milagre
O assunto deste livro, ChatGPT, é uma maravilha.
Já se passou quase meio ano desde seu lançamento em novembro de 2022, e a atenção e o impacto que o ChatGPT atraiu podem ter superado quase todos os pontos quentes da história da tecnologia da informação.
Seu número de usuários atingiu 1 milhão em 2 dias e 100 milhões em 2 meses, quebrando o recorde anterior do TikTok. E após o lançamento do aplicativo iOS em maio de 2023, ele também estará no topo da lista geral da Apple App Store sem nenhum suspense.
Pela primeira vez em suas vidas, muitas pessoas entraram em contato com um sistema de diálogo altamente inteligente que pode corrigir erros. Escrever artigos, embora muitas vezes você seja muito confiante, "absurdo sério" e até mesmo simples adição e subtração não são corretos, mas se você lembrar que está errado ou deixar ir passo a passo, será realmente muito confiável, liste as etapas para fazer as coisas de maneira ordenada e, em seguida, obtenha a resposta correta. Para algumas tarefas complicadas, você espera vê-lo brincar, mas ele o surpreende ao fornecer respostas razoáveis sem pressa.
Muitos especialistas do setor também são conquistados por ele:
Gates, que inicialmente foi pessimista e até votou contra a decisão da Microsoft de investir na OpenAI em 2019, agora compara o ChatGPT com os PCs, a Internet etc. A sugestão de Alibaba Zhang Yong é: “Vale a pena refazer todas as indústrias, aplicativos, software e serviços com base nos recursos do modelo grande”. Muitos especialistas, representados por Musk, pediram a suspensão do desenvolvimento de poderosos modelos de IA porque as capacidades inovadoras do ChatGPT podem representar uma ameaça para os seres humanos.
Na recém-concluída Conferência Zhiyuan de 2023, Sam Altman disse com confiança que a AGI provavelmente chegará dentro de dez anos, e a cooperação global é necessária para resolver vários problemas causados por ela. Os três cientistas que ganharam o Prêmio Turing por promover conjuntamente o aprendizado profundo da borda ao centro do palco têm opiniões significativamente diferentes:
Yann LeCun deixou claro que o grande modelo autorregressivo representado pelo GPT tem falhas essenciais e é necessário encontrar uma nova maneira de contornar o modelo mundial, para que ele não esteja preocupado com a ameaça da IA.
Embora Yoshua Bengio, que apareceu no vídeo de outro palestrante, não concordasse que a rota GPT por si só poderia levar à AGI (ele está otimista sobre a combinação de raciocínio bayesiano e redes neurais), ele admitiu que há um grande potencial em modelos grandes e não há um teto óbvio a partir do primeiro princípio. Portanto, ele assinou uma carta aberta pedindo uma moratória no desenvolvimento da IA.
Geoffrey Hinton, que fez o discurso final, obviamente concordou com a visão de seu discípulo Ilya Sutskever de que o modelo grande pode aprender a representação comprimida do mundo real. Ele percebeu que, com retropropagação (em termos leigos, significa um mecanismo integrado de reconhecimento e correção de erros) e uma rede neural artificial que pode ser facilmente expandida, a inteligência pode em breve superar a dos humanos. Portanto, ele também se juntou à equipe que defende o risco da IA.
A jornada de contra-ataque da rede neural artificial representada pelo ChatGPT também foi considerada altos e baixos em toda a história da ciência e da tecnologia. Foi repetidamente discriminado e atacado na comunidade de inteligência artificial com muitos gêneros. Mais de um gênio pioneiro terminou em tragédia:
Em 1943, Walter Pitts e Warren McCulloh tinham apenas 20 anos quando propuseram a representação matemática das redes neurais.
Em 1958, aos 30 anos, Frank Rosenblatt, que realmente percebeu a rede neural por meio do perceptron, se afogou em seu aniversário de 43 anos;
O principal proponente da retropropagação, David Rumelhart, sofria de uma rara doença incurável em seu auge, na casa dos 50. Ele começou a sofrer de demência em 1998 e morreu em 2011, após lutar contra a doença por mais de dez anos.
……
Algumas das principais conferências e gigantes acadêmicos como Minsky se opuseram sem cerimônia ou até rejeitaram as redes neurais, forçando Hinton e outros a adotar termos mais neutros ou obscuros, como "memória associativa", "processamento distribuído paralelo", "rede convolucional" e "aprendizagem profunda" para ganhar um espaço vital para si.
