prefácio
Pelo conteúdo anterior, acredito que todos saibam que o espaço de tabela é um conceito abstrato. Para o espaço de tabela do sistema, corresponde ao 一个或多个arquivo real no sistema de arquivo; para cada espaço de tabela independente, corresponde à 一个tabela nomeada no arquivo system.name .ibddo arquivo atual.
Você pode pensar no tablespace como um pool dividido em muitas páginas.Quando queremos inserir um registro para uma determinada tabela, retiramos uma página correspondente do pool e escrevemos os dados nela.
O conteúdo deste capítulo irá aprofundar os detalhes do espaço de tabela e levá-lo a nadar no pool da estrutura de armazenamento do InnoDB. Como haverá mais conceitos envolvidos neste capítulo, embora esses conceitos não sejam difíceis, eles dependem um do outro, por isso aconselho a leitura:不要跳着看
Índice
- 1. Lembre-se de algum conhecimento antigo
- Dois espaços de mesa independentes
- Três, a estrutura do espaço de tabela do sistema
- Quatro. Resumo
1. Lembre-se de algum conhecimento antigo
1.1 Tipos de páginas
Deixe-me enfatizar aqui novamente que o InnoDB gerencia o espaço de armazenamento 页em unidades. Nosso índice agrupado (ou seja, dados completos da tabela) e outros índices secundários são salvos no espaço da tabela na forma de árvore B+ e B+ Os nós da árvore são dados Páginas. Como dissemos anteriormente, o nome do tipo desta página de dados é na verdade: fil_page_index. Além desse tipo de página para armazenar dados de índice, o InnoDB também projeta vários tipos diferentes de páginas para diferentes finalidades. Acredito que você deva estar familiarizado com a seguinte tabela:
| Digite o nome | hexadecimal | descrever |
|---|---|---|
| fil_page_type_allocated | 0x0000 | alocação mais recente, ainda não usada |
| fil_page_undo_log | 0x0002 | desfazer página de registro |
| fil_page_inode | 0x0003 | nó de informação do segmento |
| fil_page_ibuf_free_list | 0x0004 | inserir lista livre de buffer |
| file_page_ibuf_bitmap | 0x0005 | inserir mapa de bits do buffer |
| fil_page_type_sys | 0x0006 | página do sistema |
| fil_page_type_trx_sys | 0x0007 | dados do sistema transacional |
| fil_page_type_fsp_hdr | 0x0008 | Informações do cabeçalho do espaço de tabela |
| fil_page_type_xdes | 0x0009 | Página de descrição estendida |
| fil_page_type_blob | 0x000a | página de estouro |
| fil_page_index | 0x45bf | Páginas de índice, também conhecidas como páginas de dados |
Como há um prefixo de fil_pageou antes do tipo de página fil_page_type, para simplificar, omitiremos esses prefixos ao explicar o tipo de página posteriormente. Por exemplo, fil_page_type_allocatedo tipo é chamado allocatedde tipo e fil_page_indexo tipo é chamado indexde tipo, etc.
1.2 Partes comuns da página
Dissemos MySQL之数据页结构no artigo anterior que a página de dados, ou seja, indexa página do tipo consiste em 7 partes, duas das quais são comuns a todos os tipos de páginas (é claro que não posso esperar que você se lembre do que eu disse, então novamente aqui) Qualquer tipo de página tem a seguinte estrutura geral:
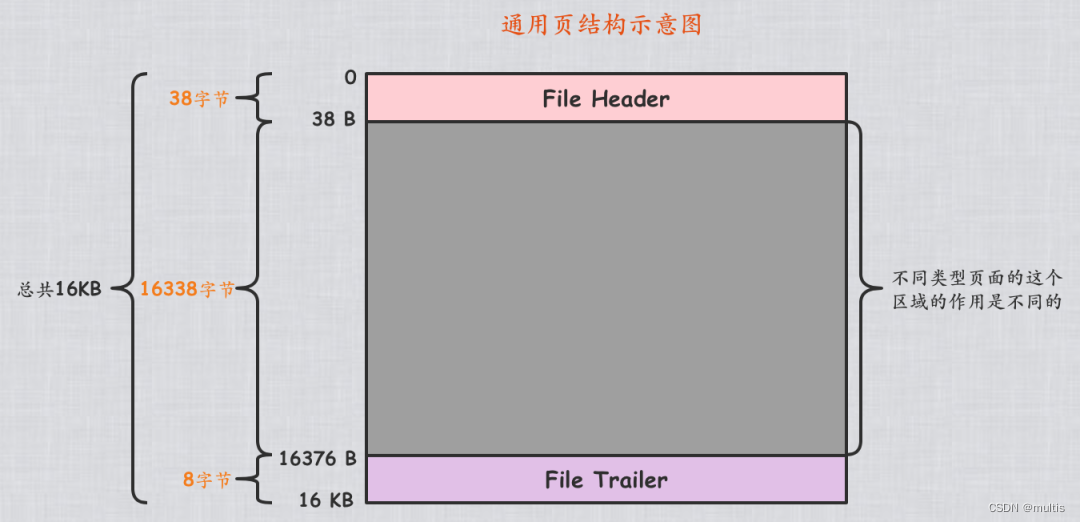
Como você pode ver na imagem acima, qualquer tipo de página conterá essas duas seções:
File Header:Algumas informações gerais sobre a página de registroFile Trailer:Verifique a integridade da página para garantir a consistência do conteúdo quando ele for atualizado da memória para o disco.
Para File Trailernão enfatizarmos muito, vamos enfatizar File Headernovamente os vários componentes aqui:
| nome | Tamanho (unidade: B) | descrever |
|---|---|---|
| fil_page_space_or_chksum | 4 | Soma de verificação da página (valor da soma de verificação) |
| fil_page_offset | 4 | número de página |
| file_page_prev | 4 | número da página anterior |
| fil_page_next | 4 | Número da página da próxima página |
| fil_page_lsn | 8 | A posição correspondente da sequência de log quando a página foi modificada pela última vez (o nome em inglês é: log sequence number) |
| fil_page_type | 2 | tipo de página |
| fil_page_file_flush_lsn | 8 | Ele é definido apenas em uma página do espaço de tabela do sistema, o que significa que o arquivo foi atualizado pelo menos para o valor lsn correspondente |
| fil_page_arch_log_no_or_space_id | 4 | a qual espaço de tabela a página pertence |
Agora, exceto pelos dois campos com LSN no nome que você pode não entender, os outros campos devem ser muito familiares, mas ainda queremos enfatizar os seguintes pontos:
-
Cada página no espaço de tabela corresponde a um número de página, ou seja
fil_page_offset, o número da página é composto por 4 bytes, ou seja, 32 bits, portanto um espaço de tabela pode ter no máximo2³²páginas, se de acordo com o tamanho padrão da página 16kb é o máximo64tbde dados suportados por um espaço de tabela. O número da primeira página do espaço de tabela é 0 e os números das páginas subsequentes são 1, 2, 3... e assim por diante -
Alguns tipos de páginas podem formar uma lista encadeada e as páginas na lista encadeada não podem ser armazenadas em ordem física, mas armazenam os números de página da página anterior e da próxima página de acordo com a
fil_page_prevsomafil_page_next. Deve-se notar que esses dois campos são principalmente paraindexos tipos de páginas, ou seja, as páginas de dados das quais falamos antes são usadas para estabelecer uma lista duplamente encadeada para cada camada de nós após o estabelecimento da árvore B+. de páginas não usam esses dois campos -
O tipo de cada página é
fil_page_typeindicado por, por exemplo, o valor deste campo de uma página de dados é0x45bf, apresentaremos vários tipos de páginas posteriormente, e diferentes tipos de páginas têm valores diferentes neste campo
Dois espaços de mesa independentes
Sabemos que o InnoDB suporta muitos tipos de tablespaces, e este artigo enfoca a estrutura de 独立表空间e 系统表空间. Suas estruturas são relativamente semelhantes, mas como o espaço de tabela do sistema contém algumas informações adicionais sobre todo o sistema, primeiro apresentaremos um espaço de tabela independente mais simples e falaremos sobre a estrutura do espaço de tabela do sistema mais tarde
2.1 O conceito de Extensão
Há muitas páginas no espaço de tabela 为了更好的管理这些页面e o InnoDB propõe extento conceito de área (nome em inglês: ). Para uma página de 16KB, 64as páginas consecutivas são uma área, ou seja, uma área ocupa o 1MBtamanho de espaço padrão. Quer seja um espaço de tabela do sistema ou um espaço de tabela independente, pode ser considerado como composto por várias áreas 每256个区被划分成一组. Faça um desenho para mostrar que é assim:
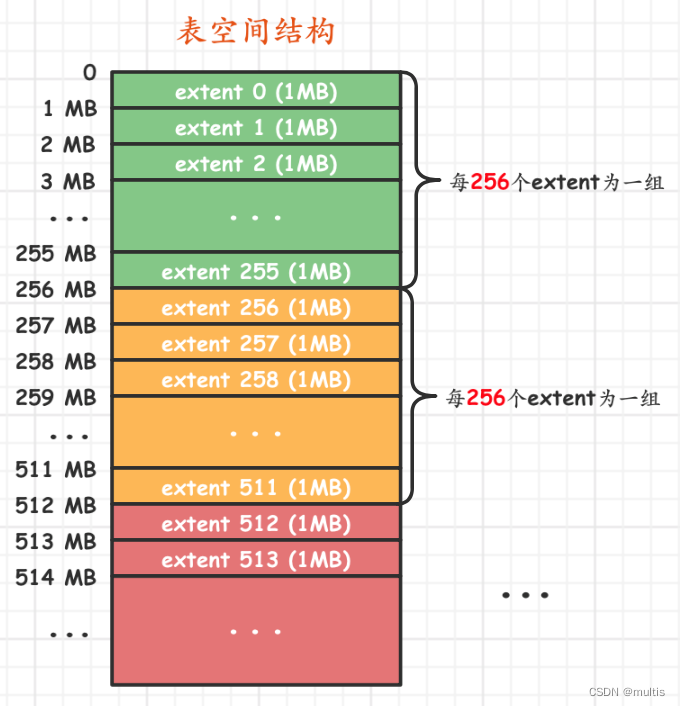
