distinção de conceito
O que é um banco de dados relacional
Um banco de dados relacional é um sistema de gerenciamento de banco de dados (DBMS) baseado em um modelo relacional. Em um banco de dados relacional, os dados são armazenados na forma de uma tabela. A tabela é composta de linhas e colunas. As linhas representam registros de dados e as colunas representam campos de dados. Cada tabela possui um identificador exclusivo, chamado de chave primária, que identifica exclusivamente cada linha da tabela.
Os principais conceitos de um banco de dados relacional incluem:
-
Tabela: Os dados são organizados na forma de tabelas, cada tabela possui um nome e um conjunto de colunas que definem o tipo de dados. As tabelas representam entidades (como pessoas, coisas, eventos, etc.) e os relacionamentos entre as entidades.
-
Linha: Cada linha da tabela representa um registro de dados e contém valores de dados de diferentes campos.
-
Coluna: Cada coluna na tabela representa um campo de dados e define o tipo e o formato dos dados.
-
Chave Primária: Cada tabela possui uma chave primária que identifica exclusivamente cada linha da tabela. A chave primária garante a exclusividade e a integridade dos dados.
-
Chave estrangeira (Foreign Key): As chaves estrangeiras são usadas para estabelecer associações entre tabelas diferentes e representam o relacionamento entre as tabelas. Chaves estrangeiras geralmente se referem a chaves primárias de outras tabelas.
-
SQL (Structured Query Language): bancos de dados relacionais usam SQL para realizar operações de consulta, inserção, atualização e exclusão de dados. SQL é uma linguagem de consulta padronizada para interagir com bancos de dados relacionais.
Alguns exemplos comuns de bancos de dados relacionais incluem:
- MySQL
- PostgreSQLName
- banco de dados Oracle
- Servidor Microsoft SQL
- SQLite
Bancos de dados relacionais são conhecidos por seus modelos de dados estruturados e ampla gama de aplicações. Eles são adequados para aplicativos que exigem relacionamentos de dados complexos e consultas ricas, como aplicativos corporativos, sistemas financeiros, gerenciamento de recursos humanos, etc. Porém, com o crescimento contínuo dos dados e a diversificação dos cenários de aplicação, muitos outros tipos de bancos de dados surgiram, como os bancos de dados NoSQL, para processamento de dados não estruturados e semiestruturados, sendo que o MongoDB citado neste artigo é não relacional. também é o protagonista do artigo.
O que é um banco de dados não relacional
Bancos de dados não relacionais (NoSQL, Not Only SQL) são um tipo de sistema de gerenciamento de banco de dados (DBMS), que usa modelos de dados e mecanismos de armazenamento diferentes dos bancos de dados relacionais tradicionais. Os bancos de dados não relacionais são adequados para processar dados em grande escala, altamente distribuídos, não estruturados ou semiestruturados e cenários de aplicativos que exigem maior escalabilidade e flexibilidade.
Os principais recursos dos bancos de dados não relacionais incluem:
-
Diversidade do modelo de dados: bancos de dados não relacionais suportam vários modelos de dados, como pares chave-valor, documentos, famílias de colunas, gráficos, etc., para acomodar diferentes tipos de dados.
-
Arquitetura distribuída: muitos bancos de dados não relacionais têm uma arquitetura distribuída que escala horizontalmente, distribuindo dados por vários servidores para alta disponibilidade e melhor desempenho.
-
Modo flexível: Bancos de dados não relacionais geralmente não requerem definições rígidas de estrutura de tabela, permitindo que os campos sejam adicionados e modificados dinamicamente durante o armazenamento de dados para se adaptar às mudanças nos modos de dados.
-
Alta escalabilidade: devido à sua natureza distribuída, os bancos de dados não relacionais podem ser facilmente dimensionados para lidar com grandes quantidades de dados e altas solicitações simultâneas.
-
Adapte-se a big data: bancos de dados não relacionais geralmente são usados para armazenar e processar dados em larga escala, como dados de mídia social, arquivos de log, dados de sensores, etc.
