DMA はダイレクト メモリ アクセスであり、FPGA システムでは、一般的に使用される DMA 要件がいくつかあります。
1. PL 内には、データの移動に継続的に介入するための PS (ここでは CPU を総称して PS と呼びます) はありません。一般的なインターフェイス形式は、AXIS と AXI、AXI と AXI です。
2. PL と PS 間のデータの移動は、ZYNQ の場合は理解しやすいため、単一チップの内部インターフェイスに属しますが、PCIe などの他のインターフェイスの場合はもう少し複雑になり、複数のチップ間のインターフェイスに属します。
DMA アプローチの目的を調べます。
1. チップ内でのデータ移動の方法、一般的なインターフェイス、DMA の実装方法を理解します。
2. チップ間のデータ移動方法、共通インターフェース、DMA の実装方法を理解します。
これを理解することで、システム データ移行のフレームワーク構造を確立でき、同様の要求が発生した場合、実際に必要なのは、既存のモジュールを呼び出して実装するだけです。
この記事では、主にインターフェイスの観点からザイリンクスの各 DMA IP を紹介します。
1 AXI4 から AXI4
1.1 AXI セントラル DMA コントローラー
AXI CDMA は、AXI4 プロトコルを使用して、メモリ マップされたソース アドレスとメモリ マップされた宛先アドレスの間に高帯域幅のダイレクト メモリ アクセス (DMA) を提供します。オプションのスキャッター ギャザー (SG) 機能を使用すると、システム CPU から制御タスクとシーケンス タスクをオフロードできます。初期化レジスタ、ステータス レジスタ、および制御レジスタには、ザイリンクス MicroBlaze™ プロセッサに適した AXI4-Lite スレーブ インターフェイスを通じてアクセスします。
なぜ CDMA と呼ばれるのでしょうか? 実際には、CPU に搭載された AXI インターフェイス メモリ内でのデータ送信を処理するためです。典型的なシナリオは MicroBlaze です。なぜ ZYNQ と呼ばないのでしょうか? ZYNQ の AXI は CPU 内に直接マウントされており、制御するために DMA を必要としません。必要に応じてソフトウェアを直接コピーすると、コピー アクションによって内部で AXI DMA 操作が開始されます。ただし、ZYNQ が PL 側で DDR を使用したい場合は、CDMA を使用して動作する必要があります。これは、ZYNQ には AXI Master インターフェイスがなく、SLAVE のみがあるためです (ここでは GP 低速インターフェイスではなく、高性能 HP インターフェイスについて話しています)。 。
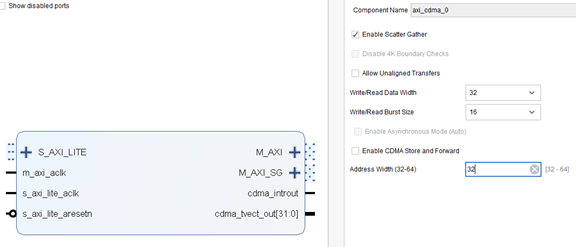
図 1-1 AXI CDMA インターフェイスとパラメータ オプション。S_AXI_LITE はメイン コントロール CPU に接続され、M_AXI はメモリに接続され、M_AXI_SG はメモリに接続されます (SG DMA モードで dma ディスクリプタを格納するために使用されます)。

図 1-2 CMDA の内部構成ブロック図

図 1-3 ZYNQ ブロック図、高性能 AXI SLAVE のみ、MASTER なし
内部レジスタを見てみましょう。これは実際にはより直観的であり、ユーザーにモジュールの構成方法を示します。構成方法から、モジュールの使用の複雑さを簡単に推定できます。レジスタ定義、制御、ステータス検出、SG DMA のディスクリプタ ポインタ、開始アドレス、ターゲット アドレス、単純な DMA の長さなど、使い方は複雑ではありません。その場合、対応するソフトウェア コードはザイリンクスの ZYNQ 側ドライバー コードを直接コピーすることをお勧めします。その後、わずかな変更を加えるだけで使用できるようになります。
最後に、リソース占有率を見てみましょう。リソース占有率はビット幅に比例します。通常、64 ビット データ ビット幅では、約 1500 個の LUT と 2500 個の FF を占有します。私の観点からは、このリソースは非常に優れています。

図 1-4 リソースの使用状況

図 1‑5 伝送効率と帯域幅
2 AXI4 への AXI ストリーム
2.1 AXI データムーバー
AXI Datamover は、AXI4 メモリ マップド ドメインと AXI4-Stream ドメイン間のデータの高スループット転送を可能にする重要なインターコネクト インフラストラクチャ IP です。 AXI Datamover は、全二重のような方式で独立して動作する MM2S および S2MM AXI4-Stream チャネルを提供します。 AXI Datamover は、AXI DMA コアの重要な構成要素であり、4 KB のアドレス境界保護、自動バースト パーティショニングを可能にするほか、AXI4-Stream プロトコルのほぼ全帯域幅機能を使用して複数の転送要求をキューに入れる機能を提供します。さらに、AXI Datamover はバイト レベルのデータ再調整を提供し、任意のバイト オフセット位置へのメモリの読み書きを可能にします。
AXI Datamover は重要な基本 IP であり、すべてのザイリンクス DMA IP には基本的にこのモジュールが含まれており、データを AXIS および AXI フォーマットに変換できます。
XDMA、VDMA、AXI DMA、AXI MCDMA などのほぼすべての DMA IP にこのモジュールが含まれており、ザイリンクスの既存の DMA ではニーズを満たせない場合は、ユーザーが自分で DMA コントローラーを設計して DMA 動作を完了することができます。
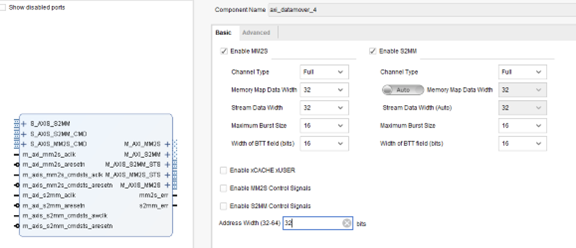
図 2-1 AXI Datamover インターフェイスと構成項目
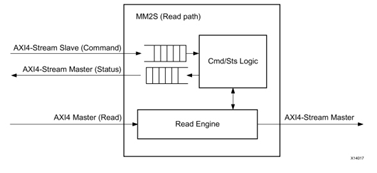
図 2-2 MM2S データ チャネルの読み取り、AXI4 インターフェイス データの読み取り、AXIS データ出力への変換
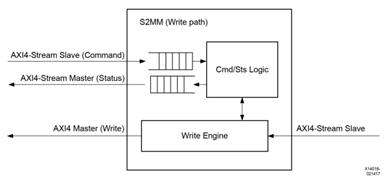
図 2-3 S2MM 書き込みデータ チャネル、AXIS データ入力、AXI4 データに変換され、AXI4 インターフェイス メモリに書き込まれる

図 2-4 リソースの使用状況
2.2 AXI DMA コントローラー
AXI ダイレクト メモリ アクセス (AXI DMA) IP は、メモリと AXI4-Stream タイプのターゲット ペリフェラル間の高帯域幅のダイレクト メモリ アクセスを提供します。オプションのスキャッター ギャザー機能も、プロセッサ ベースのシステムの中央処理装置 (CPU) からデータ移動タスクをオフロードします。初期化レジスタ、ステータス レジスタ、および管理レジスタには、AXI4-Lite スレーブ インターフェイスを通じてアクセスします。
つまり、AXI DMA コントローラーは、(AXI Lite インターフェイスを介して) ソフトウェアによって制御される AXIS および AXI4 インターフェイスの変換 (データ ストレージ) のための簡単な方法を提供します。

図 2-5 AXI DMA の内部ブロック図
ここで説明する必要があります。SG DMA モードを有効にせず、純粋なレジスタ コントロール モードを使用することを選択した場合、AXI DMA IP ではリソースの使用量が減少し、パフォーマンスが低下します (他のザイリンクス DMA IP は同様)、なぜパフォーマンスが低下するのでしょうか?これは、レジスタ モードがプリセット転送命令をサポートしておらず、1 つの転送が完了するまで待機してから次の転送を開始できるため、帯域幅が減少し、CPU 介入が増加するためです。ただし、このモードは最も単純でもあり、依然として設計の送信要件に依存します。
レジスタ テーブルを見てみましょう。このテーブルには、SG DMA とレジスタ DMA の 2 つのモードでレジスタがリストされています。このテーブルからわかるように、実際に AXI DMA を使用するのは複雑ではありません。ただし、レジスタ テーブルを直接コピーすることをお勧めします。ザイリンクス SDK のドライバー コード、ベア メタル ドライバーとサンプルで十分で、シンプルで直接的で使いやすいです。
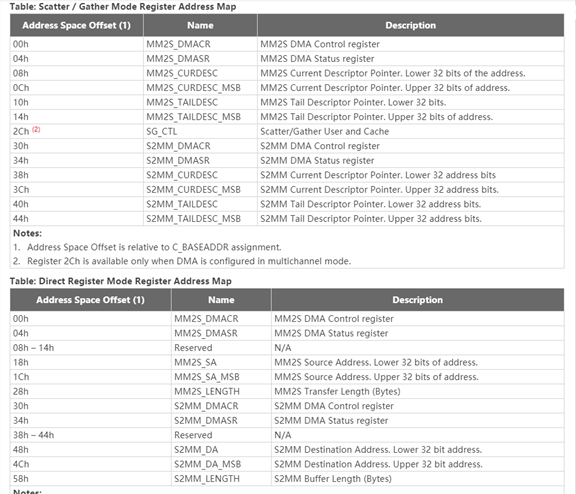
図 2-6 の表は、SG モードおよびレジスタ モードにおける関連レジスタとその意味を示しています。

図 2-7 リソース使用量という点では、依然としてかなり多くの量が使用されています。

図 2-8 遅延、パフォーマンス、および帯域幅のデータ。帯域幅のデータはかなり良好です。一般的に、80% を達成するのが適切です。読み取りは書き込みよりも速いため、MM2S の帯域幅は 100% に近く、帯域幅はS2MM の割合はわずか 75% です。
2.3 AXI マルチチャネル DMA
簡単に言えば、AXI DMA のマルチ チャネル バージョンです。マルチ チャネルの低速データ送信に対応するように設計されています。AXI MCDMA は、双方向で最大 16 チャネルをサポートし、各チャネルは互いに独立しており、これにより、多くの低速、多機能が提供されます。このアプリケーションは、小面積の FPGA ソリューションを提供します。
AXI MCDMA は AXI DMA のマルチチャネル版であるため、あまり紹介しません。
AXI MCDMA は、エンベデッド プロセッサからタスクをオフロードし、大規模なデータの移行を容易にします。これは、AXI メモリ マップド エンベデッド サブシステムと AXI ストリーミング サブシステムの間の仲介として機能します。 MCDMA IP は全二重、スキャッター/ギャザーで、最大 16 チャネルをサポートします。加重ラウンドロビンまたは完全優先として構成できます。

図 2-9 AXI MCDMA の構造ブロック図
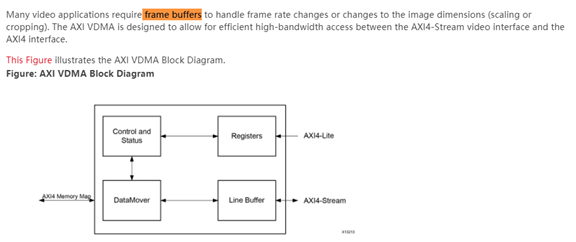
2.4 AXI ビデオ DMA
AXI ビデオ ダイレクト メモリ アクセス (AXI VDMA) コアは、メモリと AXI4-Stream タイプのビデオ ターゲット ペリフェラル間の高帯域幅のダイレクト メモリ アクセスを提供するザイリンクスのソフト IP コアです。このコアは、独立した非同期読み取りおよび書き込みチャネル操作による効率的な 2 次元 DMA 操作を提供します。初期化、ステータス、割り込み、および管理レジスタには、AXI4-Lite スレーブ インターフェイスを通じてアクセスします。
AXI DMA があるのに、なぜ AXI VDMA が必要なのでしょうか?その理由は、次の段落からわかります。ザイリンクスのビデオ処理では主に AXIS フォーマットが使用されます。しかし、実際のアプリケーションでは、フレーム レートやキャッシュ フレームを変更する必要が多くなります。AXI DMA を直接使用することは不可能ではありませんが、不可能です。他の AXIS と適切に統合される インターフェイスのビデオ IP が一致するため、AXI VDMA は主に画像フレームをキャッシュするために特別に開発されました。友人が尋ねたいのですが、BRAM はキャッシュに使用できないのですか?いいえ、画像に対応する各フレームは非常に大きい可能性があり、BRAM リソースが十分ではないためです。
AXI VDMA の使用方法は他の DMA IP と同様です。ここではこれ以上の説明は省略します。使用したい場合は、公式マニュアルを直接確認してください。
3 PCIe DMA
ザイリンクスは、PCIe インターフェイス用の AXI DMA インターフェイスも発表しました。これは、PCIe 用ザイリンクス DMA に対応します。同様に、USB や SRIO などの他のインターフェイスと同様に、同様の DMA ソリューションを設計して、信頼性が高く柔軟なシステム内部アーキテクチャを構築できます。 。
PCI Express® (PCIe) 用ザイリンクス LogiCORE™ DMA は、PCI Express 統合ブロックで使用するための高性能で構成可能な Scatter Gather DMA を実装しています。この IP は、オプションの AXI4-MM または AXI4-Stream ユーザー インターフェイスを提供します。

図3‑1 XDMAインタフェースとパラメータの設定項目

図 3-2 XDMA の内部ブロック図
では、XDMA では何ができるのでしょうか?このモジュールを使用すると、PCIe エンドポイント デバイスを AXI バス上に構築でき、柔軟で信頼性の高い、高性能のシステム オン チップ アーキテクチャが得られます。
4 インスピレーション
ユーザーは、ザイリンクスの DMA ブロック ダイアグラム アーキテクチャに基づいて、AXI および AXIS インターフェイスと相互接続された、柔軟で信頼性の高い FPGA システムを構築できます。これらの IP が要件を満たさない場合は、PCIe XDMA および他の IP のアーキテクチャを模倣して独自のシステムを構築することもできます-オンチップアーキテクチャ。