prefácio
Costumávamos dizer que o MySQL pode ter diferentes esquemas de execução para executar uma consulta, e ele escolherá o esquema de menor custo ou de menor custo para realmente executar a consulta, como posso levar você a entender isso em detalhes?
Índice
1. Qual é o custo
Costumávamos dizer que o MySQL pode ter diferentes planos de execução para executar uma consulta, e ele escolherá um deles 成本最低, ou 代价最低aquele plano para realmente executar a consulta. No entanto, nossa descrição anterior do custo é muito vaga. Na verdade, o custo de execução de uma instrução de consulta no MySQL é composto de dois aspectos a seguir:
-
I/O成本Os mecanismos de armazenamento MyISAM e InnoDB que nossas tabelas costumam usar armazenam dados e índices no disco. Quando queremos consultar os registros na tabela, precisamos carregar os dados ou índices na memória antes de operar. O tempo perdido no processo de carregamento do disco para a memória é chamado de custo de E/S.
-
CPU成本O tempo consumido por operações como ler e verificar se os registros atendem às condições de pesquisa correspondentes e classificar o conjunto de resultados é chamado de custo de CPU.
Para o mecanismo de armazenamento InnoDB, uma página é a unidade básica de interação entre disco e memória. O MySQL estipula que o custo padrão para ler uma página é 0.25(MySQL 5.7 default 1.0), e o custo padrão para ler e verificar se um registro atende à pesquisa critérios é 0.1(padrão do MySQL 5.7 0.2). 0.25E 0.1esses números são chamados de 成本常数, essas duas constantes de custo são as mais usadas, e falaremos sobre o restante das constantes de custo mais tarde.
Dica:
Ressalte-se que o custo é 0,1 independentemente de ser necessário verificar se a condição de busca é atendida na leitura do registro.
A versão do MySQL usada aqui é 8.0.32, e o custo varia entre as versões. Isso é explicado em detalhes mais adiante neste capítulo.
2. O custo da consulta de tabela única
2.1 Preparar dados
Para nosso estudo normal, ainda usamos o anterior demo8... Receio que todos se esqueçam de como é este relógio, então copiarei um artigo para você:
mysql> USE testdb;
mysql> create table demo8 (
id int not null auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key (id),
key idx_key1 (key1),
unique key idx_key2 (key2),
key idx_key3 (key3),
key idx_key_part(key_part1, key_part2, key_part3));
Um total de 1 índice clusterizado (chave primária) e 4 índices secundários foram criados para a tabela demo8:
idO índice clusterizado criado para a coluna;key1Um índice secundário criado para a coluna;key2Um índice secundário exclusivo criado para a coluna;key3Um índice secundário criado para a coluna;- Um índice secundário composto (conjunto) criado para as colunas
key_part1,key_part2, .key_part3
Então precisamos inserir 20000um registro para esta tabela, e inserir valores aleatórios nas demais colunas exceto na coluna id.
mysql> delimiter //
create procedure demo8data()
begin
declare i int;
set i=0;
while i<20000 do
insert into demo8(key1,key2,key3,key_part1,key_part2,key_part3,common_field) values(
substring(md5(rand()),1,2),
i+1,
substring(md5(rand()),1,3),
substring(md5(rand()),1,4),
substring(md5(rand()),1,5),
substring(md5(rand()),1,6),
substring(md5(rand()),1,7)
);
set i=i+1;
end while;
end;
//
delimiter ;
mysql> call demo8data();
Vamos começar oficialmente nosso estudo
2.2 Etapas de otimização baseadas em custo
Antes que uma instrução de consulta de tabela única seja realmente executada, o otimizador de consulta do MySQL descobrirá todas as soluções possíveis para executar a instrução e, após a comparação, encontrará a solução com o menor custo. Essa solução com o menor custo é a chamada execução plan, e então chamará a interface fornecida pelo mecanismo de armazenamento para realmente executar a consulta. O resumo desse processo é o seguinte:
- Encontre todos os índices possíveis para usar com base nos critérios de pesquisa
- Calcule o custo de uma varredura completa da tabela
- Calcule o custo de execução de uma consulta usando diferentes índices
- Compare os custos de vários planos de execução para encontrar aquele com o menor custo
Abaixo, usamos um exemplo para analisar essas etapas. A instrução de consulta de tabela única é a seguinte:
mysql> select * from demo8 where
key1 in ('aa','bb','cc') and
key2 > 10 and key2 < 1000 and
key3 > key2 and
key_part1 like '%3f%' and
common_field='1281259';
Parece complicado, vamos analisar passo a passo
Etapa 1: encontre todos os índices aplicáveis possíveis de acordo com os critérios de pesquisa
Como dissemos antes, para o índice da árvore B+, desde que a coluna do índice e a constante estejam conectadas usando =, <=>, IN, , NOT IN, IS NULL, IS NOT NULL, >, <>=, , , <=( diferente de também pode ser escrito ) ou operadores, então -chamado O intervalo de intervalo (LIKE corresponde ao prefixo da string também está OK), ou seja, essas condições de pesquisa podem usar índices e o MySQL chama os índices que podem ser usados em uma consulta .BETWEEN AND!=<>LIKEpossible keys
Vamos analisar várias condições de autorização envolvidas na consulta acima:
key1 in ('aa','bb','cc'), esta condição de pesquisa pode usar o índice secundárioidx_key1key2 > 10 and key2 < 1000, esta condição de pesquisa pode usar o índice secundárioidx_key2key3 > key2, como a coluna de pesquisa dessa condição de pesquisa não é comparada com uma constante, o índice não pode ser usado.key_part1 like '%3f%',key_part1uselikeoperadores para comparar strings começando com curingas e índices não podem ser usadoscommon_field=‘1281259’, já que a coluna não tem nenhum índice, o índice não será usado
Para resumir, os índices que podem ser usados na instrução de consulta acima são apenas possible keyssum idx_key1e index idx_key2.
Passo 2: Calcular o custo da verificação completa da tabela
Para o mecanismo de armazenamento InnoDB, a varredura completa da tabela significa comparar os registros no índice clusterizado com as condições de pesquisa fornecidas e adicionar os registros que atendem às condições de pesquisa ao conjunto de resultados, portanto, o índice clusterizado precisa corresponder à página é carregado na memória e verificado para ver se o registro corresponde aos critérios de pesquisa. Como 查询成本=I/O成本+CPU成本, calcular o custo de uma varredura completa da tabela requer duas informações:
聚簇索引占用的页面数该表中的记录数
De onde vêm essas duas informações? O MySQL mantém uma série de informações estatísticas para cada tabela. Explicaremos em detalhes como essas informações estatísticas são coletadas mais adiante neste capítulo. Agora vamos ver como visualizar essas informações estatísticas. O MySQL nos fornece instruções para visualizar as informações estatísticas de uma tabela. Se quisermos visualizar as informações estatísticas de uma tabela especificada, basta adicionar a instrução correspondente show table statusapós a instrução. Por exemplo, se desejarmos visualizar as informações estatísticas desta tabela , podemos escrever assim:likedemo8
mysql> show table status like 'demo8' \G;
*************************** 1. row ***************************
Name: demo8
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 20187
Avg_row_length: 78
Data_length: 1589248
Max_data_length: 0
Index_length: 2785280
Data_free: 4194304
Auto_increment: 20001
Create_time: 2023-05-16 16:36:53
Update_time: 2023-05-16 16:38:21
Check_time: NULL
Collation: utf8mb4_0900_ai_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Embora surjam muitas opções de estatísticas, nos importamos apenas com duas por enquanto:
-
Rows: Esta opção indica o número de registros na tabela. ParaMyISAMtabelas que usam mecanismos de armazenamento, esse valor é exato e, paraInnoDBtabelas que usam mecanismos de armazenamento, esse valor é uma estimativa. Como pode ser visto nos resultados da consulta, como nossademo8tabela usaInnoDBum mecanismo de armazenamento, embora haja 20.000 registros na tabela, o valorshow table statusexibidoRowsé 20.187 registros. -
Data_length: Esta opção indica o número de bytes de espaço de armazenamento ocupado. Para uma tabela que usaMyISAMum mecanismo de armazenamento, esse valor é o tamanho do arquivo de dados. Para umaInnoDBtabela que usa um mecanismo de armazenamento, esse valor é equivalente ao tamanho do espaço de armazenamento ocupado pelo índice clusterizadoOu seja, o tamanho do valor pode ser calculado assim:
Data_length = 聚簇索引的页面数量 * 每个页面的大小Nossa
demo8tabela usa o16KBtamanho de página padrão, de acordo com os resultados da consulta acima, para que possamos calcular o número de páginas no índice clusterizado:聚簇索引的页面数=1589248 ÷ 16 ÷ 1024 = 97
Agora que obtivemos o número estimado de páginas ocupadas pelo índice clusterizado e o número de registros na tabela, podemos agora observar o processo de cálculo da varredura completa da tabela:
I/OCusto: 97 * 0,25 =24.25
97refere-se ao número de páginas ocupadas pelo índice clusterizado,0.25refere-se à constante de custo de carregamento de uma páginaCPUCusto: 20187 * 0,1 =2018.7
20187refere-se ao número de registros na tabela nos dados estatísticos, queInnoDBé um valor estimado para o mecanismo de armazenamento0.1e refere-se à constante de custo necessária para acessar um registro总成本:24,25 +2018,7 =2042.95
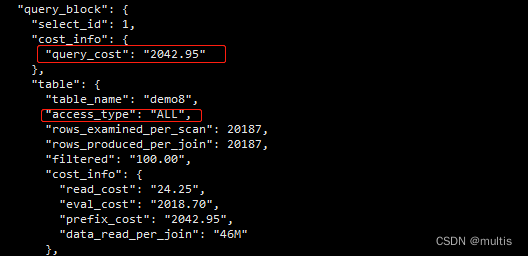
Resumindo, demo8o custo total necessário para a verificação completa da tabela é 2042.95o upload direto do código, sem bobagens e uma verificação incrível
mysql> explain format=json select * from demo8 ;
小提示:
Dissemos anteriormente que os registros na tabela são realmente armazenados nos nós folha do índice agrupado correspondente à árvore B+, portanto, desde que obtenhamos o nó folha mais à esquerda através do nó raiz, podemos seguir a lista duplamente encadeada composta por nós de folha. Verifique todos eles. Ou seja, no processo de varredura completa da tabela, alguns nós da árvore B+ não precisam ser acessados, mas o MySQL usa diretamente o número de páginas ocupadas pelo índice clusterizado como base para calcular o custo de I/O quando calculando o custo da varredura completa da tabela A distinção entre nós internos e nós folha é um pouco simplista, apenas preste atenção a ela.
Etapa 3: calcular o custo da consulta executada por diferentes índices
Da análise da etapa 1, concluímos que a consulta acima pode usar idx_key1esses idx_key2dois índices. Precisamos analisar o custo de usar esses índices sozinhos para executar a consulta e, finalmente, analisar se é possível usar a mesclagem de índices. O que precisa ser mencionado aqui é que o otimizador de consulta do MySQL primeiro analisa o custo de usar um índice secundário exclusivo e, em seguida, analisa o custo de usar um índice comum; portanto, também analisamos o custo primeiro e depois examinamos o custo idx_key2de idx_key1uso .
