Prefácio
No desenvolvimento diário, algum conhecimento raro e relativamente básico é sempre fácil de esquecer ou se torna um pouco ambíguo após um período de tempo. Este artigo registra principalmente alguns conhecimentos básicos sobre o banco de dados MySQL para uma revisão rápida no futuro.
Comandos SQL
Os comandos SQL podem ser divididos em quatro grupos: DDL , DML , DCL e TCL . Os comandos incluídos nos quatro grupos são os seguintes
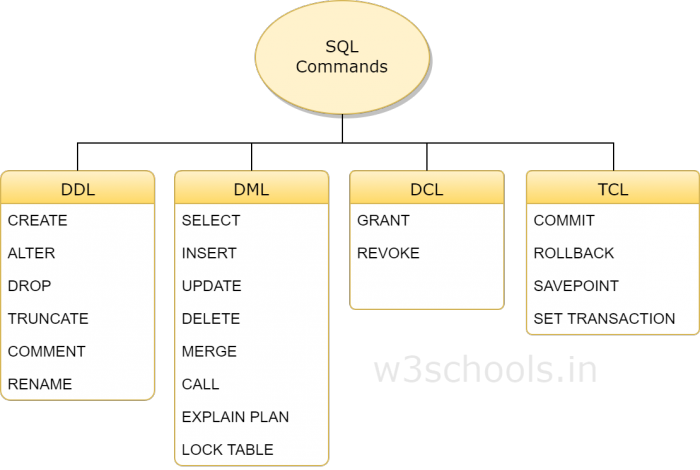
DDL
DDL é a abreviatura de Data Definition Language, que lida com esquemas de banco de dados e descreve como os dados devem residir no banco de dados.
CREATE: Cria um banco de dados e seus objetos (como tabelas, índices, visualizações, procedimentos armazenados, funções e gatilhos) ALTER: Altera a estrutura de um banco de dados existente DROP: Exclui objetos do banco de dados TRUNCATE: Exclui todos os registros da tabela, incluindo registros Todo o espaço alocado será excluído COMMENT: adicionar comentário RENAME: renomear objeto
Os comandos comuns são os seguintes:
# 建表
CREATE TABLE sicimike (
id int(4) primary key auto_increment COMMENT '主键ID',
name varchar(10) unique,
age int(3) default 0,
identity_card varchar(18)
# PRIMARY KEY (id) // 也可以通过这种方式设置主键
# UNIQUE KEY (name) // 也可以通过这种方式设置唯一键
# key/index (identity_card, col1...) // 也可以通过这种方式创建索引
) ENGINE = InnoDB;
# 设置主键
alter table sicimike add primary key(id);
# 删除主键
alter table sicimike drop primary key;
# 设置唯一键
alter table sicimike add unique key(column_name);
# 删除唯一键
alter table sicimike drop index column_name;
# 创建索引
alter table sicimike add [unique/fulltext/spatial] index/key index_name (identity_card[(len)] [asc/desc])[using btree/hash]
create [unique/fulltext/spatial] index index_name on sicimike(identity_card[(len)] [asc/desc])[using btree/hash]
example: alter table sicimike add index idx_na(name, age);
# 删除索引
alter table sicimike drop key/index identity_card;
drop index index_name on sicimike;
# 查看索引
show index from sicimike;
# 查看列
desc sicimike;
# 新增列
alter table sicimike add column column_name varchar(30);
# 删除列
alter table sicimike drop column column_name;
# 修改列名
alter table sicimike change column_name new_name varchar(30);
# 修改列属性
alter table sicimike modify column_name varchar(22);
# 查看建表信息
show create table sicimike;
# 添加表注释
alter table sicimike comment '表注释';
# 添加字段注释
alter table sicimike modify column column_name varchar(10) comment '姓名';
————————————————
版权声明:本文为CSDN博主「Sicimike」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Baisitao_/article/details/104714764DML
DML é uma linguagem de manipulação de dados abreviatura (Data Manipulation Language), incluindo a maioria das declarações comuns SQL, como SELECT, INSERT, UPDATE, DELETEetc., que é usado para armazenar , modificar , recuperar e apagar dados no banco de dados.
