
時系列データベース (TSDB) の使用は、数十年にわたってさまざまな業界、特に金融および産業用制御システムで一般的に行われてきました。しかし、モノのインターネット (IoT) の出現により、時系列データ (略して時系列データ) の量が急増し、データベースのパフォーマンスとストレージのコストに対する要件が高まったため、専用のデータベースの必要性が高まっています。時系列データベース。
従来の時系列ソリューションの時代遅れのアーキテクチャとスケーラビリティの制限という問題に直面して、分散処理と水平拡張、およびクラウドまたはオンプレミスでの柔軟な展開を可能にする最新のアーキテクチャを採用した新世代の時系列データベースが登場しました。
2022 年末、別の大ヒット製品がオープンソースの時系列データベース トラックに加わり、わずか 1 年で 60 社以上の企業によってテストおよび作成され、国内外の主要な大学や企業から 70 名以上の貢献者が集まりました。 — openGemini,ファーウェイのオープンソース分散時系列データベースは、主に大規模な時系列データの保存と分析に焦点を当てており、技術革新を通じてビジネスシステムアーキテクチャを簡素化し、大規模な時系列データの保存コストを削減し、保存と分析の効率を向上させます。時系列データ。
今日は、openGemini コミュニティのリーダーである Xiang Yu を招待して、オープンソースのストーリーについて話してもらいました~
01 社内ニーズから出発し、徐々に自己研究へ
openGemini の研究開発はもともと Huawei 自身のニーズから生まれました。
2019年、ファーウェイクラウドの設立により、広州、上海、北京、貴州、香港にデータセンターが建設され、260以上のクラウドサービスが開始され、毎日平均数TBの監視指標データが収集されました。当初のビッグデータ ソリューションは徐々に圧倒されます。データ量が増えるとクエリ効率が低下し、データ ストレージのコストが上昇し続けるため、高性能でスケーラビリティの高い専用の時系列データベースが急務となっています。
当時、需要の発展に対応できる有用な時系列データベース製品はありませんでした。 InfluxDB はまだスタンドアロン バージョンであり、国内の Apache IoTDB と TDengine は運用要件を満たしているには程遠いです。したがって、ファーウェイは独自のデータベースを構築し、データ処理を最適化し、現時点での非常に重要なビジネス上の問題を解決することを決意しています。このような状況の中で、openGemini が誕生しました。
Xiang Yu 氏によると、テクノロジーの選択に関しては、最初はオープンソースの InfluxDB に基づいてクラスター変換を実行しました。しかし、指標の数の増加と収集頻度の増加に伴い、1 日あたりのデータ量の増加は数十テラバイトに達しています。この時点で、InfluxDB 自体のアーキテクチャの欠陥が明らかになり始め、システムのパフォーマンスと安定性に影響を及ぼしました。したがって、彼らはアーキテクチャを再構築することを選択し、openGemini カーネルの自己開発を開始しました。
02 唯一無二の個性、一流のパフォーマンス
openGemini は創業以来、ファーウェイ自身のビジネス ニーズと密接に結びついてきたため、すべての設計には実用的な考慮事項が満載されています。具体的には、openGemini は次の 9 つの主要な「特性」において他の時系列データベースと異なります。
パフォーマンスの利点: openGemini の差別化された競争力の中で、高いパフォーマンスが最も重要です。大規模なデータ シナリオにおいて、openGemini は、オープン ソースの InfluxDB と比較して、単純なクエリ シナリオを 2 倍以上、中程度のクエリ シナリオを 5 倍以上、複雑なクエリ シナリオを 10 倍以上改善します。他の同様のオープンソース製品と比較すると、openGemini には明らかなパフォーマンス上の利点もあります。
