記事ディレクトリ
1.1 K 最近傍アルゴリズムの概要
学習目標
- 目標
- KNN アルゴリズムとは何かを理解する
- KNN アルゴリズムの解決プロセスを知る
1 K 最近傍アルゴリズムとは何ですか?
- 「隣人」に基づいてカテゴリーを推測します
1.1 K 最近傍アルゴリズム (KNN) の概念
K 最近傍アルゴリズムは、KNN アルゴリズムとも呼ばれ、機械学習では比較的古典的なアルゴリズムであり、一般的には比較的理解しやすいアルゴリズムです。
- 意味
サンプルの k 個の最も類似した (つまり、特徴空間内の最近傍) サンプルのほとんどが特定のカテゴリに属する場合、サンプルもこのカテゴリに属します。
出典: KNN アルゴリズムは、Cover と Hart によって分類アルゴリズムとして初めて提案されました。
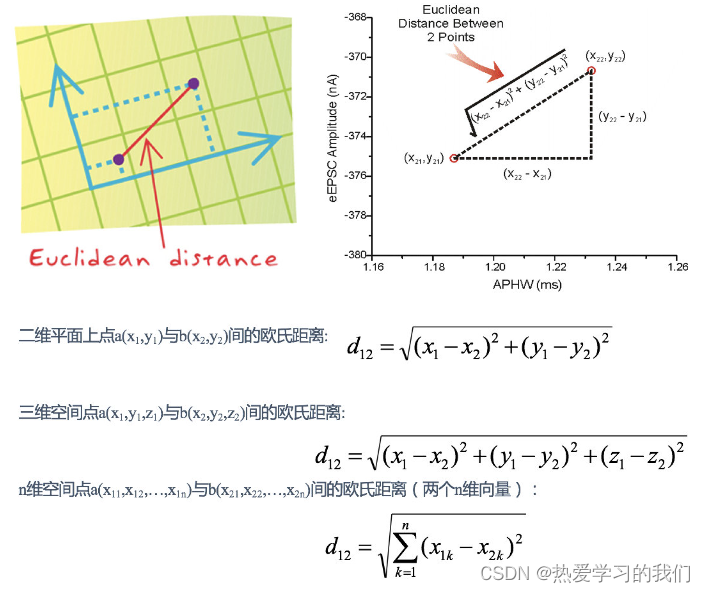
- 距離の公式
2 つのサンプル間の距離は、ユークリッド距離とも呼ばれる次の式で計算できます。距離の式については後で説明します。
1.2 映画の種類の分析
今、いくつかの映画があるとします。
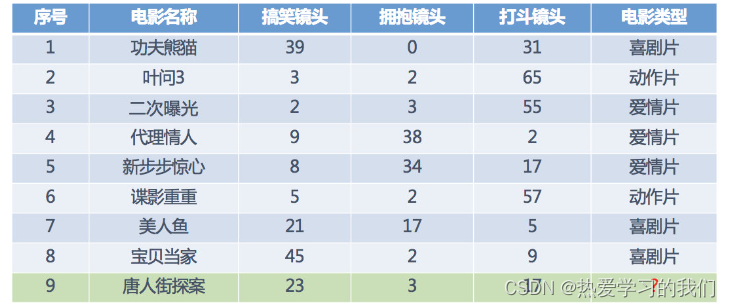
で?映画第 9 作のカテゴリーが分からない場合、どうやって予測できますか? K 最近傍アルゴリズムのアイデアを使用できます
1. 各映画と予測された映画の間の距離を個別に計算し、それを解きます。
たとえば、映画 No. 9 《チャイナタウン アドベンチャー》 と 《二重露光》 の間の距離を計算すると、
d = ( 23 − 2 ) 2 + ( 3 − 3 ) 2 + ( 17 − 55 ) 2 = 43.42 となります。 d = \sqrt{(23-2)^2 + (3-3)^2 + (17-55)^2} = 43.42d=( 23−2 )2+( 3−3 )2+( 17−55 )2=43.42
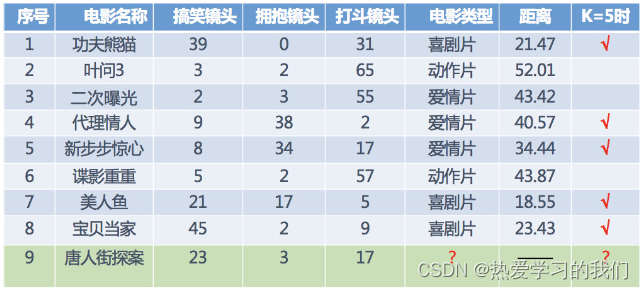
2. 距離の増加順は、7、1、8、5、4、3、6、2です。
3. k を 5 と仮定して、k 値を設定します。最初の 5 つの映画はそれぞれ 7、1、8、5、4 です。
4. コメディは3度、ラブは2度
予想値5.9はコメディ。
1.3 KNNアルゴリズムプロセスの概要
1) 既知のカテゴリ データセット内の点と現在の点の間の距離を計算します。
2) 距離の増加順に並べ替えます
3) 現在の点からの距離が最も小さい k 点を選択します
4) 最初の k 点が位置するカテゴリの出現頻度をカウントします。
5) 最初の k 点の出現頻度が最も高いカテゴリを、現在の点の予測分類として返します。
2 まとめ
- K 最近傍アルゴリズムの概要 [理解する]
- 定義:「隣人」を通じて自分がどのカテゴリーに属するかを判断すること
- あなたとあなたの「隣人」との間の距離を計算する方法: 通常、ユークリッド距離が使用されます。
1.2 k 最近傍アルゴリズム API の予備使用
学習目標
- 目標
- sklearn ツールの利点と含まれるものを理解する
- sklearn に API を適用して、KNN アルゴリズムの簡単な使用を実装します。
-
機械学習プロセスのレビュー:
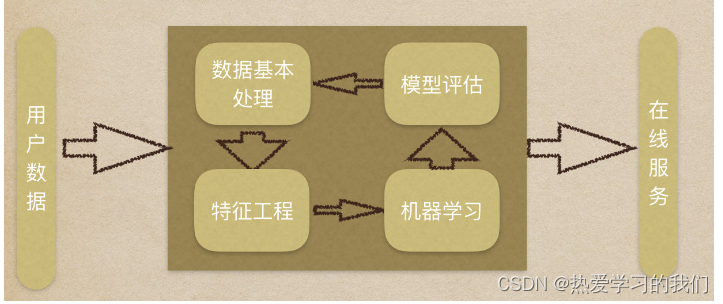
-
1. データセットを取得する
-
2. 基本的なデータ処理
-
3. 特徴量エンジニアリング
-
4. 機械学習
-
5. モデルの評価
1 Scikit-learn ツールの概要

- Python言語による機械学習ツール
- Scikit-learn には、多くのよく知られた機械学習アルゴリズムの実装が含まれています
- Scikit-learn には完全なドキュメントがあり、使いやすく、豊富な API が備わっています。
- 現在の安定バージョンは 0.19.1 です
1.1 インストール
pip3 install scikit-learn==0.19.1
インストール後、次のコマンドを実行して、インストールが成功したかどうかを確認できます。
import sklearn
- 注: scikit-learn をインストールするには、Numpy、Scipy、およびその他のライブラリが必要です
1.2 Scikit-learn の概要

- 分類、クラスタリング、回帰、次元削減、モデル選択、前処理
2 K 最近傍アルゴリズム API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors: int、オプション (デフォルト = 5)、k_neighbors はデフォルトで使用される近傍の数をクエリします。
3件
3.1 ステップ分析
- 1. データセットを取得する
- 2. 基本的なデータ処理(今回は省略)
- 3. 特徴量エンジニアリング(今回は省略)
- 4. 機械学習
- 5. モデルの評価(今回は省略)
3.2 コード処理
- インポートモジュール
from sklearn.neighbors import KNeighborsClassifier
- データセットを構築する
x = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
- 機械学習 – モデルのトレーニング
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=1)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])
4 まとめ
- sklearn の利点:
- 多くの文書があり、それらは標準化されています
- 多くのアルゴリズムが含まれています
- 実装が簡単
- knn の API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
質問
1. 距離の公式 ユークリッド距離以外に使用できる距離の公式は何ですか?
2. K 値のサイズを選択しますか?
3.API の他のパラメータの具体的な意味は何ですか?
1.3 距離の測定
学習目標
- 目標
- 機械学習における一般的な距離計算式を理解する
1 一般的な距離の公式
1.1 ユークリッド距離** (ユークリッド距離):
ユークリッド距離は最も直感的に理解しやすい距離測定法であり、小・中・高等学校などで私たちが接する空間上の2点間の距離は一般にユークリッド距離を指します。

例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
1.2 マンハッタンの距離:
マンハッタン地区のある交差点から別の交差点まで運転する場合、走行距離は明らかに 2 点間の直線距離ではありません。この実際の走行距離が「マンハッタン距離」です。マンハッタン距離は「シティブロック距離」とも呼ばれます。
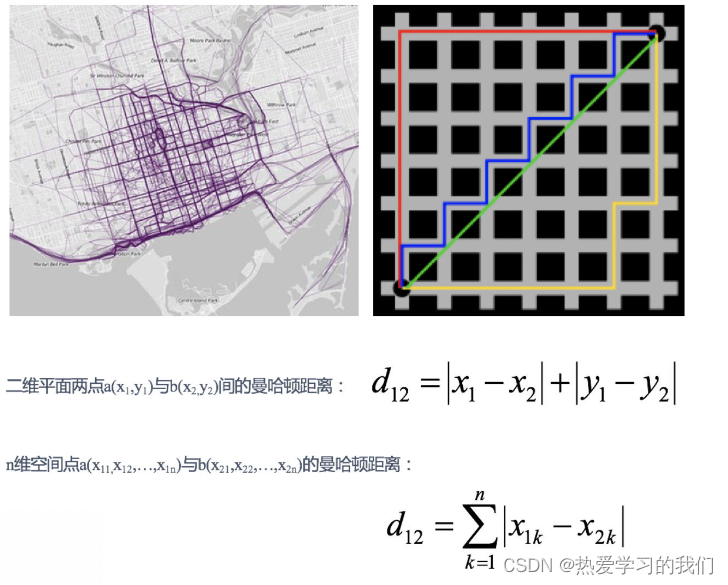
例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 2 4 6 2 4 2
1.3 チェビシェフ距離:
チェスでは、キングは直線、水平、斜めに移動できるため、1 回の移動で隣接する 8 つのマスのいずれかに移動できます。王がグリッド (x1, y1) からグリッド (x2, y2) に移動するには何歩かかりますか? この距離はチェビシェフ距離と呼ばれます。
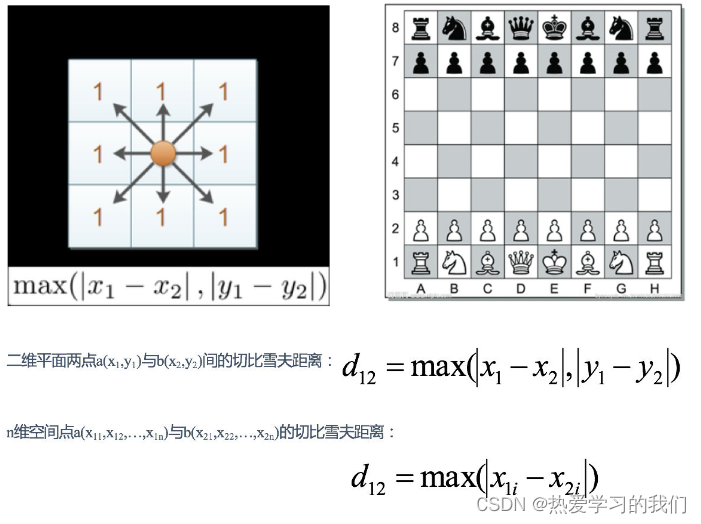
例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1 2 3 1 2 1
1.4 ミンコフスキー距離:
最小距離は距離の一種ではなく、複数の距離測定式の一般的な表現である一連の距離定義です。
2 つの n 次元変数 a(x11,x12,…,x1n) と b(x21,x22,…,x2n) の間のミンコフスキー距離は次のように定義されます。
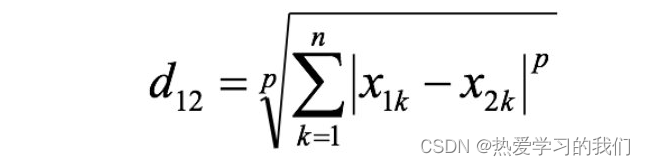
ここで、p は可変パラメータです。
- p=1 の場合、それはマンハッタン距離です。
- p=2 の場合、それはユークリッド距離です。
- p→∞のときはチェビシェフ距離です。
p に応じて、Min の距離は特定のカテゴリ/種の距離を表すことができます。
まとめ:
マンハッタン距離、ユークリッド距離、チェビシェフ距離を含む 1 分距離にはすべて明らかな欠点があります。
例えば二次元サンプル(身長[単位:cm]、体重[単位:kg])の場合、a(180,50)、b(190,50)、c(180,60)の3つのサンプルがあります。
a と b の間の最小距離 (マンハッタン距離、ユークリッド距離、チェビシェフ距離のいずれであっても) は、a と c の間の最小距離と等しくなります。しかし実際には、身長10cmと体重10kgは一致しません。
Min の距離の 2 つのデメリット:
(1) 各コンポーネントのスケール、つまり「単位」を同一に扱う。
(2) 各成分の分布(期待、分散など)が異なる可能性は考慮されていません。
[[拡張]その他の距離公式]
2 「連続属性」と「離散属性」間の距離計算
私たちはよく属性を「連続属性」と「カテゴリ属性」に分けますが、前者は定義領域内で取り得る値が無限であるのに対し、後者は定義領域内で値の数が限られています。
- 属性値間に順序関係がある場合は、連続値に変換することができ、例えば、身長属性「tall」、「medium」、「short」を{1, 0.5, 0}に変換することができる。
- ミンコフスキー距離は、順序付けされた属性に使用できます。
- 属性値間に順序関係がない場合、通常はベクトル形式に変換されます。たとえば、性別属性「男性」と「女性」は、{(1,0), (0,1)} に変換できます。
3 まとめ
- 1 一般的な距離の公式
- 2.1 ユークリッド距離 [知る]:
- 距離の二乗値で計算
- 2. マンハッタンの距離 [知っている]:
- 距離の絶対値で計算
- 3. チェビシェフ距離 [知っている]:
- 寸法の最大値を計算します
- 4. ミンコフスキー距離 [知っている]:
- p=1 の場合、それはマンハッタン距離です。
- p=2 の場合、それはユークリッド距離です。
- p→∞のときはチェビシェフ距離です。
- 2.1 ユークリッド距離 [知る]:
- 2つの属性[知っている]
- 連続属性
- 個別の属性、
- 順序関係があり、連続値に変換できます。
- 順序関係はなく、通常はベクトル形式に変換されます。
1.4 ケース: アヤメの種の予測 – データセットの紹介
学習目標
- 目標
- sklearn でデータセットを取得する方法を知る
- sklearn でデータセットを分割する方法を理解する
このラボでは、Python を使用した機械学習の基本概念をいくつか紹介します。この場合、K 最近傍 (KNN) アルゴリズムを使用して、アヤメの花の種類を分類し、花の特性を測定します。
この事件の目的:
- 完全な機械学習プロセスを追跡して理解する
- 機械学習の原理と関連用語についての基本的な理解がある。
- 機械学習モデルを評価する基本的なプロセスを理解します。
1 事例:アヤメの花種予測
アイリス データ セットは、1936 年にフィッシャーによって収集および整理された、一般的に使用される分類実験データ セットです。アイリス (アヤメの花データ セットとも呼ばれる) は、多変数分析用のデータ セットの一種です。データセットの詳細な紹介:

2 scikit-learn のデータセットの概要
2.1 scikit-learn データセット API の概要
- sklearn.datasets
- 人気のあるデータセットの読み込み
- datasets.load_*()
- データセットに含まれる小規模なデータセットを取得します。
- datasets.fetch_*(data_home=なし)
- 大規模なデータ セットを取得するには、インターネットからダウンロードする必要があります。関数の最初のパラメータは data_home で、データ セットがダウンロードされるディレクトリを示します。デフォルトは ~/scikit_learn_data/ です。
2.1.1 sklearn の小さなデータセット
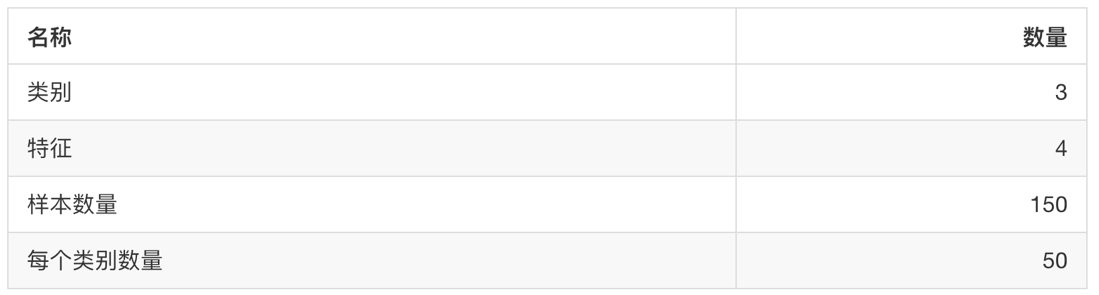
-
sklearn.datasets.load_iris()
アヤメデータセットをロードして返します
2.1.2 sklearn 大規模データセット
- sklearn.datasets.fetch_20newsgroups(data_home=なし、subset='train')
- サブセット: 'train' または 'test'、'all'、オプション、ロードするデータセットを選択します。
- トレーニング セットの場合は「train」、テスト セットの場合は「test」、両方の「all」
2.2 sklearn データセットの戻り値の概要
- ロードおよびフェッチによって返されるデータ型 datasets.base.Bunch (辞書形式)
- data: 特徴データ配列。[n_samples * n_features] の 2 次元 numpy.ndarray 配列です。
- ターゲット: ラベル配列、n_samples の 1 次元 numpy.ndarray 配列
- DESCR: データの説明
- feature_names: 機能名、ニュース データ、手書きの数字、回帰データ セットは利用できません
- target_names: タグ名
from sklearn.datasets import load_iris
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])#调用iris.data和iris["data"]效果一样
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
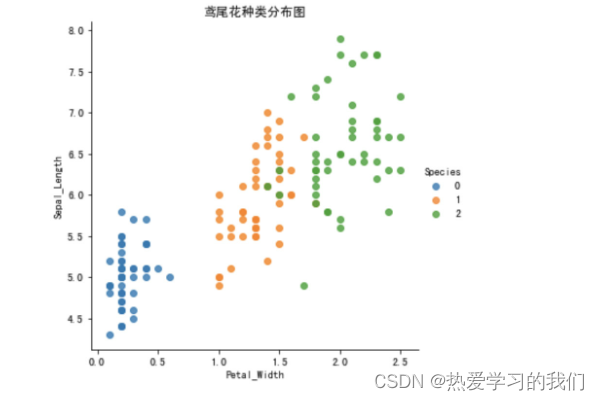
2.3 データ分布の表示
いくつかのプロットを作成して、さまざまなカテゴリが特徴によってどのように区別されるかを確認します。理想的な世界では、ラベル クラスは 1 つ以上の特徴ペアによって完全に分離されます。現実の世界では、このような理想的な状況はめったに起こりません。
- シーボーンの紹介
- Seaborn は、Matplotlib コア ライブラリをベースにしたより高度な API カプセル化であり、より美しいグラフィックスを簡単に描画できます。Seaborn の美しさは主に、より快適なカラーマッチングとグラフィック要素のより繊細なスタイルに反映されています。
- pip3をインストール Seabornをインストール
- seaborn.lmplot() は、2 次元散布図を描画するときに回帰フィッティングを自動的に完了する非常に便利なメソッドです。
- sns.lmplot() の x と y はそれぞれ水平座標と垂直座標の列名を表します。
- data= はデータセットに関連付けられており、
- hue=*は種別の分類表示、つまり花のカテゴリを表します。
- fit_reg=線形フィッティングを実行するかどうか。
- 参考リンク:APIリンク
%matplotlib inline
# 内嵌绘图
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 把数据转换成dataframe的格式
iris_d = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_d['Species'] = iris.target
def plot_iris(iris, col1, col2):
sns.lmplot(x = col1, y = col2, data = iris, hue = "Species", fit_reg = False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('鸢尾花种类分布图')
plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
2.4 データセットの分割
機械学習の一般的なデータセットは 2 つの部分に分かれています。
- トレーニング データ:モデルのトレーニングと構築に使用されます。
- テストデータ: モデルのテスト中に、モデルが有効かどうかを評価するために使用されます。
分周比:
- トレーニングセット: 70% 80% 75%
- テストセット: 30% 20% 25%
データセットパーティショニングAPI
- sklearn.model_selection.train_test_split(配列, *オプション)
- パラメータ:
- データセットの x 固有値
- データセットのyラベル値
- test_size テストセットのサイズ、通常は浮動小数点数
- random_state は乱数シードです。シードが異なると、ランダム サンプリング結果も異なります。同じ種子のサンプリング結果は同じです。
- 戻る
- x_train、x_test、y_train、y_test
- パラメータ:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1、获取鸢尾花数据集
iris = load_iris()
# 对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
3 まとめ
- データセットを取得【知る】
- 小さなデータ:
- sklearn.datasets.load_*
- 大規模なデータセット:
- sklearn.datasets.fetch_*
- 小さなデータ:
- データセットの戻り値入門【知っておきたい】
- 戻り値の型は Bunch (辞書型) です。
- 戻り値のプロパティ:
- データ: 特徴データ配列
- target: タグ (ターゲット) 配列
- DESCR: データの説明
- feature_names: 機能名、
- target_names: ラベル(ターゲット値)の名前
- データセットの分割【マスタリー】
- sklearn.model_selection.train_test_split(配列, *オプション)
- パラメータ:
- x – 固有値
- y – 目標値
- test_size – テストセットのサイズ
- ramdom_state – 乱数シード
- 戻り値:
- x_train、x_test、y_train、y_test
1.5 特徴エンジニアリング - 特徴の前処理
学習目標
- 目標
- 前処理とはどのような機能かを理解する
- 正規化と標準化の原則と違いを理解する
1 特徴前処理とは
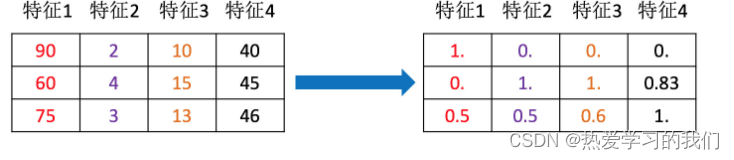
1.1 特徴前処理の定義
scikit-learnの説明
は、生の特徴ベクトルを下流の推定器により適した表現に変更するための、いくつかの一般的なユーティリティ関数とトランスフォーマー クラスを提供します。
翻訳:いくつかの変換関数を通じて、特徴データをアルゴリズム モデルにより適した特徴データに変換するプロセス
-
なぜ正規化/標準化する必要があるのでしょうか?
- 特徴の単位やサイズがまったく異なるか、特徴の分散が他の特徴よりも数桁大きいため、ターゲットの結果に影響 (支配) が生じやすく、一部のアルゴリズムが他の特徴を学習できなくなります。
-
例: デートデータ
異なる仕様のデータを同じ仕様に変換するには、無次元変換のためのいくつかのメソッドを使用する必要があります。
1.2 含まれる内容(数値データの無次元化)
- 正規化された
- 標準化
1.3 機能前処理 API
sklearn.preprocessing
2 正規化
2.1 定義
元のデータを変換してデータをマッピングします (デフォルトは [0,1])
2.2 公式
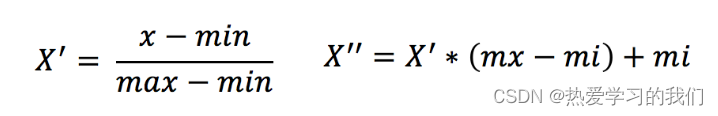
各列に作用し、max は列の最大値、min は列の最小値、X'' が最終結果、mx、mi はそれぞれ指定された間隔値です。デフォルトの mx は 1、mi は0
では、このプロセスをどのように理解すればよいのでしょうか? 例を見てみましょう
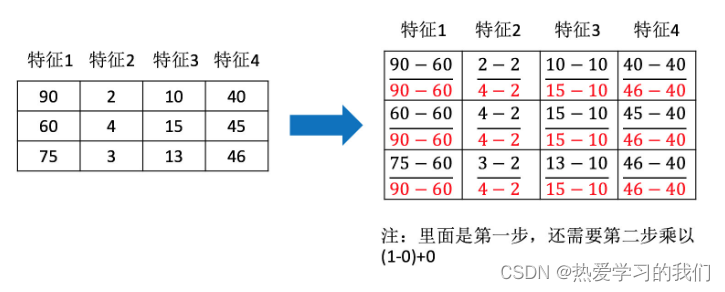
2.3 API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)…)
- MinMaxScalar.fit_transform(X)
- X: numpy 配列形式のデータ [n_samples,n_features]
- 戻り値: 変換後の同じ形状の配列
- MinMaxScalar.fit_transform(X)
2.4 データ計算
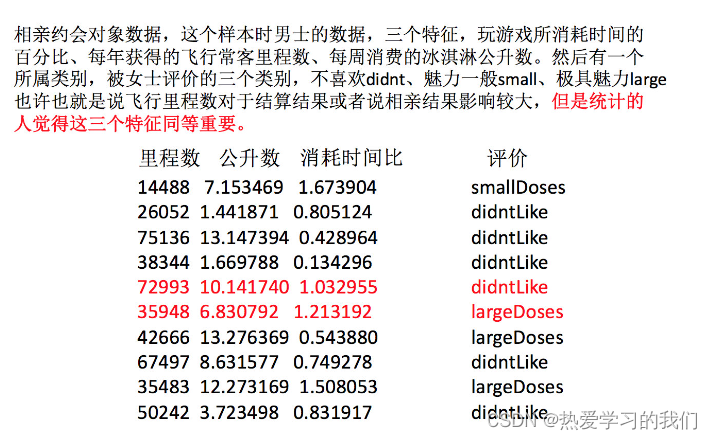
デート.txt 内の次のデータに対して操作を実行します。保存されるのは過去の日付のデータです。
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
- 分析する
1. MinMaxScalar をインスタンス化する
2.fit_transformによる変換
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
归一化演示
:return: None
"""
data = pd.read_csv("./data/dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = MinMaxScaler(feature_range=(2, 3))
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("最小值最大值归一化处理的结果:\n", data)
return None
minmax_demo()
返される結果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
.. ... ... ... ...
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最小值最大值归一化处理的结果:
[[ 2.44832535 2.39805139 2.56233353]
[ 2.15873259 2.34195467 2.98724416]
[ 2.28542943 2.06892523 2.47449629]
...,
[ 2.29115949 2.50910294 2.51079493]
[ 2.52711097 2.43665451 2.4290048 ]
[ 2.47940793 2.3768091 2.78571804]]
質問: データに外れ値が多数ある場合、どのような影響がありますか?
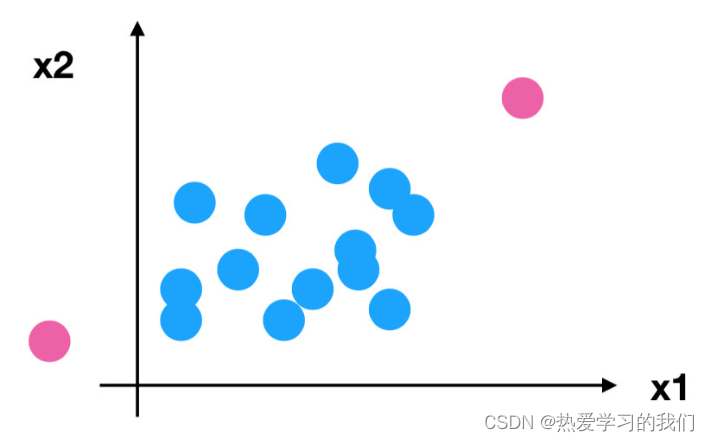
2.5 正規化された要約
最大値と最小値は変化することに注意してください。また、最大値と最小値は外れ値の影響を非常に受けやすいため、この方法は堅牢性が低く、従来の正確な小規模データのシナリオにのみ適しています。
何をするか?
