análise de vídeo relacionada ao Linux:
Analise a arquitetura do kernel Linux em 5 aspectos, para que você não esteja mais familiarizado com o kernel.Leve
você para implementar um sistema de arquivos do kernel Linux.
1. Introdução
O gerenciamento de memória é uma parte muito importante do kernel Linux. Vamos aprender com você hoje.
Quando queremos aprender um novo ponto de conhecimento, o melhor processo é primeiro entender a razão de fundo para o surgimento deste ponto de tecnologia, outras soluções ao mesmo tempo, quais problemas o novo ponto de tecnologia resolve e quais deficiências e melhorias ele tem , de modo que todo o estudo O processo é um ciclo fechado, pessoalmente acho que esta é uma boa ideia de aprendizagem.
Tudo está interligado, e alguns problemas da ciência da computação podem ser prototipados na vida real, então acho que a maioria dos cientistas da computação são bons em observar a vida e resumi-la. A sociedade humana é uma máquina complexa, cheia de mecanismos e regras, então às vezes é melhor pular no oceano do código do que voltar à vida primeiro, procurar protótipos e depois explorar o código, que pode ter um entendimento mais profundo.
Os volumes de gerenciamento de memória do Linux são numerosos, e este artigo pode fornecer apenas uma introdução passo a passo para o contorno do iceberg. Por meio deste artigo, você aprenderá o seguinte:
- Por que você precisa gerenciar a memória
- Mecanismo de gerenciamento de página de segmento Linux
- O mecanismo de fragmentação da memória
- Os princípios básicos do sistema de camaradagem
- Vantagens e desvantagens do sistema de camaradagem
- O princípio básico do distribuidor de placas
2 Por que preciso gerenciar a memória
A famosa visão de Lao Tzu é governar sem fazer nada. Simplificando, é possível operar de maneira ordenada sem muita intervenção e confiando na autoconsciência. Os ideais são bonitos e a realidade é cruel.
Existem alguns problemas no gerenciamento de memória de uma maneira simples e primitiva em um sistema Linux. Vejamos alguns cenários.
2.1 Problemas com gerenciamento de memória
Problema de isolamento de espaço de processo
Se houver três processos ABC em execução no espaço de memória do Linux, defina o espaço de endereço alocado por os para o processo A como 0-20M, o espaço de endereço do processo B 30-80M e o espaço de endereço do processo C 90-120M, conforme mostrado em a figura:
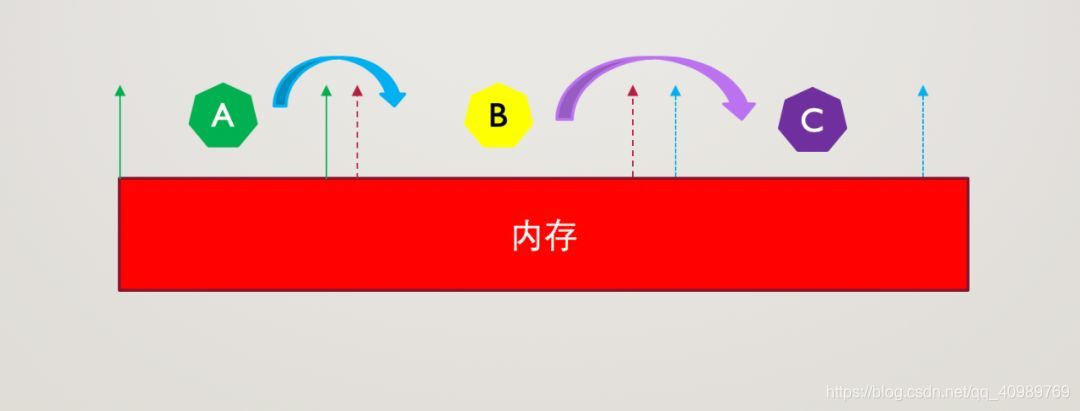
Pode haver problemas de acesso ao espaço do programa em determinados momentos. Por exemplo, o processo A acessa o espaço pertencente ao processo B, o processo B acessa o espaço pertencente ao processo C e até modifica o valor do espaço. e erros, então a China real não permite que isso aconteça.