Tipos de banco de dados não relacionais comuns incluem:
-
Armazenamentos de valor-chave: os dados são armazenados na forma de pares de valor-chave, adequados para operações de leitura e gravação de alta velocidade, como Redis e Amazon DynamoDB.
-
Armazenamento de documentos: os dados são armazenados em documentos semelhantes ao formato JSON ou XML, adequados para dados semiestruturados, como MongoDB, Couchbase.
-
Armazenamentos de famílias de colunas: os dados são armazenados na forma de famílias de colunas, adequadas para dados distribuídos em grande escala, como Apache Cassandra e HBase.
-
Bancos de dados de gráficos: usados para armazenar e consultar dados de gráficos, adequados para relacionamentos de dados complexos, como Neo4j, Amazon Neptune.
-
Bancos de dados de séries temporais: dedicados ao armazenamento de dados de séries temporais, como dados de sensores, dados de log, etc., como InfluxDB e OpenTSDB.
-
Mecanismos de pesquisa: usados para pesquisa de texto completo e análise de dados, como Elasticsearch e Solr.
Bancos de dados não relacionais estão se tornando cada vez mais importantes no desenvolvimento de aplicativos modernos, especialmente nas áreas de big data, computação em nuvem e sistemas distribuídos. A razão pela qual apresentamos o banco de dados MongoDB desta vez também é porque os requisitos de desenvolvimento do sistema exigem registros de bate-papo para be Para salvar, tendo em vista a grande quantidade de dados, a arquitetura MongoDB é considerada.
Introdução ao personagem principal MongoDB
O MongoDB é um sistema de gerenciamento de banco de dados não relacional (NoSQL DBMS) de código aberto, orientado a documentos, conhecido por sua flexibilidade, escalabilidade e poderosos recursos de consulta. O MongoDB foi projetado para atender às necessidades de dados massivos, alta disponibilidade e modelos de dados complexos em aplicativos modernos. A seguir estão alguns recursos e conceitos importantes do MongoDB:
-
Banco de dados de documentos: MongoDB usa documentos para representar dados. Documentos são semelhantes a estruturas de dados formatadas em JSON e podem conter vários tipos de dados, como strings, números, datas, arrays e documentos aninhados.
-
Orientado a documentos: o MongoDB é um banco de dados orientado a documentos e cada documento possui um identificador exclusivo (geralmente chamado _id), que é usado para identificar exclusivamente o documento.
-
Alta escalabilidade: o MongoDB oferece suporte à expansão horizontal e pode distribuir dados para vários servidores por meio de sharding para obter maior capacidade de armazenamento e desempenho.
-
Modo dinâmico: o MongoDB não requer definição rígida de estrutura de tabela e os documentos podem adicionar e modificar campos livremente para se adaptar às mudanças no modo de dados.
-
Linguagem de consulta poderosa: o MongoDB oferece suporte a uma linguagem de consulta avançada, que pode executar operações de consulta complexas, incluindo filtragem, classificação, projeção, agregação, etc.
-
Suporte de índice: MongoDB suporta vários tipos de índices, incluindo índices de campo único, índices compostos, índices de texto, índices geoespaciais, etc., para acelerar as operações de consulta.
-
Replicação e alta disponibilidade: MongoDB suporta replicação de dados e failover automático para garantir alta disponibilidade e redundância de dados.
-
Armazenamento de dados: o MongoDB armazena dados em coleções, cada uma contendo um conjunto de documentos. As coleções são semelhantes às tabelas em bancos de dados relacionais.
-
Cenários aplicáveis: MongoDB é adequado para cenários que requerem armazenamento e processamento de dados semiestruturados ou não estruturados, como big data, análise de dados em tempo real, sistemas de gerenciamento de conteúdo, registros de log e recomendações personalizadas do usuário.
Introdução à instalação do MongoDB
Instale o MongoDB no CentOS
Aqui estão as etapas detalhadas para instalar o MongoDB no CentOS:
- Atualize o sistema:
abra um terminal e faça login como root ou como usuário com privilégios sudo, primeiro atualize os pacotes do sistema para garantir que o sistema esteja atualizado:
sudo yum update
- Adicionando o repositório MongoDB:
MongoDB fornece um repositório YUM oficial que pode ser adicionado ao seu sistema usando as seguintes etapas:
sudo vi /etc/yum.repos.d/mongodb-org.repo
No editor, adicione o seguinte (salve e saia do editor):
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
- Instalar MongoDB:
Instale o pacote MongoDB com o seguinte comando:
sudo yum install -y mongodb-org
- Inicie o serviço MongoDB:
Após a conclusão da instalação, você pode iniciar o serviço MongoDB e configurá-lo para iniciar automaticamente:
sudo systemctl start mongod
sudo systemctl enable mongod
- Verifique se o MongoDB foi iniciado corretamente:
Execute o seguinte comando para verificar se o MongoDB foi iniciado com sucesso:
sudo systemctl status mongod
Você deve ver o status do serviço MongoDB como "ativo (em execução)".
- Conecte-se ao MongoDB Shell:
Para interagir com o banco de dados usando o MongoDB Shell, execute os seguintes comandos:
mongo
Isso se conectará ao shell do servidor MongoDB local.
docker instalar MongoDB
Como todos sabem meus hábitos, o método de instalação do docker é definitivamente indispensável. É
uma maneira conveniente de instalar o MongoDB e executá-lo em um contêiner do Docker. Vamos apresentar em detalhes como instalar e executar o MongoDB no Docker.
-
Instale o Docker :
Se você não tiver o Docker instalado, siga as etapas abaixo para instalar o Docker em seu sistema operacional:
- Para usuários do Linux, você pode escolher um método de instalação apropriado de acordo com sua distribuição, geralmente usando uma ferramenta de gerenciamento de pacotes (como
aptouyum) para instalar o Docker. - Para usuários do Windows, você pode baixar e executar o instalador no site oficial do Docker.
- Para usuários do macOS, você pode baixar e executar o instalador do Docker Desktop no site oficial do Docker.
- Para usuários do Linux, você pode escolher um método de instalação apropriado de acordo com sua distribuição, geralmente usando uma ferramenta de gerenciamento de pacotes (como
-
Puxe a imagem do MongoDB :
Abra um terminal (ou interface de linha de comando) e execute o seguinte comando para extrair a imagem oficial do MongoDB do Docker Hub:
docker pull mongo -
Execute o contêiner do MongoDB :
Use os comandos a seguir para criar e executar um contêiner do MongoDB. Isso criará um contêiner MongoDB chamado "my-mongodb" e o vinculará à porta 27017 na máquina host. Você mesmo pode ajustar o nome do contêiner e as ligações de porta conforme necessário.
docker run --name my-mongodb -p 27017:27017 -d mongoEste comando executará o contêiner do MongoDB no modo de segundo plano. Para parar o container, você pode usar
docker stopo comando:docker stop my-mongodbPara excluir um contêiner, você pode usar
docker rmo comando:docker rm my-mongodb -
Conecte-se ao contêiner do MongoDB :
Para se conectar ao shell Mongo de um contêiner MongoDB em execução, o seguinte comando pode ser usado:
docker exec -it my-mongodb mongoIsso entrará no shell do Mongo, onde os comandos do MongoDB podem ser executados.
Instale o MongoDB no sistema Win
Para instalar o MongoDB em um sistema Windows, siga estas etapas:
-
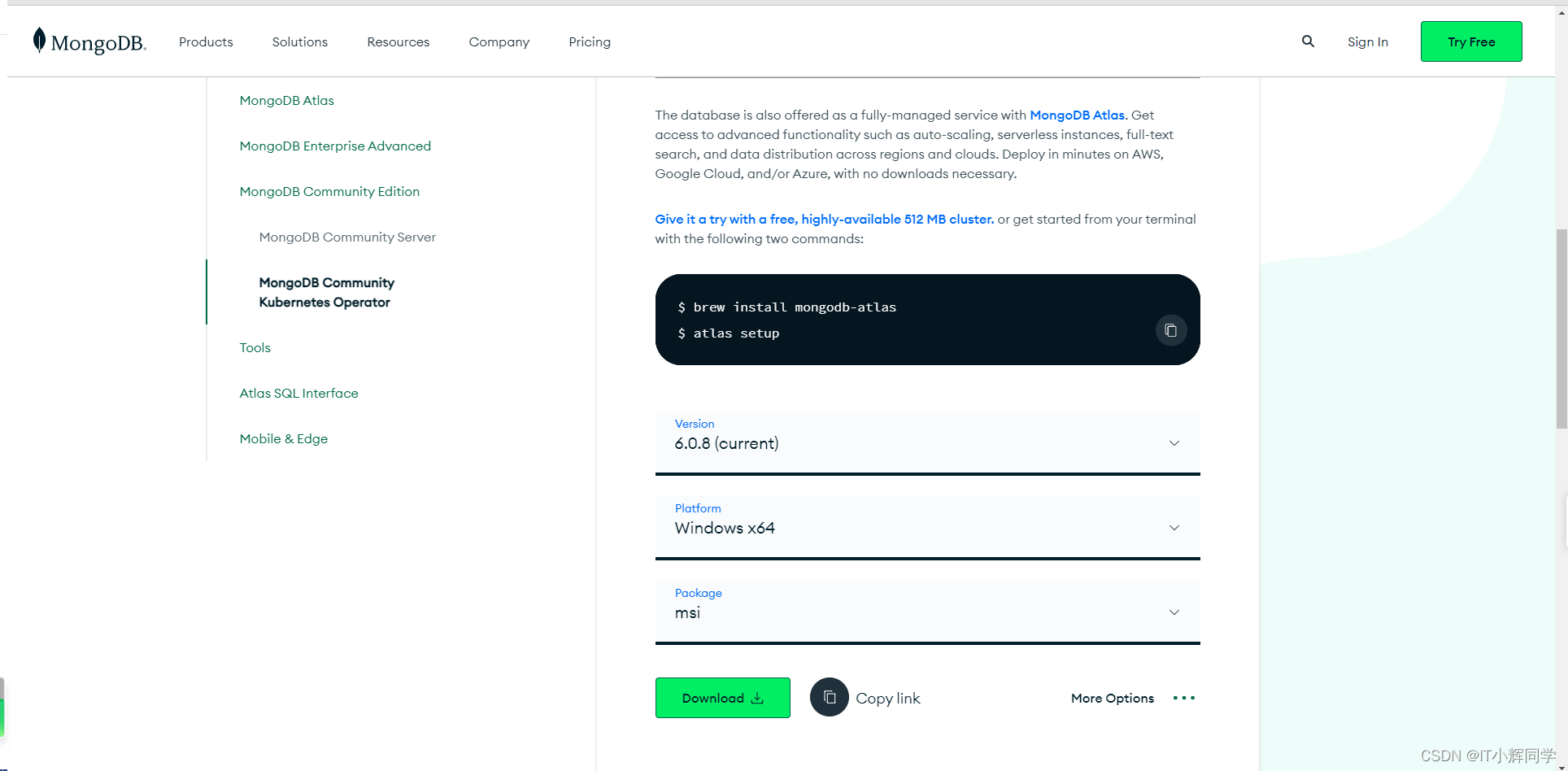
Baixe o pacote de instalação do MongoDB:
Acesse o site oficial do MongoDB (https://www.mongodb.com/try/download/community-kubernetes-operator) para baixar a versão mais recente do pacote de instalação do MongoDB. Certifique-se de escolher a versão que corresponde ao seu sistema operacional.
-
Instale o MongoDB:
Clique duas vezes no pacote de instalação baixado e siga as instruções do assistente de instalação para concluir o processo de instalação. Você pode escolher uma opção de instalação personalizada, mas para a maioria dos usuários, as opções padrão funcionarão bem. -
Configure a variável de ambiente do MongoDB:
adicione o caminho de instalação do MongoDB à variável de ambiente do sistema, para que você possa acessar o MongoDB por meio da linha de comando em qualquer diretório. Adicione o caminho de instalação (C:\Program Files\MongoDB\Server<número da versão>\bin por padrão) à variável Path nas variáveis de ambiente do sistema. -
Crie um diretório de dados:
crie um diretório de dados no local de sua escolha para armazenar arquivos de dados do MongoDB. Por exemplo, você pode criar uma pasta chamada db no diretório C:\data. -
Configure o serviço MongoDB:
Abra um prompt de comando (CMD) ou PowerShell e navegue até o diretório de instalação do MongoDB (por exemplo: C:\Program Files\MongoDB\Server<número da versão>\bin).Execute o seguinte comando para iniciar o servidor MongoDB:
mongod --dbpath <数据目录路径>Substitua
<数据目录路径>pelo caminho do diretório de dados que você criou na etapa 4. -
Conecte-se ao MongoDB:
Abra outro prompt de comando ou janela do PowerShell e navegue até o diretório onde o MongoDB está instalado (por exemplo: C:\Program Files\MongoDB\Server<número da versão>\bin).Execute o seguinte comando para se conectar ao MongoDB:
mongo
Observe que, se você não seguir as etapas acima, mas executar o exe diretamente no diretório de instalação

Então você precisa criar um diretório /data/db no caminho raiz do disco D, caso contrário, ele travará! ! !

O MongoDB não escreve variáveis de ambiente por padrão. Você precisa configurá-lo sozinho, então não vou repetir aqui! ! !
Introdução ao MongoDB
No MongoDB, o estabelecimento de coleções (semelhante às tabelas em bancos de dados relacionais) é dinâmico, portanto não há necessidade de definir explicitamente a estrutura da tabela como em bancos de dados relacionais. Basta inserir um documento (semelhante a um registro em um banco de dados relacional), e o MongoDB criará automaticamente a coleção e definirá os campos de acordo com a estrutura do documento. Execução do comando Podemos usar a ferramenta Navicat para conectar
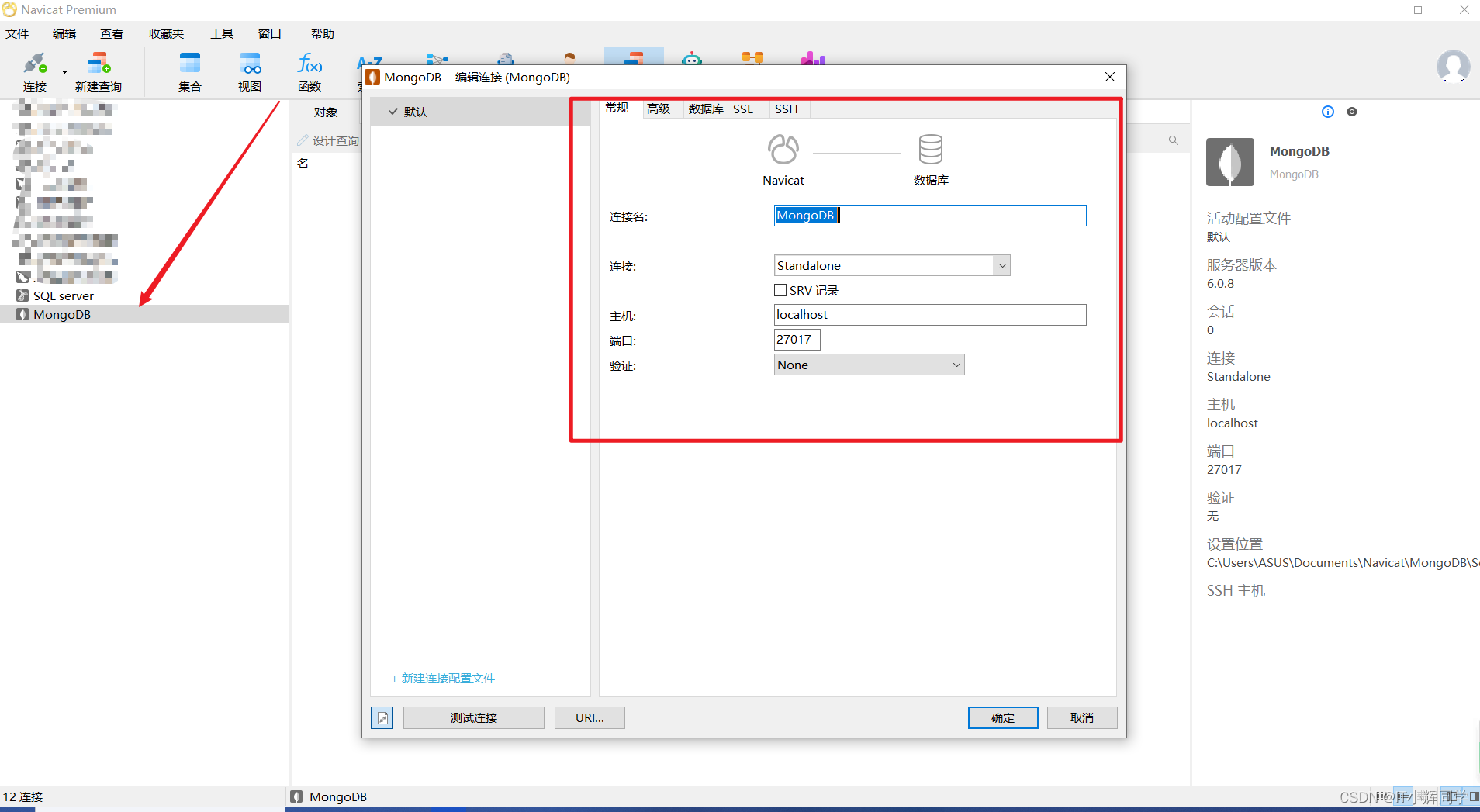
A seguir está a sintaxe e exemplos para criar coleções e inserir documentos no MongoDB:
fácil de usar
- Criar coleção e inserir documentos:
// 使用insertOne插入文档并创建集合
db.collectionName.insertOne({
field1: "value1", field2: "value2", ... })
Exemplo:
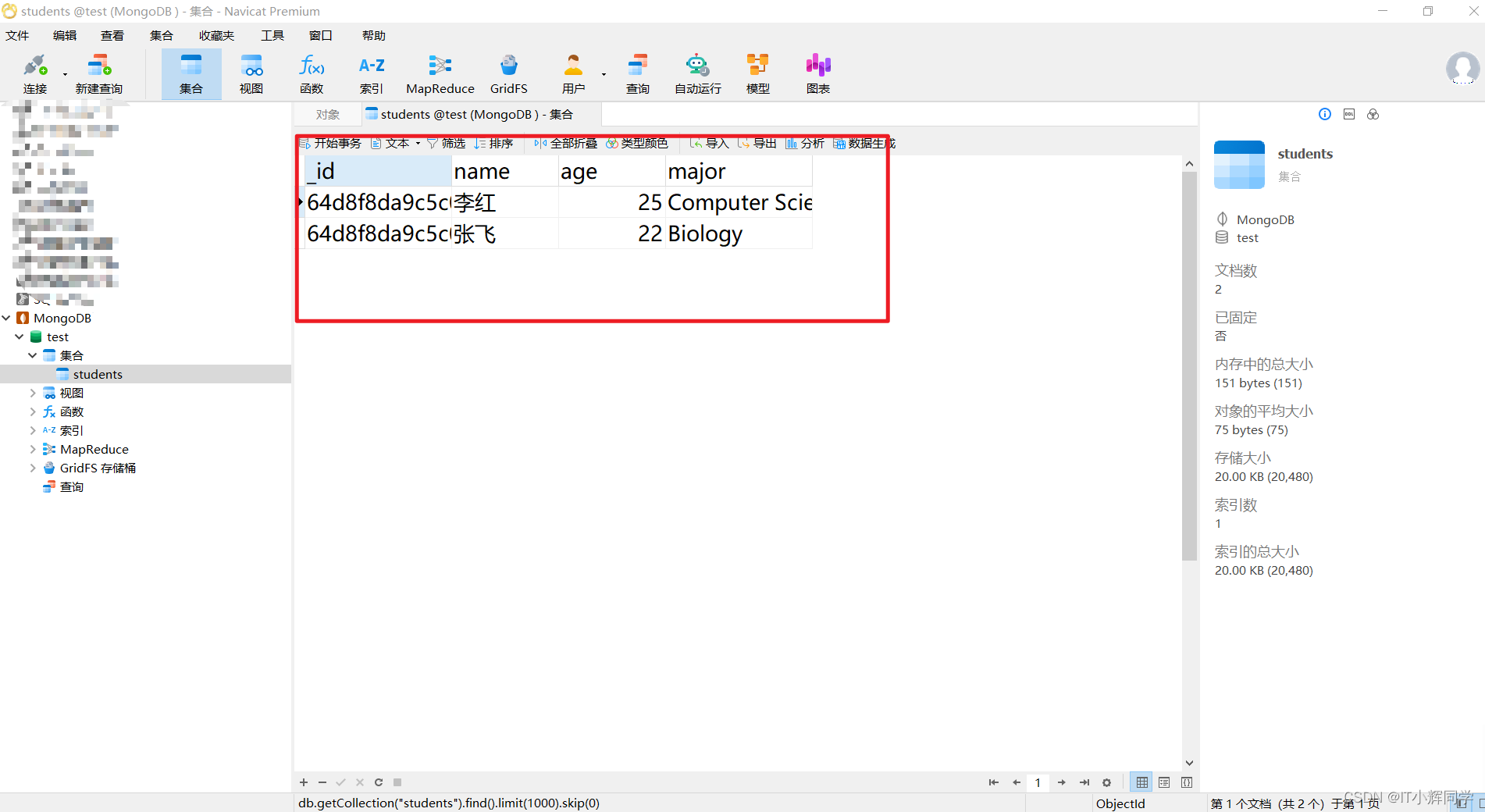
db.students.insertOne({
name: "李红", age: 25, major: "Computer Science" })
db.students.insertOne({
name: "张飞", age: 22, major: "Biology" })
- Consulta de documentos em uma coleção:
// 查询集合中的所有文档
db.collectionName.find()
// 查询特定条件的文档
db.collectionName.find({
field: "value" })
Exemplo:
// 查询所有学生
db.students.find()
// 查询年龄大于等于 25 岁的学生
db.students.find({
age: {
$gte: 25 } })
- Atualizar documentos:
// 使用updateOne更新单个文档
db.collectionName.updateOne({
condition }, {
$set: {
field: "new value" } })
// 使用updateMany更新多个文档
db.collectionName.updateMany({
condition }, {
$set: {
field: "new value" } })
Exemplo:
// 更新学生的专业
db.students.updateOne({
name: "张飞" }, {
$set: {
major: "Engineering" } })
- Excluir documento:
// 使用deleteOne删除单个文档
db.collectionName.deleteOne({
condition })
// 使用deleteMany删除多个文档
db.collectionName.deleteMany({
condition })
Exemplo:
// 删除专业为"Biology"的学生
db.students.deleteMany({
major: "Biology" })
Vamos dar outro exemplo, assumindo que estamos desenvolvendo uma plataforma de blogging simples, podemos usar o MongoDB para armazenar postagens e comentários de blog. Neste exemplo de um negócio complexo, abordaremos o seguinte:
- Crie coleções e insira documentos
- Consultar e filtrar dados
- atualizar documento
- usar índice
1. Crie uma coleção e insira documentos:
Primeiro, criamos uma coleção para armazenar postagens de blog, cada postagem contendo título, conteúdo e data de publicação:
// 创建博客集合并插入帖子文档
db.blogPosts.insertOne({
title: "MongoDB的相关介绍 ——IT小辉同学",
content: "MongoDB 是一个非关系型数据库",
publishDate: new Date("2023-08-01"),
comments: []
})
2. Consultar e filtrar dados:
Agora, consultamos as postagens na coleção do blog e filtramos as postagens com uma data de publicação dentro de um determinado intervalo:
// 查询发布日期在特定范围内的帖子
db.blogPosts.find({
publishDate: {
$gte: new Date("2023-08-01"), $lt: new Date("2023-08-10") }
})
3. Atualize a documentação:
Suponha que uma postagem tenha recebido um novo comentário, podemos adicionar o comentário à matriz de comentários da postagem:
// 更新帖子,添加新评论
db.blogPosts.updateOne(
{
title: "MongoDB的相关介绍,很有意思奥 ——IT小辉同学" },
{
$push: {
comments: {
author: "User123",
text: "MongoDB,我们一起学习!",
timestamp: new Date()
}
}
}
)
4. Use o índice:
Para melhorar o desempenho da consulta, podemos criar índices para acelerar determinadas operações de consulta. Por exemplo, para agilizar as consultas que buscam posts por título, podemos criar um índice no campo título:
// 创建标题字段的索引
db.blogPosts.createIndex({
title: "text" })
Este é um exemplo simplificado que mostra como lidar com o complexo cenário de negócios de postagens de blog e comentários no MongoDB. Nos negócios reais, mais situações podem precisar ser tratadas, como autenticação do usuário, verificação de dados, relacionamento com o usuário, etc. A flexibilidade e a funcionalidade do MongoDB podem se adaptar a várias necessidades comerciais complexas.
Observe que a sintaxe do MongoDB usa JSON, que é o que geralmente chamamos de objetos em Java, portanto, dados e consultas estão na forma de JSON.
gramática complexa
Quando você precisa executar operações de adição, exclusão, modificação e consulta mais complexas, o MongoDB fornece funções avançadas de consulta, atualização e agregação para atender às suas necessidades. Aqui está um exemplo mais complexo, abrangendo operações de consulta, atualização e agregação de várias condições:
1. Consulta multicondição:
Suponha que você queira consultar postagens cuja data de publicação esteja dentro de um intervalo específico e cujo título contenha uma palavra-chave específica:
db.blogPosts.find({
publishDate: {
$gte: new Date("2023-08-01"), $lt: new Date("2023-08-10") },
title: {
$regex: "MongoDB" }
})
2. Atualização multicondição:
Atualize os comentários de uma postagem, substituindo o texto em todos os comentários do autor especificado pelo novo texto:
db.blogPosts.updateMany(
{
"comments.author": "User123" },
{
$set: {
"comments.$[].text": "新文本" } }
)
3. Use agregação:
As operações agregadas permitem que você faça manipulação e transformação de dados. Suponha que você queira contar o número de comentários por postagem e classificar por número decrescente de comentários:
db.blogPosts.aggregate([
{
$project: {
title: 1,
numberOfComments: {
$size: "$comments" }
}
},
{
$sort: {
numberOfComments: -1 }
}
])
O código acima usa um pipeline de agregação, primeiro $projectextraindo o título e o número de comentários para cada postagem e, em seguida, $sortclassificando por número decrescente de comentários.
4. Para excluir vários documentos:
Suponha que você deseja excluir todas as postagens com comentários abaixo de um valor especificado:
db.blogPosts.deleteMany({
comments: {
$size: {
$lt: 5 } }
})
Isso excluirá todas as postagens com menos de 5 comentários.