza um método de mapeamento de grade de ocupação (OGM) e um novo módulo de mapeamento 2D para obter localização de alta precisão e interação do usuário. Seu sistema pode usar OGM para reconstruir um mapa do ambiente, exibindo a presença de obstáculos como campos variáveis igualmente espaçados, permitindo navegação contínua em tempo real enquanto planeja uma rota. A inspeção experimental dos conjuntos de dados gerados mostra sua função de proximidade sob negação do GPS. No entanto, a sua técnica tem dificuldade em funcionar bem em ambientes dinâmicos e complexos, e tem dificuldade em combinar adequadamente características em corredores e condições sem características.
Ma et al propuseram o método CPA-SLAM, um método VSLAM direto para câmeras RGB-D que utiliza planos para rastreamento e otimização de gráficos. O alinhamento quadro-a-quadro-chave e quadro-a-plano são regularmente integrados em sua tecnologia. Eles também introduzem um algoritmo de alinhamento de imagem para rastrear o alinhamento do quadro-chave de referência da câmera e da imagem plana. Os dados do quadro-chave são usados pelo CPA-SLAM para encontrar o menor tempo e distância geográfica para rastrear. O desempenho em tempo real do sistema de rastreamento do sistema é testado com e sem configuração planar e analisado nos conjuntos de dados TUM RGB-D e ICL-NUIM, bem como em cenas internas e externas. No entanto, suporta apenas um pequeno número de geometrias, nomeadamente planos.
06 Tendências de Pesquisa
6.1 Estatísticas
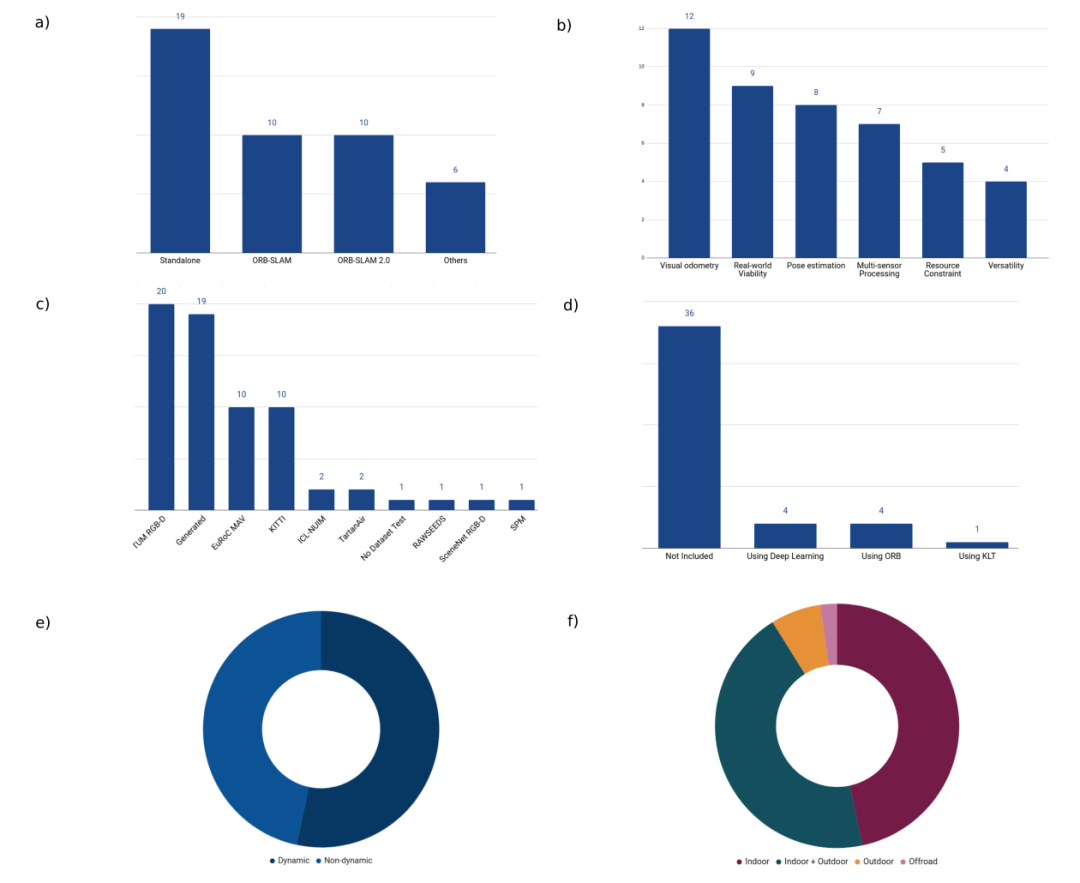
Em relação à classificação dos vários artigos de revisão mencionados acima, visualizamos os dados processados na Figura 4 para descobrir a tendência atual do VSLAM. Na subfigura “a”, podemos ver que a maioria dos sistemas VSLAM propostos são aplicações autônomas que implementam todo o processo de localização e mapeamento do zero usando sensores de visão. Embora ORB-SLAM 2.0 e ORB-SLAM sejam as plataformas básicas usadas para construir a nova estrutura, o método de minimização é baseado em outros sistemas VSLAM, como PTAM e PoseSLAM. Além disso, em termos de objetivos VSLAM, o mais importante na subfigura “b” é o módulo de odometria visual aprimorado. Portanto, a maioria dos VSLAM recentes tenta resolver os problemas dos algoritmos atuais na determinação da posição e orientação do robô. A estimativa de pose e a capacidade de sobrevivência no mundo real são outros objetivos fundamentais para a apresentação de novos artigos VSLAM. Em relação aos conjuntos de dados utilizados para avaliação nos artigos pesquisados, a subparcela “c” ilustra que a maior parte do trabalho foi testada no conjunto de dados TUM RGB-D. Este conjunto de dados foi usado como linha de base principal ou uma das várias linhas de base avaliadas em artigos pesquisados. Além disso, muitos pesquisadores tendem a realizar experimentos nos conjuntos de dados que geram. Podemos assumir que a principal motivação para gerar o conjunto de dados é demonstrar como o método VSLAM funciona em cenários reais e se pode ser utilizado como uma aplicação ponta a ponta. EuRoC MAV e KITTI são os próximos conjuntos de dados de avaliação populares no trabalho VSLAM, respectivamente. Outra informação interessante extraída da subfigura “d” diz respeito ao impacto do uso de dados semânticos quando se utiliza um sistema VSLAM. Podemos perceber que a maioria dos artigos pesquisados não inclui dados semânticos quando se trata de ambientes. Nossa hipótese é que as razões para não usar dados semânticos são:
-
Em muitos casos, treinar um modelo para reconhecer objetos e usá-lo para segmentação semântica é computacionalmente caro, o que pode aumentar o tempo de processamento.
-
A maioria dos esquemas VSLAM baseados em geometria são projetados como dispositivos plug-and-play, para que possam usar o mínimo possível de dados de câmera para localização e mapeamento.
-
A desinformação extraída da cena também pode adicionar mais ruído ao processo.
Ao considerar o ambiente, podemos observar na subfigura “e” que mais da metade dos métodos também podem funcionar em ambientes dinâmicos com condições desafiadoras, enquanto o restante dos sistemas foca apenas em ambientes sem alterações dinâmicas. Além disso, na subfigura “f”, a maioria dos métodos são aplicáveis a “ambiente interno” ou “ambiente interno e externo”, enquanto o restante dos artigos são testados apenas em condições externas. Deve-se mencionar que métodos que funcionam apenas em casos específicos podem não produzir a mesma precisão se utilizados em outros cenários. Esta é uma das principais razões pelas quais alguns métodos se concentram apenas em casos específicos.
6.2 Análise de Tendências
A pesquisa atual analisa os métodos SLAM visuais mais recentes e amplamente atraídos e ilustra suas principais contribuições neste campo. Embora tenha havido uma ampla gama de soluções estáveis e melhorias nos vários módulos do sistema VSLAM nos últimos anos, ainda existem muitas áreas de alto potencial e problemas não resolvidos, e a pesquisa nessas áreas trará mais benefícios para o futuro desenvolvimento de SLAM.método estável. Dado o grande número de métodos SLAM visuais, discutimos aqui as áreas de tendência atuais e apresentamos as seguintes direções de pesquisa abertas:
Aprendizado profundo: Redes neurais profundas têm mostrado resultados interessantes em diversas aplicações, incluindo VSLAM [15], tornando-as uma tendência importante em diversos campos de pesquisa. Devido à sua capacidade de aprendizado, essas arquiteturas têm mostrado um potencial considerável para serem usadas como extratores de recursos decentes para problemas de VO e detecção de fechamento de loop. A CNN pode ajudar o VSLAM na detecção precisa de objetos e segmentação semântica, e pode superar os algoritmos tradicionais de extração de recursos e correspondência na identificação correta de recursos feitos à mão. Deve-se mencionar que, como os métodos baseados em aprendizagem profunda são treinados em conjuntos de dados com uma grande quantidade de dados diversos e classes de objetos limitadas, há sempre o risco de classificar incorretamente pontos dinâmicos e levar a uma segmentação incorreta. Portanto, pode levar a menor precisão de segmentação e erro de estimativa de pose.
Equilíbrio entre recuperação de informações e custo computacional: Em geral, o custo de processamento e a quantidade de informações em uma cena devem estar sempre equilibrados. Dessa perspectiva, mapas densos permitem que aplicações VSLAM registrem informações completas da cena em alta dimensão, mas a execução em tempo real seria computacionalmente intensiva. Por outro lado, apesar de serem menos dispendiosas computacionalmente, representações esparsas não serão capazes de capturar todas as informações necessárias. Deve-se notar também que o desempenho em tempo real está diretamente relacionado à taxa de quadros da câmera, e a perda de quadros no pico do tempo de processamento pode impactar negativamente o desempenho de um sistema VSLAM, independentemente do desempenho do algoritmo. Além disso, o VSLAM geralmente utiliza módulos fortemente acoplados, e a modificação de um módulo pode afetar negativamente outros módulos, o que torna a tarefa de balanceamento mais desafiadora.
Segmentação Semântica: Fornecer informações semânticas durante a criação de um mapa do ambiente pode trazer informações muito úteis para os robôs. O reconhecimento de objetos (por exemplo, portas, janelas, pessoas, etc.) no campo de visão da câmera é um tema importante no trabalho VSLAM atual e futuro, pois informações semânticas podem ser usadas na estimativa de pose, planejamento de trajetória e módulos de detecção de fechamento de loop. Com o uso generalizado de algoritmos de detecção e rastreamento de objetos, o Semantic VSLAM será, sem dúvida, uma das soluções futuras neste campo.
Detecção de fechamento de loop: Qualquer sistema SLAM tem um problema chave: desvio e perda de trajetórias características devido a erros de localização acumulados . A detecção de desvio e a detecção de fechamento de loop precisam identificar informações de localização visitadas anteriormente, o que leva a um alto atraso computacional e custo para VSLAM [89]. A principal razão é que a complexidade da detecção de fechamento de loop aumenta com o tamanho da reconstrução do mapa. Além disso, combinar dados de mapas coletados em diferentes locais e refinar a pose estimada é uma tarefa muito complexa. Portanto, a otimização e o equilíbrio do módulo de detecção de fechamento de loop têm grande potencial de otimização. Uma das abordagens comuns para detecção de fechamento de loop é otimizar a recuperação de imagens treinando um dicionário visual baseado em recursos locais e depois agregando-os.
Problemas especiais da cena: trabalhar em um ambiente sem texturas, com poucos pontos característicos distintos, o que muitas vezes leva a erros de desvio na posição e orientação do robô. Sendo um dos principais desafios do VSLAM, este erro pode levar à falha do sistema. Portanto, será um tema importante considerar métodos complementares de compreensão de cena, como detecção de objetos ou características de linha, dentro de abordagens baseadas em características.
07 Conclusão
Este artigo apresenta uma família de esforços SLAM nos quais os dados visuais coletados de câmeras desempenham um papel importante. Categorizamos o trabalho recente sobre abordagens de sistemas VSLAM de acordo com várias propriedades, como configuração experimental, domínio inovador, algoritmo de detecção e rastreamento de objetos, camada semântica, desempenho, etc. Também revisamos as principais contribuições de trabalhos relacionados, bem como as armadilhas e desafios existentes em termos de perspectivas do autor, otimizações para versões futuras e questões abordadas em outros métodos relacionados. Outra contribuição do artigo é a discussão das tendências atuais nos sistemas VSLAM e questões em aberto que os pesquisadores irão investigar mais profundamente.
—— Recomendação maravilhosa——
-
Visão geral 4D | Percepção de fusão multissensor para direção autônoma
-
Todo o processo de posicionamento e navegação autônomo do robô baseado em SLAM
