Índice
- 1. A necessidade de reversão da transação
- 2. ID da transação
- 3. Formato do registro de desfazer
- 4. Estrutura Geral da Lista Ligada
- Cinco, página FIL_PAGE_UNDO_LOG
- Seis, Desfazer lista vinculada de página
- 7. O processo de gravação específico do registro de desfazer
- 8. Reutilize a página Desfazer
- Nove, segmento de reversão
-
- 9.1 O conceito de segmento de rollback
- 9.2 Solicitar a lista vinculada da página Desfazer do segmento de reversão
- 9.3 Múltiplos segmentos de reversão
- 9.4 Classificação dos Segmentos de Rollback
- 9.5 Processo detalhado de alocação da lista vinculada da página Undo para transação
- 9.6 Configuração relacionada ao segmento de rollback
1. A necessidade de reversão da transação
Quando aprendemos sobre casos anteriormente, dissemos que os negócios precisam ser garantidos 原子性, isto é 事务中的操作要么全做,要么全不做. Mas às vezes haverá algumas situações na transação, como:
情况一:Vários erros podem ser encontrados durante a execução da transação, como erros no próprio servidor, erros do sistema operacional ou até mesmo erros causados por falhas repentinas de energia- Caso 2: Os programadores podem inserir instruções manualmente durante a execução da transação
ROLLBACKpara encerrar a execução da transação atual
As duas situações acima farão com que a transação termine no meio da execução, mas muitas coisas podem ter sido modificadas durante o processo de execução da transação. Para garantir a transação, precisamos 原子性mudar as coisas de volta ao estado original. Esse processo é chamado 回滚(Nome em inglês : rollback), isso pode criar uma falsa impressão: essa transação parece não fazer nada, portanto atende aos requisitos de atomicidade.
É como jogar cartas com nossos amigos quando éramos jovens. A carta de arrependimento é uma operação de rollback muito típica, por exemplo, se você jogar duas cartas de três, a operação correspondente à carta de arrependimento é retirar as duas cartas de três. A reversão no banco de dados é semelhante ao cartão de arrependimento. Você insere um registro e a operação de reversão corresponde a excluir esse registro; você atualiza um registro e a operação de reversão corresponde a atualizar o registro para o valor antigo; você Se um registro for excluído, a operação de rollback corresponde a inserir o registro novamente. Parece tão simples
Pela descrição acima, já podemos sentir vagamente que sempre que quisermos fazer alterações em um registro (as alterações aqui podem se referir a INSERT, DELETE, UPDATE), precisamos anotar à mão tudo o que for necessário para a reversão. Por exemplo:
- Quando você insere um registro, você deve anotar pelo menos o valor da chave primária deste registro. Ao reverter posteriormente, você só precisa excluir o registro correspondente ao valor da chave primária.
- Você exclui um registro, pelo menos anote o conteúdo desse registro, para que, ao reverter mais tarde, você possa inserir os registros compostos por esses conteúdos na tabela
- Se você modificar um registro, deverá registrar pelo menos o valor antigo antes de modificar este registro, para que possa atualizar este registro para o valor antigo quando reverter mais tarde
Essas coisas gravadas pelo banco de dados para reversão são chamadas de logs de desfazer, e o nome em inglês undo logé chamado de undo日志. Uma coisa a observar aqui é que, como a operação de consulta (SELECT) não modifica nenhum registro do usuário, não é necessário registrar o log correspondente quando a operação de consulta é executada undo. Na realidade InnoDB, undoo log não é tão simples como dissemos acima, e o formato do log gerado por diferentes tipos de operações undotambém é diferente, mas vamos colocar esses detalhes que são fáceis de confundir por um tempo. Vamos voltar e ver qual é o id da transação
2. ID da transação
2.1 Quando atribuir um id a uma transação
Como dissemos anteriormente quando aprendemos sobre a introdução às transações, uma transação pode ser one 只读事务, ou one 读写事务:
- Podemos
START TRANSACTION READ ONLYabrir uma por meio de uma instrução.Em只读事务uma transação somente leitura, não podemos adicionar, excluir ou modificar tabelas comuns (tabelas que também podem ser acessadas por outras transações), mas podemos adicionar, excluir e modificar tabelas temporárias. - Podemos
START TRANSACTION READ WRITEiniciar uma transação por meio de uma instrução读写事务ou usar uma instrução para abrir uma transação por padrão.Na transação de leitura e gravação, podemos realizar operações de adição, exclusão, modificação e consulta na tabelaBEGIN.START TRANSACTION读写事务
增Se as operações , 删, e forem executadas em uma tabela durante a execução de uma transação 改, InnoDBo mecanismo de armazenamento atribuirá a ela um único 事务id, conforme a seguir:
-
Para
只读事务a transação, somente quando ela executar operações de adição, exclusão e modificação em uma tabela temporária criada por um usuário pela primeira vez, ela atribuirá um id de transação a essa transação, caso contrário, não atribuirá um id de transação小提示:
Como dissemos anteriormente,EXPLAINao executar e analisar um plano de consulta para uma determinada instrução de consulta, às vezes você verá um prompt usando temporário na coluna Extra, que indica que uma tabela temporária interna será usada ao executar a instrução de consulta.CREATE TEMPORARY TABLEEsta chamada tabela temporária interna não é igual à tabela temporária do usuário que criamos manualmente. Quando a transação é revertida, não é necessário reverter a tabela temporária interna usada na execução da instrução SELECT . -
Por
读写事务exemplo, um ID de transação será atribuído a uma transação somente quando ela executar operações de adição, exclusão ou modificação em uma tabela (incluindo tabelas temporárias criadas por usuários) pela primeira vez, caso contrário, não atribuirá um ID de transação
Às vezes, embora tenhamos ativado um 读写事务, a transação está cheia de instruções de consulta e nenhuma instrução de adição, exclusão ou modificação é executada, o que significa que esta transação não receberá um ID de transação
Depois de muito conversar, para que serve o ID da transação? Isso será mantido em segredo por enquanto, e falarei sobre isso em detalhes passo a passo mais tarde. Agora, saiba que uma transação receberá um ID de transação exclusivo apenas quando a transação fizer alterações nos registros da tabela.
2.2 Como o id da transação é gerado
Isso 事务idé essencialmente um número, e sua estratégia de alocação é row_idaproximadamente a mesma que a estratégia de alocação para colunas ocultas (colunas que o InnoDB cria automaticamente quando o usuário não cria uma chave primária e uma chave UNIQUE para a tabela) que mencionamos anteriormente. é o seguinte:
- O servidor manterá uma variável global na memória. Sempre que uma transação precisar ser alocada
事务id, o valor da variável será atribuído à transação como o ID da transação e a variável será incrementada em 1 - Sempre que o valor desta variável
256for um múltiplo de , o valor desta variável será atualizado para umMax Trx IDatributo chamado na página número 5 do espaço de tabela do sistema. O占用8个字节espaço de armazenamento deste atributo - Da próxima vez que o sistema reiniciar, ele carregará
Max Trx IDos atributos mencionados acima na memória, adicionará 256 ao valor e atribuirá à variável global que mencionamos anteriormente (porque o valor da
variável ser maior queMax Trx IDo valor do atributo)
Isso garante que o valor do ID da transação atribuído em todo o sistema seja um número crescente. A transação que recebe um id primeiro obtém um id de transação menor, e a transação que recebe um id posteriormente obtém um id de transação maior.
2.3 coluna oculta trx_id
Quando aprendemos InnoDBo formato da linha de registro, enfatizamos que além de salvar os dados completos do usuário, os registros do índice clusterizado adicionarão automaticamente uma coluna oculta chamada , trx_idse roll_pointero usuário for um usuário 没有在表中定义主键以及UNIQUE键, uma row_idcoluna oculta chamada List. Portanto, a estrutura real de um registro em uma página se parece com isso:

As colunas nele trx_idsão realmente muito fáceis de entender e são exatamente onde está localizada uma instrução que faz alterações no registro de índice clusterizado 事务对应的事务id(as alterações aqui podem ser INSERT, DELETEou UPDATEoperações). Quanto roll_pointeràs colunas ocultas, vamos analisá-las mais tarde~
3. Formato do registro de desfazer
Para perceber a atomicidade da transação, o mecanismo de armazenamento precisa primeiro anotar o log correspondente InnoDBao executar 增, 删ou um registro. Geralmente, sempre que é feita uma alteração a um registo, corresponde a um log, mas em algumas operações de atualização de registos pode também corresponder a 2 logs, dos quais falaremos mais adiante. Durante a execução de uma transação, pode haver vários registros, ou seja, muitos logs correspondentes precisam ser gravados, e esses logs serão numerados desde o início, ou seja, são chamados de nº 0 desfazer log, nº 1 log de desfazer de acordo com a ordem de geração. nº 1 log de undo, ..., nº n log de undo, etc., este número também é chamado de .改undoundoundo新增删除更新undoundo0undo no
Esses logs de desfazer são registrados em páginas do tipo FIL_PAGE_UNDO_LOG(o número hexadecimal correspondente é 0x0002, os alunos que esqueceram qual é o tipo de página precisam voltar e consultar os capítulos anteriores). Essas páginas podem ser alocadas a partir do espaço de tabela do sistema ou de um espaço de tabela dedicado ao armazenamento de logs de desfazer, que é a chamada undo tablespacealocação interna. No entanto, falaremos sobre como alocar undopáginas para armazenar logs mais tarde. Agora vamos dar uma olhada em que tipo de undologs serão gerados por diferentes operações~ Para o bom desenvolvimento da história, vamos primeiro criar uma demo18tabela chamada:
mysql> CREATE TABLE demo18 (
id INT NOT NULL,
key1 VARCHAR(100),
col VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1)
)Engine=InnoDB CHARSET=utf8;
Query OK, 0 rows affected, 1 warning (0.06 sec)
Existem 3 colunas nesta tabela, entre as quais ida coluna é a chave primária, key1criamos uma para a coluna 二级索引, e a coluna col é uma coluna comum. Como mencionamos no dicionário de dados que apresentamos anteriormente InnoDB, a cada tabela será atribuído um único table id. Podemos verificar a que determinada tabela corresponde através das tabelas information_schemano banco de dados do sistema . Agora vamos verificar a quanto ela corresponde :innodb_tablestable iddemo18table id
mysql> SELECT * FROM information_schema.innodb_tables WHERE name = 'testdb/demo18';
+----------+---------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+---------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1128 | testdb/demo18 | 33 | 6 | 66 | Dynamic | 0 | Single | 0 | 0 |
+----------+---------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.00 sec)
Como pode ser visto nos resultados da consulta, demo18a tabela corresponde table ida 1128, primeiro lembre-se desse valor, vamos usá-lo mais tarde
3.1 O log de desfazer correspondente à operação INSERT
Como dissemos antes, quando inserimos um registro na tabela, haverá uma distinção entre 乐观插入e 悲观插入, mas não importa como você o insira, o resultado final é que esse registro é colocado em uma página de dados. Se você deseja reverter a operação de inserção, basta excluir este registro, ou seja, ao gravar o undolog correspondente, registre principalmente as informações da chave primária deste registro. Para tanto, InnoDBé projetado um log TRX_UNDO_INSERT_RECdo tipo undo, cuja estrutura completa é apresentada na figura a seguir:
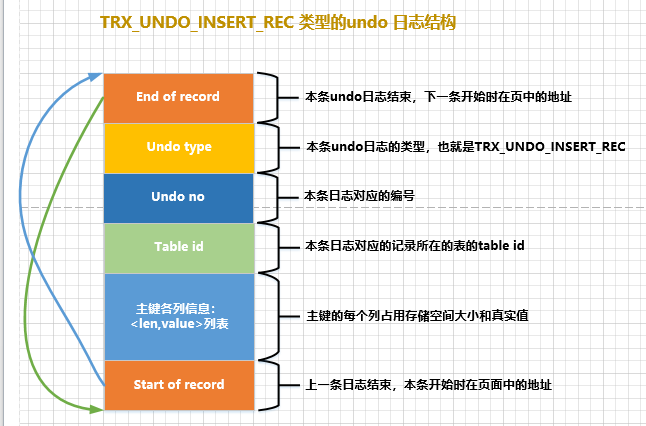
De acordo com o diagrama, destacamos alguns pontos:
-
undo noSim em uma transação从0开始递增, ou seja, enquanto a transação não for confirmada, toda vez que um log de desfazer for gerado, o número de desfazer do log aumentará em 1. -
Se a chave primária do registro contiver apenas uma coluna, basta registrar a soma ocupada pela coluna no tipo
TRX_UNDO_INSERT_RECde log, e se a chave primária do registro contiver , então todas as ocupadas precisam ser registradas (no figura representa a coluna ocupada O tamanho do espaço de armazenamento representa o valor real da coluna).undo存储空间大小真实值多个列每个列存储空间大小和对应的真实值lenvalue小提示:
Quando inserimos um registro em uma tabela, na verdade precisamos inserir um registro no índice clusterizado e em todos os índices secundários. No entanto, ao gravar logs de desfazer, precisamos apenas considerar a situação ao inserir registros no índice clusterizado, porque, na verdade, os registros do índice clusterizado e os registros do índice secundário estão em correspondência um-para-um. operação, precisamos apenas conhecer as informações da chave primária deste registro
e, em seguida, executar a operação de exclusão correspondente de acordo com as informações da chave primária. Quando a operação de exclusão for executada, os registros correspondentes em todos os índices secundários também serão excluídos. Os logs de desfazer correspondentes às operações DELETE e UPDATE mencionadas posteriormente também são para os registros de índice clusterizado, e não vamos enfatizá-los posteriormente.