Problemas de eficiência e falta de memória
A memória da máquina tem recursos limitados e o número de processos não pode ser determinado. Se um processo que foi iniciado em algum ponto ocupa todo o espaço de memória, um novo processo não pode ser iniciado neste momento porque não há memória nova disponível. Alocada, mas observamos que o processo iniciado às vezes está dormindo, ou seja, a memória não é utilizada, então a eficiência é realmente um pouco baixa, então precisamos de um administrador para esvaziar a memória não utilizada, e memória contínua É realmente precioso, muitas vezes não podemos alocar memória contígua com eficiência e no tempo, portanto, a virtualização e a discretização podem aumentar efetivamente o uso da memória.
Problemas de posicionamento, depuração, compilação e execução do programa.
Como a posição do programa é incerta quando o programa está em execução, teremos muitos problemas na localização de problemas, depuração de código e compilação e execução. Esperamos que cada processo tenha um e espaço de endereço completo. Heap, pilha, segmento de código, etc. são colocados na posição inicial para simplificar o uso do vinculador e carregador durante a compilação e execução.
2.2 Espaço de endereçamento virtual
A fim de resolver alguns dos problemas acima, o sistema Linux introduz o conceito de espaço virtual.O surgimento da virtualização está intimamente ligado ao hardware. Pode-se dizer que é o resultado da combinação de software e hardware O espaço de endereço virtual está no programa e no espaço físico.A camada intermediária adicionada também é o foco do gerenciamento de memória.
O disco como um armazenamento de grande capacidade, ele também participa da operação do programa como parte da "memória". O sistema de gerenciamento de memória fará a paginação da memória inativa que não é comumente usada. Pode-se considerar que a memória é a cache do disco, e a memória ativa é reservada Dados, que indiretamente expande o espaço limitado da memória física, que é chamado de memória virtual e é relativo à memória física.
[Benefícios do artigo] Materiais de aprendizagem do arquiteto do servidor Linux C / C ++ mais o grupo 812855908 (dados incluindo C / C ++, Linux, tecnologia golang, Nginx, ZeroMQ, MySQL, Redis, fastdfs, MongoDB, ZK, mídia de streaming, CDN, P2P, K8S, Docker, TCP / IP, corrotina, DPDK, ffmpeg, etc.)
3. Mecanismo de gerenciamento de página de segmento
Este artigo não aborda a memória de gerenciamento de segmento e memória de gerenciamento de paginação, pois existem muitos artigos excelentes sobre esses detalhes, e os interessados podem usar o mecanismo de busca para acessá-los com um clique.
O mecanismo da página de segmento não é alcançado durante a noite. Ele passou pelos estágios de segmentação física pura, paginação pura e segmentação lógica pura e, finalmente, desenvolveu um método de gerenciamento de memória que combina segmentação e paginação. A combinação de páginas de segmento obtém as vantagens de segmentação e paginação, além de evitar as lacunas de um único modelo e é um melhor modelo de gestão.
Este artigo pretende apenas explicar alguns conceitos gerais sobre o mecanismo de gerenciamento de parágrafos. O mecanismo de gerenciamento de parágrafos é uma combinação de gerenciamento de segmentos e gerenciamento de paging. O gerenciamento de segmentos é um método de gerenciamento lógico e o gerenciamento de paging é um método de gerenciamento físico.
Algumas tecnologias e implementações em computadores podem ser encontradas na vida real.A chamada arte e tecnologia vêm da vida provavelmente significa isso.
Veja o caso:
existe um conceito de bairros, condados e cidades na gestão do cadastro dos moradores, mas na verdade não existe tal entidade. É lógico, o acréscimo dessas unidades administrativas pode tornar a gestão dos endereços mais direta.
Para os nossos residentes, a única entidade é a casa própria e a residência, esta é uma unidade física, uma existência real e é também a unidade mais básica.
Em comparação com o gerenciamento de páginas de segmento do Linux, os segmentos são unidades lógicas equivalentes ao conceito de distritos, condados e cidades, e as páginas são unidades físicas equivalentes ao conceito de comunidade / casa, o que é muito mais conveniente.
A tabela de páginas de vários níveis também é fácil de entender. Se a memória física total for 4 GB e o tamanho da página for de 4 KB, então haverá 2 ^ 20 páginas no total, o que ainda é muito grande. É inconveniente criar endereçamento de índice por numeração, então Apresente tabelas de páginas de vários níveis para reduzir o armazenamento e facilitar o gerenciamento.