Paginação
-- 查询从第11条数据开始的连续5条数据 select * from sicimike limit 10, 5agrupar por
Por padrão, a instrução group by no MySQL não requer que a coluna retornada por select seja uma coluna agrupada ou uma função agregada. Se a coluna da consulta selecionada não for uma coluna agrupada ou uma função agregada, os dados do primeiro registro no grupo serão retornados. Compare as duas instruções SQL a seguir: Na segunda instrução SQL, cname não é uma coluna de agrupamento nem uma função de agregação. Portanto, no grupo liming, cname pega a primeira parte dos dados.
mysql> select * from c; +-----+-------+----------+ | CNO | CNAME | CTEACHER | +-----+-------+----------+ | 1 | 数学 | liming | | 2 | 语文 | liming | | 3 | 历史 | xueyou | | 4 | 物理 | guorong | | 5 | 化学 | liming | +-----+-------+----------+ 5 rows in set (0.00 sec) mysql> select cteacher, count(cteacher), cname from c group by cteacher; +----------+-----------------+-------+ | cteacher | count(cteacher) | cname | +----------+-----------------+-------+ | guorong | 1 | 物理 | | liming | 3 | 数学 | | xueyou | 1 | 历史 | +----------+-----------------+-------+ 3 rows in set (0.00 sec) ————————————————
A palavra-chave having é usada para filtrar os dados agrupados, e a função é equivalente a onde antes do agrupamento, mas os requisitos são mais rígidos. A condição do filtro é uma função agregada (... tendo contagem (x)> 1), ou a coluna que aparece após selecionar (selecione col1, col2 ... agrupar por x tendo col1> 1)
Atualização multi-mesa
- update tableA a inner join tableB b on a.xxx = b.xxx set a.col1 = xxx, b.col1 = xxx where ...Exclusão de várias mesas
- delete a, b from tableA a inner join tableB b on a.xxx = b.xxx where a.col1 = xxx and b.col1 = xxx
DCL
DCL é uma abreviatura de linguagem de controle de dados (Data Control Language), que contém informações como GRANTo comando e similares, e está principalmente relacionada aos privilégios do sistema de banco de dados, permissões e outros controles.
GRANT: Permissão para permitir que usuários acessem o banco de dadosREVOKE: Revogar a autoridade de acesso do usuário concedida pelo comando GRANT
TCL
TCL é uma abreviatura de linguagem de controle de transação (Transaction Control Language) para processamento de transações de banco de dados
COMMIT: Confirme a transaçãoROLLBACK: Reverter a transação em caso de qualquer erro
Paradigma
A padronização de banco de dados, também conhecida como regularização e padronização, é uma série de princípios e técnicas de design de banco de dados para reduzir a redundância de dados no banco de dados e melhorar a consistência dos dados. Edgar Cod, o inventor do modelo relacional, primeiro propôs este conceito e definiu os conceitos de primeira forma normal, segunda forma normal e terceira forma normal no início dos anos 1970, e em conjunto com Raymond F. Boyce em 1974 O paradigma aprimorado de o terceiro paradigma-paradigma BC. As exceções incluem o quarto paradigma para a dependência de múltiplos valores, o quinto paradigma, o paradigma DK e o sexto paradigma para a dependência de conexão.
Agora, o design do banco de dados satisfaz no máximo 3NF . Geralmente, acredita-se que o paradigma é muito alto. Embora tenha melhores restrições no relacionamento de dados, ele também leva ao aumento da tabela de relacionamento de dados e torna o IO do banco de dados mais ocupado. restrições de relacionamento que eram originalmente tratadas pelo banco de dados agora são mais Concluídas no banco de dados usando o programa.
Primeira forma normal
Definição: Todos os campos (colunas) no banco de dados são atributos únicos e não podem ser divididos . Este único atributo é composto de tipos de dados básicos, como inteiro, ponto flutuante, string, etc. A primeira forma normal é garantir a atomicidade da coluna.
A tabela acima não corresponde à primeira forma normal. A coluna de endereço pode ser dividida em províncias, cidades, distritos, etc.
Segunda forma normal
Definição: uma tabela de banco de dados não existe para quaisquer campos não-chave do campo-chave dependência parcial da função dependente da parte funcional significa que há uma combinação de palavras-chave caso de uma chave de decisão não-palavra-chave segundo paradigma é satisfeito com base no primeiro paradigma, elimine a dependência parcial de colunas de chave não primária na chave primária combinada
Na tabela acima, se você deseja definir a chave primária, só pode combinar o nome do produto e o nome do fornecedor para formar uma chave primária conjunta. Mas o preço ea classificação depende apenas do nome do produto , telefone fornecedor só dependem nome do fornecedor , de modo que a tabela acima não cumprir o segundo paradigma, pode ser alterado para o seguinte forma: Tabela de informações sobre o produto
Formulário de Informação do Fornecedor
Tabela de associação fornecedor de commodities
Terceira forma normal
Definição: Todos os atributos de chave não primária estão relacionados apenas a chaves candidatas, ou seja, os atributos de chave não primária devem ser independentes e não relacionados. A terceira forma normal é eliminar a dependência transitiva entre colunas com base no cumprimento da segunda forma normal .