O próprio Hinton começou na década de 1970, seguindo a direção impopular por décadas, do Reino Unido aos Estados Unidos, e finalmente estabeleceu uma posição no Canadá, a antiga fronteira acadêmica, e trabalhou duro para estabelecer uma escola com um pequeno número de elites, apesar da falta de apoio financeiro.
Até 2012, quando seu aluno de doutorado Ilya Sutskever e outros usaram novos métodos para voar alto na competição ImageNet, o aprendizado profundo começou a se tornar a ciência proeminente da IA e foi amplamente utilizado em vários setores.
Em 2020, ele liderou a equipe da OpenAI e abriu a era dos grandes modelos por meio do GPT-3 com centenas de bilhões de parâmetros.
A própria experiência de vida do ChatGPT também é muito dramática.
Em 2015, Sam Altman, de 30 anos, e Greg Brockman, de 28, se uniram a Musk para convocar Ilya Sutskever, de 30 anos, e outros grandes talentos de IA para cofundar a OpenAI, na esperança de estabelecer uma força de pesquisa de IA de fronteira neutra fora do Google, Facebook e muitos outros gigantes, e definir ambiciosamente a inteligência artificial em nível humano como seu objetivo.
Naquela época, a mídia basicamente relatou que Musk apoiava o estabelecimento de uma organização de IA sem fins lucrativos como título, e poucas pessoas estavam otimistas com o OpenAI. Mesmo uma alma como Ilya Sutskever passou por algumas lutas ideológicas antes de ingressar.
Nos últimos três anos, eles fizeram ataques de várias linhas em aprendizado por reforço, robôs, multiagentes, segurança de IA etc. e, de fato, não alcançaram resultados particularmente convincentes. Tanto que o principal patrocinador, Musk, insatisfeito com o andamento e quis administrar diretamente, após ser rejeitado pelo conselho, optou por sair definitivamente.
Em março de 2019, Sam Altman começou a atuar como CEO da OpenAI e, em poucos meses, concluiu o estabelecimento de uma empresa comercial e recebeu um investimento de US$ 1 bilhão da Microsoft, fazendo os preparativos para o desenvolvimento subsequente.
Em termos de pesquisa científica, Alec Radford, que ingressou na OpenAI dois anos após se formar no Olin College of Engineering em 2014, começou a trabalhar duro. ) e muitos outros trabalhos pioneiros. Em particular, o trabalho dos neurônios emocionais em 2017 criou uma arquitetura minimalista de "prever o próximo personagem" combinada com uma rota técnica de grandes modelos, grande poder de computação e big data, que teve um impacto fundamental no GPT subsequente.
O desenvolvimento do GPT não foi tranquilo.
Pode ser visto claramente na Figura 1 abaixo que, após a publicação do documento GPT-1, a arquitetura intencionalmente mais simples do decodificador somente do OpenAI (falando com precisão, um codificador-decodificador com autorregressivo) não recebeu muita atenção. Houve uma série de trabalhos muito influentes como xxBERT.