Agora inserimos dois registros em demo18:
mysql> BEGIN; # 显式开启一个事务,假设该事务的id为100
Query OK, 0 rows affected (0.00 sec)
mysql> # 插入两条记录
mysql> INSERT INTO demo18(id, key1, col) VALUES (1, 'AWM', '狙击枪'), (2, 'M416', '步枪');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
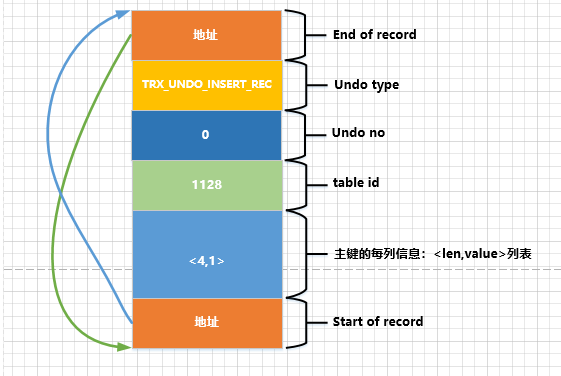
Como a chave primária do registro contém apenas uma coluna, precisamos registrar apenas o comprimento ( ) e o espaço de armazenamento ocupado pela coluna a ser inserida no registro idno log correspondente . Neste exemplo, dois registros são inseridos, então serão gerados dois logs do tipo :undoidid列的类型为INT,INT类型占用的存储空间长度为4个字节真实值TRX_UNDO_INSERT_RECundo
- O primeiro
undologundo noé0, o comprimento do espaço de armazenamento ocupado pela chave primária do registro é4, e o valor real é1. Desenhe um esquema como este:
- No segundo
undolog , o comprimento do espaço de armazenamento ocupado pela chave primária do registro é , e o valor real é . Desenhe um esquema como este:undo no142
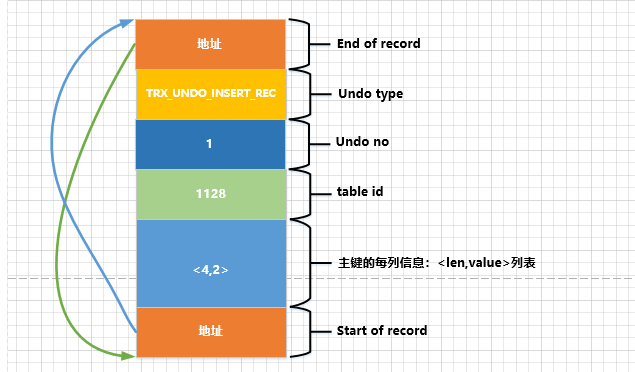
Em comparação com o primeiro artigo undo日志, undo nohá 主键各列信息uma diferença.
O significado da coluna oculta roll_pointer
É hora de revelar roll_pointero verdadeiro véu. Este 7campo que ocupa 3 bytes na verdade não é nada misterioso. É essencialmente um ponteiro para o registro correspondente undo日志的一个指针. demo18Por exemplo, inserimos um registro na tabela acima 2, e cada registro tem um correspondente undo日志. Os registros são armazenados em FIL_PAGE_INDEXpáginas do tipo (ou seja, as páginas de dados das quais falamos antes) e undoos logs são armazenados em FIL_PAGE_UNDO_LOGpáginas do tipo . O efeito é mostrado na figura:
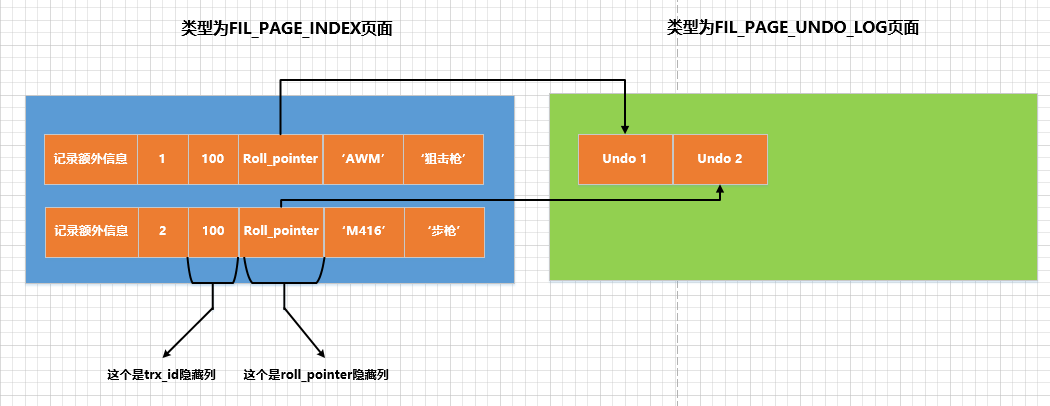
Também pode ser visto de forma mais intuitiva pela figura que roll_pointera essência é um ponteiro para o log correspondente ao registro undo. roll_pointerNo entanto, o significado específico de cada byte desses 7 bytes undoserá explicado em detalhes depois que falarmos sobre como alocar páginas para armazenar logs~
3.2 Desfazer log correspondente à operação DELETE
Sabemos que os registros inseridos na página formarão next_recorduma lista vinculada unidirecional de acordo com os atributos nas informações do cabeçalho do registro. Chamamos essa lista vinculada de lista vinculada de registro normal; como dissemos antes quando falamos sobre a estrutura da página de dados , registros excluídos Na verdade, uma lista vinculada também será formada de acordo com os atributos nas informações do cabeçalho do registro next_record, mas nesta lista vinculada 记录占用的存储空间可以被重新利用, portanto, essa lista vinculada também é chamada 垃圾链表. PageHeaderA seção possui um PAGE_FREEatributo chamado , que aponta para o nó principal na lista de lixo que consiste em registros excluídos. Para o bom desenvolvimento da história, vamos primeiro fazer um desenho, assumindo que a distribuição dos registros em uma determinada página no momento é assim (não é um demo18registro da tabela, mas apenas um exemplo que citamos aleatoriamente):
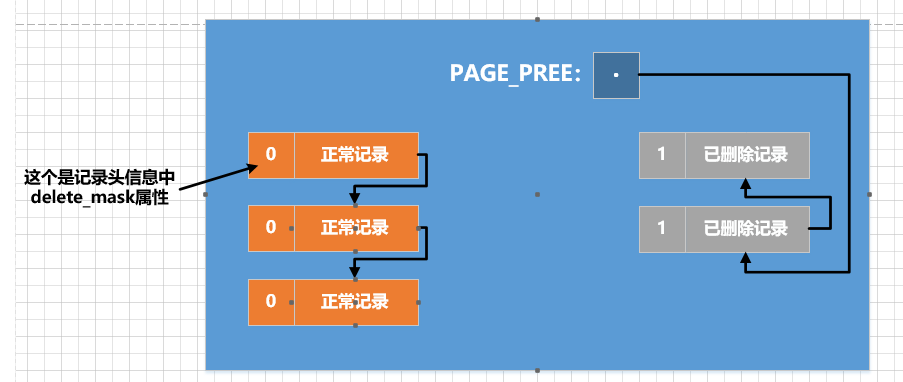
Para destacar o tema, nesta versão simplificada do diagrama esquemático, mostramos apenas delete_maskas bandeiras dos registros. Pode-se ver na figura que 正常记录链表中包含了3条正常记录, a lista encadeada de lixo contém 2条已删除记录, e o espaço de armazenamento ocupado por esses registros na lista encadeada de lixo pode ser reutilizado. Page HeaderO valor da propriedade da parte da página PAGE_FREErepresenta um ponteiro para o nó principal da lista de lixo. Supondo que vamos usar DELETEo comando 正常记录链表para deletar o último registro em , na verdade, o processo de deleção precisa passar por duas etapas:
-
Fase 1: Defina apenas
delete_masko bit de identificação do registro para1, e não modifique os demais (na verdade, os valores dessas colunas ocultas do registro serão modificadostrx_id)roll_pointer. O InnoDB chama esse estágiodelete marde k. É assim que o processo é desenhado: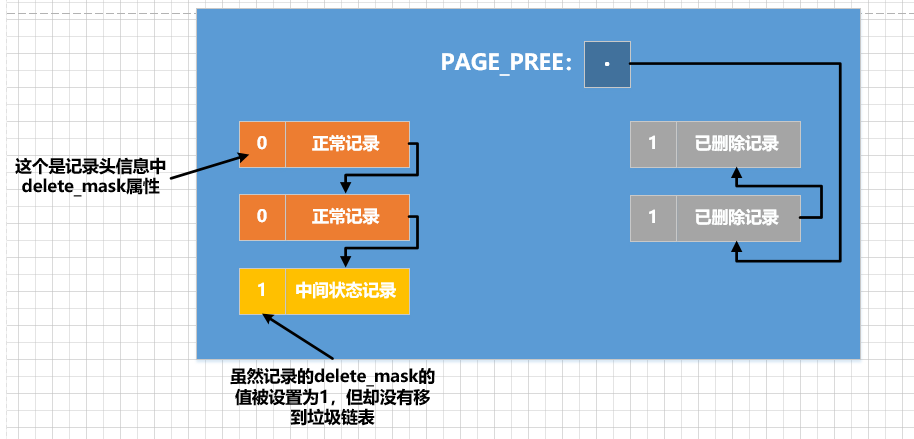 Pode-se ver que o último registro na lista encadeada de registros normal
Pode-se ver que o último registro na lista encadeada de registros normal delete_mask值被设置为1não foi adicionado垃圾链表. Ou seja, o registro está em um estado neste momento中间状态, e o registro excluído esteve nesse chamado estado até que a transação na qual a instrução de exclusão foi confirmada seja confirmada中间状态.小提示:
Por que existe um estado intermediário tão estranho? Na verdade, é principalmente para realizar uma função chamada MVCC, haha, vou apresentá-la mais tarde. -
Fase 2:
当该删除语句所在的事务提交之后, haverá专门的线程uma exclusão real do registro posteriormente. A chamada exclusão real consiste em remover o registro正常记录链表dele e adicioná垃圾链表-lo a ele e, em seguida, ajustar algumas outras informações da página, como o número de registros do usuário na páginaPAGE_N_RECS, a posição do último registro inseridoPAGE_LAST_INSERT, o ponteiro do nó principal da lista de lixoPAGE_FREE, o número de bytes que podem ser reutilizados na páginaPAGE_GARBAGEe algumas informações sobre o diretório da página, etc. O InnoDB chama essa fasepurge.Após
阶段二a conclusão da execução, o registro é realmente excluído. O espaço de armazenamento ocupado por este registro excluído também pode ser reutilizado. É assim que está desenhado: comparando com a figura, também devemos prestar atenção a um ponto: ao adicionar o registro excluído à lista de lixo, na verdade, ele modificará o valor do atributo
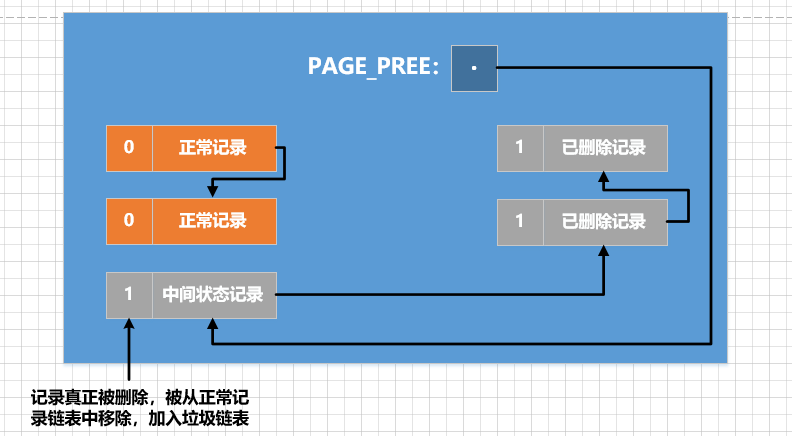
quando ele for adicionado .链表的头节点处PAGE_FREE小提示:
A parte do cabeçalho da página possui um atributo PAGE_GARBAGE, que registra o número total de bytes ocupados pelo espaço de armazenamento reutilizável na página atual. Sempre que um registro excluído for adicionado à lista de lixo, o valor do atributo PAGE_GARBAGE será adicionado ao espaço de armazenamento ocupado pelo registro excluído. PAGE_FREE aponta para o nó principal da lista de lixo e, sempre que um novo registro for inserido, primeiro julgue se o espaço de armazenamento ocupado pelo registro excluído representado pelo nó principal apontado por PAGE_FREE é suficiente para acomodar o registro recém-inserido, se não, solicite diretamente um novo espaço na página para armazenar este registro (sim, você leu certo, ele não tentará percorrer toda a lista de lixo para encontrar um nó que possa acomodar o novo registro). Se puder ser acomodado, reutilize diretamente o espaço de armazenamento desse registro excluído e aponte PAGE_FREE para o próximo registro excluído na lista de lixo. Mas há um problema aqui, se o espaço de armazenamento ocupado pelo registro recém inserido for menor que o espaço de armazenamento ocupado pelo nó de cabeça da lista de lixo, isso significa que parte do espaço de armazenamento ocupado pelo registro correspondente ao nó de cabeça não é usado. Esta parte do espaço é chamada de espaço de detritos. Esses espaços fragmentados não seriam usados para sempre? Na verdade, não é. O tamanho do espaço de armazenamento ocupado por esses espaços fragmentados será contabilizado no atributo PAGE_GARBAGE. Esses espaços fragmentados não serão reutilizados até que toda a página esteja quase esgotada. No entanto, quando a página estiver quase cheia , se você inserir outro registro, neste momento, o espaço para um registro completo não pode ser alocado na página. Neste momento, primeiro verificaremos se o espaço combinado de PAGE_GARBAGE e o espaço restante disponível podem acomodar este registro. Se possível , o InnoDB vai tentar reorganizar O processo de reorganização dos registros na página é abrir primeiro uma página temporária, inserir os registros na página um a um, pois nenhum fragmento será gerado ao inserir em sequência, e depois copiar o conteúdo da a página temporária para esta página, para que você possa liberar esses espaços fragmentados (obviamente, reorganizar os registros na página consome mais desempenho).
