Diretório do artigo
- Question1: Fale sobre o registro de serviços e a descoberta de serviços?
- Resposta 1:
- Question2: E quanto a "API Gateway / API Gateway"?
- Answer2:
- Question3: Apresente brevemente o centro de configuração da arquitetura de microsserviço?
- Resposta3:
- Question4: Descreva brevemente o agendamento de eventos (kafka)?
- Resposta4:
- Question5: Uma breve introdução ao rastreamento de serviço (iniciador-detetive)?
- Resposta5:
- Question6: Qual é o fusível de serviço (Hystrix)?
- Resposta6:
Os blogs orientados para entrevistas são apresentados no estilo Q / A.
Question1: Fale sobre o registro de serviços e a descoberta de serviços?
Resposta 1:
O registro de serviço é manter um registro, que gerencia todos os endereços de serviço no sistema. Quando o novo serviço é iniciado, ele confessa suas informações de endereço ao registro. A parte confiável do serviço solicita diretamente o endereço do provedor de serviços no registro. Existem muitas ferramentas para registro de serviços, como ZooKeeper, Consul, Etcd e eureka da Netflix. Existem duas formas de registro de serviço: registro de cliente e registro de terceiros.
Registro de cliente (tratador)
O registro de cliente é o próprio serviço responsável pelo registro e cancelamento. Quando o serviço iniciar, registre-se no centro de registro e cancele seu registro quando o serviço ficar offline. Durante esse período, você ainda precisa manter um batimento cardíaco no centro de registro. O batimento cardíaco não precisa ser realizado pelo cliente, mas também pode ser tratado pelo centro de registro (esse processo é chamado de Tanhuo). A desvantagem desse método é que o trabalho de registro é associado ao serviço, e diferentes idiomas devem implementar um conjunto de lógica de registro.
O registro do cliente é mostrado abaixo:
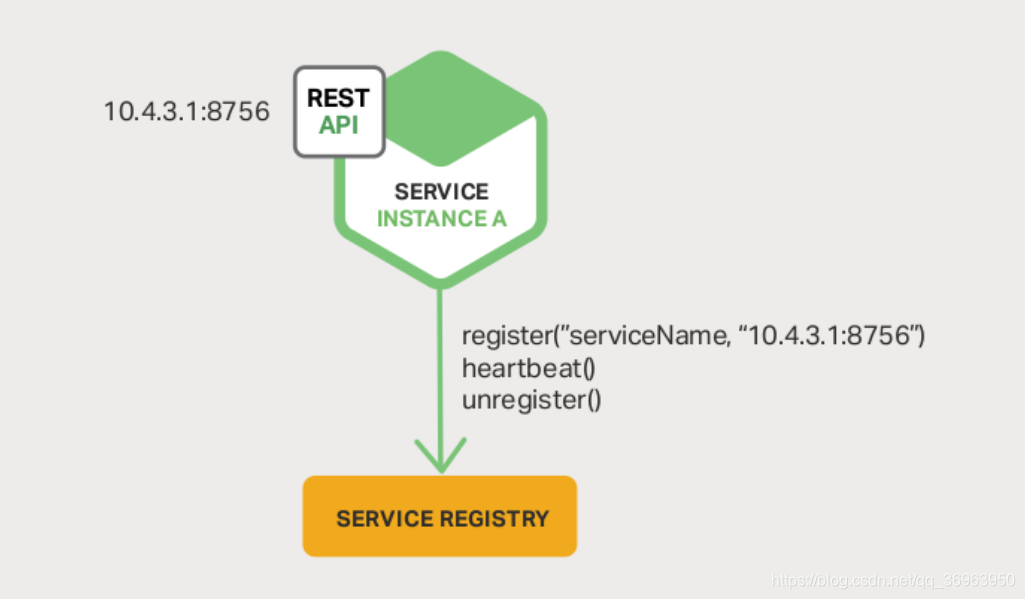
Para a explicação acima:
o serviço que precisa se registrar, Sevice, lida diretamente com o Service Register Service Register, existem três métodos entre os dois, incluindo register register (), heartbeat (), unregister / unregister (), aqui, O serviço de registro precisa ser associado ao centro de registro, que não atende ao conceito de design de baixo acoplamento e depende do registro de terceiros (registro de serviço independente).
