Conhecimento relacionado ao NoSQL
- 1. A evolução do mysql independente
- 2. Visão geral do NoSQL
- Três, 3V + 3 de altura
- 4. Visão geral técnica
- 5. Quatro categorias de NoSQL
1. A evolução do mysql independente
1. Mysql autônomo (evolução 1)
1.1 Processo de acesso do usuário
APP——>DAL——>Mysql

1.2 Antecedentes
O tráfego de um site básico geralmente não é muito grande e um único banco de dados é totalmente suficiente.
2. Cache (evolução 2)
2.1 Estrutura
Memcached (cache) + MySQL + divisão vertical
2.2 Introdução
Como 80% do site é lido, cada consulta é muito problemática, portanto, para reduzir a pressão dos dados, você pode usar o cache para garantir a eficiência.
2.3 Processo de desenvolvimento
Otimize a estrutura e o índice de dados -> cache de arquivo (IO) -> Memcached (o ano mais quente)
2.4 Funções
Realize a separação leitura-gravação e armazenamento em cache
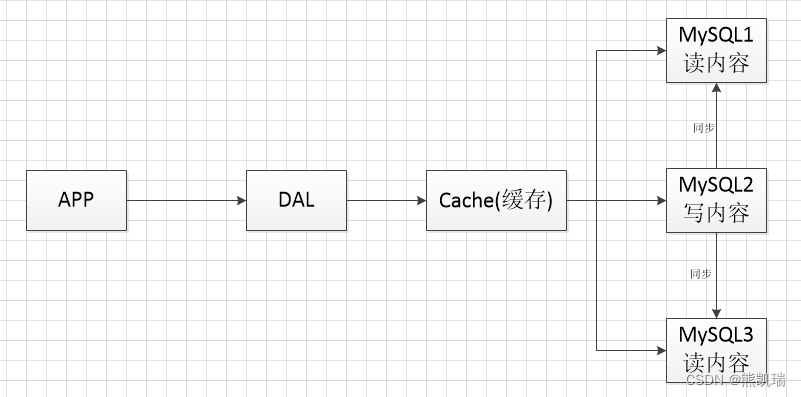
3. Cluster (evolução 3)
3.1 Estrutura
Subbanco de dados e tabela + divisão horizontal + cluster MySQL + cache
3.2 Introdução
MyISAM: Os bloqueios de tabela afetam muito a eficiência e ocorrerão sérios problemas de bloqueio sob alta simultaneidade.
Innodb: bloqueios de linha
3.3 Processo
Use subbanco de dados e subtabela para resolver a pressão de escrita, e o MySQL também introduz o conceito de partição de tabela
3.4 Função
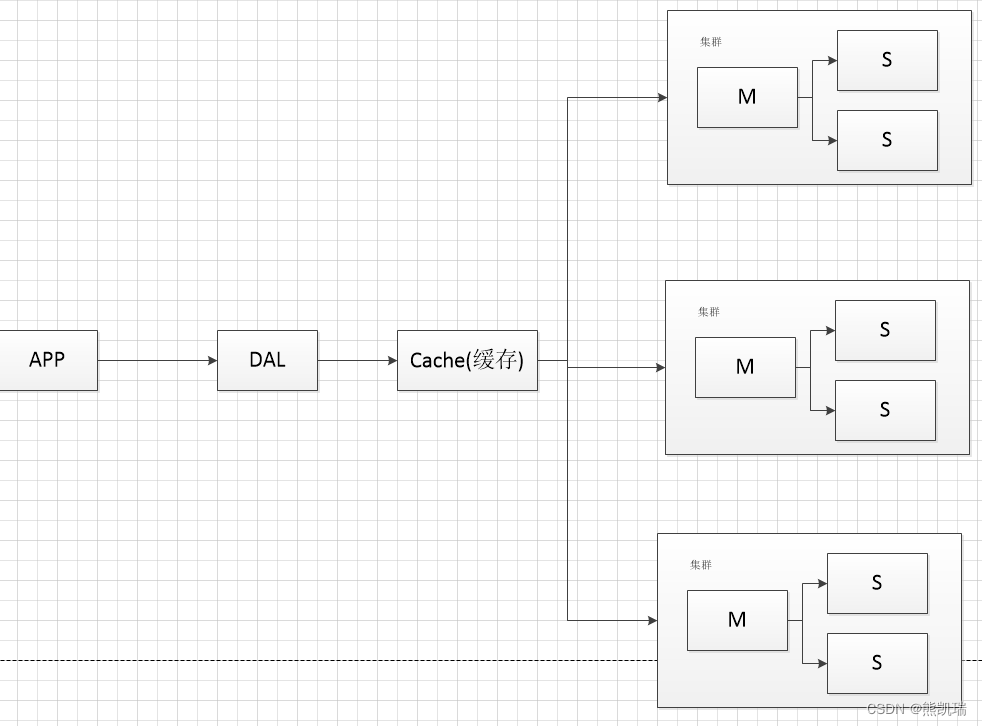
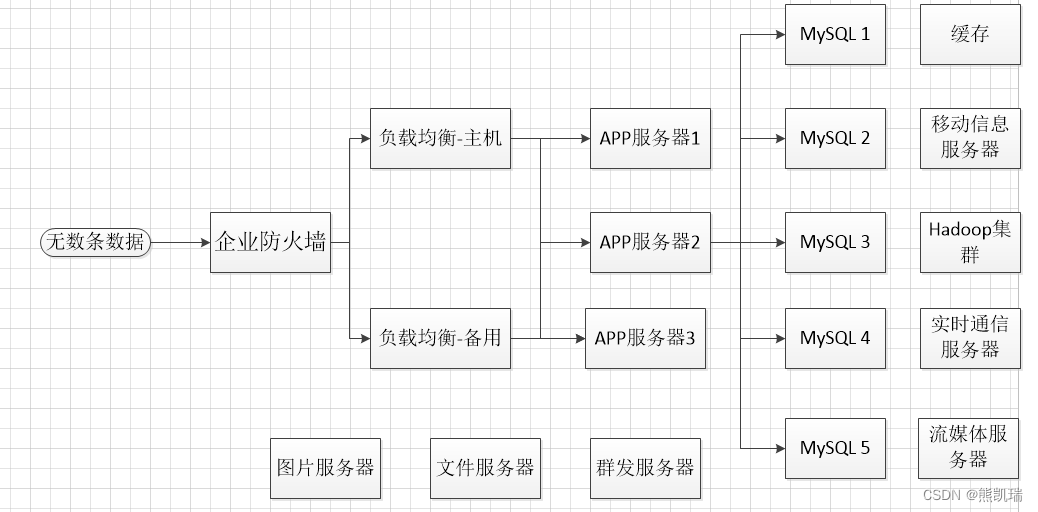
4. agora
4.1 Estrutura
Balanceamento de carga + subbanco de dados e subtabela + divisão horizontal + cluster MySQL + cache + vários servidores
