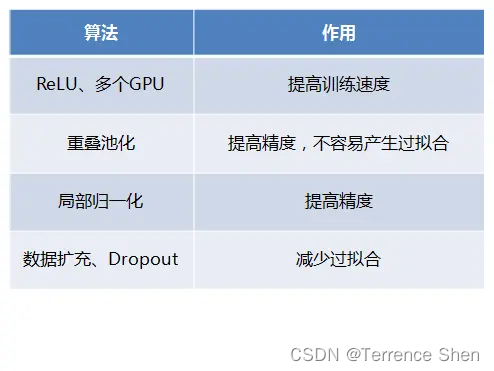
歴史的地位
2012年、トロント大学のジェフ・ヒントン研究室でAlex KrizhevskyとIlya Sutskeverが深層畳み込みニューラルネットワークAlexNetを設計し、2012年のImageNet LSVRCチャンピオンシップで優勝し、その正解率が2位を大きく上回り(トップ5のエラー率は15.3%、2位は26.2%)、大きなセンセーションを巻き起こした。AlexNet は、歴史的に重要なネットワーク構造と言えます。それ以前は、ディープ ラーニングは長い間沈黙していましたが、2012 年の AlexNet の誕生以来、その後の ImageNet チャンピオンは畳み込みニューラル ネットワーク (CNN) で作られ、層はますます深くなり、CNN が画像認識と分類の中核アルゴリズム モデルとなり、ディープ ラーニングに大きな爆発をもたらしました。
基本的
1. AlexNet モデルの特徴
AlexNet の成功は、主に次のようなこのモデル設計の特徴に関連しています。
使用した非線形活性化関数:
過学習を防ぐReLU手法:ドロップアウト、データ拡張(Data augmentation)
その他:マルチGPU実装、LRN正規化層の利用
AlexNet の機能と革新性は主に次のとおりです。
ReLUアクティベーション機能を利用する
従来のニューラル ネットワークは一般に、活性化関数として Sigmoid や Tanh などの非線形関数を使用しますが、勾配分散や勾配飽和が発生する傾向があります。シグモイド関数を例にとると、入力値が非常に大きいか非常に小さい場合、これらのニューロンの勾配は 0 に近くなります (勾配飽和現象) が、入力の初期値が大きい場合、バックプロパゲーション中に勾配にシグモイド導関数を乗算する必要があり、勾配がますます小さくなり、ネットワークの学習が困難になります。(詳細については、このブログの記事「深層学習で一般的に使用されるインセンティブ関数」を参照してください)。
AlexNet では、ReLU (Rectified Linear Units、整流線形関数) 活性化関数が使用されます。この関数の式は次のとおりです: f ( x ) = max ( 0 , x ) f(x)=\max (0, x)f ( x )=最大( 0 ,x )の場合、次の図に示すように、入力信号 < 0 の場合、出力は 0 になり、入力信号 > 0 の場合、出力は入力と等しくなります。
ローカル応答正規化 (略して LRN)
神経生物学には「側方抑制」(側方抑制)と呼ばれる概念があり、活性化されたニューロンによって隣接するニューロンが抑制されることを指します。正規化の目的は「抑制」ですが、ローカル正規化は、特に ReLU を使用する場合に、ローカル抑制を実現するために「サイド抑制」のアイデアを借用することです。局所正規化を使用するスキームは汎化能力を高めるのに役立ちます。
LRN の計算式は次のとおりです。中心となるアイデアは、正規化に隣接するデータを使用することです。この戦略は、トップ 5 のエラー率の 1.2% に寄与しています。
bx , yi = ax , yi / ( k + α ∑ j = max ( 0 , i − n / 2 ) min ( N − 1 , i + n / 2 ) ( ax , yj ) 2 ) β b_{x, y}^i=a_{x, y}^i /\left(k+\alpha \sum_{ j=\max ( 0、in / 2)}^{\min (N-1, i+n / 2)}\left(a_{x, y}^j\right)^2\right)^\betabx 、y私は=あるx 、y私は/
k+あるj = m a x ( 0 , i − n /2 )∑min ( N − 1 , i + n / 2 ) _( _x 、yj)2
b

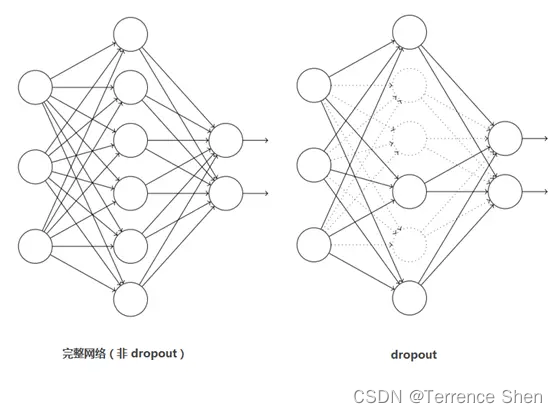
脱落
ドロップアウトは主に過学習を防ぐために導入されています。ニューラル ネットワークでは、ドロップアウトは、ニューラル ネットワーク自体の構造を変更することで実現されます。ある層のニューロンについて、定義された確率でニューロンを 0 に設定すると、このニューロンはネットワーク内で削除されるのと同じように、順方向および逆方向の伝播に参加しなくなります。同時に、入力層と出力層のニューロンの数は変更されず、ニューラル ネットワークの学習方法に従ってパラメーターが更新されます。次の反復では、トレーニングが終了するまで、いくつかのニューロンが再びランダムに削除されます (0 に設定されます)。
Dropout は AlexNet の偉大な革新とみなされるべきであり、「ニューラル ネットワークの父」ヒントンはその後長い間スピーチで Dropout を使用しました。ドロップアウトはモデルの組み合わせとみなすこともできます。毎回生成されるネットワーク構造は異なります。複数のモデルを組み合わせることで、過学習を効果的に減らすことができます。ドロップアウトでは、モデルの組み合わせの効果を得るのに必要なトレーニング時間は 2 倍だけであり (平均化と同様)、非常に効率的です。
以下に示すように:
重複プーリング
以下の図に示すように、一般的なプーリング (Pooling) はオーバーラップせず、プーリング領域のウィンドウ サイズはステップ サイズと同じです。 AlexNet で使用されるプーリング (Pooling) はオーバーラップします。つまり、プーリング中、各移動のステップ サイズはプーリング ウィンドウの長さよりも小さくなります
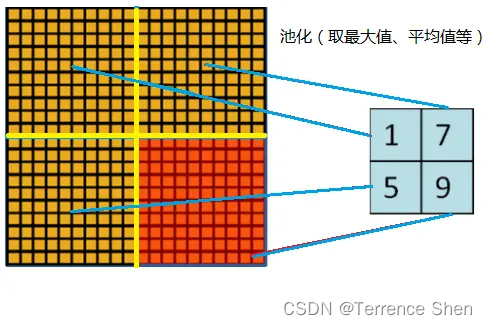
。AlexNet プーリングのサイズは 3×3 の正方形で、各プーリングは 2 ステップ サイズで移動するため、重複が生じます。重複プーリングにより過剰適合を回避でき、この戦略は上位 5 エラー率の 0.3% に寄与します。
マルチGPUトレーニング
当時、AlexNet はトレーニングに GTX580 GPU を使用していました。1 つの GTX 580 GPU のメモリは 3GB しかないため、その上でトレーニングされるネットワークの最大サイズが制限されるため、各 GPU にコア (またはニューロン) の半分を配置し、並列コンピューティングのためにネットワークを 2 つの GPU に分散することで、AlexNet のトレーニング速度が大幅に高速化されました。
データの増強
ニューラル ネットワークはデータによってフィードされるという見解がありますが、トレーニング データを増やすことができ、トレーニングに大量のデータが提供されれば、過学習を回避できるネットワーク構造がさらに増加し、深くなります。トレーニング データが制限されている場合、トレーニング データを迅速に拡張するために、いくつかの変換を通じて既存のトレーニング データ セットからいくつかの新しいデータを生成できます。著者は、ランダムクロッピングが行われない場合、大規模なネットワークは基本的に過学習になる、(3) RGB 空間に対して PCA (主成分分析) を実行し、主成分に対して (0, 0.1) ガウス摂動を行う、つまり色と光を変換すると、エラー率がさらに 1% 減少する、と述べています。

AlexNet ネットワーク構造は合計 8 層で構成されています。最初の 5 層は畳み込み層、最後の 3 層は全結合層です。最後の全結合層の出力は 1000 ウェイのソフトマックス層に渡され、1000 個のクラス ラベルの分布に対応します。
AlexNet はトレーニングに 2 つの GPU を使用するため、ネットワーク構造図は上部と下部で構成され、1 つの GPU はグラフの上の層を実行し、もう 1 つの GPU はグラフの下の層を実行し、2 つの GPU は特定の層でのみ通信します。たとえば、2 番目、4 番目、および 5 番目の畳み込み層のカーネルは、同じ GPU 上の前の層のカーネル特徴マップにのみ接続され、3 番目の畳み込み層は 2 番目の層のすべてのカーネル特徴マップに接続され、完全接続層のニューロンは前の層のすべてのニューロンに接続されます。
AlexNet の構造:
次の図は、AlexNet のネットワーク構造図です。
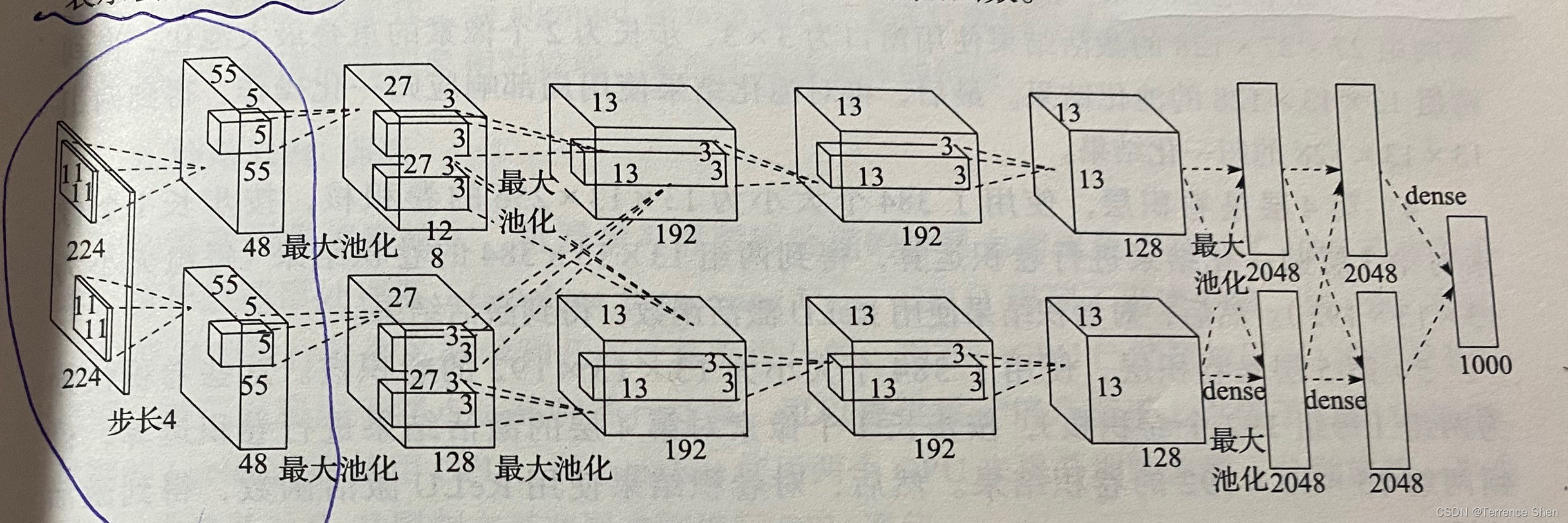
AlexNet ネットワーク構造は合計 8 層で構成されています。最初の 5 層は畳み込み層、最後の 3 層は全結合層です。最後の全結合層の出力は 1000 ウェイのソフトマックス層に渡され、1000 個のクラス ラベルの分布に対応します。
AlexNet はトレーニングに 2 つの GPU を使用するため、ネットワーク構造図は上部と下部で構成され、1 つの GPU はグラフの上の層を実行し、もう 1 つの GPU はグラフの下の層を実行し、2 つの GPU は特定の層でのみ通信します。たとえば、2 番目、4 番目、および 5 番目の畳み込み層のカーネルは、同じ GPU 上の前の層のカーネル特徴マップにのみ接続され、3 番目の畳み込み層は 2 番目の層のすべてのカーネル特徴マップに接続され、完全接続層のニューロンは前の層のすべてのニューロンに接続されます。
1. 第1層(畳み込み層)
サイズ 11X11 の 96 個のコンボリューション カーネルが使用されます。
これらのコンボリューション カーネルは 2 つのグループ (各グループに 48 個のコンボリューション カーネル) に分割され、入力層の画像に対して 4 ピクセルのステップ サイズに従ってコンボリューション演算が実行され、55X55X48 の 2 つのグループのコンボリューション結果が得られます。
次に、アクティベーション関数を使用し、
55X55X48 の 2 つのグループのアクティベーション結果に対して、ウィンドウ 3X3、ステップ サイズ 2 で重複最大プーリングを実行します。
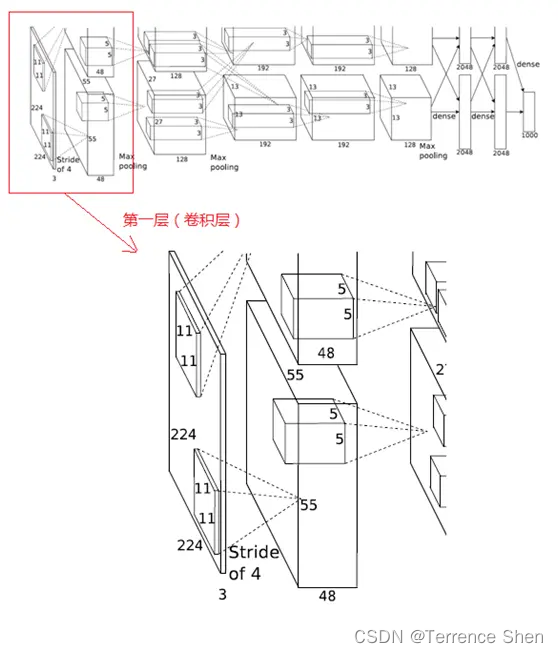
この層の処理フローは以下の通りです。畳み込み -> ReLU -> プーリング -> 正規化
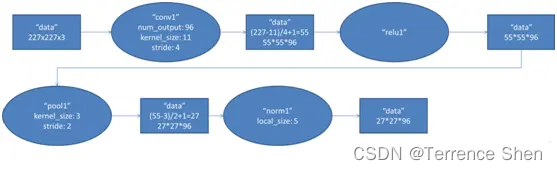
(1) 畳み込み
入力の元の画像サイズは 224×224×3 (RGB 画像) ですが、学習時に 227×227×3 になるように前処理されます。この層では、11×11×3の96個のコンボリューションカーネルをコンボリューション計算に使用して新しいピクセルを生成します。並列計算には 2 つの GPU が使用されるため、ネットワーク構造図の上部と下部はそれぞれ 48 個のコンボリューション カーネルの演算を担当します。
畳み込みカーネルは、画像に沿って x 軸と y 軸に移動して畳み込みを計算し、新しい特徴マップを生成します。そのサイズは次のとおりです:floor ((img_size - filter_size)/stride) +1 = new_feture_size、floor は切り捨てを意味します、img_size は画像サイズ、filter_size はカーネル サイズ、stride はステップ サイズ、new_feture_size は畳み込み特徴マップのサイズです。この式は、画像サイズからコンボリューション カーネル サイズをステップ サイズで割った値を減算し、生成された 1 つのピクセルに対応するカーネル サイズ ピクセルを減算した値が、コンボリューション後の特徴マップのサイズとなります。
AlexNet におけるこの層の畳み込み移動ステップ サイズは 4 ピクセルで、移動計算後に畳み込みカーネルによって生成される特徴マップのサイズは (227-11)/4+1=55、つまり 55×55 になります。
(2)
ReLU 畳み込み後の 55×55 ピクセル レイヤーは、ReLU ユニットによって処理されてアクティブ ピクセル レイヤーが生成されますが、そのサイズは 2 セットの 55×55×48 ピクセル レイヤー データのままです。
(3) RuLU をプーリングした後のピクセル層
に対してプーリング操作が行われます、プーリング操作のサイズは 3×3、ステップ サイズは 2 です、プールされたイメージのサイズは (55-3)/2+1=27、つまりプールされたピクセルのサイズは 27×27×96 となります (4) 正規
化
次に、プールされたピクセル レイヤーが正規化されます。正規化された操作のサイズは 5x5 で、正規化されたピクセル サイズは変更されず、27x27x96 のままです。96 ピクセル レイヤーは、それぞれ 48 ピクセル レイヤーを持つ 2 つのグループに分割され、各グループは独立した GPU で操作されます。
2.第2層(畳み込み層)
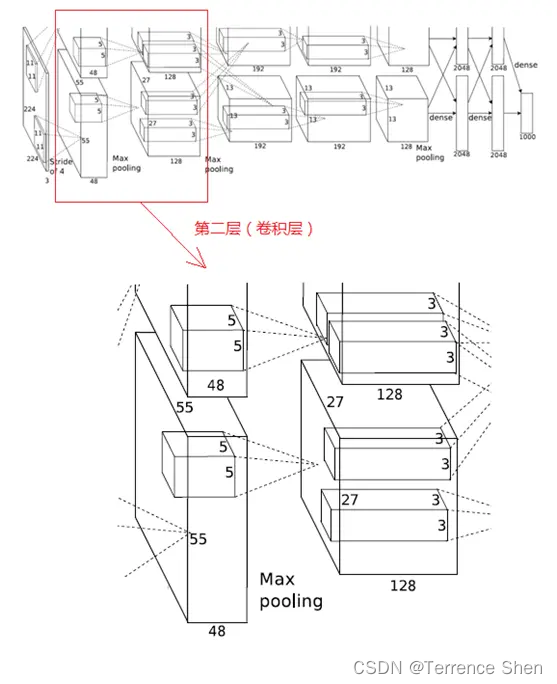
この層は第 1 層と同様で、畳み込み --> ReLU --> プーリング --> 正規化という処理の流れで、フローチャートは次のようになります。
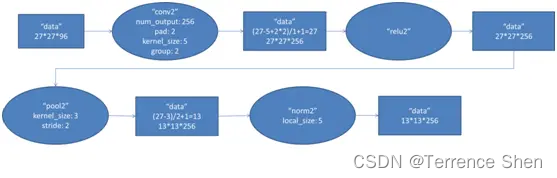
(1)
コンボリューションの第 2 層の入力データは、第 1 層が出力した 27×27×96 ピクセル レイヤー (27×27×48 ピクセル レイヤーを 2 つのグループに分けて 2 つの異なる GPU に配置して計算) ですが、後の処理の便宜上、各ピクセル レイヤーの上下左右の端を 2 ピクセルで埋める (0 で埋める)、つまり画像のサイズは (27+2+2) ×(27+2+) になります。 2)。第2層のコンボリューションカーネルのサイズは5×5、移動ステップは1ピクセルであり、第1層の点(1)の計算式と同じであり、コンボリューションカーネル計算後のピクセル層のサイズは、(27+2+2−5)/1+1=27となり、コンボリューション後のサイズは27×27となる。
このレイヤーは 256 個の 5×5×48 畳み込みカーネルを使用します。これも 128 個ずつ 2 つのグループに分割され、畳み込み演算のために 2 つの GPU に分散され、結果として 27×27×128 畳み込みピクセル レイヤーの 2 つのグループが形成されます。
(2) ReLU
これらのピクセル レイヤーは ReLU ユニットによって処理されてアクティブ ピクセル レイヤーを生成します。サイズは依然として 27×27×128 ピクセル レイヤーの 2 セットです。
(3) プーリング
とその後のプーリング演算後、プーリング演算のサイズは 3×3、ステップ サイズは 2、プーリング後の画像のサイズは (57-3)/2+1=13、つまりプーリング後のピクセルのサイズは 13×13×128 ピクセル レイヤーの 2 グループになります。 (4) 正規化とその後の正規化処理、正規化演算のスケールは 5×5、正規化されたピクセル レイヤーのサイズは 1 の 2 グループです3×13×128 のピクセル層はそれぞれ 2 つの GPU によって動作し
ます
。
3. 第3層(畳み込み層)
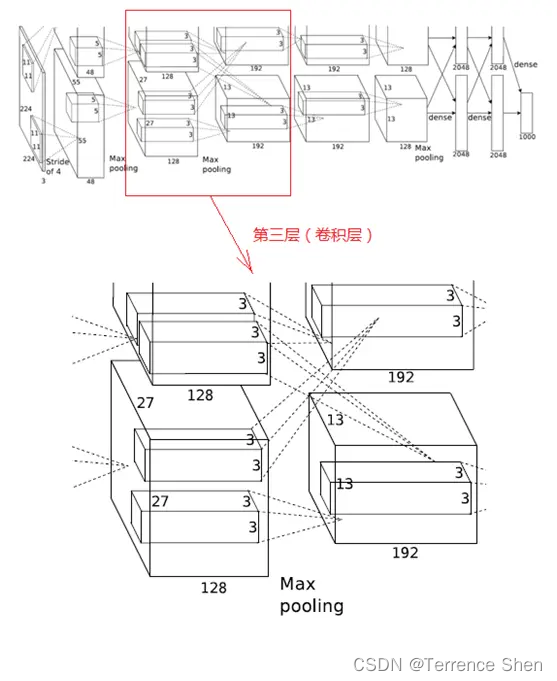
第 3 層の処理の流れは Convolution → ReLU
(1) Convolution
第 3 層の入力データは、第 2 層が出力した 13×13×128 ピクセル レイヤー 2 組で、後の処理の便宜上、各ピクセル レイヤーの上下左右の端を 1 ピクセルで埋め、埋めた後は (13+1+1)×(13+1+1)×128 となり、2 つの GPU に分散して計算します。
この層の各 GPU には 192 個のコンボリューション カーネルがあり、各コンボリューション カーネルのサイズは 3×3×256 です。したがって、各 GPU のコンボリューション カーネルは、13×13×128 ピクセル レイヤーの 2 つのグループのすべてのデータに対してコンボリューション演算を実行できます。この層の構造図に示すように、2 つの GPU が点線で交差して接続されています。これは、各 GPU が前の層のすべての GPU からの入力を処理することを意味します。
この層の畳み込みステップは 1 ピクセルで、畳み込み演算後のサイズは (13+1+1-3)/1+1=13 です。つまり、各 GPU には合計 13×13×192 個の畳み込みカーネルがあり、2 つの GPU には 13×13×384 個の畳み込みピクセル層があります。
(2)
ReLU 畳み込み後のピクセル レイヤーは、ReLU ユニットによって処理されてアクティブ ピクセル レイヤーが生成されます。サイズは依然として 13×13×192 ピクセル レイヤーの 2 グループであり、処理のために 2 つの GPU グループに割り当てられます。
4. 第4層(畳み込み層)
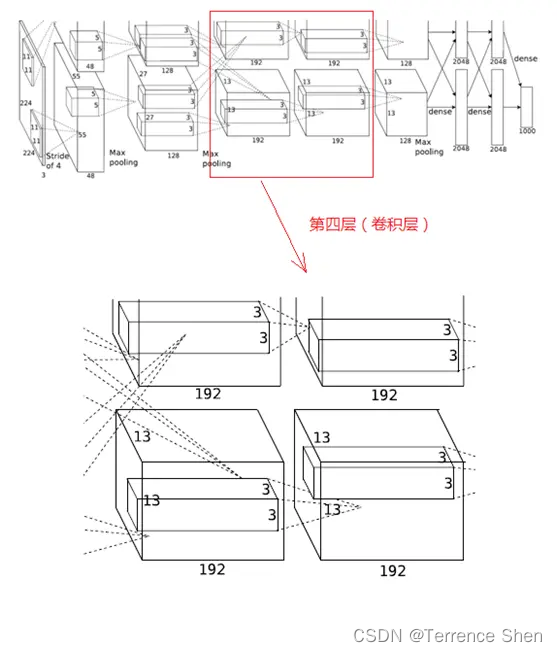
第 4 層の処理の流れは、第 3 層と同様、畳み込み → ReLU

(1) 畳み込み
第 4 層の入力データは、第 3 層が出力した 13×13×192 ピクセルのレイヤー 2 組であり、第 3 層と同様に、後の処理の都合上、各ピクセルレイヤーの上下左右の端を 1 ピクセルで埋めています。
この層の各 GPU には 192 個のコンボリューション カーネルがあり、各コンボリューション カーネルのサイズは 3×3×192 です (第 3 層とは異なり、第 4 層では GPU 間のドット接続はありません。つまり、GPU 間の通信はありません)。畳み込みの移動ステップは 1 ピクセルで、畳み込み演算後のサイズは (13+1+1-3)/1+1=13 になります。各 GPU には 13×13×192 個の畳み込みカーネルがあり、2 つの GPU は畳み込み後に 13×13×384 ピクセル レイヤーを生成します。
(2) ReLU
畳み込み後のピクセル レイヤーは、ReLU ユニットによって処理されてアクティブ ピクセル レイヤーが生成されます。サイズは依然として 13×13×192 ピクセル レイヤーの 2 つのグループであり、処理のために 2 つの GPU に割り当てられます。
5. 第5層(畳み込み層)
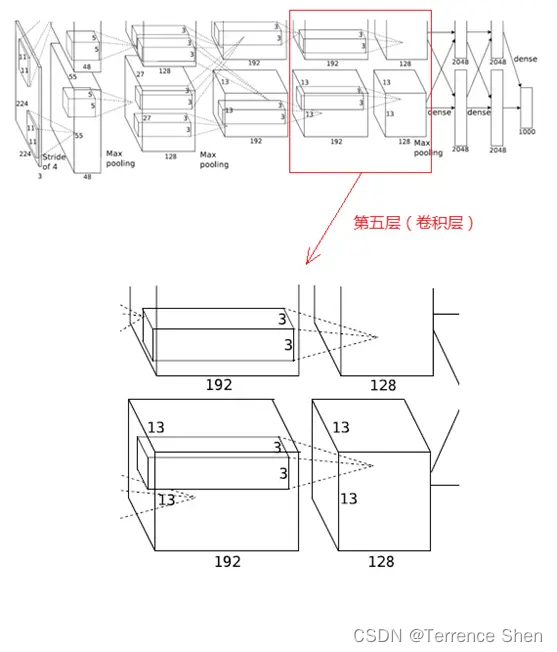
第 5 層の処理の流れは Convolution → ReLU → Pooling
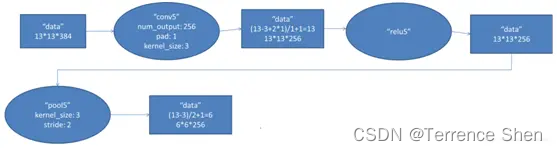
(1) Convolution
第 5 層の入力データは、第 4 層が出力した 13×13×192 ピクセル レイヤー 2 組で、以降の処理の便宜上、各ピクセル レイヤーの上下左右の端を 1 ピクセルで埋め、埋め尽くされたサイズは (13+1+1)×(13+1+1) となり、2 組のピクセル レイヤー データを異なる 2 つのレイヤーに送信します。計算用のGPU。
このレイヤの各 GPU には 128 のコンボリューション カーネルがあります。各コンボリューション カーネルのサイズは 3×3×192 です。コンボリューション ステップ サイズは 1 ピクセルです。コンボリューション後のサイズは (13+1+1-3)/1+1=13 です。各 GPU には 13×13×128 のコンボリューション カーネルがあり、2 つの GPU コンボリューションで 13×13×256 ピクセル レイヤが生成されます。
(2)
ReLU 畳み込み後のピクセル レイヤーは ReLU ユニットによって処理され、アクティブ ピクセル レイヤーが生成されます。アクティブ ピクセル レイヤーは依然として 2 つのグループの 13×13×128 ピクセル レイヤーであり、それぞれ 2 つの GPU によって処理されます。
(3) プーリング (最大重複プーリング)
2 グループの 13×13×128 ピクセル レイヤーを 2 つの異なる GPU でそれぞれ処理し、プーリング操作のサイズは 3×3、ステップ サイズは 2 です。 6ピクセルレイヤーデータ。
6. 第6層(全結合層)
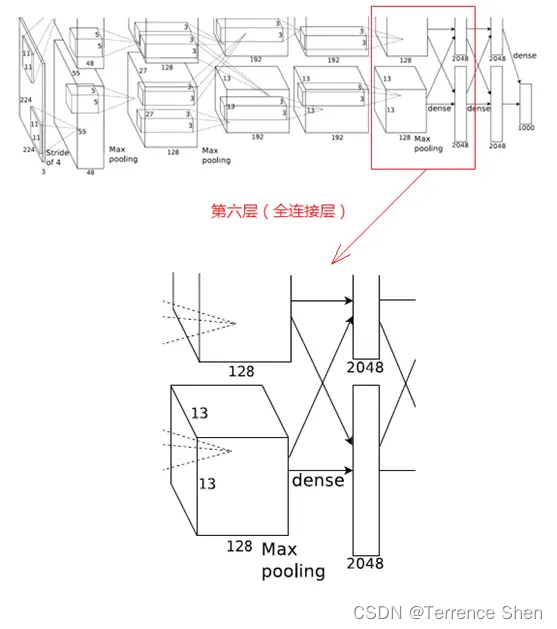
第 6 層の処理の流れは、畳み込み(全結合)→ReLU→Dropout となります。

(1)畳み込み(全結合)
第 6 層の入力データは、6×6×256 のサイズの第 5 層の出力となります。この層には畳み込みカーネルが 4096 個あり、各畳み込みカーネルのサイズは 6×6×256 です。畳み込みカーネルのサイズは処理対象の特徴マップ (入力) のサイズと全く同じであるため、つまり畳み込みカーネルの各係数には 1 対 1 に対応する特徴マップ (入力) のサイズのピクセル値が乗算されるだけであるため、この層は全結合層と呼ばれます。畳み込みカーネルのサイズは特徴マップと同じであるため、畳み込み演算後の値は 1 つだけであるため、畳み込みピクセル層のサイズは 4096×1×1、つまり 4096 個のニューロンが存在します。
(2)
ReLUの4096個の演算結果は、ReLU活性化機能により4096個の値を生成します。
(3) ドロップアウト
し、ドロップアウト操作を通じて 4096 個の結果値を出力します。
7. 第7層(全結合層)
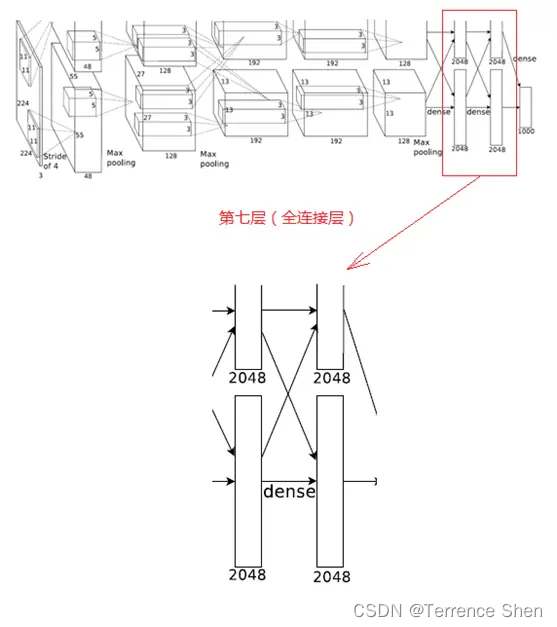
第7層の処理の流れは、全結合→ReLU→ドロップアウトです。第
6層が出力した4096個のデータは、第7層のニューロン4096個と全結合され、ReLUで処理されて4096個のデータが生成され、ドロップアウト処理後に4096個のデータが出力されます。
8. 第8層(全結合層)
第7層が出力した4096個のデータは第8層の1000個のニューロンと全結合されており、学習後には予測結果である1000個のfloat値が出力されます。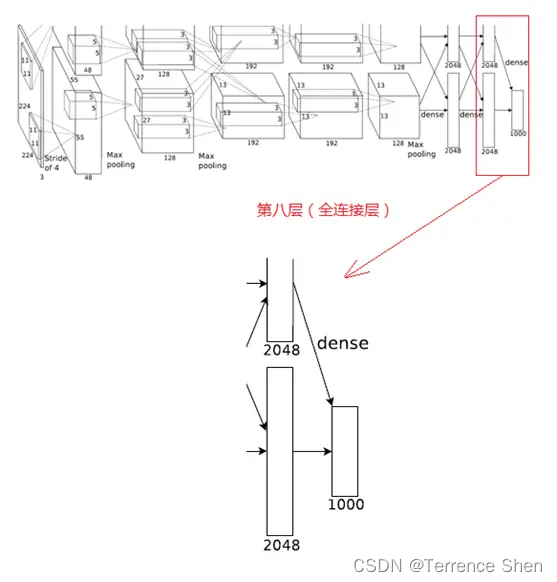
スケッチ:
