Diretório de artigos
Crie seu próprio conjunto de dados VOC
Primeiro, armazene as imagens e arquivos .xml no conjunto de dados VOC de acordo com o seguinte formato de pasta.

Minhas pastas de conjunto de dados em todos os níveis são mostradas na figura:
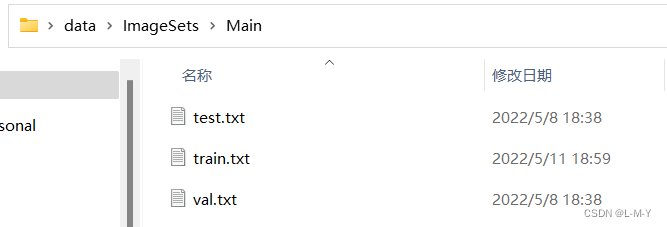
Gerar arquivo de nome do conjunto de dados
O train.txt armazena os nomes de todas as imagens do conjunto de dados (observe, é o nome sem o nome do sufixo !!!)

Conforme mostrado na figura, existem vários arquivos .jpg na minha pasta de imagens, nesta pasta de imagens Crie um arquivo . txt com o conteúdo conforme a figura:
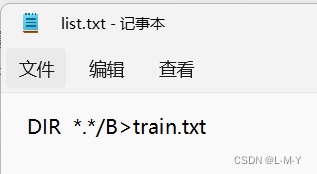
DIR *.*/B>train.txt
Modifique o sufixo do arquivo .txt para .bat, conforme mostrado na figura:
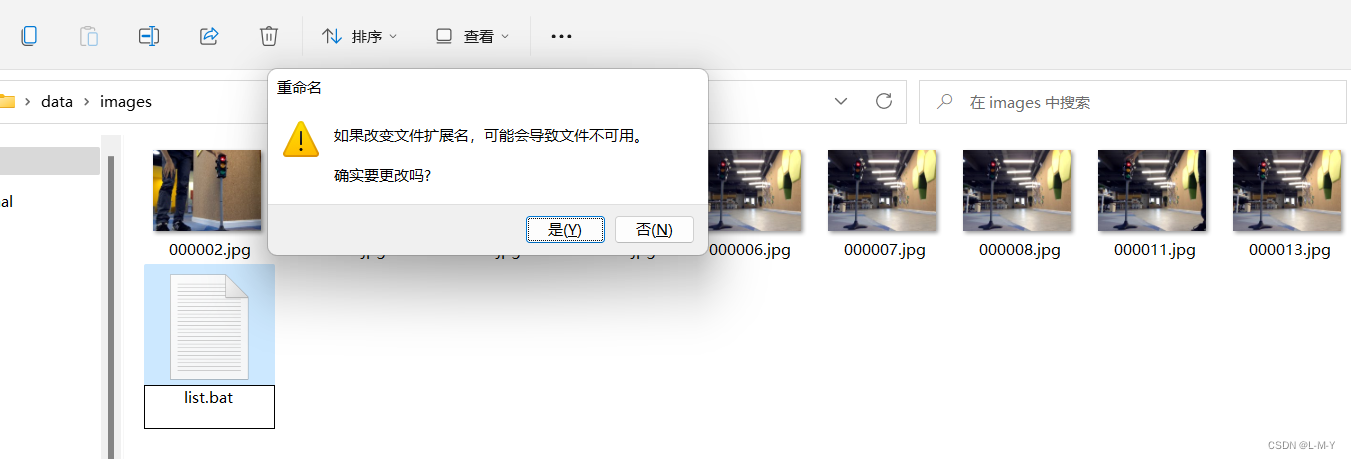
Clique duas vezes no arquivo .bat e você verá que um arquivo train.txt é gerado.
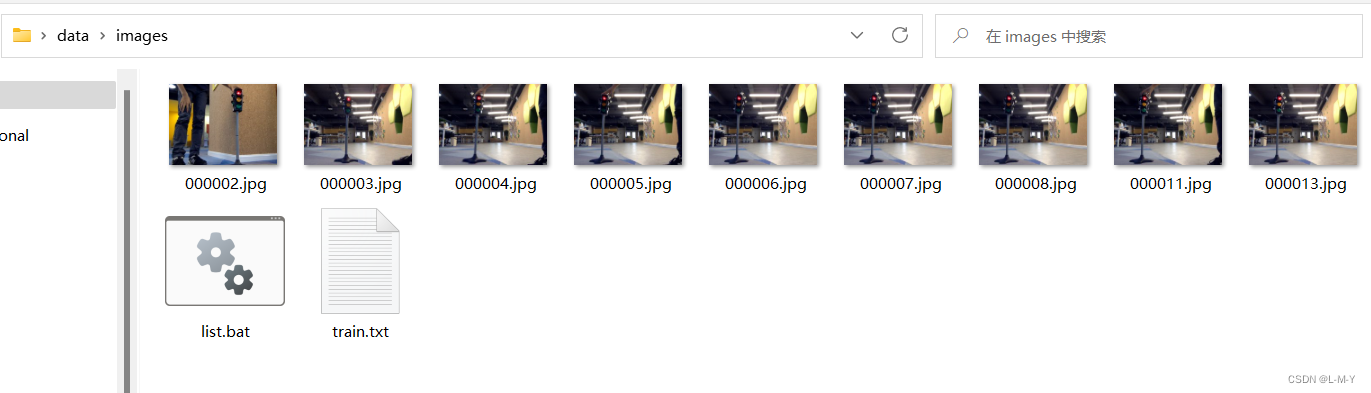
Abra o train.txt e você verá que o conteúdo são os nomes de todos os arquivos na pasta de imagens. .
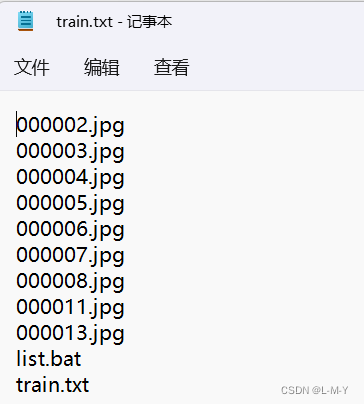
Apague as duas linhas de list.bat e train.txt, deixando apenas o nome da figura
Obs: Como no train.txt final pode ficar apenas o nome da figura sem o sufixo , é necessário colocar ".jpg " em cada linha do arquivo train.txt "Excluir, você pode excluir manualmente, mas se o conjunto de dados for muito grande, você pode usar o seguinte script python para excluir:
import os
filename = r"train.txt"
new_filename = r"train1.txt"
with open(filename,encoding="utf-8") as f1, open(new_filename,"w",encoding="utf-8") as f2:
for line in f1:
new_line = line[:-5]
f2.write(new_line)
f2.write('\n')
f1.close()
f2.close()
O efeito de corrida é mostrado na figura:
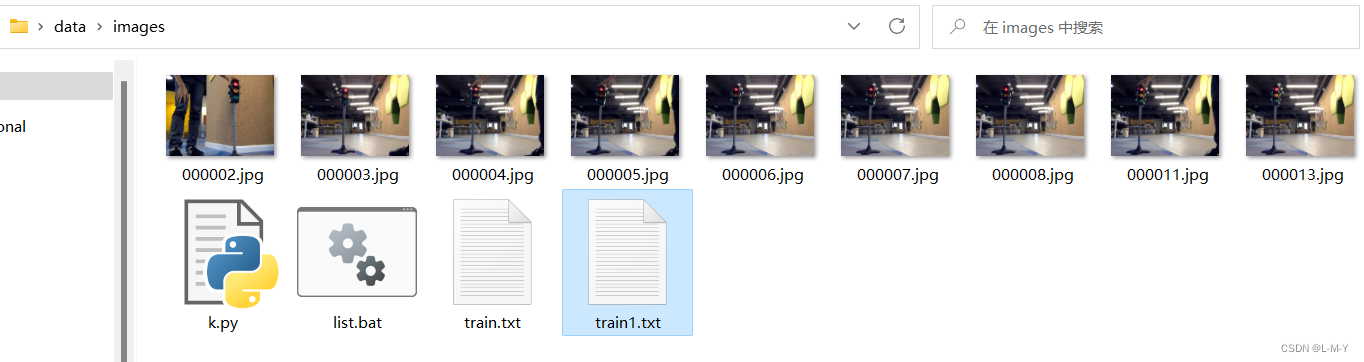
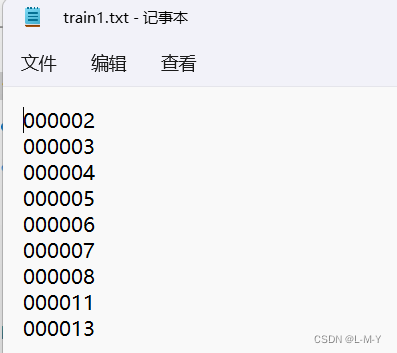
Abra o train1.txt recém-gerado e você verá que os sufixos foram excluídos.
Neste momento, copie o conteúdo do train1.txt para \data\ImageSets\Main\train.txt.
arquivo .xml para arquivo .txt
O modelo yolo de arquivo .xml para .txt fornece oficialmente o código de conversão e o método de uso é mostrado abaixo:
Crie um arquivo .py com o seguinte conteúdo:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['red', 'yellow','green', 'turn_left', 'turn_right', 'stop'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('C:/Users/Lenovo/Desktop/data/Annotations/%s.xml' % (image_id),encoding='utf-8')
out_file = open('C:/Users/Lenovo/Desktop/data/labels/%s.txt' % (image_id), 'w',encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('C:/Users/Lenovo/Desktop/data/labels/'):
os.makedirs('C:/Users/Lenovo/Desktop/data/labels/')
image_ids = open('C:/Users/Lenovo/Desktop/data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), mode='w', encoding='utf-8')
for image_id in image_ids:
list_file.write('C:/Users/Lenovo/Desktop/data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
Observações sobre o uso do código de conversão:
- Altere a sexta linha para 'train', 'val', 'test'
- Altere o conteúdo nas classes da sétima linha para o nome da categoria em seu próprio conjunto de dados
- Preste atenção na escrita de cada endereço, certifique-se de usar barras invertidas
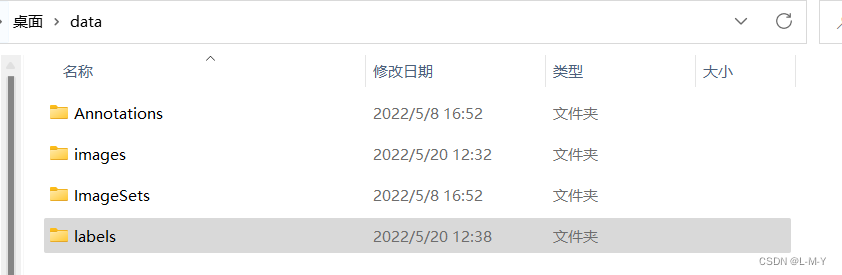
Depois de executar este script, você descobrirá que uma nova pasta de etiquetas é gerada nos dados, o que significa que a conversão de dados foi bem-sucedida
Melhore seu próprio conjunto de dados YOLO
Por fim, copie a pasta labels para o conjunto de dados yolo.