Pela descrição acima, também podemos ver que antes da transação onde a instrução delete é confirmada, ela passará apenas pela fase um, ou seja, delete markfase (não precisamos fazer rollback após o commit, então só precisamos considerar fazendo a fase um da operação de exclusão afetada pela reversão). InnoDBPara tanto, é projetado um TRX_UNDO_DEL_MARK_RECtipo de toro undo, cuja estrutura completa é apresentada na figura a seguir:
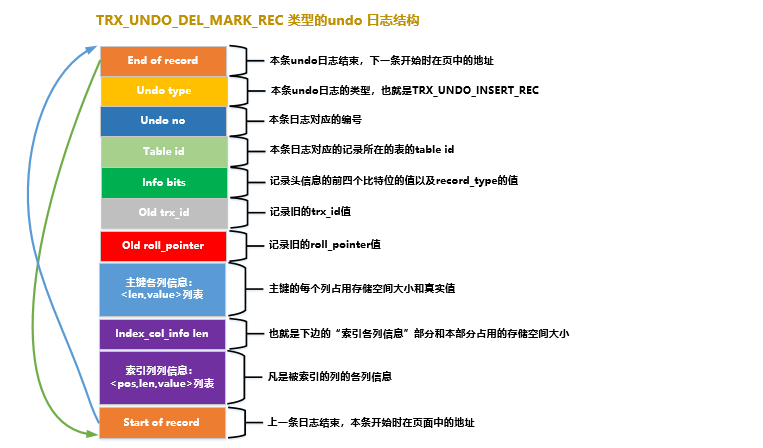 Meu deus, há muitos atributos nisso ~ (Na verdade, o significado da maioria dos atributos foi apresentado acima) Sim, existem muitos, mas por favor, não preste atenção, se você não consegue se lembrar de Don não se force, estou listando todos eles aqui para que todos se familiarizem. Eu gostaria de incomodar a todos para superar o transtorno de pânico intenso primeiro e, em seguida, procurar os atributos no registro desse tipo acima, prestando atenção especial a estes pontos
Meu deus, há muitos atributos nisso ~ (Na verdade, o significado da maioria dos atributos foi apresentado acima) Sim, existem muitos, mas por favor, não preste atenção, se você não consegue se lembrar de Don não se force, estou listando todos eles aqui para que todos se familiarizem. Eu gostaria de incomodar a todos para superar o transtorno de pânico intenso primeiro e, em seguida, procurar os atributos no registro desse tipo acima, prestando atenção especial a estes pontos TRX_UNDO_DEL_MARK_REC:undo
-
Antes de operar em um registro
delete mark, os valores antigostrx_ideroll_pointerocultos da coluna do registro precisam ser registrados no log correspondente , que é o atributo sumundomostrado em nossa figura . Isso tem a vantagem de que o log correspondente ao registro antes da modificação pode ser encontrado através do log . Por exemplo, em uma transação, primeiro inserimos um registro e, em seguida, executamos uma operação de exclusão no registro. O diagrama esquemático desse processo é o seguinte:oldtrx_idold roll_pointerundoold roll_pointerundo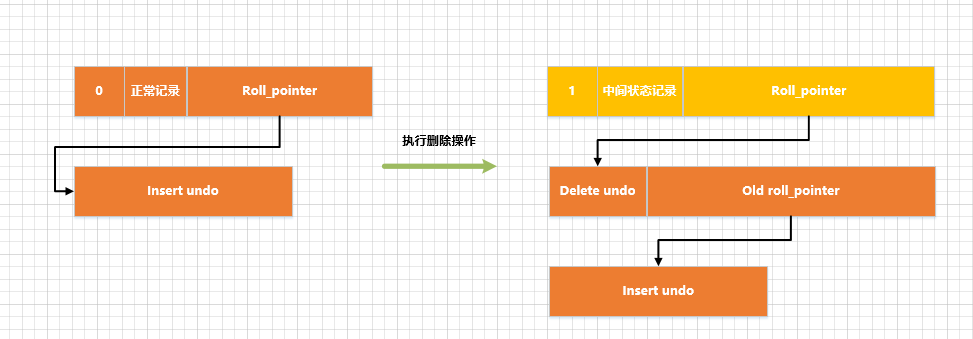
-
Pode-se ver na figura que
delete markapós a execução da operação, seuundolog correspondente e o logINSERTcorrespondenteundoda operação formam uma lista encadeada. Isso é muito interessante. Essa lista vinculada é chamada版本链. Agora parece que não podemos ver o uso dessa cadeia de versões. Vamos dar uma olhada mais tarde. Depois de falar sobre o logUPDATEcorrespondenteundoda operação, essa chamada cadeia de versões será ser exibido lentamente.Fora de seu lugar de força. -
Diferentemente do log do tipo
TRX_UNDO_INSERT_REC,undoo log do tipoTRX_UNDO_DEL_MARK_RECpossuiundoum索引列各列信息conteúdo a mais, ou seja, se uma coluna está incluída em um índice, suas informações relacionadas devem ser registradas nesta索引列各列信息parte, as chamadas informações relacionadas Incluindo a posição de a coluna no registro (indicadopospor ), o espaço de armazenamento ocupado pela coluna (indicadolenpor ) e o valor real da coluna (indicado porvalue). Portanto,索引列各列信息o conteúdo armazenado é essencialmente<pos, len, value>uma lista de arquivos . Esta parte da informação é usada principalmente no中间状态记录segundo estágio da exclusão real após a confirmação da transação, ou seja, épurgeusada no estágio. Como usá-la pode ser ignorada agora~
Concluímos a introdução, agora continuamos a excluir um registro na transação acima idpara a transação, por exemplo, excluímos o registro para :100id1
mysql> DELETE FROM demo18 WHERE id = 1;
Query OK, 1 row affected (0.01 sec)
delete markA estrutura do log correspondente a esta operação undoé a seguinte:
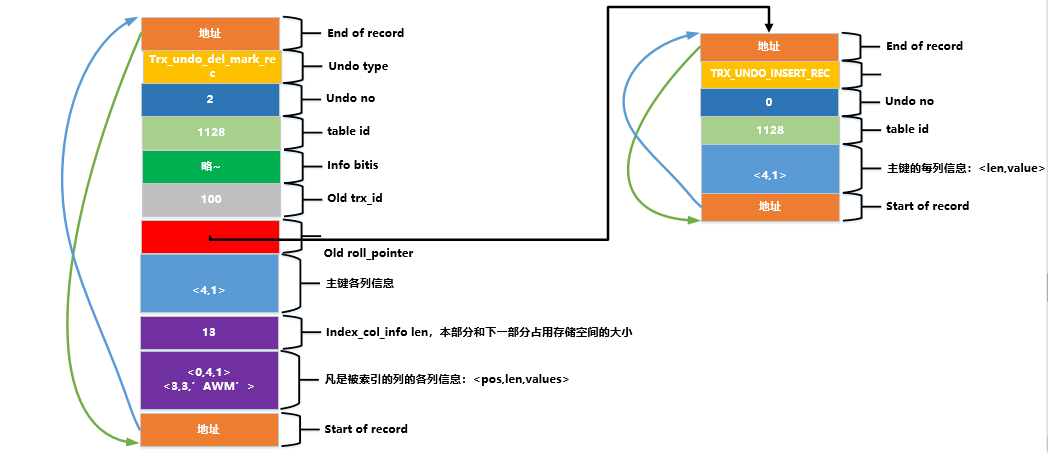 de acordo com esta figura, devemos prestar atenção aos seguintes pontos:
de acordo com esta figura, devemos prestar atenção aos seguintes pontos:
-
Porque esse log de desfazer é gerado na transação com id 100
第3条undo日志,所以它对应的undo no就是2. -
Ao operar no registro
delete mark,trx_ido valor da coluna oculta do registro é100(ou seja, a última modificação do registro ocorreu nesta transação), então preencha100oold trx_idatributo. Em seguida, retireroll_pointero valor da coluna oculta do registro e preencha-oold roll_pointerno atributo, para que o logold roll_pointergerado na última alteração do registro possa ser encontrado através do atributo value .undo -
Como existem 2 índices na tabela demo18:
一个是聚簇索引, um é二级索引idx_key1.posDesde que seja uma coluna incluída no índice, a posição ( ), o espaço de armazenamento ocupado (len) e o valor real ( ) desta coluna no registrovalueprecisam ser armazenados no log de desfazer.-
Para a chave primária, há apenas uma
idcoluna e as informações relevantes armazenadas no log de desfazer são:-
pos:idA coluna é a chave primária, ou seja, ela é gravada第一个列, e seu valor pos correspondente é 0. pos leva 1 byte para armazenar. -
len: O tipo da coluna id é INT, ocupando 4 bytes, então o valor de len é 4. len ocupa 1 byte para armazenar. -
value: O valor da coluna id no registro excluído é 1, ou seja, o valor do valor é 1. O valor leva 4 bytes para ser armazenado. -
Faça um desenho para demonstrá-lo assim:
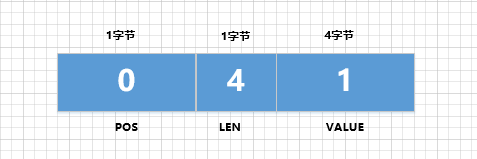
-
Portanto, para
ida coluna, o resultado final do armazenamento é <0, 4, 1> e o espaço de armazenamento ocupado pelo armazenamento dessas informações é1 + 1 + 4 = 6个字节.
-
-
Para
idx_key1, há apenas umakey1coluna eundoas informações relevantes armazenadas no log são:-
pos: A coluna key1 é organizada após a coluna id, coluna trx_id e coluna roll_pointer e seu valor pos correspondente3. pos leva 1 byte para armazenar. -
len: O tipo da coluna key1 é VARCHAR(100), e o conjunto de caracteres utf8 é usado. O conteúdo de armazenamento real do registro excluído é AWM, então ocupa um total de 3 bytes, ou seja, o valor de len é 3 . len ocupa 1 byte para armazenar. -
value: O valor da coluna key1 no registro excluído é AWM, ou seja, o valor do valor é AWM. O valor leva 3 bytes para ser armazenado. -
Faça um desenho para demonstrá-lo assim:
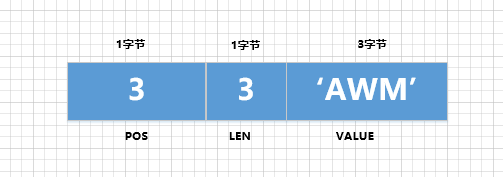
-
Portanto, para
key1a coluna, o resultado final do armazenamento é <3, 3, 'AWM'> e o espaço de armazenamento ocupado pelo armazenamento dessas informações é1 + 1 + 3 = 5bytes.
-
Como pode ser visto na descrição acima,
<0, 4, 1>e<3, 3, 'AWM'>ocupam11um total de bytes. Entãoindex_col_info lenocupa2um byte, então ocupa um total de13bytes, e o número 13 é preenchidoindex_col_info lenno atributo. -
3.3 Desfazer log correspondente à operação UPDATE
Ao executar UPDATEuma instrução, o InnoDB lida com 更新主键esses 不更新主键dois casos de maneira completamente diferente.
3.3.1 O caso em que a chave primária não é atualizada
No caso de não atualizar a chave primária, pode ser subdividido no caso em que o espaço de armazenamento ocupado pela coluna atualizada não muda ou muda.
Atualização no local (atualização no local)
Ao atualizar um registro, para cada coluna a ser atualizada, se o espaço de armazenamento ocupado pela coluna atualizada e a coluna anterior à atualização forem os mesmos, então uma atualização in-loco pode ser realizada, ou seja, a coluna correspondente pode ser diretamente modificado com base no registro original. O valor da coluna. Novamente, o espaço de armazenamento ocupado por cada coluna é o mesmo antes e depois da atualização. Qualquer coluna atualizada ocupa um espaço de armazenamento maior do que após a atualização, ou o espaço de armazenamento ocupado antes da atualização é menor do que após a atualização. Atualizar em lugar. Por exemplo, existe um registro com valor de id 2 na tabela demo18, e o tamanho de suas colunas é mostrado na figura (porque é usado o conjunto de caracteres utf8, os dois caracteres 'rifle' ocupam 6 bytes):
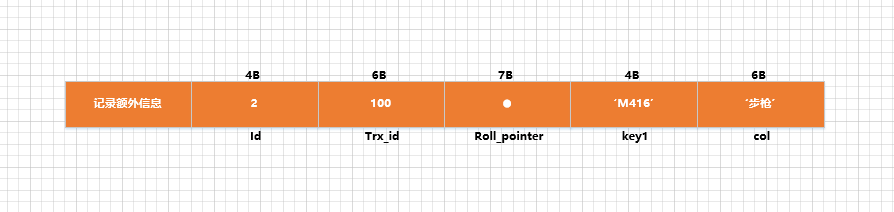
Suponha que temos uma declaração como esta UPDATE:
UPDATE demo18 SET key1 = 'P92', col = '手枪' WHERE id = 2;
Nesta instrução UPDATE, a coluna col é atualizada de um rifle para uma pistola, ocupando 6 bytes antes e depois, ou seja, o espaço de armazenamento ocupado não foi alterado; a coluna key1 é atualizada de M416 para P92, ou seja, é alterado de 4
bytes A atualização é de 3 bytes, o que não atende às condições exigidas para atualização no local, portanto, a atualização no local não pode ser executada. Mas se a instrução UPDATE for assim:
UPDATE demo18 SET key1 = 'M249', col = '机枪' WHERE id = 2;
Como o espaço de armazenamento ocupado por cada coluna atualizada é o mesmo antes e depois da atualização, tal instrução pode realizar uma atualização in-loco.
Exclua os registros antigos primeiro e depois insira os novos
No caso de não atualizar a chave primária, se o espaço de armazenamento ocupado por qualquer uma das colunas atualizadas for inconsistente antes e depois da atualização, você precisará excluir este registro antigo da página de índice clusterizado primeiro e, em seguida, de acordo com o valor da coluna atualizada cria um novo registro e o insere na página.
Observe que a exclusão de que estamos falando aqui não é delete markuma operação, mas uma exclusão real, ou seja, remova este registro da lista de registros normal e adicione-o à lista de lixo e modifique as informações estatísticas correspondentes na página ( Para exemplo PAGE_FREE, PAGE_GARBAGEaguarde essas informações). No entanto, o thread que faz a operação de exclusão real aqui não é outro thread especial usado ao fazer a operação na instrução nagging, mas a operação de exclusão real é executada de forma síncrona pelo thread do usuário. Após a exclusão real, ele deve ser atualizado de acordo com cada DELETEcolunapurge
Aqui, se o espaço de armazenamento ocupado pelo registro recém-criado não exceder o espaço ocupado pelo registro antigo, você poderá reutilizar diretamente o espaço de armazenamento ocupado pelo registro antigo adicionado à lista de lixo, caso contrário, será necessário solicitar um novo Seção de espaço na página para O novo registro é usado, se não houver espaço disponível nesta página, a operação de divisão de página é necessária e, em seguida, um novo registro é inserido.