4.2 Antecedentes
A quantidade de dados é grande e muda rapidamente, e bancos de dados relacionais como o MySQL não são suficientes.
4.3 Função
2. Visão geral do NoSQL
1. Introdução
NoSQL geralmente se refere a bancos de dados não relacionais. Com o nascimento da Internet web 2.0, é difícil para os bancos de dados relacionais tradicionais lidar com comunidades de grande escala e alta simultaneidade. Portanto, o NoSQL está se desenvolvendo rapidamente no atual ambiente de big data. (Muitos tipos de dados são informações pessoais do usuário, rede social, localização geográfica, o armazenamento desses tipos de dados não precisa de um formato fixo)
2. Recursos
(1) Fácil de expandir (sem relacionamento entre dados, fácil de expandir)
(2) Grande volume de dados e alto desempenho (Redis grava 80.000 vezes por segundo, lê 110.000 e o nível de registro de cache do NoSQL é um Cache refinado, o desempenho será relativamente alto)
(3) O tipo de dados é diverso (não há necessidade de projetar o banco de dados com antecedência, basta pegá-lo e usá-lo)
3. A diferença entre RDBMS e NoSQL
3.1 RDBMS (banco de dados relacional)
Organização estruturada, SQL, dados e relacionamentos são armazenados em tabelas separadas, aderem às regras ACID, etc.
3.2 NoSQL (banco de dados não relacional)
Armazenamento não é apenas dados, não há linguagem de consulta fixa, armazenamento de pares de valores-chave, armazenamento de colunas, armazenamento de documentos,
consistência eventual de banco de dados gráfico, teorema CAP e BASE, alto desempenho, alta disponibilidade e alta escalabilidade.