Entre eles , extent 0 ~ extent 255esses 256 distritos são contados 第一个组, extent 256 ~ extent 511esses 256 distritos são contados 第二个组e extent 512 ~ extent 767esses 256 distritos são contados 第三个组(a figura acima não desenha todos os distritos do terceiro grupo, por favor, decida-se), e assim por diante, mais grupos pode ser dividido. As primeiras páginas desses grupos são de tipo semelhante, por exemplo:
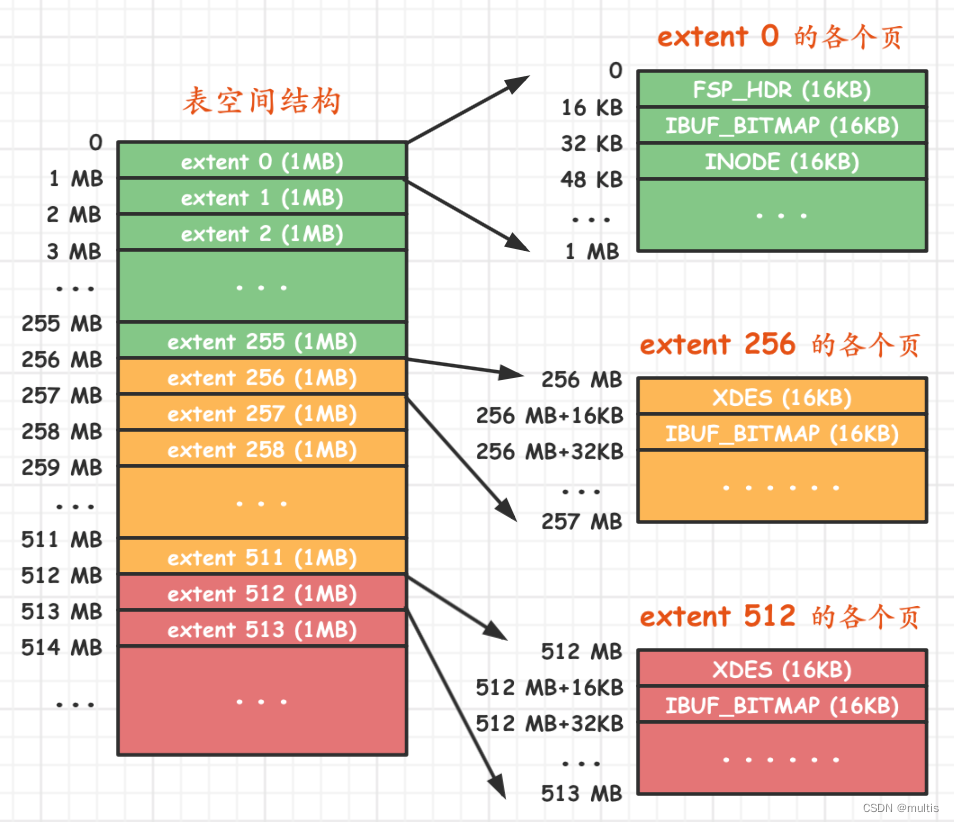
Da figura acima podemos saber as seguintes informações:
-
第一个组最开始的3个页面的类型是固定的, ou seja, os tipos das três primeiras páginas na área da extensão 0 são fixos, e são eles:FSP_HDR类型:Este tipo de página é usado para registrar表空间的一些整体属性以及本组所有的区as propriedades de todas as 256 áreas, ou seja, extensão 0 ~ extensão 255. Uma coisa a observar é que todo o tablespace está disponível apenas一个FSP_HDR类型的页面.IBUF_BITMAP类型:Este tipo de página contém本组所有的区的所有页面关于INSERT BUFFERinformações armazenadas.INODE类型:Esse tipo de página armazena váriasINODEestruturas de dados chamadas .
-
Para o restante
最开始的2个页面的类型是固定dos grupos, ou seja, os tipos das duas primeiras páginas de extensão 256 e extensão 512 são fixos, respectivamente:XDES类型:O nome completo é Extent Descriptor,用来登记本组256个区的属性ou seja, para este tipo de página na extensão 256, os atributos dessas áreas são armazenados na extensão 256 ~ extensão 511, e para este tipo de página na extensão 512, é armazenado na extensão 512 ~ extensão 767 propriedades dessas áreas. A página de tipo FSP_HDR apresentada acima é realmente semelhante à página de tipo XDES, exceto que a página de tipo FSP_HDR armazenará adicionalmente alguns atributos de espaço de tabela.IBUF_BITMAP类型:O mesmo que acima, sem mais explicações aqui.
A estrutura da macro é assim, e você não precisa memorizar os substantivos nela com muita clareza, desde que você se lembre aproximadamente:表空间被划分为许多连续的区,每个区默认由64个页组成,每256个区划分为一组,每个组的最开始的几个页面类型是固定的就好了
2.2 O conceito de segmento (Segment)
Se a quantidade de dados em nossa tabela for pequena, como se houvesse apenas dezenas ou centenas de dados em sua tabela, o conceito de área de fato não é necessário, porque os dados correspondentes podem ser armazenados em algumas páginas simples, mas em no estágio posterior, você não pode reter mais e mais registros na tabela.
Teoricamente falando, usar apenas o conceito de página sem introduzir o conceito de área não tem nenhum efeito no funcionamento do mecanismo de armazenamento, mas vamos considerar o seguinte cenário:
- Cada vez que inserimos um registro na tabela, basicamente inserimos dados na tabela
聚簇索引e所有二级索引nos nós da árvore B+ representada. E as páginas em cada camada da árvore B+ formarão uma lista duplamente encadeada, se assim for以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能离得非常远. Quando apresentamos os cenários aplicáveis do índice de árvore B+范围查询只需要定位到最左边的记录和最右边的记录, mencionamos especificamente que basta digitalizar ao longo da lista duplamente vinculada e, se houver duas páginas adjacentes na lista vinculada物理位置离得非常远, é o chamado随机I/O.
Dica:
A velocidade do disco é várias ordens de grandeza diferente da velocidade da memória, e a E/S aleatória é muito lenta, portanto, devemos tentar tornar as posições físicas das páginas adjacentes na lista encadeada adjacentes umas às outras, de modo que somente ao executar consultas de intervalo, as chamadas E/S sequenciais podem ser usadas.
É por isso que o conceito de extensão foi introduzido 一个区就是在物理位置上连续的64个页(1M). Quando a quantidade de dados na tabela é grande, ao alocar espaço para um índice, ele não é mais alocado em unidades de páginas, mas em unidades de regiões. Mesmo quando os dados na tabela são muito, muito grandes, pode ser alocados de uma só vez. Alocar várias regiões contíguas. Embora possa causar um pouco de desperdício de espaço (os dados são insuficientes para preencher toda a área), mas do ponto de vista do desempenho, pode eliminar muitas E/S aleatórias e os méritos superam as desvantagens.
A consulta de intervalo que mencionamos é, na verdade 对B+树叶子节点中的记录进行顺序扫描, e se você não distinguir entre nós folha e não folha e colocar todas as páginas representadas pelos nós na área aplicada, o efeito da verificação de intervalo será bastante reduzido. Portanto, o InnoDB trata os nós folha e não folha da árvore B+ de maneira diferente, ou seja 叶子节点有自己独有的区, , 非叶子节点也有自己独有的区. 存放叶子节点的区的集合就算是一个段(segment),存放非叶子节点的区的集合也算是一个段. Isso é 一个索引会生成2个段,一个叶子节点段,一个非叶子节点段.
Por padrão, uma tabela que usa o mecanismo de armazenamento InnoDB possui apenas um índice clusterizado, e um índice gerará 2 segmentos, e uma 段是以区为单位申请存储空间área ocupa 1M de espaço de armazenamento por padrão; portanto, por padrão, uma pequena tabela com apenas alguns registros também precisa de 2M espaço de armazenamento? Preciso solicitar 2M a mais de espaço de armazenamento toda vez que adicionar um índice no futuro?
Isso é simplesmente um grande desperdício para tabelas que armazenam menos registros. O InnoDB é bastante econômico e, claro, essa situação é levada em consideração. O cerne desse problema é que as áreas que apresentamos até agora são todas muito puras, ou seja, uma área é totalmente alocada para um determinado segmento, ou todas as páginas de uma área existem para armazenar os dados do mesmo segmento. os dados do segmento não preenchem todas as páginas da zona, as páginas restantes não podem ser usadas para outros fins. Agora, para considerar o fato de que alocar para um determinado segmento em unidades de uma área completa é muito desperdício de espaço de armazenamento para uma tabela com uma pequena quantidade de dados, o InnoDB propõe que em uma área fragmentada, nem todas as páginas sejam para 一个碎片(fragment)区的概念o existem dados do mesmo segmento, mas as páginas na área fragmentada podem ser usadas para finalidades diferentes. Por exemplo, algumas páginas são usadas para o segmento A, algumas páginas são usadas para o segmento B e algumas páginas nem pertencem a nenhum segmento . A área fragmentada pertence diretamente ao espaço de tabela e não pertence a nenhum segmento. Assim, a estratégia de alocação de espaço de armazenamento para um determinado segmento é a seguinte:
-
No início da inserção de dados na tabela, o segmento aloca espaço de armazenamento em unidades de uma única página de uma área fragmentada
-
当某个段已经占用了32个碎片区页面之后, o espaço de armazenamento será alocado em unidades de áreas completas
Agora, um segmento não pode ser definido apenas como uma coleção de certas áreas, mas, mais precisamente, deve ser uma coleção de algumas páginas dispersas e algumas áreas completas. Além dos segmentos de nó folha e segmentos de nó não folha do índice, o InnoDB também possui segmentos definidos para armazenar alguns dados especiais, como segmentos de rollback. Claro, não nos importamos com outros tipos de segmentos agora, e agora só precisamos saber Um segmento é uma coleção de páginas fragmentadas, bem como seções completas.
