prefácio
Depois de aprender, explicamos os sete componentes da página de dados do InnoDB. Sabemos que cada página de dados pode formar uma lista vinculada bidirecional e os registros em cada página de dados formarão uma lista vinculada unidirecional na ordem da chave primária valores de pequeno a grande. Cada página de dados gerará um diretório de páginas para os registros armazenados nela. Ao pesquisar um registro por meio da chave primária, você pode usar o método de dicotomia no diretório de páginas para localizar rapidamente o slot correspondente, e, em seguida, percorra o grupo correspondente do slot.registros para localizar rapidamente o registro especificado. Então, desenhamos um diagrama simples da relação da seguinte forma:
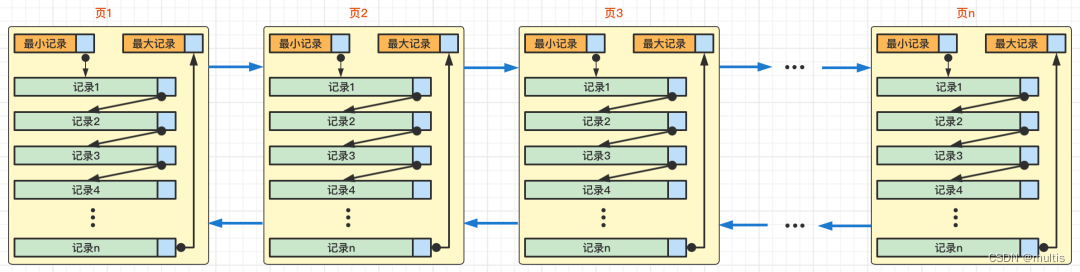
Em que página 1, página 2, página 3... página n essas páginas podem não estar conectadas na estrutura física, mas apenas precisam ser associadas por meio de uma lista duplamente encadeada.
Sempre ouvi dizer que criar um índice para o banco de dados pode melhorar o desempenho da consulta, mas o que é um índice e como ele funciona? Hoje, vamos aprender sobre o índice de árvore B+ do mecanismo de armazenamento InnoDB.
Índice
- 1. Pesquise sem índice
- 2. Índice
- 3. Índice Agrupado
- Em quarto lugar, o índice secundário (Índice Secundário)
- 5. Índice conjunto (índice composto)
- 6. Precauções para o índice de árvore B+ do InnoDB
- Sete, uma breve introdução ao esquema de índice no MyISAM
- 8. Instruções para criar e excluir índices no MySQL
- Nove. Resumo
1. Pesquise sem índice
Antes de aprender formalmente o índice, precisamos entender como encontrar registros quando não há índice. Para facilitar o entendimento, usamos apenas a condição de pesquisa para corresponder exatamente a uma determinada coluna (correspondência exata significa que a condição de pesquisa é igual a = para conectar a expressão) como um exemplo, como a seguinte declaração:
select[列名列表] from 表名 where 列名 = xxx;
1.1 Pesquisar em uma página
Sabemos que o tamanho de uma página de dados é de 16KB (16384 bytes), exceto que as informações de metadados necessárias na página requerem uma parte do espaço de armazenamento, sobrará muito espaço para armazenar nossos Registros de Usuário. Assumindo que existem relativamente poucos registros na tabela atual, todos os registros podem ser armazenados em uma página. Ao pesquisar registros, pode ser dividido em duas situações de acordo com diferentes condições de pesquisa:
-
A chave primária é usada como condição de pesquisa.Use
o método de dicotomia no diretório da página para localizar rapidamente o slot correspondente (Slot) e, em seguida, percorra os registros no grupo correspondente ao slot para encontrar rapidamente o registro especificado. -
Usando outras colunas como critérios de pesquisa
O processo de pesquisa de colunas de chave não primária não é tão feliz, porque não há o chamado diretório de página para colunas de chave não primária na página de dados, portanto, não podemos localizar rapidamente os slots correspondentes por meio de o método da dicotomia. Nesse caso, podemos apenas percorrer cada registro na lista encadeada individualmente começando pelo menor registro e, em seguida, comparar se cada registro atende às condições de pesquisa. Obviamente, a eficiência dessa busca é muito baixa.
1.2 Encontre em muitas páginas
Na maioria dos casos, há muitos registros armazenados em nossa tabela e muitas páginas de dados são necessárias para armazenar esses registros. Encontrar registros em muitas páginas pode ser dividido em duas etapas:
- Navegue até a página onde o registro está localizado.
- Encontre o registro correspondente na página em que você está.
Na ausência de um índice, seja pesquisando com base nos valores da coluna de chave primária ou em outras colunas, uma vez que não podemos localizar rapidamente a página onde o registro está localizado, podemos apenas pesquisar a lista duplamente vinculada a partir da primeira página .Em cada página, encontre o registro especificado de acordo com o método de pesquisa que acabamos de falar. Como todas as páginas de dados devem ser percorridas, esse método obviamente consome muito tempo.Se uma tabela tiver 100 milhões de registros, se você usar esse método para encontrar registros, terá que esperar até que o macaco anos para obter os resultados da pesquisa.
Então, o índice entra em jogo.
2. Índice
Para facilitar a exibição, primeiro criamos uma tabela:
mysql> create table demo6(c1 int primary key,c2 int,c3 char(1)) row_format=compact;
Query OK, 0 rows affected (0.02 sec)
A tabela demo6 recém-criada possui 2 colunas do tipo int e 1 coluna do tipo char(1), e estipulamos que a coluna c1 é a chave primária.Esta tabela usa o formato de linha Compact para realmente armazenar registros. Para facilitar o entendimento do índice, simplificamos o diagrama de formato de linha da tabela demo6:
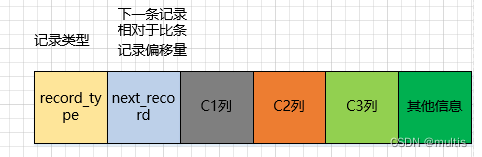
Vamos revisar o significado específico dessas partes mostradas:
- record_type: Um atributo da informação do cabeçalho do registro, indicando o tipo de registro, 0 significa registro comum, 2 significa o menor registro, 3 significa o maior registro, 1 ainda não usamos, falaremos sobre isso em breve
- next_record: Um atributo das informações do cabeçalho do registro, indicando o deslocamento do endereço do próximo endereço relativo a este registro. Para facilitar o entendimento, setas são usadas para indicar quem é o próximo registro
- O valor de cada coluna: apenas três colunas na tabela demo6 são registradas aqui, ou seja, c1, c2 e c3
- Outras informações: Todas as informações, exceto os 3 tipos de informações acima, incluindo os valores de outras colunas ocultas e informações adicionais registradas.