Registro de terceiros (Registrador de serviço independente)
Um Registrador de serviço independente é responsável pelo registro e cancelamento. Quando o serviço é iniciado, o Registrador é notificado de alguma forma e o Registrador é responsável por iniciar o trabalho de registro no Registro. Ao mesmo tempo, o centro de registro deve manter a pulsação com o serviço.Quando o serviço estiver indisponível, o serviço será cancelado no centro de registro. A desvantagem desse método é que o Registrador deve ser um sistema altamente disponível; caso contrário, o trabalho de registro não poderá progredir.
O registro de terceiros é mostrado abaixo:
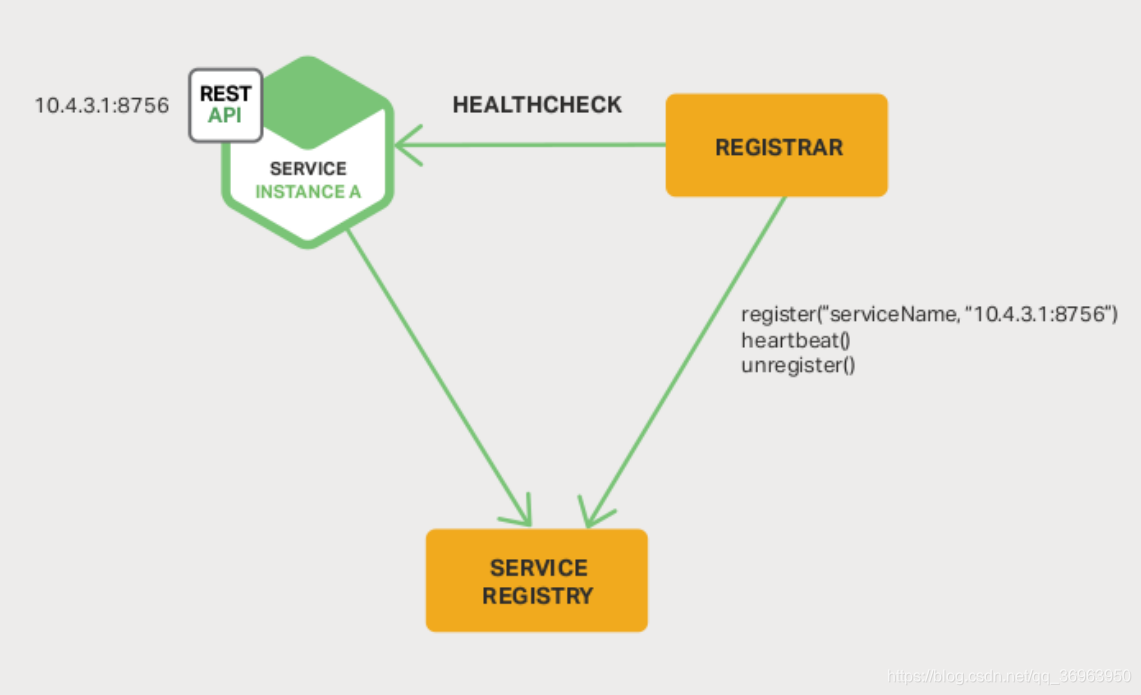
Para a explicação da figura acima:
o serviço que precisa ser registrado, Sevice, interage com o Registrador de serviço independente de terceiros. Quando o serviço é iniciado, o Registrador é notificado de uma certa maneira. Durante esse período, o Registrador envia uma verificação de pulsação para o Serviço de serviço em um horário fixo.
Dessa maneira, o serviço Serviço pode seguir sua própria lógica comercial, sem registro adicional, cancelamento adicional, centro de registro do serviço de notificação de pulsação em tempo real.