Na tabela acima, a descrição da classificação do produto depende da classificação , e a classificação depende do nome do produto , ao invés da descrição da classificação que depende diretamente do nome do produto . Isso forma uma dependência transitiva , portanto, não se ajusta à terceira forma normal. Pode ser alterado para o seguinte formulário
Mesa de commodities
Tabela de classificação de commodities
No projeto de banco de dados, seguir paradigma e antiparadigma sempre foi uma questão controversa. Seguir o paradigma tem melhores restrições nas relações de dados e reduz a redundância de dados, o que pode garantir melhor a consistência dos dados. O antiparadigma é para melhor desempenho. Portanto, não existe um padrão claro de paradigma ou antiparadigma, e aquele que se adequa ao seu cenário de negócios é o melhor.
No design anti-paradigma, as seguintes questões precisam ser consideradas, nomeadamente inserir exceção, atualizar exceção e excluir exceção
- Exceção de inserção: Se existe uma entidade com a existência de outra entidade, ou seja, a ausência de uma entidade não é capaz de representar essa entidade, então há uma exceção de inserção para esta tabela.
- Exceção de atualização: se você precisar atualizar várias linhas ao alterar um único atributo de uma instância de entidade correspondente à tabela, significa que a tabela tem uma exceção de atualização
- Excluir exceção: se você excluir uma linha da tabela para indicar que uma instância de entidade falhou, causando a perda de outras informações de instância de entidade, esta tabela terá uma exceção de exclusão
Pegue uma tabela que viola a segunda forma normal como exemplo
Se o fornecedor da segunda planta de fabricação de coque ainda não iniciou o fornecimento, não há um segundo registro na tabela, e o número de telefone do fornecedor não pode ser registrado, então haverá uma exceção de inserção; se o preço da coque precisar ser aumentado , a tabela precisa ser atualizada. Se você excluir as informações de abastecimento da segunda fábrica de Coca-Cola, o telefone do fornecedor também será perdido, portanto, há uma exclusão anormal.
Geralmente, haverá atualização anormal e exclusão de tabelas anormais.
Mesa horizontal e mesa vertical
Script SQL
# 横表
CREATE TABLE `table_h2z` (
`name` varchar(32) DEFAULT NULL,
`chinese` int(11) DEFAULT NULL,
`math` int(11) DEFAULT NULL,
`english` int(11) DEFAULT NULL
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
/*Data for the table `table_h2z` */
insert into `table_h2z`(`name`,`chinese`,`math`,`english`) values
('mike',45,43,87),
('lily',53,64,88),
('lucy',57,75,75);
# 纵表
CREATE TABLE `table_z2h` (
`name` varchar(32) DEFAULT NULL,
`subject` varchar(8) NOT NULL DEFAULT '',
`score` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `table_z2h` */
insert into `table_z2h`(`name`,`subject`,`score`) values
('mike','chinese',45),
('lily','chinese',53),
('lucy','chinese',57),
('mike','math',43),
('lily','math',64),
('lucy','math',75),
('mike','english',87),
('lily','english',88),
('lucy','english',75);
Mesa horizontal para mesa vertical
SELECT NAME, 'chinese' AS `subject`, chinese AS `score` FROM table_h2z
UNION ALL
SELECT NAME, 'math' AS `subject`, math AS `score` FROM table_h2z
UNION ALL
SELECT NAME, 'english' AS `subject`, english AS `score` FROM table_h2zResultados do
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| mike | chinese | 45 |
| lily | chinese | 53 |
| lucy | chinese | 57 |
| mike | math | 43 |
| lily | math | 64 |
| lucy | math | 75 |
| mike | english | 87 |
| lily | english | 88 |
| lucy | english | 75 |
+------+---------+-------+
9 rows in set (0.00 sec)
Mesa vertical para horizontal
SELECT NAME,
SUM(CASE `subject` WHEN 'chinese' THEN score ELSE 0 END) AS chinese,
SUM(CASE `subject` WHEN 'math' THEN score ELSE 0 END) AS math,
SUM(CASE `subject` WHEN 'english' THEN score ELSE 0 END) AS english
FROM table_z2h
GROUP BY NAME
Resultados do
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| lily | 53 | 64 | 88 |
| lucy | 57 | 75 | 75 |
| mike | 45 | 43 | 87 |
+------+---------+------+---------+
3 rows in set (0.00 sec)referência
Autor: Sicimike
Fonte: https://blog.csdn.net/Baisitao_/article/details/104714764