Um diagrama simplificado da relação de mapeamento entre endereços lógicos e endereços físicos suportados pelo mecanismo de página de segmento, ou seja, a relação correspondente entre endereços virtuais e endereços físicos:
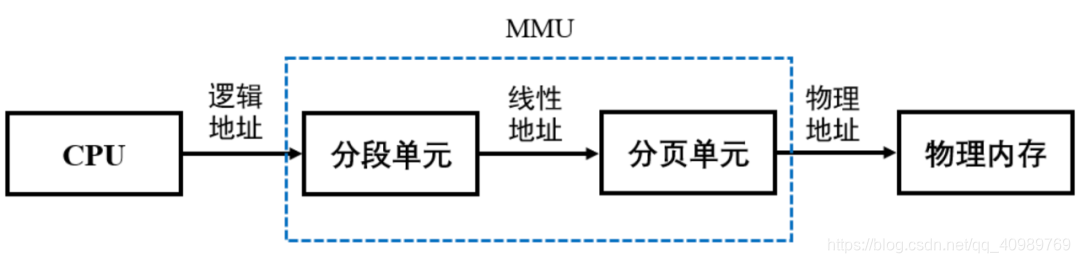
A MMU Memory Management Unit (MMU Memory Management Unit) é um componente da camada de hardware que fornece principalmente o mapeamento de endereços virtuais para endereços físicos.
Fluxo de trabalho MMU: a CPU gera endereço lógico e o entrega à unidade de segmentação, a unidade de segmentação realiza o processamento para converter o endereço lógico em endereço linear e, em seguida, o endereço linear é entregue à unidade de paginação, a unidade de paginação converte o endereço físico da memória de acordo com o mapeamento da tabela de página, que pode ocorrer falha de página interrompida.
A interrupção de falha de página (Falha de página) ocorre apenas quando o software tenta acessar um endereço virtual, após a página de segmento ser convertida em um endereço físico, é descoberto que a página não está na memória neste momento, então a cpu irá relatar uma interrupção e, em seguida, execute a correlação A transferência ou alocação de memória virtual pode ser interrompida diretamente se ocorrer uma exceção.
4. Memória física e fragmentação da memória
O mecanismo de gerenciamento de página de segmento mencionado anteriormente faz parte do espaço virtual, mas outra parte importante do gerenciamento de memória Linux é o gerenciamento de memória física, ou seja, como alocar e recuperar memória física, que envolve alguns algoritmos de alocação de memória e alocadores.
4.1 Alocador de memória física
Alocadores e algoritmos de alocação são como as finanças da empresa, e a memória é como os fundos da empresa. Como usar os fundos de maneira razoável é responsabilidade das finanças e como usar a memória física de maneira razoável é tarefa do alocador.
4.2 Classificação e Mecanismo de Fragmentação da Memória
Se não sabemos o que é fragmentação da memória, basta pensar no tempo fragmentado que costumamos dizer, ou seja, o tempo que fica ocioso mas não é utilizado, aliás, o mesmo vale para a memória.
Nem o tempo nem a memória podem ser usados com eficácia após serem fragmentados, portanto, o gerenciamento razoável e a redução da fragmentação são cruciais para nós, que também é o foco dos algoritmos e alocadores de alocação de memória física.