Custo das consultas realizadas usando idx_key2
idx_key2A condição de busca correspondente é: key2 > 10 and key2 < 1000, ou seja, o intervalo de alcance correspondente é: ( 10, 1000), e idx_key2o diagrama de busca é o seguinte:
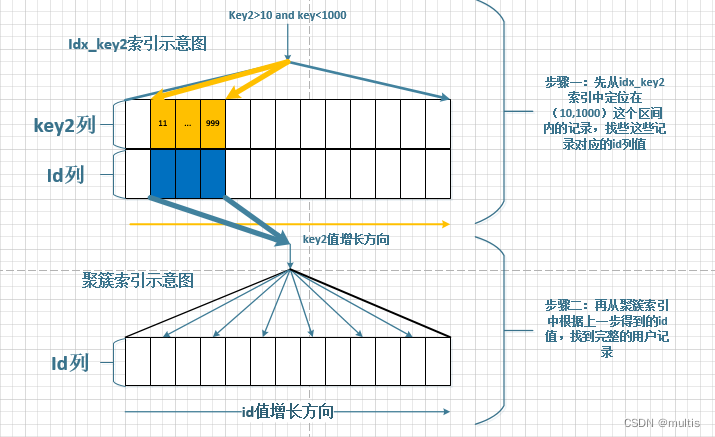
Para 二级索引+回表a consulta do método, o MySQL calcula que o custo dessa consulta depende de dois aspectos dos dados:
-
范围区间的数量:Não importa quantas páginas sejam ocupadas pelo índice secundário em um determinado intervalo, o otimizador de consulta o considera aproximadamente读取索引的一个范围区间的I/O成本和读取一个页面是相同的. Neste exemplo, existe apenas um intervalo usando idx_key2: (10,1000), portanto, o equivalente a acessar o índice secundário desse intervaloI/O成本é:1 * 0.25 = 0.25 -
需要回表的记录数:O otimizador precisa calcular quantos registros estão contidos em um determinado intervalo do índice secundário. Para a razão, é necessário calcular10,1000quantos registros do índice secundário idx_key2 contém no intervalo ( ). O processo de cálculo é o seguinte:-
Etapa 1: primeiro
key2 > 10visiteidx_key2o índice da árvore B+ correspondente de acordo com esta condição e encontrekey2 > 10o primeiro registro que atenda a esta condição. Chamamos esse registro de registro mais à esquerda do intervalo. Dissemos anteriormente que o processo de localizar um registro na árvore de números B+ é extremamente rápido e constante, portanto, o consumo de desempenho desse processo é insignificante -
Etapa 2: continue a encontrar o primeiro registro que atenda a essa condição
key2 < 1000doidx_key2índice de árvore B+ correspondente de acordo com essa condição. Chamamos esse registro de registro mais à direita no intervalo e o consumo de desempenho desse processo também é insignificante. -
Etapa 3: Se o intervalo entre o registro mais à esquerda e o registro mais à direita no intervalo não for muito distante (na versão do MySQL 5.7.21, desde que o intervalo não seja inferior a 10 páginas), você pode contar com precisão o índices secundários que atendem às
key2> 10 AND key2 < 1000condições O número de registros. Caso contrário, basta ler 10 páginas à direita junto ao registro mais à esquerda no intervalo, calcular o número médio de registros contidos em cada página e depois multiplicar essa média pelo número de páginas entre o registro mais à esquerda e o registro mais à direita no intervalo. Então a pergunta vem novamente, como estimar quantas páginas existem entre o registro mais à esquerda no intervalo e o registro mais à direita no intervalo? Para resolver este problema, temos que voltar à estrutura do índice da árvore B+: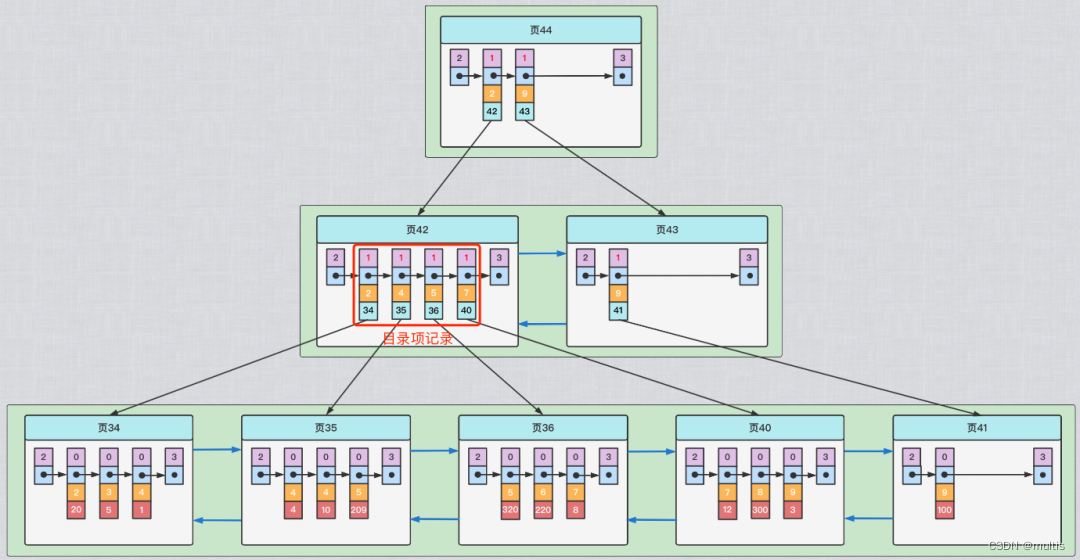
-
Conforme mostrado na figura, por exemplo, o registro mais à esquerda no intervalo está na página 34 e o registro mais à direita no intervalo está na página 40. Então, quero calcular o número de páginas entre o registro mais à esquerda no intervalo e o registro mais à direita no intervalo, o que equivale a calcular o número entre a página 34 e a página 40. Quantas páginas existem e cada registro de entrada de diretório corresponde a uma página de dados, portanto, calcular o número de páginas entre a página 34 e a página 41 é equivalente a calcular a distância entre os registros de entrada de diretório correspondentes em seus nós pais (ou seja, página 42) Não seria suficiente ter alguns registros? Se houver muitas páginas antes da página 34 e página 41 (os itens de diretório correspondentes não estão na mesma página do nó pai), continue a contagem recursivamente. Esse processo estatístico é realizado na página do nó pai. Dissemos antes que um A árvore B+ tem 4 A altura da camada já é muito alta, portanto, não consome muito desempenho.