O registrador de serviço independente interage diretamente com o registro de serviço Service Register.Existem três métodos entre os dois, incluindo register register (), heartbeat () e unregister / unregister (). Quando o serviço é iniciado, o Registrador é notificado e o Registrador registra o serviço no centro de registro de serviços; depois que o serviço é iniciado, o Registrador executa uma verificação de pulsação no serviço em intervalos. Se o serviço sobreviver, ele chama a pulsação () para informar o centro de registro de serviços. Ligue para cancelar registro () para cancelar o serviço no centro de registro de serviços.
Resumo: O registro de terceiros usa um serviço independente, o Registrador, para separar o serviço de registro do centro de registro, o que está alinhado com o conceito de design de baixo acoplamento.Claro, esse método requer um sistema de Registrador altamente disponível adicional comparado ao registro do cliente.
Descoberta do cliente A descoberta do
cliente significa que o cliente é responsável por consultar os endereços de serviço disponíveis e o balanceamento de carga. Este método é o mais conveniente e direto, e também é conveniente para o balanceamento de carga. Além disso, uma vez que um serviço é considerado indisponível, ele é imediatamente alterado para outro, o que é muito simples. A desvantagem também é o trabalho repetido em vários idiomas, cada idioma implementa a mesma lógica.
A descoberta do cliente é mostrada abaixo:
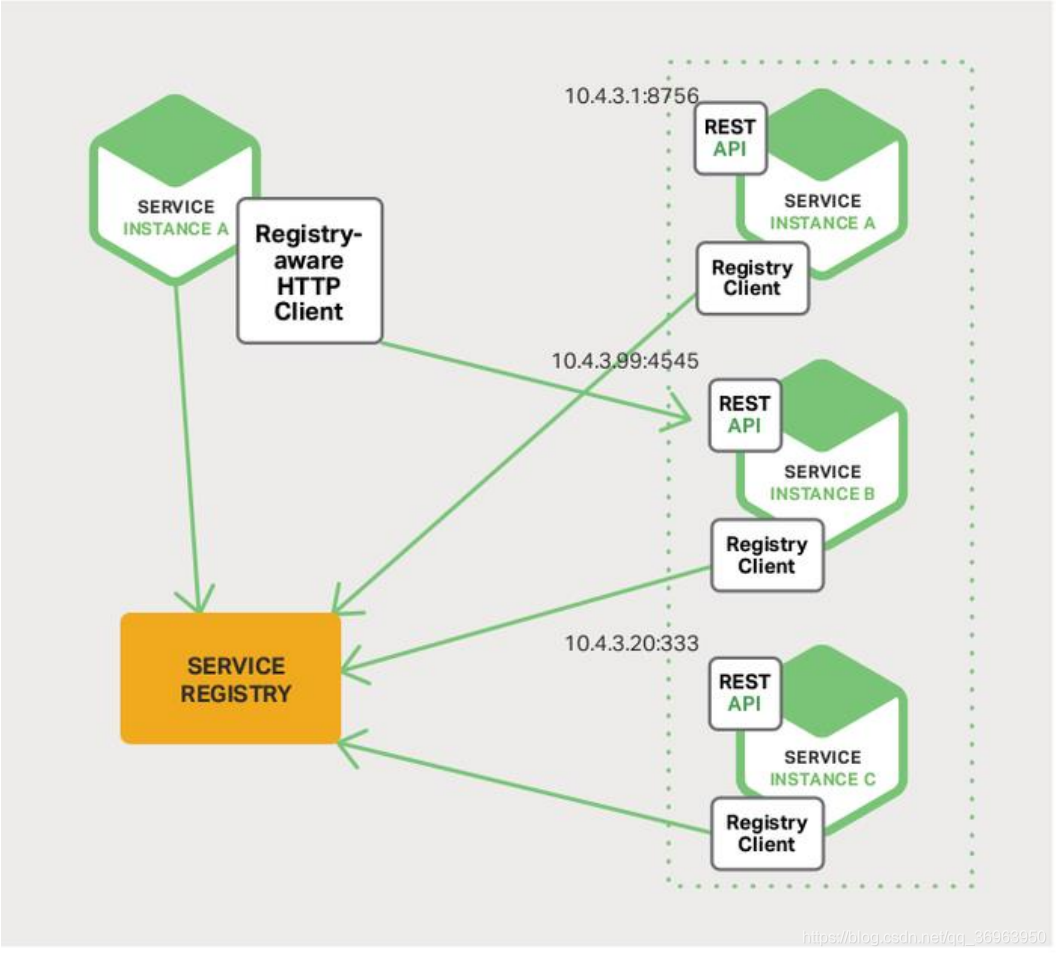
Para a explicação da figura acima: O
serviço em execução Sevice atua como um cliente cliente, usa diretamente a solicitação http para lidar com o servidor e consulta diretamente o endereço de serviço disponível, usado para realizar o trabalho de balanceamento de carga. O design é simples, mas o serviço ao cliente e o servidor são acoplados, o que não atende ao conceito de design de baixo acoplamento e depende do registro do servidor.
Descoberta do servidor A descoberta do
servidor requer serviços adicionais do roteador. As solicitações são enviadas primeiro ao roteador e, em seguida, o roteador é responsável por consultar os serviços e balancear a carga. Embora esse método não tenha as deficiências descobertas pelo cliente, sua falha é garantir a alta disponibilidade do roteador.
A descoberta do servidor é mostrada abaixo:
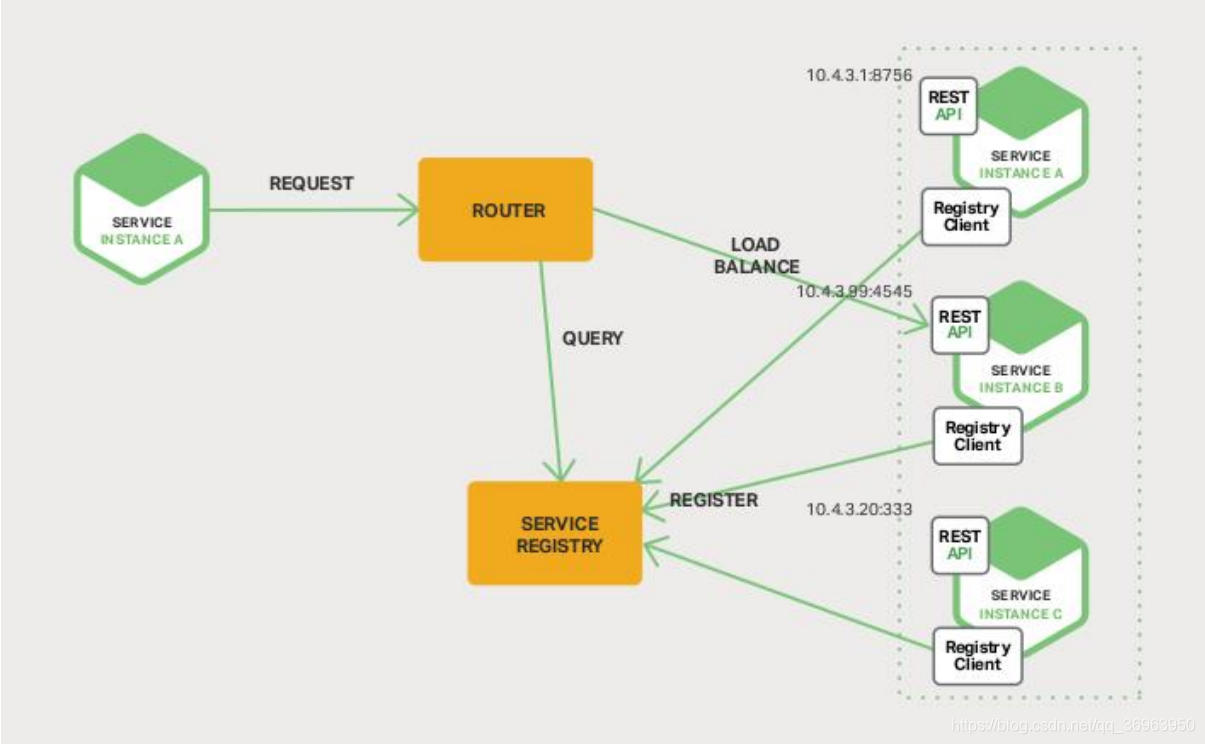
Para a explicação da figura acima: o
serviço em execução Sevice atua como um cliente cliente e se comunica com o roteador através do uso de solicitações de solicitação. O roteador é responsável por consultar serviços e balanceamento de carga. O serviço de serviço não pergunta mais sobre serviços de consulta e balanceamento de carga.
Resumo: O registro do servidor, a consulta do roteador em vez do servidor de consulta do cliente reduz a carga no serviço do cliente; é claro, esse método requer um sistema de roteador adicional e altamente disponível em comparação à descoberta do cliente.
Question2: E quanto a "API Gateway / API Gateway"?
Answer2:
O API Gateway é um servidor e também pode ser considerado o único nó que entra no sistema. Isso é semelhante ao padrão Fachada no padrão de design orientado a objetos. O API Gateway encapsula a arquitetura interna do sistema e fornece APIs para vários clientes. Também pode ter outras funções, como autorização, monitoramento, balanceamento de carga, armazenamento em cache, compartilhamento e gerenciamento de solicitações e processamento de resposta estática. A figura a seguir mostra um API Gateway que se adapta à arquitetura atual.
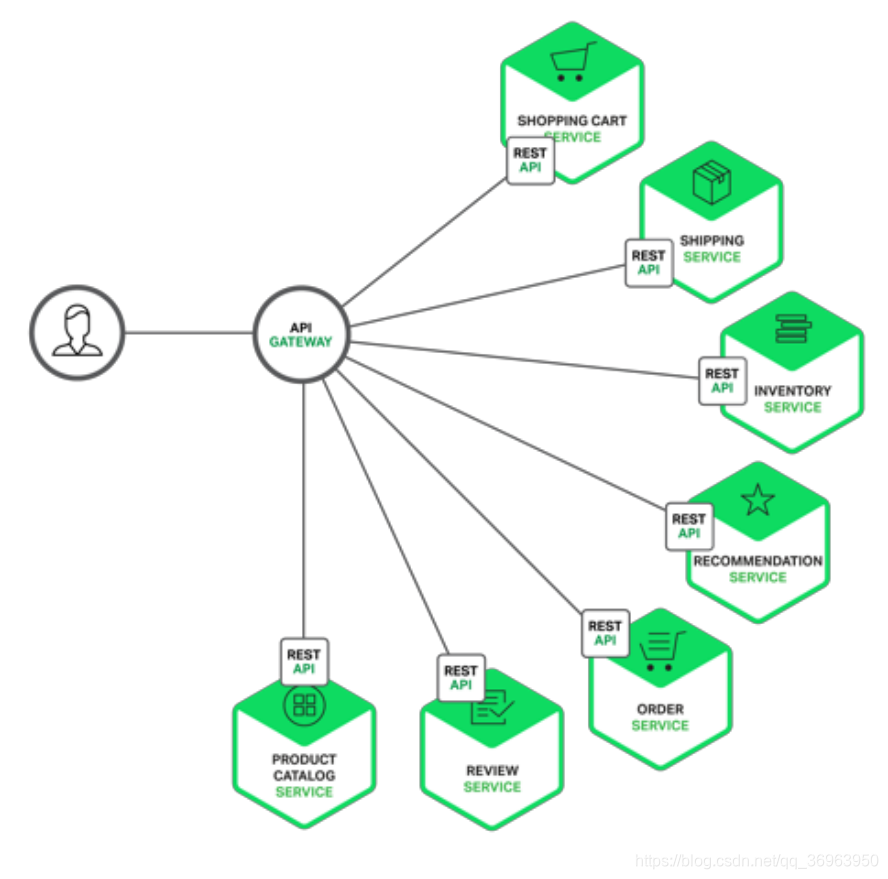
A figura acima mostra que o gateway da API deve monitorar quase todos os outros módulos de negócios, serviço de carrinho de compras, serviço de compras de serviço, serviço de lista de inventário de serviço de inventário, serviço de recomendação de serviço de recomendação, serviço de recomendação de serviço de ordem, serviço de pedido de serviço de ordem, serviço de revisão de serviço de revisão, catálogo de produtos serviço tipo de produto serviço.
O API Gateway é responsável pelo encaminhamento de solicitação, síntese e conversão de protocolo. Todas as solicitações do cliente devem primeiro passar pelo API Gateway e, em seguida, rotear essas solicitações para os microsserviços correspondentes. O API Gateway costuma chamar vários microsserviços para processar uma solicitação e agregar os resultados de vários serviços. Ele pode converter entre protocolos da Web e protocolos não compatíveis com a Web usados internamente, como o protocolo HTTP e o protocolo WebSocket.
Encaminhamento de solicitação O encaminhamento de
serviço é principalmente para encaminhar a carga da solicitação do cliente para instalar microsserviços em diferentes serviços.
Mesclagem de respostas Mescla
o trabalho que precisa chamar várias interfaces de serviço nos negócios em uma única chamada para fornecer serviços unificados ao mundo externo.
Conversão de protocolo O
foco é oferecer suporte à conversão de protocolo entre SOAP, JMS e Rest.
A conversão de dados
se concentra no suporte aos recursos de conversão de formato de mensagem entre XML e Json (opcional).
Certificação de segurança
- Controle de acesso do cliente baseado em token e estratégia de segurança
- Dados de transmissão e criptografia de mensagens, descriptografia para o servidor, você precisa ter um pacote de agente SDK separado no cliente
- Criptografia de transmissão baseada em Https, suporte a certificado digital de cliente e servidor
- Autenticação de segurança de serviço com base no OAuth2.0 (código de autorização, cliente, modo de senha etc.)
Question3: Apresente brevemente o centro de configuração da arquitetura de microsserviço?
Resposta3:
O centro de configuração é geralmente usado como a configuração de parâmetros do sistema e precisa atender aos seguintes requisitos: aquisição eficiente, reconhecimento em tempo real e acesso distribuído.
Exemplo:
O diagrama da arquitetura implementado pelo centro de configuração do zookeeper é mostrado abaixo: O método de carregamento de dados na memória é usado para resolver o problema da aquisição eficiente, e a percepção em tempo real é realizada usando o mecanismo de monitoramento de nós do zookeeper.
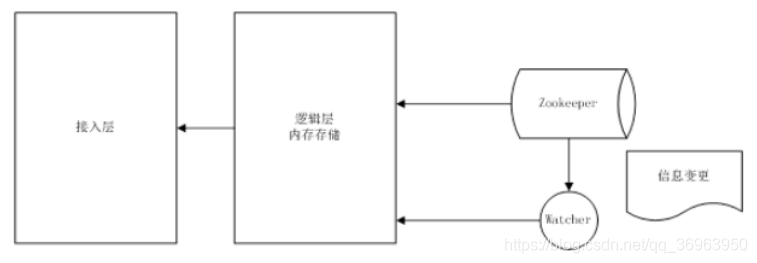
A figura acima mostra que o tratador do centro de configuração observará quaisquer alterações nas informações pelo observador observador e notificará a camada de lógica de negócios e, em seguida, a camada de acesso.
Classificação de dados do centro de configuração
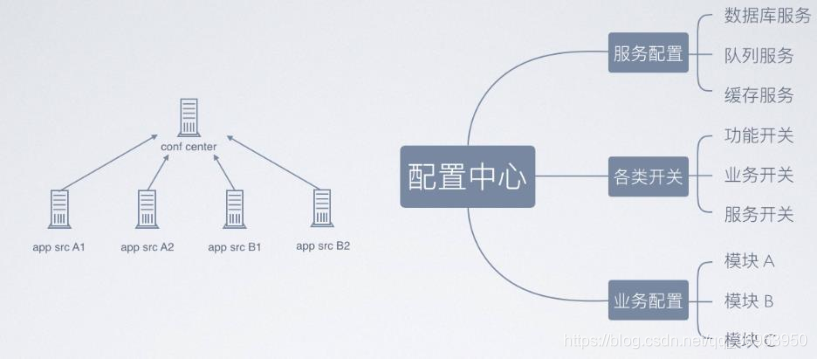
A figura acima mostra que o centro de configuração (centro de conf., Centro de configuração de nome completo) inclui configuração de serviço, vários comutadores e configuração comercial.
A configuração de serviço inclui configuração de serviço de banco de dados, configuração de serviço de fila, configuração de serviço de cache, etc.;
vários tipos de comutadores incluem vários comutadores funcionais, vários tipos de comutadores de negócios e vários tipos de comutadores de serviço;
configuração de negócios conforme mostrado acima, incluindo o módulo A application src A (app src A1 + app src A2), módulo B aplicativo src B (app src B1 + app src B2) etc.
Question4: Descreva brevemente o agendamento de eventos (kafka)?
Resposta4:
Planejamento unificado de serviços e eventos de mensagens, kafka, activemq, etc. comumente usados
Question5: Uma breve introdução ao rastreamento de serviço (iniciador-detetive)?
Resposta5:
À medida que o número de microsserviços continua a crescer, é necessário rastrear a propagação de uma solicitação de um microsserviço para o próximo microsserviço.O SpringCloud Sleuth resolve o problema.Introduz um ID exclusivo no log para garantir a consistência entre as chamadas de microsserviço Sexo, para que você possa acompanhar como uma solicitação é passada de um microsserviço para o próximo.
- Para obter o rastreamento de solicitações, quando a solicitação é enviada para o terminal de entrada do sistema distribuído, apenas a estrutura de rastreamento de serviço precisa criar um identificador de rastreamento exclusivo para a solicitação, e a estrutura sempre passa o identificador exclusivo ao circular no sistema distribuído. Até retornar ao solicitante, esse identificador exclusivo é o ID de rastreamento mencionado anteriormente. Através do registro do Trace ID, podemos correlacionar todos os logs do processo de solicitação.
- Para contar o atraso de tempo de cada unidade de processamento, quando a solicitação atinge cada componente de serviço ou quando a lógica de processamento atinge um determinado estado, seu início, processo específico e final também são marcados por um identificador exclusivo. Esse identificador é mencionado em nosso artigo anterior. Para cada período, o ID do período deve ter dois nós: início e fim. Ao registrar o registro de horário do período inicial e do período final, o atraso de tempo do período pode ser contado. Além do registro do registro de data e hora, Também pode conter alguns outros metadados, como: nome do evento, informações de solicitação etc.
- No exemplo de início rápido, implementamos facilmente o acesso às informações de rastreamento no nível do log, graças à implementação do componente spring-cloud-starter-sleuth. No aplicativo Spring Boot, depois de introduzir a dependência spring-cloud-starter-sleuth no projeto, ele criará automaticamente um mecanismo de rastreamento para cada canal de comunicação do aplicativo atual, como:
(1) através de RabbitMQ, Kafka (ou outro Qualquer middleware de mensagem implementado por qualquer fichário do Spring Cloud Stream).
(2) A solicitação passada pelo agente Zuul.
(3) Solicitação iniciada pelo RestTemplate.
Question6: Qual é o fusível de serviço (Hystrix)?
Resposta6:
Geralmente, existem várias chamadas da camada de serviço na arquitetura do microsserviço.A falha do serviço básico pode levar a uma falha em cascata, que por sua vez faz com que todo o sistema fique indisponível.Este fenômeno é chamado de efeito avalanche de serviço. O efeito avalanche de serviço é um processo no qual o "consumidor de serviço" fica indisponível devido à indisponibilidade do "provedor de serviços" e aumenta gradualmente a indisponibilidade.
O princípio do fusível é muito simples, como um protetor de sobrecarga de energia. Ele pode conseguir uma falha rápida.Se detectar muitos erros semelhantes em um período de tempo, forçará suas chamadas múltiplas subsequentes a falhar rapidamente e não acessará mais o servidor remoto, impedindo o aplicativo de tentar continuamente executar operações que podem falhar. , Para que o aplicativo possa continuar executando sem aguardar a correção do erro ou perder tempo da CPU para aguardar um longo tempo limite. O fusível também pode permitir que o aplicativo diagnostique se o erro foi corrigido.Se tiver sido corrigido, o aplicativo tentará chamar a operação novamente.
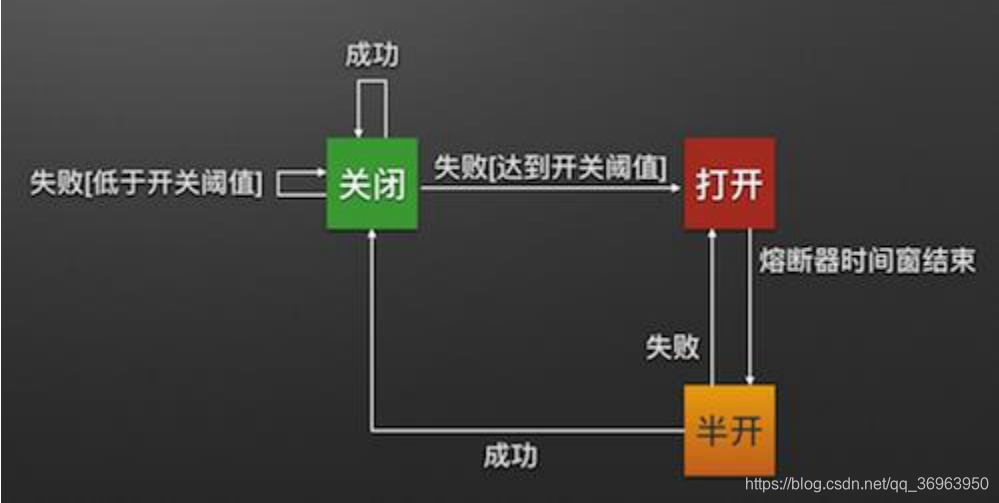
O disjuntor do mecanismo do disjuntor Hystrix
é bem compreendido. Quando o número de falhas no serviço de back-end da solicitação do Comando Hystrix exceder uma certa porcentagem (padrão 50%), o disjuntor passará para o estado aberto (Aberto). Nesse momento, todas as solicitações falharão diretamente e não serão enviadas. Para o serviço de back-end. Após o disjuntor permanecer no estado aberto por um período de tempo (padrão 5 segundos), ele alterna automaticamente para o estado semi-aberto (MEIA-OPEN). Nesse momento, o status de retorno da próxima solicitação será julgado. Se a solicitação for bem-sucedida, se o pedido for bem-sucedido, o disjuntor será desligado. Retorne ao estado fechado (FECHADO), caso contrário, volte ao estado aberto (OPEN) .O disjuntor da Hystrix é como um fusível em nosso circuito doméstico. Uma vez que o serviço de back-end não estiver disponível, o disjuntor cortará diretamente a cadeia de solicitações para evitar o envio de um grande número de solicitações inválidas Afeta a taxa de transferência do sistema e o disjuntor tem a capacidade de auto-detectar e recuperar.