Três, 3V + 3 de altura
1. 3V na era do big data
(1) Grande volume
(2) Variedade
(3) Velocidade em tempo real
2. Três pontos altos na era do big data
(1) Alta simultaneidade
(2) Alta escalabilidade
(3) Alto desempenho
4. Visão geral técnica
1. Informações básicas do produto
1.1 Cenários
Nome, preço, informações comerciais
1.2 Tecnologia
Banco de dados relacional (MySQL/Oracle)
2. Descrição e comentários do produto
2.1 Cenários
mais texto
2.2 Tecnologia
Banco de dados de documentos (MongoDB)
3. Fotos
3.1 Cenários
imagem da loja
3.2 Tecnologia
Sistema de arquivos distribuído FastDFS
Sistema de arquivos Taobao TFS
Sistema de arquivos Google GFS
Sistema de arquivos Hadoop HDFS
Alibaba Cloud File System OSS
4. As palavras-chave do produto
4.1 Cenários
procurar
4.2 Tecnologia
Mecanismo de pesquisa solr, elasticsearch, ISerach
5. Informações de banda de commodities populares
5.1 Cenários
Vendas de produtos
5.2 Tecnologia
Banco de dados de memória Redis, Tair, Memache...
6. Transações de mercadorias, interface de pagamento externo
Aplicativo de três partes
5. Quatro categorias de NoSQL
1. Par chave-valor KV
1.1 Exemplo
Sina: Redis
Meituan: Redis + Tair
Ali, Baidu: Redis + memecache
1.2 Cenários de aplicação
O cache de conteúdo é usado principalmente para lidar com altas cargas de acesso de grandes quantidades de dados e também é usado em alguns sistemas de log e assim por diante.
1.3 Modelo de Dados
Chave aponta para o par chave-valor de Valor, que geralmente é implementado por tabela hash.
1.4 Vantagens
pesquisa rápida
1.5 Desvantagens
Os dados não são estruturados e geralmente são tratados apenas como string ou dados binários
2. Banco de dados de documentos (o formato bson é igual ao json)
1.1 MongoDB,CouchDB
MongoDB é um banco de dados baseado em armazenamento distribuído de arquivos. É escrito em C++ e é usado principalmente para processar um grande número de documentos
. MongoDB é um produto intermediário entre bancos de dados relacionais e bancos de dados não relacionais. Como um banco de dados relacional.
1.2 Cenários de aplicação
Aplicação web (semelhante ao Key-Value, o Value é estruturado, a diferença é que o banco de dados consegue entender o conteúdo do Value)
1.3 Modelo de Dados
O par de valores-chave correspondente a Valor-chave e Valor são dados estruturados.
1.4 Vantagens
Os requisitos de estrutura de dados não são rígidos, a estrutura da tabela é variável e não há necessidade de pré-definir a estrutura da tabela como um banco de dados relacional.
1.5 Desvantagens
O desempenho da consulta não é alto e falta uma sintaxe de consulta unificada.
3. Banco de dados de armazenamento de colunas
3.1 Exemplo
HBase (grandes dados)
3.2 Cenários de aplicação
sistema de arquivos distribuído
3.3 Modelo de Dados
Armazene em clusters de colunas, armazene dados na mesma coluna juntos
3.4 Vantagens
A velocidade de pesquisa é rápida, a escalabilidade é forte e é mais fácil realizar expansão distribuída.
3.5 Desvantagens
Funções relativamente limitadas
4. Banco de dados relacional gráfico
Não é um banco de dados que armazena imagens, mas armazena relacionamentos
4.1 Exemplos
Neo4J, InfoGrid, Gráfico Infinito
4.2 Cenários de aplicação
Redes sociais, sistemas de recomendação, etc., com foco na construção de gráficos de relacionamento
4.3 Modelo de Dados
estrutura gráfica
4.4 Vantagens
Use algoritmos relacionados à estrutura do gráfico, como endereçamento de caminho mais curto, pesquisa de relacionamento de N graus, etc.
4.5 Desvantagens
Em muitos casos, é necessário calcular todo o gráfico para obter as informações necessárias, e esta estrutura não é fácil de distribuir.