公式に発表されたスタンドアロンの書き込みパフォーマンスは次のとおりです (テスト ツールは TSBS です。関連するテストの詳細については、openGemini 公式 Web サイトのドキュメントを参照してください)。

公式に発表された、DevOps シナリオにおける単一マシンのクエリ パフォーマンスの比較 (平均レイテンシ、ミリ秒):

公式に発表された、IoT シナリオにおける単一マシンのクエリ パフォーマンスの比較 (平均遅延、ミリ秒):
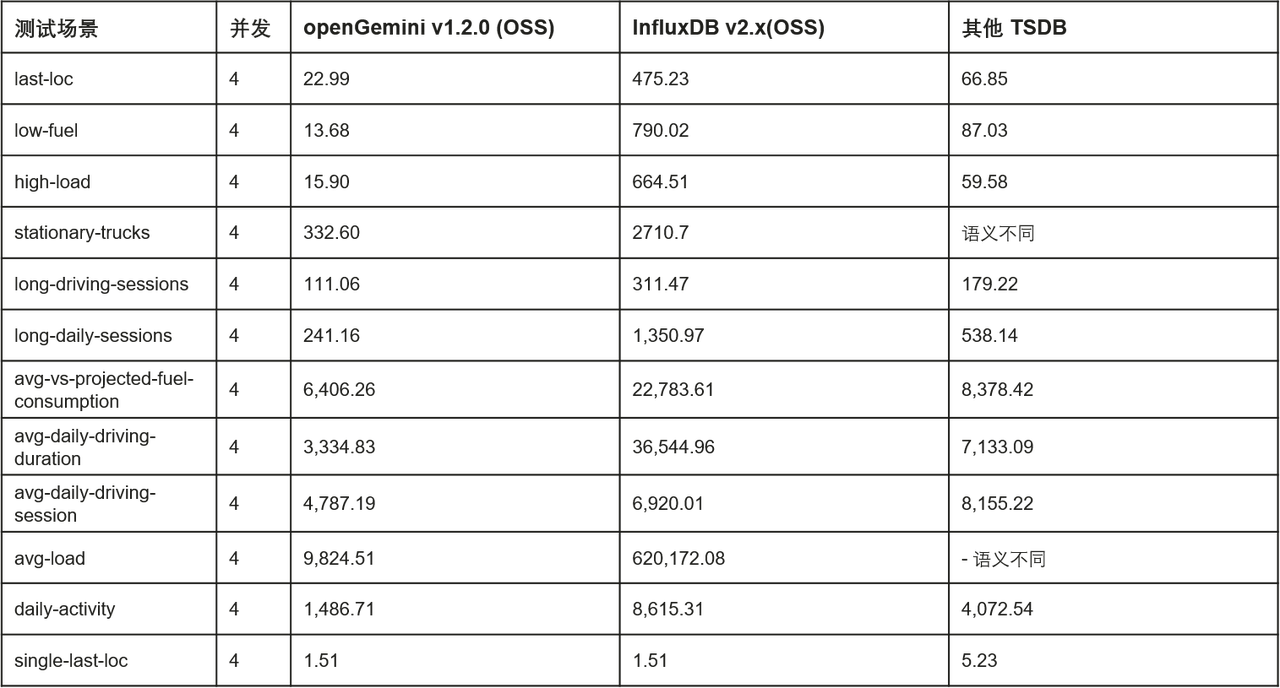
さらに、openGemini は、より差別化された競争力を構築するために、データ ストレージとデータ分析における一連の実用的な機能を開始しました。
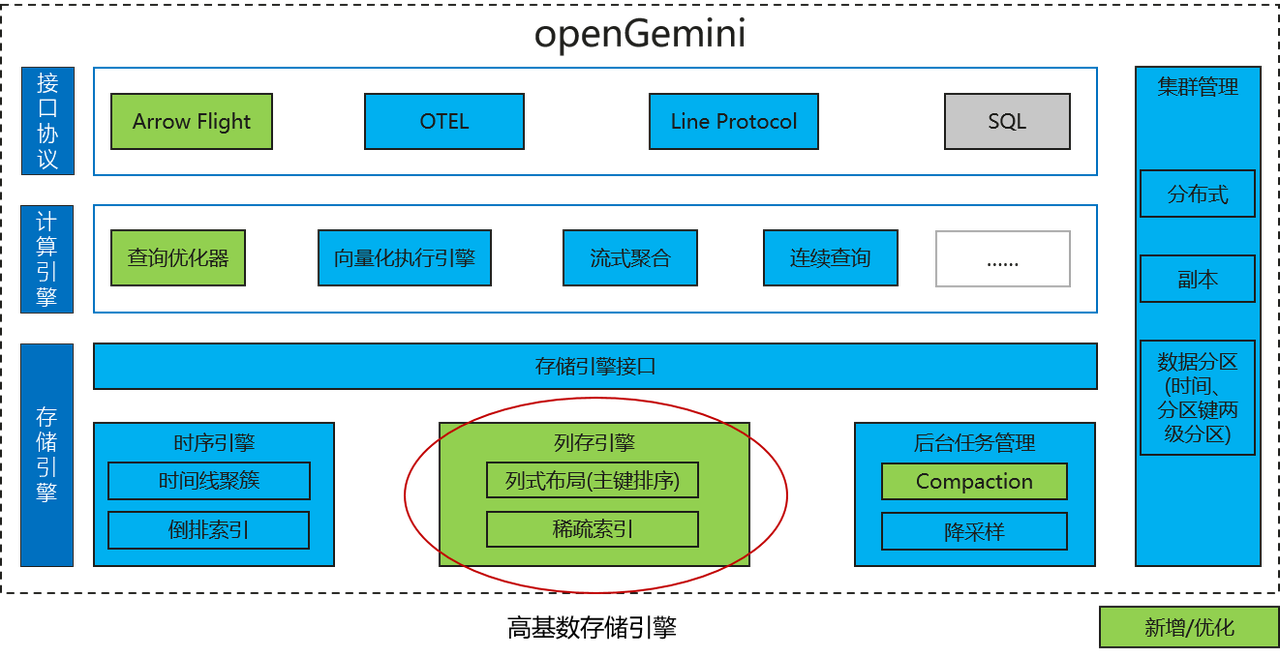
独自の分散アーキテクチャ: openGemini は、スタンドアロン クラスタと分散クラスタの 2 つのバージョンを提供します。分散クラスタは、コンピューティング エンジン、ストレージ エンジン、およびメタデータ管理を独立したコンポーネントに分割する MPP 大規模並列処理階層型アーキテクチャを採用しています。それぞれ -store と ts-meta です。さまざまなコンポーネントが独立した水平拡張をサポートしており、複雑なアプリケーションシナリオに柔軟に対応できます。
高カーディナリティ エンジン:高カーディナリティの問題 (次元の惨事とも呼ばれます) は、逆インデックスの拡張を引き起こし、過度のメモリ リソースの消費と読み取りおよび書き込みのパフォーマンスの低下を引き起こします。これは、時系列データベースの開発を長い間悩ませてきました。 openGemini 高基数エンジンは、時系列固有のスパース インデックスを構築することにより、この問題を完全に解決します。これは、ネットワーク監視、金融リスク管理、モノのインターネット、交通およびその他の分野での使用に非常に適しています。
テキスト検索:テキスト データは一般的なデータ タイプであり、openGemini はテキスト データのインデックスの作成をサポートし、動的学習単語セグメンテーション手法を採用し、正確なフレーズおよびファジー マッチングをサポートし、メモリ リソースの使用量が少なく、検索効率が高いという利点があります。
ストリーミング集約:ストリーミング集約は、データの書き込み中にデータをダウンサンプリングする事前集約手法であり、その目的は、計算のために大量の履歴データをディスクから読み取って重大な I/O 増幅を引き起こす従来のダウンサンプリング手法の問題を解決することです。問題。
マルチレベルダウンサンプリング:既存の履歴データの場合、従来のダウンサンプリング方法では履歴データの詳細が保持されます。一部のシナリオでは、履歴データの詳細は重要ではなく、データ特性のみを保持する必要があります。マルチレベル ダウンサンプリング機能を使用すると、履歴データの詳細の特徴を抽出し、履歴データの詳細を適切に置き換えることができるため、データの量をさらに削減できます。ストレージコストが 50% 削減されます。
異常の検出と予測:異常の検出と予測は現在、時系列データ分析の最も成熟したアプリケーションの 1 つであり、定量的トランザクション、ネットワーク セキュリティの検出、データ センター、産業機器、IT の日常メンテナンスなどのシナリオで広く使用されています。インフラストラクチャー。 openGemini は、13 の一般的な異常シナリオの検出アルゴリズムをカプセル化した異常検出ライブラリー openGemini-castor を提供します。これには、高速検出速度、高精度、ストリームとバッチの統合という利点があり、アプリケーションのデータ分析効率の向上に役立ちます。
ホットおよびコールド データ階層型ストレージ:オブジェクト ストレージへの履歴データの転送をサポートし、履歴データを永続的に保持する低コストの方法を可能にし、ビッグ データのオフライン分析もサポートします。 [この機能は下半期にリリースされる予定です]
データの信頼性: データの信頼性をさらに向上させるために、複数のコンピューティング コピーをサポートします。 [この機能は下半期にリリースされる予定です]

03 ユーザーエクスペリエンスを重視し、簡単に始められるようにする
openGemini は強力なパフォーマンスを備えているだけでなく、そのユニークな設計により、実際のアプリケーションで多くの快適な体験をもたらすことができます。
始めるにあたって、openGemini は InfluxDB v1 と完全な互換性があります。同時に、openGemini は InfluxDB と同じ Line Protocol を使用しており、データ モデリングはシンプルで理解しやすく、リレーショナル データベースの開発者にとっても使いやすいものです。最後に、openGemini は SQL に似たクエリ言語を使用します。これは追加の学習を必要とせず、簡単に開始できます。クラスターの展開については、コミュニティでは、多くの構成作業を節約するワンクリック展開ツール Gemix も提供しています。
オペレーティング システムに関しては、 openGemini は現在、主流の Linux システム (openEuler を含む)、Windows、および MacOS をサポートしており、アプリケーションの開発とデバッグがより便利になっています。プロセッサは、X86 アーキテクチャと ARM64 アーキテクチャの両方をサポートします。
クラウド ネイティブ性の観点から、openGemini は Dockerfile と Docker イメージを提供し、Docker、K8s、KubeEdge などのプラットフォームの展開をサポートします。コンテナーの再起動後に IP アドレスが変更されるため、openGemini では、コンテナーの再起動後もクラスター ノードが接続を維持できるようにするためのドメイン名機能を追加しました。コミュニティは、ユーザーがワンクリックでコンテナを展開できるようにするために、openGemini-operator プロジェクトも作成しました。 openGemini は Prometheus のリモート読み取りおよび書き込みをサポートしており、ストレージ容量不足の問題を解決する Prometheus のバックエンド ストレージとして使用できます。 [ちなみに、openGemini は現在開発中の PromQL も直接サポートします]
可観測性の観点から、コミュニティはノードとカーネルのインジケーターの収集に特化した ts-monitor コンポーネントを開発しました。これは 19 のサブカテゴリーと 260 以上の項目に分かれており、動作ステータスの包括的な監視を実現します。オープンジェミニの。たとえば、CPU とメモリの使用率、書き込み帯域幅、書き込みレイテンシ、書き込み同時実行性、QPS などの指標をビジュアル インターフェイスで一目で確認できるため、動作ステータス、データベース パフォーマンスのチューニング、問題の正確な位置を簡単に確認できます。いつでも。
04 社内実戦テスト後、オープンソースに還元
openGemini は時系列データベースとして、現在、IoT や運用保守監視などで最もよく使われており、大量のデータを処理するという点で、通常のデータベースでは得られない利点があります。同時に、openGemini は Huawei の内部プロジェクトとして、「自社の人材」のテストに合格しました。