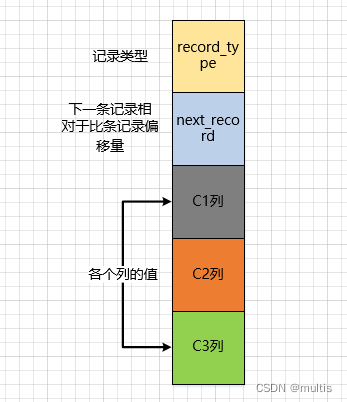
Vamos fazer alguns ajustes no diagrama novamente, removendo outras informações do diagrama de formato de registro e montando-o. Este é o efeito:
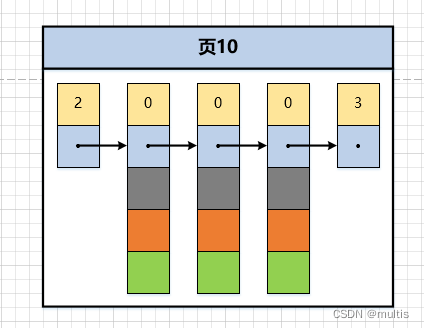
O diagrama esquemático de colocar alguns registros na página é o seguinte (veja a cor para saber o significado):
2.1 Um esquema de indexação simples
Voltando ao tópico, por que percorrer todas as páginas de dados ao procurar alguns registros com base em uma determinada condição de pesquisa? Como os registros em cada página não são regulares, não sabemos quais registros em quais páginas nossas condições de pesquisa correspondem, então temos que percorrer todas as páginas de dados sucessivamente. E se quisermos localizar rapidamente em quais páginas de dados estão os registros que precisamos encontrar? Lembra do diretório de páginas que configuramos para localizar rapidamente a posição de um registro na página com base no valor da chave primária? Também podemos encontrar uma maneira de criar outro diretório para localizar rapidamente a página de dados onde o registro está localizado. Para criar esse diretório, as seguintes coisas devem ser feitas:
Primeiro: o valor da chave primária do registro do usuário na próxima página de dados deve ser maior que o valor da chave primária do registro do usuário na página anterior
Precisamos fazer uma suposição aqui: suponha que cada uma de nossas páginas de dados possa armazenar até 3 registros (na verdade, uma página de dados é muito grande e pode armazenar muitos registros). Com essa suposição, demo6inserimos 3 registros na tabela:
mysql> insert into demo6 values(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
Em seguida, esses registros foram concatenados em uma lista vinculada unidirecional de acordo com o tamanho do valor da chave primária, conforme mostrado na figura:
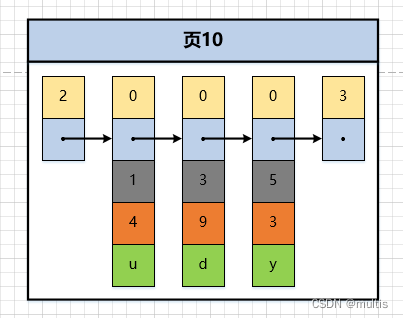
Pode ser visto na figura que demo6todos os três registros na tabela foram inseridos na página de dados numerada 10. Agora vamos inserir outro registro:
mysql> insert into demo6 values(4, 4, 'a');
Query OK, 1 row affected (0.01 sec)
A página 10 só pode conter até 3 registros, então temos que alocar uma nova página
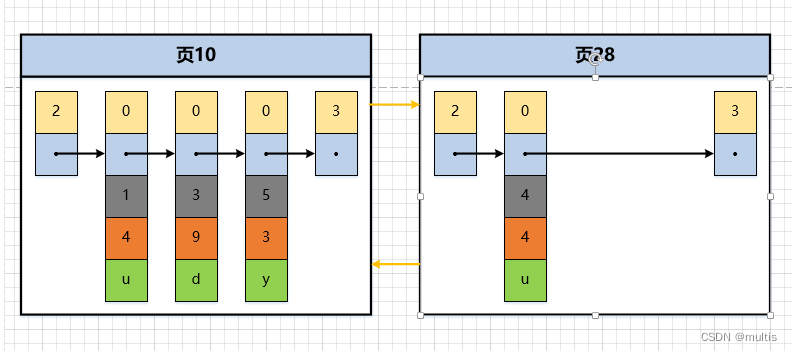
Os números das páginas de dados recém-alocadas podem não ser consecutivos, o que significa que as páginas que usamos podem não estar próximas umas das outras no espaço de armazenamento. Eles apenas estabelecem um relacionamento de lista encadeada mantendo os números da página anterior e da página seguinte.
O valor máximo da chave primária do registro do usuário na página 10 é 5, e o valor da chave primária de um registro na página 28 é 4, porque 5 > 4, portanto, isso não atende ao requisito de que o valor da chave primária do registro do usuário na próxima página de dados deve ser maior que a exigência do valor da chave primária do registro do usuário na página anterior, portanto, ao inserir o registro com o valor da chave primária de 4, ele precisa ser acompanhado de uma movimentação de registro, ou seja , o registro com o valor de chave primária de 5 é movido para a página 28 e, em seguida, insira um registro com um valor de chave primária de 4 na página 10. O diagrama esquemático desse processo é o seguinte:
-
Mova o registro com valor de chave primária 5 para a página 28
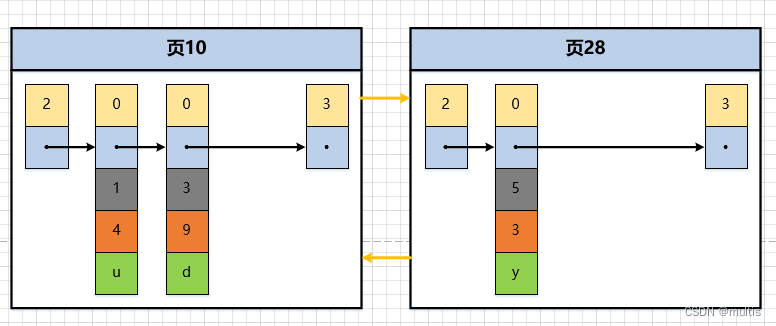
-
Insira a chave primária 4 na página 10

Esse processo mostra que no processo de adicionar, excluir e modificar registros na página, devemos sempre garantir esse estado por meio de algumas operações como movimentação de registros: o valor da chave primária do registro do usuário na próxima página de dados deve ser maior que o anterior O valor da chave primária do registro do usuário na página. Também podemos chamar esse processo de页分裂.
Segundo: crie uma entrada de diretório para todas as páginas
Como os números das páginas de dados podem não ser contínuos, após demo6inserir muitos registros na tabela, o efeito pode ser o seguinte:
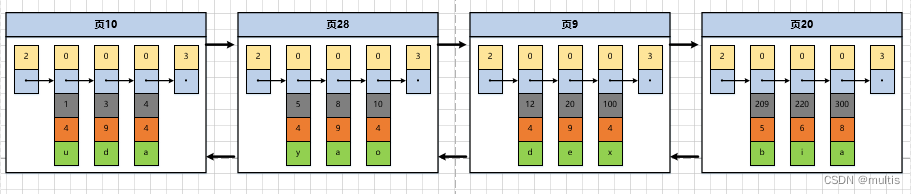
Como essas páginas de 16 KB podem não estar próximas umas das outras no armazenamento físico, se quisermos localizar rapidamente a página onde alguns registros estão localizados com base no valor da chave primária de tantas páginas, precisamos criar um diretório para eles e cada página corresponde a um Itens de diretório, cada item de diretório inclui as duas partes a seguir:
- O menor valor de chave primária no registro do usuário da página, denotamos
keypor - Número da página, denotamos
page_nopor
Assim, o catálogo que fizemos nas páginas anteriores fica assim:
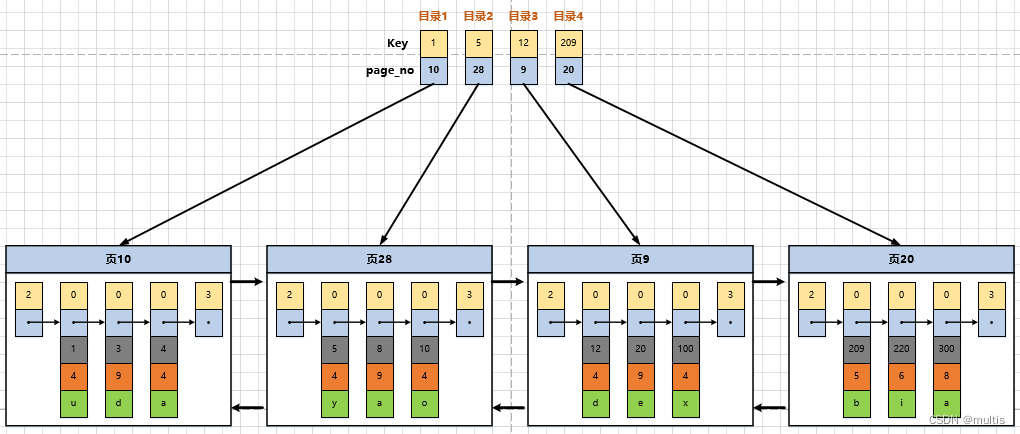
Tomando como exemplo a página 28, corresponde ao item 2 do diretório, que contém o número da página 28 da página e o valor mínimo da chave primária 5 dos registros do usuário na página. Precisamos apenas armazenar vários itens de diretório continuamente na memória física, por exemplo, colocá-los em uma matriz e, então, podemos realizar a função de pesquisar rapidamente um determinado registro de acordo com o valor da chave primária. Por exemplo, se queremos encontrar registos com um valor de chave primária de 20, o processo de pesquisa específico divide-se em dois passos:
- Primeiro, determine rapidamente a partir da entrada do diretório que o registro com um valor de chave primária de 20 está na entrada do diretório 3 (porque 12<20<209) e sua página correspondente é a página 9.
- Em seguida, vá para a página 9 para localizar o registro específico de acordo com o método de busca de registros na página mencionada acima.
Até agora, o índice simples da página de dados está pronto. Este diretório tem um alias chamado index.
2.2 Esquema de índice no InnoDB
A razão pela qual o acima é chamado de esquema de indexação simples é porque assumimos que todas as entradas de diretório podem ser armazenadas continuamente na memória física para usar o método de dicotomia para localizar rapidamente entradas de diretório específicas ao pesquisar com base no valor da chave primária, mas isso tem alguns problemas:
- O InnoDB utiliza as páginas como unidade básica para gerenciamento do espaço de armazenamento, ou seja, pode garantir um espaço de armazenamento contínuo de até 16KB, e conforme o número de registros na tabela aumenta, é necessário um espaço de armazenamento contínuo muito grande para armazenar todos os diretórios entradas. , o que não é realista para tabelas com um número muito grande de registros.
- Muitas vezes adicionamos e excluímos registros. Suponha que excluímos todos os registros na página 28, não há necessidade da página 28, o que significa que não há necessidade do item de diretório 2, que requer o item de diretório Os itens de diretório após 2 são todos movidos para a frente. Esse tipo de design que afeta todo o corpo não é uma boa ideia ~
Portanto, o InnoDB precisa de uma maneira de gerenciar com flexibilidade todas as entradas de diretório. Essas entradas de diretório realmente se parecem com nossos registros de usuário, exceto que as duas colunas nas entradas de diretório são chaves primárias e números de página, portanto, elas reutilizam as páginas de dados que armazenavam registros de usuário anteriormente para armazenar entradas de diretório. Para fazer uma distinção, referimos a esses registros usados para representar entradas de diretório como registros de entrada de diretório. Então, como o InnoDB distingue se um registro é um registro de usuário comum ou um registro de entrada de diretório? Não se esqueça de registrar os atributos nas informações do cabeçalho record_type. Os significados de cada valor são os seguintes:
0:registro de usuário normal1:registro de entrada de diretório2:registro mínimo3:maior recorde
Você entende o significado do valor record_type de 1? O diagrama esquemático de colocar os itens de diretório que usamos anteriormente na página de dados é o seguinte:
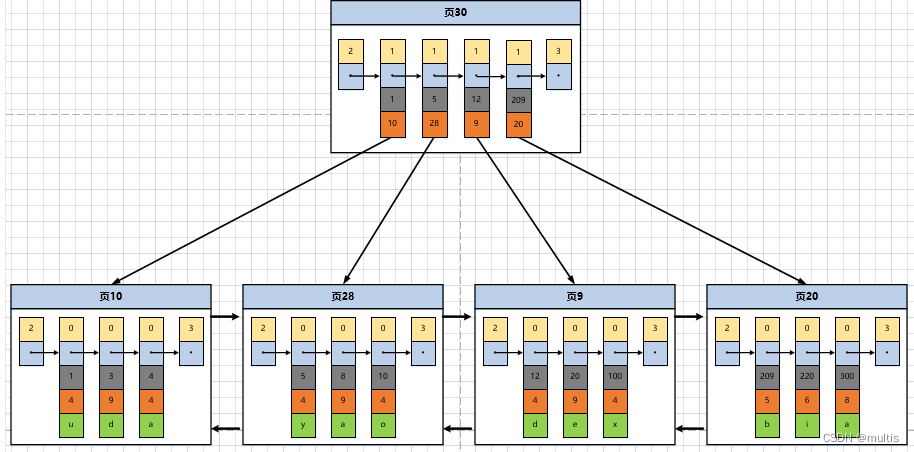 Como pode ser visto na figura, alocamos recentemente uma página numerada 30 para armazenar registros de entrada de diretório. Aqui, novamente, a diferença entre registros de entrada de diretório e registros de usuários comuns é enfatizada:
Como pode ser visto na figura, alocamos recentemente uma página numerada 30 para armazenar registros de entrada de diretório. Aqui, novamente, a diferença entre registros de entrada de diretório e registros de usuários comuns é enfatizada:
- O valor record_type dos registros de entrada de diretório é 1, enquanto o valor record_type dos registros de usuários comuns é 0
- Os registros de entrada do diretório possuem apenas duas colunas, o valor da chave primária e o número da página, enquanto as colunas dos registros de usuário comuns são definidas pelo usuário e podem conter muitas colunas.Além disso, existem colunas ocultas adicionadas pelo próprio InnoDB.
- Você ainda se lembra que quando estávamos falando sobre as informações do cabeçalho do registro, dissemos que existe um atributo chamado ? Apenas o valor min_rec_mask do registro de entrada de diretório com o menor valor de chave primária na página que armazena o registro de entrada de diretório é 1, e o valor
min_rec_maskde outros registros émin_rec_mask
Exceto pelos pontos acima, não há diferença entre as duas, elas usam a mesma página de dados (o tipo da página é 0x45bf), e a estrutura da página também é a mesma, e ambas irão gerar um Diretório de Páginas para o valor da chave primária (diretório da página) para que a dicotomia possa ser usada para acelerar as consultas ao procurar pelo valor da chave primária. Agora considere a busca por um registro com uma chave primária de 20 como exemplo. As etapas para localizar um registro com base em um determinado valor de chave primária podem ser divididas aproximadamente nas duas etapas a seguir:
- Primeiro, vá para a página onde o registro de entrada do diretório está armazenado, ou seja, a página 30 localiza rapidamente a entrada do diretório correspondente pelo método da dicotomia, porque 12<20<209, portanto, a página onde o registro correspondente está localizado é a página 9
- Vá para a página 9 onde os registros do usuário estão armazenados e localize rapidamente os registros do usuário com um valor de chave primária de 20 de acordo com a dicotomia
Embora apenas o valor da chave primária e o número da página correspondente sejam armazenados no registro de entrada do diretório, que é muito menor do que o espaço de armazenamento exigido pelo registro do usuário, mas de qualquer maneira, uma página tem apenas 16 KB de tamanho e os registros de entrada do diretório que podem ser armazenados também são limitados.Se houver muitos dados na tabela, de modo que uma página de dados não seja suficiente para armazenar todos os registros de entrada de diretório, o que devo fazer?
Claro, há mais uma página para armazenar registros de entrada de diretório~ Para entender melhor o processo de alocação de uma nova página de registro de entrada de diretório, assumimos que uma página para armazenar registros de entrada de diretório pode armazenar apenas até 4 registros de entrada de diretório ( Observe que é uma suposição, pode armazenar muitas entradas na situação real), portanto, se inserirmos um registro de usuário com um valor de chave primária de 320 na imagem superior neste momento, precisamos alocar um novo página para armazenar registros de entrada de diretório. :
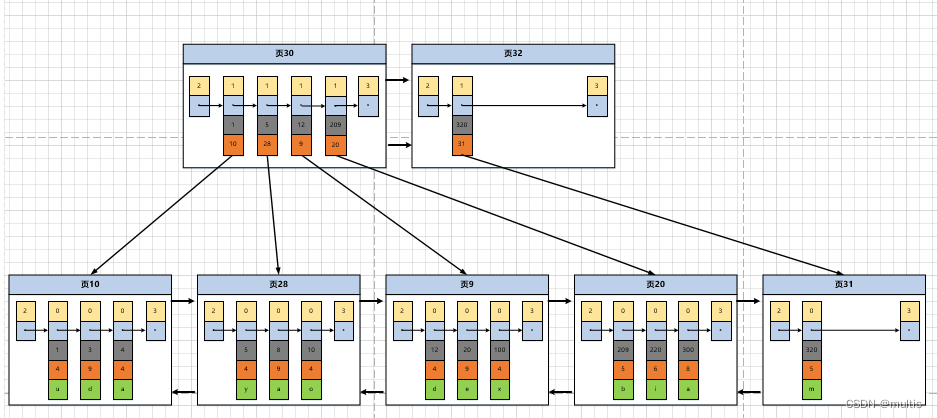
Como pode ser visto na figura, precisamos de duas novas páginas de dados após inserir um registro de usuário com um valor de chave primária de 320:
- A página 31 foi criada recentemente para armazenar este registro de usuário
- Como a capacidade da página 30 que originalmente armazenava registros de entrada de diretório está cheia (assumimos que apenas 4 registros de entrada de diretório podem ser armazenados), uma nova página 32 deve ser necessária para armazenar a entrada de diretório correspondente à página 31
Agora, como há mais de uma página para armazenar registros de entrada de diretório, se quisermos encontrar um registro de usuário com base no valor da chave primária, são necessárias cerca de 3 etapas. Faça a pesquisa por um registro com um valor de chave primária de 20 como um exemplo:
- Determine a página de registro de entrada de diretório, agora temos duas páginas para armazenar registros de entrada de diretório, ou seja, página 30 e página 32, e porque o intervalo do valor da chave primária da entrada de diretório representado pela página 30 é [1, 320), página 32 representa O valor da chave primária da entrada do diretório não é menor que 320, portanto, a entrada do diretório correspondente ao registro com o valor da chave primária de 20 é registrada na página 30
- Determine a página onde o registro do usuário está realmente localizado por meio da página de registro do item do diretório
- Localize registros específicos na página que realmente armazena os registros do usuário
Aqui vem o problema. Na primeira etapa desta etapa de consulta, precisamos localizar as páginas que armazenam os registros de entrada do diretório, mas essas páginas podem não estar próximas umas das outras no espaço de armazenamento. Se houver muitos dados em nosso tabela, muitos diretórios de armazenamento serão gerados. página de registro de item, como localizar rapidamente uma página que armazena registros de item de diretório com base no valor da chave primária? Na verdade, também é simples. Um diretório mais avançado é gerado para essas páginas que armazenam registros de itens de diretório, assim como um diretório de vários níveis. Diretórios pequenos são aninhados em diretórios grandes e os dados reais estão nos diretórios pequenos. Então agora cada página O esquema fica assim:
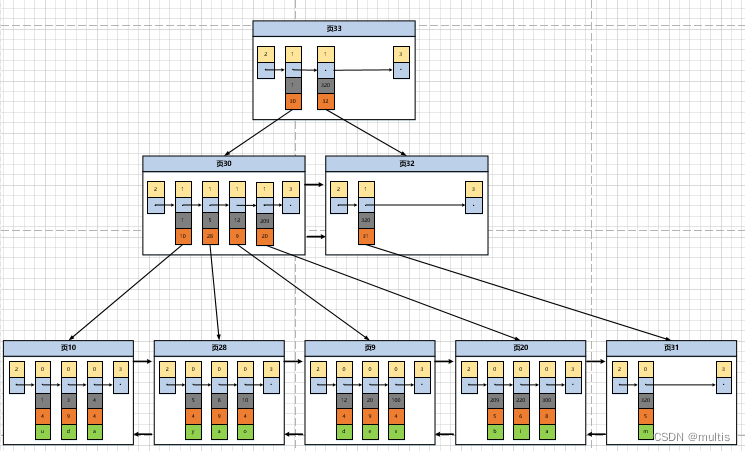
Conforme mostrado na figura, geramos uma página 33 que armazena itens de diretório de nível superior. Os dois registros nesta página representam a página 30 e a página 32, respectivamente. Se o valor da chave primária do registro do usuário estiver entre [1, 320) , vá para a página 30 para encontrar registros de entrada de diretório mais detalhados, se o valor da chave primária não for inferior a 320, vá para a página 32 para encontrar registros de entrada de diretório mais detalhados. À medida que os registros na tabela aumentam, a hierarquia desse diretório continuará a aumentar. Esta imagem não é como uma árvore de cabeça para baixo, com raízes em cima e folhas embaixo! Na verdade, esta é uma forma de organização de dados, ou uma estrutura de dados, e seu nome é árvore B+.
Seja uma página de dados que armazena registros de usuários ou uma página de dados que armazena registros de itens de diretório, nós os armazenamos na estrutura de dados da árvore B+, então também chamamos essas páginas de nós de nós. Como pode ser visto na figura, nossos registros de usuário reais são realmente armazenados nos nós inferiores da árvore B+. Esses nós também são chamados, e o restante dos nós usados para armazenar itens de diretório são chamados , entre os quais o 叶子节点或叶节点topo 非叶子节点或者内节点do A árvore B+ é chamada também conhecida como nó 根节点.
Pode-se ver na figura que os nós de uma árvore B+ podem realmente ser divididos em várias camadas. Para facilitar a discussão, o InnoDB estipula que a camada inferior, ou seja, a camada onde nossos registros de usuário são armazenados, é a 0ª camada e, em seguida, adicionar sequencialmente. No ambiente real, o número de registros armazenados em uma página é muito grande. Assuma, suponha, suponha que todas as páginas de dados representadas por nós folha que armazenam registros de usuários podem armazenar 100 registros de usuários e todas as páginas de dados representadas por nós internos armazenando diretório registros de entrada podem Para armazenar 1000 registros de entrada de diretório, então: 如果B+树有4层,最多能存放1000×1000×1000×100=100000000000registros. Portanto, em circunstâncias normais, a árvore B+ que usamos não excederá 4 camadas, então só precisamos fazer uma pesquisa em 4 páginas no máximo para encontrar um registro através do valor da chave primária (encontre 3 páginas de itens de diretório e uma página de registro de usuário) , e por haver um chamado Page Directory (diretório de página) em cada página, também é possível localizar registros rapidamente na página por meio da dicotomia. É por isso que os índices podem acelerar as consultas.
3. Índice Agrupado
A árvore B+ que introduzimos acima é um diretório ou um índice. Tem duas características:
-
Use o tamanho do valor da chave primária do registro para classificar registros e páginas, o que inclui três significados:
- Os registros na página são organizados em uma lista encadeada unidirecional na ordem do tamanho da chave primária
- Cada página que armazena os registros do usuário também é organizada em uma lista duplamente vinculada de acordo com a ordem do tamanho da chave primária dos registros do usuário na página
- As páginas que armazenam os registros de entrada do diretório são divididas em níveis diferentes e as páginas no mesmo nível também são organizadas em uma lista duplamente encadeada de acordo com a ordem do tamanho da chave primária dos registros de entrada do diretório na página.
-
Os nós folha da árvore B+ armazenam registros completos do usuário
O chamado registro de usuário completo significa que os valores de todas as colunas (incluindo colunas ocultas) são armazenados neste registro
Chamamos a árvore B+ com essas duas características de índice agrupado, e todos os registros completos do usuário são armazenados nos nós folha desse índice agrupado. Este índice clusterizado não exige que usemos explicitamente a instrução de índice na instrução MySQL para criar, o mecanismo de armazenamento InnoDB criará automaticamente um índice clusterizado para nós. Outro ponto interessante é que no mecanismo de armazenamento InnoDB, o índice clusterizado é o método de armazenamento de dados (todos os registros do usuário são armazenados nos nós folha), ou seja, o chamado índice são os dados e os dados são o índice.
Em quarto lugar, o índice secundário (Índice Secundário)
O índice clusterizado só pode funcionar quando a condição de pesquisa é o valor da chave primária, porque os dados na árvore B+ são classificados de acordo com a chave primária. E se quisermos usar outras colunas como critérios de pesquisa? Só é possível percorrer os registros sequencialmente ao longo da lista encadeada do começo ao fim?
Não, podemos construir várias outras árvores B+, e os dados em diferentes árvores B+ adotam regras de classificação diferentes. Por exemplo, usamos o tamanho da coluna c2 como regra de classificação da página de dados e dos registros na página e, em seguida, construímos uma árvore B+, o efeito é mostrado na figura a seguir:
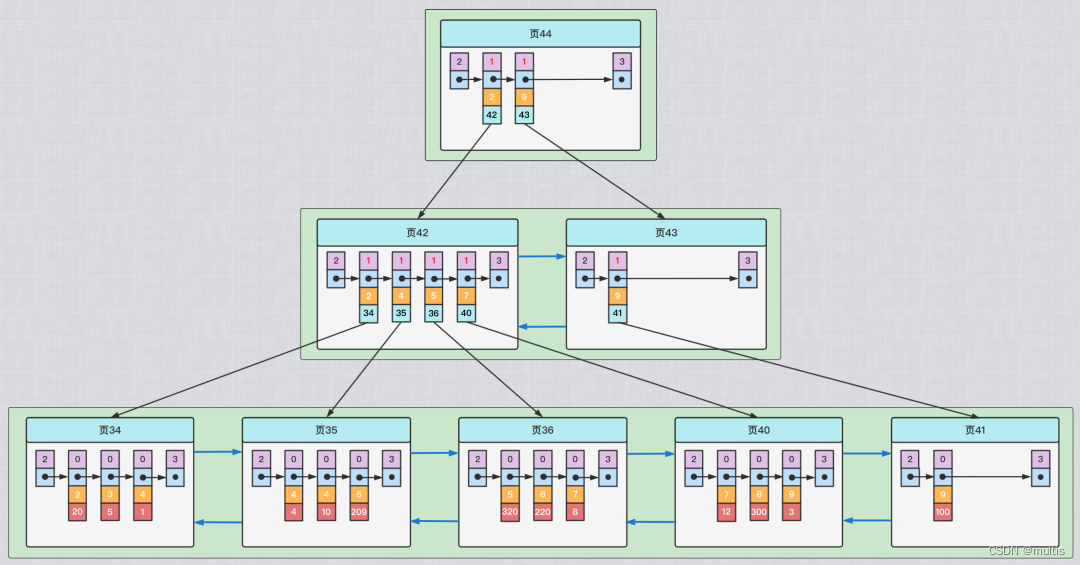
Essa árvore B+ tem várias diferenças em relação ao índice agrupado apresentado acima:
-
Use o tamanho da coluna do registro c2 para classificar registros e páginas, o que inclui três significados:
- Os registros na página são organizados em uma lista encadeada unidirecional na ordem do tamanho da coluna c2
- Cada página que armazena os registros do usuário também é organizada em uma lista duplamente encadeada de acordo com o tamanho da coluna c2 registrada na página
- As páginas que armazenam os registros de entrada do diretório são divididas em diferentes níveis, e as páginas no mesmo nível também são organizadas em uma lista duplamente encadeada de acordo com a ordem do tamanho da coluna c2 dos registros de entrada do diretório na página.
-
Os nós folha da árvore B+ não armazenam registros completos do usuário, mas apenas os valores das duas colunas c2 + chave primária.
-
O registro do item do diretório não é mais a combinação de chave primária + número da página, mas a combinação da coluna c2 + número da página.
Portanto, se agora quisermos encontrar alguns registros por meio do valor da coluna c2, podemos usar a árvore B+ que acabamos de construir. Tomemos como exemplo a busca pelo registro cujo valor é 4 na coluna c2, o processo de busca é o seguinte:
Portanto, se agora quisermos encontrar alguns registros por meio do valor da coluna c2, podemos usar a árvore B+ que acabamos de construir. Tomemos como exemplo a busca pelo registro cujo valor é 4 na coluna c2, o processo de busca é o seguinte:
-
Determine a página de registro de entrada de diretório
De acordo com a página raiz, ou seja, a página 44, você pode localizar rapidamente a página onde o registro de entrada de diretório está localizado na página 42 (porque 2<4<9) -
De acordo com a página raiz, ou seja, a página 33, pode-se localizar rapidamente que a página onde está localizado o registro de entrada do diretório é a página 30.
-
Use a página de registro de entrada de diretório para determinar a página onde o registro do usuário realmente reside.
Na página 42, a página que realmente armazena os registros do usuário pode ser localizada rapidamente, mas como não há restrição única na coluna c2, os registros cujo valor é 4 na coluna c2 podem ser distribuídos em várias páginas de dados e porque 2< 4≤4, portanto, verifique se as páginas que realmente armazenam os registros do usuário estão nas páginas 34 e 35 -
Localize um registro específico na página que realmente armazena os registros do usuário.
Vá para a página 34 e página 35 para localizar o registro específico -
No entanto, os registros nos nós folha dessa árvore B+ armazenam apenas duas colunas, c2 e c1 (ou seja, a chave primária), portanto, devemos procurar o registro completo do usuário novamente no índice clusterizado de acordo com o valor da chave primária.
Podemos determinar apenas o valor da chave primária do registro que estamos procurando com base na árvore B+ classificada pelo tamanho da coluna c2; portanto, se quisermos encontrar o registro de usuário completo com base no valor da coluna c2, ainda precisa verificá-lo novamente no índice clusterizado, esse processo também é chamado 回表. Ou seja, consultar um registro de usuário completo com base no valor da coluna c2 precisa usar 2 árvores B+!
Dica:
Se você colocar os registros completos do usuário nos nós folha, não precisa retornar a tabela, mas ocupa muito espaço~ É equivalente a copiar todos os registros do usuário toda vez que você constrói uma árvore B+, que é um pouco demais Desperdício de espaço de armazenamento. Como esse tipo de árvore B+ construída de acordo com a coluna de chave não primária precisa de uma operação de retorno de tabela para localizar o registro completo do usuário, esse tipo de árvore B+ também é chamado de índice secundário (nome em inglês Secondary Index) ou índice auxiliar. Como usamos o tamanho da coluna c2 como regra de classificação da árvore B+, também chamamos essa árvore B+ de índice construído para a coluna c2.
5. Índice conjunto (índice composto)
Também podemos usar o tamanho de várias colunas como regra de classificação ao mesmo tempo, ou seja, criar índices para várias colunas ao mesmo tempo. Por exemplo, queremos que a árvore B+ seja classificada de acordo com o tamanho de c2 e colunas c3. Isso contém dois significados:
- Primeiro classifique cada registro e página de acordo com a coluna c2.
- Quando a coluna c2 dos registros é a mesma, a coluna c3 é usada para ordenação.
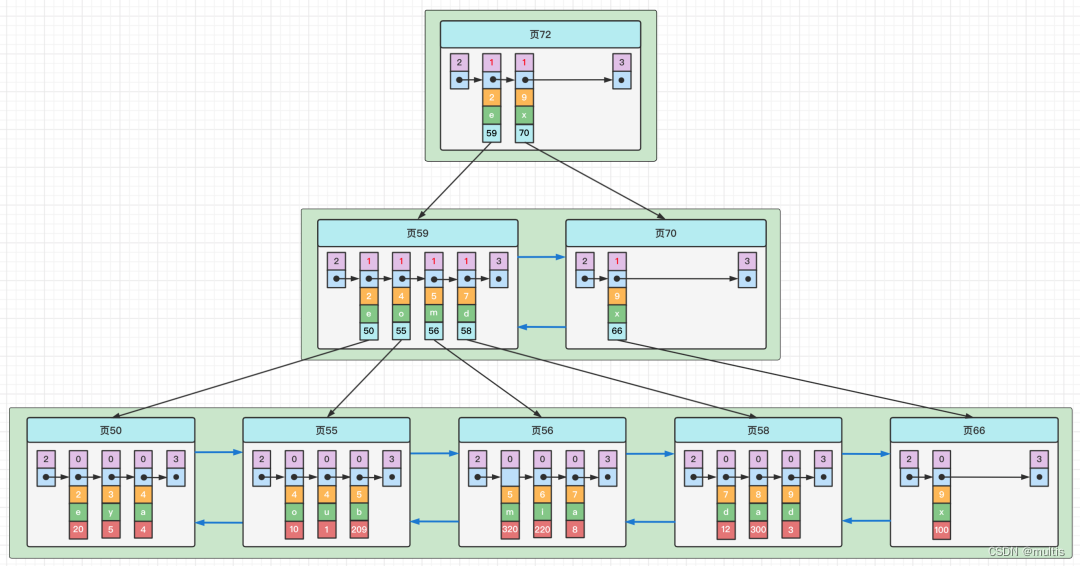
Como mostrado na figura, precisamos prestar atenção aos seguintes pontos:
-
Cada registro de entrada de diretório consiste em três partes: c2, c3 e número da página. Cada registro é primeiro classificado de acordo com o valor da coluna c2. Se os registros da coluna c2 forem iguais, eles serão classificados de acordo com o valor da coluna c3 .
-
O registro do usuário no nó folha da árvore B+ consiste nas colunas c2, c3 e na chave primária c1.
Deve-se notar que a árvore B+ construída com o tamanho das colunas c2 e c3 como regra de classificação é chamada de índice conjunto, que é essencialmente um índice secundário. Seu significado é diferente da expressão de índices de construção para as colunas c2 e c3 respectivamente. As diferenças são as seguintes:
- A construção de um índice conjunto criará apenas uma árvore B+, conforme mostrado na figura acima.
- A criação de índices para as colunas c2 e c3, respectivamente, criará duas árvores B+ com o tamanho das colunas c2 e c3 como regras de classificação
6. Precauções para o índice de árvore B+ do InnoDB
6.1 A página raiz nunca se move
Quando introduzimos o índice da árvore B+ anteriormente, para conveniência de todos, primeiro desenhe os nós folha que armazenam os registros do usuário e, em seguida, desenhe os nós internos que armazenam os registros do item do diretório. Na verdade, o processo de formação da árvore B+ é como segue:
-
Sempre que um índice de árvore B+ é criado para uma tabela (o índice clusterizado não é criado artificialmente, ele existe por padrão), uma página de nó raiz será criada para este índice. Quando não há dados na tabela no início, não há registro de usuário nem registro de item de diretório no nó raiz correspondente a cada índice de árvore B+.
-
Ao inserir registros do usuário na tabela posteriormente, armazene os registros do usuário neste nó raiz primeiro.
-
Quando o espaço livre no nó raiz for usado, continue a inserir registros. Neste momento, todos os registros no nó raiz serão copiados para uma página recém-alocada, como a página a, e então a nova página será dividida em obtenha outra A nova página, digamos página b. Neste momento, os novos registros inseridos serão alocados para a página a ou página b de acordo com o tamanho do valor da chave (ou seja, o valor da chave primária no índice clusterizado, o valor da coluna do índice correspondente no índice secundário) , e o nó raiz será Páginas promovidas para armazenar registros de entrada de catálogo.
Este processo exige que todos prestem atenção especial: o nó raiz de um índice de árvore B+ não se moverá desde o seu nascimento. Desta forma, desde que criemos um índice para uma tabela, o número da página de seu nó raiz será gravado em algum lugar e, a partir daí, sempre que o mecanismo de armazenamento InnoDB precisar usar esse índice, ele retirará o nó raiz daquele fixo lugar para acessar o índice.
Dica:
A informação em que página o nó raiz de um determinado índice está armazenado é um item de informação no dicionário de dados lendário. Mais detalhes sobre o conteúdo do dicionário de dados serão explicados em detalhes posteriormente
6.2 Exclusividade dos registros de entrada de diretório em nós internos
Sabemos que o conteúdo do registro de entrada do diretório no nó interno do índice da árvore B+ é a combinação da coluna do índice + número da página, mas essa combinação é um pouco imprecisa para o índice secundário. Pegue também demo6a tabela como exemplo, supondo que os dados dessa tabela sejam assim:
| c1 | c2 | c3 |
|---|---|---|
| 1 | 1 | 'você' |
| 3 | 1 | 'd' |
| 5 | 1 | 'y' |
| 7 | 1 | 'a' |
Se o conteúdo do registro de entrada de diretório no índice secundário for apenas a combinação da coluna do índice + número da página, a árvore B+ após a coluna de indexação c2 deve ter esta aparência:
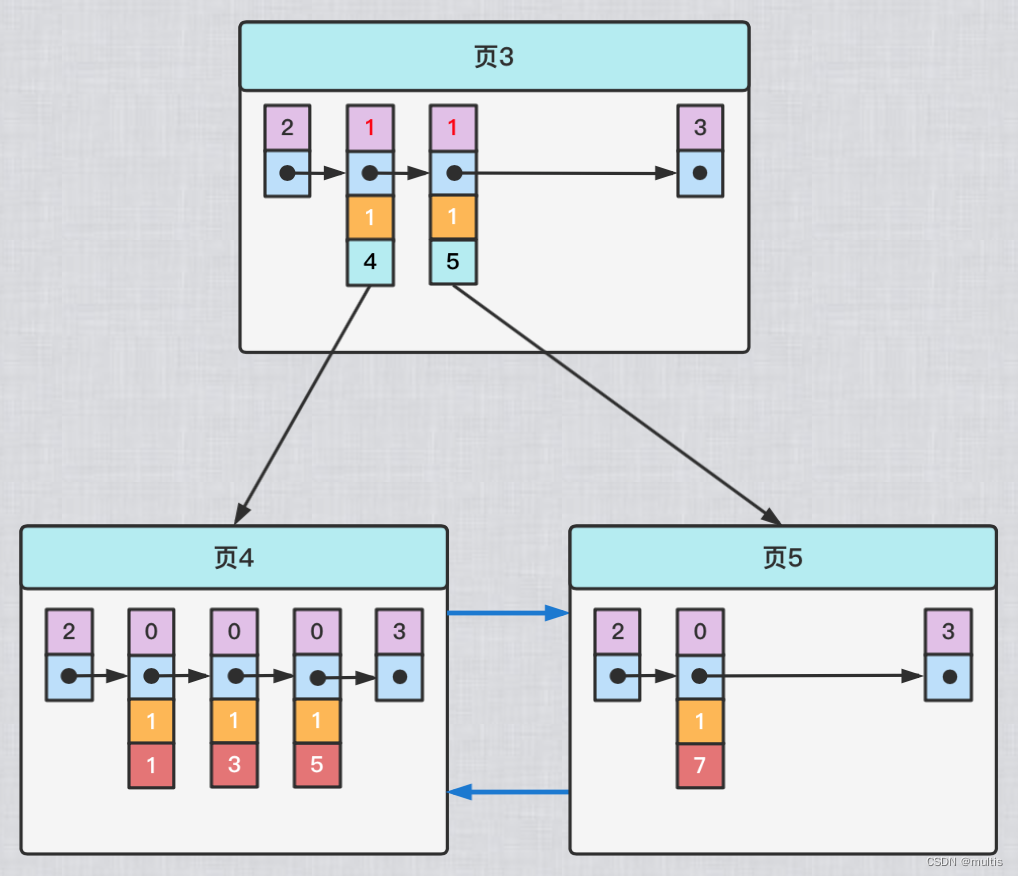
Se quisermos inserir uma nova linha de registros, onde os valores de c1, c2 e c3 são: 9, 1 e 'c' respectivamente, então encontramos um grande problema ao modificar a árvore B+ correspondente ao secundário índice estabelecido para a coluna c2 : Como o registro de entrada de diretório armazenado na página 3 é composto pelo valor da coluna c2 + número da página, os valores da coluna c2 correspondentes aos dois registros de entrada de diretório na página 3 são ambos 1 e o registro recém-inserido O valor da coluna c2 também é 1, então nosso registro recém-inserido deve ser colocado na página 4 ou na página 5? A resposta é: desculpe, confuso.
Para que o registro recém-inserido se encontre nessa página, precisamos garantir que o registro de entrada de diretório do nó no mesmo nível da árvore B+ seja único, exceto pelo campo de número de página. Portanto, o conteúdo registrado na entrada do diretório do nó interno do índice secundário é, na verdade, composto de três partes:
- o valor da coluna indexada
- valor da chave primária
- número de página
Ou seja, também adicionamos o valor da chave primária ao registro de entrada de diretório no nó do índice secundário, para que possamos garantir que cada registro de entrada de diretório em cada camada do nó da árvore B+ seja exclusivo, exceto para o campo de número de página, então nós O diagrama esquemático depois de estabelecer o índice secundário para a coluna c2 deve ficar assim:
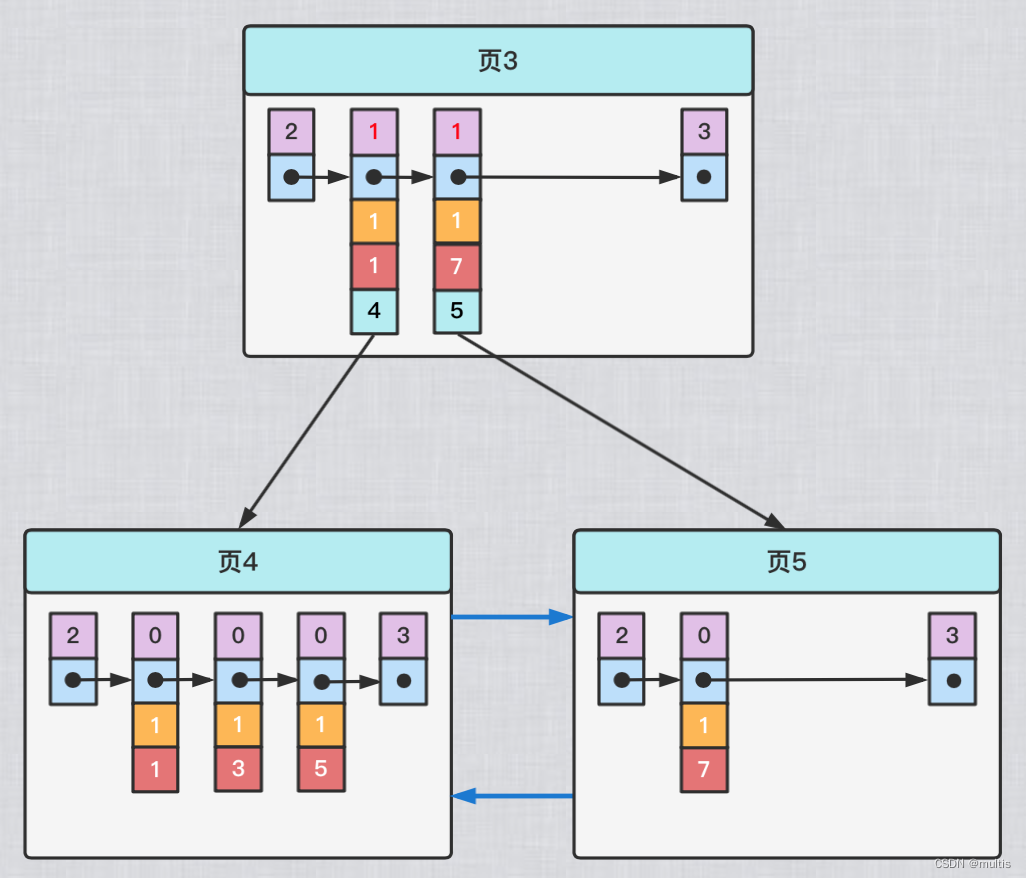
Desta forma, ao inserirmos o registro (9, 1, 'c'), como o registro de entrada de diretório armazenado na página 3 é composto pelo valor da coluna c2 + chave primária + número da página, podemos primeiro combinar o valor de coluna c2 do novo registro com Compare os valores da coluna c2 de cada entrada de diretório na página 3. Se os valores da coluna c2 forem iguais, você poderá comparar os valores da chave primária, porque os valores de coluna c2 + chave primária de diferentes entradas de diretório na mesma camada da árvore B+ devem ser diferentes. O mesmo, então o único registro de entrada de diretório pode ser localizado no final, neste caso, é finalmente determinado que o novo registro deve ser inserido na página 5.
6.3 Uma página armazena pelo menos 2 registros
Dissemos anteriormente que uma árvore B+ pode armazenar facilmente centenas de milhões de registros com apenas alguns níveis, e a velocidade da consulta é rápida! Isso ocorre porque a árvore B+ é essencialmente um grande diretório multinível e muitos subdiretórios inválidos são filtrados toda vez que um diretório é passado, até que o diretório que armazena os dados reais seja finalmente acessado. Então, qual é o efeito se apenas um subdiretório for armazenado em um diretório grande? Ou seja, existem muitos, muitos níveis de diretório e apenas um registro pode ser armazenado no último diretório que armazena dados reais. Demorou muito para armazenar apenas um registro de usuário real? Você está brincando comigo? Portanto, uma página de dados do InnoDB pode armazenar pelo menos dois registros.Essa também é uma conclusão que dissemos quando introduzimos o formato de linha de registro.
Sete, uma breve introdução ao esquema de índice no MyISAM
Agora vamos apresentar brevemente o esquema de indexação no mecanismo de armazenamento MyISAM. Sabemos que o índice no InnoDB são os dados, ou seja, todos os registros completos do usuário foram incluídos nos nós folha da árvore B+ do índice clusterizado, enquanto o esquema de índice MyISAM também usa uma estrutura de árvore, mas o índice e Os dados são armazenados separadamente:
-
Os registros da tabela são armazenados separadamente em um arquivo de acordo com a ordem de inserção dos registros, que é chamado de arquivo de dados (arquivo .MYD no disco). Este arquivo não é dividido em várias páginas de dados, pois muitos registros são inseridos neste arquivo. Podemos acessar rapidamente um registro pelo número da linha.
Os registros MyISAM também precisam de informações de cabeçalho de registro para armazenar alguns dados adicionais. Vamos pegar a tabela mencionada acima
demo6como exemplo e ver como os registros nesta tabela usam o MyISAM como mecanismo de armazenamento no espaço de armazenamento: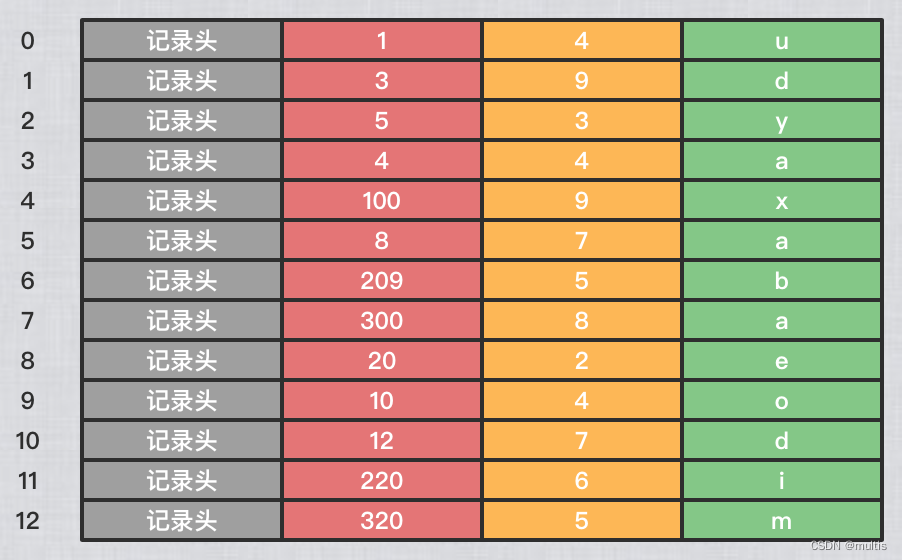
Como os dados não são deliberadamente classificados de acordo com o tamanho da chave primária ao inserir dados, não podemos usar o método de dicotomia para pesquisar esses dados. -
As tabelas que usam o mecanismo de armazenamento MyISAM também armazenam informações de índice em outro arquivo chamado arquivo de índice (arquivo .MYI no disco). O MyISAM criará um índice para a chave primária da tabela separadamente, mas o que é armazenado no nó folha do índice não é um registro de usuário completo, mas uma combinação de valor da chave primária + número da linha. Ou seja, primeiro encontre o número da linha correspondente por meio do índice e, em seguida, encontre o registro correspondente por meio do número da linha!
Isso é completamente diferente do InnoDB. No mecanismo de armazenamento InnoDB, precisamos apenas pesquisar o índice clusterizado com base no valor da chave primária para encontrar o registro correspondente, mas no MyISAM, precisamos executar uma operação de tabela de retorno, o que significa Os índices estabelecidos no MyISAM são equivalentes a todos os índices secundários!
-
Se necessário, também podemos criar índices separados ou índices conjuntos para outras colunas. O princípio é semelhante ao índice no InnoDB, mas a coluna correspondente + o número da linha são armazenados no nó folha. Esses índices também são todos índices secundários.
Dica:
os formatos de linha MyISAM incluem formato de registro de comprimento fixo (Static), formato de registro de comprimento variável (Dynamic) e formato de registro compactado (Compressed). A tabela utilizada acimademo6adota o formato de registro de comprimento fixo, ou seja, o tamanho do espaço de armazenamento ocupado por um registro é fixo, de modo que o deslocamento de endereço de um determinado registro no arquivo de dados pode ser facilmente calculado. Mas o formato de registro de comprimento variável não funciona.MyISAM irá armazenar diretamente o deslocamento de endereço do registro no arquivo de dados no nó folha do índice. Pode-se ver a partir disso que a operação de retorno da tabela do MyISAM é muito rápida, pois ele busca dados diretamente do arquivo com o deslocamento do endereço. Em contraste, o InnoDB procura registros no índice clusterizado após obter a chave primária. Embora não seja lento para digamos, mas ainda não é tão bom quanto usar diretamente o endereço para acessar. Espero que você entenda que o índice no InnoDB são os dados e os dados são o índice, mas no MyISAM, o índice é o índice e os dados são os dados
8. Instruções para criar e excluir índices no MySQL
Patrocinando para aprender o princípio da indexação, como usamos as instruções do MySQL para construir esse tipo de índice? InnoDB e MyISAM tomarão a iniciativa de criar um índice de árvore B+ para a chave primária ou a coluna declarada como UNIQUE, mas se quisermos criar um índice para outras colunas, precisamos especificá-lo explicitamente. Por que não criar automaticamente um índice para cada coluna? Não se esqueça, toda vez que um índice é criado, uma árvore B+ é construída, e toda vez que um registro é inserido, a relação de ordenação de cada registro e página de dados deve ser mantida, o que consome muito desempenho e espaço de armazenamento.
Podemos especificar uma única coluna a ser indexada ou várias colunas a serem indexadas ao criar uma tabela:
create talbe 表名 (
各种列的信息 ··· ,
[key|index] 索引名 (需要被索引的单个列或多个列)
)
Dica:
chave e índice são sinônimos, você pode escolher qualquer um
Também podemos adicionar índices ao modificar a estrutura da tabela:
alter table 表名 add [index|key] 索引名 (需要被索引的单个列或多个列);
Você também pode excluir o índice ao modificar a estrutura da tabela:
alter table 表名 drop [index|key] 索引名;
Por exemplo, se quisermos adicionar um índice conjunto às colunas c2 e c3 ao criar a tabela index_demo, podemos escrever a instrução de criação da tabela da seguinte forma:
create table demo7(
c1 int,
c2 int,
c3 char(1),
primary key(c1),
index idx_c2_c3(c2,c3)
);
O nome do índice que criamos nesta instrução de criação de tabela é idx_c2_c3, que pode ser nomeado à vontade, mas ainda recomendamos prefixá-lo com idx_, seguido pelos nomes das colunas que precisam ser indexadas e vários nomes de colunas são separados por _sublinhados abrir.
Se quisermos excluir esse índice, podemos escrever assim:
alter table demo7 drop index idx_c2_c3;
Se quisermos consultar o índice
show index from 表名;
Nove. Resumo
Há muito conteúdo hoje, vamos resumir brevemente:
-
Cada índice corresponde a uma árvore B+. A árvore B+ é dividida em várias camadas, a camada inferior é o nó folha e o restante são nós internos. Todos os registros de usuário são armazenados nos nós folha da árvore B+ e todos os registros de entrada de diretório são armazenados nos nós internos.
-
O mecanismo de armazenamento InnoDB criará automaticamente um índice clusterizado para a chave primária (caso contrário, ele será adicionado automaticamente para nós) e os nós folha do índice clusterizado contêm registros de usuário completos.
-
Podemos criar um índice secundário para as colunas que nos interessam. Os registros de usuário contidos nos nós folha do índice secundário são compostos por colunas de índice + chaves primárias, portanto, se quisermos encontrar registros de usuário completos por meio do índice secundário, devemos precisa voltar para a tabela. , ou seja, após o valor da chave primária ser encontrado por meio do índice secundário, o registro completo do usuário é pesquisado no índice clusterizado.
-
Cada camada de nós na árvore B+ é classificada de acordo com a ordem dos valores da coluna de índice de pequeno a grande para formar uma lista duplamente encadeada, e os registros em cada página (sejam registros de usuário ou registros de entrada de diretório) são classificados de acordo com os valores da coluna de índice de pequeno a grande A ordem grande forma uma lista vinculada individualmente. Se for um índice conjunto, as páginas e registros são primeiro classificados de acordo com a coluna na frente do índice conjunto e, se os valores da coluna forem iguais, eles são classificados de acordo com a coluna atrás do índice conjunto.
-
A pesquisa de registros por meio do índice começa no nó raiz da árvore B+ e pesquisa camada por camada. Como cada página estabelece o Page Directory (diretório da página) de acordo com o valor da coluna do índice, a busca nessas páginas é muito rápida.
-
O MyISAM criará um índice para a chave primária da tabela separadamente, mas o que é armazenado no nó folha do índice não é um registro de usuário completo, mas uma combinação de valor da chave primária + número da linha. No mecanismo de armazenamento InnoDB, precisamos apenas pesquisar o índice clusterizado uma vez de acordo com o valor da chave primária para encontrar o registro correspondente, mas no MyISAM, precisamos realizar uma operação de tabela de retorno, o que significa que os índices estabelecidos no MyISAM são equivalentes para todos é um índice secundário.
-
Precauções para o índice de árvore B+ do InnoDB:
-
A página raiz nunca é aninhada;
-
O registro de entrada de diretório no nó interno é exclusivo;
-
Uma página armazena pelo menos 2 registros.
-
-
O índice no InnoDB são os dados e os dados são o índice, enquanto no MyISAM o índice é o índice e os dados são os dados.
Hoje aprendemos sobre o índice de árvore B+ do InnoDB, conhecemos sua estrutura e princípio de funcionamento, o artigo de hoje é muito importante
Até agora, o estudo de hoje acabou, espero que você se torne um eu indestrutível
~~~
Você não pode ligar os pontos olhando para frente; você só pode conectá-los olhando para trás. Portanto, você precisa confiar que os pontos de alguma forma se conectarão em seu futuro. Você precisa confiar em algo - seu instinto, destino, vida, karma, seja o que for. Essa abordagem nunca me decepcionou e fez toda a diferença na minha vida
Se meu conteúdo for útil para você, por favor 点赞, criar não é fácil, o apoio de todos é a 评论motivação 收藏para eu perseverar