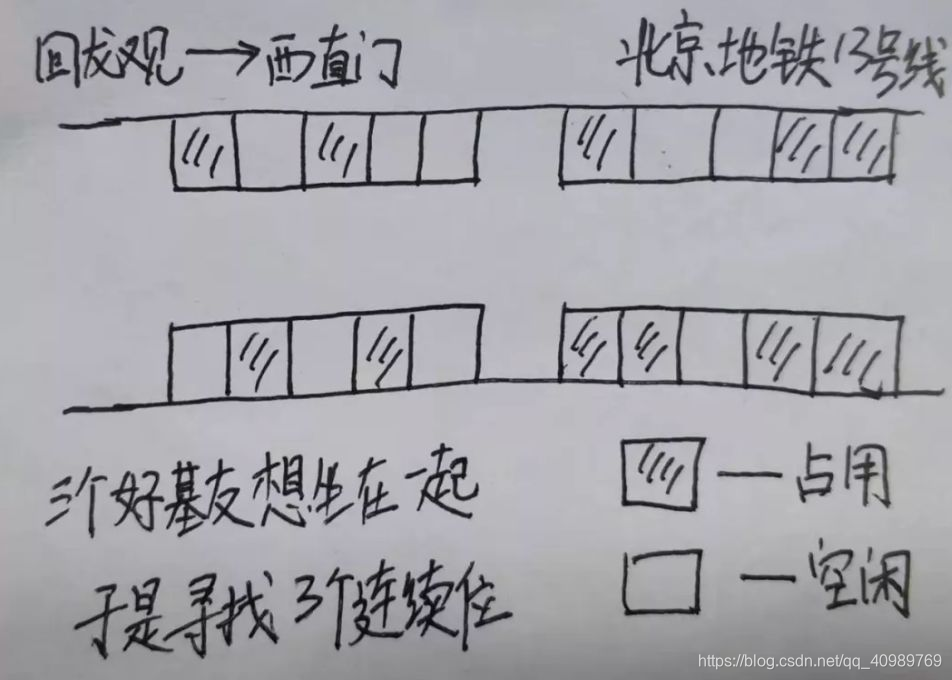
De acordo com a localização e a causa dos fragmentos, os fragmentos de memória são divididos em fragmentos externos e fragmentos internos. Vejamos a exibição visual desses dois fragmentos:
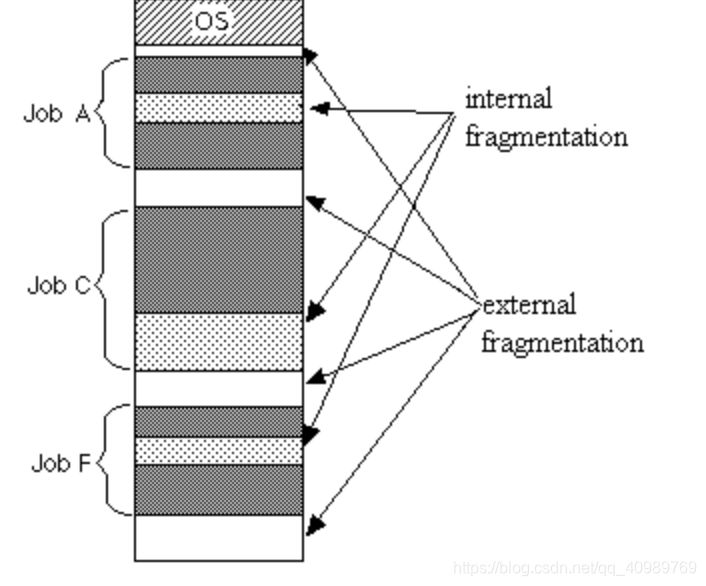
Pode-se ver na figura que os fragmentos externos são espaço de memória não alocado entre os processos. O aparecimento de fragmentos externos está diretamente relacionado à alocação e liberação frequente de memória pelos processos. Isso é bem compreendido. Simule a liberação de processos que alocam diferentes espaços em momentos diferentes. Você pode ver a geração de detritos externos.
A fragmentação interna se deve principalmente à granularidade do alocador e a algumas restrições de endereço que fazem com que a memória alocada real seja maior do que a memória necessária, portanto, haverá falhas de memória no processo.
