
目次
1. アプリケーション層
1. リクエストとレスポンス
この層には既製のプロトコルが多数あり、多くの場合、プログラマー自身がプロトコルを定義する必要があります。
設計プログラムを開発するときは、事前に綿密な計画を立てる必要があります
テイクアウト ソフトウェアを開き、販売者のリストを表示します。リストには多くの項目があり、各項目には販売者の名前、写真、肯定的な評価、あなたからの所在地、評価などの情報が含まれています。
これらの操作のために、次の設計を作成しました。
1. 現在のリクエストとレスポンスにどのような情報が含まれているかを明確にする(要件に従って)
リクエスト: ユーザー ID、ユーザーの現在位置
応答: いくつかのビジネス情報が含まれています
2. 具体的なリクエストとレスポンスのフォーマットを明確にする
例 1:

いわゆるクリア フォーマットは文字列の構築方法によって異なり、この文字列は TCP または UDP ペイロードとして送信できます。
一方、サーバーはこの文字列を解析して、ユーザー ID がカンマの前にあり、経度と緯度がカンマの後にあることを解析できます。

この時点で、応答文字列が構築されており、クライアントはこの形式に従ってそれを解析できます。
ネットワーク上で送信されるデータは本質的に文字列(正確にはバイナリの「文字列」)であり、Java オブジェクトなどのコンテンツを直接送信することはできません。
Java でコードを記述する場合、さまざまなオブジェクトが存在することがよくあります。
ただし、最後にデータを送信するときは、オブジェクトを(バイナリ)文字列に変換する必要があります[シリアル化]
データを受信するときは、(バイナリ) 文字列をオブジェクトに変換し直す必要もあります [逆シリアル化]
例 2:

使用!各加盟店を分割するには、各加盟店の情報を使用し、分割するには
例 3:

上記の方法から、リクエストとレスポンスの特定のデータ編成形式は非常に柔軟であることがわかります。プログラマは、必要に応じて編成できます。必要なのは、クライアントとサーバーが同じルールを使用することを確認することだけです。
2. 共通プロトコルフォーマット
カスタム プロトコル フォーマットは任意であるとは言いますが、過度に空想的な設計を避けるために、一部の人々が「ユニバーサル プロトコル フォーマット」を発明しました。これらのフォーマットを参照することで、プロトコルの設計について決定を下すことができます。重要な指導的役割
表現方法はたくさんありますので、ここでは重要なものをいくつか選んでご紹介します。
(1)xml
ペアのタグは「キーと値のペア」情報を表すために使用され、タグのネストはより複雑なツリー構造のデータを形成するためにサポートされています。

利点: XML は構造化データを非常に明確に表現します。
短所: データを表現するには多数のラベルを導入する必要があり、面倒に思われるだけでなく、多くのネットワーク帯域幅も消費します。
(2)json
json は最も人気のあるデータ編成形式です
これは本質的にキーと値のペアですが、xml よりもはるかにきれいに見えます。

json では、{ } はキーと値のペアを表すために使用され、[ ] は配列を表すために使用されます。
配列内の各要素には、数値、文字列、その他の { } または [ ] を指定できます。
利点: XML と比較して、表現されるデータははるかにシンプルで読みやすいため、プログラマーは結果を観察し、問題をデバッグすることが容易になります。
欠点: 結局のところ、キー名を送信するにはある程度の帯域幅が必要です。
json は改行に敏感ではないため、これらすべての内容が同じ行に配置されていれば、完全に合法です。
一般に、ネットワーク送信中、json は圧縮され (不要な改行とスペースが削除され)、すべてのデータが 1 行にまとめられて取得され、占有される全体の帯域幅が低くなります (可読性に影響します)。
(3)プロトバッファ
Google が提案した一連のバイナリ データのシリアル化メソッド
バイナリ メソッドを使用して、どの属性を表す特定のバイト数を合意するか
スペースを最大限に節約します(キーを送信する必要がなく、位置と長さに応じて各属性を区別します)
利点: 帯域幅を節約し、効率を最大化します。
欠点: バイナリ データは肉眼で直接観察できず、デバッグには不便で、使用が複雑です (データがどのようなものかを記述するために特別な proto ファイルを作成する必要があります)
これは主に、より高いパフォーマンス要件が必要なシナリオで使用されます。
2. トランスポート層
1、UDP
UDP の基本特性: コネクションレス、信頼性の低い伝送、データグラム指向、全二重
プロトコルを学ぶには、そのプロトコルの特徴を習得することはもちろん、プロトコルのメッセージ形式を理解する必要があります。

マストヘッドには何が入っているのでしょうか?それは一体何を意味するのでしょうか?
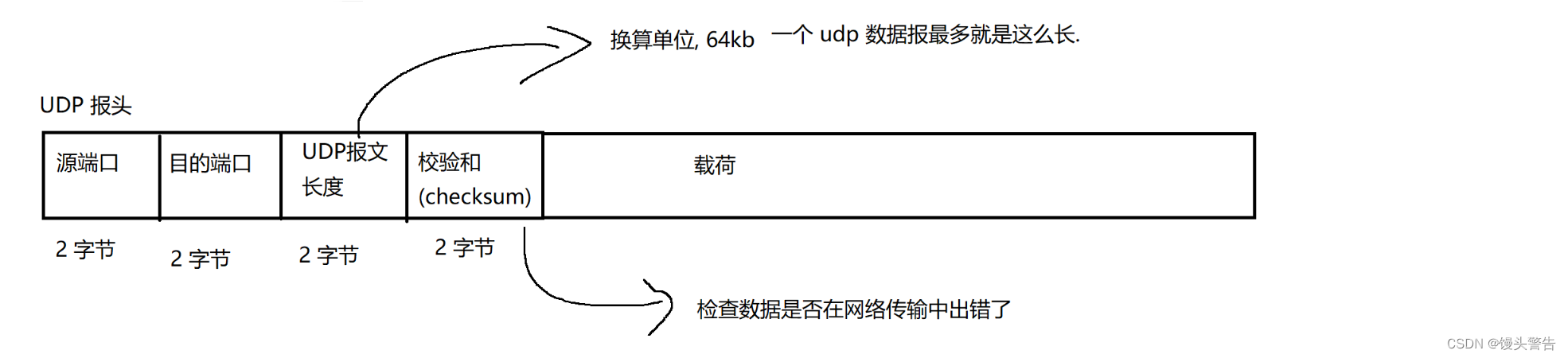
通信には 5 つのタプルが含まれます。
送信元ポート、宛先ポート、送信元IP、宛先IP、プロトコルタイプ
有効なポート番号の範囲は 0 ~ 65535 です。実際には、0 は使用されません。
このうち、1 ~ 1024 (ウェルノウン ポート番号) はシステムによって特別な意味が与えられているため、通常は使用をお勧めしません。
もちろん、1024 より前のポートを使用するプログラムを作成することもできます (プログラムには管理者権限が必要です)。
ネットワーク上でのデータ送信のプロセス中に、外部干渉によりデータが破損する可能性があります。
ネットワークデータは本質的に光信号・電気信号・電磁波です。
外部からの干渉を受けると、送信したいデータに0→1、1→0などのエラーが発生する可能性があります。
受信機はデータを受信した後、そのデータが不正なデータであるかどうかを確認する必要がありますが、チェックサムは簡単で効果的な方法です。
実際のチェックサムは単なる「長さ」ではなく、データの内容に基づいて生成され、内容が変化することでエラーを検知することができます。
UDP チェックサムはどのように実装されますか?
シンプルで粗雑な CRC チェック アルゴリズム (巡回冗長チェックサム) が使用されます
UDP データグラム内の各バイトを順番に蓄積し、蓄積された結果を 2 バイトの変数に保存します
追加していくと溢れてしまうこともありますが、溢れても問題ありません。
すべてのバイトが追加された後、最終的にチェックサムが取得されます
データを送信する際には、元のデータとチェックサムを一緒に送信し、受信側はデータを受信するとともに、送信側が送信したチェックサム(旧チェックサム)も受信します。
受信側では同様に計算し直して新しいチェックサムを求め、古いチェックサムと新しいチェックサムが同じであればデータ送信処理中とみなして、そうでない場合は送信処理中とみなします。データが間違っています
ただし、チェックサムが同じであってもデータが同じであるとは限りませんが、その可能性は比較的低いです。
より高い精度を達成できる検証用のアルゴリズムは他にもいくつかありますが、コストが高くなります。
2、TCP
(1) TCP プロトコルのセグメント形式:
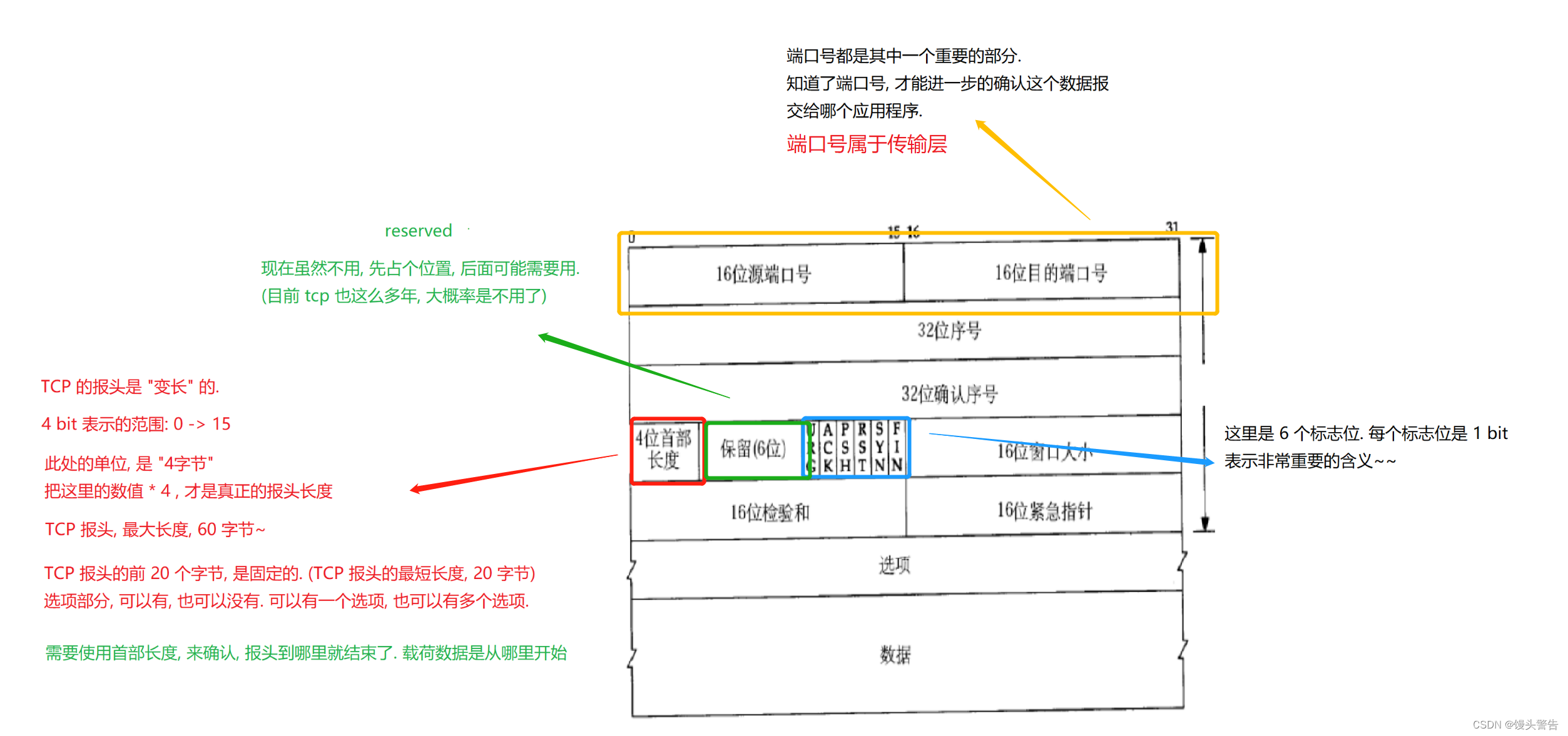
TCP の特性: 接続、信頼性の高い伝送、バイト ストリーム指向、全二重
信頼性の高い送信はカーネルによって実装され、コードを作成するときに認識することはできません (認識コストが低く、使用コストも低い)
(2) 確実な伝送の実装メカニズム:
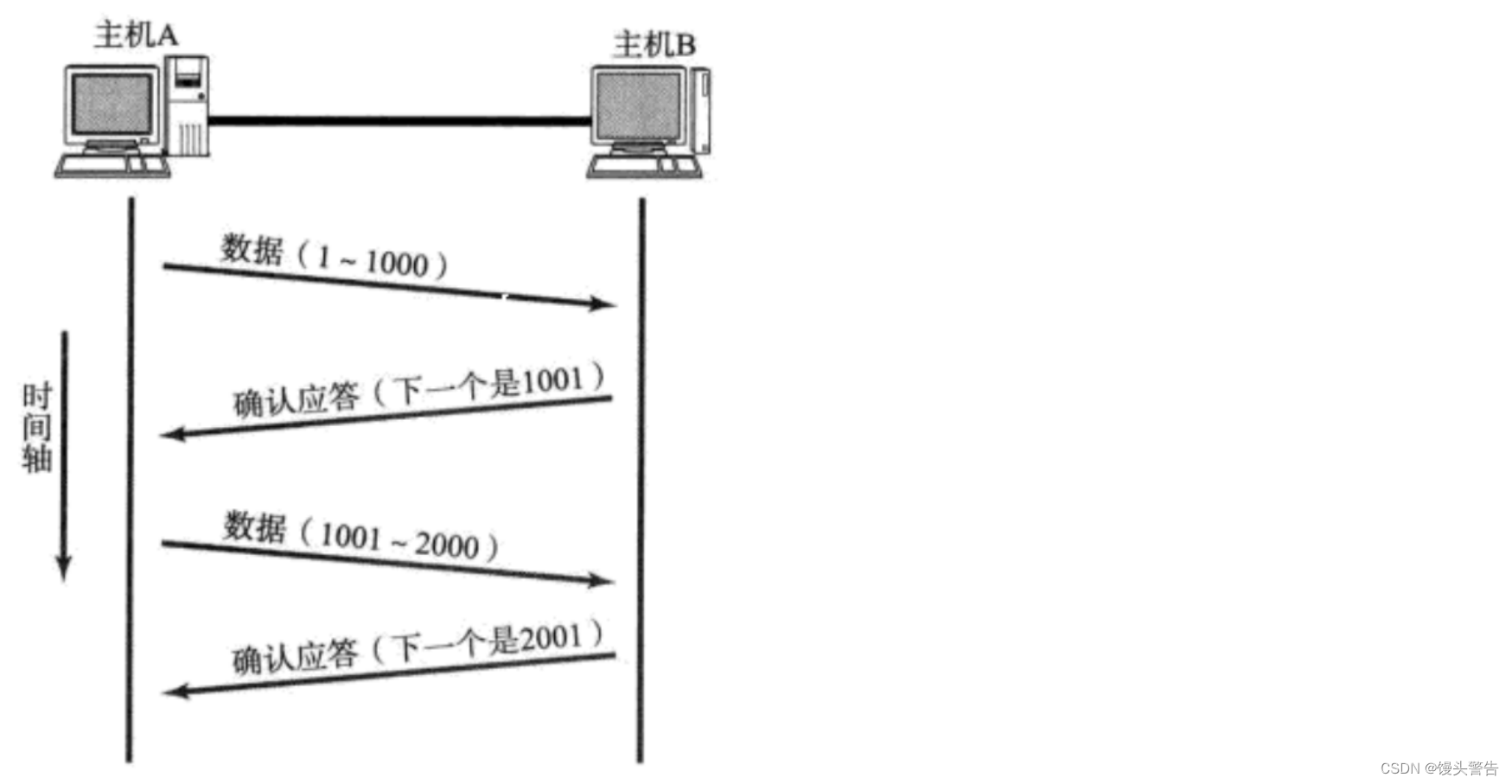
確認応答メカニズム (信頼性):
確認応答は「信頼性」を確保するための核となる仕組み
複数のデータを連続して送信すると、複数のデータが「最後に提供されたものから提供されたもの」の状況になる場合があります。つまり、1 つのデータグラムが最初に送信され、別のデータグラムが後で送信されますが、後のデータグラムが後で送信されます。最初に到着しました
なぜ「後者優先」の状況が起こるのでしょうか?
ネットワーク上には A --> B のパスが多数ありますが、2 つのデータグラムが A --> B の同じルートをたどるとは限りません。
さらに、各ノード (ルーター/スイッチ) はさまざまなレベルでビジー状態となり、このときの転送プロセスにも違いが生じます。
上記の問題を解決するにはどうすればよいでしょうか?
データに番号を付ける
TCP はバイト ストリームを指向しており、「バー」単位で送信されないため、バイトに番号を付けます。

(1) 「バー」ではなく、バイト数です。
(2) 応答メッセージも、受信データと同等ではなく、関連付けられている必要があります。
このバイト列の開始番号とバイトの長さがわかっていれば、各バイトの番号も自然にわかります。
このバイト列の最初のバイト番号を TCP ヘッダーに指定し、それをメッセージの長さと組み合わせるだけで、この時点で各バイトの番号が決まります。
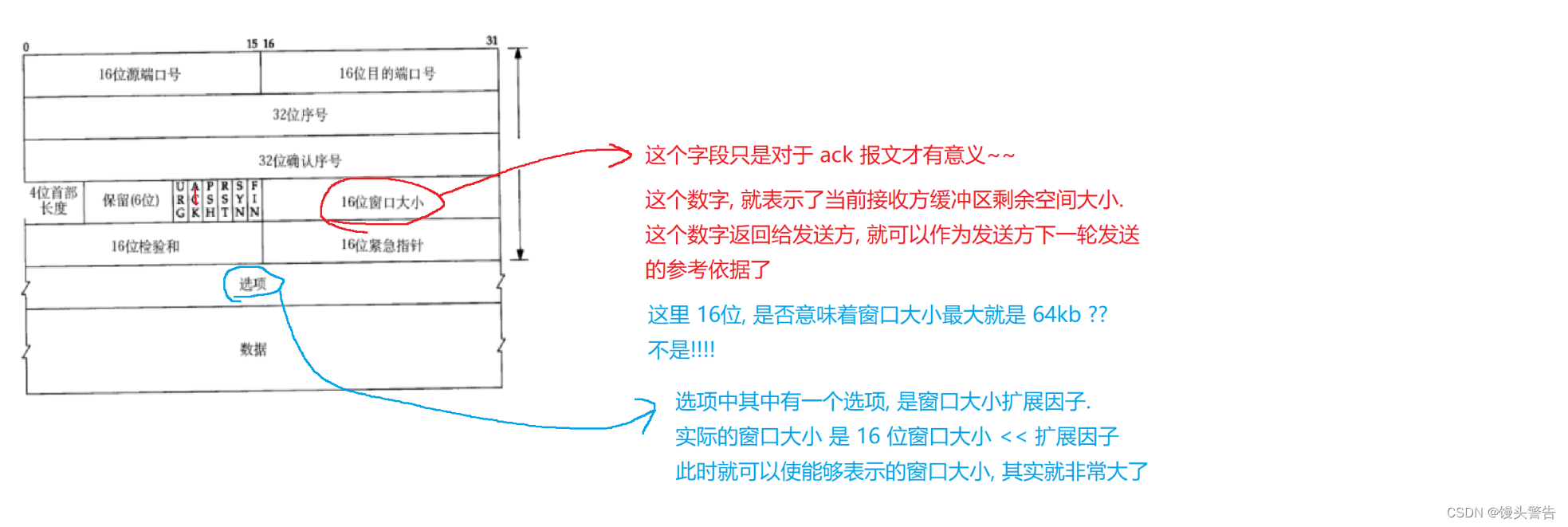
確認シーケンス番号の値は、受信した最後のバイトの番号に 1 を加えたものです。
前の構造図では、32 ビットのシリアル番号の部分に、このバイト列の最初のバイトの番号が格納されます。
データには、数バイトを含む TCP ペイロード データが保存されます。
32 ビットの確認シーケンス番号フィールドは、応答メッセージに使用されます。
現在のメッセージが通常のメッセージか確認応答メッセージかを区別するにはどうすればよいですか?
2 番目のフラグであるACKに注目して、6 つのフラグを確認してください。

ACK = 0 は、これが通常のメッセージであり、現時点では 32 ビットのシーケンス番号のみが有効であることを意味します
ACK = 1 は、これが応答メッセージであり、このメッセージのシーケンス番号と確認シーケンス番号が両方とも有効であることを示します。
確認メッセージのシーケンス番号と通常メッセージのシーケンス番号には相関はなく、自ホストが送信するデータの番号となります。
場合によっては、ack は応答メッセージを指すために使用されることもあります。
確認応答は、信頼性を確保するための TCP の中核的なメカニズムです。
タイムアウト再送信メカニズム (信頼性):
パケット損失: ネットワーク上では、データの一部が送信され、その後データが失われる可能性が非常に高くなります。
ルーター/スイッチは、多くのデバイスを接続する「トランスポート ハブ」として理解できます。
構造は複雑で、送信されるデータ量も不確実で、より多くのデータが送信される場合もあれば、より少ないデータが送信される場合もあります。
デバイスがビジー状態である場合、待ち時間が長すぎると新しいデータが破棄される可能性があります。
ネットワーク負荷が高くなると、ネットワークが混雑し、パケットが失われやすくなります。
パケットロスにはどう対処すればいいのでしょうか?
タイムアウト再送を行う
タイムアウト再送信は、確認応答の重要な補足に相当します。
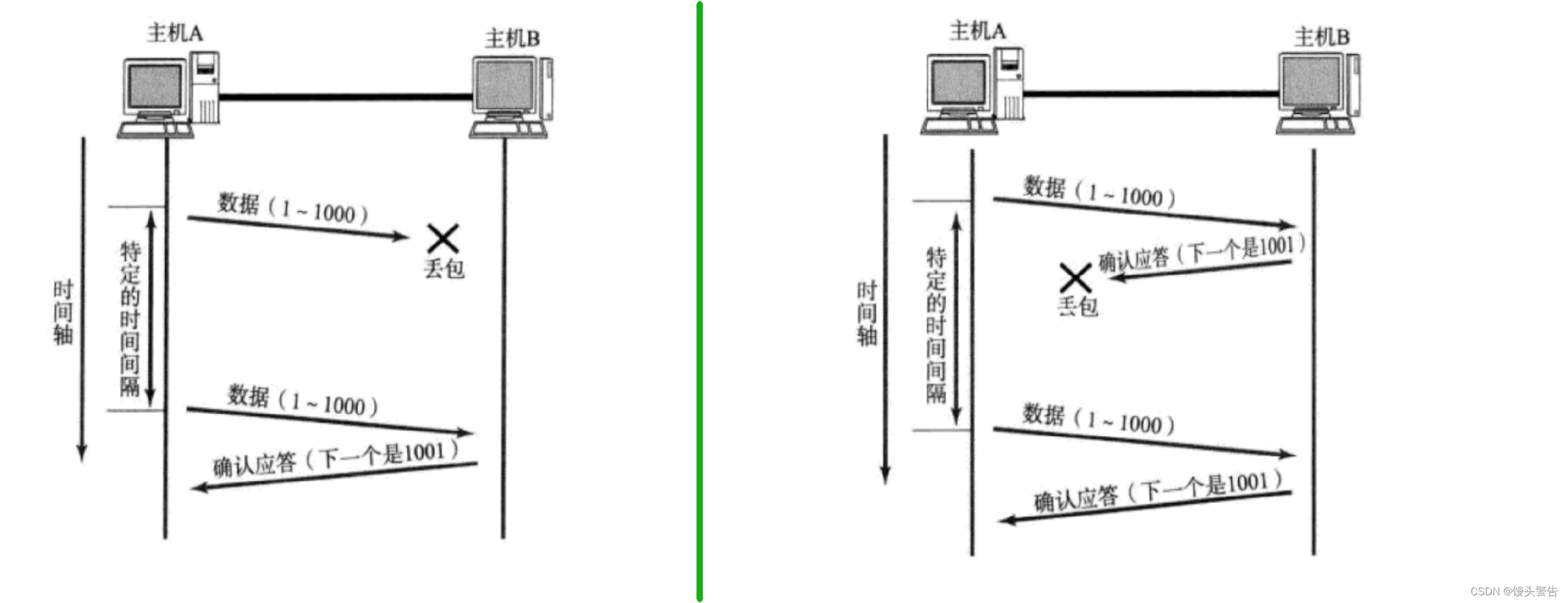
タイムアウト再送信には、上記の 2 つの状況があります。
1 つ目は送信メッセージ自体が失われる場合、2 つ目は応答メッセージが失われる場合です。
しかし、送信者はどちらの場合かを区別できません
区別できないので全て再送信してください。
しかし、2番目のシナリオでは、Bは同じメッセージを2回受信しましたが、このとき10元が転送されたと仮定しますが、再送信により20元が転送されたため、ここで問題が発生します
データを受信した後、受信側はデータの重複を排除し、重複したデータを破棄して、アプリケーションが inputStream.read を呼び出したときにデータの読み取りが繰り返されないようにする必要があります。
重複を削除するにはどうすればよいですか? 現在受信しているデータが重複しているかどうかを効率的に判断するにはどうすればよいですか?
TCPシーケンス番号を直接判断基準として使用する
TCPはカーネル内にソケットオブジェクトごとに「受信バッファ」とも呼ばれるキューに相当するメモリ空間を確保し、受信したデータはバッファ内に置かれ、シリアル番号に従ってソートされます。
シリアル番号に従って配置すると、後発先着の状況であっても、アプリケーションによって読み取られるデータが確実に順序どおりに配置されるようになります。
この時点で、新しく受信したデータが重複しているかどうかを簡単に知ることができます。
データを読み取った後、データはキュー内に残りますか?
これには再び生産者・消費者モデルが関係します。
データを受信した後、受信側のネットワーク カードは、(カーネル内の) 対応するソケット オブジェクトの受信バッファにデータを置きます。
アプリケーションは read を呼び出して、この受信バッファからデータを消費します。read がなくなったら、キューからデータを取得できます (通常、read は読み取り後にデータを削除します)。
再送信中にデータが転送されるのはなぜですか?
パケットロスは本質的に確率の問題です
パケット損失の確率が 10%、送信成功の確率が 90% であると仮定すると、2 回連続してパケット損失が発生する確率はわずか 1% です。
再送信の回数が増えると、送信が成功する全体的な確率が高くなります。
待機タイムアウトはどのくらいですか?
この値を特別に覚える必要はありません
タイムアウトは固定値ではなく、タイムアウト ラウンドが増加するにつれてさらに増加します。
再送信回数が増えると待ち時間が長くなります。
これは、現在、通常の状況では 2 回目の再送で再送が成功する確率が高いと考えられているためです。複数回の再送が失敗した場合、現在のネットワーク自体のパケット損失率がすでに非常に高いことを意味します。重大な欠陥
この時点で、頻繁な再送信は労力の無駄であり、時間間隔を延長すると、ネットワークを回復する余地も残ります。
ただし、タイムアウト再送回数は無制限ではなく、再送回数が一定のレベルに達すると、TCP 接続の「リセット」が試行されます。
これには TCP リセット メッセージが含まれます

RST = 1 の場合、リセット メッセージを意味します。ネットワークに重大な障害が発生した場合、リセット操作/リセット操作は成功せず、最終的には接続を放棄する必要があります。
接続管理メカニズム (信頼性):
接続管理とは、端的に言えば次の 2 つのことです。
1. 接続を確立します (3 ウェイ ハンドシェイク)。
2.切断(4回振る)
3回の握手:
握手:handshake
挨拶データ (このデータにはビジネス情報は含まれません) を送信し、その挨拶を使用して特定のシナリオをトリガーします
接続を確立するプロセスを完了するには、A と B が 3 回挨拶するためのデータが必要です。

これら 4 つの対話が完了すると、接続が確立され、双方が相手に関する情報を保存します。
4回に見えますが、真ん中の2つを1つにまとめることができます

なぜ合併するのか?
合併後は、カプセル化や分離の工程が省略され、コストが削減され、効率が向上しますので、可能であれば原則として合併します。
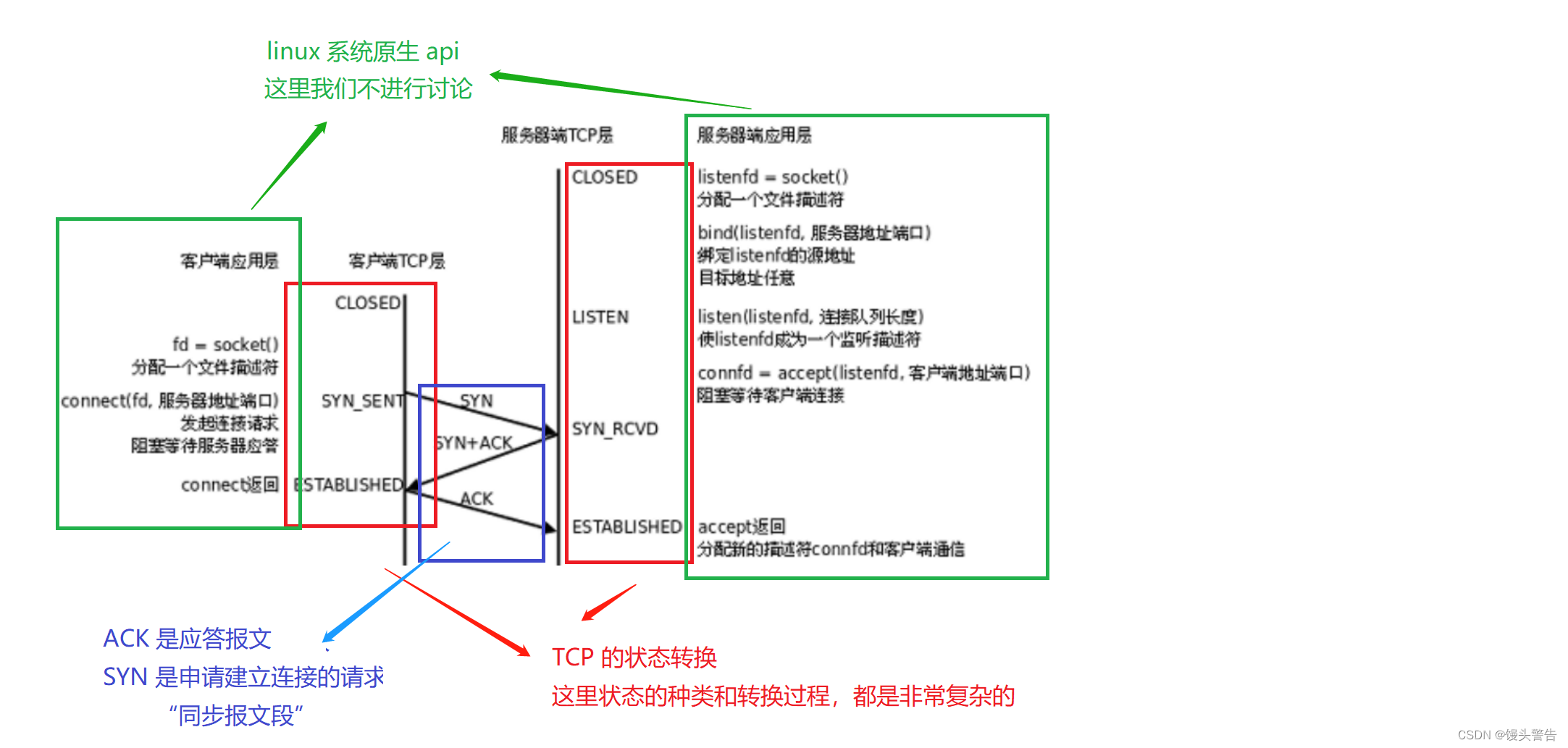
SYN は接続を確立するためのリクエスト、「同期セグメント」です
SYN = 1 の場合、それは同期セグメントであり、あるホストが別のホストとの接続を確立しようとしていることを意味します。
TCP スリーウェイ ハンドシェイクのプロセスは何ですか?

この写真は、スリーウェイ ハンドシェイクのプロセスを生き生きと表しています。
スリーウェイ ハンドシェイク、最初の SYN はクライアントによって開始される必要があります

このコードは 3 ウェイ ハンドシェイクを開始し、新しい操作が完了すると 3 ウェイ ハンドシェイクが完了します。
スリーウェイ ハンドシェイク。これはカーネルによって行われる作業であり、アプリケーションはここに介入できません。
同時に、サーバーは 3 ウェイ ハンドシェイクにアプリケーション層のコードを関与させる必要はなく、プロセスが対応する TCP インターフェイスにバインドされていれば、3 ウェイ ハンドシェイクはカーネル内で自動的に完了します。 、コードはどのように書かれているかに関係なく、
![]()
3 ウェイ ハンドシェイクが完了すると、クライアントとサーバーの両方が接続を形成します。
この時点で、accept は戻り、接続キューから head 要素を取り出し、さらにその中のソケット オブジェクトを取得してピアと通信することができます。
ただし、accept は 3 ウェイ ハンドシェイク プロセスには参加しません。
シングルスレッド TCP サーバーでは、サーバーが最初のクライアントを処理しているとき、2 回目に accept を呼び出すことはできませんが、カーネルの動作には影響しません。カーネルは 2 番目のクライアントとの 3 ウェイ ハンドシェイクを完了しており、形成されたオブジェクトは接続キュー内にあります。
つまり、接続は形成されていますが、誰もキューから接続を取得していません。受け入れジョブは、キューから要素を取り出すことです。
3ウェイハンドシェイクにはどのような意味があり、どのような目的を達成するためのものなのでしょうか?
スリーウェイ ハンドシェイクも信頼性を確保するための仕組みです。
TCP が信頼性の高い伝送を保証するには、ネットワーク パスがスムーズであることが信頼性の高い伝送の前提条件です。
TCP の 3 ウェイ ハンドシェイクは、ネットワークへの通信がスムーズであるかどうかを確認し、各ホストの送受信能力を確認するために行われます。
これは、地下鉄が特定の路線で起こり得る故障を防ぐために毎朝空の電車を運行するのと同じです。
握手は3回、なぜ3回も?
正確に 3 回行うと、双方の送受信機能が正常であることを確認できます。
双方向ハンドシェイクではデバイスの通信機能が正しいことを検証できますが、サーバーは検証に合格した情報を知る方法がありません。
4回でもいいけど、必要はない(途中2回に分ける)1回で十分、結合できるなら結合する、2回に分けると効率が悪くなる
3 ウェイ ハンドシェイクには「メッセージ ネゴシエーション」の効果もある
通信にはいくつかのパラメーターが含まれており、双方が一貫性を保ち、ネゴシエーションを通じて集合的なパラメーターを決定する必要があります。
TCP 通信プロセス中に、実際にはネゴシエートする必要がある情報がたくさんあります。
たとえば、両当事者のシリアル番号はどこから始まるのでしょうか?
これは、メッセージのシーケンス番号が 2 つの接続間で大きく異なる可能性があるため、メッセージがこの接続に属しているかどうかを判断しやすくするためです。
例: ネットワーク上で送信されたメッセージが最初に到着する場合があります。極端な場合には、特定のメッセージが長時間遅れる場合があります。メッセージが相手側に到着した時点で、サーバーとクライアントは以前の接続を切断しています。これは再接続です。接続が確立されました。
このとき、シーケンス番号により、これが以前の接続からのメッセージであることが明確に識別でき、破棄できます。
要約すると、3 ウェイ ハンドシェイクの本来の目的は 2 つあります。
(1) 道を尋ね、通信が円滑に行われているか、双方の送受信能力が正常かどうかを確認します。
(2) クライアントとサーバーがメッセージ送信に同じパラメータを使用するように、必要なパラメータをネゴシエートします。
4 つの波:
接続中、通信の両当事者は相手側の関連情報をメモリに保存します。
ただし、接続が不要になった場合は、上記のストレージ スペースを時間内に解放する必要があります。
4 回手を振るプロセスは、3 回手を振るプロセスと非常に似ています。
3 つのウェーブはクライアントによって開始される必要があります。4 つのウェーブは (ほとんどの場合) サーバーまたはクライアントによって開始されます。

FIN は 6 つのフラグの 1 つです
FIN = 1 の場合、メッセージセグメントの終わりを意味します

上記の 4 つの手順を完了すると、接続は使用されなくなり、双方が自分のスペースを解放してピアのメッセージを保存できるようになります。
なぜ4回も手を振るのでしょうか?3回でもいいですか?
4 回手を振れば確かに 3 回できる場合もありますが、そうでない場合もあります。
FIN のトリガーはアプリケーション コードによって制御され、socket.close() が呼び出されるか、プロセスが終了すると、FIN がトリガーされます。
一方、ACK はカーネルによって制御され、FIN を受信するとすぐに ACK が返されます。
 このクローズがいつ実行されるかを言うのは難しく、コードの記述方法によって異なります。
このクローズがいつ実行されるかを言うのは難しく、コードの記述方法によって異なります。
上記のコードでは、close が非常に迅速に実行されるため、クライアントが切断されるとすぐにサーバーがそれを感知し、ループを終了し、close をトリガーします。
ただし、サーバーが他の多くの仕上げ作業を行う必要がある場合、close の実行は実際には非常に遅くなります。
close がすぐにトリガーされると、前の ACK とマージされる可能性があります。
close のトリガーが遅い場合は、前の ACK とマージできません。
サーバーが閉じなかったらどうなるのでしょうか?
この時点で、サーバーの TCP は CLOSE_WAIT 状態になっています。

サーバー側から見ると、ここでの接続は閉じられていませんが、正常に使用できなくなります。
現在のソケットで読み取り操作を実行するとき、データがまだ読み取られていない場合 (バッファーにデータがまだある場合)、通常どおりに読み取ることができます。データが読み取られている場合は、この時点で EOF が読み取られます (バイト ストリーム、戻り値 - 1。scanner.hasNext の場合、false になります)
現在のソケットで書き込み操作を実行すると、例外が直接トリガーされます。
いずれにせよ、接続はもう役に立たないため、閉じることが唯一の選択肢です
より極端なケースでは、たとえば、コードに BUG が記述されている場合、close が忘れられます。
このとき、クライアント側から見ると、相手のFINが長期間受信されていないため、待機することになります。
長時間待機できない場合は、その時点で接続が一方的に破棄され、クライアントは保存していたピア情報を直接削除して解放します。
リソースを解放する際には、双方がスムーズに解放できることが最善ですが、それができない状況の場合でも、クライアントの一方的な解放には影響しません。
通信中にパケットロスが発生した場合はどうすればよいですか?
これにはタイムアウト再送信も含まれます。
3 ウェイ ハンドシェイクと 4 ウェイ ウェーブには再送信メカニズムもあります。
可能な限り再送信しますが、それでも連続して再送信に失敗した場合は、一方的に接続が解放されます。
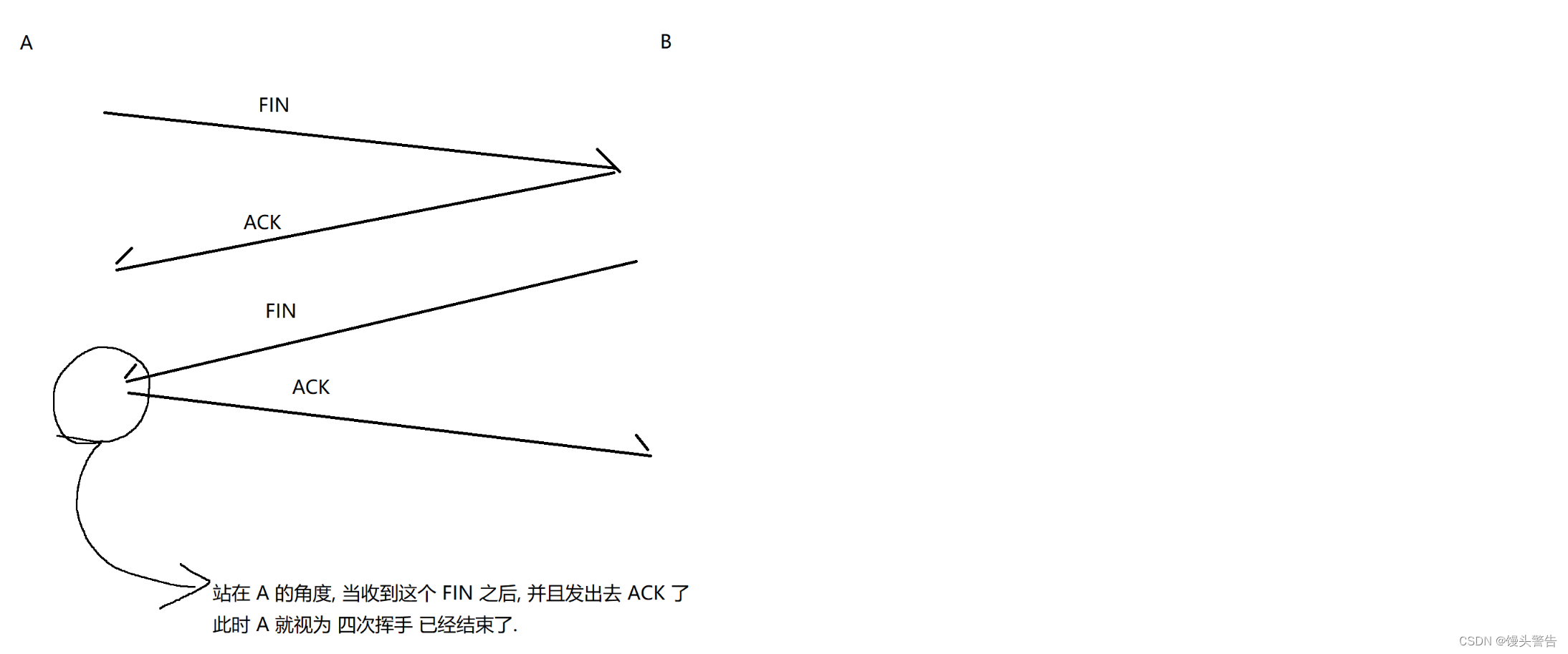
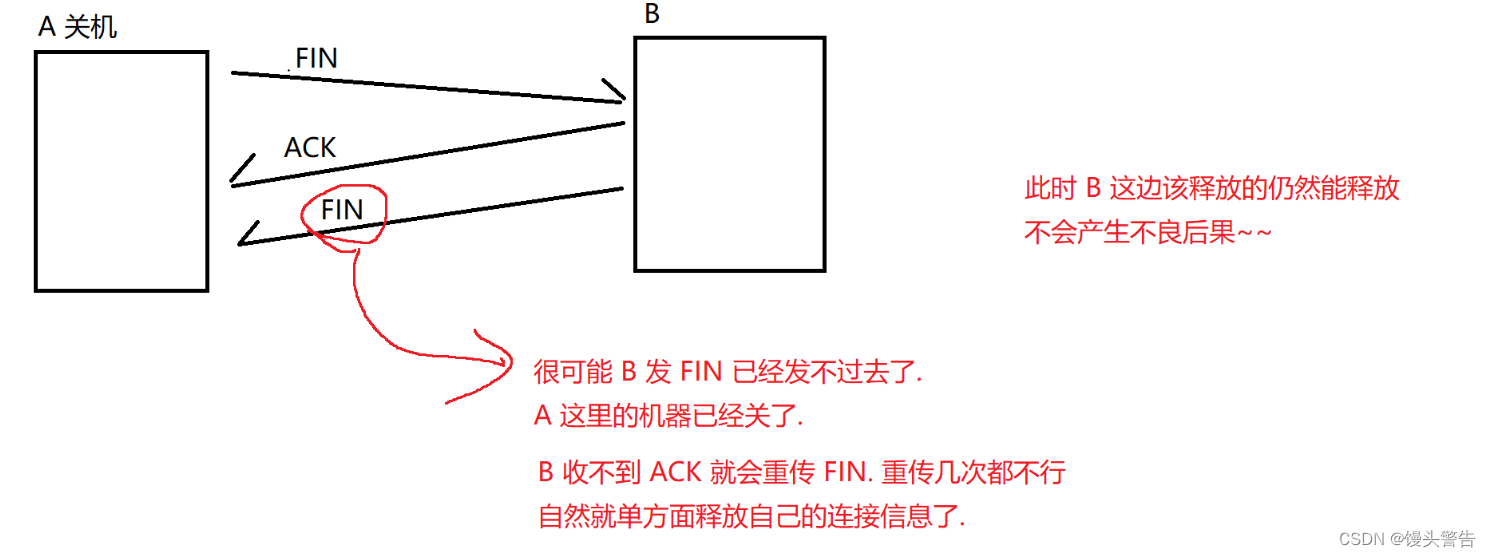
FIN/ACK の最初のセットが失われた場合、A は FIN を直接再送信できます。
2 番目の FIN/ACK セットが失われた場合は、ACK 損失に焦点を当てます。
図の丸で囲った部分ですが、このときAさんは直接接続を解除できますか?
いいえ、最後の ACK がまだ失われている可能性があるためです。
最後の ACK が失われた場合、B は FIN を再送信します。
このとき、A がコネクションを解放していると、再送された FIN に対して誰も ACK できなくなります。
したがって、最後の ACK を送信した後、A をしばらく待つ必要があります (主に、待機プロセス中に相手が再送信された FIN を受信するかどうかを確認するためです。一定時間待っても、相手は FIN を再送信していません) .FIN、相手がACKを受信したものとみなされます)
この時点で、A は正しく接続を解放できます。
A は接続が解放されるまでどのくらい待ちますか?
待ち時間はネットワーク上の任意の2点間の最大伝送時間(MSL) ※2
タイムアウト再送信は MSL 以下でなければなりません
タイムアウトが MSL に達すると 100% のパケットが失われたことになり、タイムアウトを大きく設定しても意味がありません。
極端なケースもあります。たとえば、A が 2MSL 時間待機している間に、B が FIN を何度も再送信し、これらの FIN が (理論上) 失われます。
もし本当にこのような状況が発生した場合、現在のネットワークには重大な障害が発生しているはずですが、この時点では「確実に伝送できる」という前提条件が満たされていないため、Aが一方的にリソースを解放しても問題はありません。
スライディングウィンドウ機構(効率):
伝送効率の向上(正確には、確実な伝送を前提にTCPの効率を上げすぎないようにする)(それを補う)
スライディング ウィンドウを使用すると、TCP を UDP より高速にすることはできませんが、その差を縮めることはできます。
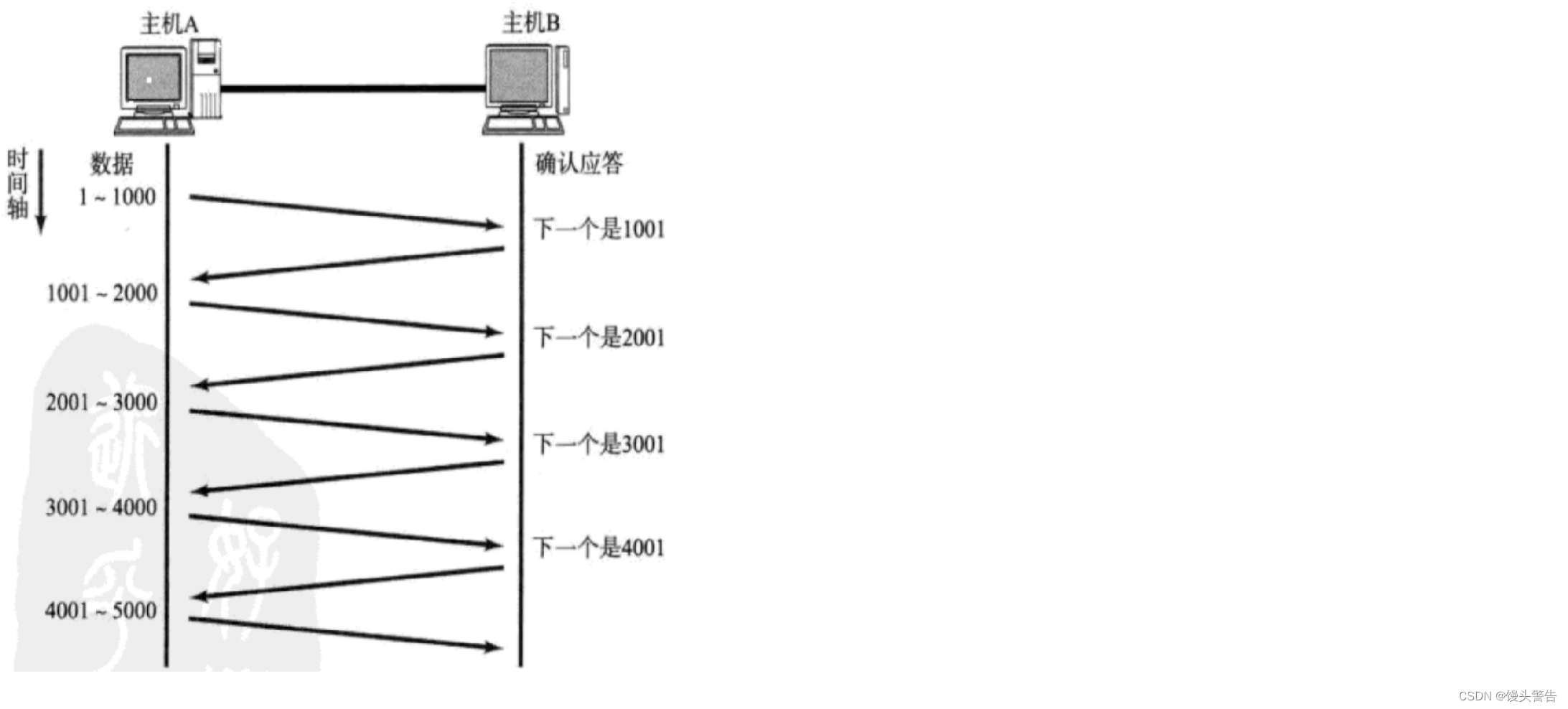
スライディング ウィンドウがないため信頼性は確保されますが、ACK の待機に多くの時間がかかります。
スライディングウィンドウを使用する目的は、上記の待ち時間を短縮することです。
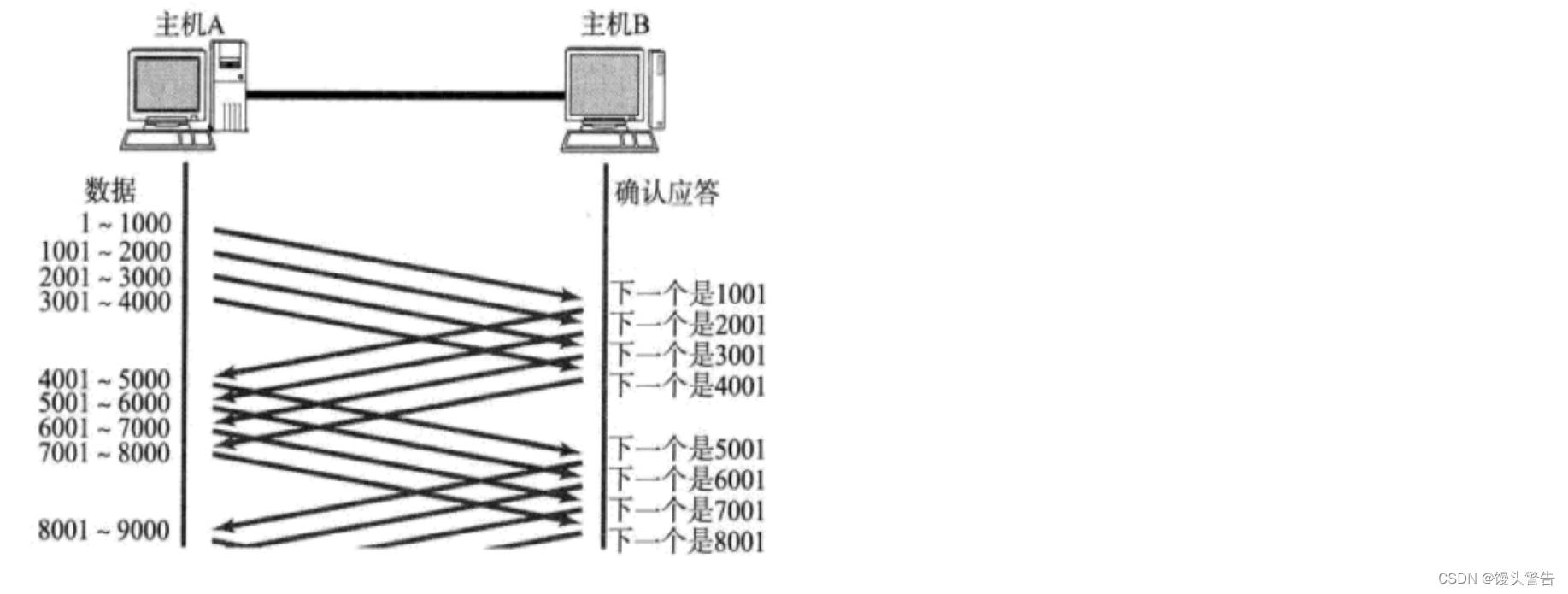 一連のデータを一度に送信します。この一連のデータを送信するプロセス中、ACK を待つ必要はなく、単に転送するだけです。
一連のデータを一度に送信します。この一連のデータを送信するプロセス中、ACK を待つ必要はなく、単に転送するだけです。
このとき、4回のACKを待つのに「1回の待ち時間」だけを使用したのと同等になります。
ACKを待たずに一度に送信できるデータ量を「ウィンドウ」と呼びます。
ウィンドウが大きいほど、バッチで送信されるデータが大きくなり、効率が高くなります。
ただし、ウィンドウを無限に大きくすることはできず、無限に大きくすると、ACK をまったく待たなくてもよいことになり、この時点では信頼性の低い送信とほぼ同じになります。
無限大だと受信機が対応しきれなくなったり、途中のネットワーク機器が耐えられなくなったりする可能性があります。

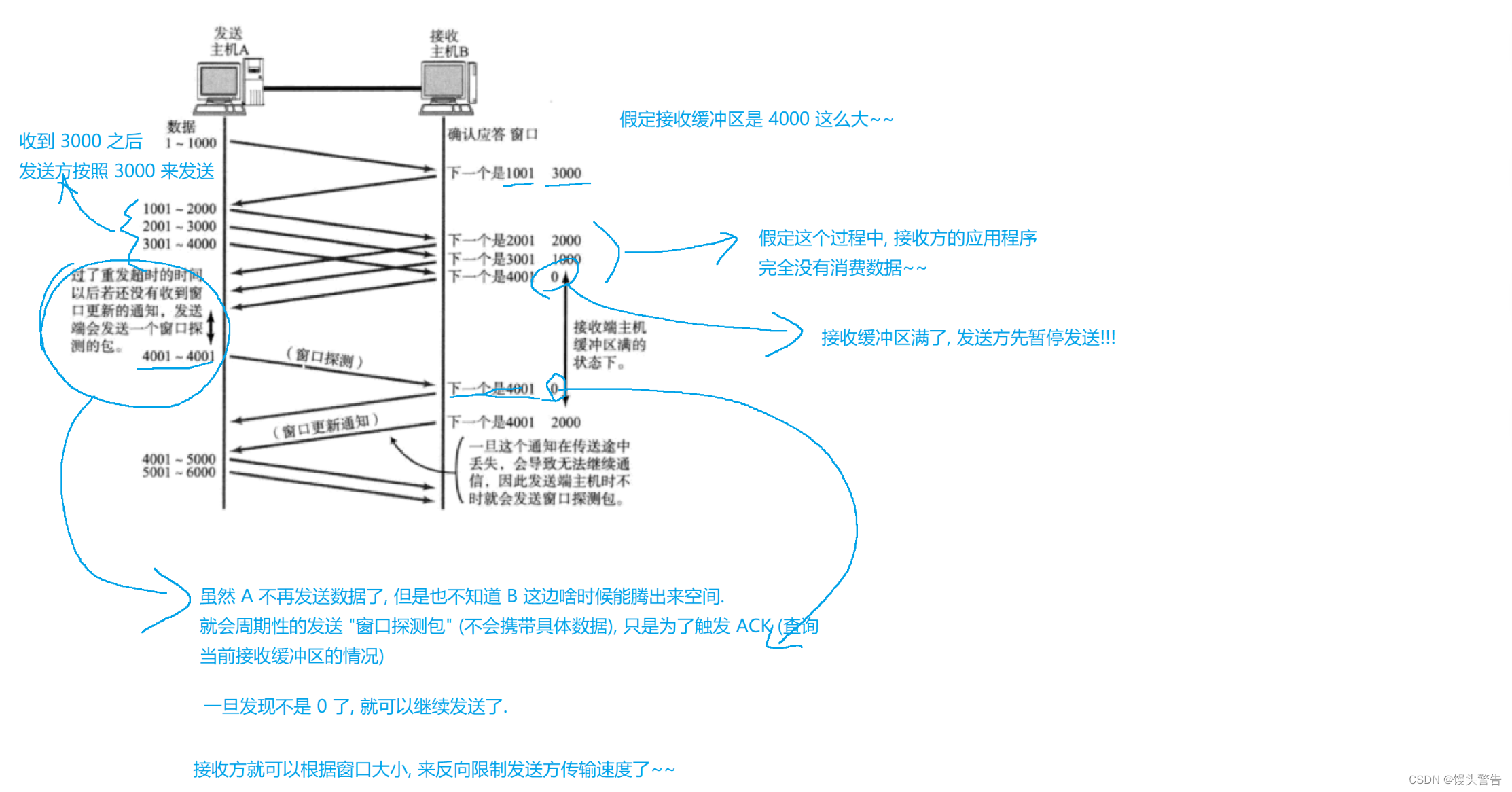
現在、A は 1001 ~ 5000 のデータをバッチで B に送信し、対応する ACK が 4 回返されるまで待つ必要があります。
これら 4 つの ACK の到着順序も最初と最後です。
2001 がホスト A に到達したとき、A は次のメッセージを送信し続ける必要がありますか? それとも、A は次のメッセージの送信を続ける前に、5001 が到着するまで待つ必要がありますか?
A は 2001 の ACK を受信後、すぐに 5001 ~ 6000 のデータを送信しますが、このとき A が待っている ACK は 3001 ~ 6000 です。
まだ 4 つの ACK を待っていますが、1 グリッド前に移動しました
感覚的には窓が一段下がったように見えます。
スライディング ウィンドウは鮮やかな比喩であり、基本的にはデータをバッチで送信することです。
これにより、従来よりも待ち時間が短縮され、効率がある程度向上します(ただし、UDP よりも向上するわけではありません)。
さて、このバッチ方式で送信した場合、途中でパケットが失われた場合はどうすればよいでしょうか。
TCP の場合、効率の向上が信頼性に影響を与えるべきではありません。
2 つの状況:
(1) データが失われる
(2) ACKロスト
1. ACK が失われました
ACK が失われた場合は、何も処理する必要はありません。これも正しいことです。
2001 確認シーケンス番号。1 ~ 1000 を含む、2001 年より前のすべてのデータが受信されたことを示します。
A は 1001 の ACK を受信しませんでしたが、2001 の ACK で 1001 の意味がカバーされます。
すべての ACK が失われる (重大なネットワーク障害が発生する) 場合を除き、失われるのは ACK の一部だけであり、信頼性の高い送信には影響しません。
2. データグラムが失われる

このとき再送が必要です
1001 ~ 2000 が失われた後、データ 2001 ~ 3000 が B に到達し、B から返される確認シーケンス番号は 1001 のままです。
次に、B は A にデータ 1001 を要求します。
後続の A から B へのデータはスムーズに送信できますが、データ 1001 が利用できない限り、B は常に A からのデータ 1001 を要求します (返される ACK 確認シーケンス番号は常に 1001 です)。
A は、B から 1001 を要求するデータを連続して数回受信すると、1001 が失われたことを理解し、1001 ~ 2000 のデータを再送信します。
再送された 1001 が B に到達すると、B から返される ACK は 7000 です。
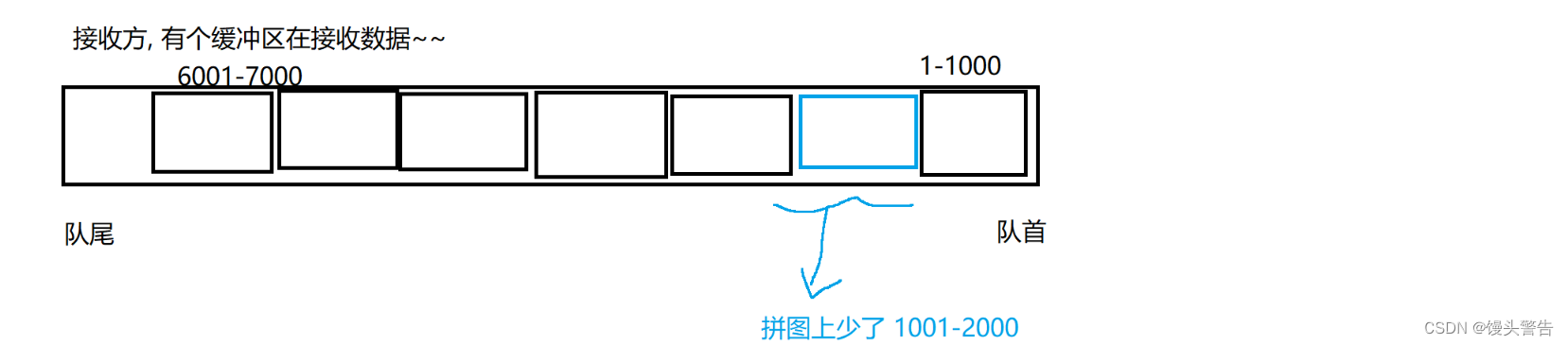
受信バッファにこのブロックがない場合、返される ACK は常に 1001 データグラムを要求します。1001 データグラムが追加されると、1001 ~ 2000 以降のデータは再送信する必要はありません (すべてバッファ内に留まります)。
次に、次のデータに欠落がないかを確認し、欠落があれば該当するデータを要求し、欠落がなければバッファ内の最後のデータの次のデータを要求します。
このとき、最小限のコストでデータの再送を完了することと同等となる。
(失われたデータのみ再送信され、他のデータは繰り返されません)
これを高速再送信と呼びますが、これはタイムアウト再送信とスライディング ウィンドウの下で生成される変形操作を組み合わせたものですが、本質的には依然としてタイムアウト再送信です。
スライディング ウィンドウは、必ずしも TCP の使用を意味するものではありません。
通信相手が大規模なデータを送信する場合は、スライディング ウィンドウ (高速再送信) にする必要があります。
通信する双方が送信するデータのサイズが比較的小さい場合、この時点ではスライディング ウィンドウは使用されません (タイムアウト再送信)。
フロー制御機構(信頼性):
引き違い窓の補完として
スライディング ウィンドウでは、ウィンドウが大きいほど伝送効率は高くなりますが、ウィンドウを無限に大きくすることはできません。ウィンドウが大きすぎると、受信機が処理できなかったり、伝送の中間リンクが処理できなかったりする可能性があります。それを処理するために。
これにより、パケット損失と再送信が発生し、ウィンドウは効率を向上させるものではなく、実際には影響を与えます。
フロー制御は、スライディング ウィンドウにブレーキをかけることで、ウィンドウが大きくなりすぎて受信側が処理できなくなることを回避します。
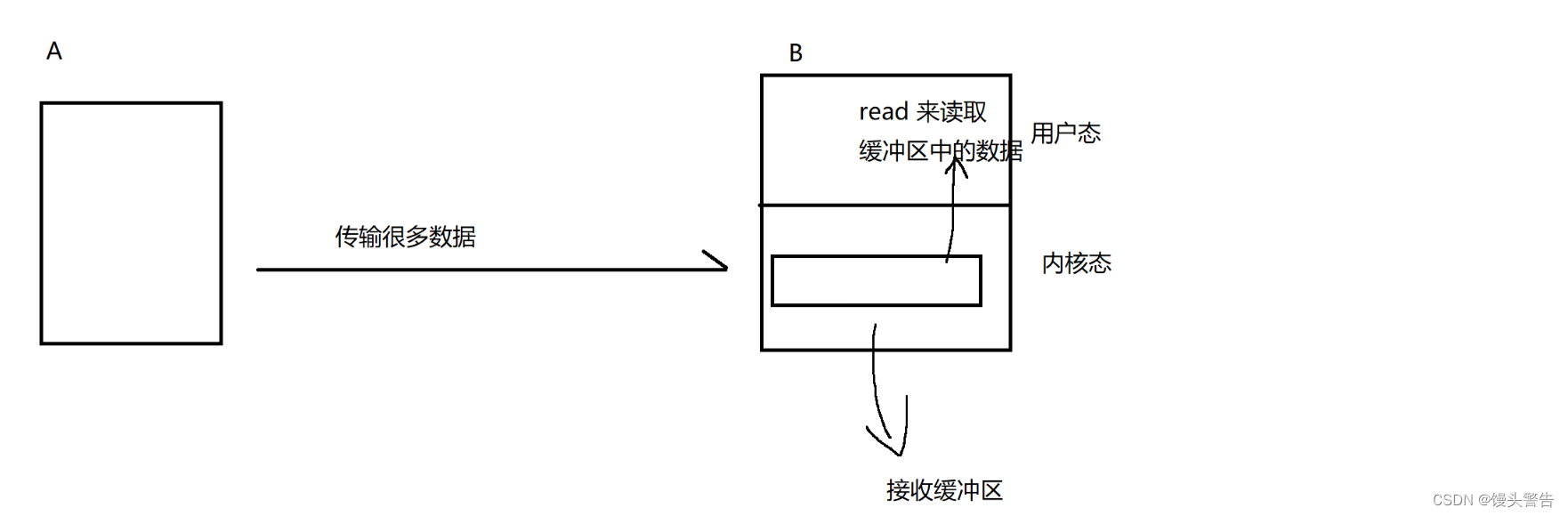
これは生産者/消費者モデルです。
ここの生産速度は非常に速いですが、ここBの消費速度が追いつきません。
受信バッファはどんどん増えていき、最終的にはいっぱいになってしまい、いっぱいになった後もデータを送信し続けるとパケットロスが発生します。
そこで、受信側の処理能力に応じて、送信側の送信速度(ウィンドウサイズ)を制限するのがフロー制御です。
受信機の処理速度を測定するにはどうすればよいですか?
ここでは、受信バッファの残り容量を尺度として使用します。
残りのスペースが大きいほど、アプリケーションはデータをより速く消費します
ここで、受信バッファの残りのスペースは、送信側の次のデータ送信のウィンドウ サイズの基準として、ACK メッセージを通じて送信側に直接フィードバックされます。
輻輳制御メカニズム (信頼性):
全体的な伝送効率はバレル効果であり、最短のボードに依存します。
A から B にデータを送信するプロセスでは、多くのスイッチ/ルーターを通過する必要があり、比較的長い送信リンクが形成されます。
転送能力が特に劣るリンクが途中にある場合、A の送信速度はここでのしきい値を超えてはなりません。
中間デバイスの転送能力を具体的に測定するにはどうすればよいですか?
ここでは、中間デバイスの転送能力を定量化するのではなく、「実験的」アプローチを採用して動的に調整し、適切なウィンドウ サイズを生成します。
中央のすべての機器を全体として扱います
(1) 送信ウィンドウを小さくし、送信がスムーズであればウィンドウサイズを大きくしてください。
(2) ウィンドウを大きくして送信し、送信中にパケットが失われる(輻輳が発生する)場合は、ウィンドウを小さく調整してください。
このようにして、ネットワーク環境の動的な変化にもうまく適応できます。
輻輳ウィンドウ: 輻輳制御メカニズムで使用されるウィンドウ サイズ
TCP では、輻輳制御は具体的には次のように展開されます。
1. スロースタート: 通信が最初に開始されると、最初に水をテストするために非常に小さなウィンドウが使用されます。
ネットワークが混雑して大量のトラフィックが発生すると、豊かでないネットワーク帯域幅が悪化するためです。
2. 指数関数的増加: スムーズな伝送の過程で、輻輳ウィンドウは指数関数的に増加します (*2)
指数関数的な増加率は非常に速いため、無制限にすることはできません。そうしないと、非常に大きな値が表示されます。
3. 線形増加: 指数関数的増加 輻輳ウィンドウがしきい値に達すると、指数関数的増加から線形増加 (+ n) に変換されます。
ここでの指数関数的増加と線形増加は、送信のラウンドに基づいています。
例: 指定されたウィンドウ サイズが 4000 であるため、4000 個分のデータを送信すると、このラウンドは終了し、ACK を受信した後、データを送信し続けて次のラウンドに入ります。
線形成長は成長でもあり、送信速度はどんどん速くなり、あるレベルに達するとネットワーク伝送の限界に近づき、パケットロスが発生する可能性があります。
4. 輻輳ウィンドウが小ウィンドウに戻る: ウィンドウ サイズが増加すると、送信中にパケット損失が発生した場合、現在のネットワークが輻輳していると考えられ、このときウィンドウ サイズは元の小ウィンドウに調整され、以前の指数関数的な増加 + 線形の増加に戻り続けます。増加のプロセスに加えて、しきい値も現在の輻輳ウィンドウ サイズに基づいて調整されます。

輻輳ウィンドウは、このプロセス中に常に変更および再調整されるプロセスです。
このような調整は、変化するネットワーク環境にうまく適応できます。
もちろん、ここでもパフォーマンスが大幅に低下します。
スロースタートに戻すたびに通信速度が大幅に低下します。
したがって、輻輳制御の背後でいくつかの最適化アルゴリズムが生まれました(スモールウィンドウ時間を可能な限り短縮する)。
実際の送信者ウィンドウ = 最小 (輻輳ウィンドウ、フロー制御ウィンドウ)
輻輳制御と流量制御は共にスライディング ウィンドウ機構を制限し、信頼性を前提として伝送効率を向上させることができます。
遅延応答メカニズム (効率):
伝達効率を高める仕組みです
条件が許せばウィンドウサイズをできるだけ大きくするにはどうすればよいでしょうか?
ACKを返す際には少しの遅延が必要ですが、この遅延時間を利用することでアプリケーションがデータを消費する時間を増やすことができ、受信バッファの残り時間が長くなります。
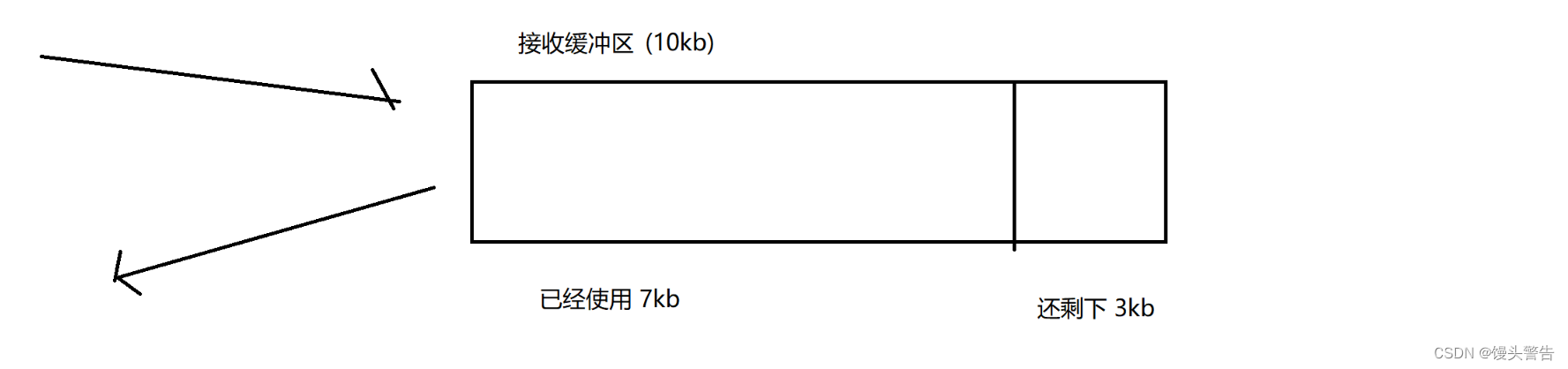
ACK がすぐに返される場合、返されるウィンドウのサイズは 3 kb です。
ただし、500ms 待った後、この時点で ACK が返されます。この 500ms の間に、アプリケーションはさらに 2kb を消費した可能性があります。この時点で返されるウィンドウのサイズは 5kb です。
ここで、応答を遅らせることによってどの程度速度が向上するかは、受信側アプリケーションの実際の処理能力に依存します。
では、すべてのパケットに遅延応答できるでしょうか?
数量制限: N パケットごとに 1 回応答します (スライディング ウィンドウの場合)
制限時間: 最大遅延時間の後に 1 回応答します (非スライディング ウィンドウの場合)
遅延応答により、信頼性の高い伝送が伝送効率に及ぼす影響が軽減されます。
ピギーバック応答メカニズム (効率):
遅延応答に基づいて、効率をさらに向上させるメカニズムが導入されています。
遅延応答は ACK 送信のタイミングを遅くすることであり、ピギーバック応答は遅延応答に基づいてデータをマージできるようにすることです。
クライアントとサーバー間の対話は質問と回答の形式で行われます。
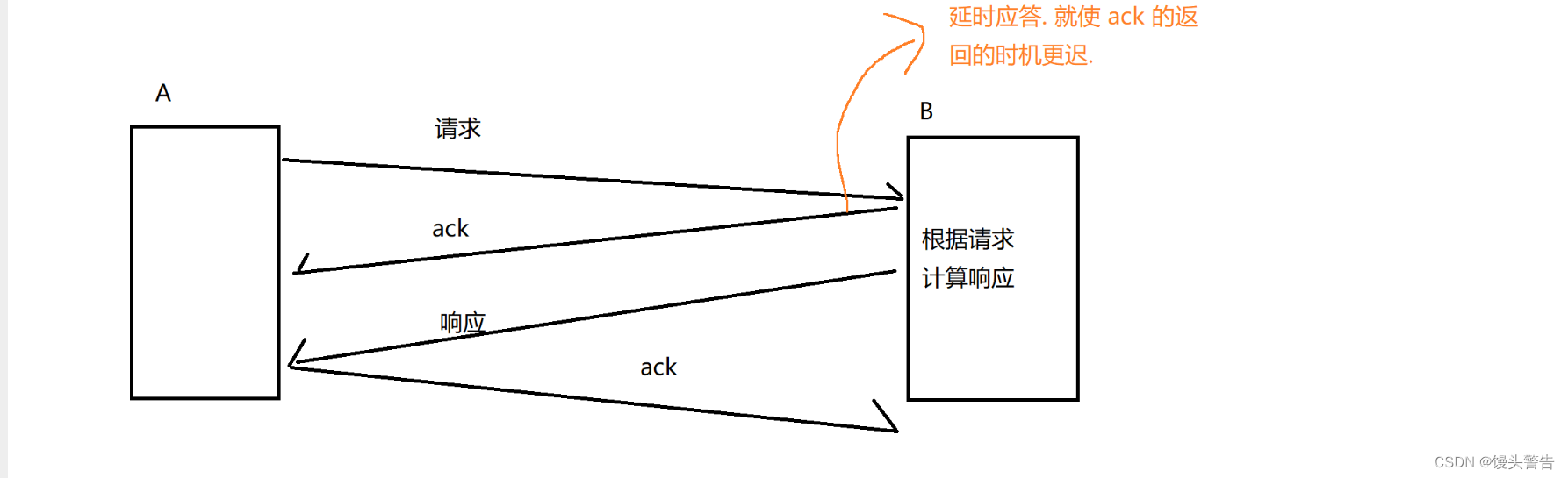
 4 つの波が 3 回になる可能性があるとなぜ言われるのでしょうか?
4 つの波が 3 回になる可能性があるとなぜ言われるのでしょうか?
主に応答遅れや便乗応答の影響によるもの
データグラムが 2 つから 1 つに統合され、効率が大幅に向上します。
主な理由は、データがここで送信されるたびに、カプセル化して分離する必要があるためです。
合併の理由:
一方で、タイミングは同時に行うことができます。
一方、ACK データ自体はペイロードを運ぶ必要がなく、通常のデータと競合することはなく、このデータグラムがペイロードと ACK 情報 (ACK フラグ ビット、ウィンドウ サイズ、確認情報) の両方を運ぶことは完全に可能です。シーケンス番号)
バイトストリームを重視。
バイトストリーム指向の場合、いくつかの問題が発生します
粘着性のあるバッグの問題:
ここでの「スティッキー」は「アプリケーション層データグラム」を指します。
TCPを介して読み書きされるデータは、TCPデータパケットのペイロード、つまりアプリケーション層のデータです。
送信者は複数のアプリケーション層データグラムを一度に送信できますが、受信時に完全なデータグラムがどこから来たのかをどのように区別するのでしょうか?
つまり、2 つのパケットを送信しても、1 つまたは 1.5 つのパケットとして読み取られると、この時点で問題が発生します。

ここでの正しいアプローチは、アプリケーション層プロトコルを合理的に設計することです。
この問題はアプリケーション層の観点から解決する必要があります
1. アプリケーション層プロトコルでは、パケット間の境界を区別するためにデリミタが導入されます。
2. アプリケーション層プロトコルでは、パケット間の境界を区別するために「パケット長」が導入されます。
1. パッケージ間の区切り文字として \n を使用します
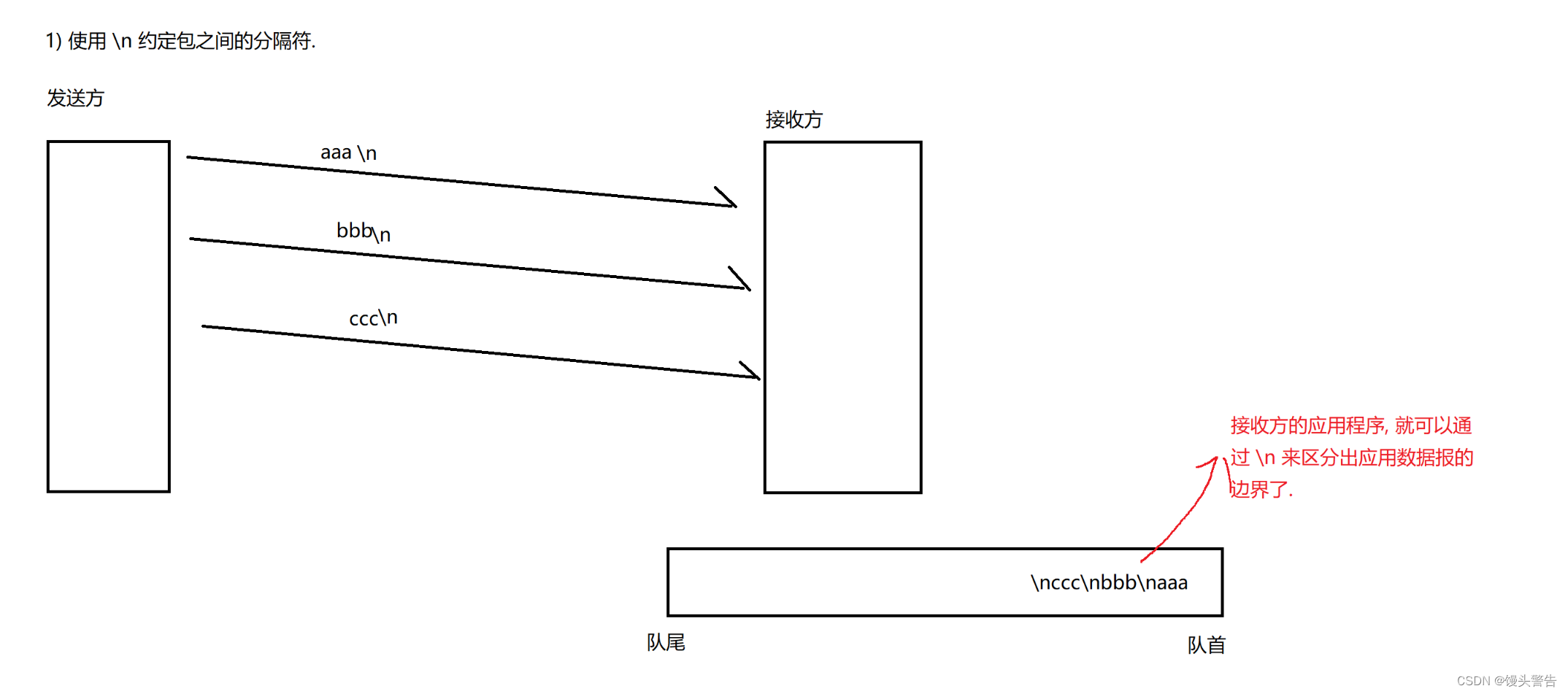
区切り文字の文字が公式メッセージに存在しないことを確認する限り、任意の記号を区切り文字として使用できます。
2. パケットの長さを使用して区別します。
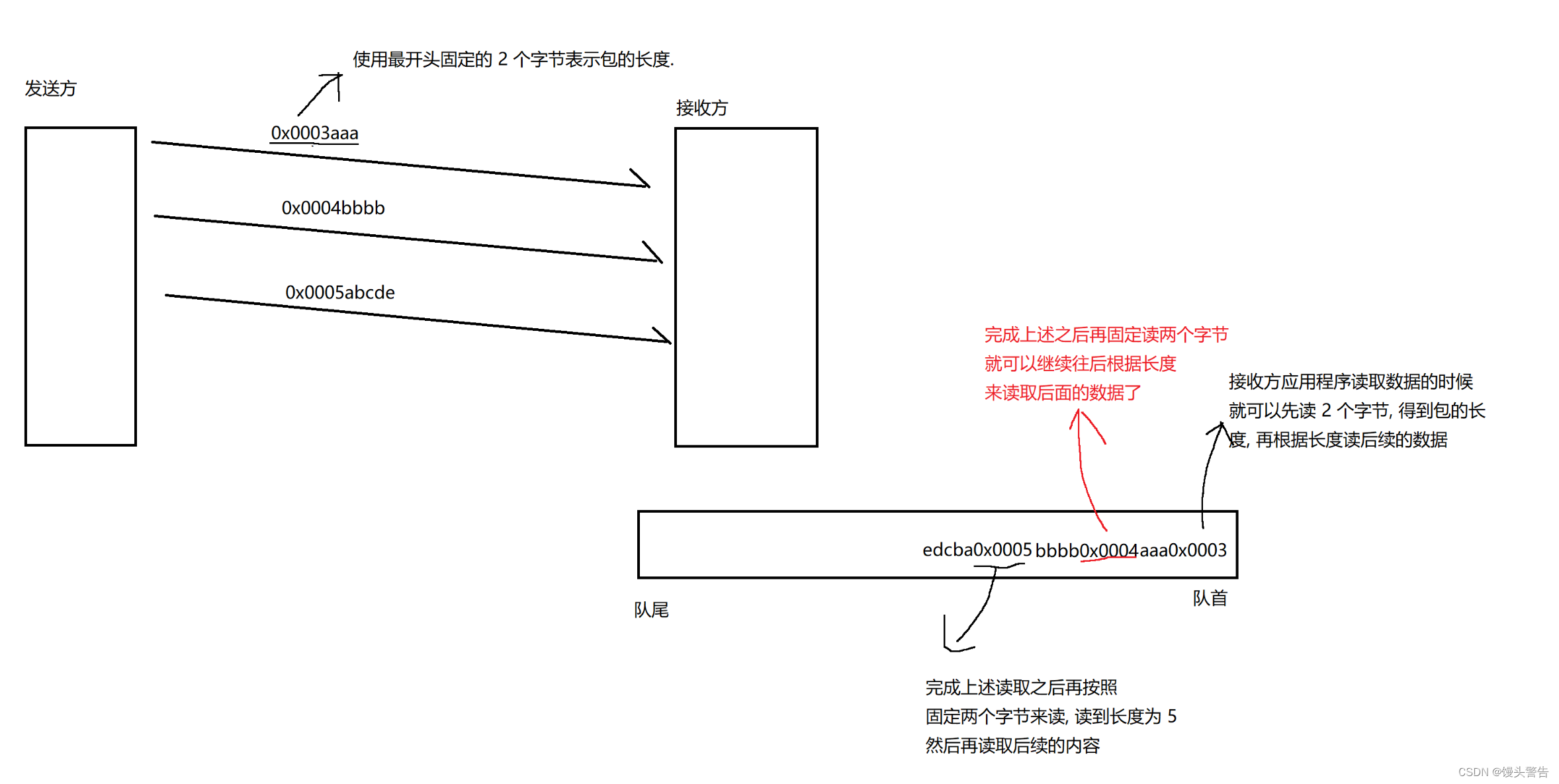 以上の処理により、全体の読み取り・解析処理が完了する。
以上の処理により、全体の読み取り・解析処理が完了する。
スティッキー パケットの問題は TCP に固有の問題だけではなく、バイト ストリーム指向のメカニズム (ファイル) である限り同じ問題があります。
解決策は同じで、区切り文字または長さを使用します。
特にアプリケーション層プロトコルをカスタマイズする場合、このアイデアを使用して問題を解決できます。
対照的に、以前に紹介した次のソリューションは次のとおりです。
xml / jsonは区切り文字で区別されます
プロトバッファは長さで区別されます
TCP例外処理:
ネットワーク自体にいくつかの変数が存在し、TCP 接続が適切に機能しなくなる可能性があります。
1. プロセスのクラッシュ
プロセスがクラッシュする --> PCB がなくなる --> ファイル記述子テーブルが解放される -->ソケット.close() を呼び出すのと同等 --> クラッシュした側が FIN を発行し、これによりさらに 4 つのウェーブがトリガーされます。接続が正常に解放される時間
ソンケットはシステム カーネル内のファイルでもあり、ファイル記述子テーブルにも配置されます。
この時点では、TCP 処理と通常のプロセスの開始および終了に違いはありません。
2. ホストをシャットダウンします(通常のシャットダウン手順)
通常のシャットダウンでは、最初にすべてのプロセスを強制終了しようとします (プロセスを終了しようとします)。これは、先ほど述べたクラッシュ処理と同じです。
ホストがシャットダウンするまでには一定の時間がかかりますが、この時間内に 4 つのウェーブが完了する場合があります (ちょうどいい)。そうでない場合は問題ありません。
3. ホストの電源がオフになっています (電源プラグを抜きます。反応する余地がありません)。
突然コンピュータがブラックになり、当然この時点では操作の余地がなく、この時点では A は B に FIN を送信できません。
(1) B が A にメッセージを送信している場合 (受信機の電源がオフの場合)
この状況は対処が簡単です。B が送信したメッセージに対する ACK はありません。B はタイムアウト再送信をトリガーします。それでも再送信が失敗する場合は、リセット メッセージ (RST = 1) がトリガーされます。B は、メッセージをリセットしようとします。接続を確立しましたが、リセット操作はまだ失敗します。この時点でも接続は一方的に解放され続けます (B には悪影響はありません)。
(2) この時点で A が B にメッセージを送信している場合 (送信側の電源がオフになっている)
この状況はもう少し複雑です
B は A からのメッセージを待っていましたが、A は突然メッセージの送信を停止し、B は A がメッセージを送信し続けるかどうか分からず、ブロック待機状態になります。
これには「ハートビート パッケージ」が関係します。
B は受信者ですが、ビジネス データ (ペイロード) を含まない TCP データグラムを定期的に相手に送信します。
このパケットを送信する目的は、ACK をトリガーすることです。これは、A が正常に動作しているかどうかを確認すること、またはネットワークがスムーズであるかどうかを確認することです。
A 側が ACK を正しく返せない場合、A 側がダウンしていることを意味します。
ハートビート パケットは、前に説明した「フロー制御」ウィンドウ検出パケットと同じものです。
TCP はすでにハートビート パケットをサポートしていますが、それだけでは十分ではなく、多くの場合、アプリケーション層やアプリケーションでハートビート パケットを再実装する必要があります (TCP ハートビート パケット、サイクルが長すぎます)。
4. ネットワークケーブルが外れている
ホストの電源が失われた場合のアップグレード バージョンと同等
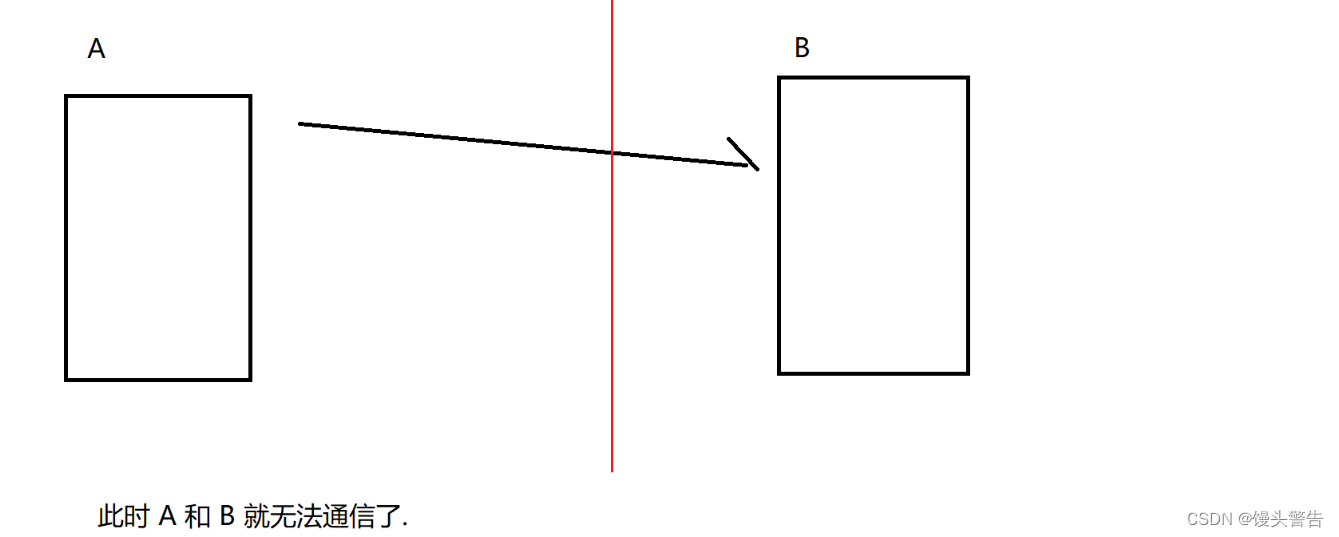
