ドロップアウトのプロフィール
機械学習モデルでは1は、モデルのパラメータが多すぎる、少なすぎるトレーニングサンプルは、訓練されたモデルは、現象をオーバーフィットする傾向があります。特定の性能過剰適合:小さい損失関数にトレーニング・データ・モデル、予測
より高い精度が、しかし機能テストデータの損失に比較的大きく、低い予測精度です。
2.Dropout:とき前方に広がる、そのニューロンの値は動作を停止するために一定の確率pで活性化されていることをあなたはもっと一般化モデルを作ることができるので、それはいくつかの局所的な特徴にあまり依存しないので、。

ワークフローと使用.Dropout
我々は、図2に示すようなニューラルネットワークを訓練したいと:
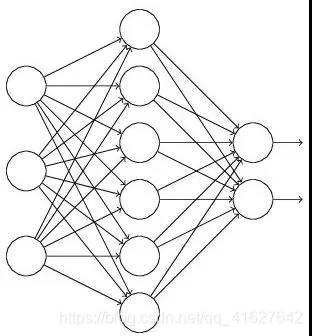
通常のプロセスである:xが入力され、出力はYであり、第一のネットワークを介して伝播する前に、我々のX、エラーバックプロパゲーションは、パラメータを更新する方法を決定することを可能にしますネットワーク学習。:ドロップアウト使用後、プロセスは次のようになる
(1)まず、ランダム(仮)削除ネットワーク半分隠れニューロンは、出力ニューロンは、一定の入力ままである(図中の破線3が削除部分の一時的なニューロンである。)
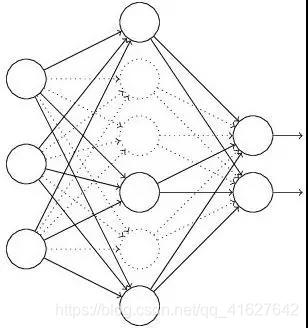
(2 )とネットワークを介して伝播する前に、入力xは、バックプロパゲーションネットワークを変更することにより、次いで、得られた損失を改変しました。このプロセスを実行した後トレーニングサンプル少数の後、ニューロンは(B、W)は、対応するメソッドのパラメータは、確率的勾配に従って減少更新を削除されません。
:その後、(3)とは、プロセス(1および2)を繰り返していき
ニューロンが削除され、復元(削除、完全なニューロンのために、しかし、ニューロンは更新されません削除されました)。
ニューラルネットワークを使用してドロップアウト
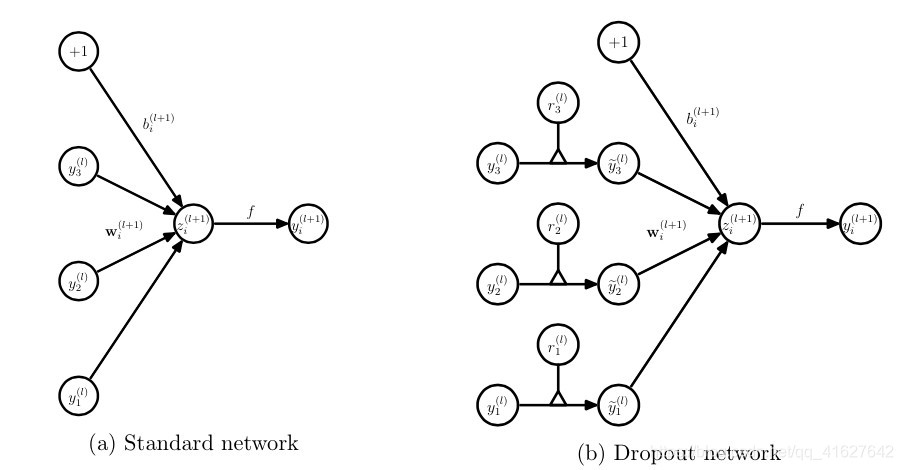
ノードロップアウトネットワーク式:
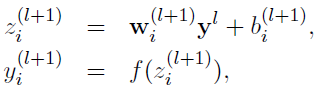
式のネットワークドロップアウト:
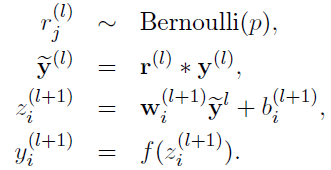
なぜドロップアウトフィット感を解消することができますか?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