2.3 Classificação das zonas
O espaço de mesa é composto por várias áreas, que podem ser divididas em 4 tipos:
-
空闲的区:Nenhuma página nesta zona é usada atualmente. -
有剩余空间的碎片区:Indica que ainda há páginas disponíveis na área fragmentada. -
没有剩余空间的碎片区:Indica que todas as páginas na área fragmentada são usadas e não há páginas livres. -
附属于某个段的区:Cada índice pode ser dividido em segmentos de nó folha e segmentos de nó não folha. Além disso, o InnoDB também definirá alguns segmentos de finalidade especial. Quando a quantidade de dados nesses segmentos for grande, a área será usada como a unidade básica de alocação .
Esses 4 tipos de zonas também podem ser referidos como os 4 estados da zona. O InnoDB define substantivos específicos para esses 4 estados de zonas:
| nome do estado | significado |
|---|---|
| livre | área livre |
| free_frag | Área fragmentada com espaço livre |
| full_frag | Área fragmentada sem espaço restante |
| fseg | zona anexada a um segmento |
É preciso enfatizar novamente que free、free_frag和full_fragos distritos desses três estados são independentes, portanto são 直属于表空间; e fsegos distritos do estado são 附属于某个段.
Dicas
Se você comparar o espaço de tabela com um país, um segmento equivale a uma província e um distrito equivale a uma cidade. Uma cidade geral pertence a uma determinada província, assim como todos os distritos do estado fseg pertencem a um determinado segmento. No entanto, os três estados de free, free_frag e full_frag estão diretamente sob o tablespace, assim como Beijing, Tianjin e Shanghai estão diretamente sob o gerenciamento de estado.
Para facilitar o gerenciamento dessas áreas, o InnoDB projetou uma estrutura chamada XDES Entry (nome completo é Extent Descriptor Entry), cada área corresponde a uma estrutura XDES Entry, que registra alguns atributos da área correspondente. Vamos primeiro olhar a imagem para ter uma compreensão geral dessa estrutura:
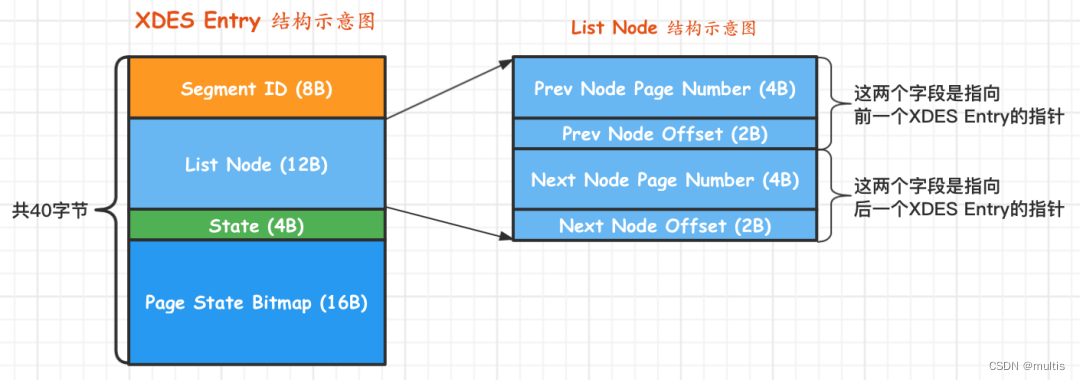
Na figura, podemos ver que a Entrada XDES é uma estrutura de 40 bytes, dividida aproximadamente em 4 partes. A interpretação de cada parte é a seguinte:
-
ID do Segmento (8 bytes)
Cada segmento possui um número único, que é representado pelo ID.O campo ID do Segmento aqui indica o segmento onde a área está localizada. Claro que a premissa é que a área foi alocada para um segmento, caso contrário o valor deste campo não tem sentido. -
A
parte List Node (12 bytes) pode conectar várias estruturas XDES Entry em uma lista encadeada. Dê uma olhada na estrutura do List Node: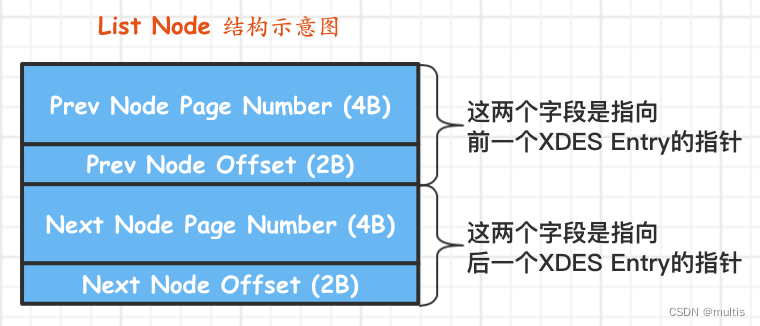
Se quisermos localizar uma determinada posição no espaço de tabela, precisamos apenas especificar o número da página e o deslocamento de página da posição no número de página especificado. então:-
A combinação de Prev Node Page Number e Prev Node Offset é um ponteiro para a entrada XDES anterior
-
A combinação de Next Node Page Number e Next Node Offset é um ponteiro para a próxima entrada XDES
-
-
Estado (4 bytes)
Este campo indica o estado da zona. Os valores opcionais são os quatro que mencionamos anteriormente, a saber: free, free_frag, full_frag e fseg. -
Page State Bitmap (16 bytes)
Esta parte ocupa um total de 16 bytes, ou seja, 128 bits. Dizemos que uma área possui 64 páginas por padrão, e esses 128 bits são divididos em 64 partes, sendo que cada parte possui 2 bits, correspondendo a uma página na área. Por exemplo, o 1º e o 2º bits da parte do Bitmap do estado da página correspondem à 1ª página da área, o 3º e o 4º bits correspondem à 2ª página da área e assim por diante, a parte do bitmap do estado da página é a 127ª e a 128ª bits do correspondente à 64ª página na zona. O primeiro bit desses dois bits indica se a página correspondente está livre e o segundo bit ainda não foi usado
2.4 Lista encadeada de entradas XDES
Até agora, propusemos conceitos como área, segmento, área de fragmento, área anexada a um segmento e Entrada XDES. Nossa intenção original de tornar as coisas tão problemáticas é apenas melhorar a eficiência da inserção de dados na tabela sem reduzir a quantidade de dados. A tabela desperdiça espaço. Agora sabemos que inserir dados na tabela é essencialmente inserir dados nos segmentos de nó folha e segmentos de nó não folha de cada índice na tabela. Também sabemos que áreas diferentes têm estados diferentes e, em seguida, voltam ao ponto de partida original e seguir em frente. O processo de inserção de dados em um segmento:
-
Quando houver menos dados no segmento, ele primeiro verificará se existe
free_fraguma área no espaço da tabela com status , ou seja, encontrará uma área fragmentada com espaço livre. Se for encontrada, pegue algumas páginas espalhadas do área e insira os dados nela. Caso contrário, vá para o espaço de tabela para solicitar umafreeárea com um estado de , ou seja, uma área livre, altere o estado da área para free_frag e, em seguida, pegue algumas páginas fragmentadas do novo área aplicada e insira os dados nela. Mais tarde, quando diferentes segmentos usarem páginas fragmentadas, elas serão retiradas desta área até que não haja espaço livre nesta área, e então o status desta área se tornará full_frag.A questão agora é como você sabe quais áreas no espaço de tabela estão livres, quais áreas são free_frag e quais áreas são full_frag? Você deve saber que o tamanho do espaço da tabela pode ser aumentado continuamente. Quando ele crescer para o nível GB, o número de distritos será de milhares. Não podemos percorrer as estruturas de entrada XDES correspondentes a esses distritos todas as vezes, certo? Neste momento, é hora da parte do nó da lista no XDES Entry ter um efeito milagroso. Podemos fazer três coisas através do ponteiro no nó da lista:
Conecte a estrutura de entrada XDES correspondente à área livre por meio do nó da lista para formar uma lista encadeada. Chamamos essa lista encadeada de lista encadeada livre.
-
Conecte a estrutura de entrada XDES correspondente à área cujo status é free_frag em uma lista encadeada por meio do nó da lista. Chamamos essa lista encadeada de lista encadeada free_frag.
-
Conecte a estrutura XDES Entry correspondente à área cujo status é full_frag em uma lista encadeada por meio do nó de lista. Chamamos essa lista encadeada de lista encadeada full_frag.
Dessa forma, sempre que quisermos encontrar uma área de estado free_frag, retiramos diretamente o nó principal da lista vinculada free_frag, pegamos algumas páginas espalhadas desse nó para inserir dados e modificamos quando a área correspondente a esse nó é usada O valor do campo de estado desse nó é então movido da lista vinculada free_frag para a lista vinculada full_frag. Da mesma forma, se não houver nó na lista vinculada free_frag, pegue diretamente um nó da lista vinculada gratuita para mover para o estado da lista vinculada free_frag e modifique o valor do campo de estado do nó para free_frag e, em seguida, obtenha o fragmento da área correspondente a este nó A página está ótima.
-
-
Quando os dados do segmento tiverem ocupado 32 páginas dispersas, solicite diretamente uma área completa para inserir os dados.
Ainda a mesma pergunta, como saber quais áreas pertencem a qual segmento? Em seguida, percorrer cada estrutura de entrada XDES? É impossível atravessar, e é impossível atravessar nesta vida.Há uma lista encadeada e é um fio de lã. Portanto, adicionamos todas as estruturas de entrada xdes correspondentes à área fseg a uma lista encadeada? Bobagem, como diferentes segmentos podem compartilhar uma área? Deseja armazenar o segmento do nó folha do índice a e o segmento do nó folha do índice b em uma zona? Obviamente, queremos que cada segmento tenha sua própria lista vinculada, para que possamos criar uma lista vinculada com base no número do segmento (ou seja, id do segmento) Quantas listas vinculadas podemos construir com tantos segmentos quantos forem? Parece ser um pouco problemático, porque pode haver muitas áreas em um segmento, algumas áreas são totalmente gratuitas, algumas áreas ainda têm algumas páginas disponíveis e algumas áreas não têm páginas gratuitas para usar, então precisamos continuar a pontos de detalhe, o innodb cria três listas vinculadas para a estrutura de entrada xdes correspondente à zona em cada segmento:
- Lista encadeada livre: No mesmo segmento, a estrutura XDES Entry correspondente à área onde todas as páginas são livres será adicionada a esta lista encadeada. Observe que é diferente da lista encadeada livre pertencente diretamente ao espaço de tabela.A lista encadeada livre aqui é anexada a um determinado segmento.
- lista encadeada not_full: No mesmo segmento, a estrutura XDES Entry correspondente à área que ainda possui espaço livre será adicionada a esta lista encadeada.
- Lista encadeada completa: No mesmo segmento, a estrutura XDES Entry correspondente à área que não possui espaço livre será adicionada a esta lista encadeada.
Ressalta-se novamente que cada índice corresponde a dois segmentos, e cada segmento manterá as três listas encadeadas acima. Por exemplo, considere a seguinte tabela:
create table demo9 (c1 int not null auto_increment,c2 varchar(100),c3 varchar(100),primary key (c1), key idx_c2 (c2));
Esta tabela t possui dois índices, um índice clusterizado e um índice secundário idx_c2, então esta tabela possui 4 segmentos no total, e cada segmento manterá as 3 listas encadeadas acima, um total de 12 listas encadeadas, mais o que dissemos acima Existem 3 listas vinculadas pertencentes diretamente ao espaço de tabela e um total de 15 listas vinculadas precisam ser mantidas em todo o espaço de tabela independente. Portanto, se o segmento inserir dados quando a quantidade de dados for relativamente grande, ele obterá primeiro o nó principal da lista vinculada not_full e inserirá os dados diretamente na área correspondente ao nó principal. usado, mova o nó para a lista encadeada completa.
2.4.1 Nó base da lista encadeada
Existem muitas listas vinculadas apresentadas acima, como localizar essas listas vinculadas ou como localizar a posição do nó principal ou do nó final de uma lista vinculada no espaço de tabela? Obviamente, o InnoDB considerou esse problema e projetou uma estrutura chamada List Base Node, que é traduzida para o chinês como o nó base da lista encadeada. Essa estrutura contém ponteiros para o nó principal e o nó final da lista encadeada e informações sobre quantos nós estão contidos na lista encadeada. Vamos desenhar um diagrama para ver o diagrama esquemático dessa estrutura:

Cada lista encadeada que introduzimos acima corresponde a uma estrutura de nó base de lista, onde:
- O comprimento da lista indica quantos nós a lista encadeada possui.
- Número da Página do Primeiro Nó e Deslocamento do Primeiro Nó indicam a posição do nó principal da lista encadeada no espaço de tabela.
- Número da Página do Último Nó e Deslocamento do Último Nó indicam a posição do nó final da lista encadeada no espaço de tabela.
Geralmente, colocamos a estrutura do Nó Base da Lista correspondente a uma determinada lista encadeada em uma posição fixa no espaço de tabelas, de forma que fica muito simples localizar uma determinada lista encadeada.
2.4.2 Resumo da lista encadeada
Resumindo, o espaço de tabela é composto por várias áreas, e cada área corresponde a uma estrutura XDES Entry. A estrutura XDES Entry correspondente à área pertencente diretamente ao espaço de tabela pode ser dividida em três listas encadeadas: free, free_frag e full_frag; Um segmento pode ser anexado a várias áreas, e a estrutura XDES Entry correspondente à área em cada segmento pode ser dividida em três listas encadeadas: free, not_full e full. Cada lista vinculada corresponde a uma estrutura List Base Node, que registra as posições dos nós principais e finais da lista vinculada e o número de nós contidos na lista vinculada. É justamente pela existência dessas listas encadeadas que o gerenciamento dessas áreas se tornou uma questão muito simples.
2.4.3 Estrutura da seção
Como dissemos anteriormente, um segmento na verdade não corresponde a uma área física contínua no tablespace, mas a um conceito lógico que consiste em várias páginas espalhadas e algumas áreas completas. Como cada zona tem uma entrada XDES correspondente para registrar os atributos nesta zona, o InnoDB define uma estrutura de entrada INODE para cada segmento para registrar os atributos no segmento. Vamos dar uma olhada no diagrama esquemático:
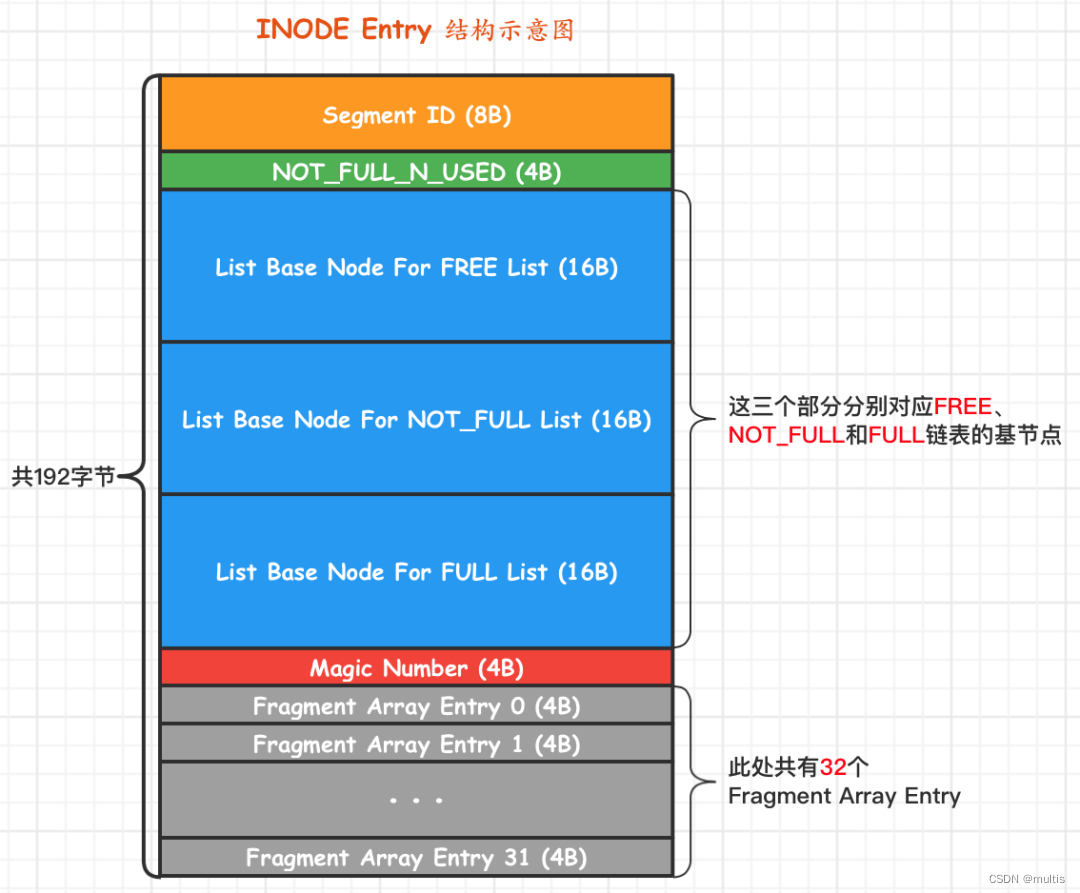
Suas várias partes são explicadas a seguir:
-
ID do segmento
refere-se ao número (ID) do segmento correspondente à estrutura de entrada INODE. -
O campo NOT_FULL_N_USED
refere-se a quantas páginas foram usadas na lista vinculada NOT_FULL. -
Os três nós base da lista
definem os nós base da lista para a lista encadeada livre, lista encadeada not_null e lista encadeada completa do segmento, respectivamente, de modo que, quando queremos encontrar o nó principal e o nó final de uma lista encadeada de um determinado segmento, podemos ir diretamente para esta parte para encontrá-los Corresponde ao Nó base da lista da lista encadeada. -
O valor de Magic Number
é usado para marcar se o INODE Entry foi inicializado (inicialização significa preencher os valores de cada campo). Se este número for um valor de 97937874, indica que a entrada INODE foi inicializada, caso contrário, não foi inicializada. (Não se preocupe com o significado especial deste valor, regulamentos). -
O segmento Fragment Array Entry
é uma coleção de algumas páginas fragmentadas e algumas áreas completas. Cada estrutura Fragment Array Entry corresponde a uma página fragmentada. Esta estrutura tem um total de 4 bytes, indicando o número da página fragmentada.
Combinado com esta estrutura de entrada INODE, você pode ter uma compreensão mais profunda de um segmento como uma coleção de páginas dispersas e algumas áreas completas
2.4.4 Tipo FSP_HDR
A primeira página do tablespace, página número 0. O tipo desta página é FSP_HDR, que armazena alguns atributos gerais do espaço de tabela e a estrutura de Entrada XDES correspondente dos 256 distritos do primeiro grupo. Veja o diagrama esquemático deste tipo de página diretamente:
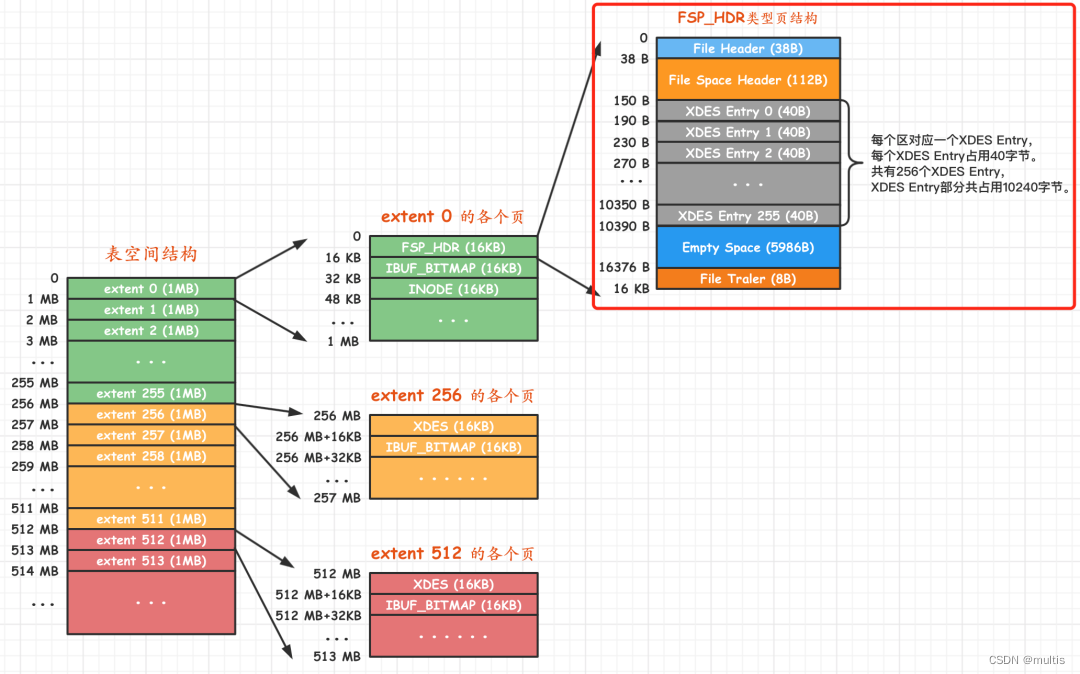 Uma página completa do tipo FSP_HDR é composta aproximadamente por 5 partes, e a interpretação específica de cada parte é a seguinte:
Uma página completa do tipo FSP_HDR é composta aproximadamente por 5 partes, e a interpretação específica de cada parte é a seguinte:
| nome | nome chinês | Tamanho do espaço ocupado | Descrição rápida |
|---|---|---|---|
| Cabeçalho do arquivo | cabeçalho do arquivo | 38 bytes | Algumas informações gerais na página |
| Cabeçalho do espaço de arquivo | cabeçalho do espaço de tabela | 112 bytes | Algumas informações gerais de atributo do espaço de tabela |
| Entrada XDES | Informações de descrição do distrito | 10240 bytes | Armazene as informações de atributos correspondentes aos 256 distritos deste grupo |
| Espaço vazio | espaço não utilizado | 5986 bytes | É usado para preencher a estrutura da página, que não tem significado prático |
| Trailer do arquivo | fim do arquivo | 8 bytes | Se a página de verificação está completa |
O Cabeçalho do Arquivo e o Trailer do Arquivo não são mais enfatizados. Entre as outras partes, Espaço Vazio é o espaço não utilizado. Vamos ignorá-lo e focar nas duas partes do Cabeçalho do Espaço do Arquivo e Entrada XDES.