3 標準化
3.1 定義
元のデータを変換すると、データは平均 0、標準偏差 1 の範囲に変換されます。
3.2 公式
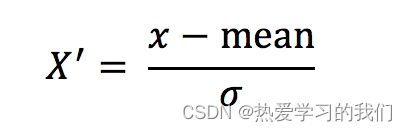
各列に作用します。mean は平均値、σ は標準偏差です。
それでは、先ほどの異常な点に戻り、標準化について見てみましょう
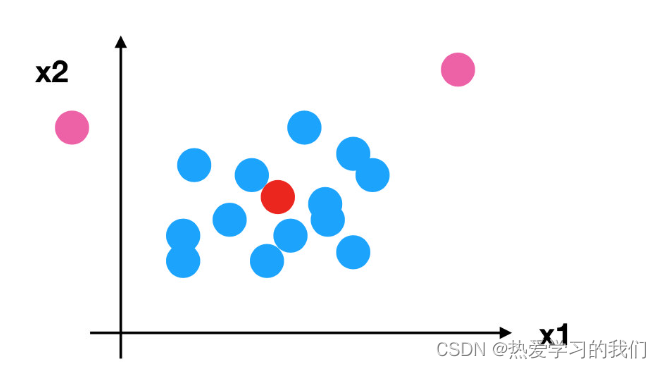
- 正規化の場合: 最大値と最小値に影響を与える外れ値がある場合、結果は明らかに変わります。
- 標準化の場合: 一定量のデータにより外れ値が発生した場合、少数の外れ値は平均値に大きな影響を与えないため、分散はほとんど変化しません。
3.3 API
- sklearn.preprocessing.StandardScaler()
- 処理後、各列のすべてのデータは平均 0 の周りに集中し、標準偏差は 1 になります。
- StandardScaler.fit_transform(X)
- X: numpy 配列形式のデータ [n_samples,n_features]
- 戻り値: 変換後の同じ形状の配列
3.4 データ計算
上記のデータも同様に処理します
- 分析する
1.StandardScaler をインスタンス化する
2.fit_transformによる変換
import pandas as pd
from sklearn.preprocessing import StandardScaler
def stand_demo():
"""
标准化演示
:return: None
"""
data = pd.read_csv("./data/dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
返される結果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
.. ... ... ... ...
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
标准化的结果:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...,
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]
每一列特征的平均值:
[ 3.36354210e+04 6.55996083e+00 8.32072997e-01]
每一列特征的方差:
[ 4.81628039e+08 1.79902874e+01 2.46999554e-01]
3.5 標準化の概要
十分なサンプルがある場合は比較的安定しており、ノイズの多い最新のビッグ データ シナリオに適しています。
4 まとめ
- 特徴量エンジニアリングとは [知っている]
- 意味
- いくつかの変換関数を通じて特徴データをアルゴリズムモデルにより適した特徴データに変換するプロセス
- 含まれるもの:
- 正規化された
- 標準化
- 意味
- 正規化【知る】
- 意味:
- 元のデータを変換し、データをマッピングします (デフォルトは [0,1])
- API:
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)…)
- パラメータ: feature_range – 範囲を自分で指定します。デフォルトは 0 ~ 1
- 要約:
- 堅牢性が低い(外れ値の影響を受けやすい)
- 従来の正確な小規模データのシナリオにのみ適しています (今後は使用しません)
- 意味:
- 標準化[マスタリー]
- 意味:
- 元のデータを平均が 0、標準偏差が 1 になる範囲に変換します。
- API:
- sklearn.preprocessing.StandardScaler()
- 要約:
- 異常値は私にほとんど影響を与えません
- 現代の騒々しいビッグデータのシナリオに適しています (今後も使用します)
- 意味:
1.6 ケース: アヤメの種の予測 - プロセスの実装
学習目標
- 目標
- KNeighborsClassifier の使用法を理解する
1 K 最近傍アルゴリズム API を再理解する
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:
- int、オプション (デフォルト = 5)、k_neighbors はデフォルトで使用される近傍の数をクエリします。
- アルゴリズム:{'auto','ball_tree','kd_tree','brute'}
- Fast k 最近傍検索アルゴリズム。デフォルトのパラメーターは auto です。これは、アルゴリズム自体が適切な検索アルゴリズムを決定するものと理解できます。さらに、検索アルゴリズム ball_tree、kd_tree、およびブルート メソッドを指定して検索することもできます。
- brute は総当たり検索であり、線形スキャンであるため、トレーニング セットが大きい場合、計算に非常に時間がかかります。
- kd_tree は、迅速な検索のためにデータを保存する kd ツリーを構築するツリー データ構造です。kd ツリーは、データ構造内のバイナリ ツリーでもあります。中央値分割によって構築されたツリー (各ノードは超長方形) は、次元が 20 未満の場合に効率的です。
- ボールツリーは、kd ツリーの高次元破綻を克服するために発明されたもので、その構築プロセスはサンプル空間を質量中心 C と半径 r で分割し、各節点は超球です。
- Fast k 最近傍検索アルゴリズム。デフォルトのパラメーターは auto です。これは、アルゴリズム自体が適切な検索アルゴリズムを決定するものと理解できます。さらに、検索アルゴリズム ball_tree、kd_tree、およびブルート メソッドを指定して検索することもできます。
- n_neighbors:
2 事例:アヤメの種予測
2.1 データセットの概要
アイリス データ セットは、1936 年にフィッシャーによって収集および整理された、一般的に使用される分類実験データ セットです。アイリス (アヤメの花データ セットとも呼ばれる) は、多変数分析用のデータ セットの一種です。データセットの詳細な紹介:

2.2 ステップ分析
- 1. データセットを取得する
- 2. 基本的なデータ処理
- 3. 特徴量エンジニアリング
- 4. 機械学習(モデルトレーニング)
- 5. モデルの評価
2.3 コード処理
- インポートモジュール
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
- まず sklearn からデータセットを取得し、次にデータセットを分割します。
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
- データの標準化を実行する
- 固有値の標準化
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- モデルは予測するようにトレーニングされています
# 4、机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=9)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 方法2:直接计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
3 事例の概要
この場合、具体的な完了内容には次のものが含まれます。
- 視覚化を使用してデータをロードおよび調査し、特徴が異なるカテゴリを分けているかどうかを判断します。
- 数値特徴を正規化し、トレーニング セットとテスト セットにランダムにサンプリングすることでデータを準備します。
- 統計や精度測定を通じて機械学習モデルを構築および評価します。
完成したばかりの機械学習コードについてクラスメート間で話し合い、それが各自のコンピューターで正常に実行されるかどうかを確認します。
4 まとめ
- KNeighborsClassifierの使い方【Know】
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- Algorithm(auto,ball_tree, kd_tree, brute) – 計算にどのアルゴリズムを選択するか
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
1.7 KNNアルゴリズムの概要
k最近傍アルゴリズムの長所と短所のまとめ
-
アドバンテージ:
- シンプルかつ効果的
- k 最近傍アルゴリズムは、再トレーニングせずに新しいデータをデータ セットに直接追加できるオンライン テクノロジです。
- 異常値やノイズに対して高い耐性を持っています。
- k 最近傍アルゴリズムは本質的に多重分類をサポートしており、パーセプトロン、ロジスティック回帰、および SVM とは区別されます。
- クラスドメイン間のサンプルに適しています
