

本稿では、生成AIの関連技術、特に画像認識分野における畳み込みニューラルネットワーク(CNN)の応用を中心に紹介します。この記事はシリーズの 2 番目です。

前回の記事でニューラル ネットワークとディープ ラーニングの概要を理解していれば、AI 関連の概念と原理を徐々に深く理解するのは比較的簡単なはずです。
最後の記事が皆さんに、「AI はあなたが思っているほど複雑ではない」という印象を与えられれば幸いです。 AIは膨大な情報を処理できますが、人間には理解が難しいほど複雑な仕組みを持っているわけではありません。なぜなら、仕組みが比較的単純であれば、消費エネルギーが少なく、計算速度が速く、より多くの情報を処理できるからです。自然界でも同じことが言えます。脳の仕組みが今よりも複雑だったら、脳は燃え尽きてしまうでしょう。
前回の記事では、最も基本的なニューラル ネットワークを使用して手書きの数字を認識できることを説明しましたが、同時に、ニューラル ネットワークがうまく「学習」できず、抽象的な理解ができない場合もあることがわかりました。問題の一般的な法則に従うと、過学習はデータとモデルという 2 つの要素に関連して発生することがよくあります。この記事では、過学習に対処するための画像認識分野での経験について説明し、ニューラル ネットワークと深層学習を自然言語処理などの他の分野にどのように拡張できるかについても説明します。

前述したように、ニューラル ネットワークは画像認識に使用できます。画像認識なので、コンピューターグラフィックスの既知の手法を組み合わせてディープラーニングの効果を高めることはできないでしょうか?答えは「はい」です。畳み込みニューラルネットワークは、グラフィックス手法を組み合わせることで画像認識の効果と効率を大幅に最適化するネットワークです。
▐畳み込みニューラルネットワークの原理
-
特徴のキャプチャ - 畳み込み演算 (convolve): 畳み込みレイヤーは画像全体をスキャンし、画像処理と同様のフィルターを通じてオブジェクトのエッジやテクスチャなどの基本的な特徴を強調します。これは、さらに認識するために画像内の局所的な特徴を捉える「線を描く」ステップとみなすことができます。 -
単純化と強調 - プーリング: 畳み込みによって特徴が抽出された後、プーリング層は特徴データのサイズを削減するのに役立ち、同時に画像の複雑さと計算要件を簡素化します。プーリング レイヤーは、輪郭と全体の構造を強調するために、絵画内のそれほど重要ではない細部の一部を意図的に省略するように機能します。 -
このプロセスを繰り返して抽象化レベルを高めます。畳み込みニューラル ネットワークには、複数の畳み込みとプーリングの操作が含まれることがよくあります。一連の畳み込みとプールを繰り返すことで、ネットワークは単純な特徴を徐々にフィルタリングして組み合わせて、より複雑な形状やパターンを作ります。これは、子供が線から形状へと描画して文字を完成させるプロセスと同様です。 -
特徴合成 - 全結合層: 子供が最終的に頭、体、手足を適切な位置に配置して人物の絵を完成させるのと同じように、畳み込みニューラル ネットワークは、複数のレベルで抽象化された特徴に基づいて全結合層を使用して最終的な処理を実行します。統合と分類作業。完全に接続された層は、画像レベルの特徴全体を考慮し、それらの間の複雑な関係を学習して、特徴から最終的なターゲット認識 (写真内の人物の識別など) までのプロセスを完了します。フルリンク層は誰もがよく知っています。これは、前述の高密度層で構成されるニューラル ネットワークです。
-
畳み込み演算を複数回繰り返した後、後続の完全に接続された層 (前述のニューラル ネットワークと同じ) で処理する必要があるオブジェクトは、明らかな「現実的な意味論」を持たないピクセルや色から、エッジ、輪郭、テクスチャ、など、特定の「現実的なセマンティクス」機能を備えており、画像認識の精度が大幅に向上します。 -
畳み込み演算により、完全に接続された層で処理される最小単位が 1 レベルずつ増加します (コードを記述するときに 1 行ずつステートメントを記述するのではなく、チェーンを使用してアトミック機能を編成するようなものです)。プーリング操作も画像の処理量が比較的軽減されるため、これら 2 つは理論的には (同様の精度の他の方法と比較して) 効率を向上させることができます。
▐畳み込みニューラルネットワークにおけるグラフィックスとはフィルターを意味します
では、畳み込みニューラルネットワークはどのようなグラフィック手法を組み合わせているのでしょうか?畳み込みニューラル ネットワークの畳み込みカーネル (カーネル) を見てみましょう。グラフィックスではフィルターと呼ばれます。 Photoshop や GIMP に精通している学生は、次の 4 つのフィルター (図では 3x3 ベクトル) などを知っておく必要があります。
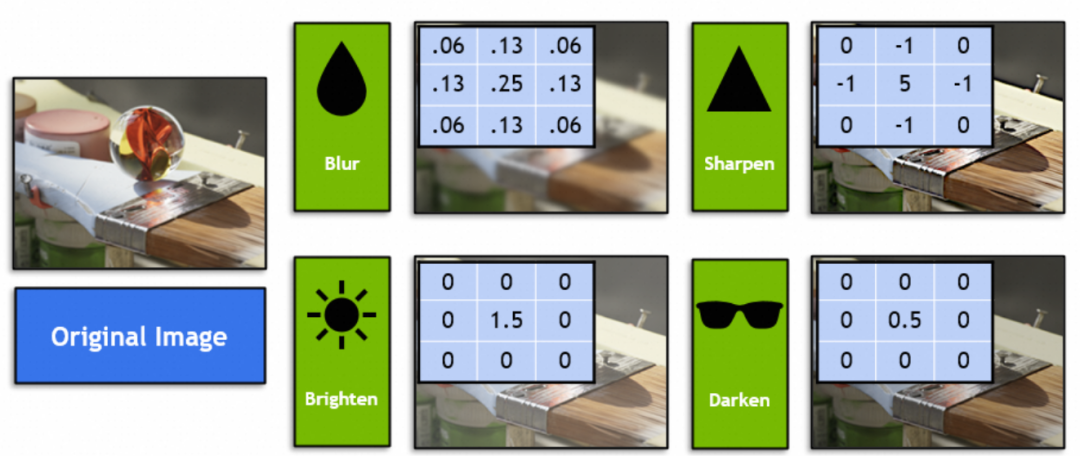
数学では、フィルターは線形代数のベクトル演算です。元のイメージ内の各 3x3 ベクトルがフィルターの 3x3 ベクトルで乗算され、合計されます。たとえば、画像内のこのフィルター ベクトルは、9 つの隣接するピクセルを中間点にブレンドすることでぼかしを実現します。
経験的データ: 畳み込みニューラル ネットワークでは、3x3 サイズの畳み込みカーネルを選択すると、良好な結果が得られます。
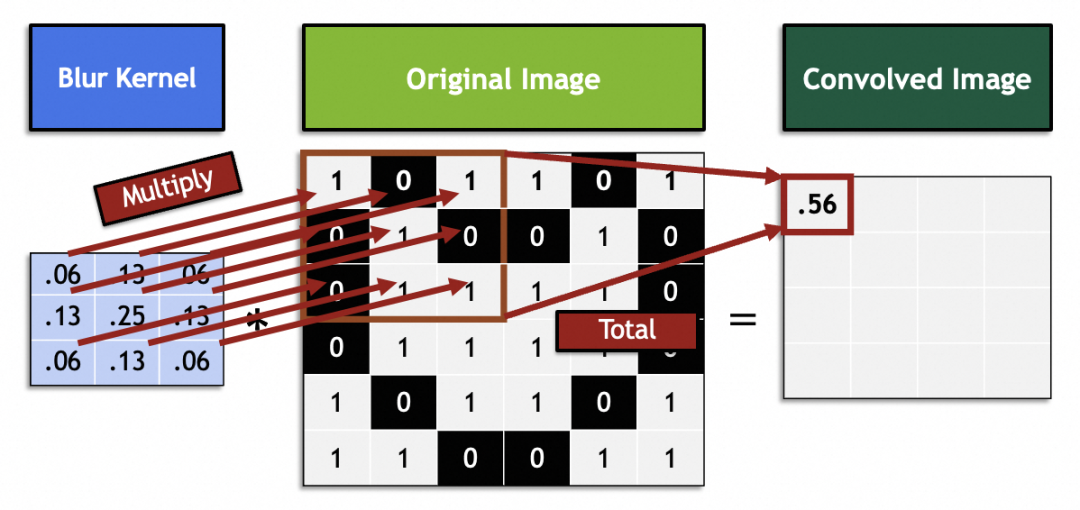
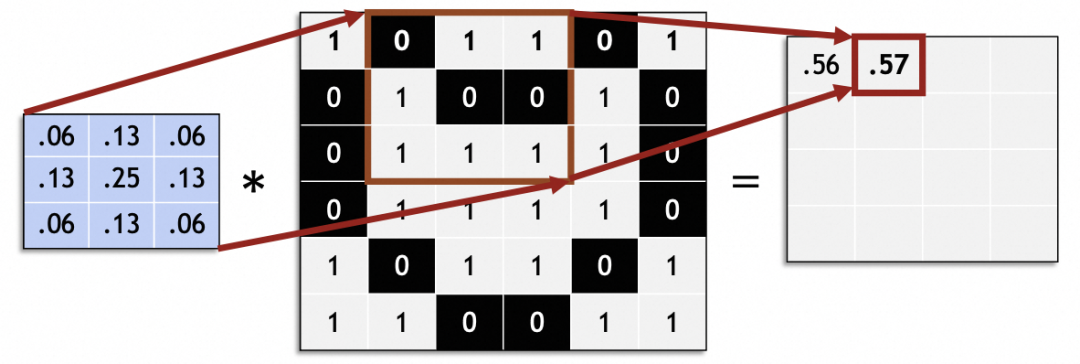
元の画像全体をスライドして処理し、新しい画像を生成します。
畳み込みニューラル ネットワークでは、スライディング ステップ サイズ (ストライド) は通常 1 です。 1 以外の値を指定すると、元の画像サイズをストライドで均等に分割できないなどの問題が発生する可能性があります。
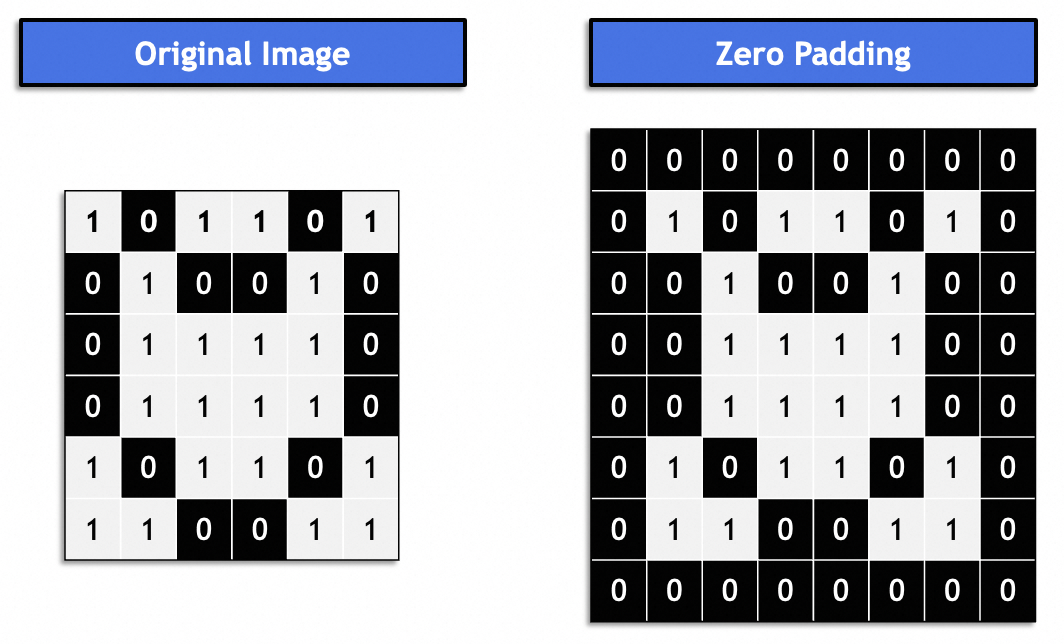
一般に、これは「同じパディング」であり、結果として得られる画像は元の画像と一貫したままになります。通常は 0 で埋められます。
では、コンボリューション カーネルやフィルターはどのような問題を解決するために使用されるのでしょうか?以下のコンボリューション カーネルを見てみましょう。これらは、元の画像の垂直エッジと水平エッジを強調するために特定のベクトル値を使用します。図に示すように、コンボリューション カーネルを実際に使用して、元の画像から特徴を抽出できます。

最後に、グラフィックスのフィルターはニューラル ネットワークにどのように適用されるのでしょうか?
まず、コンボリューション カーネル ベクトルと元の画像ベクトルが乗算され、合計されます (再アクティブ化されます)。これは、ニューロン パラメーターと入力が乗算され、合計され、再アクティブ化されるのと同様です。コンボリューション カーネルは、ニューラル ネットワーク内のニューロンによって表現できます。
第 2 に、上記のブラー、シャープ、水平および垂直エッジ フィルターの既知のベクトル値とは異なり、コンボリューション カーネルのベクトル値はトレーニング可能であり、入力特徴とニューロン パラメーターを動的にキャプチャするために使用されます。使い方は一貫しています。
実際、コンボリューション カーネルはコンボリューション層のニューロンです。全結合層ニューロンと同様に、そのパラメーターも入力重み + バイアス定数であり、入力重みの数は入力の数と同じです。入力イメージはスタック イメージであるため、入力重みの数はx * y * n、バイアス定数です。は 1 に固定されており、x * y * n + 1合計 1 つあります。この 2 スタック、3x3 カーネルの図に示されているように、パラメーターの数は です3 * 3 * 2 + 1 = 19。
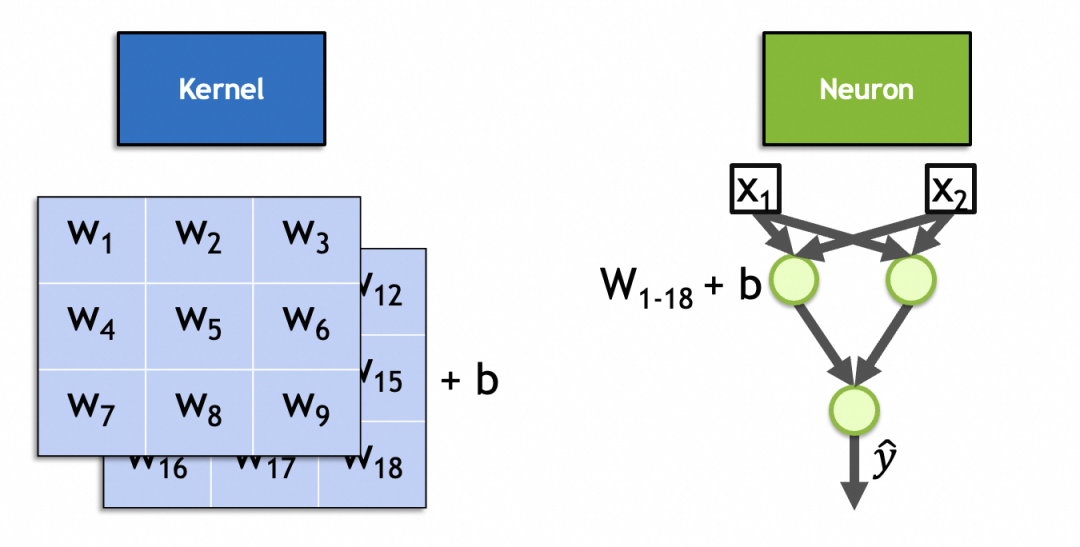
▐畳み込みニューラルネットワークの計算プロセス
畳み込みニューラル ネットワークの計算は、前のニューラル ネットワークと同じ順伝播と逆伝播であるため、詳細な説明は省略します。
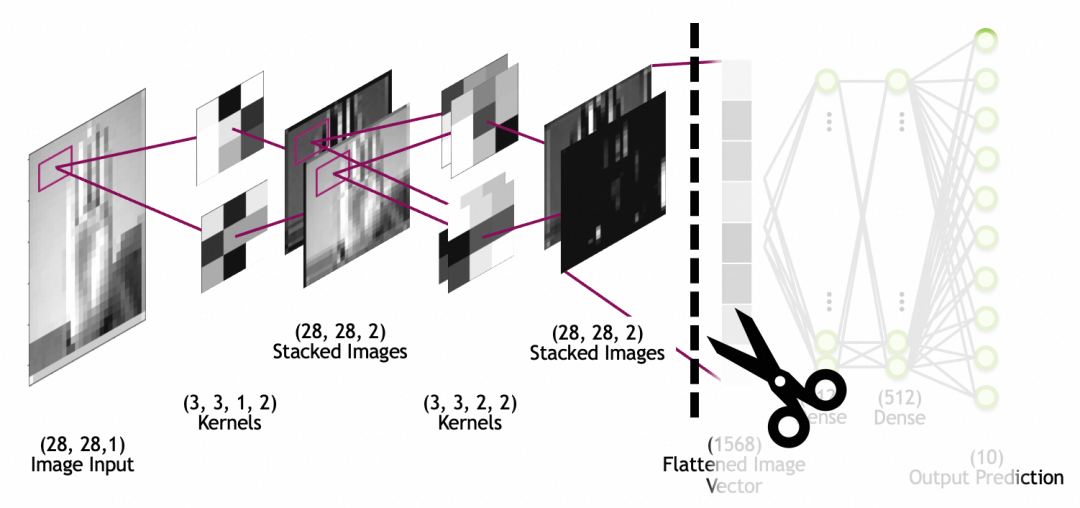
下の図では、画像入力は 28x28 サイズの入力画像、1 つのスタック (1 つのグレースケール層) です。スタックされた画像はネットワーク層ではなく、最後にスタックされた畳み込み層の出力であることに注意してください。画像は、後続の完全接続層ネットワークで使用するために、平坦化層を通じて 1 次元配列 (図の平坦化画像ベクトル) に平坦化されます (完全接続層については上で説明しました)。
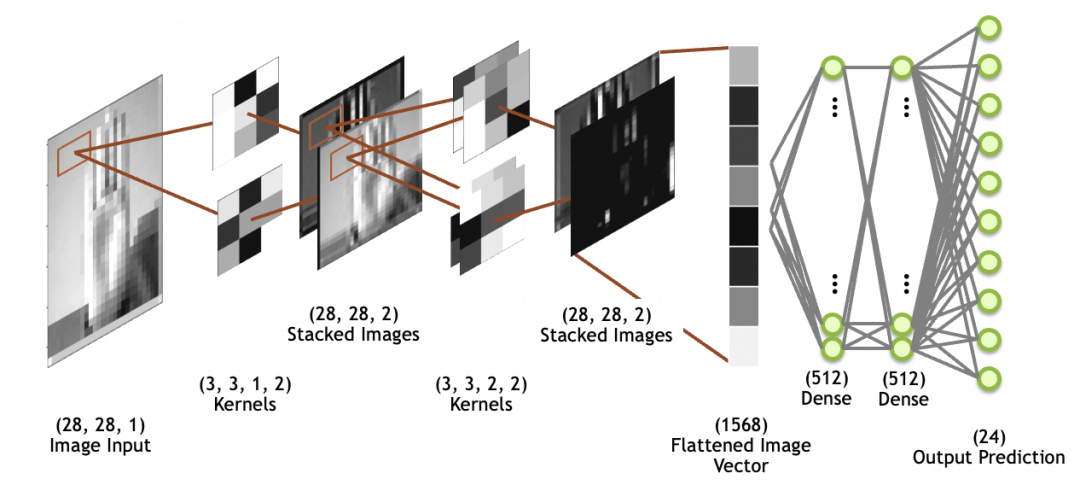
畳み込み
数値である以前の全結合層 (Dense) ニューロンの出力とは異なり、コンボリューション カーネル ニューロンは毎回乗算され、アクティブ化されて 2 つの方向を組み合わせて連続的にスライドすることで、最終的に 2 次元マップが得られることに注意してください。得られる。
输入是
x * y * N
的堆叠图像。其中,x=28,y=28(
28 * 28 * N
)。卷积层每个神经元因为要和输入相乘,所以也是N叠,假设神经元采用
3 * 3
大小,则每个神经元是
3 * 3 * N
。输出经过padding,每叠大小和输入保持一致,
28 * 28
。输出堆叠图像的每一叠为输入堆叠图像x单个神经元的结果,所以叠数和卷积层神经元个数一致。假设卷积层有M个神经元,则输出堆叠图像为
28 * 28 * M
。这里强调一下,卷积层每个神经元的叠数=输入图像的叠数。输出图像的叠数=卷积层神经元的个数。
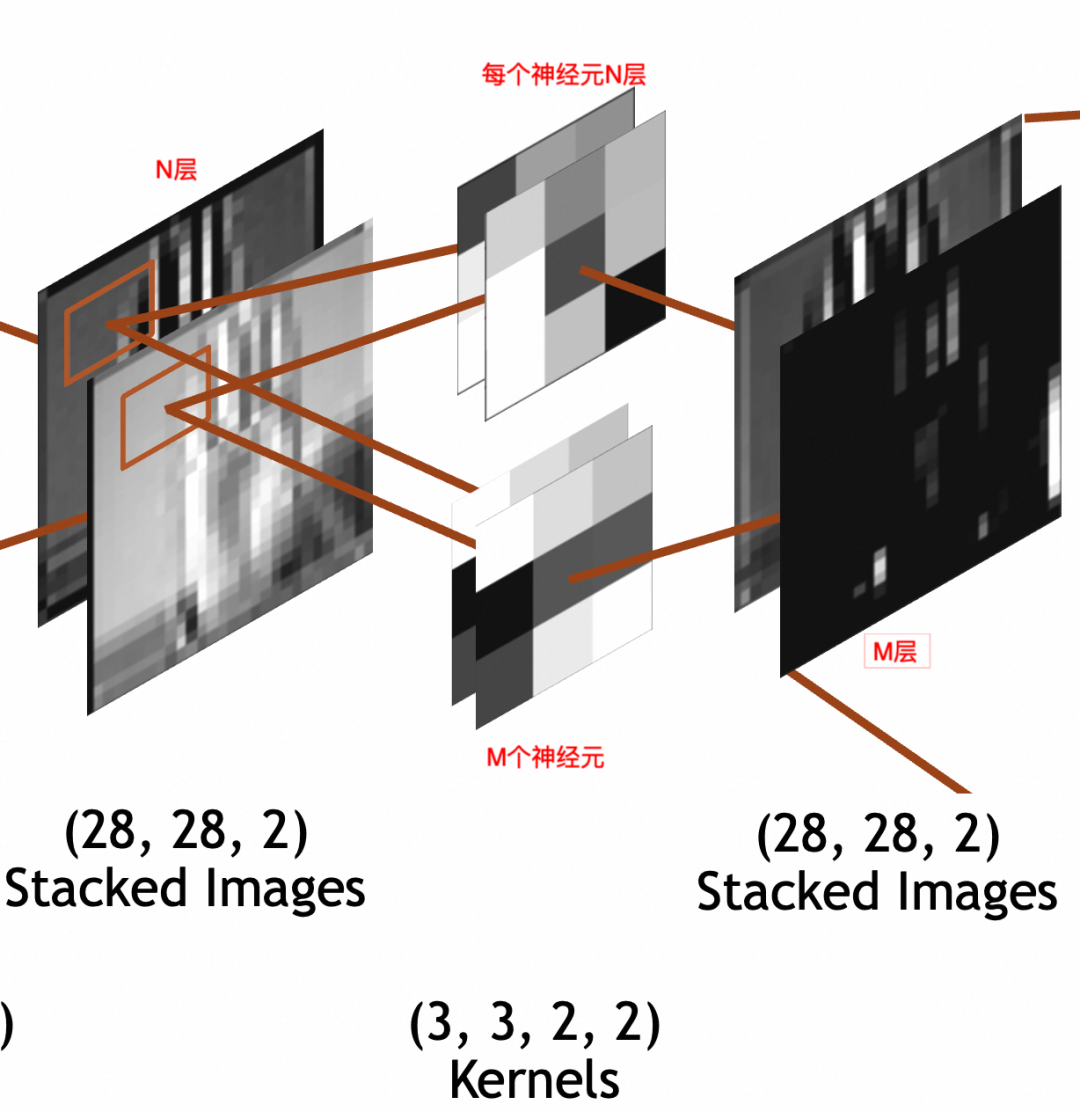
3 * 3 * N
的卷积核,每次要和N叠输入图像的
3 * 3
部分相乘,所以权重参数(weights)个数为
3 * 3 * N
,此外还通过一个偏置(bias)整体左右移。所以总参数个数为
3 * 3 * N + 1
,激活结果计算公式还是和上文普通神经元一样
output = activation_function(W * X + b)
。
为了神经网络整体处理方便,网络的输入图像、中间的堆叠图像都被统一成了 x * y * Z三维数组结构,但是两者关于叠/层的语义是不同的。输入图像的语义是图像的图层,不管是灰阶图像的1层,RGB的3层,还是RGBA的4层,是有现实关联性的。堆叠图像的各层分别是输入图像和单个神经元计算的结果,是一个特征,相互之间没有关联性,比如一层可能是纵边特征,另一层可能是横边特征。
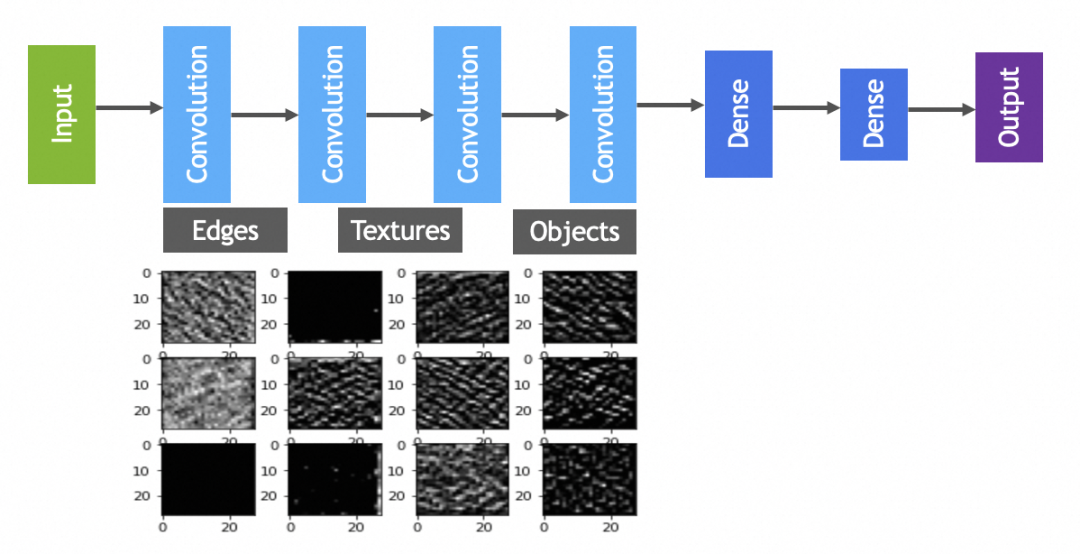
讲原理时已经提到过,一般会有多轮卷积,主要目的分别是从原图提取最小的特征,从最小特征中提取中等特征,……,如下图所示:
池化
池化层的作用,主要是通过缩小图像,丢弃次要特征,保留主要特征:
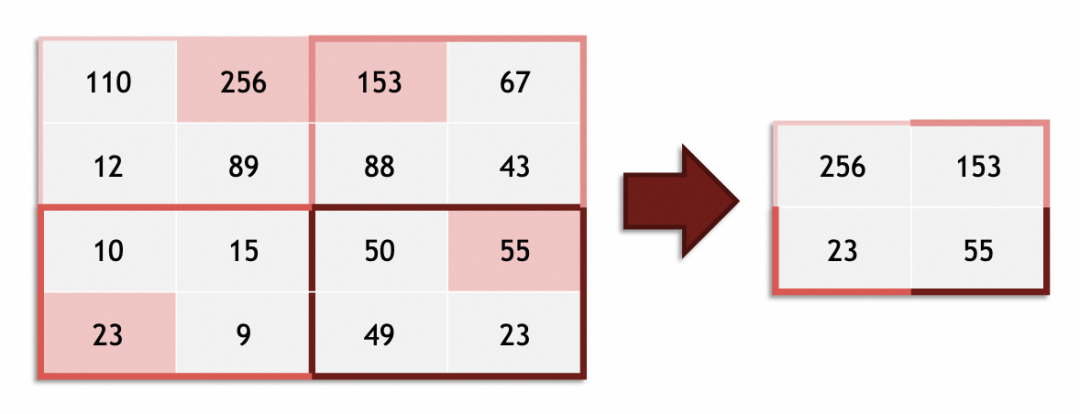
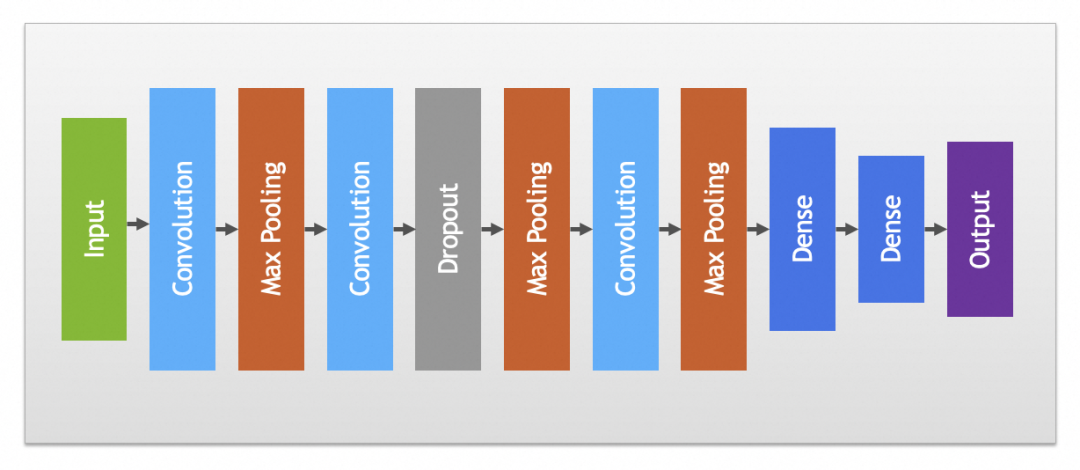
实践中卷积和池化层一般会搭配使用,完整卷积神经网络如下图:
其它
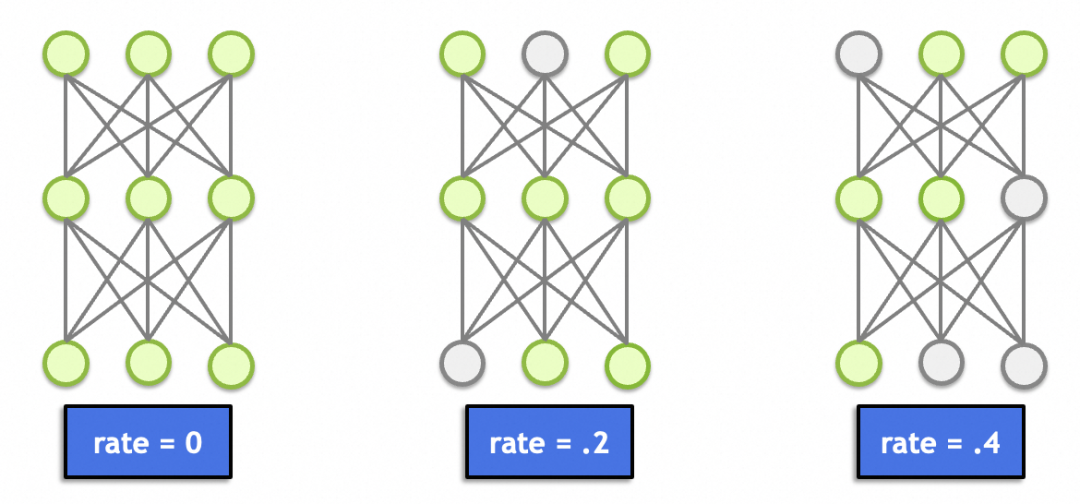
这里面还有一个丢弃层(Dropout),这个理论上跟图形学、图像处理没啥关系。主要作用是随机丢弃一定比例节点的输入(置0),避免因为节点过多(总参数过多、记忆能力太强)导致记忆效应,产生过拟合。
▐ 卷积神经网络实例讲解
本文卷积神经网络讲解的实例是对美国手语的识别,因为是手语照片,相对上文手写文字的案例来讲干扰因素过多,比如背景、衣服、掌纹等,所以采用普通神经网络过拟合比较严重。后面可以看到,改用卷积神经网络后,结果提升了不少。
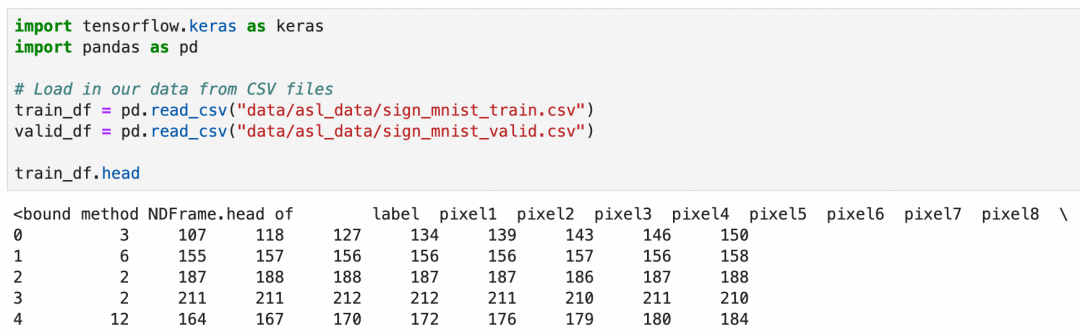
美国手语一共26个字母,其中2个字母带动作,这里只识别24个静止的字母。这次的数据集是使用csv文件存储的,可以加载后查看一下数据概貌:
csv文件一共785列,第一列是label,值是1-24,表示24种字母。第2到785列分别存放的灰阶值,值是0-255,表示从黑到白的颜色。
处理一下加载的值,将标签存入y_train和y_valid,784个像素值保留到x_train和x_valid:
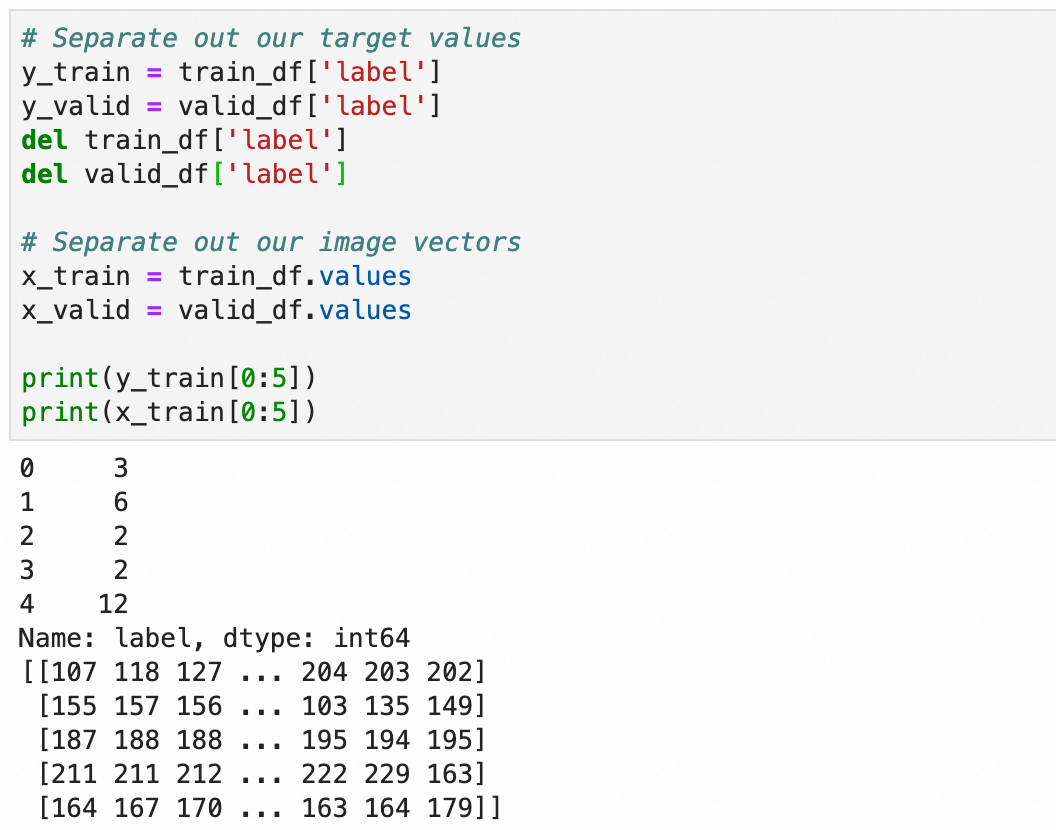
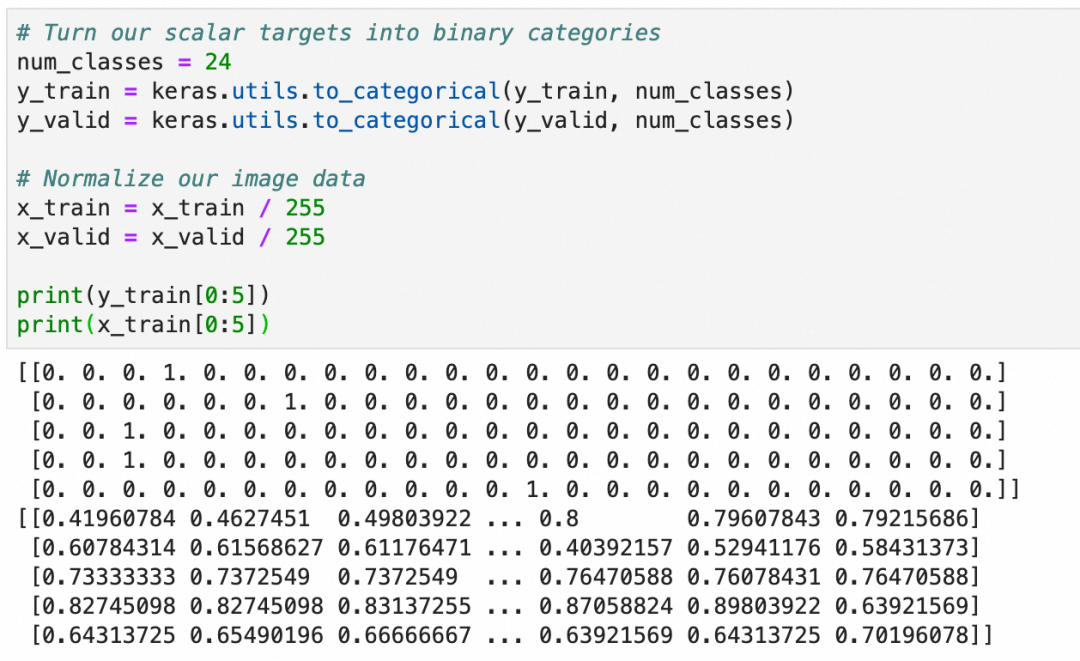
和上文一致,将y转成one-hot编码,用于分类算法,x转成0.0-1.0之间的浮点数:


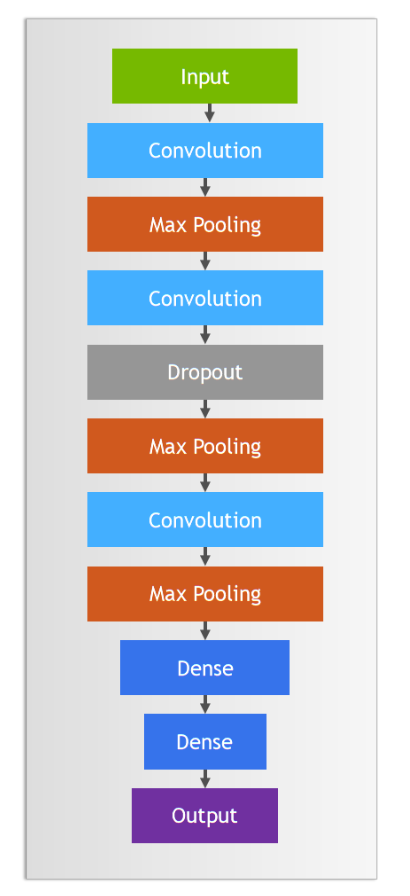
构建语句,其中:
Conv2D(75, (3, 3), stride=1, padding="same", activation="relu", input_shape=(28, 28, 1))创建一个卷积层,输入是28*28*1,75个神经元,每层大小3*3,因为输入是1层,所以每个神经元只有1层。BatchNormalization()创建一个批量标准化层,标准化上层输出平均激活值接近于0,激活值的标准差接近于1。MaxPool2D((2, 2), strides=2, padding="same")创建一个池化层,每2*2像素保留1像素,即长宽各缩小1倍。Dropout(0.2)创建一个丢弃层,丢弃20%输入。

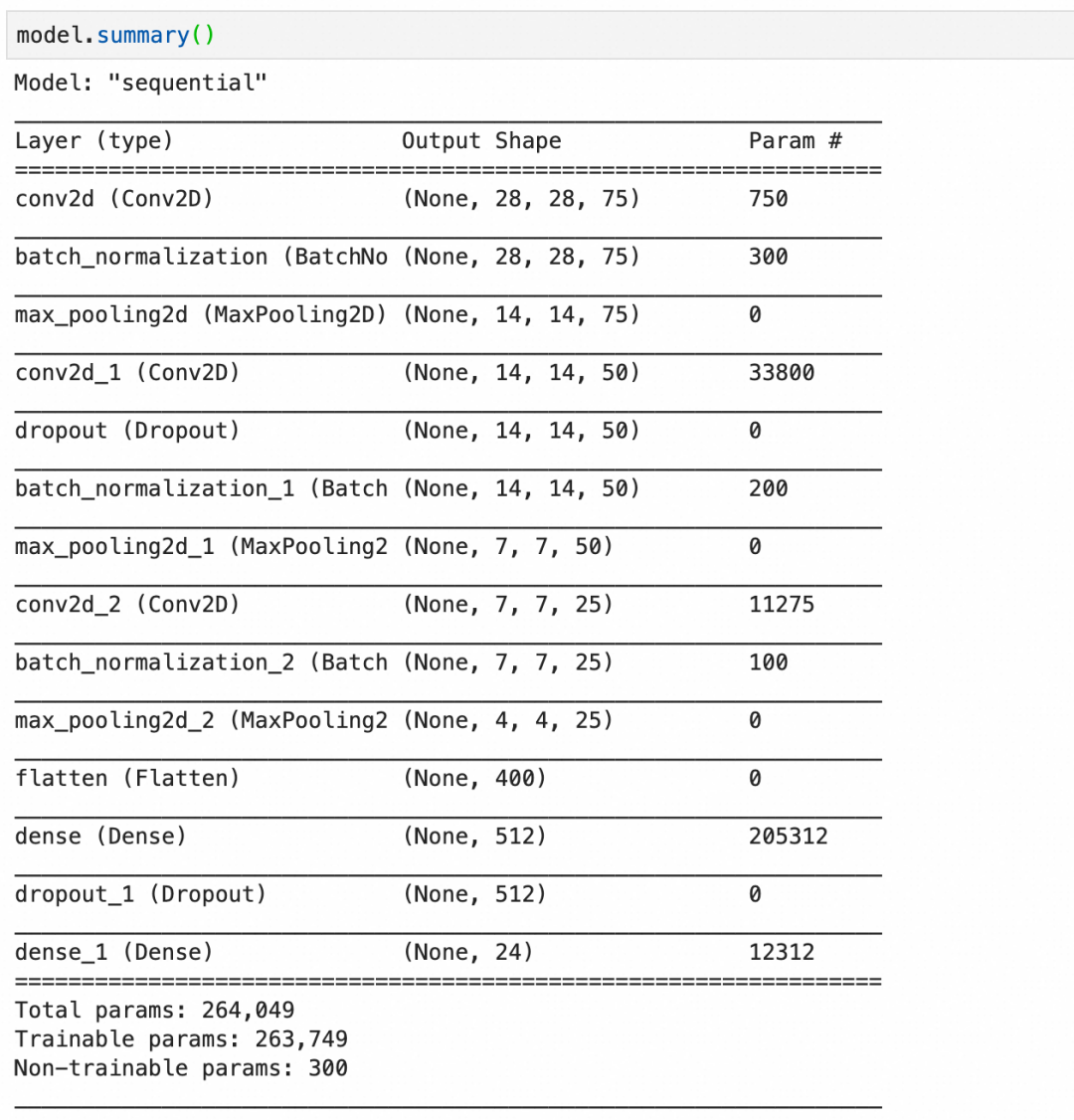
第1层,卷积层,75个神经元,每个神经元 3*3*1+1 个参数,一共750个参数。
第2层,批量标准化层,75层输入,每层4个参数,其中2个可训练参数:缩放和偏移,还有2个不可训练参数,存储本批数据的统计值。一共300个参数。
第3层,池化层,池化层都是运算,没有参数。
第4层,卷积层,50个神经元,每个神经元3*3*75+1个参数(每个神经元有75层,分别对应输入的75层),一共33800个参数。
第5层,丢弃层,丢弃层只有运算,没有参数。
第11层,flatten层,只有转化,没有参数。
最后,总的参数个数里,有300个不可训练参数,这是由3个批量标准化层的不可训练参数加在一起构成。

本卷积神经网络校验集的准确度最后能到92%左右,算是比较好的结果:

上面一章我们看了如何通过优化模型来降低过拟合,下面我们来看看如何通过数据增强来提升整体准确度。
数据增强通俗的理解就是通过丰富训练集数据、增加样本数量,减少模型对具体实例的“记忆”、增加模型抽象一般规律的能力。比如我们要训练识别狗的图片,能提供的训练样本当然是越全越好,即需要很多正例(比如金毛、边牧等不同品种的狗),也需要尽可能多的反例(比如猫、狼)。
道理很好理解,但是准备足够多样的训练样本是一件很费事的事情。数据增强是深度学习框架提供的一套工具,通过对现有训练集进行细微变化,比如(适度的)缩放、旋转、位移等等,来批量生产新的训练样本。
需要注意的是,需要根据数据集的特征来决定要进行怎样的变化,比如上一章的手语图片,样本是可以左右翻转的,因为左撇子的手势刚好左右翻转,但是垂直翻转则没有意义;同理,上文中的手写数字,则既不能垂直翻转,也不能左右翻转。
另外,样本的变化也要注意范围,因为网络接收的图片尺寸从一开始就是确定的,这些变化不会改变接收图片的尺寸。比如图片放大缩小,超出图片大小的部分会被裁剪,缺失的部分会被填充。所以,需要考虑变化后的图片是否还有意义,比如手语图片过分放大,放大到只剩一根手指,细节部分是清晰了,但是整体已经完全看不出所代表的手语字母了。
本章不涉及原理,因为这符合人们的一般理解。重点讲一下数据增强的过程:
第1步,还是上一章所用的训练集和模型不变。
train_df = pd.read_csv(...)...model = Sequential()model.add(...)...model.compile(...)
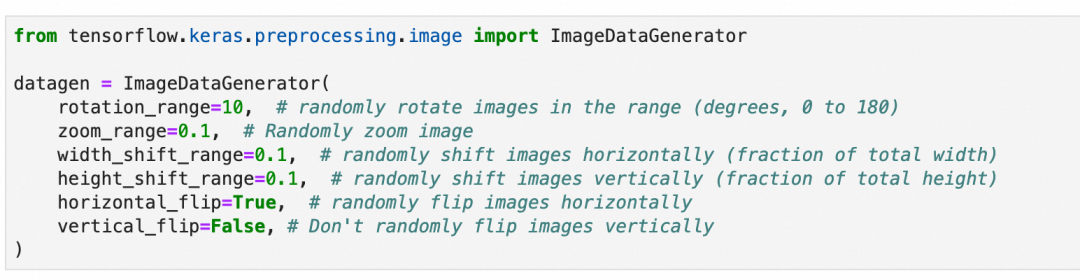
第2步,准备数据增强用的图像数据生成器:随机旋转10度、缩放10%、左右上下位移10%以内,随机水平翻转,但不垂直翻转。
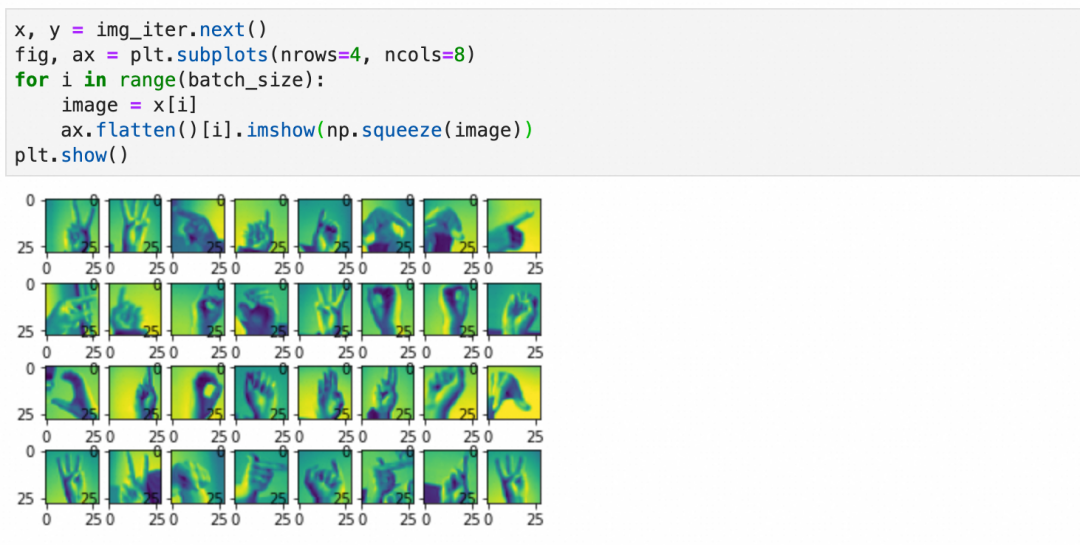
第3步,设置分批生成数据的大小:设置每批生成32张图片。

上面得到的是一个生成数据的迭代器,可以可视化一下第一批数据的样子:
对训练样本的变化除了上面提到的旋转、缩放、位移等,还有基于原训练样本统计值的变化(本案例没用到)。
这一步是统计整个原训练样本,并记录必要的统计信息到数据生成器。

第5步,用数据生成器进行训练:
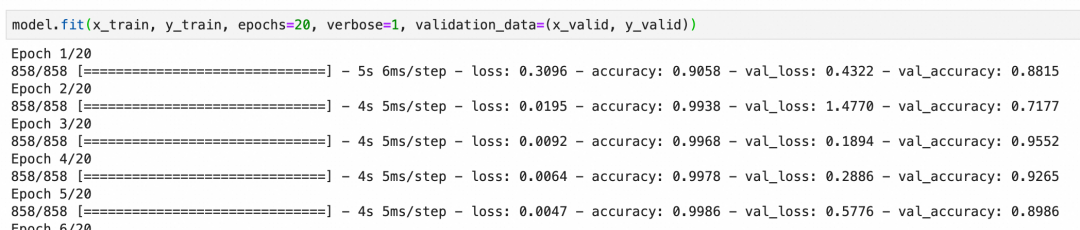
和上一章案例直接使用原始样本不同model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))。这里使用数据生成器生成的内容。
还是20个周期,但是每个周期里训练的样本数等于steps_per_epoch * batch_size,基于丰富度和训练时长兼顾考虑,这里采用steps_per_epoch=len(x_train)/batch_size,每周期样本数和原训练集差不多(但是都是经过数据生成器,随机变化过后的新样本)。
最后结果可以看出,准确度很快就上去了,数据增强有非常明显的效果。


▐ 迁移学习
迁移学习就是通过将已经训练好的模型的一部分摘出来,重新和其它网络层组成新的网络,从而复用网络能力和提升网络效果的过程。
比如,我们可以拿google已经训练好的,进行动物分类的模型,拿来识别自家的猫主子,做一个自动猫门。
为什么要这么做?简单的说就是你自己的训练集不够,你给自家猫拍一千张照片来从头训练一个模型,也可能把外面的流浪猫放进来,因为你缺少足够的正负样本。
因为篇幅原因,这里不详细展开,只讲一下关键步骤。细节可以参考Transfer learning and fine-tuning官方教程:
第1步,摘取预训练模型的前半段(卷积层+池化层),去掉后半部分(include_top=False)。
第2步,拼接模型的后半段为新的、未经训练的全连接层。
第3步,设置前半部分参数不动(trainable=False),拿新的正负样本训练模型的后半段。
你会发现,有了预训练模型的前半段,很快就可以取得不错的结果。
这里我们也可以得出结论,网络前半段的参数,包含了比较通用的特征,比如一般的猫狗,网络后半段则包含了比较具体的特征,比如你家的猫主子。
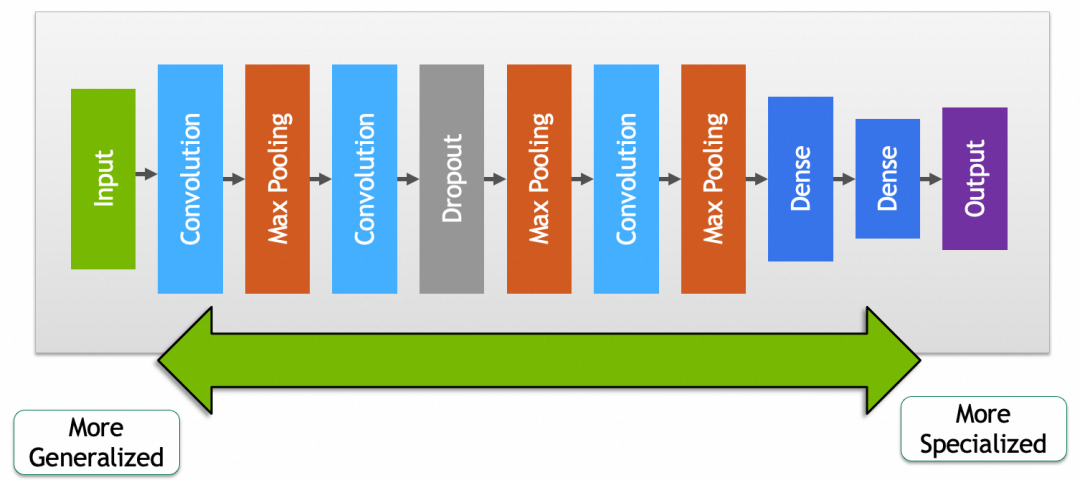
▐ 微调
如果复用网络后,发现效果没有特别满意,可能是因为预训练模型和你要求解的问题没有完全匹配,或者现有模型参数里缺少一些针对性的特征。微调就是通过稍微调整一下预训练模型部分的参数,提升被复用网络效果的过程。
微调的过程很简单,前面3步保持不变,增加下面的步骤:
第4步,设置前半部分参数可训练(trainable=True),同时设置训练步长为一个非常小的值。
第5步,继续训练几个周期,这样整个网络的参数,包括预训练的前半段,和你新加入的后半段,都会按新的数据进行调整,针对特定问题的结果也会更好。
这里要注意两点:
第4步训练步长一定要小,这样每次参数的变化非常小,尽可能的保持预训练模型中的参数(一般特征)。
第3步一定要训练完成,即后半部分已经基于新数据训练过。否则,如果后半部分参数很随机,反向传播时,就算训练步长非常小,前半部分的参数也会发生非常大的波动,导致模型的基础特征被破坏。

高级神经网络不仅包括卷积神经网络,还涵盖了循环神经网络。卷积神经网络主要应用于图像识别的领域,而循环神经网络则广泛用于处理自然语言。随着Transformer模型的出现,自然语言处理的技术有了新的发展。关于自然语言处理的更多细节,将在后续关于Transformer原理的文章中详细介绍,故在此不作过多阐述。
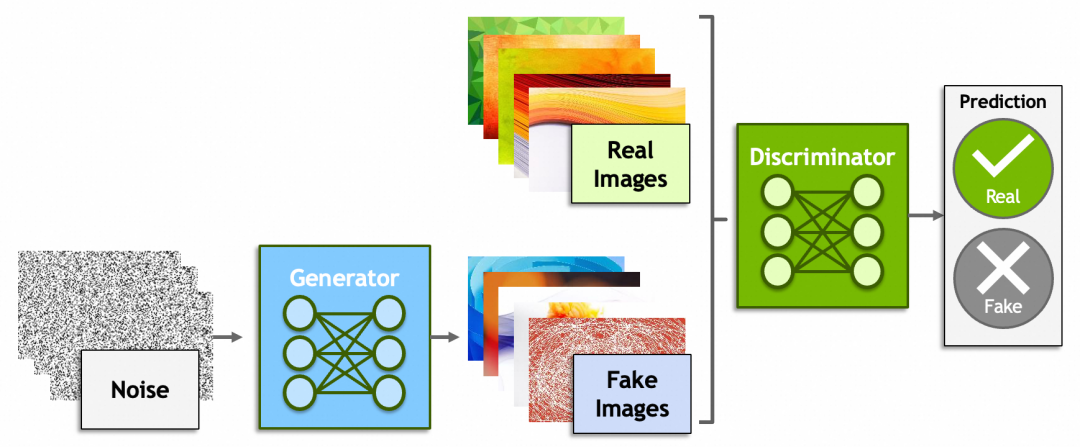
除了神经网络,深度学习里还有一些概念比较有意思,比如生成式对抗网络(Generative Adversarial Networks)、强化学习(Reinforcement Learning)。
生成式对抗网络一方是生成器(Generator)从一堆噪音里生成出假的图片,企图骗过鉴别器(Discriminator);而另一方鉴别器则尽可能的识别出真假图片。原理上还是脱离不了之前讲过的内容,鉴别器会给出一个分数,生成器会根据这个分数反向传播,修改由噪音生成图片的参数。
还记得“前GPT时代”,2022年Google研究员Blake Lemoine爆料AI有自我意识,被公司开除的新闻吗[捂脸哭]?谁说ChatGPT、MidJourney、Sora不是一些骗过了研究员、非常成功的生成式对抗网络呢?然而另一方面,就像【中文房间】描述的问题一样,哪里才是生成式对抗和真正理解的边界?大模型究竟能不能走向通用人工智能?
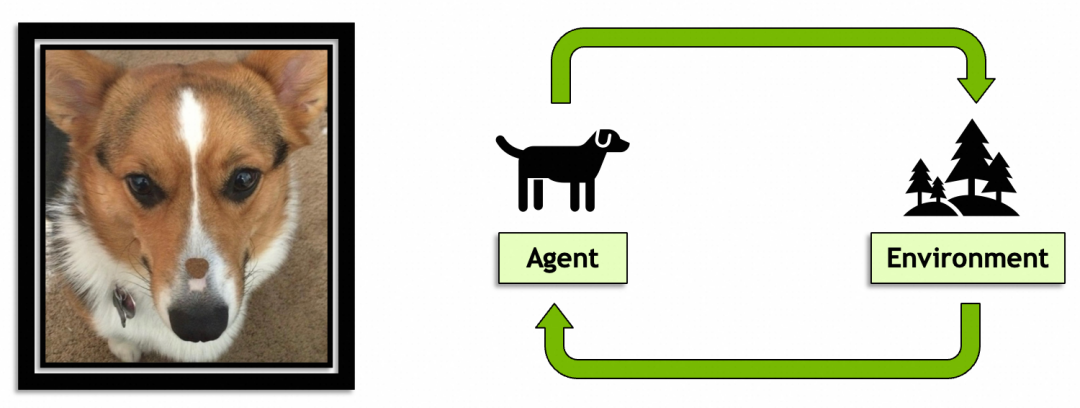
后一个概念,强化学习就是AI从环境中学习的过程和能力,目前机器人领域用得比较多。个人认为这个概念有意思是因为它是通向通用人工智能的必经之路,预计未来会扮演比较重要的角色。
本系列头两篇文章到这里就结束了,希望能激起大家学习AI原理的好奇心和勇气。个人水平有限,如果文章有什么问题,欢迎留言探讨。

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。