-
Depois de saber contar o número de registros em um determinado intervalo do índice secundário, é necessário voltar ao problema real, de acordo com o algoritmo acima, há cerca de um registro no idx_key2intervalo ( ). O custo da CPU para ler esse registro de índice secundário é:10, 1000989989989 * 0.1 = 98.9
Onde 989é o número de registros de índice secundário que precisam ser lidos 0.1e é a constante de custo para ler um registro
Após obter os registros através do índice secundário, mais duas coisas precisam ser feitas:
-
De acordo com o valor da chave primária nesses registros, volte ao índice clusterizado para executar as operações da tabela
Aqui você precisa olhar mais de perto. A avaliação do MySQL sobre o custo de I/O da operação de retorno da tabela ainda é muito ousada. Eles acham que cada operação de retorno da tabela equivale a acessar uma página, ou seja, quantos registros existem estão na faixa do índice secundário. Quantas vezes retornar à tabela, ou seja, quantas páginas I/Os precisam ser executadas. De acordo com as estatísticas acima, ao usar o índice secundário idx_key2 para realizar consultas, estima-se que 989 registros de índice secundário precisem ser retornados à tabela. O custo de E/S causado pela operação de retorno da tabela é:
989 x 0.25 = 247.25onde
989é o número esperado de registros de índice secundário e0.25é uma constante para o custo de E/S de uma página. -
O registro completo da conta obtido após retornar à tabela e, em seguida, verificar se outras condições de pesquisa são verdadeiras
A essência da operação de retorno da tabela é localizar o registro do usuário completo no índice clusterizado por meio do valor da chave primária do registro do índice secundário e, em seguida, verificar se as condições de pesquisa diferentes dessa condição de pesquisa são
key2 > 10 and key2 < 1000verdadeiras. Como obtivemos um total de 989 registros de índice secundário por meio do intervalo de intervalo, que corresponde a um registro de usuário completo no índice clusterizado989, o custo da CPU para ler e verificar se esses registros de usuário completos atendem ao restante das condições de pesquisa é o seguinte:989 x 0.1 = 98.9Entre eles, 989 é o número de registros a serem detectados,
0.1que é a constante de custo para detectar se um registro atende às condições de pesquisa fornecidas
Portanto, o custo de execução de uma consulta usando idx_key2 neste exemplo é o seguinte:
-
I/O成本:1.0x 0.25 + 989 x 0.25 = 247.5(número de intervalos de intervalo + número estimado de registros de índice secundário) -
CPU成本:989 x 0.1 + 0.01 + 989 x 0.1 = 197.81(O custo de ler os registros de índice secundário + o custo de ler e detectar os registros de índice clusterizado após retornar à tabela)
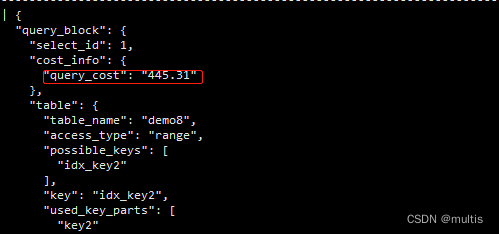
Resumindo, o custo total de usar idx_key2 para executar a consulta é: 247.5 + 197.81 = 445.31, faça o upload do código diretamente, sem bobagens, uma verificação linda:
mysql> explain format=json select * from demo8 where key2 > 10 and key2 < 1000 and key3 > key2 and key_part1 like '%3f%' and common_field='1281259';
小提示:
Se você usar o índice, há um ajuste fino das condições para ler o índice secundário, mas não para ler o índice clusterizado. Qualquer registro no intervalo de varredura e de volta à tabela equivale à leitura de uma página. Caso o índice não seja utilizado, o valor do ajuste fino será analisado separadamente, o que é diferente do anterior.
Custo das consultas realizadas usando idx_key2
idx_key1A condição de pesquisa correspondente key1 in ('aa','bb','cc')também é equivalente a três intervalos de ponto único:
['aa','aa']['bb','bb']['cc','cc']
O diagrama esquemático do uso idx_key1da pesquisa é o seguinte:
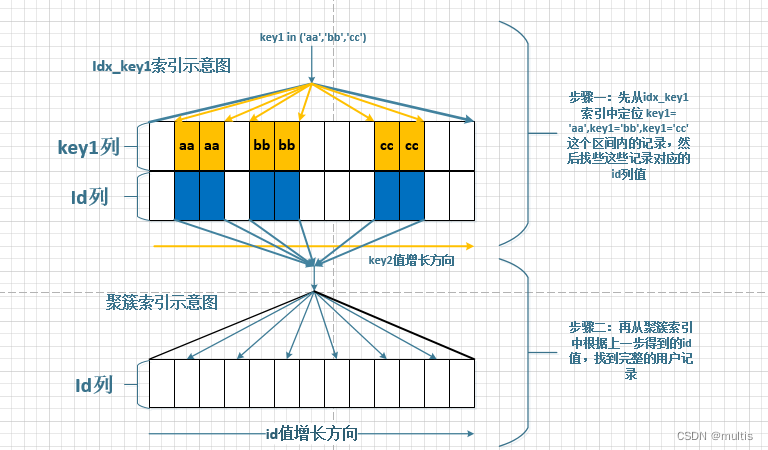
Semelhante ao idx_key2caso de uso, também precisamos idx_key1do número de intervalos de alcance que precisam ser acessados e o número de registros que precisam ser retornados à tabela.
范围区间数量idx_key1: há obviamente três intervalos de ponto único ao usar a consulta, portantoI/O, o custo de acessar o índice secundário desses três intervalos de intervalo é3 x 0.25 = 0.75需要回表的记录数:['aa','aa']Pesquisar o número de registros de índice secundário correspondentes a um intervalo de ponto único é o mesmo que pesquisar o número de registros de índice secundário correspondentes a um intervalo de intervalo contínuo. Tanto o registro mais à esquerda quanto o registro mais à direita do intervalo são calculados primeiro e então o número de registros entre eles é calculado .['aa','aa']registro de índice secundário de intervalo de ponto único é:67['bb','bb']O registro de índice secundário correspondente à pesquisa de intervalo de ponto único é:88['cc','cc']O registro de índice secundário correspondente à pesquisa de intervalo de ponto único é:75
Portanto, o número total de registros que precisam ser retornados à tabela para esses três intervalos de ponto único é: 67+88+75 = 230, e o custo de leitura desses registros de índice secundário CPUé:230 x 0.1 + 0.01 = 23.01
Após obter o número total de registros que precisam ser devolvidos à tabela, considere:
- De acordo com o valor da chave primária nesses registros, a operação da tabela é realizada no índice clusterizado e o
I/Ocusto necessário é:230 x 0.25 = 57.5 - Após retornar à tabela, obtém-se o registro completo do usuário, e
CPUo custo correspondente a esta etapa de comparar se outras condições de pesquisa são verdadeiras é:230 x 0.1 = 23
Portanto, o custo de execução de uma consulta usando idx_key1 neste exemplo é o seguinte:
I/O成本:0,75 + 57,5 =58.25CPU成本:23 + 23,01 =46.01
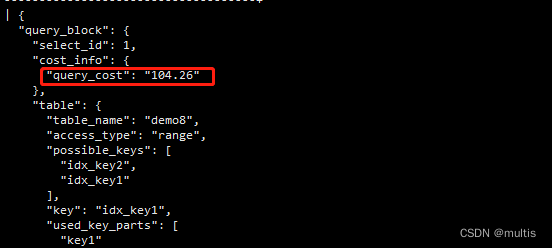
Resumindo, o custo total de execução de uma consulta usando idx_key1 é: 58.25 + 46.01 = 104.26, faça o upload do código diretamente, sem bobagens, uma verificação linda:
mysql> explain format=json select * from demo8 where key1 in ('aa','bb','cc') and key2 > 10 and key2 < 1000 and key3 > key2 and key_part1 like '%3f%' and common_field='1281259';
É possível usar a mesclagem de índice
Neste exemplo, as condições de pesquisa key1para e são conectadas usando concatenação, enquanto para e são consultas de intervalo, ou seja, os registros de índice não agrupados encontrados não são classificados de acordo com o valor da chave primária e não atendem às condições para usar a mesclagem de índice, portanto, nenhuma mesclagem de índice será usada.key2ANDidx_key1idk_key2Intersection
小提示:
O algoritmo usado pelo otimizador de consulta do MySQL para calcular o custo da mesclagem de índices também é complicado. Não vou falar sobre isso aqui. Basta entender como o custo é calculado e saber que o MySQL selecionará o índice de acordo com esse algoritmo.