Parte do cabeçalho do espaço de arquivo
Esta parte é usada para armazenar algumas informações gerais de atributo do espaço de tabela, consulte a figura a seguir para obter detalhes:
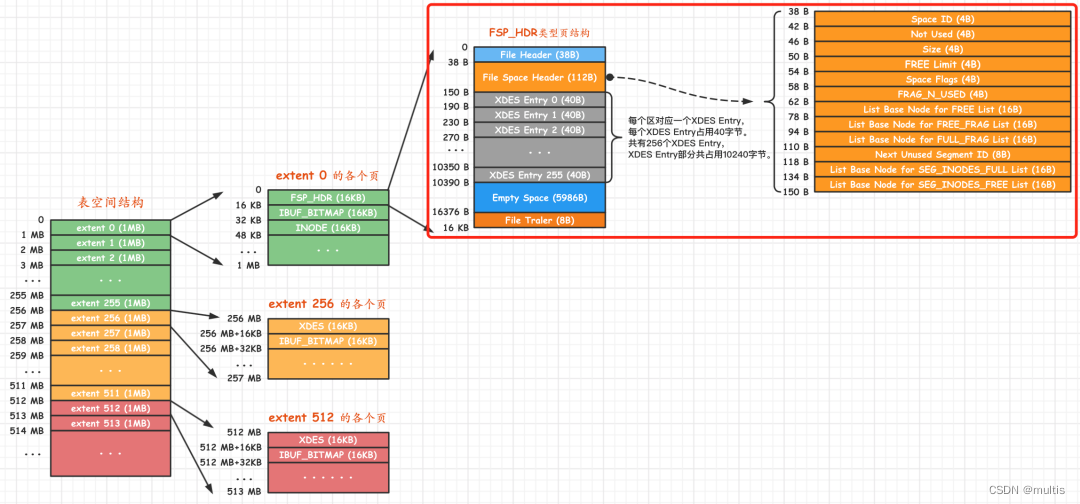
A seguir, uma breve descrição de cada atributo:
| nome | Tamanho do espaço ocupado | descrever |
|---|---|---|
| ID do espaço | 4 bytes | ID do espaço de tabela |
| Não usado | 4 bytes | Esses 4 bytes não são usados e podem ser ignorados |
| Tamanho | 4 bytes | O número de páginas ocupadas pelo tablespace atual |
| Limite GRATUITO | 4 bytes | O número mínimo de página que não foi inicializado e a estrutura XDES Entry correspondente à área maior ou igual a este número de página não foi adicionado à lista FREE |
| Bandeiras Espaciais | 4 bytes | Alguns atributos do espaço de tabela que ocupam espaço de armazenamento relativamente pequeno |
| FRAG_N_USED | 4 bytes | O número de páginas usadas na lista vinculada FREE_FRAG |
| Nó base de lista para lista GRATUITA | 16 bytes | O nó base da lista encadeada GRATUITA |
| Nó base da lista para a lista FREE_FRAG | 16 bytes | O nó base da lista encadeada FREE_FRAG |
| Nó base da lista para a lista FULL_FRAG | 16 bytes | O nó base da lista encadeada FULL_FRAG |
| Próximo ID de segmento não utilizado | 8 bytes | O próximo ID de segmento não utilizado no tablespace atual |
| List Base Node for SEG_INODES_FULL List | 16字节 | SEG_INODES_FULL链表的基节点 |
| List Base Node for SEG_INODES_FREE List | 16字节 | SEG_INODES_FREE链表的基节点 |
这里头的Space ID、Not Used、Size这三个字段大家肯定一看就懂,其他的字段我们再详细看一下:
-
List Base Node for FREE List、List Base Node for FREE_FRAG List、List Base Node for FULL_FRAG List
这三个大家看着太亲切了,分别是直属于表空间的FREE链表的基节点、FREE_FRAG链表的基节点、FULL_FRAG链表的基节点,这三个链表的基节点在表空间的位置是固定的,就是在表空间的第一个页面(也就是FSP_HDR类型的页面)的File Space Header部分。所以之后定位这几个链表就很简单啦。 -
FRAG_N_USED
这个字段表明在FREE_FRAG链表中已经使用的页面数量。 -
FREE Limit
我们知道表空间都对应着具体的磁盘文件,一开始我们创建表空间的时候对应的磁盘文件中都没有数据,所以我们需要对表空间完成一个初始化操作,包括为表空间中的区建立XDES Entry结构,为各个段建立INODE Entry结构,建立各种链表的各种操作。我们可以一开始就为表空间申请一个特别大的空间,但是实际上有绝大部分的区是空闲的,我们可以选择把所有的这些空闲区对应的XDES Entry结构加入FREE链表,也可以选择只把一部分的空闲区加入FREE链表,等啥时候空闲链表中的XDES Entry结构对应的区不够使了,再把之前没有加入FREE链表的空闲区对应的XDES Entry结构加入FREE链表,中心思想就是啥时候用到啥时候初始化,InnoDB采用的就是后者,他们为表空间定义了FREE Limit这个字段,在该字段表示的页号之前的区都被初始化了,之后的区尚未被初始化。 -
Next Unused Segment ID
表中每个索引都对应2个段,每个段都有一个唯一的ID,那当我们为某个表新创建一个索引的时候,就意味着要创建两个新的段。那怎么为这个新创建的段找一个唯一的ID呢?去遍历现在表空间中所有的段么?我们说过,遍历是不可能遍历的,这辈子都不可能遍历,InnoDB提出了这个名叫Next Unused Segment ID的字段,该字段表明当前表空间中最大的段ID的下一个ID,这样在创建新段的时候赋予新段一个唯一的ID值就so easy啦,直接使用这个字段的值就好了。 -
Space Flags
表空间对于一些布尔类型的属性,或者只需要寥寥几个比特位搞定的属性都放在了这个Space Flags中存储,虽然它只有4个字节,32个比特位大小,却存储了好多表空间的属性,详细情况如下表:
| 标志名称 | 占用空间(单位:bit) | 描述 |
|---|---|---|
| POST_ANTELOPE | 1 | 表示文件格式是否大于ANTELOPE |
| ZIP_SSIZE | 4 | 表示压缩页面的大小 |
| ATOMIC_BLOBS | 1 | 表示是否自动把值非常长的字段放到BLOB页里 |
| PAGE_SIZE | 4 | 页面大小 |
| DATA_DIR | 1 | 表示表空间是否是从默认的数据目录中获取的 |
| SHARED | 1 | 是否为共享表空间 |
| TEMPORARY | 1 | 是否为临时表空间 |
| ENCRYPTION | 1 | 表空间是否加密 |
| UNUSED | 18 | 没有使用到的比特位 |
-
List Base Node for SEG_INODES_FULL List和List Base Node for SEG_INODES_FREE List
每个段对应的INODE Entry结构会集中存放到一个类型为INODE的页中,如果表空间中的段特别多,则会有多个INODE Entry结构,可能一个页放不下,这些INODE类型的页会组成两种列表:-
SEG_INODES_FULL链表,该链表中的INODE类型的页面都已经被INODE Entry结构填充满了,没空闲空间存放额外的INODE Entry了。
-
SEG_INODES_FREE链表,该链表中的INODE类型的页面仍有空闲空间来存放INODE Entry结构。
由于我们现在还没有详细介绍INODE类型页,所以等会说过INODE类型的页之后再回过头来看着两个链表。
-
XDES Entry部分
紧接着File Space Header部分的就是XDES Entry部分了,我们嘴上说过无数次,却从没见过真身的XDES Entry就是在表空间的第一个页面中保存的。我们知道一个XDES Entry结构的大小是40字节,但是一个页面的大小有限,只能存放有限个XDES Entry结构,所以我们才把256个区划分成一组,在每组的第一个页面中存放256个XDES Entry结构。大家回看那个FSP_HDR类型页面的示意图,XDES Entry 0就对应着extent 0,XDES Entry 1就对应着extent 1… 依此类推,XDES Entry255就对应着extent 255。
因为每个区对应的XDES Entry结构的地址是固定的,所以我们访问这些结构就非常简单啦。
2.4.5 XDES类型
每一个XDES Entry结构对应表空间的一个区,虽然一个XDES Entry结构只占用40字节,但你抵不住表空间的区的数量也多啊。在区的数量非常多时,一个单独的页可能就不够存放足够多的XDES Entry结构,所以我们把表空间的区分为了若干个组,每组开头的一个页面记录着本组内所有的区对应的XDES Entry结构。由于第一个组的第一个页面有些特殊,因为它也是整个表空间的第一个页面,所以除了记录本组中的所有区对应的XDES Entry结构以外,还记录着表空间的一些整体属性,这个页面的类型就是我们刚刚说完的FSP_HDR类型,整个表空间里只有一个这个类型的页面。除去第一个分组以外,之后的每个分组的第一个页面只需要记录本组内所有的区对应的XDES Entry结构即可,不需要再记录表空间的属性了,为了和FSP_HDR类型做区别,我们把之后每个分组的第一个页面的类型定义为XDES,它的结构和FSP_HDR类型是非常相似的:
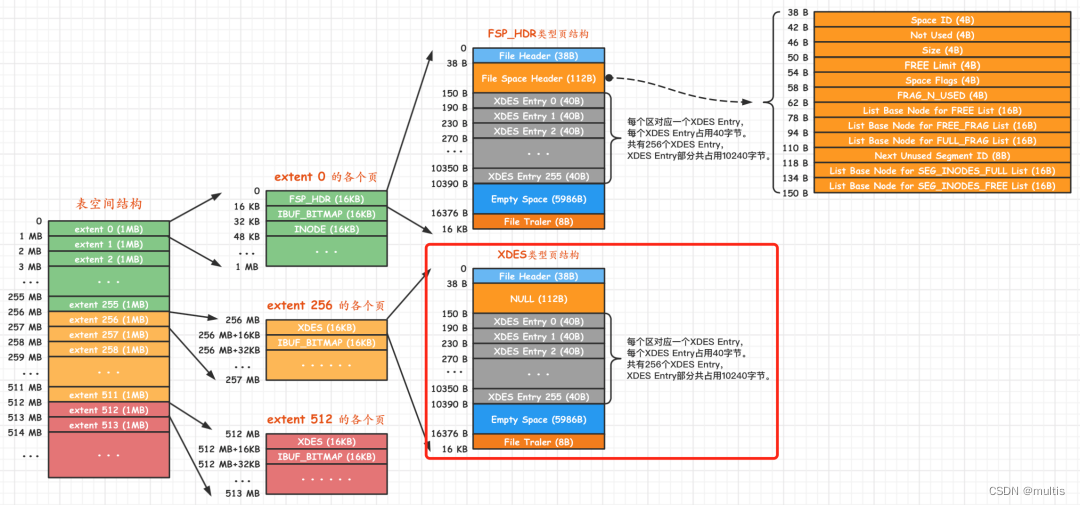
与FSP_HDR类型的页面对比,除了少了File Space Header部分之外,也就是除了少了记录表空间整体属性的部分之外,其余的部分是一样一样的。
2.4.6 IBUF_BITMAP类型
每个分组的第二个页面的类型都是IBUF_BITMAP,这种类型的页里边记录了一些有关Change Buffer的信息。
2.4.7 INODE类型
再次对比前边介绍表空间的图,第一个分组的第三个页面的类型是INODE。我们前边说过InnoDB为每个索引定义了两个段,而且为某些特殊功能定义了些特殊的段。为了方便管理,他们又为每个段设计了一个INODE Entry结构,这个结构中记录了关于这个段的相关属性。而我们这会儿要介绍的这个INODE类型的页就是为了存储INODE Entry结构而存在的。
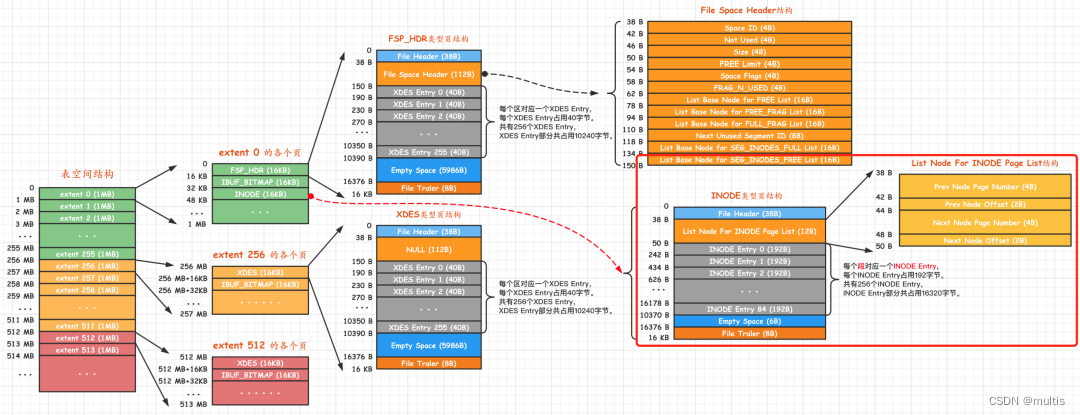
一个INODE类型的页面是由这几部分构成的:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| List Node for INODE Page List | 通用链表节点 | 12字节 | 存储上一个INODE页面和下一个INODE页面的指针 |
| INODE Entry | 段描述信息 | 16320字节 | 存储段描述信息 |
| Empty Space | 尚未使用空间 | 6字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
除了File Header、Empty Space、File Trailer这几个老朋友外,我们重点关注List Node for INODE Page List和INODE Entry这两个部分。
首先看INODE Entry部分,我们前边已经详细介绍过这个结构的组成了,主要包括对应的段内零散页面的地址以及附属于该段的FREE、NOT_FULL和FULL链表的基节点。每个INODE Entry结构占用192字节,一个页面里可以存储85个这样的结构。
重点看一下List Node for INODE Page List,因为一个表空间中可能存在超过85个段,所以可能一个INODE类型的页面不足以存储所有的段对应的INODE Entry结构,所以就需要额外的INODE类型的页面来存储这些结构。还是为了方便管理这些INODE类型的页面,InnoDB将这些INODE类型的页面串联成两个不同的链表:
- SEG_INODES_FULL链表:该链表中的INODE类型的页面中已经没有空闲空间来存储额外的INODE Entry结构了。
- SEG_INODES_FREE链表:该链表中的INODE类型的页面中还有空闲空间来存储额外的INODE Entry结构了。
想必大家已经认出这两个链表了,我们前边提到过这两个链表的基节点就存储在File Space Header里边,也就是说这两个链表的基节点的位置是固定的,所以我们可以很轻松的访问到这两个链表。以后每当我们新创建一个段(创建索引时就会创建段)时,都会创建一个INODE Entry结构与之对应,存储INODE Entry的大致过程就是这样的:
- 先看看SEG_INODES_FREE链表是否为空,如果不为空,直接从该链表中获取一个节点,也就相当于获取到一个仍有空闲空间的INODE类型的页面,然后把该INODE Entry结构放到该页面中。当该页面中无剩余空间时,就把该页放到SEG_INODES_FULL链表中。
- 如果SEG_INODES_FREE链表为空,则需要从表空间的FREE_FRAG链表中申请一个页面,修改该页面的类型为INODE,把该页面放到SEG_INODES_FREE链表中,与此同时把该INODE Entry结构放入该页面
2.4.8 Segment Header结构的运用
我们知道一个索引会产生两个段,分别是叶子节点段和非叶子节点段,而每个段都会对应一个INODE Entry结构,那我们怎么知道某个段对应哪个INODE Entry结构呢?所以得找个地方记下来这个对应关系。记得之前学习过的数据页MySQL之数据页结构,也就是INDEX类型的页有一个Page Header部分,所以把Page Header部分粘一下:
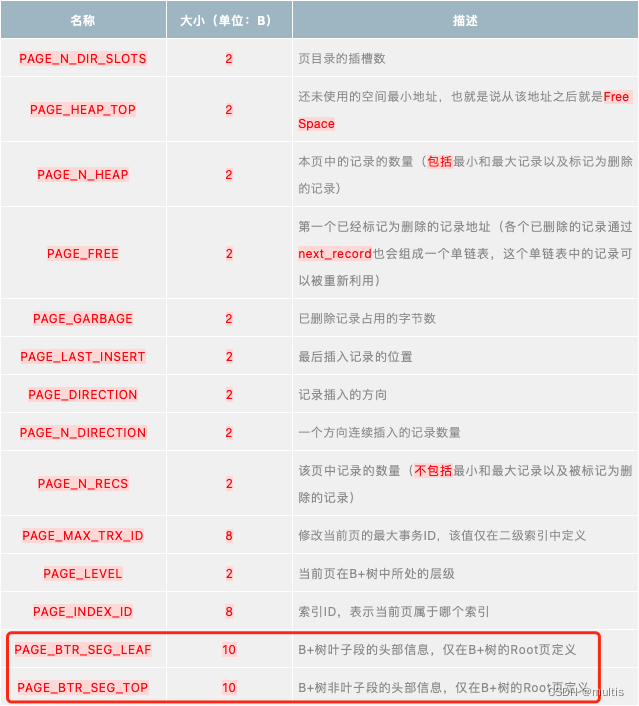
其中的PAGE_BTR_SEG_LEAF和PAGE_BTR_SEG_TOP都占用10个字节,它们其实对应一个叫Segment Header的结构,该结构图示如下:
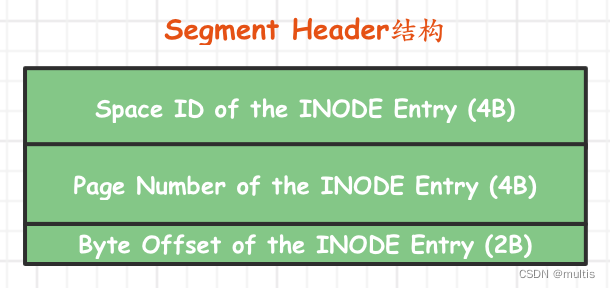
各个部分的具体释义如下:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| Space ID of the INODE Entry | 4字节 | INODE Entry结构所在的表空间ID |
| Page Number of the INODE Entry | 4字节 | INODE Entry结构所在的页面页号 |
| Byte Offset of the INODE Entry | 2字节 | INODE Entry结构在该页面中的偏移量 |
这样子就很清晰了,PAGE_BTR_SEG_LEAF记录着叶子节点段对应的INODE Entry结构的地址是哪个表空间的哪个页面的哪个偏移量,PAGE_BTR_SEG_TOP记录着非叶子节点段对应的INODE Entry结构的地址是哪个表空间的哪个页面的哪个偏移量。这样子索引和其对应的段的关系就建立起来了。不过需要注意的一点是,因为一个索引只对应两个段,所以只需要在索引的根页面中记录这两个结构即可。
2.5 真实表空间对应的文件大小
上边的这些概念已经压的快喘不过气了。不过独立表空间有那么大么?我到数据目录里看了,一个新建的表对应的.ibd文件只占用了96K,才6个页面大小,上边的说了那么多概念,那么大的空间占用,为什么只有96KB大小?
一开始表空间占用的空间自然是很小,因为表里边都没有数据。.ibd文件是自扩展的,随着表中数据的增多,表空间对应的文件也逐渐增大。
三、系统表空间结构
了解完了独立表空间的基本结构,系统表空间的结构也就好理解多了,系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页面,所以会比独立表空间多出一些记录这些信息的页面。因为这个系统表空间最厉害,相当于是表空间之首,所以它的表空间 ID(Space ID)是0。
3.1 系统表空间整体结构
系统表空间与独立表空间的一个非常明显的不同之处就是在表空间开头有许多记录整个系统属性的页面,如图:
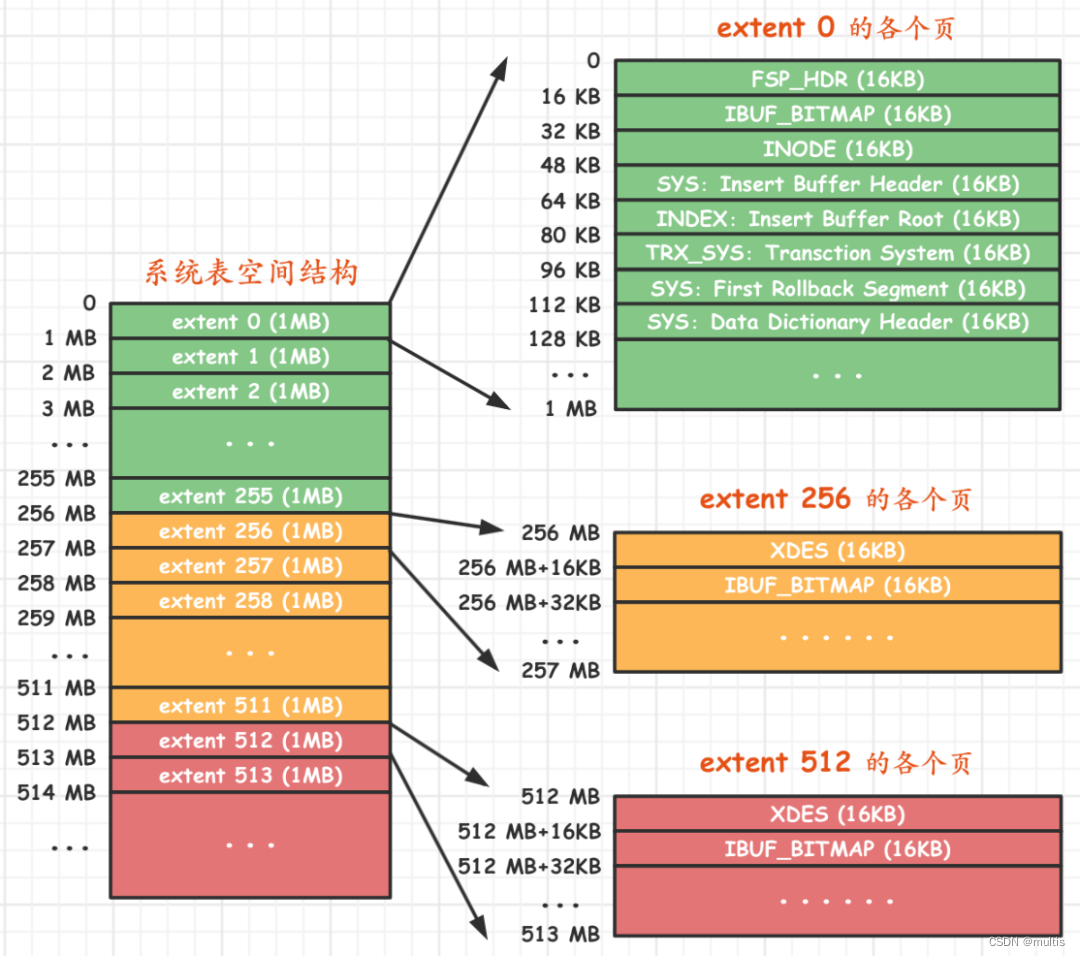
可以看到,系统表空间和独立表空间的前三个页面(页号分别为0、1、2,类型分别是FSP_HDR、IBUF_BITMAP、INODE)的类型是一致的,只是页号为3~7的页面是系统表空间特有的,我们来看一下这些多出来的页面都是干啥使的:
| 页号 | 页面类型 | 英文描述 | 描述 |
|---|---|---|---|
| 3 | SYS | Insert Buffer Header | 存储Insert Buffer的头部信息 |
| 4 | INDEX | Insert Buffer Root | 存储Insert Buffer的根页面 |
| 5 | TRX_SYS | Transction System | 事务系统的相关信息 |
| 6 | SYS | First Rollback Segment | 第一个回滚段的页面 |
| 7 | SYS | Data Dictionary Header | 数据字典头部信息 |
除了这几个记录系统属性的页面之外,系统表空间的extent 1和extent 2这两个区,也就是页号从64~191这128个页面被称为Doublewrite buffer,不过上述的大部分知识都涉及到了事务和多版本控制的问题,这些问题我们会放在后边的章节中进行学习,所以现在我们只学习下有关InnoDB数据字典的知识,其余的概念在后边再看
3.2 InnoDB数据字典
我们平时使用INSERT语句向表中插入的那些记录称之为用户数据,MySQL只是作为一个软件来为我们来保管这些数据,提供方便的增删改查接口而已。但是每当我们向一个表中插入一条记录的时候,MySQL先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要知道该表的聚簇索引和所有二级索引对应的根页面是哪个表空间的哪个页面,然后把记录插入对应索引的B+树中。所以说,MySQL除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:
- 某个表属于哪个表空间,表里边有多少列
- 表对应的每一个列的类型是什么
- 该表有多少索引,每个索引对应哪几个字段,该索引对应的
- 页面在哪个表空间的哪个页面
- 该表有哪些外键,外键对应哪个表的哪些列
- 某个表空间对应文件系统上文件路径是什么等等
上述这些数据并不是我们使用INSERT语句插入的用户数据,实际上是为了更好的管理我们这些用户数据而不得已引入的一些额外数据,这些数据也称为元数据。InnoDB存储引擎特意定义了一些列的内部系统表(internal system table)来记录这些这些元数据:
| 表名 | 描述 |
|---|---|
| SYS_TABLES | 整个InnoDB存储引擎中所有的表的信息 |
| SYS_COLUMNS | 整个InnoDB存储引擎中所有的列的信息 |
| SYS_INDEXES | 整个InnoDB存储引擎中所有的索引的信息 |
| SYS_FIELDS | 整个InnoDB存储引擎中所有的索引对应的列的信息 |
| SYS_FOREIGN | 整个InnoDB存储引擎中所有的外键的信息 |
| SYS_FOREIGN_COLS | 整个InnoDB存储引擎中所有的外键对应列的信息 |
| SYS_TABLESPACES | 整个InnoDB存储引擎中所有的表空间信息 |
| SYS_DATAFILES | 整个InnoDB存储引擎中所有的表空间对应文件系统的文件路径信息 |
| SYS_VIRTUAL | 整个InnoDB存储引擎中所有的虚拟生成列的信息 |
这些系统表也被称为数据字典,它们都是以B+树的形式保存在系统表空间的某些页面中,其中SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS这四个表尤其重要,称之为基本系统表(basic system tables),我们先看看这4个表的结构。
3.2.1 SYS_TABLES 表
SYS_TABLES表的列
| 列名 | 描述 |
|---|---|
| NAME | 表的名称 |
| ID | InnoDB存储引擎中每个表都有一个唯一的ID |
| N_COLS | 该表拥有列的个数 |
| TYPE | 表的类型,记录了一些文件格式、行格式、压缩等信息 |
| MIX_ID | 已过时,忽略 |
| MIX_LEN | 表的一些额外的属性 |
| CLUSTER_ID | 未使用,忽略 |
| SPACE | 该表所属表空间的ID |
这个SYS_TABLES表有两个索引:
- 以
NAME列为主键的聚簇索引 - 以
ID列建⽴的二级索引
3.2.2 SYS_COLUMNS表
SYS_COLUMNS表的列
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该列所属表对应的ID |
| POS | 该列在表中是第几列 |
| NAME | 该列的名称 |
| MTYPE | main data type,主数据类型,就是那堆INT、CHAR、VARCHAR、FLOAT、DOUBLE之类的等 |
| PRTYPE | precise type,精确数据类型,就是修饰主数据类型的那堆东东,比如是否允许NULL值,是否允许负数啥的 |
| LEN | 该列最多占用存储空间的字节数 |
| PREC | 该列的精度,不过这列貌似都没有使用,默认值都是0 |
这个SYS_COLUMNS表只有一个聚集索引:
- 以
(TABLE_ID, POS)列为主键的聚簇索引
3.2.3 SYS_INDEXES表
SYS_INDEXES表的列
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该索引所属表对应的ID |
| ID | InnoDB存储引擎中每个索引都有一个唯一的ID |
| NAME | 该索引的名称 |
| N_FIELDS | 该索引包含列的个数 |
| TYPE | 该索引的类型,比如聚簇索引、唯一索引、更改缓冲区的索引、全文索引、普通的二级索引等等各种类型 |
| SPACE | 该索引根页面所在的表空间ID |
| PAGE_NO | 该索引根页面所在的页面号 |
| MERGE_THRESHOLD | 如果页面中的记录被删除到某个比例,就把该页面和相邻页面合并,这个值就是这个比例 |
这个SYS_INEXES表只有一个聚集索引:
- 以
(TABLE_ID, ID)列为主键的聚簇索引
3.2.4 SYS_FIELDS表
SYS_FIELDS表的列
| 列名 | 描述 |
|---|---|
| INDEX_ID | 该索引列所属的索引的ID |
| POS | 该索引列在某个索引中是第几列 |
| COL_NAME | 该索引列的名称 |
这个SYS_INEXES表只有一个聚集索引:
- 以
(INDEX_ID, POS)列为主键的聚簇索引
3.3 Data Dictionary Header页面
只要有了上述4个基本系统表,也就意味着可以获取其他系统表以及用户定义的表的所有元数据。比方说我们想看看SYS_TABLESPACES这个系统表里存储了哪些表空间以及表空间对应的属性,那就可以:
-
到
SYS_TABLES表中根据表名定位到具体的记录,就可以获取到SYS_TABLESPACES表的TABLE_ID -
使用这个
TABLE_ID到SYS_COLUMNS表中就可以获取到属于该表的所有列的信息。 -
使用这个
TABLE_ID还可以到SYS_INDEXES表中获取所有的索引的信息,索引的信息中包括对应的INDEX_ID,还记录着该索引对应的B+数根页面是哪个表空间的哪个页面。 -
使用
INDEX_ID就可以到SYS_FIELDS表中获取所有索引列的信息。
也就是说这4个表是表中之表,那这4个表的元数据去哪里获取呢?没法搞了,只能把这4个表的元数据,就是它们有哪些列、哪些索引等信息硬编码到代码中,然后InnoDB拿出一个固定的页面来记录这4个表的聚簇索引和二级索引对应的B+树位置,这个页面就是页号为7的页面,类型为SYS,记录了Data Dictionary Header,也就是数据字典的头部信息。除了这4个表的5个索引的根页面信息外,这个页号为7的页面还记录了整个InnoDB存储引擎的一些全局属性:
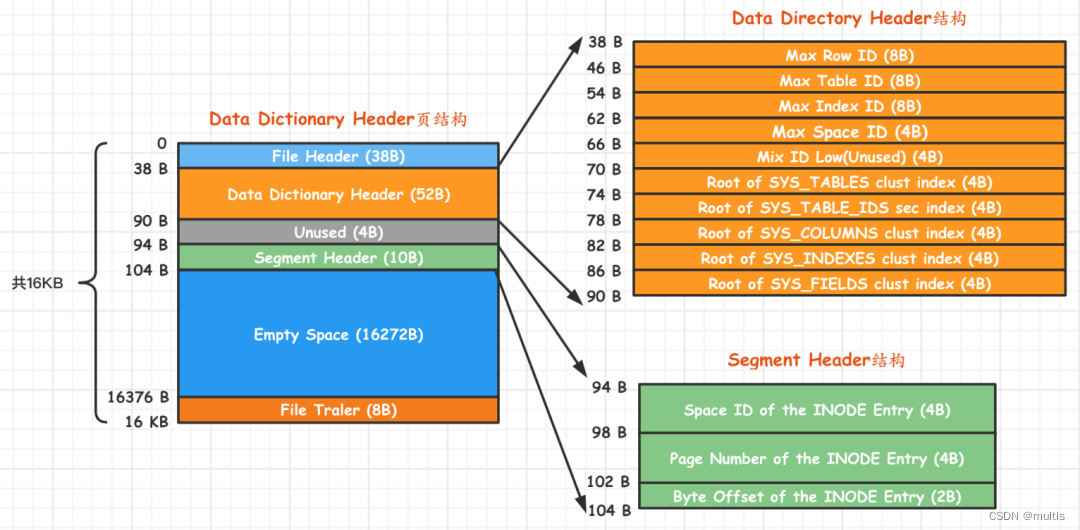
可以看到这个页面由下边几个部分组成:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Data Dictionary Header | 数据字典头部信息 | 56字节 | 记录一些基本系统表的根页面位置以及InnoDB存储引擎的一些全局信息 |
| Segment Header | 段头部信息 | 10字节 | 记录本页面所在段对应的INODE Entry位置信息 |
| Empty Space | 尚未使用空间 | 16272字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
可以看到这个页面里竟然有Segment Header部分,意味着InnoDB把这些有关数据字典的信息当成一个段来分配存储空间,我们就姑且称之为数据字典段吧。由于目前我们需要记录的数据字典信息非常少(可以看到Data Dictionary Header部分仅占用了56字节),所以该段只有一个碎片页,也就是页号为7的这个页。
接下来我们需要细细说一下Data Dictionary Header部分的各个字段:
-
Max Row ID:我们说过如果我们不显式的为表定义主键,而且表中也没有UNIQUE索引,那么InnoDB存储引擎会默认为我们生成一个名为row_id的列作为主键。因为它是主键,所以每条记录的row_id列的值不能重复。原则上只要一个表中的row_id列不重复就可以了,也就是说表a和表b拥有一样的row_id列也没啥关系,不过InnoDB只提供了这个Max Row ID字段,不论哪个拥有row_id列的表插入一条记录时,该记录的row_id列的值就是Max Row ID对应的值,然后再把Max Row ID对应的值加1,也就是说这个Max Row ID是全局共享的。 -
Max Table ID:InnoDB存储引擎中的所有的表都对应一个唯一的ID,每次新建一个表时,就会把本字段的值作为该表的ID,然后自增本字段的值。 -
Max Index ID:InnoDB存储引擎中的所有的索引都对应一个唯一的ID,每次新建一个索引时,就会把本字段的值作为该索引的ID,然后自增本字段的值。Max Space ID:InnoDB存储引擎中的所有的表空间都对应一个唯一的ID,每次新建一个表空间时,就会把本字段的值作为该表空间的ID,然后自增本字段的值。 -
Mix ID Low(Unused):这个字段没啥用,跳过。 -
Root of SYS_TABLES clust index:本字段代表SYS_TABLES表聚簇索引的根页面的页号。 -
Root of SYS_TABLE_IDS sec index:本字段代表SYS_TABLES表为ID列建立的二级索引的根页面的页号。 -
Root of SYS_COLUMNS clust index:本字段代表SYS_COLUMNS表聚簇索引的根页面的页号。 -
Root of SYS_INDEXES clust index:本字段代表SYS_INDEXES表聚簇索引的根页面的页号。 -
Root of SYS_FIELDS clust index:本字段代表SYS_FIELDS表聚簇索引的根页面的页号。 -
Unused:这4个字节没用,跳过。
以上就是页号为7的页面的全部内容,看一次肯定懵,一定要反复多看几次。
3.4 information_schema系统数据库
需要注意一点的是,用户是不能直接访问InnoDB的这些内部系统表的,除非你直接去解析系统表空间对应文件系统上的文件。不过InnoDB考虑到查看这些表的内容可能有助于大家分析问题,所以在系统数据库information_schema中提供了一些以innodb开头的表:
mysql> USE information_schema;
Database changed
mysql> show tables like 'in%';
+------------------------------------+
| Tables_in_information_schema (IN%) |
+------------------------------------+
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_POOL_STATS |
| INNODB_CACHED_INDEXES |
| INNODB_CMP |
| INNODB_CMP_PER_INDEX |
| INNODB_CMP_PER_INDEX_RESET |
| INNODB_CMP_RESET |
| INNODB_CMPMEM |
| INNODB_CMPMEM_RESET |
| INNODB_COLUMNS |
| INNODB_DATAFILES |
| INNODB_FIELDS |
| INNODB_FOREIGN |
| INNODB_FOREIGN_COLS |
| INNODB_FT_BEING_DELETED |
| INNODB_FT_CONFIG |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_DELETED |
| INNODB_FT_INDEX_CACHE |
| INNODB_FT_INDEX_TABLE |
| INNODB_INDEXES |
| INNODB_METRICS |
| INNODB_SESSION_TEMP_TABLESPACES |
| INNODB_TABLES |
| INNODB_TABLESPACES |
| INNODB_TABLESPACES_BRIEF |
| INNODB_TABLESTATS |
| INNODB_TEMP_TABLE_INFO |
| INNODB_TRX |
| INNODB_VIRTUAL |
+------------------------------------+
31 rows in set (0.00 sec)
在information_schema数据库中的这些以INNODB开头的表并不是真正的内部系统表(内部系统表就是我们上边唠叨的以SYS开头的那些表),而是在存储引擎启动时读取这些以SYS开头的系统表,然后填充到这些以INNODB_SYS开头的表中。以INNODB_SYS开头的表和以SYS开头的表中的字段并不完全一样,但供大家参考已经足矣。
四、总结
今天我们学习了关于InnoDB存储引擎表空间的结构,通篇几乎全是概念、图片,这部分知识本就枯燥乏味,但是’春天’马上就到来,最枯燥乏味的内容马上结束了。由于今天的内容都是偏理论的概念,加上篇幅原因,就不做知识点总结了。
今天的文章我第一次读原著时,一脸懵逼,好像知道了表空间结构是怎么一回事儿,但是好像又讲不出来什么,所以建议大家多看几次,我相信一句话:书读百遍,其义自见。当你一次看不懂的时候,就一定要多看几次。同时,建议大家多动手画一画结构图,这样理解起来更加深刻。

Por meio do estudo deste artigo, conheço a complexidade e a sutileza do design do banco de dados MySQL. O autor do livro original, o garoto 4919, está tão envolvido em pesquisa de tecnologia que atualmente estou fora do meu alcance. Portanto, siga o ritmo do grandalhão e progrida um pouco todos os dias. Espero que todos se tornem um grande tiro nos olhos dos outros. Vamos encorajar uns aos outros!
Até agora, o estudo de hoje acabou, espero que você se torne um eu indestrutível
~~~
Você não pode ligar os pontos olhando para frente; você só pode conectá-los olhando para trás. Portanto, você precisa confiar que os pontos de alguma forma se conectarão em seu futuro. Você precisa confiar em algo - seu instinto, destino, vida, karma, seja o que for. Essa abordagem nunca me decepcionou e fez toda a diferença na minha vida
Se meu conteúdo for útil para você, por favor 点赞, criar não é fácil, o apoio de todos é a 评论motivação 收藏para eu perseverar