- KNN メソッドは、クラス ドメインを識別する方法ではなく、主に限られた周囲のサンプルに依存して、クラス ドメインが属するカテゴリを決定します。したがって、サンプル セットがクラス ドメイン内でより多くの交差または重複で分割される場合、KNN はこの方法は他の方法より効率的であり、適切です。
-
欠点:
- 怠惰な学習
- KNN アルゴリズムは遅延学習手法 (基本的に学習なし) であり、一部の能動学習アルゴリズムはより高速です。
- メモリを占有します
- KD ツリーやボール ツリーなどのモデルの構築には大量のメモリが必要です。
- 出力はあまり解釈しにくい
- たとえば、デシジョン ツリーの出力はより解釈しやすくなります。
- アンバランスサンプルは苦手
- たとえば、あるクラスのサンプル容量が非常に大きく、他のクラスのサンプル容量が非常に小さいなど、サンプルのバランスが崩れている場合、新しいサンプルが入力されたときに、大容量クラスのサンプルが占める割合が大きくなる可能性があります。サンプルの K 個の近傍のうちの大多数について。このアルゴリズムは、「最も近い」近傍サンプルのみを計算します。特定のタイプのサンプルの数が多い場合、このタイプのサンプルはターゲット サンプルに近くないか、このタイプのサンプルはターゲット サンプルに非常に近いかのいずれかです。いずれの場合も、数量は操作の結果に影響を与えません。これを改善するには、重み付け法 (サンプルからの距離が近い近傍の重みが大きくなります) を使用できます。
- 計算量が多い
- 現在一般的に使用されている解決策は、既知のサンプル ポイントを事前に編集し、分類にほとんど影響を与えないサンプルを削除することです。
- 怠惰な学習
1.8 相互検証、グリッド検索
学習目標
- 目標
- 検証セットが必要な理由を理解する
- 相互検証とグリッド検索の概念を理解する
- 相互検証とグリッド検索を使用してトレーニング モデルを最適化できる
1 相互検証とは何ですか?
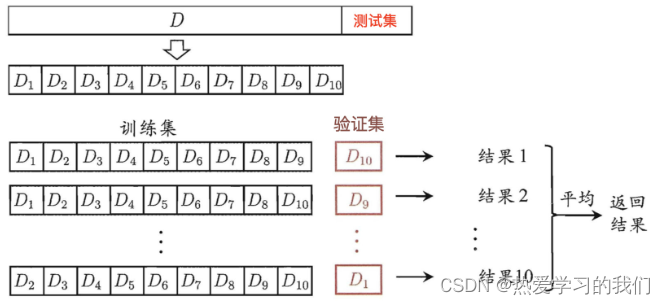
相互検証: 取得したトレーニング データをトレーニング セットと検証セットに分割します。次の図を例に挙げます。データは 4 つの部分に分割され、そのうちの 1 つが検証セットとして使用されます。次に、4 回 (セット) のテストを行った後、毎回異なる検証セットに置き換えました。つまり、4 組のモデルの結果が得られ、その平均値が最終結果となります。4 分割相互検証とも呼ばれます。
1.1 分析
データがトレーニング セットとテスト セットに分割されることは以前からわかっていましたが、これはトレーニングから得られるモデルの結果をより正確にするためです。**以下の処理を行う
- トレーニングセット: トレーニングセット + 検証セット
- テストセット: テストセット
1.2 相互検証が必要な理由
検証セットの目的: ハイパーパラメータを調整すること
相互検証の目的:評価されたモデルをより正確かつ信頼できるものにすること
質問: これは評価されたモデルの正確さと信頼性を高めるだけですが、パラメーターを選択または調整するにはどうすればよいですか?
2 グリッド検索とは何ですか?
通常、手動で指定する必要があるパラメーター (k 最近傍アルゴリズムの K 値など) が多数あり、それらは ハイパーパラメーター と呼ばれます。ただし、手動プロセスは複雑であるため、モデルに対してハイパーパラメーターのいくつかの組み合わせを事前に設定する必要があります。ハイパーパラメーターの各セットは、相互検証を使用して評価されます。最後に、最適なパラメーターの組み合わせを選択してモデルを構築します。

3 相互検証、グリッド検索 (モデルの選択と調整) API:
- sklearn.model_selection.GridSearchCV(推定、param_grid=なし、cv=なし)
- 推定器の指定されたパラメータ値の徹底的な検索を実行します
- 推定子: 推定子オブジェクト
- param_grid: 推定パラメータ (dict){"n_neighbors":[1,3,5]}
- cv: 複数の交差検証を指定します。
- フィット: 入力トレーニング データ
- スコア: 精度
- 結果分析:
- ベストスコア__: 相互検証で検証された最良の結果
- 最良の推定器: 最良のパラメトリック モデル
- cv結果: 各相互検証後の検証セットの精度の結果とトレーニング セットの精度の結果
4. アイリスケースにK値チューニングを追加
- GridSearchCV を使用した推定器の構築
from sklearn.model_selection import GridSearchCV
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、特征工程:标准化
# 实例化一个转换器类
transfer = StandardScaler()
# 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {
"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 4.3 fit数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
- 次に、最終的な選択結果と相互検証結果を確認するために評価します。
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的模型:\n", estimator.best_estimator_)
print("最好模型的参数:\n",estimator.best_params_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
5 まとめ
- 相互検証【知る】
- 意味:
- 取得したトレーニング データをトレーニング セットと検証セットに分割します
- *フォールドクロスバリデーション
- 分割方法:
- トレーニングセット: トレーニングセット + 検証セット
- テストセット: テストセット
- 相互検証が必要な理由
- 評価モデルをより正確かつ信頼できるものにするため
- 注: 相互検証ではモデルの精度を向上させることはできません
- 意味:
- グリッド検索【知る】
- ハイパーパラメータ:
- sklearn では、手動で指定する必要があるパラメータをハイパーパラメータと呼びます。
- グリッド検索とは、これらのハイパーパラメータの値を辞書形式で渡し、最適な値を選択することです。
- ハイパーパラメータ:
- API【知る】
- sklearn.model_selection.GridSearchCV(推定、param_grid=なし、cv=なし)
- 推定器 - どのトレーニング モデルが選択されたか
- param_grid – 渡されるハイパーパラメータ
- cv – 数倍の相互検証
- sklearn.model_selection.GridSearchCV(推定、param_grid=なし、cv=なし)
知識の拡張: 他の距離公式
1 標準化されたユークリッド距離:
標準化ユークリッド距離は、ユークリッド距離の欠点に対処するために行われた改良です。
アイデア: データの各次元コンポーネントの分布は異なるため、まず各コンポーネントを「標準化」して平均と分散が等しくなるようにします。
S_k S**k は各次元の標準偏差を表す
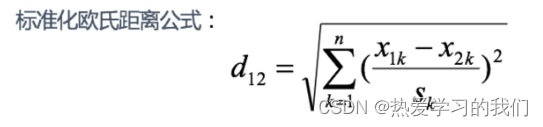
分散の逆数を重みとみなした場合、加重ユークリッド距離とも呼ばれます。
例:
X=[[1,1],[2,2],[3,3],[4,4]];(假设两个分量的标准差分别为0.5和1)
经计算得:
d = 2.2361 4.4721 6.7082 2.2361 4.4721 2.2361
2 コサイン距離
幾何学では、角度の余弦を使用して 2 つのベクトル間の方向の差を測定できます。機械学習では、この概念をサンプル ベクトル間の差を測定するために借用します。
- 2 次元空間におけるベクトル A(x1,y1) とベクトル B(x2,y2) の間の角度のコサイン公式:
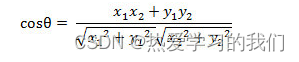
- 2 つの n 次元サンプル点 a(x11,x12,…,x1n) と b(x21,x22,…,x2n) の間の角度の余弦は次のとおりです。

今すぐ:
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-oPC0ym2D-1664343761290) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t6cjvi7j306f01qa9t) .jpg)]](https://img-blog.csdnimg.cn/da92f62ddbd74c38b2ac7726fbbfbe68.png)
夾角の余弦の値の範囲は[-1,1]です。コサインが大きいほど 2 つのベクトル間の角度は小さくなり、コサインが小さいほど 2 つのベクトル間の角度は大きくなります。2つのベクトルの方向が一致する場合、コサインの最大値は1となり、2つのベクトルの方向が完全に逆の場合、コサインは最小値−1となる。
例:
X=[[1,1],[1,2],[2,5],[1,-4]]
经计算得:
d = 0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.8107
3 ハミング距離 [理解]:
2 つの等しい長さの文字列 s1 と s2 のハミング距離は、一方を他方に変更するために必要な文字置換の最小数です。
例えば:
The Hamming distance between "1011101" and "1001001" is 2.
The Hamming distance between "2143896" and "2233796" is 3.
The Hamming distance between "toned" and "roses" is 3.
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが存在する可能性があります。画像を保存して直接アップロードすることをお勧めします (img-wocCqjOI-1664343761290) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t6bsafnj30kg0cgmzu) .jpg)]](https://img-blog.csdnimg.cn/8446529d388c4aefa07d0ba4b69e9d57.png)
随堂练习:
求下列字符串的汉明距离:
1011101与 1001001
2143896与 2233796
irie与 rise
ハミング重み: 同じ長さのゼロ文字列に対する文字列のハミング距離です。つまり、文字列内の非ゼロ要素の数です。バイナリ文字列の場合、1 の数です。なので、11101 のハミング重みは 4 です。したがって、ベクトル空間内の要素 a と b の間のハミング距離が、それらのハミング重みの差 ab に等しい場合。
応用: ハミング重み分析は、情報理論、符号化理論、暗号学およびその他の分野を含む分野に応用されています。例えば、情報の符号化処理においては、誤り耐性を高めるために、符号間の最小ハミング距離をできるだけ大きくする必要がある。ただし、長さの異なる 2 つの文字列を比較する場合は、置換だけでなく挿入や削除の操作も必要となり、通常は編集距離などのより複雑なアルゴリズムが使用されます。
例:
X=[[0,1,1],[1,1,2],[1,5,2]]
注:以下计算方式中,把2个向量之间的汉明距离定义为2个向量不同的分量所占的百分比。
经计算得:
d = 0.6667 1.0000 0.3333
4 ジャカード距離 [理解]:
ジャッカード類似度係数: A と B の結合における 2 つのセット A と B の交差要素の割合は、2 つのセットのジャッカード類似度係数と呼ばれ、記号 J(A, B) で表されます。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-z5opAsN3-1664343761294) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t66j2f7j30ai04i0sr) .jpg)]](https://img-blog.csdnimg.cn/4dd14afb99524294b4410a428061d018.png)
Jaccard 距離: Jaccard 類似度係数とは対照的に、2 つのセット間の差は、2 つのセット内の異なる要素の全要素に対する比率によって測定されます。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-8JJAyRSf-1664343761296) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t65450oj30o204smxb) .jpg)]](https://img-blog.csdnimg.cn/134c1c67808044c68167769ce8357ffe.png)
例:
X=[[1,1,0],[1,-1,0],[-1,1,0]]
注:以下计算中,把杰卡德距离定义为不同的维度的个数占“非全零维度”的比例
经计算得:
d = 0.5000 0.5000 1.0000
5 マハラノビス距離【わかる】
下の図には2つの正規分布のグラフがあります。それぞれの平均はaとbですが、分散が異なります。グラフの点Aはどちらの母集団に近いでしょうか? 言い換えれば、A は誰に属する可能性がより高いでしょうか? 明らかに、A は左側の集団に近く、A と a の間のユークリッド距離は遠くなりますが、A が左側の母集団に属する確率はより高くなります。これがマハラノビス距離の直感的な説明です。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-fRIoP9Lz-1664343761297) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t67dr3cj30za0au78d) .jpg)]](https://img-blog.csdnimg.cn/c4dec3c30a3d494db073bee00fd51447.png)
マハラノビス距離はサンプル分布に基づく距離です。
マハラノビス距離はインドの統計学者マハラノビスによって提案され、データの共分散距離を表します。これは、2 つの位置サンプル セットの類似性を計算する効率的な方法です。
ユークリッド距離とは異なり、測定スケールに関係なく、さまざまなプロパティ間の関係が考慮されます。
**マハラノビス距離の定義: **母集団 G が m 次元母集団 (m 個の指標が検査される)、平均ベクトルが μ= (μ1, μ2,..., μm,)`、共分散行列であると仮定します。 ∑= (σij) 、
次に、サンプル X=(X1, X2,...,Xm,)` と母集団 G の間のマハラノビス距離は次のように定義されます。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-KdVJDgQp-1664343761297) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t6841bfj30ze086q5u) .jpg)]](https://img-blog.csdnimg.cn/1b110165c09144c9baaee83194b1f618.png)
マハラノビス距離は、同じ分布に従い、共分散行列が Σ である 2 つの確率変数間の差異の程度として定義することもできます。共分散行列が単位行列の場合、マハラノビス距離はユークリッド距離に簡略化されます。 ; 共分散行列が対角行列の場合、正規化ユークリッド距離とも呼ばれます。
マハラノビスの距離特性:
1.次元的に独立しており、変数間の相関の干渉を排除します。
2.マハラノビス距離の計算は母集団サンプルに基づいています。同じ 2 つのサンプルを取得し、それらを 2 つの異なる母集団に入れる場合、最終的に計算された 2 つのサンプル間のマハラノビス距離は通常異なります。共分散行列が異なる場合を除き、同じです。 2 つの集団がたまたま同じであることもあります。
3. マハラノビス距離の計算中、サンプル全体の数がサンプルの次元よりも大きいことが必要です。そうでない場合、得られるサンプル全体の共分散行列の逆行列は存在しません。この場合、単に使用します。ユークリッド距離の計算。
4. 条件が満たされ、サンプル全体の数がサンプルの次元より大きいが、共分散行列の逆行列がまだ存在しないという別の状況もあります (3 つのサンプル点 (3, 4) など)。 (5, 6)、(7, 8)、この状況は、3 つのサンプルがそれらが配置されている 2 次元空間平面内で同一線上にあるためです。この場合、ユークリッド距離計算も使用されます。
ユークリッド距離とマハラノビス距離:
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-fvQdKslr-1664343761298) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t6911xoj30xe0a8778) .jpg)]](https://img-blog.csdnimg.cn/d639858997c542caabf484bb68ee2d86.png)
例:
2 つのカテゴリ G1 と G2 があることがわかっています。たとえば、G1 は設備 A によって生産された製品であり、G2 は設備 B によって生産された同様の製品です。装置Aの製品品質は高い(例えば、検査指標は耐摩耗性である。損失μ2=75は、装置精度のばらつきσ2(2)=4を反映している)。
現在製品 G0 があり、測定された耐摩耗性は X0 = 78 です。この製品がどの装置で製造されているか調べてみてください。
感覚的にはX0とμ1(装置A)の絶対距離の方が近いのですが、最近距離原理に基づき、この製品は装置Aで製造されたものと判断すべきでしょうか?
分散に関連した距離を考慮し、X0 と G1、G2 の間の相対距離を d1、d2 とすると、次のようになります。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-oDEkLHTm-1664343761299) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t64may4j30v40ak440) .jpg)]](https://img-blog.csdnimg.cn/4491028094854dae9c7977ab376c8d86.png)
d2=1.5 < d1=4 であるため、この距離基準によれば、X0 は装置 B によって生成されたものと判断されるはずです。
設備 B で生産される製品の品質はより分散しており、X0 が 78 になる可能性が高くなりますが、設備 A で生産される製品の品質はより集中しており、X0 が 78 になる可能性は小さくなります。
この分散に対する距離判断がマハラノビス距離です。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-g0JT1wJ5-1664343761300) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8t6a16yvj30w40d8tbq) .jpg)]](https://img-blog.csdnimg.cn/744d58418e8d4b50bd1fa5eff5556967.png)
1.9 ケース 2: Facebook チェックイン場所の予測
学習目標
- 目標
- Facebook位置予測事例を通じて第1章の学習内容をマスターする
1 プロジェクトの説明
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-ZWbTZqDP-1664343761303) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8u5nj8stj30nu07gaio) .jpg)]](https://img-blog.csdnimg.cn/b35d00ea0ddc42cb83a53984498016af.png)
このコンテストの目的は、人がどこにサインするかを予測することです。このコンテストのために Facebook は、10 キロメートル×10 キロメートル、合計 100 平方キロメートルにわたる約 100,000 の場所を含む仮想世界を作成しました。指定された一連の座標について、ユーザーの位置、精度、タイムスタンプなどに基づいてユーザーの次のチェックイン位置を予測することがタスクとなります。データは、モバイル デバイスからの位置データに似るように作成されています。注意: 提供されたデータを使用してのみ予測を行うことができます。
2 データセットの概要
データの紹介:
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムが備わっている可能性があります。画像を保存して直接アップロードすることをお勧めします (img-1htKvqGU-1664343761304) (C:\Users\Administrator\Documents\assets\006tNbRwly1ga8u5nxn8qj30cy058js5) .jpg)]](https://img-blog.csdnimg.cn/07b28fcde0e744b89aa6d12ede1fbc47.png)
文件说明 train.csv, test.csv
row id:签入事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,这也是你需要预测的内容
公式ウェブサイト:https://www.kaggle.com/c/facebook-v-predicting-check-ins
3ステップ分析
- データの基本的な処理を実行します (ここで実行される処理の一部は良好な結果が得られない可能性があります。ここでは簡単に試しているだけであり、いくつかの特徴選択方法に基づいていくつかの特徴を処理できます)
- 1 データセット DataFrame.query() のスコープを縮小します。
- 2 便利な時間機能を選択する
- 3 チェックイン位置がn未満のユーザーを削除する
- データセットを分割する
- 標準化
- k最近傍予測
具体步骤:
# 1.获取数据集
# 2.基本数据处理
# 2.1 缩小数据范围(这个不是处理数据的技巧,只是因为我们的数据集太大了,我们使用了部分数据来做演示)
# 2.2 选择时间特征
# 2.3 去掉签到较少的地方
# 2.4 确定特征值和目标值
# 2.5 分割数据集
# 3.特征工程 -- 特征预处理(标准化)
# 4.机器学习 -- knn+cv
# 5.模型评估
4 コードの実装
- 1. データセットを取得する
# 1、获取数据集
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
facebook = pd.read_csv("./data/train.csv")
- 2. 基本的なデータ処理
# 2.基本数据处理
# 2.1 缩小数据范围
#(这个不是处理数据的技巧,只是因为我们的数据集太大了,我们使用了部分数据来做演示)
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s")#将该列数据转换为时间类型
time = pd.DatetimeIndex(time)#将时间类型数据转换为索引格式
facebook_data = facebook_data.copy()
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 2.3 去掉签到较少的地方(我们可以认为签到少的地方是异常值)
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"]>30]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy","hour", "weekday"]]
y = facebook_data["place_id"]
# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1,random_state=22)
- 3. 特徴エンジニアリング – 特徴の前処理 (標準化)
# 3.特征工程--特征预处理(标准化)
# 3.1 实例化一个转换器
transfer = StandardScaler()
# 3.2 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- 4. 機械学習 – knn+cv
# 4.机器学习--knn+cv
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 调用gridsearchCV
param_grid = {
"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=3)
# 4.3 模型训练
estimator.fit(x_train, y_train)
- 5. モデルの評価
# 5.模型评估
# 5.1 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)
meIndex(time)#時刻型データをインデックス形式に変換
facebook_data = facebook_data.copy()
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
5. チェックインの少ない場所を削除します (チェックインの少ない場所を外れ値として考えることができます)
place_count = facebook_data.groupby(“place_id”).count()
place_count = place_count[place_count[“row_id”]>30]
facebook_data = facebook_data[facebook_data[“place_id”].isin(place_count.index)]
6 特性値と目標値の決定
x = facebook_data[[“x”, “y”, “精度”,“時間”, “曜日”]]
y = facebook_data[“place_id”]
7 データセットを分割する
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1,random_state=22)
- 3.特征工程--特征预处理(标准化)
```python
# 3.特征工程--特征预处理(标准化)
# 3.1 实例化一个转换器
transfer = StandardScaler()
# 3.2 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- 4. 機械学習 – knn+cv
# 4.机器学习--knn+cv
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 调用gridsearchCV
param_grid = {
"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=3)
# 4.3 模型训练
estimator.fit(x_train, y_train)
- 5. モデルの評価
# 5.模型评估
# 5.1 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)