Passo 4: Compare os custos de vários planos de execução e encontre aquele com o menor custo
Os vários esquemas executáveis para executar a consulta neste exemplo e seus custos correspondentes estão listados abaixo:
全表扫描o custo de:2042.95idx_key2Custos usados :445.31idx_key1Custos usados :104.26
Obviamente, idx_key1o custo mais baixo para usar, é claro, opte idx_key1por executar a consulta.
2.3 Cálculo de custos com base nas estatísticas do índice
Às vezes, há muitos intervalos de ponto único ao usar um índice para executar uma consulta. Por exemplo, usar a instrução IN pode gerar facilmente muitos intervalos de ponto único, como a consulta abaixo (o ... na instrução de consulta abaixo indica que existem muitos parâmetros):
select * from demo8 where key1 in ('aa', 'bb', 'cc', ... , 'ee');
Obviamente, o índice que pode ser usado nesta consulta é idx_key1. Como este índice não é o único índice secundário, não é possível determinar o número de registros de índice secundário correspondentes a um intervalo de ponto único. Precisamos calculá-lo. O método de cálculo foi apresentado acima, que é primeiro obter o registro mais à esquerda e o registro mais à direita do intervalo da árvore B+ correspondente ao índice e, em seguida, calcular quantos registros existem entre esses dois registros (isso pode ser feito quando o número de registros é pequeno) Cálculo preciso, às vezes apenas estimativas). O MySQL chama esse método de cálculo do número de registros de índice correspondentes a um determinado intervalo de intervalo, acessando diretamente a árvore B+ correspondente ao índice index dive.
小提示:
A tradução literal de mergulho para chinês significa mergulho e mergulho. Perdoe meu inglês. mergulho de índice, mergulho de índice? Deslocamento do índice? Não parece ser adequado, então não vou traduzi-lo. No entanto, todos devem entender que index dive é usar diretamente a árvore B+ correspondente ao índice para calcular o número de registros correspondentes a um determinado intervalo.
Se houver vários intervalos de ponto único, não é um problema usar o método index dive para calcular o número de registros correspondentes a esses intervalos de ponto único, mas você não suporta alguns amigos tentando colocar coisas na instrução IN . Se houver 20.000 registros no parâmetro de instrução IN, o que significa que o otimizador de consulta do MySQL precisa executar 20.000 operações de mergulho de índice para calcular o número de registros de índice correspondentes a esses intervalos de ponto único. registros é maior do que o custo da varredura completa direta da tabela. Claro, o MySQL considerou esta situação, então ele fornece uma variável de sistema eq_range_index_dive_limitVamos dar uma olhada no valor padrão desta variável de sistema:
mysql> show variables like '%dive%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 200 |
+---------------------------+-------+
1 row in set (0.00 sec)
Ou seja, se o número de parâmetros em nossa instrução IN for menor que 200, index dive será usado para calcular o número de registros correspondentes a cada intervalo de ponto único. Se for maior ou igual a 200, index dive não pode ser usado. , é estimado usando as chamadas estatísticas de índice. Que tipo de estimativa? Leia.
O MySQL manterá dados estatísticos para cada tabela, e o MySQL também manterá dados estatísticos para cada índice na tabela. A sintaxe que pode ser usada para visualizar os dados estatísticos de um índice em uma tabela, por exemplo, examinamos show index from 表名cada demo8index As estatísticas podem ser escritas assim:
mysql> show index from demo8;
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| demo8 | 0 | PRIMARY | 1 | id | A | 18750 | NULL | NULL | | BTREE | | | YES | NULL |
| demo8 | 0 | idx_key2 | 1 | key2 | A | 18565 | NULL | NULL | YES | BTREE | | | YES | NULL |
| demo8 | 1 | idx_key1 | 1 | key1 | A | 256 | NULL | NULL | YES | BTREE | | | YES | NULL |
| demo8 | 1 | idx_key3 | 1 | key3 | A | 4053 | NULL | NULL | YES | BTREE | | | YES | NULL |
| demo8 | 1 | idx_key_part | 1 | key_part1 | A | 16122 | NULL | NULL | YES | BTREE | | | YES | NULL |
| demo8 | 1 | idx_key_part | 2 | key_part2 | A | 18570 | NULL | NULL | YES | BTREE | | | YES | NULL |
| demo8 | 1 | idx_key_part | 3 | key_part3 | A | 18570 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
7 rows in set (0.02 sec)
Existem muitos atributos, mas esses atributos não são difíceis de entender, vamos apresentar brevemente esses atributos aqui:
| Nome do Atributo | descrever |
|---|---|
| Mesa | O nome da tabela à qual o índice pertence |
| Não Único | Se o valor da coluna do índice é exclusivo, o valor da coluna do índice clusterizado e do índice secundário exclusivo é 0 e o valor da coluna do índice secundário comum é 1 |
| Key_name | nome do índice |
| Seq_in_index | A posição da coluna do índice no índice, contando a partir de 1. Por exemplo, para o índice comum idx_key_part, as posições correspondentes de key_part1, key_part2 e key_part3 são 1, 2 e 3, respectivamente |
| Nome da coluna | o nome da coluna do índice |
| Agrupamento | O método de classificação para armazenar os valores na coluna do índice. Quando o valor for A, significa armazenar em ordem crescente e, quando for NULL, significa armazenar em ordem decrescente |
| Cardinalidade | O número de valores exclusivos na coluna do índice. Vamos nos concentrar nesta propriedade mais tarde. |
| Sub_parte | Para colunas que armazenam strings ou strings de bytes, às vezes queremos apenas indexar os primeiros n caracteres ou bytes dessas strings, e esse atributo representa o valor n. Se a coluna completa for indexada, o valor desta propriedade é NULL |
| Embalado | Como a coluna do índice é compactada, o valor NULL significa não compactado. Não entendemos esse atributo por enquanto, então podemos ignorá-lo primeiro. |
| Nulo | Se a coluna de índice permite armazenar valores NULL. |
| Index_type | O tipo de índice usado, o mais usado é o BTREE, que na verdade é o índice da árvore B+ |
| Comente | Informações de comentário da coluna de índice |
| Índice_comentário | Informações de Anotação de Índice |
PackedExceto pelo fato de você não entender os atributos acima , não deve haver nada que você não consiga entender. Se houver algum, você deve tê-lo ignorado ao ler o artigo anterior. Na verdade, o que mais nos preocupa agora é o atributo Cardinalidade, Cardinalityque significa literalmente 基数o número de valores únicos na coluna do índice. Por exemplo, para uma tabela com 10.000 registros, o atributo Cardinalidade de uma coluna de índice é 10000, o que significa que não há valores duplicados na coluna. Se o atributo Cardinalidade for 1, significa que todos os valores da coluna são duplicatas. No entanto, deve-se observar que, para o mecanismo de armazenamento InnoDB, o show indexatributo Cardinalidade de uma coluna de índice exibida pela instrução é um 估计值e não é preciso. Vamos falar sobre como o valor desse atributo de Cardinalidade é calculado mais tarde, vamos ver para que serve.
>=Conforme mencionado anteriormente, quando o valor da variável de sistema do número do parâmetro na instrução IN eq_range_index_dive_limit, o método não será usado index divepara calcular o número de registros de índice correspondentes a cada intervalo de ponto único, mas os dados estatísticos do índice, os dados estatísticos do índice referidos até aqui Refere-se a estes dois valores:
-
Use o valor
show table statusexibido pela instruçãoRows, ou seja, quantos registros há em uma tabela -
Usando as propriedades
show indexexibidas pela instruçãoCardinality
Combinado com as estatísticas Rows anteriores, podemos calcular o número médio de vezes que um valor é repetido para a coluna do índice. 一个值的重复次数≈Rows÷Cardinality, tomando como exemplo o índice demo8da tabela , seu valor Rows é , que corresponde ao valor da coluna do índice key1 , então podemos calcular o número de repetições do valor único médio da coluna key1:idx_key120187Cardinality25620187÷256≈79
Agora observe a declaração de consulta acima:
select * from demo8 where key1 in ('aa', 'bb', 'cc', ... , 'ee');
Supondo que haja um parâmetro na instrução IN 20000, os dados estatísticos são usados diretamente para estimar o número de registros correspondentes ao intervalo de ponto único para esses parâmetros. Cada parâmetro corresponde a aproximadamente um 79registro, portanto, o número total de registros que precisam a ser devolvido à mesa é:20000 x 79 = 1580000
Usar dados estatísticos para calcular o número de registros de índice correspondentes a um intervalo de ponto único index diveé muito mais simples, mas sua fraqueza fatal é: o 不精确!custo da consulta calculado usando dados estatísticos pode ser muito diferente do custo real.
小提示:
Quando a consulta IN é usada em sua consulta, mas o índice não é realmente usado, você deve considerar se o valor eq_range_index_dive_limit é muito pequeno
3. O custo da consulta de conexão
2.1 Preparar dados
A consulta de conexão requer pelo menos duas tabelas, e apenas uma tabela demo8 não é suficiente, portanto, para o bom desenvolvimento da história, construímos diretamente duas tabelas s1 e s2 exatamente iguais à tabela demo8
mysql> create table s1 (
id int not null auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key (id),
key idx_key1 (key1),
unique key idx_key2 (key2),
key idx_key3 (key3),
key idx_key_part(key_part1, key_part2, key_part3));
Query OK, 0 rows affected (0.04 sec)
mysql> create table s2 (
id int not null auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key (id),
key idx_key1 (key1),
unique key idx_key2 (key2),
key idx_key3 (key3),
key idx_key_part(key_part1, key_part2, key_part3));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into s1 select * from demo8;
Query OK, 20000 rows affected (0.83 sec)
Records: 20000 Duplicates: 0 Warnings: 0
mysql> insert into s2 select * from demo8;
Query OK, 20000 rows affected (0.89 sec)
Records: 20000 Duplicates: 0 Warnings: 0
2.2 Introdução à filtragem de condição
Como dissemos antes, a consulta de junção no MySQL usa o algoritmo de junção de loop aninhado, a tabela de direção será acessada uma vez e a tabela de direção pode ser acessada várias vezes, portanto, para a consulta de junção de duas tabelas, o custo da consulta é o seguinte Consiste em duas partes:
- O custo de uma única consulta direcionando a tabela
- O custo de consultar a tabela direcionada várias vezes (
具体查询多少次取决于对驱动表查询的结果集中有多少条记录)
Chamamos o número de registros obtidos após consultar a tabela de condução como a tabela de condução 扇出(nome em inglês: fanout). Obviamente, quanto menor o valor fan-out da tabela de direcionamento, menor o número de consultas à tabela de direcionamento e menor o custo total da consulta de conexão. Quando o otimizador de consulta deseja calcular o custo de toda a consulta de junção, ele precisa calcular o valor fan-out da tabela de direcionamento. Às vezes, o cálculo do valor fan-out é muito fácil, como nas duas consultas a seguir:
Consulta um:
select * from s1 inner join s2;
Supondo que s1a tabela seja usada como tabela de controle, é óbvio que a consulta de tabela única da tabela de controle só pode ser realizada por varredura completa da tabela, e o valor de fan-out da tabela de controle também é muito claro, ou seja , quantos registros estão na tabela de controle, o valor de fan-out é o número . O número de registros na tabela s1 nos dados estatísticos é yes 20250, ou seja, o otimizador irá 20250considerá-lo diretamente como o valor de fan-out na s1tabela.
Consulta dois:
select * from s1 inner join s2 where s1.key2 > 10 and s1.key2 < 1000;
Ainda assumindo que a tabela s1 é a tabela de direção, é óbvio que as consultas de tabela única na tabela de direção podem usar o índice idx_key2 para realizar consultas. Neste momento, quantos registros existem no intervalo de alcance (10, 1000) de idx_key2, então qual é o valor fan-out. Calculamos anteriormente que o número de registros que satisfazem o intervalo de intervalo (10, 1000) de idx_key2 é 989, o que significa que, nessa consulta, o otimizador considerará 95 como o valor fan-out da tabela de controle s1.
Claro, as coisas nem sempre correm bem, ou o enredo seria muito plano. Às vezes, o cálculo do valor do fan-out torna-se complicado, como a seguinte consulta:
Pergunta três:
select * from s1 inner join s2 where s1.common_field > 'xyz'
common_field > 'xyz'Esta consulta é semelhante à consulta 1, exceto que há mais uma condição de pesquisa para a tabela de direcionamento s1 . O otimizador de consulta não executará realmente a consulta, portanto, quantos registros neste 只能猜registro satisfazem a condição common_field > 'xyz'20250
Pergunta quatro:
select * from s1 inner join s2 where s1.key2 > 10 and s1.key2 < 1000 and s1.common_field > 'xyz'
No entanto, como essa consulta pode usar idx_key2índices, é necessário apenas adivinhar quantos registros atendem às condições dos registros que atendem ao intervalo do índice secundário common_field > 'xyz', ou seja, apenas 猜quantos 989registros atendem common_field > 'xyz'às condições
Pergunta cinco:
select * from s1 inner join s2 where s1.key2 > 10 and s1.key2 < 1000 and s1.key1 in('aa','bb','cc') and s1.common_field > 'xyz'
Esta consulta é semelhante à consulta 2, mas depois que a tabela do drive s1seleciona idx_key1o índice para executar a consulta, o otimizador precisa selecionar 猜quantos registros dos registros que atendem ao intervalo do índice secundário atendem às duas condições a seguir:
- key2 > 10 e key2 < 1000
- campo_comum > 'xyz'
Ou seja, o otimizador precisa adivinhar 230quantos registros atendem às duas condições acima.
Tendo dito tanto, na verdade, quero expressar que, nesses dois casos, é necessário confiar em suposições ao calcular o valor do fan-out da tabela do drive:
- Se você usar uma consulta de tabela única executada por varredura de tabela completa, precisará adivinhar quantos registros satisfazem a condição de pesquisa ao calcular o fan-out da tabela de controle
- Se você estiver usando uma varredura de tabela única executada por um índice, precisará adivinhar quantos registros satisfazem outras condições de pesquisa diferentes daquelas que usam o índice correspondente ao calcular o fan-out da tabela de controle.
O MySQL chama esse processo de adivinhação condition filtering. Claro, este processo pode usar índices ou dados estatísticos, ou pode ser pura suposição do MySQL. Todo o processo de avaliação é bastante complicado, então nós o ignoramos.
2.3 Análise de custo de conexão multi-tabela
Aqui, consideramos primeiro quantas sequências de conexão podem ser geradas durante a conexão multitabela:
- Para a conexão de duas tabelas, como a conexão entre a tabela A e a tabela B, existem apenas duas sequências de conexão de AB e BA. Na verdade, é equivalente a 2 × 1 = 2 sequências de conexão
- Para a conexão de três tabelas, como tabela A, tabela B e tabela C, existem seis sequências de conexão, como ABC, ACB, BAC, BCA, CAB e CBA. Na verdade, é equivalente a 3 × 2 × 1 = 6 sequências de conexão
- Para quatro conexões de mesa, haverá 4 × 3 × 2 × 1 = 24 sequências de conexão
- Para a conexão de n tabelas, existem n × (n-1) × (n-2) × ··· × 1 sequência de conexão, que é a sequência fatorial de conexão de n, ou seja, n!
4. Constante de custo de ajuste
Apresentamos dois anteriormente 成本常数:
- O custo padrão de leitura de uma página é:
0.25 - O custo padrão de verificar se um registro corresponde aos critérios de pesquisa é:
0.1
Na verdade, além dessas duas constantes de custo, o MySQL também suporta muito, e elas são armazenadas em mysqlduas tabelas do banco de dados (este é um banco de dados do sistema, que apresentamos anteriormente):
mysql> show tables from mysql like '%cost%';
+--------------------------+
| Tables_in_mysql (%cost%) |
+--------------------------+
| engine_cost |
| server_cost |
+--------------------------+
2 rows in set (0.06 sec)
Como dissemos antes, a execução de uma instrução é, na verdade, dividida em duas camadas:
- camada do servidor
- camada do mecanismo de armazenamento
Noserver层 gerenciamento de conexão, cache de consulta, análise de sintaxe, otimização de consulta e outras operações, operações específicas de acesso a dados são executadas na camada do mecanismo de armazenamento. Ou seja, o custo de execução de uma instrução na camada servidor não tem nada a ver com o mecanismo de armazenamento utilizado pela tabela na qual ela opera, portanto, as constantes de custo correspondentes a essas operações são armazenadas na tabela server_cost e dependem de alguns operações do mecanismo de armazenamento A constante de custo correspondente é armazenada na tabela engine_cost
4.1 tabela server_cost
As constantes de custo correspondentes a algumas operações realizadas na camada servidor na tabela server_cost são as seguintes:
mysql> select * from mysql.server_cost;
+------------------------------+------------+---------------------+---------+---------------+
| cost_name | cost_value | last_update | comment | default_value |
+------------------------------+------------+---------------------+---------+---------------+
| disk_temptable_create_cost | NULL | 2023-04-24 19:39:12 | NULL | 20 |
| disk_temptable_row_cost | NULL | 2023-04-24 19:39:12 | NULL | 0.5 |
| key_compare_cost | NULL | 2023-04-24 19:39:12 | NULL | 0.05 |
| memory_temptable_create_cost | NULL | 2023-04-24 19:39:12 | NULL | 1 |
| memory_temptable_row_cost | NULL | 2023-04-24 19:39:12 | NULL | 0.1 |
| row_evaluate_cost | NULL | 2023-04-24 19:39:12 | NULL | 0.1 |
+------------------------------+------------+---------------------+---------+---------------+
6 rows in set (0.00 sec)
Vamos primeiro ver o que cada coluna de server_cost significa:
cost_name: Indica o nome da constante de custocost_value: Indica o valor correspondente à constante de custo. Se o valor desta coluna for NULL, significa que a constante de custo correspondente adotará o valor padrãolast_update: Indica a hora em que o registro foi atualizado pela última vezcomment: Comentedefault_value:Padrões
Pode ser visto a partir do conteúdo em server_cost que as constantes de custo correspondentes a algumas operações na camada do servidor são as seguintes:
| nome da constante de custo | Padrões | descrever |
|---|---|---|
| disk_temptable_create_cost | 40,0 | O custo de criação de tabelas temporárias baseadas em disco. Se você aumentar esse valor, o otimizador criará o mínimo possível de tabelas temporárias baseadas em disco. |
| disk_temptable_row_cost | 1,0 | O custo de gravar ou ler um registro em uma tabela temporária baseada em disco. Se você aumentar esse valor, o otimizador criará o mínimo possível de tabelas temporárias baseadas em disco |
| key_compare_cost | 0,1 | O custo de comparar dois registros é usado principalmente em operações de classificação. Se esse valor for aumentado, o custo do filesort será aumentado e o otimizador pode estar mais inclinado a usar índices para concluir a classificação em vez do filesort |
| memory_temptable_create_cost | 2.0 | O custo de criação de tabelas temporárias baseadas em memória. Se você aumentar esse valor, o otimizador criará o mínimo possível de tabelas temporárias baseadas em memória. |
| memory_temptable_row_cost | 0,2 | O custo de gravar ou ler um registro em uma tabela temporária baseada em memória. Se você aumentar esse valor, o otimizador criará o mínimo possível de tabelas temporárias baseadas em memória |
| row_evaluate_cost | 0,2 | Este é o custo de detectar se um registro atende aos critérios de pesquisa que usamos antes. Aumentar esse valor pode tornar o otimizador mais inclinado a usar índices em vez de verificações diretas de tabelas completas |
小提示:
O MySQL pode criar uma tabela temporária internamente ao executar consultas como consultas DISTINCT, consultas de agrupamento, consultas Union e consultas de classificação sob certas condições especiais e usar esta tabela temporária para ajudar a concluir a consulta (por exemplo, para consultas DISTINCT, você pode crie um com A tabela temporária do índice UNIQUE insere diretamente os registros que precisam ser desduplicados nessa tabela temporária e o registro após a conclusão da inserção é o conjunto de resultados). No caso de uma grande quantidade de dados, é possível criar uma tabela temporária baseada em disco, ou seja, usar mecanismos de armazenamento como MyISAM e InnoDB para a tabela temporária e criar uma tabela temporária baseada em memória quando o quantidade de dados não é grande, ou seja, para usar o armazenamento de memória do mecanismo do produto. Todos aqui sabem que o custo de criar uma tabela temporária e escrever e ler essa tabela temporária ainda é muito alto.
server_costOs valores iniciais dessas constantes de custo NULLsão , o que significa que o otimizador usará seus valores padrão para calcular o custo de uma operação. Se quisermos modificar o valor de uma determinada constante de custo, precisamos fazer duas etapas :
Etapa 1: atualizar a constante de custo em que estamos interessados
Por exemplo, se quisermos aumentar o custo de verificar se um registro atende aos critérios de pesquisa para 0.3, podemos escrever uma declaração de atualização como esta:
update mysql.server_cost set cost_value = 0.4 where cost_name = 'row_evaluate_cost';
Passo 2: Deixe o sistema recarregar o valor desta tabela, basta usar a seguinte instrução
flush optimizer_costs;
Claro, se você quiser mudá-los de volta depois de modificar uma determinada constante de custo 默认值, você pode cost_valuedefinir diretamente o valor como NULLe, em seguida, usar flush optimizer_costsa instrução para permitir que o sistema o recarregue.
4.2 tabela engine_cost
engine_costAs constantes de custo correspondentes a algumas operações realizadas na camada do mecanismo de armazenamento na tabela são as seguintes:
mysql> select * from mysql.engine_cost;
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+
| engine_name | device_type | cost_name | cost_value | last_update | comment | default_value |
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+
| default | 0 | io_block_read_cost | NULL | 2023-04-24 19:39:12 | NULL | 1 |
| default | 0 | memory_block_read_cost | NULL | 2023-04-24 19:39:12 | NULL | 0.25 |
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+
2 rows in set (0.01 sec)
Em comparação com server_cost, engine_costhá mais duas colunas:
engine_nameColuna: Refere-se ao nome do mecanismo de armazenamento ao qual a constante de custo se aplica. Se o valor for padrão, significa que a constante de custo correspondente se aplica a todos os mecanismos de armazenamentodevice_typeColuna: refere-se ao tipo de dispositivo usado pelo mecanismo de armazenamento. Isso é principalmente para distinguir entre discos rígidos mecânicos convencionais e discos rígidos de estado sólido. No entanto, no MySQL 5.7.21,
o O valor é 0 por padrão
Podemos ver no conteúdo da tabela engine_cost que há apenas duas constantes de custo do mecanismo de armazenamento suportadas atualmente:
| nome da constante de custo | Padrões | descrever |
|---|---|---|
| io_block_read_cost | 1,0 | O custo de ler um bloco do disco. Note que eu uso a palavra bloco, não página. Para o mecanismo de armazenamento InnoDB, uma página é um bloco, mas para o mecanismo de armazenamento MyISAM, o padrão é 4096 bytes como um bloco. Aumentar esse valor aumentará o custo de E/S, o que pode tornar o otimizador mais inclinado a optar por usar o índice para realizar consultas em vez de executar varreduras completas de tabelas |
| memory_block_read_cost | 0,25 | Semelhante ao parâmetro anterior, exceto que mede o custo correspondente à leitura de um bloco da memória |
Depois de ler os valores padrão dessas duas constantes de custo, você está um pouco confuso? Por que o custo padrão de ler um bloco da memória é diferente do custo do disco? Isso ocorre principalmente porque, à medida que o MySQL evolui, o MySQL pode prever com precisão quais blocos estão no disco e quais estão na memória.
Assim como atualizar server_costos registros na tabela, também podemos engine_costalterar a constante de custo sobre o mecanismo de armazenamento atualizando os registros na tabela e também podemos engine_costadicionar uma constante de custo específica para um determinado mecanismo de armazenamento inserindo um novo registro para a tabela:
Etapa 1: Insira uma constante de custo para um determinado mecanismo de armazenamento.
Por exemplo, se quisermos aumentar o custo de E/S da página do mecanismo de armazenamento InnoDB, basta escrever uma instrução de inserção normal:
insert into mysql.engine_cost values ('innodb', 0, 'io_block_read_cost', 2.0, current_timestamp, 'increase innodb i/o cost');
Passo 2: Deixe o sistema recarregar o valor desta tabela usando a seguinte instrução:
flush optimizer_costs;
Até agora, o estudo de hoje acabou, espero que você se torne um eu indestrutível
~~~
Você não pode ligar os pontos olhando para frente; você só pode conectá-los olhando para trás. Portanto, você precisa confiar que os pontos de alguma forma se conectarão em seu futuro. Você precisa confiar em algo - seu instinto, destino, vida, karma, seja o que for. Essa abordagem nunca me decepcionou e fez toda a diferença na minha vida
Se meu conteúdo for útil para você, por favor 点赞, criar não é fácil, o apoio de todos é a 评论motivação 收藏para eu perseverar