Para a situação em que UPDATE não atualiza a chave primária (incluindo a atualização no local mencionada acima e primeiro exclua o registro antigo e insira o novo registro), o InnoDB projetou um tipo de log de desfazer, sua estrutura completa é a seguinte TRX_UNDO_UPD_EXIST_REC:
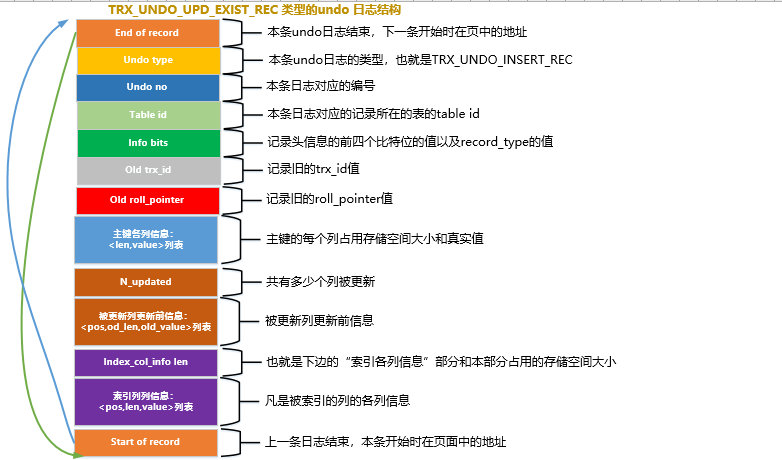
TRX_UNDO_DEL_MARK_RECNa verdade, a maioria das propriedades são semelhantes aos tipos de logs de desfazer que introduzimos , mas ainda precisamos prestar atenção aos seguintes pontos:
n_updatedO atributo indica que várias colunas serão atualizadas após a execução desta instrução UPDATE, e as seguintes<pos, old_len, old_value>indicam respectivamente a posição da coluna atualizada no registro, o espaço de armazenamento ocupado pela coluna antes da atualização e o valor real do coluna antes da atualização.- Se
UPDATEa coluna atualizada na instrução incluir uma coluna de índice, as informações da coluna da coluna de índice também serão adicionadas, caso contrário, esta parte não será adicionada.
Agora continue atualizando um registro na transação acima idpara a transação, por exemplo, vamos atualizar o registro para :100id2
BEGIN; # 显式开启一个事务,假设该事务的id为100
# 插入两条记录
INSERT INTO demo18(id, key1, col) VALUES (1, 'AWM', '狙击枪'), (2, 'M416', '步枪');
# 删除一条记录
DELETE FROM demo18 WHERE id = 1;
# 更新一条记录
UPDATE demo18 SET key1 = 'M249', col = '机枪' WHERE id = 2;
UPDATEO tamanho da coluna atualizada por esta instrução não foi alterado, portanto 采用就地更新, pode ser executado da seguinte maneira: Ao alterar o registro da página, um TRX_UNDO_UPD_EXIST_REClog de desfazer do tipo será registrado primeiro, que se parece com isso:
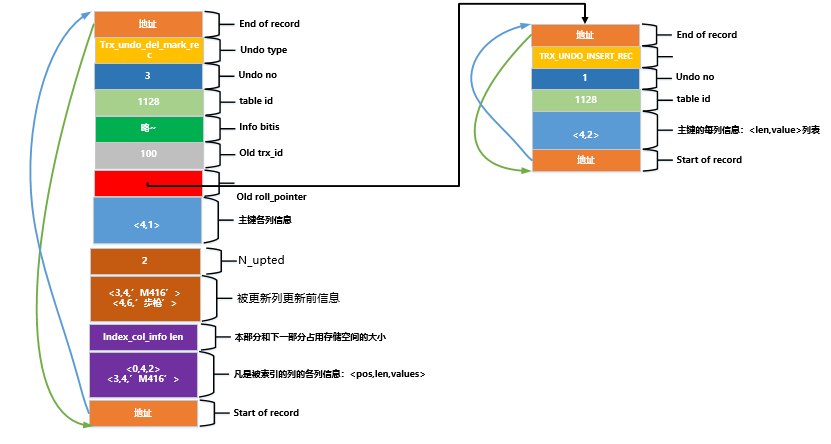
Com esta foto, vamos prestar atenção a esses lugares, como:
- Como esse
undolog é o primeiro log gerado na transaçãoid, ele corresponde a .1004undoundo no3 - O log
roll_pointerque apontaundo nopara 1 deste log é2o log gerado quando o registro com o valor da chave primária é inseridoundo, ou seja, o log gerado quando o registro foi alterado pela última vezundo. - Como o valor
UPDATEda coluna do índice é atualizado nesta declaraçãokey1, é necessário registrar as informações de cada coluna da coluna do índice, ou seja, preencherkey1as informações da chave primária e da coluna antes da atualização.
3.3.2 O caso de atualização da chave primária
No índice clusterizado, os registros são conectados em uma lista vinculada unidirecional de acordo com o tamanho do valor da chave primária. Se atualizarmos o valor da chave primária de um registro, isso significa que a posição desse registro no índice clusterizado será alterar. Alterar, por exemplo, se você for gravar 主键值从1更新为10000, se houver muitos registros cujos valores de chave primária estão distribuídos entre 1 e 10000, então esses dois registros podem estar muito distantes no índice clusterizado, ou mesmo separados em no meio Tantas páginas. No UPDATEcaso em que o valor da chave primária do registro é atualizado na instrução, InnoDBo índice clusterizado é processado em duas etapas:
-
Excluir operação de marcação em registros antigos
高能注意:Aqui está a operação de marca de exclusão! Ou seja,UPDATEantes que a transação da instrução seja confirmada, apenas umadelete markoperação é executada no registro antigo e, após a confirmação da transação, um thread especial executapurgea operação e a adiciona à lista de lixo. Isso deve ser diferenciado do que dissemos acima, quando o valor da chave primária do registro não é atualizado, o registro antigo é realmente excluído primeiro e, em seguida, o novo registro é inserido!小提示:
A razão pela qual a operação de marcação de exclusão é realizada apenas no registro antigo é que outras transações também podem acessar esse registro ao mesmo tempo.Se ele for realmente excluído e adicionado à lista de lixo, outras transações não poderão acessá-lo. Essa função é chamada de MVCC, e falaremos sobre o que é um MVCC em detalhes nos capítulos seguintes. -
Crie um novo registro com base nos valores atualizados de cada coluna e insira-o no índice clusterizado (necessário reposicionar a posição inserida).
Como o valor da chave primária do registro atualizado foi alterado, é necessário realocar o local desse registro do índice clusterizado e, em seguida, inseri-lo.
Para UPDATEo caso onde o comando atualiza o valor da chave primária do registro, antes de operar sobre o registro delete mark, será registrado um log do tipo undo TRX_UNDO_DEL_MARK_REC; quando um novo registro for inserido posteriormente, será registrado um log do tipo TRX_UNDO_INSERT_REC, undoou seja, um registro para cada par Quando o valor da chave primária é alterado, dois logs de desfazer serão gravados. Já falamos sobre o formato desses logs acima, então não vou entrar em detalhes.
4. Estrutura Geral da Lista Ligada
Múltiplas listas encadeadas serão usadas no 写入undo日志processo, e muitas listas encadeadas têm a mesma estrutura de nós, conforme mostrado na figura:
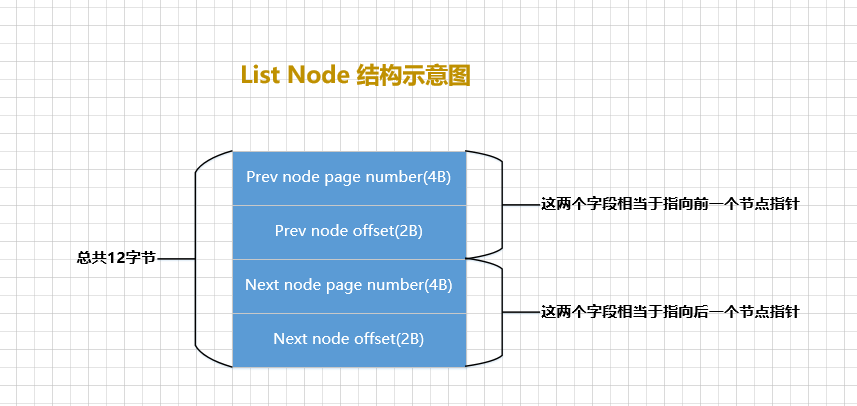
Em um determinado espaço de tabela, podemos localizar de forma única a posição de um nó através do número da página e do deslocamento dentro da página.Essas duas informações são equivalentes a um ponteiro apontando para esse nó. então:
Pre Node Page NumberA combinação de ePre Node Offseté um ponteiro para o nó anteriorNext Node Page NumberA combinação de eNext Node Offseté um ponteiro para o próximo nó.
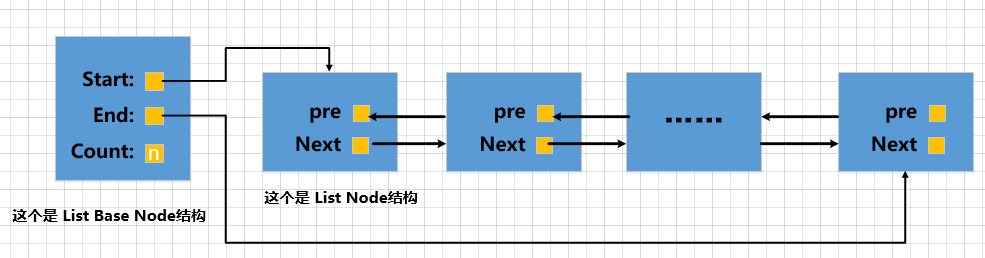
O todo List Nodeocupa 12 bytes de espaço de armazenamento. Para melhor gerenciar a lista encadeada, o InnoDB propõe um 基节点的结构, que armazena este 链表的头节点, 尾节点e 链表长度信息o diagrama de estrutura do nó base é o seguinte:
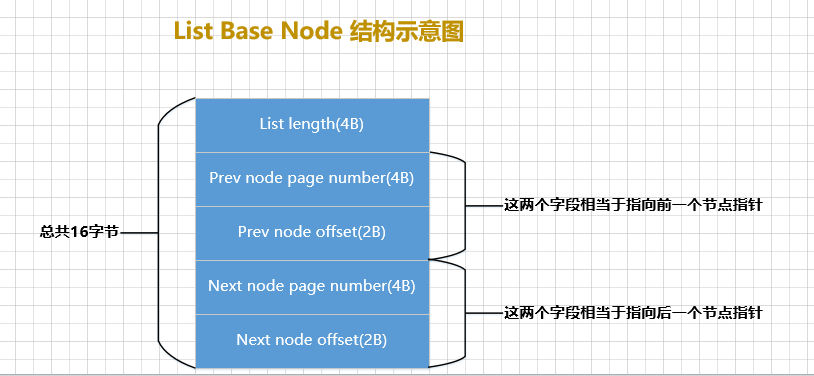
em:
List LengthIndica quantos nós existem na lista encadeada.First Node Page Number和First Node OffsetA combinação é um ponteiro para o nó principal da lista encadeada.Last Node Page Number和Last Node OffsetA combinação é um ponteiro para o nó final da lista encadeada.
O todo List Base Nodeocupa 16bytes de espaço de armazenamento. Portanto, o diagrama esquemático de uso List Base Nodeda List Nodelista encadeada composta por essas duas estruturas é assim:
Cinco, página FIL_PAGE_UNDO_LOG
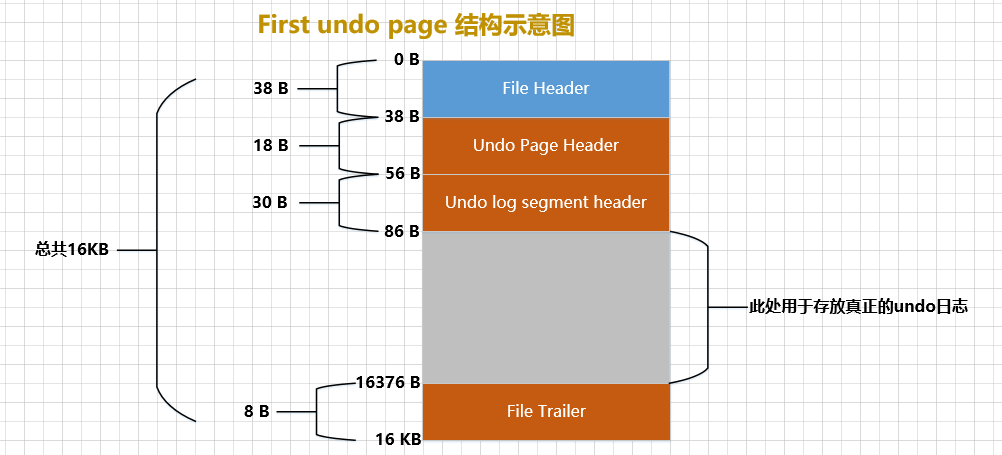
Quando falamos anteriormente sobre o espaço de tabela, dissemos que o espaço de tabela é, na verdade, composto de muitas 页面构成páginas 默认大小为16KB. Existem diferentes tipos dessas páginas. Por exemplo, FIL_PAGE_INDEXpáginas do tipo são usadas para armazenar índices agrupados e índices secundários, FIL_PAGE_TYPE_FSP_HDRpáginas do tipo são usadas para armazenar informações de cabeçalho do espaço de tabela e vários outros tipos de páginas, uma das quais é chamada Este FIL_PAGE_UNDO_LOGtipo de página é especialmente usado 存储undo日志e a estrutura geral desse tipo de página é mostrada na figura a seguir (tome o tamanho padrão de 16 KB como exemplo):
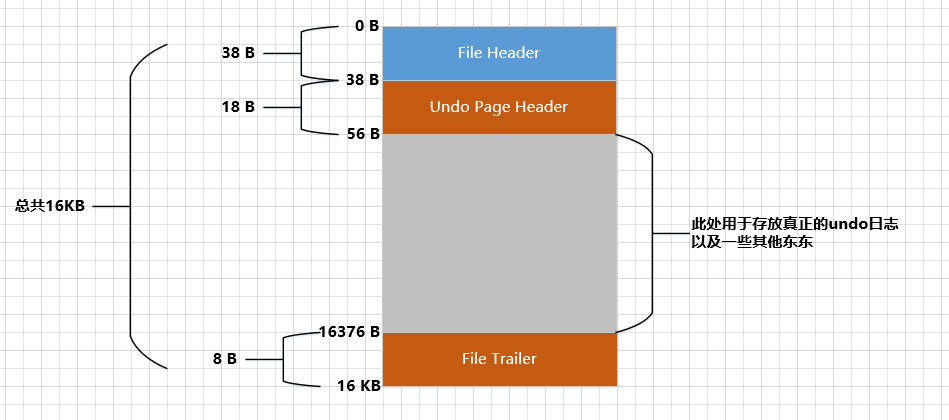
Uma página do tipo FIL_PAGE_UNDO_LOGé simplesmente referida como Undouma página. File HeaderO e na figura acima File Trailersão as estruturas comuns de várias páginas. Já aprendemos muitas vezes antes, então não vou entrar em detalhes aqui. Undo Page Headeré Undo页面único, vamos dar uma olhada em sua estrutura:
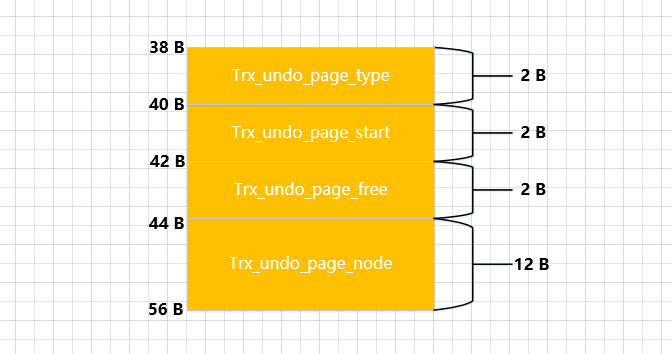
O significado de cada atributo é o seguinte:
-
TRX_UNDO_PAGE_TYPE: Que tipo de logs de desfazer serão armazenados nesta página.
Apresentamos vários tipos de logs de desfazer anteriormente, que podem ser divididos em duas categorias:-
TRX_UNDO_INSERT(Denotado por decimal 1): OTRX_UNDO_INSERT_REClog de desfazer do tipo pertence a esta categoria e geralmente éINSERTgerado por uma instrução, ou esse tipo de logUPDATEtambém será gerado quando a chave primária for atualizada na instrução .undo -
TRX_UNDO_UPDATE(denotado por decimal 2), exceto para logs do tipoTRX_UNDO_INSERT_REC,undotodos os outros tipos de logs pertencem a esta categoria, como o , etc.undoque mencionamos anteriormente , e os logs gerados pela instrução geralmente pertencem a esta categoria.TRX_UNDO_DEL_MARK_RECTRX_UNDO_UPD_EXIST_RECDELETEUPDATEundo
Os valores opcionais deste
TRX_UNDO_PAGE_TYPEatributo são os dois acima, que são usados para marcar qual categoria de logs esta página é usada para armazenarundo. Logs de categorias diferentesundonão podem ser armazenados juntos. Por exemplo , se uma página tiver valor de atributo deUndoum logs e outros tipos de logs de desfazer não podem ser colocados nesta página.TRX_UNDO_PAGE_TYPETRX_UNDO_INSERTTRX_UNDO_INSERT_RECundo小提示:
A razão pela qual os logs de undo são divididos em duas categorias é que os logs de undo do tipo TRX_UNDO_INSERT_REC podem ser excluídos diretamente após a confirmação da transação, enquanto outros tipos de logs de undo também precisam atender ao chamado MVCC e não podem ser excluídos diretamente. O processamento precisa ser tratado de forma diferente. Claro, se você ficou confuso depois de ler esta passagem, não precisa lê-la novamente. Agora você só precisa saber que os logs de desfazer são divididos em duas categorias. Explicaremos mais detalhes posteriormente. -
-
TRX_UNDO_PAGE_START: Indica ondeundoo log está armazenado na página atual, ou o deslocamento inicial do primeiroundolog nesta página. -
TRX_UNDO_PAGE_FREE: Correspondente ao acima , indica o deslocamento no final doTRX_UNDO_PAGE_STARTúltimo log armazenado na página atual ou, a partir desta posição, você pode continuar a gravar novos logs de desfazer.undoSupondo que 3 logs de desfazer sejam gravados na página agora, o diagrama esquemático de
TRX_UNDO_PAGE_STARTeTRX_UNDO_PAGE_FREEé assim:
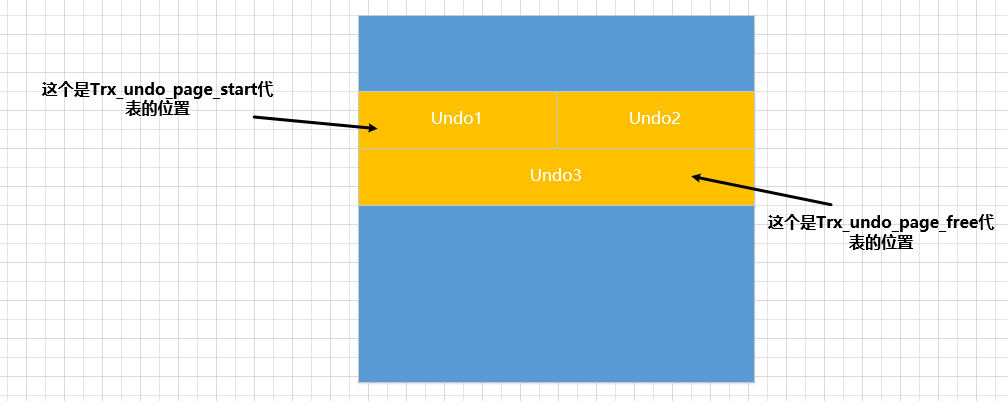
Claro, quando nenhum log de desfazer é gravado no início, o valor deTRX_UNDO_PAGE_STARTeTRX_UNDO_PAGE_FREEé o mesmo. -
TRX_UNDO_PAGE_NODE: Representa uma estrutura List Node (nó comum da lista encadeada, acabamos de citar acima), este atributo será utilizado logo abaixo, então não fique impaciente.
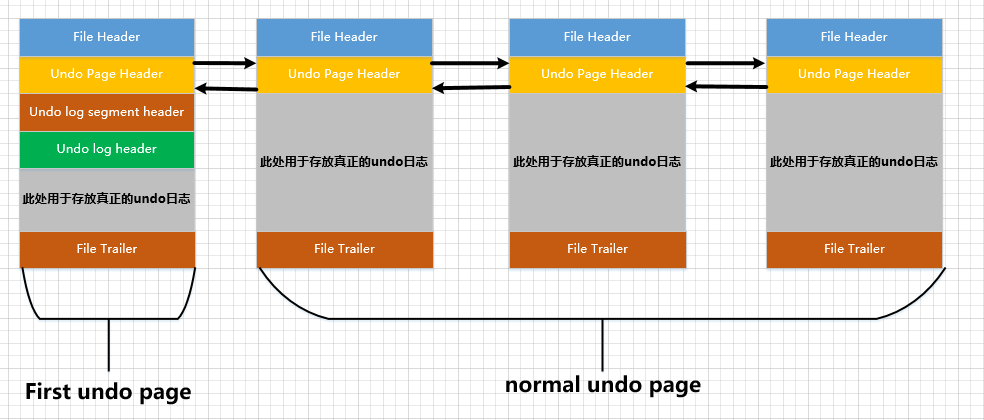
Seis, Desfazer lista vinculada de página
6.1 Desfazer lista encadeada de páginas em uma única transação
Como uma transação pode conter várias declarações, e uma declaração pode alterar vários registros, e cada registro precisa ser registrado antes da alteração, portanto, durante a 1条或2条的undo日志execução de uma transação 产生很多undo日志, esses logs podem não caber em uma página, precisa ser colocado em várias páginas, e essas páginas são TRX_UNDO_PAGE_NODEconectadas em uma lista encadeada por meio dos atributos que apresentamos acima :
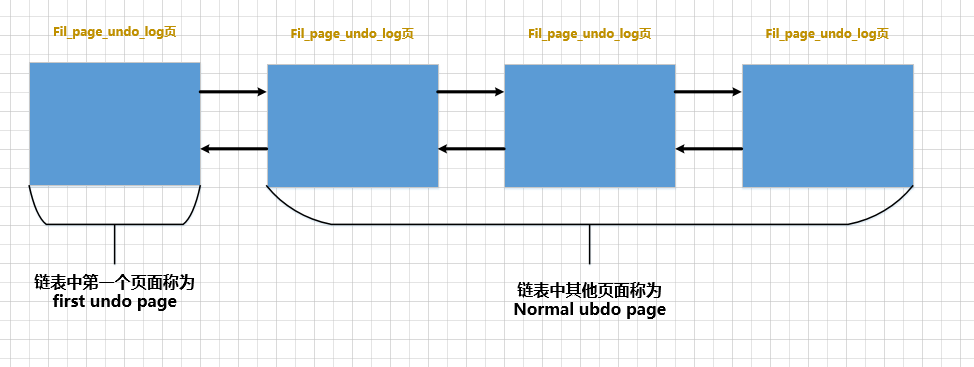 Você pode dar uma olhada na figura acima, e ao mesmo tempo chamar a primeira página Undo na lista vinculada como Undo
Você pode dar uma olhada na figura acima, e ao mesmo tempo chamar a primeira página Undo na lista vinculada como Undo first undo page, pois first undo pagealém dos registros Undo Page Header, ela também registrará outras informações de gerenciamento. O resto das páginas Desfazer chamam isso de normal undo page.
Durante a execução de uma transação, as instruções INSERT, DELETEe UPDATEpodem ser executadas de forma mista, o que significa que diferentes tipos de logs de desfazer serão gerados. Mas, como dissemos antes, a mesma Undopágina armazena apenas TRX_UNDO_INSERTgrandes categorias de logs de desfazer ou apenas TRX_UNDO_UPDATEgrandes categorias de logs de desfazer. De qualquer forma, eles não podem ser misturados, portanto, duas listas vinculadas de páginas de desfazer podem ser necessárias durante a execução de um transaction. , uma é chamada insert undode lista encadeada e a outra é chamada update undode lista encadeada. Desenhe um diagrama esquemático como este:
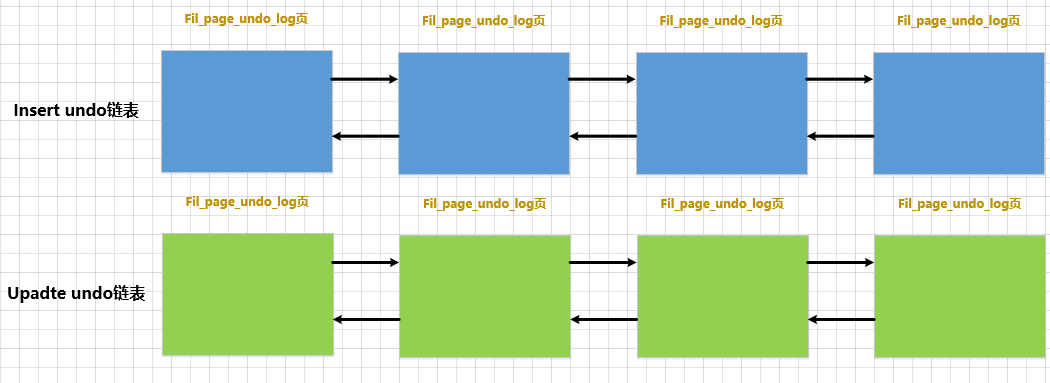
Além disso, os logs InnoDBgerados quando os registros das tabelas ordinárias e das tabelas temporárias são alterados undodevem ser registrados separadamente (explicado mais adiante), para que haja no máximo 4 Undolistas encadeadas compostas por páginas como nós em uma transação:
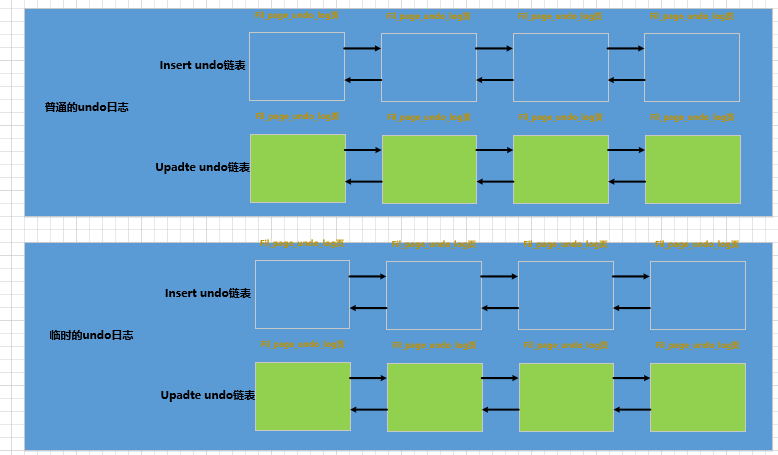
claro, não no início da transação Essas 4 listas encadeadas serão alocadas para esta transação, mas alocadas sob demanda. A estratégia de alocação específica é a seguinte:
- Quando a transação acaba de ser iniciada, uma lista encadeada da página Desfazer também não é alocada.
- Quando um registro é inserido em uma tabela comum ou uma operação de atualização da chave primária de um registro é realizada durante a execução da transação, uma
insert undolista encadeada de uma tabela comum será alocada a ele. - Quando os registros da tabela ordinária forem excluídos ou atualizados durante a execução da transação, uma
update undolista encadeada da tabela ordinária será atribuída a ela. - Quando um registro é inserido na tabela temporária ou a operação de atualização da chave primária do registro é realizada durante a execução da transação, uma lista encadeada da tabela temporária será alocada a ele
insert undo. - Quando os registros da tabela temporária forem excluídos ou atualizados durante a execução da transação, uma
update undolista encadeada da tabela temporária será atribuída a ela.
Resumindo é:什么时候需要啥时候再分配,不需要就不分配.
6.2 Desfazer lista encadeada de páginas em várias transações
Para melhorar a eficiência de gravação do log de desfazer tanto quanto possível, 不同事务执行过程中产生的undo日志需要被写入到不同的Undo页面链表中. Por exemplo, agora existem duas transações com IDs de transação 1 e 2 respectivamente, nós as chamamos de trx 1sum respectivamente trx 2, assumindo que durante a execução dessas duas transações:
trx 1A operação é feita na tabela comum e a operaçãoDELETEé feita na tabela temporária . Será alocada uma lista encadeada , que são:INSERTUPDATE
InnoDBtrx 13update undoLista encadeada para tabela normalinsert undoLista encadeada para tabela temporária- Uma lista encadeada em uma tabela temporária
update undo.
- trx 2 executou operações INSERT, UPDATE e DELETE em tabelas comuns, mas não fez alterações em tabelas temporárias.
InnoDBSerátrx 2alocada uma lista encadeada2, que são:- Inserir lista vinculada de desfazer para tabela comum
- Atualize a lista vinculada de desfazer para a tabela comum.
Para resumir, no processo de trx 1execução trx 2, InnoDBum total de 5 Undolistas vinculadas de páginas precisam ser alocadas para essas duas transações. Veja como fazer um desenho:
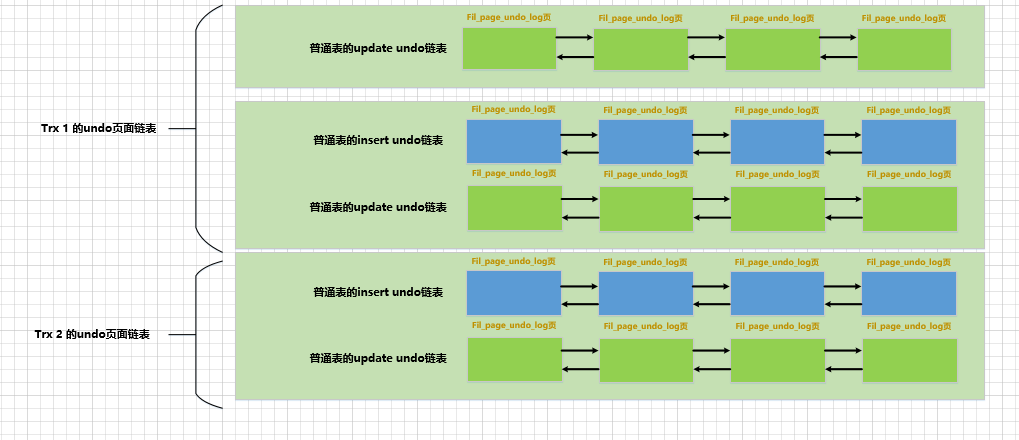
Se houver mais transações, isso significa que mais listas vinculadas da página Desfazer podem ser geradas.
7. O processo de gravação específico do registro de desfazer
7.1 O conceito de segmento (segmento)
Se você leu com atenção o capítulo sobre espaço de tabela, deve ter ficado impressionado com o conceito desse segmento, passamos muito espaço falando sobre esse conceito. Simplificando, este segmento é um conceito lógico, composto essencialmente por várias páginas dispersas e várias áreas completas. Por exemplo, um índice de árvore B+ é dividido em dois segmentos, um segmento de nó folha e um segmento de nó não folha, de modo que os nós folha possam ser armazenados juntos tanto quanto possível, e os nós não folha possam ser armazenados juntos tanto quanto possível. possível. Cada segmento corresponde a uma estrutura de entrada INODE. Essa estrutura de entrada INODE descreve várias informações desse segmento, como o ID do segmento, vários nós básicos de lista encadeada no segmento e os números de página de páginas dispersas, etc. (especificamente, nesta estrutura Você pode revisitar o significado de cada atributo no capítulo sobre espaço de tabela). Também dissemos antes que, para localizar uma entrada INODE, o InnoDB projetou uma Segment Headerestrutura:

O todo Segment Headerocupa 10 bytes de tamanho, e o significado de cada atributo é o seguinte:
-
ID do Espaço da Entrada INODE: ID do espaço de tabela onde a estrutura da Entrada INODE está localizada.
-
Número da página da entrada INODE: O número da página da estrutura da entrada INODE.
-
Byte Offset do INODE Ent: O deslocamento da estrutura INODE Entry nesta página
Conhecendo o ID do espaço de tabela, o número da página e o deslocamento dentro da página, você pode localizar exclusivamente o endereço de uma entrada INODE ~
小提士:
Os vários conceitos de segmentos nesta parte são explicados em detalhes no capítulo sobre o espaço de tabela. Vou mencioná-lo aqui apenas para despertar sua memória adormecida. Se você tiver algum ponto obscuro, pode voltar ao espaço de tabela novamente. Leia cuidadosamente
7.2 Desfazer Cabeçalho de Segmento de Log
InnoDBDe acordo com os regulamentos, cada lista encadeada da página Desfazer corresponde a um segmento, denominado Undo Log Segment. Ou seja, as páginas na lista vinculada são todas solicitadas a partir desta seção, então eles first undo pageprojetaram uma Undo Log Segment Headerparte chamada a primeira página da lista vinculada da página Desfazer, que é a mencionada acima. Esta parte contém as informações do segmento correspondente à lista vinculada segment headere outras informações sobre esse segmento, portanto, Undo页a primeira página da lista vinculada se parece com isso:
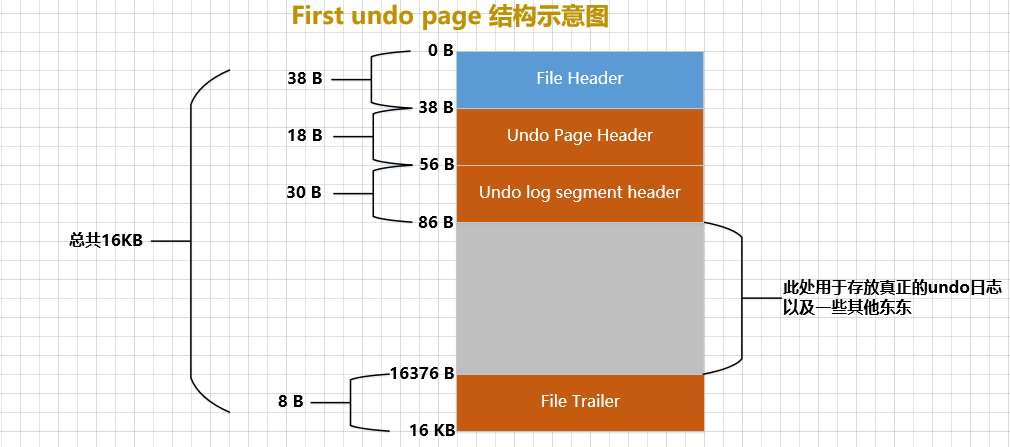
Você pode ver que Undo链表a primeira página desta página é maior que a página normal Undo Log Segment Header. Vamos dar uma olhada em sua estrutura:
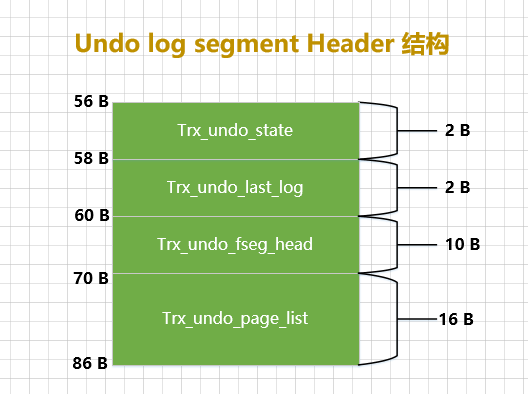
O significado de cada atributo é o seguinte:
-
TRX_UNDO_STATE: Em que estado está a lista vinculada da página Desfazer? UmUndo Log Segmentestado possível inclui o seguinte:-
TRX_UNDO_ACTIVE: Estado ativo, ou seja, uma transação ativa está gravando logs de desfazer neste segmento. -
TRX_UNDO_CACHED: O estado em cache. A lista vinculada da página Desfazer neste estado está aguardando para ser reutilizada por outras transações. -
TRX_UNDO_TO_FREE: Para a lista encadeada de desfazer inserção, se a lista encadeada não puder ser reutilizada após a confirmação da transação correspondente, ela estará neste estado. -
TRX_UNDO_TO_PURGE: Para a lista vinculada de desfazer atualização, se a lista vinculada não puder ser reutilizada após a confirmação da transação correspondente, ela estará neste estado. -
TRX_UNDO_PREPARED: Contém logs de undo gerados por transações na fase PREPARE
小提士:
Quando e como a lista vinculada da página Desfazer será reutilizada, isso será discutido em detalhes posteriormente. A fase PREPARE da transação só aparece na chamada transação distribuída.Este livro não introduzirá mais sobre transações distribuídas, então você pode ignorar este estado por enquanto. -
-
TRX_UNDO_LAST_LOG: A última posição na lista vinculada da página DesfazerUndo Log Header. -
TRX_UNDO_FSEG_HEADERUndo: A informação do segmento correspondente à lista encadeada nesta páginaSegment Header(ou seja, a estrutura de 10 bytes que introduzimos na seção anterior, através da qual você pode encontrar o segmento correspondenteINODE Entry) -
TRX_UNDO_PAGE_LIST: o nó base da lista de páginas Desfazer.Dissemos acima que a parte Undo Page Header da página Undo tem um
TRX_UNDO_PAGE_NODEatributo de 12 bytes, que representa umaList Nodeestrutura. CadaUndopágina contémUndo Page Headeruma estrutura e essas páginas podem ser vinculadas a uma lista vinculada por meio desse atributo. EsteTRX_UNDO_PAGE_LISTatributo representa o nó base desta lista encadeada, claro, este nó base só existe naUndoprimeira página da lista encadeada de páginas, ou seja,first undo pageem.
Desfazer cabeçalho do registro
A forma como uma transação Undoescreve undoum log em uma página é muito simples e violenta, ou seja, ela escreve diretamente nela, e escreve outra imediatamente depois de escrever uma, e cada undolog é íntimo. Depois de escrever uma página Desfazer, solicite uma nova página do segmento, insira esta página na lista vinculada da página Desfazer e continue escrevendo na página recém-aplicada. O InnoDB considera os logs de desfazer gravados em uma lista vinculada da página de desfazer pela mesma transação como um grupo. 2 alocará 2 listas vinculadas de páginas de desfazer, também gravará 2 grupos de logs de desfazer. Cada vez que um grupo de logs de undo é escrito, alguns atributos sobre este grupo serão gravados antes deste grupo de logs de undo.InnoDB chama o local onde esses atributos são armazenados Undo Log Header. Portanto, antes que a primeira página da lista de páginas Undo seja realmente gravada no log de undo, ela será preenchida com U ndo Page Header, Undo Log Segment Header, Undo Log Headeressas três partes, conforme mostrado na figura:
A Undo Log Headerestrutura específica é a seguinte:
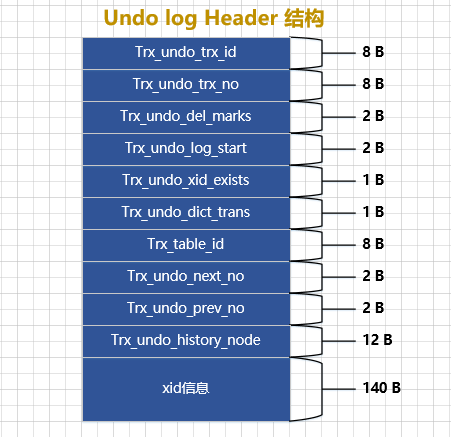
Há muitos atributos novamente, vamos dar uma olhada no que todos eles significam:
-
TRX_UNDO_TRX_ID: Gere o ID da transação deste grupo de logs de desfazer -
TRX_UNDO_TRX_NO: Um número de sequência é gerado depois que a transação é confirmada e esse número de sequência é usado para marcar a ordem de confirmação da transação (o número de sequência enviado primeiro é pequeno e o número de sequência enviado posteriormente é grande). -
TRX_UNDO_DEL_MARKS: Marque se este grupoundode logs contémDelete marklogs de desfazer gerados por operações. -
TRX_UNDO_LOG_START: Indica o deslocamento de página do primeiro log de undo neste grupo de logs de undo. -
TRX_UNDO_XID_EXISTS: se este grupo de logs de desfazer contém informações de XID. -
TRX_UNDO_DICT_TRANS: Marque se este grupo de logs de desfazer é gerado por instruções DDL. -
TRX_UNDO_TABLE_ID: Se TRX_UNDO_DICT_TRANS for verdadeiro, então este atributo indica o id da tabela operada pela instrução DDL. -
TRX_UNDO_NEXT_LOG: O deslocamento na página onde o próximo conjunto de logs de desfazer começa. -
TRX_UNDO_PREV_LOG: O deslocamento na página onde os logs de desfazer do grupo anterior começam.小提士:
De um modo geral, uma lista vinculada da página Desfazer armazena apenas um conjunto de logs de desfazer gerados durante a execução de uma transação, mas, em alguns casos, depois que uma transação é confirmada, a transação aberta subsequente pode reutilizar essa lista vinculada da página Desfazer, de modo que, como Como resultado, vários conjuntos de logs de Undo podem ser armazenados em uma página de Undo. TRX_UNDO_NEXT_LOG e TRX_UNDO_PREV_LOG são usados para marcar os deslocamentos do próximo conjunto e do conjunto anterior de logs de undo na página. Sobre quando reutilizar a lista vinculada da página Undo e como reutilizar essa lista vinculada, explicaremos em detalhes mais adiante. Por enquanto, apenas entenda o significado dos dois atributos TRX_UNDO_NEXT_LOG e TRX_UNDO_PREV_LOG. -
TRX_UNDO_HISTORY_NODE: Uma estrutura de nó de lista de 12 bytes que representa um nó chamado lista encadeada de histórico.
resumo
Para a lista encadeada de páginas que não foi reutilizada Undo, a primeira página da lista encadeada, ou seja, antes first undo pagede ser realmente gravada undono log, será preenchida Undo Page Header、Undo Log Segment Header、Undo Log Header这3个部分e, em seguida, será oficialmente gravada no log de desfazer. Para as demais páginas, ou seja, antes de normal undo pagerealmente gravar undono log, ele será preenchido apenas Undo Page Header. List Base NodeO armazenamento da lista encadeada first undo page的Undo Log Segment Header部分, List Nodeas informações são armazenadas na parte de cada Undopágina undo Page Header, então desenhe um Undodiagrama esquemático da lista encadeada de páginas assim:
8. Reutilize a página Desfazer
undoDissemos anteriormente que, para melhorar o desempenho de várias transações simultâneas gravadas no log, InnoDBdecidimos alocar uma Undolista vinculada de página correspondente para cada transação (até 4 listas vinculadas podem ser alocadas separadamente). Mas isso também causou alguns problemas. Por exemplo, de fato, apenas um ou alguns registros podem ser modificados durante a execução da maioria das transações. Para uma determinada lista encadeada da página Undo, apenas poucos logs de undo são gerados, e esses logs de undo podem ocupam apenas um pouco. Para espaço de armazenamento, Undonão seria muito desperdício ? Na verdade, é um desperdício, então o InnoDB decidiu reutilizar a lista de páginas da transação em alguns casos após a confirmação da transação Undo. As condições para saber se uma Undolista encadeada de páginas pode ser reutilizada são simples:
-
A lista vinculada contém apenas uma
Undopágina.
Se uma transação for gerada durante a execução非常多的undo日志, pode ser necessário adicionar várias páginas à lista vinculada da página Desfazer. Após o envio da transação, se as páginas em toda a lista vinculada forem reutilizadas, isso significa que, mesmo que a nova transação nãoUndograve muitosundologs na lista vinculada de páginas, muitas páginas devem ser mantidas na lista vinculada. não estão disponíveis não podem ser usados por outras empresas, o que gera outro tipo de resíduo. PortantoInnoDB, somenteUndoquando a lista de páginas Desfazer contém apenas uma página, a lista pode ser reutilizada pela próxima transação. -
O espaço já utilizado pela página Desfazer
小于整个页面空间的3/4
Como dissemos anteriormente, a lista encadeada da página Desfazer pode ser dividida eminsert undolista encadeada eupdate undolista encadeada de acordo com a categoria dos logs de desfazer armazenados. As estratégias dessas duas listas encadeadas também são diferentes quando são reutilizado. dê uma olhada-
inserir lista de desfazer
insert undoTRX_UNDO_INSERT_RECSomente logs do tipo são armazenados na lista encadeadaundoEste tipo de log de desfazer é inútil depois que a transação é confirmada e pode ser limpa. Então, depois que uma transação é confirmada, ao reutilizar a lista vinculada de desfazer desta transação (há apenas uma página nesta lista vinculada), você pode sobrescrever diretamente um conjunto de logs de desfazer gravados pela transação anterior e escrever um conjunto de desfazer logs para a nova transação do log zero, conforme a figura abaixo: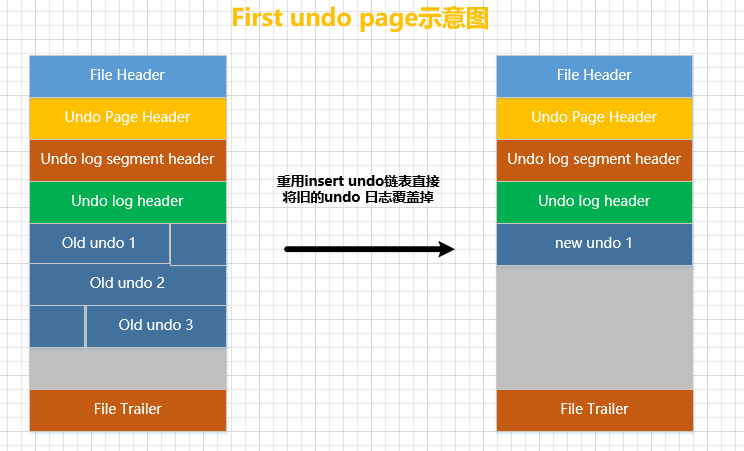
Conforme mostrado na figura, suponha que haja uma lista vinculada usada por uma transaçãoinsert undo. Quando a transação é confirmada, apenas 3 logs de desfazer são inseridos na lista vinculada de inserção e desfazer. Essa lista vinculada de inserção e desfazer se aplica apenas a uma página de desfazer. Assumindo que neste momento该页面已使用的空间小于整个页面大小的3/4, a próxima transação pode reutilizar estainsert undolista encadeada (há apenas uma página na lista encadeada). Supondo que uma nova transação reutilize ainsert undolista encadeada neste momento, o antigo conjunto de logs de desfazer pode ser substituído diretamente e um novo conjunto deundologs pode ser gravado. -
atualizar desfazer lista vinculada
Depois que uma transação é confirmada, os logsupdate undoem sua lista vinculadaundonão podem ser excluídos imediatamente (esses logs são usados para MVCC, sobre o qual falaremos mais adiante). Portanto, se as transações subsequentes quiserem reutilizarupdate undoa lista encadeada, elas não poderão sobrescrever os logs gravados pelas transações anterioresundo.UndoIsso é equivalente a gravar vários grupos de logs na mesma páginaundoe o efeito se parece com isso
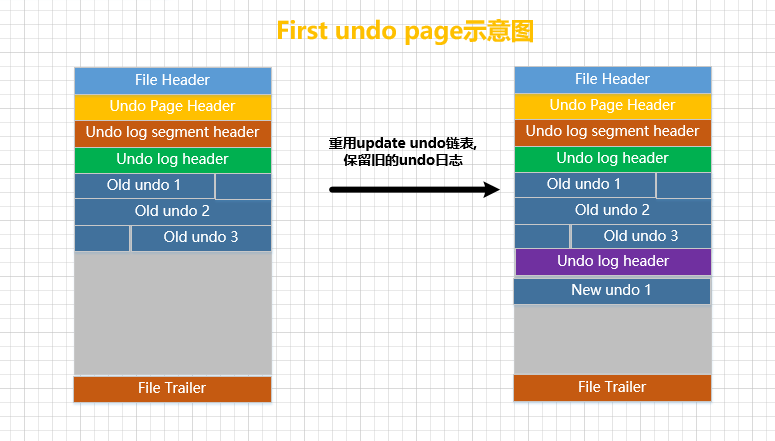
-
Nove, segmento de reversão
9.1 O conceito de segmento de rollback
Agora sabemos que uma transação pode alocar até 4 listas vinculadas de páginas durante a execução Undoe transações diferentes têm Undolistas vinculadas de páginas diferentes ao mesmo tempo, portanto, pode haver muitas listas vinculadas de páginas de desfazer no sistema ao mesmo tempo. Para melhor gerenciar essas listas encadeadas , InnoDBuma página chamada . Podemos entender que cada lista encadeada de página equivale a uma turma, e essa lista encadeada equivale ao monitor desta turma. Se você encontrar o monitor desta turma, poderá encontrar outros alunos da turma (outros alunos são equivalentes ) . Às vezes a escola precisa passar o espírito para essas aulas, e precisa chamar todos os monitores da sala de conferências, que equivale a uma sala de conferências.Rollback Segment HeaderUndofrist undo pageundo slotUndofirst undo pagenormal undo pageRollback Segment Header
Vamos dar uma olhada na Rollback Segment Headeraparência dessa chamada página (pegue o padrão de 16 KB como exemplo):
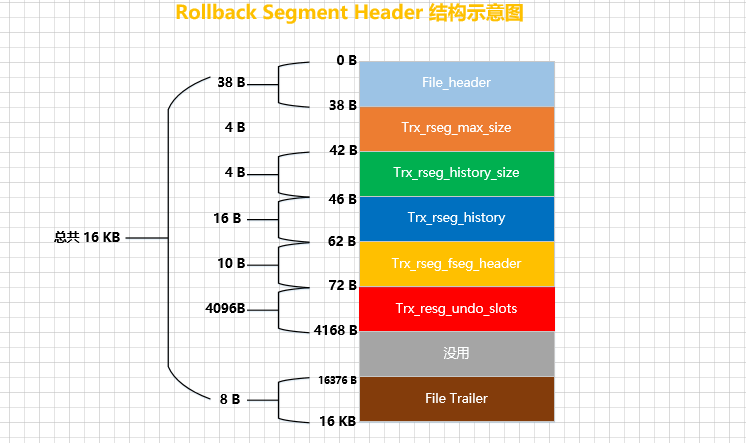
InnoDBÉ estipulado que cada Rollback Segment Headerpágina corresponde a um segmento, e esse segmento é denominado Rollback Segment, ou seja 回滚段. Diferente das várias seções que introduzimos antes, Rollback Segmentna verdade há apenas uma página nesta (isso pode ser InnoDBporque eles pensam que, se quiserem alocar páginas para um determinado propósito, devem primeiro solicitar uma seção, ou pensam que, embora a versão atual tem MySQLapenas Rollback Segmentuma página, mas pode ser possível adicionar páginas em versões posteriores).
Depois de entender Rollback Segmento significado de , vamos dar uma olhada no Rollback Segment Headersignificado de cada parte dessa chamada página:
-
TRX_RSEG_MAX_SIZE: O valor máximo da soma do número de páginas emRollback Segmenttodas as listas encadeadas de páginas gerenciadas neste livro . Em outras palavras, Ben .UndoUndoRollback Segment中所有Undo页面链表中的Undo页面数量之和不能超过TRX_RSEG_MAX_SIZE代表的值O valor desta propriedade é infinito por padrão, ou seja, podemos escrever quantas páginas Undo quisermos.
小提士:
Infinito na verdade é apenas um exagero, o maior número que pode ser representado por 4 bytes é 0xFFFFFFFF, mas veremos mais adiante que o número 0xFFFFFFFF tem um propósito especial, então o valor real de TRX_RSEG_MAX_SIZE é 0xFFFFFFFE. -
TRX_RSEG_HISTORY_SIZE:HistoryO número de páginas ocupadas pela lista encadeada. -
TRX_RSEG_HISTORY:HistoryO nó base da lista encadeada. -
TRX_RSEG_FSEG_HEADER: Esta é umaRollback Segmentestrutura de 10 bytes correspondente a estaSegment Headerseção, através da qual você pode encontrar a seção correspondenteINODE Entry.
TRX_RSEG_UNDO_SLOTS: a coleção de números de página de cada Undolista vinculada de página , ou seja, a coleção.first undo pageundo slot
Um número de página ocupa 4bytes. Para 16KBuma página deste tamanho, esta TRX_RSEG_UNDO_SLOTSparte armazena um total de 1024bytes undo slot, portanto, um total de 1024 × 4 = 4096个字节
9.2 Solicitar a lista vinculada da página Desfazer do segmento de reversão
Inicialmente, como nenhuma Undolista encadeada de páginas é alocada para nenhuma transação, Rollback Segment Headercada uma delas undo sloté definida com um valor especial para uma página: FIL_NULL(o valor hexadecimal correspondente é 0xFFFFFFFF), indicando que undo slotnão aponta para nenhuma página.
Com o passar do tempo, existem transações que precisam alocar Undolistas vinculadas de páginas, portanto, comece pela primeira do segmento de rollback undo slotpara ver se undo sloto valor é FIL_NULL:
-
Se for
FIL_NULL, crie um novo segmento (ou seja), no espaço de tabela eUndo Log Segment, em seguida, solicite uma página do segmento como umaUndolista de links de páginafirst undo pagee, em seguida, definaundo sloto valor disso para o número da página da página recém-aplicada , o que significa Istoundo sloté atribuído a esta transação. -
Se não
FIL_NULL, significa que esteundo slotjá apontou para umaundolista encadeada, ou seja, estaundo slotjá foi ocupada por outras transações, então pule para a próximaundo slot, julgueundo slotse o valor desta está corretoFIL_NULL, e repita os passos acima.
Rollback Segment HeaderIncluído em uma página 1024个undo slot, 1024se undo sloto valor desta for nenhum FIL_NULL, significa que 1024esta undo slotjá foi nomeada (atribuída a uma determinada transação). Neste momento, porque a nova transação não pode mais obter uma nova Undolista de páginas, ela rolará volte a transação e reporte um erro ao usuário:
Too many active concurrent transactions
Quando o usuário vê esse erro, ele pode optar por reexecutar a transação (talvez outras transações sejam confirmadas durante a reexecução e a transação possa ser alocada em uma Undolista de páginas).
Quando uma transação é confirmada, o que ela ocupa undo slottem dois destinos:
-
Se a lista vinculada
undo slotà páginaUndoapontada atender à condição de ser reutilizada (ou seja, a lista vinculada da página Desfazer que mencionamos acima ocupa apenas uma página e o espaço utilizado é inferior a 3/4 da página inteira).Está
undo slotno estado de cache eInnoDBé estipulado que o atributoUndoda lista vinculada à páginaTRX_UNDO_STATE(a parte rfirst undo pagedo atributoUndo Log Segment Heade) será definido comoTRX_UNDO_CACHED.Os em cache serão adicionados a uma lista vinculada e serão adicionados a diferentes listas vinculadas,
undo slotdependendo do tipo da lista vinculada da página correspondente :Undo-
Se a
Undolista vinculada da página correspondente forinsert undouma lista vinculada, elaundo slotserá adicionada àinsert undo cachedlista vinculada. -
Se a
Undolista vinculada da página correspondente forupdate undouma lista vinculada, elaundo slotserá adicionada àupdate undo cachedlista vinculada.
Um segmento de rollback corresponde às duas
cachedlistas vinculadas acima. Se houver uma nova transação a ser alocada , ela será encontrada primeiro na lista vinculadaundo slotcorrespondente .cachedSe não estiver armazenado em cacheundo slot, ele irá para a的Rollback Segment Headerpágina do segmento de reversão para localizá-lo novamente. -
-
Se a lista vinculada de página
undo slotapontadaUndonão atender à condição de ser reutilizada, a lista vinculada de páginaundo slotcorrespondenteUndoserá tratada de forma diferente de acordo com o tipo: -
Se a
Undolista vinculada à página correspondente forinsert undouma lista vinculada, o atributoUndoda lista vinculada à páginaTRX_UNDO_STATEserá definido comoTRX_UNDO_TO_FREE, e então oUndosegmento correspondente à lista vinculada à página será liberado (o que significa que as páginas no segmento podem ser usadas para outros propósitos ) e, em seguida, oundo slotvalor é definido comoFIL_NULL. -
Se a
Undolista vinculada da página correspondente forupdate undouma lista vinculada, a propriedadeUndoda lista vinculada da páginaTRX_UNDO_STATEserá definida comoTRX_UNDO_TO_PRUGE, eundo sloto valor será definido comoFIL_NULL, e então um conjunto de logs gravados por esta transaçãoundoserá colocado no chamadoHistoryvinculado list (observe que, o segmento correspondente à lista vinculada da página Desfazer não será liberado aqui, pois essesundologs ainda são úteis~)
9.3 Múltiplos segmentos de reversão
Dizemos que o mais alocado durante a execução de uma transação 4个Undo页面链表, mas apenas em um segmento de rollback 1024个undo slot, obviamente undo sloto número é um pouco pequeno. 1Mesmo se assumirmos que apenas uma listaUndo encadeada de páginas é alocada durante a execução de uma transação de leitura e gravação , isso pode suportar apenas a execução simultânea de duas transações de leitura e gravação e travará se houver mais. Isso equivale ao fato de que a sala de conferência pode acomodar apenas um monitor para realizar uma reunião ao mesmo tempo. Se milhares de pessoas vierem à sala de conferência para uma reunião ao mesmo tempo, esses monitores não terão lugar para sentar e só pode esperar que as pessoas na frente terminem a reunião antes de entrar.1024undo slot10241024
Diz-se que InnoDBhá realmente apenas um segmento de reversão no estágio inicial de desenvolvimento, mas InnoDBdepois percebeu esse problema, como resolver esse problema? Não há salas de conferência suficientes, então precisamos construir mais algumas salas de conferência. Portanto, InnoDBdefinir 128um segmento de rollback em uma respiração é equivalente a ter um 128 × 1024 = 131072个undo slot. 1Supondo que apenas uma lista vinculada de página seja alocada durante a execução de uma transação de leitura e gravação Undo, 131072a execução simultânea de várias transações de leitura e gravação pode ser suportada ao mesmo tempo (nunca vi tantas transações executadas simultaneamente em uma máquina ~)
Cada segmento de rollback corresponde a uma Rollback Segment Headerpágina. Se houver 128um segmento de rollback, deve haver 128uma Rollback Segment Headerpágina. Os endereços dessas páginas devem ser armazenados em algum lugar! Portanto, uma determinada área da InnoDBpágina nº do espaço de tabela do sistema 5contém 128 grades de 8 bytes:
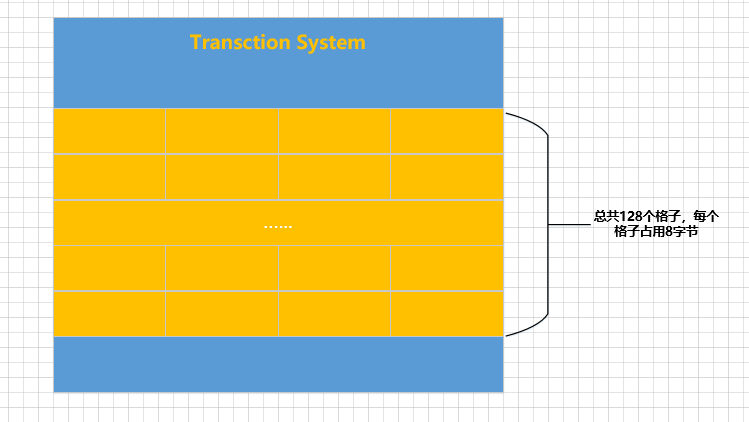
Cada grade de 8 bytes é construída assim:

Conforme mostrado, cada grade de 8 bytes consiste, na verdade, em duas partes:
-
4 bytes de tamanho
Space ID, representando o ID de um tablespace. -
4 bytes de tamanho
Page number, representando um número de página.
Ou seja, cada tamanho de 8 bytes 格子é equivalente a um ponteiro, apontando para uma determinada página em um determinado espaço de tabela, e essas páginas são Rollback Segment Header. Uma coisa a observar aqui é que, para localizar um Cabeçalho de Segmento de Rollback, você precisa conhecer o ID do tablespace correspondente, o que significa que diferentes segmentos de rollback podem ser distribuídos em diferentes tablespaces.
Portanto, por meio da descrição acima, podemos entender aproximadamente que há dois endereços de página 5armazenados na página Nº do espaço de tabela do sistema, cada um dos quais equivalente a um segmento de rollback. Na página, ele também contém , cada um correspondendo a uma lista encadeada de páginas. Vamos desenhar um diagrama:128Rollback Segment HeaderRollback Segment HeaderRollback Segment Header1024个undo slotundo slotUndo
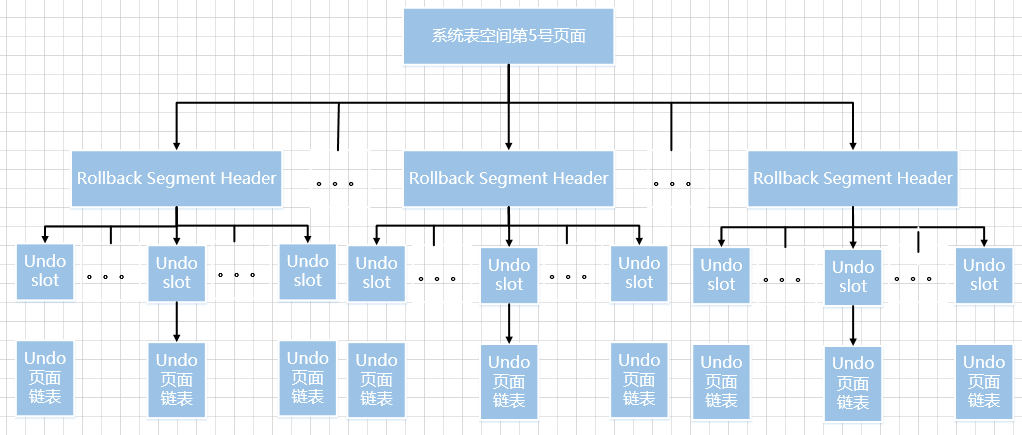
É muito mais revigorante quando a imagem é desenhada.
9.4 Classificação dos Segmentos de Rollback
Vamos numerar os 128 segmentos de rollback. O segmento de rollback inicial é chamado de segmento de rollback nº 0 e, em seguida, incrementado sucessivamente. O último segmento de rollback é chamado de segmento de rollback nº 127. Os 128 segmentos de rollback podem ser divididos em duas categorias:
-
第0号、第33~127号回滚段属于一类. Entre eles, o segmento de rollback nº 0 deve estar no espaço de tabela do sistema (ou seja, a página Cabeçalho do segmento de rollback correspondente ao segmento de rollback nº 0 deve estar no espaço de tabela do sistema) e os segmentos de rollback nº 33 a 127 podem ser no tablespace do sistema, ou no tablespace de undo configurado por você, falaremos sobre como configurá-lo mais tarde.Se uma transação precisar alocar uma lista encadeada da página Undo devido a alterações nos registros da tabela comum durante a execução, o slot de undo correspondente deve ser alocado a partir desse tipo de segmento.
-
第1~32号回滚段属于一类. Esses segmentos de rollback devem estar no tablespace temporário (correspondente ao arquivo ibtmp1 no diretório de dados).Se uma transação precisar alocar uma lista encadeada da página Undo devido a alterações nos registros da tabela temporária durante a execução, ela deverá ser alocada a partir desse tipo de segmento
undo slot.
Ou seja, se uma transação alterar tanto os registros da tabela ordinária quanto os registros da tabela temporária durante a execução, é necessário alocar 2 segmentos de rollback para este registro, e então ir para os dois segmentos de rollback correspondentes a este registro. a alocação no segmento undo slot.
Não sei se você tem alguma dúvida, por que devemos dividir diferentes tipos de segmentos de rollback para tabelas comuns e tabelas temporárias? Isso tem que Undocomeçar com a própria página. Dizemos que Undouma página é na verdade FIL_PAGE_UNDO_LOGa abreviação de uma página do tipo . Afinal, ela também é uma página comum. Como dissemos antes, você deve redoescrever o log correspondente antes de modificar a página, para que quando o sistema travar e reiniciar, ele possa restaurar o estado anterior ao travamento. UndoEscrever logs na undoprópria página também é um processo de escrever páginas. Por esse motivo, muitos tipos de logs InnoDBsão projetados , como , , , e assim por diante. Ou seja, qualquer alteração que fizermos na página registrará o correspondente tipo de registro. Mas para tabelas temporárias, os logs gerados pela modificação de tabelas temporárias só precisam ser válidos durante a operação do sistema. Se o sistema travar, não é necessário restaurar as páginas onde esses logs estão localizados ao reiniciar, portanto, ao escrever para tabelas temporárias Há não há necessidade de gravar o log correspondente quando a página é exibida . Resuma os motivos para dividir diferentes tipos de segmentos de rollback para tabelas comuns e tabelas temporárias: ao modificar as páginas nos segmentos de rollback para tabelas comuns, você precisa registrar os logs correspondentes e modificar as páginas nos segmentos de rollback para tabelas temporárias log correspondente.redoMLOG_UNDO_HDR_CREATEMLOG_UNDO_INSERTMLOG_UNDO_INITUndoredoundoundoUndoredoUndoredoUndoredo
小提士:
Se fizermos alterações apenas nos registros da tabela comum, apenas o segmento de rollback da tabela comum será alocado para a transação e o segmento de rollback da tabela temporária não será alocado. Mas se fizermos apenas alterações nos registros da tabela temporária, a transação será alocada tanto o segmento de reversão para a tabela comum quanto o segmento de reversão para a tabela temporária (mas a alocação do segmento de reversão não alocará imediatamente o desfazer slot e apenas aloque o slot de desfazer no segmento de reversão quando a lista vinculada da página de desfazer for realmente necessária).
9.5 Processo detalhado de alocação da lista vinculada da página Undo para transação
Undo页面Existem muitos conceitos mencionados acima e todos devem se sentir um pouco tontos. Em seguida, vamos pegar o exemplo de uma transação alterando os registros de uma tabela comum para resolver o processo completo de alocação de uma lista encadeada durante a execução da transação.
-
Antes de fazer qualquer alteração nos registros de tabelas comuns pela primeira vez durante a execução de uma transação, ele primeiro alocará um segmento de reversão para a página 5 do espaço de tabelas do sistema (na verdade, é para obter o endereço de uma página)
Rollback Segment Header. Depois que um determinado segmento de rollback é atribuído a esta transação, quando os registros da tabela comum são alterados na transação posteriormente, ele não será alocado repetidamente.Use o método lendário
round-robin(reciclagem) para alocar segmentos de reversão. Por exemplo, se a transação atual alocar o segmento de rollback nº 0, a próxima transação alocará o segmento de rollback nº 33 e a próxima transação alocará o segmento de rollback nº 34. Simplificando, esses segmentos de rollback são alocados Alocação para assuntos diferentes por sua vez (é tão simples e rude, não há nada a dizer). -
Depois que o segmento de rollback for atribuído, verifique primeiro
cachedse as duas listas vinculadas do segmento de rollback foram armazenadas em cacheundo slot. Por exemplo, se a transação forINSERTuma operação, vá para a lista vinculada i correspondente ao segmento de rollbacknsert undo cachedpara ver se há algum cacheundo slot; Se a transação forDELETEuma operação, vá para a lista encadeada correspondente ao segmento de rollbackupdate undo cachedpara ver se existe algum cacheundo slot. Se houver um cacheundo slot,undo slotatribua esse cache à transação. -
Se não houver cache
undo slotdisponível para alocação, será necessárioRollback Segment Headerencontrar uma alocação disponívelundo slotna página para a transação atual.Rollback Segment HeaderA forma de alocar as páginas disponíveis da páginaundo slottambém é mencionada acima, ou seja, a partir da 0ªundo slot, se oundo slotvalor desse valorFIL_NULLsignificar queundo slotestá livre,undo slotatribua-a à transação atual, caso contrário, verifique se a primeiraundo sloté condição satisfeita, e assim sucessivamente, até a últimaundo slot. Se nenhum dos 1024 slots de desfazer tiver um valorFIL_NULL, apenas reporte um erro (geralmente isso não acontecerá) ~ -
Depois de encontrar o disponível
undo slot, se forundo slotobtido dacachedlista vinculada, o correspondenteUndo Log Segmentfoi alocado, caso contrário, ele precisa ser realocadoUndo Log Segmente, em seguida,Undo Log Segmentsolicitar uma página dele comoUndoa lista vinculada de páginasfirst undo page. -
Em seguida, a transação pode
undogravar o log no aplicativo acimaUndo页面链表了!
Os passos para modificar os registros da tabela temporária são os mesmos descritos acima, por isso não os repetirei aqui. No entanto, é necessário enfatizar novamente que, se uma transação alterar os registros da tabela comum e os registros da tabela temporária durante a execução, será necessário alocar 2 segmentos de rollback para este registro. De fato, diferentes transações executadas simultaneamente também podem ser atribuídas ao mesmo segmento de rollback, desde que sejam atribuídos a segmentos diferentes undo slot.
9.6 Configuração relacionada ao segmento de rollback
9.6.1 Configurar o número de segmentos de rollback
Dissemos anteriormente que há um total de segmentos de rollback no sistema 128. Na verdade, este é apenas o valor padrão. Podemos configurar o número de segmentos de rollback através dos parâmetros de inicialização innodb_rollback_segments. O intervalo configurável é 1~128. Mas este parâmetro não afetará o número de segmentos de rollback para tabelas temporárias, o número de segmentos de rollback para tabelas temporárias é sempre 32, ou seja:
-
Se
innodb_rollback_segmentsdefinirmos o valor como1, haverá apenas1um segmento de rollback disponível para tabelas normais, mas ainda haverá32um disponível para tabelas temporárias. -
Se
innodb_rollback_segmentsdefinirmos o valor como um número entre , o efeito será o mesmo2~33que defini-lo como .1 -
Se definirmos o número
innodb_rollback_segmentscomo大于33, o número de segmentos de rollback disponíveis para tabelas comuns será该值减去32.
9.6.2 Configurando o tablespace undo
Por padrão, os segmentos de rollback (número 0e 33~127segmentos de rollback) configurados para tabelas comuns são alocados para o espaço de tabelas do sistema. O 0segmento de rollback nº 1 está sempre no espaço de tabela do sistema, mas o 33~127segmento de rollback nº 1 pode ser colocado em um undoespaço de tabela customizado por meio da configuração. Porém esta configuração só pode ser utilizada quando o sistema for inicializado (ao criar o diretório de dados), uma vez finalizada a inicialização não poderá ser alterada novamente. Vamos dar uma olhada nos parâmetros de inicialização relevantes:
-
Ao
innodb_undo_directoryespecificarundoo diretório onde o tablespace está localizado, se este parâmetro não for especificado, oundodiretório padrão onde o tablespace está localizado é o diretório de dados. -
Definindo o
innodb_undo_tablespacesnúmeroundode tablespaces. O valor padrão desse parâmetro é0, indicando que nenhumundoespaço de tabela foi criado.Os segmentos de rollback nº 33 a 127 podem ser distribuídos uniformemente para diferentes tablespaces de undo.
小提士:
Se especificarmos a criação do tablespace undo quando o sistema for inicializado, o segmento de rollback nº 0 no tablespace do sistema ficará indisponível.
Por exemplo, quando inicializamos o sistema, especificamos como innodb_rollback_segments, para que os segmentos No. e No. rollback sejam distribuídos para um espaço de tabela respectivamente .35innodb_undo_tablespaces23334undo
undo表空间Um dos benefícios da configuração é que, quando o undoarquivo no espaço de tabela for grande o suficiente, ele poderá ser convertido automaticamente em um arquivo pequeno. O tamanho do espaço de tabela do sistema só pode ser aumentado continuamente, mas não pode ser truncado.undo表空间截断truncate