Embora o endereço virtual torne a memória usada pelo processo discreta na memória física, muitas vezes o processo requer uma certa quantidade de memória física contínua. Se houver um grande número de fragmentos, isso causará o problema de não ser possível iniciar o processo , conforme mostrado no Processo 7, que requer uma memória física contínua. Mas não pode ser atribuído:
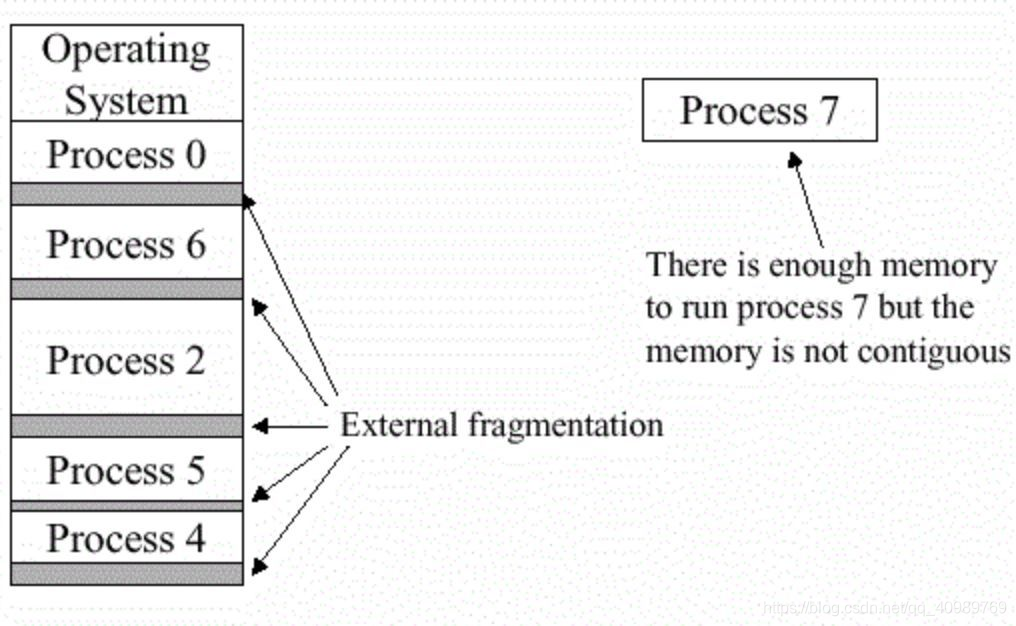
Se ainda não estiver claro, imagine a cena em que você costuma ir ao refeitório ou pegar um ônibus com três ou cinco amigos. Não há três assentos consecutivos em todo o carro, então você deve sentar-se separadamente ou ficar em pé:
5. Princípios básicos do algoritmo do sistema camarada
5.1 Alguns conhecimentos preparatórios
Frame de página física O
Linux divide a memória física em páginas. O tamanho das páginas de memória pode ser diferente em diferentes softwares e hardwares. O kernel do Linux está definido para 4 KB e alguns kernels podem ser maiores ou menores, mas diferentes naquele momento O tamanho é sempre considerado na prática, assim como o pão, lá são grandes e pequenos, não uniformes.
Estrutura de registro de quadro de página
No kernel, a fim de estabelecer o monitoramento do uso da página de memória física, haverá uma estrutura de dados, como uma página de estrutura para registrar o endereço de localização / uso da página, etc., que é equivalente a uma conta do gerenciamento do kernel das páginas de memória.
Alocação atrasada e alocação em tempo real Os
sistemas Linux são divididos em modo kernel e modo de usuário.O aplicativo do modo kernel para memória é imediatamente satisfeito e a solicitação deve ser razoável. No entanto, a solicitação de memória do modo de usuário é sempre atrasada o máximo possível para alocar memória física, de modo que o processo do modo de usuário primeiro obtém uma área de memória virtual e obtém um pedaço de memória física real por meio de uma exceção de falha de página em tempo de execução. get quando executamos malloc é apenas A memória virtual nada mais é que a memória física real, que também é causada por este motivo.
5.2 Introdução ao sistema buddy A
primeira vez que ouço esse nome de algoritmo, estou curioso para saber por que ele é chamado de sistema buddy. Vamos revelar o segredo juntos.
Qual é o problema que o
sistema buddy resolve? O algoritmo do sistema buddy é uma ferramenta poderosa para resolver fragmentos externos. Em termos simples, ele estabelece um conjunto de mecanismos de gerenciamento para alocar e recuperar recursos com eficiência para cenários em que um grupo de quadros de páginas contínuos de diferentes tamanhos são frequentemente solicitados e liberados. Reduza a fragmentação externa.
A
primeira ideia de resolver fragmentos externos : mapear os fragmentos externos existentes para o espaço linear contínuo por meio de novas tecnologias para mapear essas memórias livres não contíguas para o espaço linear contínuo. Na verdade, é equivalente a uma solução de governança em vez de reduzir a geração de externos fragmentos. Mas esse esquema é ineficaz quando a memória física contígua é realmente necessária.
A segunda ideia: registrar essas pequenas memórias descontínuas livres, se houver uma nova necessidade de alocação, procurar memória livre adequada para alocar, de modo a evitar alocar memória em uma nova área, há uma variação A sensação de usar o lixo como um tesouro é na verdade muito familiar. Quando você quiser comer um pacote de biscoitos, sua mãe certamente dirá para comer a metade restante dos biscoitos primeiro, em vez de abrir um novo.
Com base em algumas outras considerações, o kernel Linux escolheu a segunda ideia para resolver a fragmentação externa.