Huawei Cloud SRE は、監視データ ストレージ ベースとして openGemini を使用しており、最大クラスター サイズは 70 ノードで、ネットワーク全体に合計 25 個のクラスターが展開されており、1 秒あたり 4,000 万件の同時データ書き込みの実際のテストに耐えることができました。クエリ。元のソリューションと比較して、同じビジネスを実行する場合、元のシステムのエンドツーエンド遅延が 50% 削減され、CPU リソースが 68% 節約され、メモリ リソースが 50% 節約され、ハードディスクが節約されます。リソースを 90% 以上節約できます。
Huawei Cloud の産業用 IoT プラットフォームは、以前は InfluxDB のスタンドアロン バージョンを使用していましたが、openGemini に切り替えて以来、エンドツーエンドのパフォーマンスとクエリの数が 3 倍向上しました。デバイスへのアクセスは百万レベルに増加しました。
Xiang Yu 氏は、openGemini はオープン ソースから生まれ、InfluxDB オープン ソース プロジェクトから多くの恩恵を受けていると紹介し、オープン ソースの精神に従って、すべての openGemini コードがオープン ソース化され、世界中のより多くの企業や開発者がその恩恵を受けることを望んでいます。また、オープン コミュニティを通じて、このプラットフォームが開発者と協力して技術革新を促進し、オープンソースの成果を共有することも期待しています。
現在のところ、openGemini はオープンソース版とクラウドサービスのみを提供しており、オフラインの商用版には関与する予定はなく、財団に寄付する予定です。現時点では、コミュニティにはまだ多くの不完全な点があります。次に、コミュニティは、openGemini のエコロジー ツール (データ移行ツール、SDK、ビッグデータのエコロジー統合など)、ビジュアル管理インターフェイス、ドキュメントなどをさらに充実させます。
「現在、コミュニティの技術計画は、一般に、モノのインターネット、運用と保守の監視と可観測性の 3 つの重要なアプリケーション シナリオに焦点を当て、関連技術の生態学的互換性とカーネル機能の構築を強化します。私たちは次の実証を開始し始めています。 openGemini の世代のソフトウェア アーキテクチャです」と Xiang Yu 氏は言いました。
「短期的には、openGemini は産業関連のシナリオを考慮しません。産業分野のビジネス シナリオは非常に複雑で、リアルタイム要件が非常に高く、産業用ソフトウェア メーカーの堀が非常に深いためです。また、時系列データベースで実行できることは限られているため、このシナリオについては十分な知識がありません。その後、産業用ソフトウェア サプライヤーなどのパートナーを探すことを検討します。プロバイダーなどと協力し、一緒に改善していきたい」とXiang Yu氏は語った。
openGemini公式サイトホームページ:https://www.openGemini.org/
openGemini オープンソース アドレス: https://github.com/openGemini
仲間のニワトリがDeepin-IDE を 「オープンソース」化し、ついにブートストラップを達成しました。 いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた Tencent Cloud の 4 月 8 日の障害レビューと状況説明 RustDesk リモート デスクトップ起動の再構築 Web クライアント WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始 TIOBE 4 月リスト: PHPは史上最低値に落ち、 FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし 、Google は大規模なコード モデル CodeGemma をリリースしました 。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツール