Se a IA de grandes modelos como o ChatGPT é a coisa mais quente, os modelos mundiais são a bandeira.
Dois dos três pesquisadores de IA mais influentes da história, Yann LeCun e Yoshua Bengio, foram aclamados como o caminho mais provável para a superinteligência de IA, representando uma visão de IA que não aprendemos sobre nosso mundo não por força bruta ou aprendizado mecânico ( como ChatGPT), mas formando representações abstratas dele, a maneira como os humanos pensam.
Nesta narrativa, a Arquitetura de Previsão de Incorporação Conjunta Baseada em Imagem (I-JEPA) construída pela Meta torna-se o primeiro sucesso tangível na concretização desta visão.
Requer dez vezes menos recursos e não requer truques humanos para ajudar as máquinas a compreender os conceitos mais simples do nosso mundo, dando-nos um vislumbre de um futuro onde a inteligência artificial aprenderá da mesma forma que os humanos.
Muito se tem falado sobre o GPT-4 e seu potencial para ser o primeiro precursor da AGI (Inteligência Geral Artificial), ou o momento em que a vida de IA superinteligente e senciente nasce em nosso mundo.
Mas quão inteligente é o GPT-4?
“Não é tão bom quanto um cachorro ”, diz o cientista-chefe da Meta, Yann LeCun .
Mas como pode um modelo que consegue imitar Shakespeare impecavelmente ser considerado estúpido?
por exemplo, condução autônoma
Pense em aprender a dirigir um carro.
Em média, uma pessoa leva cerca de 20 horas para aprender a fazer isso corretamente.
Os sistemas de condução autónoma, por outro lado, requerem milhares de horas de treino e milhares de milhões de pontos de dados, mas são menos capazes de conduzir do que os humanos.
Então, como é que nós, humanos, aprendemos de uma forma mais eficiente do que os nossos modelos de última geração?
A razão para isso pode ser o modelo mundial, uma teoria que recentemente ganhou popularidade na comunidade científica.
Um modelo mundial é uma representação abstrata do mundo criada pelo cérebro humano para ajudar os humanos a interagir e essencialmente sobreviver em seu ambiente.
Estes modelos mundiais têm um conceito-chave: são capazes de prever acontecimentos imprevistos para ajudar a orientar as nossas ações e minimizar a possibilidade de ferimentos ou morte.
Em outras palavras, presume-se que sejam o que chamamos de “senso comum ”, um senso que nos ajuda a pensar sobre quais decisões são melhores em cada etapa de nossas vidas.
Se há uma coisa que está clara sobre grandes modelos como o ChatGPT é que, a partir de hoje, eles carecem totalmente de bom senso.
Os cães lhe mostrarão o porquê.
Cães e GPT
Comparando o ChatGPT com o que Yann fez com cães, podemos ver claramente como os métodos de aprendizagem são diferentes.
Por exemplo, um cachorro sabe que pular de uma varanda do terceiro andar não é a melhor ideia em termos de sobrevivência, mesmo que esse cachorro nunca tenha experimentado como seria pular de tal altura.
Porém, para treinar um robô de IA, é necessário convencê-lo a pular, fazendo-o entender que, para manter sua integridade, ele deve evitar pular de grandes alturas.
No entanto, os cães, assim como os humanos, devem enfrentar decisões na vida, sem possibilidade de julgamento e sem espaço para erros.
Nesse caso, o bom senso entra em jogo e salva o dia, dizendo “se você pular, não verá no dia seguinte” , eliminando a incerteza.
Mas o que isso realmente significa?
Muito simplesmente, ao contrário dos modelos de última geração de hoje, não precisamos de aprender tudo por tentativa e erro.
Na verdade, grande parte do nosso aprendizado vem da observação parcial do mundo.
Em nenhum lugar isso é mais evidente do que em nossos eus mais jovens, bebês.
sugerindo a causa a partir da observação
O gráfico abaixo mostra o tempo médio que os bebês levam para aprender uma série de conceitos humanos básicos:

Como Yann explicou em seu primeiro artigo sobre o tema , o gráfico acima mostra em que idade os bebês normalmente adquirem vários conceitos sobre como o mundo funciona.
É consistente com a ideia de que conceitos abstratos (como o facto de os objetos estarem sujeitos à gravidade e à inércia) são adquiridos em cima de conceitos não abstratos (como a persistência de objetos e a atribuição de objetos a categorias amplas).
O conceito-chave aqui é que a maior parte do conhecimento é adquirida principalmente através da observação, com pouca intervenção direta, especialmente nas primeiras semanas e meses.
Assim, podemos ver claramente o que falta à IA de última geração: a capacidade de aprender eficazmente através da observação, permitindo-lhe criar raízes no nosso mundo e ajudá-la a superar as incertezas que a regem.
Em termos leigos, criar um modelo mundial para uma IA é dar-lhe bom senso.
Então, como a Meta pretende capacitar a inteligência artificial de forma mais poderosa?
modelo de mundo artificial
Se você perguntasse ao cientista-chefe de IA da Meta como seria a inteligência autônoma, ele lhe mostraria este diagrama:

Fonte: Yann LeCun
Não vou entrar em detalhes, mas basicamente o que você precisa entender é que o modelo mundial faz duas coisas:
- Estimar informações faltantes sobre o estado do mundo não fornecidas pelo módulo de percepção (dados sensoriais recebidos do mundo como entrada)
- Preveja possíveis estados futuros do mundo
Por outras palavras, é um elemento necessário para ajudar os sistemas de IA (grandes modelos ou não) a tomar melhores decisões que assumem que o mundo tem resultados incertos que o modelo precisa de resolver para sobreviver.
Seu sistema baseado em ChatGPT pode ser capaz de escrever como a maioria dos humanos, mas também é capaz de fazer as suposições mais idiotas já feitas, simplesmente porque eles não entendem inerentemente o nosso mundo; eles apenas aprenderam a imitar a linguagem.
Por exemplo, se tomarmos MidJourney como exemplo, até recentemente esse modelo de texto para imagem tinha sérios problemas com mãos humanas porque quase sempre adicionava/perdia um número aleatório de dedos em cada mão que desenhava.
A razão é óbvia.
Embora fosse capaz de gerar desenhos e fotos impressionantes, não entendia naturalmente o que estava desenhando.
É um paradigma paradoxal onde a IA pode mapear as coisas da melhor forma, mas não consegue entender o que está desenhando.
É assim que você entende a vida? claro que não.
Você acabou de aprender o que é uma mão, aprendeu a representação abstrata das mãos, o que é suficiente para reconhecê-las e saber que geralmente têm cinco dedos.
Porém, a máquina precisa analisar cada pixel da imagem para chegar a uma conclusão, e de todos esses milhares de pixels, um certo número deles está agrupado de uma forma que representa uma mão, que geralmente tem cinco dedos.
Assim, para evitar uma infinidade de erros como o problema dos dedos, os modelos são alimentados com tantos dados que se tornam imitadores incríveis.
Mas há claramente uma lacuna de conhecimento aqui porque é aprendido mecanicamente.
Mas o I-JEPA é o primeiro modelo que realmente se assemelha à forma como aprendemos.
Modelo I-JEPA
O I-JEPA é a primeira tentativa de fazer com que a inteligência artificial aprenda representações complexas e abstratas do nosso mundo.
Com muito pouco treinamento (como os humanos precisariam), um modelo de IA deveria ser capaz de ver um cachorro em qualquer situação possível e ainda assim entender que se trata de um cachorro.
Para tanto, o I-JEPA possui a seguinte arquitetura:
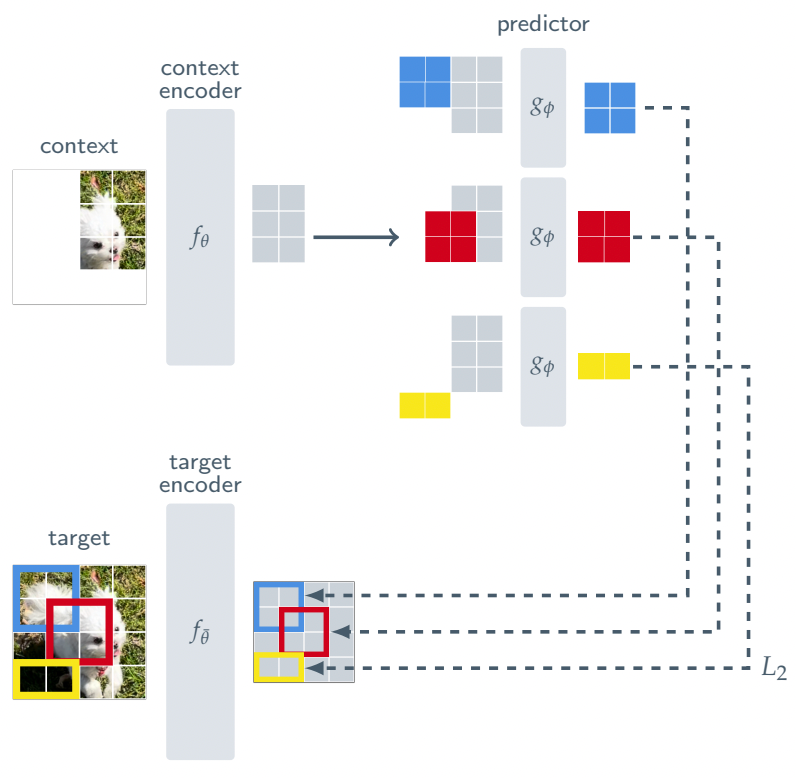
Em vez de tentar reconstruir cada pixel de uma imagem como fazem os modelos generativos de hoje, forçando-os a examinar cada pixel durante o treinamento, o I-JEPA analisa apenas uma pequena parte da imagem e é treinado para prever outros blocos na representação da imagem Imagem (indicada pela cor acima).
Dessa forma, em vez de reconstruir imagens completas repetidamente para esconder lacunas cada vez mais profundas na compreensão, o modelo é impedido de ver observações completas dos objetos que precisa aprender, forçando-o a realmente compreender a semântica por trás deles .
Mais importante ainda, o I-JEPA pode prever representações ausentes desses patches. Em termos leigos, isso significa que é preciso evitar detalhes desnecessários e focar em entender o que é realmente importante na imagem, ou ela irá falhar.
Além do mais, ao expor modelos a visões parcialmente observáveis da realidade, você pode treinar esses modelos para lidar com a incerteza.
Por exemplo, se você vir o rosto do seu cachorro escondido do lado de fora da porta do seu quarto, você não precisa ver o cachorro inteiro para saber que ele está lá, porque mesmo que você consiga ver apenas metade do rosto dele, você desenvolveu. resumo que o resto do corpo do cachorro também está lá.
Se você treinar um modelo para detectar cães, mas não incluir milhares de imagens recortadas de cães em seu conjunto de dados, ele falhará terrivelmente.
Mesmo com eles, os resultados não são, na melhor das hipóteses, ruins, porque para este modelo isso não é um cachorro, porque sua representação semântica não é boa o suficiente, embora seja obviamente boa o suficiente.
abstração é inteligência
A ideia desse modelo de mundo foi crescendo em minha mente.
Não há dúvida de que treinar sistemas de IA para compreender verdadeiramente o que vêem, lidando com as incertezas criadas por observações parciais, é um próximo passo inegável na nossa busca pela inteligência artificial geral.
Também ajuda o fato de que o I-JEPA basicamente supera quase todos os outros modelos de classificação de imagens do setor, com dez vezes mais requisitos de treinamento.
Mas a chave aqui não é o resultado, mas a visão que a Meta está tentando alcançar com o I-JEPA.
Como o I-JEPA tem uma compreensão mais profunda do que vê, não precisa de milhões de imagens e de tempo de treinamento para entender o que vê... como um ser humano faz.
Não creio que grandes modelos, modelos que aprendem sobre o nosso mundo lendo textos que o descrevem, sejam o caminho para a superinteligência.
Mas se conseguirmos incorporar o modelo mundial no modelo maior... isso é outra história.
Meta e I-JEPA começaram a liderar o caminho.