A definição do bloco de memória
do parceiro No sistema do parceiro, duas áreas de memória com o mesmo tamanho e endereços físicos contínuos são chamadas de parceiros. Os requisitos para endereços contínuos são, na verdade, mais rigorosos, mas essa também é a chave do algoritmo, porque essas duas memórias as áreas podem ser mescladas em uma área maior.
A ideia central do
sistema buddy O sistema buddy gerencia quadros de página físicos contínuos de tamanhos diferentes, aloca a partir do tamanho de quadro de página mais próximo ao aplicar e desmonta o resto e mescla a memória com a parceria em um quadro de página grande.
5.3 O processo básico do
sistema buddy O sistema buddy mantém um total de 11 listas de blocos vinculados com n = 0 ~ 10, e cada lista de bloco contém 2 ^ n páginas físicas consecutivas. Quando n = 10, 1024 páginas de 4 KB correspondem a blocos de memória física contíguos de 4 MB, onde n é chamado de ordem. No sistema parceiro, a ordem é de 0 a 10, ou seja, o menor é de 4 MB e o maior bloco de memória é de 4 MB. Esses blocos físicos do mesmo tamanho formam uma lista duplamente vinculada para gerenciamento. A figura mostra as duas listas duplamente vinculadas com pedido = 0 e pedido = 2:
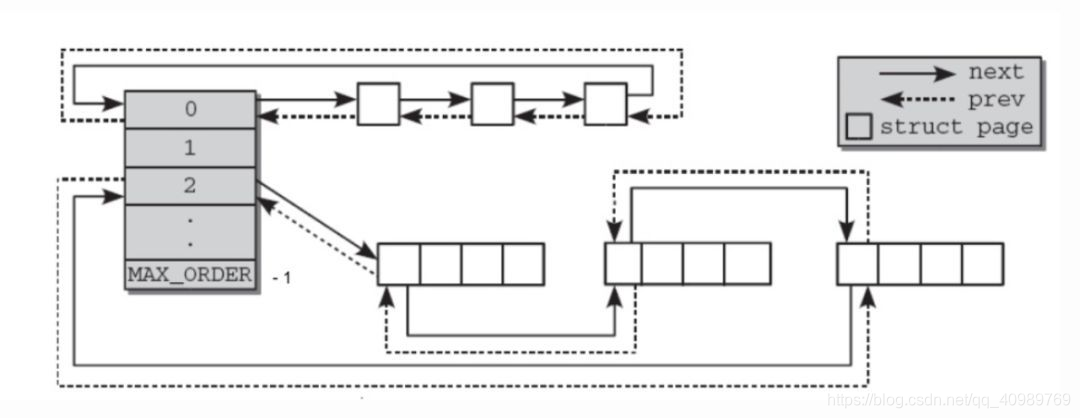
Processo de aplicação de memória: Supondo que um bloco de quadro de página seja solicitado, o algoritmo do sistema parceiro primeiro verifica se há um bloco livre a ser alocado na lista vinculada com ordem = 0. Caso contrário, pesquise o próximo bloco maior, encontre um bloco livre na lista vinculada de pedido = 1, divida 2 quadros de página se houver na lista vinculada e aloque 1 quadro de página e adicione 1 quadro de página ao pedido = 0 Em a lista vinculada. Se nenhum bloco livre for encontrado na lista vinculada de ordem = 1, ele continuará a procurar por uma ordem maior. Se for encontrado para divisão, se não houver nenhum bloco livre na lista vinculada de ordem = 10, o algoritmo irá relatar um erro.
O processo de fusão de memória: O processo de fusão de memória é a personificação do bloco parceiro no algoritmo de parceiro. O algoritmo funde dois blocos de memória com o mesmo tamanho A e seus endereços físicos em um único bloco com tamanho 2A. O algoritmo buddy é mesclado iterativamente de baixo para cima. Na verdade, esse processo é muito semelhante ao processo de mesclagem sst no leveldb. A diferença é que o algoritmo buddy exige que os blocos de memória sejam contínuos. Esse processo também reflete a simpatia do parceiro sistema para grandes blocos de memória.
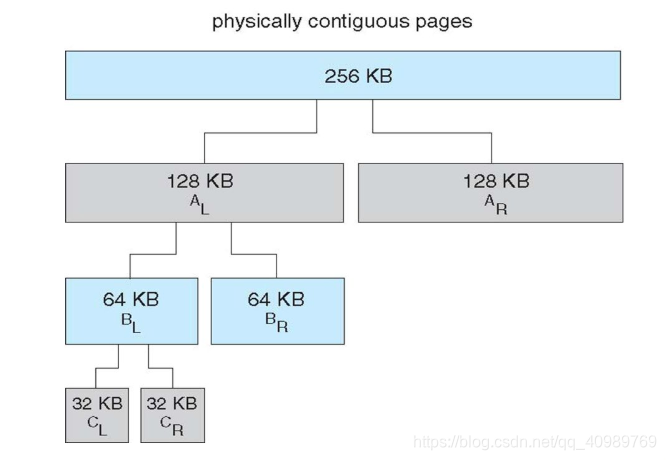
5.4 Vantagens e desvantagens do
sistema buddy O algoritmo do sistema buddy resolve o problema de fragmentação externa e é mais amigável para a alocação de grandes blocos de memória. A memória de baixa granulação pode causar fragmentação interna, mas o sistema buddy é muito restrito na definição do bloco de parceiro. O processo de mesclar blocos de parceiro envolve muitas operações de lista vinculada. Para alguns aplicativos frequentes, eles podem ser divididos logo após a fusão, o que é inútil, por isso o sistema de parceiro ainda tem alguns problemas.
6. Distribuidor de placas
Desde a introdução do sistema buddy, pode-se saber que a menor unidade de alocação é um quadro de página de 4 KB, o que ainda é muito desperdiçador para algumas memórias solicitadas com frequência, tão pequenas quanto dezenas de bytes, portanto, precisamos de um alocador mais refinado É o distribuidor de placas.
O distribuidor de placas não é separado do sistema parceiro, mas é construído no sistema parceiro. Pode ser considerado um distribuidor secundário do sistema parceiro e está mais próximo do lado do usuário. No entanto, porque o distribuidor de placas está mais próximo do usuário , está na estrutura A realização é mais complicada do que o sistema do parceiro, este artigo pode apenas resumir brevemente.
Pessoalmente sinto que os destaques do alocador de laje incluem: a menor granularidade é o retorno de objetos e memória preguiçosamente.
A base do alocador slab usado pelo Linux é um algoritmo introduzido pela primeira vez por Jeff Bonwick para o sistema operacional SunOS. O alocador de Jeff gira em torno do cache de objetos. No kernel, uma grande quantidade de memória é alocada para um conjunto limitado de objetos (como descritores de arquivo e outras estruturas comuns). Jeff descobriu que o tempo necessário para inicializar objetos comuns no kernel excede o tempo necessário para alocá-los e liberá-los. Portanto, sua conclusão é que a memória não deve ser liberada de volta para um pool de memória global, mas deve ser mantida em um estado de inicialização específico.
de "Análise do alocador de blocos do linux"
A base teórica para o uso de objetos pela laje como a menor unidade é que o tempo para inicializar uma estrutura pode exceder o tempo de alocação e liberação.
O alocador de placas pode ser considerado um mecanismo de pré-alocação de memória, assim como um supermercado coloca os itens comumente usados em um local que é mais fácil para todos encontrarem, e esses objetos podem ser alocados imediatamente quando estiverem prontos para aplicação com antecedência.

slabs_full: as lajes na lista vinculada foram totalmente alocadas
slabs_partial: as lajes na lista vinculada foram alocadas
slabs_empty: as lajes na lista vinculada são livres, ou seja, os
objetos que podem ser reciclados são alocados e liberados da placa , each kmem_cache A lista de lajes está sujeita à migração de estado, mas a parte recuperada da laje não será devolvida ao sistema do parceiro imediatamente, e o objeto lançado mais recentemente será atribuído primeiro durante a alocação. O objetivo é usar o princípio de localidade do cache de cpu, que pode ser visto Os detalhes do alocador de blocos são suficientes, mas para implementar essa lógica complexa, manter várias filas é mais complicado do que o sistema parceiro.
O conteúdo da placa é mais complicado do que amigo, portanto, este artigo não será expandido.
7. Conclusão
Na verdade, existem muitas coisas sobre o gerenciamento de memória do Linux. Este artigo é apenas uma breve discussão. Para uma compreensão mais aprofundada, você ainda precisa ler os livros do kernel. Não há atalhos