A ここで送信される状況は、ホストの電源が失われたときの最初の状況です。
B によってここに送信された状況は、ホストが電源を失ったときの 2 番目の状況です。
TCPとUDPの比較
TCP の利点は信頼性であり、ほとんどのシナリオに適しています。
UDP の利点は効率であり、コンピュータ ルーム内およびホスト間の通信に適しています (コンピュータ ルーム内では帯域幅が比較的豊富で、輻輳やパケット ロスが発生しにくく、ホスト間の通信は期待されます)。もっと早くしてください)
典型的なシナリオ: 競争力のあるゲームでは、信頼性の高い伝送と効率性の両方が必要ですが、この場合、TCP も UDP も適していません。
場合によっては、KCP などの他のより適切なプロトコルも使用されます (他のいわゆる「トランスポート層プロトコル」は、トランスポート層では実際には機能しませんが、多くの場合、トランスポート層メカニズムと同様にアプリケーション層で実装されます)。同時に、下部にある信頼性の高い送信を実現するために UDP に基づいています)
3. ネットワーク層
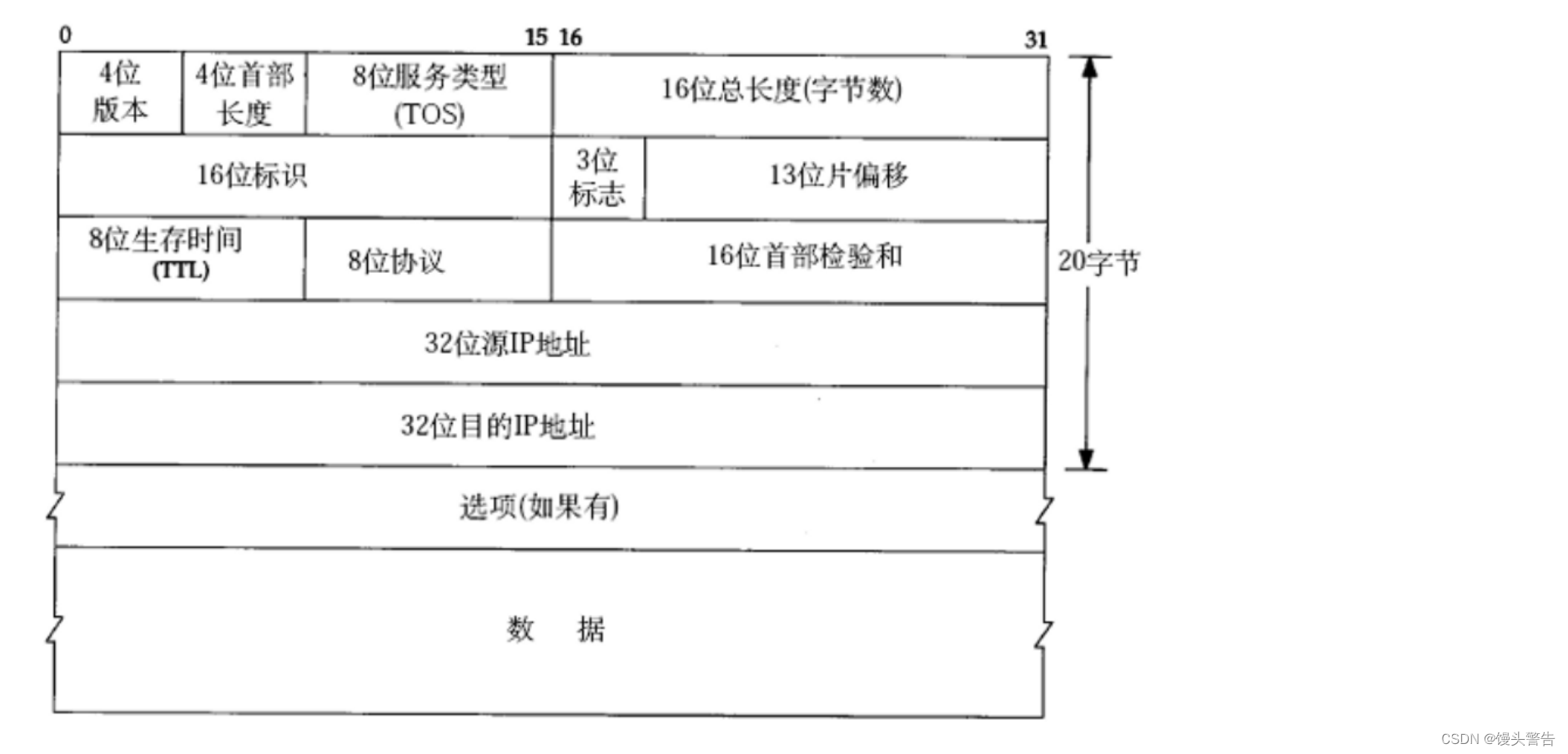
(1) 4 桁のバージョン番号: IP プロトコルのバージョンを示すために使用されます。
既存の IP プロトコルには IPv4 と IPv6 の 2 つのバージョンしかなく、他のバージョンは研究室にのみ存在しており、商業的に大規模に使用されていません。
(2) ヘッダ長4ビット、設定はTCPと同じ
IP ヘッダーは長くてもよく、IP ヘッダーにはオプションがあります。
こちらも単位は4バイトです
(3) 8ビットサービスタイプ
(実際には4ビットのみが有効です)
最小遅延: データグラムの送信時間を可能な限り短くします。
最大スループット: 一定時間内にできるだけ多くのデータを転送します。
最高の信頼性: 送信中にパケット損失が発生する可能性が最も低い
最小コスト: 送信プロセス中に消費されるハードウェア リソースが最小限に抑えられます。
4 つの形式は相互に排他的であり、1 つの形式にのみ切り替えることができます。
IP プロトコルはこのメカニズムをサポートしていますが、実際の開発に適用されることはほとんどなく、通常はシステム レベルでの詳細なカスタマイズが行われます。
(4) 全長16ビット
この長さは、IP ヘッダー + ペイロード長を指します。
全長 - IP ヘッダー長 = ペイロード長 (TCP パケットの全長)
TCP メッセージの合計長 - TCP ヘッダー長 = TCP ペイロード長
ここでの 16 ビットの合計長には 64 kb の問題が含まれますが、IP プロトコル自体は「アンパックおよびグループ化」メカニズムをサポートしており、ここでの 64 kb は IP データグラムのみを制限します。
比較的長いデータを伝送する必要がある場合、IP プロトコルは 1 つのデータを複数のデータグラムに自動的に分割し、受信側も分割時に複数のデータグラムを 1 つにマージします。
(5) 16ビット識別、3ビット識別ビット、13ビットスライスオフセット
これら 3 つは、IP データグラムのアンパックとパッケージ化のプロセス全体を説明します。
IP データグラムが比較的長いデータを伝送する必要がある場合、アンパック操作が IP プロトコル層でトリガーされます。
パッケージを複数の小さなパッケージに分割する
複数の小さな IP データグラムが IP ヘッダーを運び、ペイロードは TCP データグラムのいくつかの部分になります。
16 ビット識別子: これらの複数のパッケージの 16 ビット識別子は同じです。
13ビットスライスオフセット: 前のパケットのスライスオフセットが小さく、後のパケットのスライスオフセットが大きく、スライスオフセットによってパケットの順序を区別できます。
3 桁の識別ビット: 1 つは未使用、もう 1 つはアンパックが許可されているかどうかを示し、残りの 1 つはエンドマーク (現在のパケットが最後のパケットであるかどうかを識別) を示します。
(6) 8 ビット存続時間 TTL
単位は回です
最初は、TTL の値は (32/64/128) になります。
ルーター経由で転送されるたびにTTLが-1され、TTL=0の場合は破棄されます。
通常は。TTL は、ネットワーク上の任意の場所に到達するデータグラムをサポートするには十分ですが、0 が表示される場合は、基本的に IP に到達できないと考えられます。
(7) 8ビットプロトコル
上位層であるトランスポート層で使用されるプロトコルを説明します。
(8) 16ビットヘッダチェックサム
データが正しいかどうかを確認するには、ヘッダーを確認するだけで済みます。
ペイロード部分はTCPかUDPなので自分でも確認済みです。
(9) 32 ビット送信元アドレス、32 ビット宛先アドレス
IPプロトコルの最も重要な部分