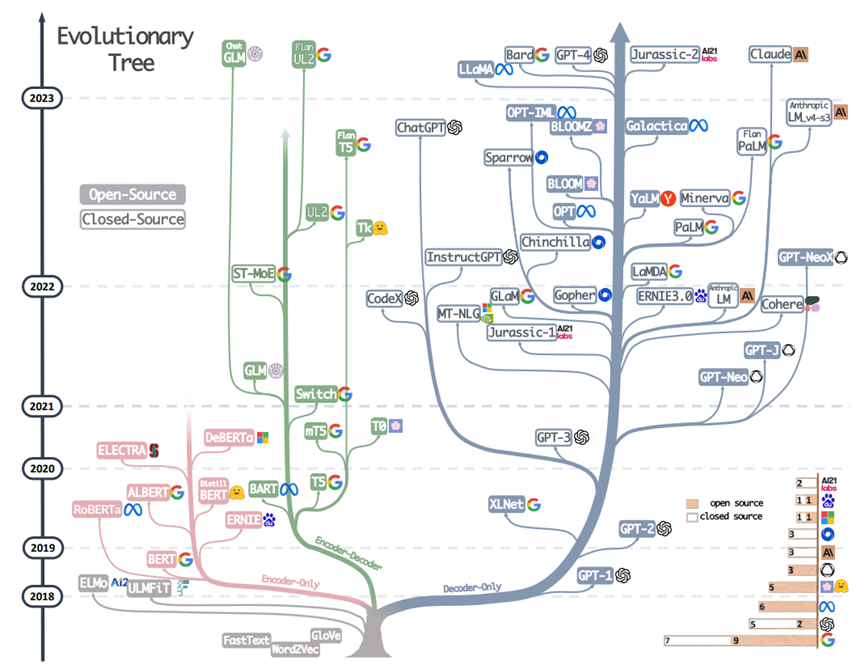
Figura 1 Árvore evolutiva de modelo grande, do artigo "Aproveitando o poder dos LLMs na prática" de Amazon Yang Jingfeng et al. em abril de 2023
Ainda hoje, este último acumulou mais de 68.000 referências, o que ainda é uma ordem de grandeza superior às menos de 6.000 do GPT-1. Os caminhos técnicos dos dois jornais são diferentes, seja na academia ou na indústria, quase todo mundo optou pelo BERT camp naquela época.
O GPT-2, lançado em fevereiro de 2019, aumentou a escala máxima de parâmetros para 1,5 bilhão. Ao mesmo tempo, usando dados de maior escala, qualidade e diversidade, o modelo começou a mostrar fortes capacidades gerais.
Naquela época, não foi a pesquisa em si que fez o GPT-2 chegar às manchetes na comunidade técnica (até hoje, o número de citações em artigos ainda está no início de 6.000, o que é muito menor que o do BERT), mas o OpenAI apenas abriu o código do menor modelo de 345 milhões de parâmetros por motivos de segurança, o que causou um alvoroço. A impressão da comunidade sobre se o OpenAI não é aberto começa aqui.
Antes e depois disso, a OpenAI também realizou pesquisas sobre o impacto da escala nas capacidades do modelo de linguagem e propôs a "Lei de Escala" (Scaling Law), que determinou a direção principal de toda a organização: grandes modelos. Por esse motivo, outras direções, como aprendizado por reforço e robótica, foram cortadas. O que é louvável é que a maioria do pessoal principal de P&D escolheu ficar, mudar sua direção de pesquisa, desistir de seu ego e se concentrar em fazer grandes coisas. Muitas pessoas se voltaram para a engenharia e o trabalho de dados ou reposicionaram sua direção de pesquisa em torno de grandes modelos (por exemplo, o aprendizado por reforço desempenhou um papel importante no GPT 3.5 e sua evolução subsequente). Essa flexibilidade organizacional também é um fator importante para o sucesso da OpenAI.
Com o surgimento do GPT-3 em 2020, algumas pessoas perspicazes no pequeno círculo de PNL começaram a perceber o grande potencial da rota técnica OpenAI. Na China, o Instituto de Pesquisa de Inteligência Artificial Zhiyuan de Pequim lançou modelos como GLM e CPM em conjunto com a Universidade de Tsinghua e outras universidades e está promovendo ativamente o conceito de grandes modelos nos círculos acadêmicos domésticos. Como pode ser visto na Figura 1, depois de 2021, a rota GPT ganhou completamente a vantagem, enquanto a árvore evolutiva das "espécies" de BERT quase parou.
No final de 2020, os irmãos e irmãs de Dario e Daniela Amodei, dois vice-presidentes da OpenAI, levaram vários colegas do GPT-3 e da equipe de segurança a sair e fundaram a Anthropic. A posição de Dario Amodei na OpenAI é extraordinária. Ele é outro criador do roteiro de tecnologia além de Ilya Sutskever, e também é o diretor geral dos projetos GPT-2 e GPT-3 e a direção de segurança. E com ele, há muitos núcleos de GPT-3 e documentos de lei de escala.
Um ano depois, a Anthropic publicou o artigo "A General Language Assistant as a Laboratory for Alignment" e começou a estudar problemas de alinhamento com assistentes de chat. Desde então, evoluiu gradualmente para Claude, um produto de chat inteligente.
O artigo "Emergent Abilities of Large Language Models" foi lançado em junho de 2022. O primeiro trabalho foi Jason Wei, um pesquisador do Google que se formou no Dartmouth College por apenas dois anos como estudante de graduação (ele também foi para a OpenAI em fevereiro deste ano, durante a onda de empregos de elite do Google). Neste artigo, estuda-se a capacidade emergente de modelos grandes, que não existe em modelos pequenos e só aparecerá quando a escala do modelo se expandir a um determinado nível. Ou seja, "a mudança quantitativa levará à mudança qualitativa" com a qual estamos familiarizados.
Em meados de novembro, os funcionários da OpenAI que estavam desenvolvendo o GPT-4 receberam instruções da administração para suspender todos os trabalhos e lançar uma ferramenta de bate-papo com todas as forças por causa da concorrência. Duas semanas depois, nasceu o ChatGPT. O que aconteceu depois disso ficou registrado na história.
A indústria especula que a administração da OpenAI deveria ter aprendido sobre o progresso do Anthropic Claude, percebeu o enorme potencial deste produto e decidiu agir primeiro. Isso demonstra o julgamento super estratégico do pessoal central. Você sabe, mesmo os principais desenvolvedores do ChatGPT não sabem por que o produto é tão popular depois de lançado ("Meus pais finalmente sabem o que estou fazendo"), e eles não se sentiram nada bem quando o experimentaram.
Em março de 2023, após meio ano de "avaliação, testes contraditórios e melhorias iterativas para modelos e mitigações no nível do sistema", o GPT-4 foi lançado.
O estudo da Microsoft Research sobre sua versão interna (capaz de exceder a versão on-line disponível publicamente) conclui: "Em todas essas tarefas, o GPT-4 tem um desempenho surpreendentemente próximo ao desempenho humano...
Desde então, empresas nacionais e estrangeiras e instituições de pesquisa científica seguiram, e um ou mais novos modelos são lançados quase todas as semanas, mas o OpenAI ainda é o melhor em termos de recursos abrangentes, e o único que pode competir com ele é o Anthropic.
Muitas pessoas vão perguntar, por que a China não produziu o ChatGPT? Na verdade, a pergunta (prompt) correta deveria ser: Por que apenas OpenAI no mundo é capaz de fazer ChatGPT? Qual é a razão do sucesso deles? Pensar nisso ainda é relevante hoje.
ChatGPT, que milagre.
homem estranho
O autor deste livro, Stephen Wolfram, é um homem estranho.

Embora ele não seja uma celebridade tecnológica conhecida como Musk, ele é de fato conhecido no pequeno círculo de geeks da tecnologia e é chamado de "a pessoa viva mais inteligente".
Um dos fundadores do Google, Sergey Brin, foi atraído pela empresa de Wolfram para um estágio durante seus anos de faculdade. Wang Xiaochuan, o fundador da Sogou and Baichuan Intelligent, também é um famoso fã obstinado dele, "com reverência e fanatismo ... seguindo e seguindo por muitos anos."
Wolfram era conhecido como uma criança prodígio quando criança. Porque eles desdenham ler os "livros estúpidos" recomendados pela escola, e não são bons em aritmética, e não querem fazer as perguntas que já foram respondidas.No início, os professores acharam que a criança não era boa.
Como resultado, aos 13 anos, escrevi vários livros de física sozinho, um dos quais se chamava "Subatomic Particle Physics".
Aos 15 anos, ele publicou um artigo sério sobre física de alta energia "Hadronic Electrons?" no Australian Journal of Physics, propondo uma nova forma de acoplamento elétron-hádron de alta energia. Este artigo também possui 5 citações.

Wolfram passou alguns anos em universidades famosas como Eton College e Oxford University no Reino Unido, e ele não frequentava muito as aulas. Ele odiava os problemas que haviam sido resolvidos por outros, então fugiu antes de se formar. Finalmente, aos 20 anos, ele obteve um Ph.D diretamente.
Ele então permaneceu e se tornou professor na Caltech.
Em 1981, Wolfram ganhou o primeiro MacArthur Genius Award e foi o vencedor mais jovem. O mesmo grupo são todos mestres de várias disciplinas, incluindo Walcott, vencedor do Prêmio Nobel de 1992.
Ele rapidamente perdeu o interesse pela física pura. Em 1983, transferiu-se para o Institute for Advanced Study em Princeton e começou a estudar autômatos celulares, na esperança de encontrar leis mais subjacentes aos fenômenos naturais e sociais.
Essa transformação teve um impacto enorme. Tornou-se um dos fundadores da disciplina de sistemas complexos e é considerado por alguns como tendo produzido trabalhos dignos do Prêmio Nobel. Aos 20 anos, ele participou dos primeiros trabalhos do Santa Fe Institute com vários ganhadores do Prêmio Nobel Gell-Mann e Philip Anderson (foi ele quem publicou o artigo "More is Different" em 1972 e propôs o conceito de emergência) e fundou o centro de pesquisa de sistemas complexos na UIUC. Ele também fundou a revista acadêmica Complex Systems.
Para tornar mais convenientes os experimentos de computador relacionados aos autômatos celulares, ele desenvolveu o software matemático Mathematica (o nome foi dado por seu amigo Jobs) e, a seguir, fundou a empresa de software Wolfram Research, tornando-se um empresário de sucesso.
O poder do software Mathematica pode ser sentido intuitivamente a partir da gramática altamente abstrata e clara ao interpretar o ChatGPT posteriormente neste livro. Para ser sincero, isso me fez querer estudar seriamente esse software e as tecnologias relacionadas.
Em 1991, Wolfram voltou ao estado de pesquisa e começou a se esconder à noite, enterrando-se em experimentos e escrevendo por dez anos todas as noites, e publicou uma obra-prima de mais de 1.000 páginas, A New Kind of Science.
O principal ponto de vista do livro é: tudo é calculado, e vários fenômenos complexos do universo, inclusive os produzidos por humanos ou espontâneos na natureza, podem ser simulados por cálculos simples com algumas regras.
A afirmação da resenha do livro na Amazon pode ser melhor compreendida: "Galileu certa vez afirmou que a natureza é escrita na linguagem da matemática, mas Wolfram acredita que a natureza é escrita em linguagens de programação (e linguagens de programação muito simples)."
Além disso, esses fenômenos ou sistemas, como o trabalho do cérebro humano e a evolução do sistema meteorológico, são equivalentes em termos de cálculo e têm a mesma complexidade, o que se chama de "princípio da equivalência computacional".
O livro é muito popular, porque a linguagem é muito popular, e tem quase mil fotos, mas também há muitas críticas do meio acadêmico, principalmente dos antigos colegas da física. As teorias principalmente concentradas no livro não são originais (o trabalho de Turing sobre complexidade computacional, o jogo da vida de Conway, etc. são semelhantes) e carecem de rigor matemático, portanto, muitas conclusões são difíceis de suportar o teste (por exemplo, a seleção natural não é a causa raiz da complexidade biológica, Scott Aaronson, autor do livro de Turing "Quantum Computing Open Course", também apontou que o método de Wolfram não pode explicar os resultados do teste de Bell em computação quântica).
Wolfram respondeu às críticas lançando o mecanismo de computação de conhecimento Wolfram|Alpha, considerado por muitos como a primeira tecnologia de inteligência artificial verdadeiramente prática. Combinando conhecimento e algoritmos, ele permite que os usuários emitam comandos em linguagem natural e o sistema retorna as respostas diretamente. Usuários de todo o mundo podem usar este poderoso sistema através da web, Siri, Alexa, incluindo o plug-in ChatGPT.
Se pegarmos a rede neural representada pelo ChatGPT para examinar a teoria de Wolfram, encontraremos uma relação coincidente: a arquitetura autorregressiva subjacente do GPT, comparada com muitos modelos de aprendizado de máquina, pode de fato ser classificada como "computação com regras simples" e sua capacidade emerge através do acúmulo de mudanças quantitativas.
Wolfram geralmente fornece suporte técnico para filmes de ficção científica de Hollywood e usa a linguagem de programação Mathematica e Wolfram para gerar alguns efeitos realistas.


Ele acabou deixando a academia naquele ano, devido a uma rixa com seus colegas de Princeton. O professor Feynman escreveu para persuadi-lo: "Você não entenderá os pensamentos das pessoas comuns, eles são apenas tolos para você."
Fiz minhas próprias coisas e vivi uma vida maravilhosa.
Stephen Wolfram é incrível.
livro estranho
Coisas estranhas + pessoas estranhas, este livro é obviamente um livro estranho.
É um milagre em si que um mestre como Stephen Wolfram possa escrever um livro popular sobre um tema de grande interesse para uma ampla gama de leitores.
Ele passou da física pura para sistemas complexos há 40 anos porque queria resolver os primeiros princípios de fenômenos como a inteligência humana, e acumulou muito. Por causa de seus extensos contatos, ele se comunicou com figuras importantes como Geffrey Hinton, Ilya Sutskever e Dario Amodei, e tem informações em primeira mão, o que garante a precisão da tecnologia. Não é à toa que o CEO da OpenAI o chamou de "a melhor explicação do princípio do ChatGPT" após a publicação deste livro.
O livro inteiro é dividido em duas partes, e o espaço é muito pequeno, mas os pontos mais importantes sobre o ChatGPT são mencionados, e a explicação é popular e completa.
Iniciei o "ChatGPT Learning Camp" na comunidade de Turing. Tive muitos intercâmbios com alunos de vários níveis técnicos e formações profissionais. Achei muito importante entender o modelo grande e estabelecer corretamente alguns conceitos básicos. Sem esses pilares, mesmo que você seja um engenheiro de algoritmo sênior, sua cognição pode ser muito tendenciosa.
Por exemplo, um dos conceitos centrais da rota da tecnologia GPT é usar a arquitetura de geração autorregressiva mais simples para resolver o problema de aprendizado não supervisionado, ou seja, usar os dados originais sem rotulagem humana e aprender o mapeamento dos dados para o mundo. Entre eles, a arquitetura generativa autorregressiva é a muito popular "basta adicionar uma palavra de cada vez" no livro. É importante observar aqui que o objetivo de escolher essa arquitetura não é fazer tarefas de geração, mas entender ou aprender e perceber os recursos gerais do modelo. Nos anos anteriores e mesmo posteriores a 2020, muitos profissionais do setor presumiram que o GPT servia para gerar tarefas e optaram por ignorá-lo. Como todos sabem, o título do documento GPT-1 é "Melhorando a compreensão da linguagem por meio de pré-treinamento generativo".
Por outro exemplo, para leitores que não têm muito conhecimento técnico ou conhecimento de aprendizado de máquina, a dificuldade imediata que eles podem encontrar ao entender os últimos desenvolvimentos em inteligência artificial é que eles não conseguem entender os antigos conceitos básicos de "modelo" e "parâmetros (pesos em redes neurais)", e esses conceitos não são tão fáceis de explicar com clareza. Neste livro, o grande autor explicou com exemplos intuitivos (funções e botões) com muita atenção. (Veja a seção "O que é um modelo")
As diversas seções sobre redes neurais são ricas em imagens e textos. Acredito que será muito útil para todos os tipos de leitores ter uma compreensão mais profunda da natureza das redes neurais e seu processo de treinamento, bem como conceitos como funções de perda e gradiente descendente.
O autor não ignorou a natureza ideológica da explicação. Por exemplo, os parágrafos a seguir são uma boa introdução ao significado de aprendizado profundo:
O grande avanço no "aprendizagem profunda" por volta de 2012 foi relacionado à descoberta de que pode ser mais fácil minimizar (pelo menos aproximadamente) quando muitos pesos estão envolvidos do que quando relativamente poucos pesos estão envolvidos.
Em outras palavras, pode parecer contra-intuitivo que problemas complexos às vezes sejam mais fáceis de resolver com redes neurais do que com problemas simples. A razão geral é que quando há muitas "variáveis de peso", há "muitas direções diferentes" no espaço de alta dimensão que podem nos levar ao mínimo; e quando há menos variáveis, é fácil cair no "lago da montanha" do mínimo local e não conseguir encontrar a "direção para fora".
Este parágrafo deixa claro o valor do aprendizado de ponta a ponta:
Nos primórdios das redes neurais, as pessoas tendiam a pensar que "as redes neurais deveriam fazer o mínimo possível". Por exemplo, ao converter fala em texto, acredita-se que o áudio da fala deva ser analisado primeiro, dividido em fonemas e assim por diante. Mas acontece que (pelo menos para "tarefas semelhantes a humanos") a melhor abordagem geralmente é tentar treinar uma rede neural para "resolver o problema de ponta a ponta", deixando-a "descobrir" os recursos intermediários necessários, codificações etc.
Dominar o porquê desses conceitos é benéfico para entender o histórico da GPT.
O conceito de incorporação é crucial para pesquisadores de algoritmos envolvidos no desenvolvimento de modelos em larga escala, programadores baseados no desenvolvimento de aplicativos de modelos em larga escala e leitores comuns que desejam entender o GPT em profundidade. É também a "ideia central do ChatGPT", mas é relativamente abstrato e não é particularmente fácil de entender. A seção "O Conceito de 'Incorporação'" neste livro é a melhor explicação deste conceito que já vi. Através dos três métodos de diagrama, código e interpretação de texto, acredito que todos possam entendê-lo. Claro, há muitas imagens coloridas na seção "Espaço de Significado e Leis do Movimento Semântico" no texto a seguir, que podem aprofundar ainda mais esse conceito.
No final desta seção, os tokens de palavras comuns (token) também são apresentados e vários exemplos intuitivos em inglês são fornecidos.
A seguinte introdução ao princípio de funcionamento e processo de treinamento do ChatGPT também é popular e rigorosa. A tecnologia mais complicada do Transformer é muito detalhada e também é verdadeiramente informada de que a teoria atual não descobriu por que isso é eficaz.
A primeira parte termina no final, combinando a teoria da irredutibilidade computacional do autor, elevando a compreensão do ChatGPT a um nível superior, o que é semelhante à ideia geral do GPT que Illya Sutskever enfatizou em várias entrevistas é obter a representação comprimida do modelo mundial por meio da geração.
Na minha opinião, esta passagem é muito instigante:
O que é preciso para produzir "linguagem humana significativa"? No passado, poderíamos ter pensado que o cérebro humano era essencial. Mas agora sabemos que a rede neural do ChatGPT também pode fazer um trabalho muito bom. …Eu suspeito fortemente que o sucesso do ChatGPT indica um importante fato "científico": que a linguagem humana significativa é realmente mais estruturada e mais simples do que pensamos, e pode acabar sendo possível descrever como organizar tal linguagem com regras bastante simples.
A linguagem é uma ferramenta para o pensamento sério, tomada de decisão e comunicação.Comparada com a percepção e a ação, deveria ser a tarefa mais difícil na inteligência do ponto de vista da sequência e dificuldade de aquisição das crianças. Mas é provável que o ChatGPT tenha quebrado a senha, como disse Wolfram "". Isso indica que, no futuro, podemos melhorar ainda mais o nível geral de inteligência por meio de linguagem de computação ou outras representações.
A partir disso, o progresso da inteligência artificial pode ter efeitos semelhantes em várias disciplinas: assuntos que antes eram considerados difíceis não são tão difíceis de outra perspectiva. Juntamente com a bênção de um assistente inteligente de uso geral como o GPT, "algumas tarefas mudaram de basicamente impossíveis para basicamente viáveis" e, eventualmente, o nível tecnológico de toda a humanidade atingiu um novo patamar.
A segunda parte deste livro é uma introdução à comparação e combinação dos sistemas ChatGPT e Wolfram|Alpha, com muitos exemplos. Se a inteligência geral do GPT é mais parecida com os seres humanos, a maioria dos seres humanos de fato não é boa em cálculo preciso e pensamento por natureza. A combinação de modelos de propósito geral e modelos de propósito especial no futuro também deve ser uma direção promissora.
É um pouco lamentável que este livro se concentre apenas na parte pré-treinamento do ChatGPT, mas não abranja as seguintes etapas de ajuste fino que também são importantes: ajuste fino supervisionado (SFT), modelagem de recompensa e aprendizado por reforço. Um material de aprendizado melhor a esse respeito é o discurso "State of GPT" proferido por Andrej Karpathy, membro fundador da OpenAI e ex-líder da Tesla AI, na conferência Microsoft Build em maio de 2023.

Forneci um vídeo deste discurso e imagens de texto refinado em chinês na comunidade Turing "ChatGPT Learning Camp". Haverá também uma aula de leitura guiada deste livro no futuro. Sejam todos bem-vindos.
O Sr. Liu Jiang e o Sr. Wan Weigang compartilharão o conteúdo relacionado ao livro "This is ChatGPT" no dia 25 de julho.
Clique para ler o texto original e participe do ChatGPT Learning Camp.