1. アンカーフリーの概要
1. まずアンカーが何であるかを知る必要があります (これには、より高速な rcnn、YOLO V2 以降や SSD などの一次検出器などの第 2 段階を理解する必要があります)。
従来、ターゲット検出は通常、候補フレームの分類と回帰としてモデル化されていましたが、候補領域の生成方法の違いに応じて、2 段階 (2 段階) の検出と 1 段階 (1 段階) の検出に分けられました。前者の候補ボックスは、RPN (地域推奨ネットワーク) ネットワークを通じて提案を生成し、特定の特徴マップ上の各位置に異なるサイズとアスペクト比の事前ボックス (アンカー) を生成します。以下に示すように:

2. なぜアンカーを放棄してアンカーフリーにするのか
1) アンカーの設定(アスペクト比、スケールサイズ、アンカーの数)を手動で設計する必要があり、データセットごとに異なる設計が必要であり、非常に面倒です。
2) Anchor のマッチング機構により、極端なスケール (極端に大きいオブジェクトや極端に小さいオブジェクト) のマッチング頻度が中程度のサイズのオブジェクトに比べて低くなり、DNN が学習中にこれらの極端なサンプルをうまく学習することは容易ではありません。
3) 膨大な数のアンカーにより、サンプリングプロセスに関わる深刻な不均衡の問題が発生しますが、実際には、Focal loss と同様の戦略は安定しておらず、サンプリングに多くのピットが存在します。
4) アンカーの数が膨大であり、アンカーごとに IOU の計算が必要となるため、膨大な計算能力が消費され、効率が低下します。
3. アンカーの方向は自由です
最も初期のアンカーフリーモデルであるはずのYOLOアルゴリズムにまで遡ることができ、最近のアンカーフリー手法は主に密予測と キーポイント推定
に基づく
2種類に分けられます 。
4. アンカーフリーの限界
現時点では、見栄えの良い結果を得るために、論文では実験の一部の詳細を隠したり、不公平な比較を行ったりしています (バックボーン ネットワークで砂時計を使用して他の人の resnet を比較するなど)。
5. アンカーフリープロジェクトの推奨
YOLOV5 の導入により、私たちはアンカーフリーの考え方を主に理解しており、エンジニアリング アプリケーションでは主に次のことを試すことができます。
1) centerNet (オブジェクトとしてのポイントバージョン)
2) ExtremeNet (回帰境界ボックスを極値点に変更)
2. アンカーフリーの解釈
以下の構成で紹介します
×、×××
1. 主な貢献
2. 主なアイデア
3. 具体的な内容
1)入力
2)バックボーン
3)首と頭
4)損失関数
5)トリック
4. 結果
A. 密集ボックス (Baidu IDL および Horizon、2015 年 9 月)
1. 主な貢献
1) FCN をターゲット検出に導入すると、優れた効率と精度を達成できます。エンドツーエンドのマルチタスクターゲット検出フレームワークです。
2) DenseBox のマルチタスク学習にターゲットランドマークの測位を導入すると、検出精度がさらに向上します。
3) 顔検出では、DenseBox は MALF と KITTI で優れた結果を達成しました。
2. 主なアイデア

上に示すように:
1) 画像ピラミッドを使用し、CNN を入力し、特徴マップ上の bbox + 分類スコアを直接予測します (つまり、5 層の特徴マップ: 4 層は Bbox 回帰を表し、1 層はバイナリ分類顔スコアを表します)
2) DenseBox の NMS ステップを除いて、モデル全体は完全な畳み込み演算であり、完全に接続された層はなく、領域提案生成ステップは必要ありません。
3) 画像はダウンサンプリング + アップサンプリング (双一次補間) されます。これはセグメンテーション ネットワーク FCN と同様です。
3. 具体的な内容
1)入力
a. トレーニング段階
元の画像には背景が多すぎるため、トレーニングではあまり意味のない背景領域の計算と判断に時間がかかります。そのため、トリミングされた画像パッチを使用して DenseBox トレーニングに参加することは、トリミングされた画像パッチには顔が含まれており、十分な背景情報があれば十分です。
具体的な操作: DenseBox トレーニングは、画像セグメンテーション手法のようなものです。まず、元の画像から画像パッチを切り抜き、次にサイズを 240 x 240 に変更します。画像の中心には、高さ約 50 の顔 gt bbox が含まれていますpix; この操作は実装が簡単で、元のイメージ + gt イメージからパッチをトリミングするのと同じですが、このパッチは顔がパッチの中心にあることを確認する必要があり、gt bbox のサイズは 50 x になります。サイズ変更後は 50 になるため、トリミングのサイズを指定する特定のパッチのサブエリアを実行する必要があります。均等な比率で計算します。栗を例にします。元の画像の顔の gt bbox が 80 x 80 であることを確認する必要があります。サイズ変更後の顔のスケールが 50 x 50 の場合、元のイメージでトリミングする必要があるパッチのサブエリアは 240 x 80 / 50 = 384、つまり 384 x 384 のサブエリアになります。
b. テスト段階
画像ピラミッドを使用する
2)バックボーン

VGG19 のネットワーク パラメータの最初の 12 層を多重化した、合計 16 層の畳み込み演算。
3)首と頭
Conv 4-4 の後には 4 つの 1 x 1 conv レイヤーが続きます。図 3 からわかるように、実際には 2 つのブランチに分割されています: 2 つの 1 x 1 conv レイヤーは最後に顔分類スコア計算用の 1 チャネルの特徴マップを出力します。他の 2 つの 1 x 1 conv レイヤーは、顔 bbox 回帰の計算に使用される 4 チャネルの特徴マップを出力します。conv 3-4 と conv 4-4 の特徴マップの特徴が融合され、連結が行われます。下位層の特徴マップ上の特徴にはターゲットのより局所的な詳細が含まれているため、ターゲットの局所領域を判断しやすくなりますが、高レベルの特徴マップ上の特徴はより大きな受容野を持っているため、 、より多くの音声情報とコンテキスト情報が含まれており、ターゲットの全体的な情報を認識するのが簡単です; conv 3-4 の受容野は 48 x 48 であり、顔の gt bbox スケールとほぼ同じです。 conv 4-4 は 118 x 118 なので、より多くのグローバル情報 + コンテキスト情報を統合できます。また、conv 4-4 の特徴マップのスケールは conv3-4 のスケールの半分です (プール 3 の操作が多くなります)。連結する場合は、conv 4-4 の双線形アップサンプリングを実行して、両方のスケールが同じであることを確認する必要があります。要素ごとの加算ではなく連結のみであるため、チャネル数が同じであることを確認する必要はありません。
4)損失
a. 分類損失、特徴マップ上のピクセル単位の L2 損失。
著者は、DenseBox の L2 損失パフォーマンスは非常に優れており、ヒンジ損失、クロスエントロピー損失などは試していないと述べました。
b. bbox 回帰損失は、特徴マップ上のピクセル単位の L2 損失でもあります。
4)トリック
a. 陽性サンプルと陰性サンプルを定義する
各ミニバッチ反復では、正のサンプルと負のサンプルの数は大きく異なり、負のサンプルが大部分を占めます。これらの負のサンプルがトレーニングに使用される場合、最終的な損失は多数の負のサンプルに偏ることになります。同時に、
分類境界上の曖昧な陽性サンプルと陰性サンプルがトレーニングされた場合
、モデルは貴重な情報を学習できず、パフォーマンスも低下します。
最終的な機能マップでは次のようになります。
肯定的なサンプル: ラベル ボックスの中心点 (個人的な理解と中心点は円の中心であり、ラベル ボックスの高さは一定の比率を持っています。たとえば、半径 0.3 の円内の点)。
陰性サンプル: 上記の陽性サンプルの外側の点。
無視サンプル: ネガティブ サンプルのピクセル (x, y)。その近くの 2 ピクセル距離以内にポジティブ サンプル ピクセルがある場合、そのピクセルは無視されたサンプルとみなされます。
b. 困難なサンプル採掘
ミニバッチでは、最初にすべてのサンプルが順方向演算を実行され、すべてのピクセル出力が式 (1) の損失に従って降順にソートされ、上位 1% が困難なネガティブ サンプルとして選択され、すべてのポジティブ サンプル (ポジティブ ラベルが付けられます)ピクセル) が保持され、ポジティブ サンプルとネガティブ サンプルの比率を 1:1 に制御します。すべてのネガティブ サンプルの半分は、ハード ネガティブ サンプル (つまり、残りの上位 99% のネガティブ サンプル) からのランダム サンプリングから取得され、残りの半分はサンプリングから取得されます。上位 1% からハードネガティブ; ミニバッチでは、サンプルが選択されているかどうかを識別するために Fsel = 1 に設定します (ポジティブ サンプル + 困難なネガティブ サンプル + ランダムに選択されたネガティブ サンプル)
ポジティブ サンプル: 入力 240 x 240 ピクセルのパッチ、パッチの中心位置には特定のスケール範囲 (約 50 x 50 ピクセル) 内のポジティブ サンプルが含まれており、各パッチにはポジティブ サンプルの近くにいくつかのネガティブ サンプルが含まれる場合があります。ネガティブ サンプル: ランダム パッチ : 画像からランダムなスケールでパッチをランダムにトリミングし (トレーニング画像からランダムなスケールでパッチをランダムにトリミング)、その後 240 x 240 ピクセルのパッチ入力ネットワークにサイズ変更します。トレーニング中に、ランダム パッチのネガティブ サンプルに対するポジティブ サンプルの比率が決まります。 1:1です。
c. データの拡張
ポジティブパッチとネガティブパッチの左右をランダムに反転、25 ピクセルの変換、スケール変換 [0.5、1.25]。
B.ヨロ V1
1. 主な貢献
1 段階の高速なエンドツーエンドのトレーニング
2. 主なアイデア

完全な畳み込みネットワークを通じて、入力画像は 7*7*30 テンソルにマッピングされます。7*7 は、画像全体が 7*7 グリッドに分割されていることを意味し、各グリッドは 2 つの事前選択ボックスで設定されます (トレーニングは可能です)。進化の考え方については、以下の左図に示すように、30 は右図に示すように各位置のエンコーディングです。
20 のオブジェクト分類の確率: YOLO は 20 の異なるオブジェクト (人、鳥、猫、車、椅子など) の認識をサポートします。
2 つの境界ボックスの位置: 各境界ボックスには、その位置を表す 4 つの値 (Center_x、Center_y、幅、高さ) が必要です。
2 つの境界ボックスの信頼度: 境界ボックス内のオブジェクトの確率 * 境界ボックスとオブジェクトの実際の境界ボックスの間の IOU。グリッドにオブジェクトが含まれていない場合、信頼度のラベルは 0 です。オブジェクトが含まれている場合、信頼度のラベルは、予測フレームと実際のオブジェクト フレームの IOU 値になります。


3. 具体的な内容
1)インアウト
入力は元の画像であり、唯一の要件はそれを 448*448 に拡大縮小することです。主な理由は、YOLO のネットワークでは、畳み込み層が最後に 2 つの全結合層に接続されており、全結合層は入力として固定サイズのベクトルを必要とするためです。
2)バックボーン
ダークネット
3)
首と頭
上の 2 つの図に示すように、合計 49*2=98 の候補領域があり、2 つの境界ボックスのサイズと形状は事前設定されておらず、各境界ボックスのオブジェクト出力の予測はありません。これは、オブジェクトの 2 つの境界ボックスを予測し、比較的正確な方を選択することのみを意味します。正確には教師ありアルゴリズムではありませんが、進化的アルゴリズムのようなものです。1 枚の写真で最大 49 個のオブジェクトを検出できます。オブジェクトの境界ボックスの中心位置を計算し、その中心位置がどのグリッドに該当するかを計算し、そのグリッドに対応する出力ベクトル内のオブジェクトのカテゴリ確率が 1 であり、これがオブジェクトの予測に関与します。オブジェクトの他のグリッドは 0 に設定されます (オブジェクトの予測には関与しません)。
4)
損失関数

5)裏技
a. 中心点の座標値を直接返すのではなく、格子点の左上隅の座標を基準とした相対的な変位値を返します。
b. 各格子点は 2 つ以上の長方形のボックスを予測します. 損失関数の計算では, 実物体に最も近いボックスの損失のみが計算され, 残りのボックスは補正されません. 著者は 2 つのボックスを予測しました.格子点のサイズやアスペクト比、またはいくつかのカテゴリが段階的に分割され、全体の再現率が向上します。
c. 推論中、オブジェクトのカテゴリ予測の最大値 p に予測ボックスの最大値 c を乗算した値を、出力予測オブジェクトの信頼度として使用します。
C、FCOS (完全畳み込み 1 段階物体検出はオープンソースになっています)
1. 主な貢献
1) 重複点の解決方法: FPN 階層化 + 同じレイヤーが重複する属性領域を持つ最小のボックスを使用します
2) ピクセル単位の低品質フレームを解決する方法: 中心性戦略を提案 (本質は YOLOV1 の予測対象と同じであると個人的に考えています)
2. 主なアイデア
FPNを使用して特徴マップ上のすべての点を実行します:分類の予測+位置回帰+中心かどうか(個人的には本質はYOLOV1の予測対象と実際には同じであると考えています)

3. 具体的な内容
1)入力
特別な要件はありません
2)バックボーン
特別なことは何もありません。実験では resnext-32x8d-101-fpn などを試しました。
3)首と頭
a. 上の図 2 に示すように、FPN ネイティブ実装とは若干異なることに注意してください。
FCOS は、バックボーンによって出力された C3、C4、および C5 特徴マップを使用し、P3、P4、および P5 を水平合成します。P6 と P7 は、ステップ サイズ 2 の畳み込み層を介して P5 と P6 によって取得されます。最終的な特徴マップはすべて合計 5 であり、ダウンサンプリング倍数はそれぞれ 8、16、32、64、および 128 です。
b.label は分類 + 回帰で構成されます。
位置 (x, y) が与えられた場合、その点が GT 境界ボックス内にある場合、その位置は正の例として識別され、カテゴリ ラベル c* がそれに付けられます。それ以外の場合、c*=0 は背景を意味します。さらに、この位置 (x, y) に対して、回帰の対象として 4 次元ベクトル t = (l*, t*, r*, b* ) を与えます。(l*、t*、r*、b* は、点から境界ボックスの左 (左)、上 (上)、右 (右)、下 (下) までの距離をそれぞれ表します)。下の図。

回帰ターゲットはほぼすべて正のサンプルであるため、exp() 関数を使用して回帰ターゲットを (0, ∞) にマップします。これには、境界ボックスの認識が向上するという利点があります。
与えられた画像に対して、各位置のカテゴリ スコア Px, y と位置回帰予測 t (x, y) が FCOS によって取得され、px, y > 0.05 の位置が正の例として選択されます。
アンカー ベースの方法では、アンカー ボックスを選択するときに、GT との IOU 比が考慮され、しきい値を超えたものは正のサンプルとなります。違いは、FCOS がトレーニング回帰にできるだけ多くの前景サンプルを使用できることです。
c. 重複領域処理

最初のケース (特徴マップの同じレイヤー内): 小さな領域を持つ境界ボックスを回帰ターゲットとして選択します。これにより、不鮮明なサンプルを大幅に減らすことができます。
2 番目のケース (FPN による異なるレイヤーのフィーチャ マップ): 異なるレイヤーのフィーチャ マップを使用して、異なるサイズのオブジェクトを検出します。
具体的な方法:
位置が max(l∗, t∗, r∗, b∗) > mi または max(l∗, t∗, r∗, b∗) < mi-1 を満たす場合、その位置は負のサンプルとして設定されるため、もう境界ボックスを回帰する必要はありません。ここで mi は、特徴レベル i が後退するために必要な最大距離です。この作品ではm2、m3、m4、m5、m6、m7を0、64、128、256、512、∞に設定しています。
d.中心性

FPN を使用した後も、ネットワークの効果と最先端のターゲット検出アルゴリズムの間にはまだギャップがあり、分析の結果、低品質の検出フレームが原因であることが判明しまし
た
。
畳み込みニューラル ネットワークでは、特徴マップ上の点が受容野の中心に対応するため、現在の人物を予測するには、図 5 のオレンジ色の点が 2 つの緑の点よりも優れているはずです。次に、2 つの緑色の点は低品質予測点と呼ばれます。中心性とはグリーンポイントの重みを抑えることです。まず中心性の計算式を見てください。

式によれば、点がグラウンド トゥルースの中心に近いほど、中心性の値は高くなります。しかし、ここで新たな問題が発生します. 中心性を取得するには 2 つの方法があります. 1: 予測値 l*, r*, t*, b* に従って直接中心性を計算する; 2: 中心を返すラベル値 l、r、t、b に従って、ness 値を個別に指定してブランチをトレーニングします。図 4 のネットワーク構造から、著者が方法 2 を採用したことがわかります。実際、著者は 2 つの方法を比較しました。

結果が最終決定権を持ちます。つまり、単一の中心性回帰ブランチが mAP を改善します。
4)損失関数

UnitBox の論文では、カテゴリ損失関数は焦点損失を使用し、回帰損失関数は IOU 損失を使用します。
コードを確認すると、実際には BCEloss を使用する中心性損失関数ブランチがありますが、ラベルはワンホット エンコーディングのバイナリ分類ラベルではなく、上記の中心性に対して計算されます。
5)トリック
なし
4. 結果
論文内の比較実験結果:
 図 8 FCOS 精度比較
図 8 FCOS 精度比較
少なくとも、FCOS の精度は古い古典的なアルゴリズム Faster R-CNN を超えていることがわかります。

FCOSのパフォーマンス
速度の具体的な値については論文では詳しく言及されていませんが、上記の数値は論文の公式 Web サイトのコードから引用したものであり、マシンによっては値が若干異なる可能性があります。推論速度は2段階のFaster R-CNNほど速くはありませんが、基本的にリアルタイム性能を満たしています。mAP は Faster R-CNN を大幅に上回っています。
D、 FSAF(シングルショット物体検出用の特徴選択的アンカーフリーモジュール)
1. 主な貢献
FPN を使用する現在のターゲット検出とグラウンド トゥルースおよびアンカーのアイデアのマッチングでは、主に自動マッチング方法を提供する iou または階層メカニズムに依存しています。
2. 主なアイデア
FPN の各レイヤーを使用してインスタンスを検出してみて、どのレイヤーの検出結果がこのインスタンスの損失が最小であるか、このレイヤーがこのインスタンスの検出に最適であるかを確認します。
3. 具体的な内容
1)入力
解決策は必要ありません
2)バックボーン
著者はresnext-101を実験してみた
3)
首と頭
a. 支店構造
FSAF モジュールを使用すると、各インスタンスが FPN 内の最適なフィーチャ レイヤーを自動的に選択できます。このモジュールでは、フィーチャ選択の基準が元のインスタンスのサイズからインスタンスのコンテンツに変更され、自動モデル学習が実現され、FPN で最適なフィーチャ レイヤーを選択できます。 FPN。
FSAF は RetinaNet を基本構造として使用し、元の分類サブネットおよび回帰サブネットと並行して FSAF ブランチを追加するため、元の構造を変更することなく完全なエンドツーエンドのトレーニングを実現できます。FSAF には、図に示すように、分類 (シグモイド関数を使用) とボックス回帰の 2 つのブランチも含まれており、これらはターゲットのカテゴリと座標値を予測するために使用されます。

b. バベル定義
最初: ターゲット (インスタンス)、そのカテゴリが
lable = c であり、
境界ボックスの座標が であると 仮定し
 ます。(x, y) はターゲットの中心座標です。
ます。(x, y) はターゲットの中心座標です。
(w, h) はオブジェクトの幅と高さです。
2 番目: FPN におけるこのターゲットの
 フィーチャ レイヤー投影の座標は です
フィーチャ レイヤー投影の座標は です
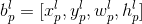 。ここで、 は です
。ここで、 は です
 。
。
3 番目: 定義投影の有効なターゲット フレーム座標は です
 。つまり、図 3 の「car」クラスの白い領域です。ここで、
。つまり、図 3 の「car」クラスの白い領域です。ここで、
 式の は です
。
式の は です
。
4 番目: 定義投影の無視されたターゲット フレームの座標は です
。つまり、図 3 の「car」クラスの灰色の領域です。ここで
、式の は です
 。
。

クラス出力: クラス出力はアンカーベースのブランチを備えた並列構造です。その次元は W×H×K、K はカテゴリの総数 (背景カテゴリを含む必要があります)、クラス出力には合計 K 個の特徴マップがあります。このターゲットのカテゴリを c (図では自動車カテゴリ) とすると、クラス出力のラベル次元は W×H×K のテンソルとなり、K 特徴量のうち c 番目の特徴マップの定義となります。マップは図 3 の「car」クラスにあります。白い領域は
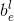 定義値 1 の正のターゲット領域、灰色の領域は無視される領域、つまり
定義値 1 の正のターゲット領域、灰色の領域は無視される領域、つまり
 勾配逆伝播は実行されません。黒の領域は定義
値 0 の負のターゲット領域です。使用される関数は Focal Loss です。
勾配逆伝播は実行されません。黒の領域は定義
値 0 の負のターゲット領域です。使用される関数は Focal Loss です。
ボックス出力: ボックス出力はアンカーベースのブランスを備えた平行構造で、その寸法は W×H×4 で、4 はオフセットを表します。オフセットの意味を説明するための例を示します。ボックス出力のラベルは 有効領域
 内のピクセルの もので
内のピクセルの もので
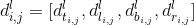 、4 つの次元の値は です 。
ここで、 は上、左を基準とした ピクセル位置です。 図 4 に示すように、それぞれ、下、および右です。さらに、S =4.0 です。使用される損失関数は IoU Loss です。
、4 つの次元の値は です 。
ここで、 は上、左を基準とした ピクセル位置です。 図 4 に示すように、それぞれ、下、および右です。さらに、S =4.0 です。使用される損失関数は IoU Loss です。
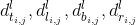
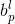
ピクセル点で
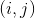 、予測されたオフセットが
、予測されたオフセットが
 、 まで の距離が
、 まで の距離が
 、 予測された 左上隅と右下隅の座標がそれぞれと の 場合、予測されたバウンディング ボックスの座標はそれぞれ と と と で乗算さ れ ます 。
、 予測された 左上隅と右下隅の座標がそれぞれと の 場合、予測されたバウンディング ボックスの座標はそれぞれ と と と で乗算さ れ ます 。


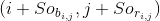

3)損失関数
a. アンカーベースのアルゴリズムでは、通常、ターゲットのサイズは指定されたフィーチャ レイヤーに割り当てられますが、FSAF モジュールはターゲットの内容に基づいて最適なフィーチャ レイヤーを選択します。番目のフィーチャ レイヤーに割り当てられた分類損失と位置推定損失は次のとおりです。

ここで、 は有効領域の画素数です。
次に、最適な予測ターゲットを持つフィーチャ レイヤーが次の式によって取得されます。つまり、結合損失関数が最小になります。
b. アンカーなしのブレースとアンカーベースのブレースを組み合わせるにはどうすればよいですか?
推論では、FSAF は予測結果を分岐単独で出力することも、元のアンカーベースの分岐と同時に予測結果を出力することもできます。両方が存在する場合、2 つのブランチの出力結果が結合され、NMS を使用して最終的な予測結果が得られます。トレーニングではマルチタスクロスが使用されます。つまり、式は次のとおりです。
重み係数は 0.5 です。
5)トリック
なし
4. 結果
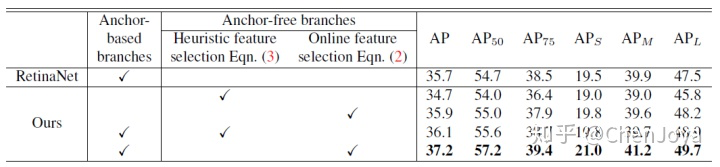
E、フィーベアボックス
1. 主な貢献
多くの考え方は fcos と FSAF に似ているため、違いは、回帰ではターゲットの中心から 4 つの側面までの距離を直接学習するのではなく、予測された座標と実際の座標の間のマッピング関係を学習することです。
2. 主なアイデア
オブジェクトの存在確率とグラウンド トゥルース ボックスの座標を直接学習します (事前選択ボックスは生成されません)。主に次の 2 つの支店を通じて行われます。
クラス依存のセマンティック グラフがオブジェクトとして存在する確率を予測する
中心点とフレーム座標の間のマッピング関係を予測する

3. 具体的な内容
1) 入力
画像の解像度に特別な要件はありません。
2)バックボーン
主にretina netと比較し、バックボーンはResNet101とResNext101を試してみました。
3)首と頭
a. RetinaNet との公平な比較を行うために、著者は、ピラミッドの層数と入力画像の解像度がまったく同じネットワーク構造、つまり ResNet+FPN の構造を使用しまし
 た
た
 。
。

b. Bbox に一致
FPN の各層が特定の範囲内のバウンディング ボックスを予測すると仮定し、各特徴ピラミッドには基本領域、つまり 32*32 ~ 512*512 があるため、次のように表され、 と設定され
 ます
ます
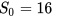 。l=3 のとき、全体の面積は 1024=32*32 になります。ただし、各レイヤーを特定のオブジェクト スケールに応答させるために、FoveaBox は 次のように 各ピラミッド レイヤー
L の有効範囲を計算します。これは、このスケール範囲を制御するために使用されます (私の理解では、エリア マッチングに依存しています)。
。l=3 のとき、全体の面積は 1024=32*32 になります。ただし、各レイヤーを特定のオブジェクト スケールに応答させるために、FoveaBox は 次のように 各ピラミッド レイヤー
L の有効範囲を計算します。これは、このスケール範囲を制御するために使用されます (私の理解では、エリア マッチングに依存しています)。
実験の結果、著者は制御係数が 2 のときが最適な状況であることを発見しました。

c. ポジティブ領域とネガティブ領域の決定
まず、予測分類のサブネットワークを見てみましょう。その出力は一連のピラミッド型ヒートマップであり、各ヒートマップのサイズは HxW、次元は K (K はカテゴリの数) です。指定されたグラウンド トゥルース ボックスが (x1,y1,x2,y2) である場合、まずそれをターゲット ピラミッドにマッピングします。つまり、次のようになります。

陽性サンプル領域(中心窩)は、DenseBox の設定と同じ、元の領域の減衰領域として設計されています。この設定の理由は、意味領域の重なりを防ぐためです。その中には
 スケーリング係数が含まれており、陽性サンプル領域の各セルには対応するカテゴリ ラベルが割り当てられます。負のサンプルの場合、負のサンプル領域を生成するための倍率も設定します
スケーリング係数が含まれており、陽性サンプル領域の各セルには対応するカテゴリ ラベルが割り当てられます。負のサンプルの場合、負のサンプル領域を生成するための倍率も設定します
 。セルが割り当てられていない場合、無視領域はバックプロパゲーションに参加しません。この設定は FSAF に非常に似ています。サンプル間の不均衡のため、焦点損失を使用して最適化します。中心窩面積の計算式は次のとおりです。
。セルが割り当てられていない場合、無視領域はバックプロパゲーションに参加しません。この設定は FSAF に非常に似ています。サンプル間の不均衡のため、焦点損失を使用して最適化します。中心窩面積の計算式は次のとおりです。
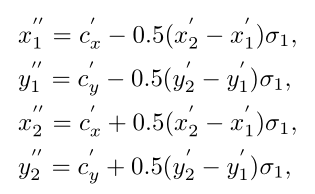
下図に示すように、ズーム率を設定することにより、プラス領域とマイナス領域、無視される領域に分割されます。特徴マップ全体に比べて正のサンプル領域の割合が比較的小さく、トレーニング中に正のサンプルと負のサンプルのバランスが崩れるため、分類損失は焦点損失であることがわかります。

4)損失関数
分類 + 回帰損失の使用 (境界予測)
a. 分類損失
分類には焦点損失が使用されており、具体的な実装ペーパーでは言及されていませんが、推測では、各クラス (分類ブランチの各特徴マップ、正と負に注目し、領域を無視) が 2 つのカテゴリに分けられ、その場合は sigmod が使用されます。
b. 回帰分岐
次に、単純な L1 損失が最適化に使用されます。ここで、 は
 出力空間を 1 を中心とする空間にマッピングする正規化係数であり、トレーニングを安定させます。最後に、ログスペース関数を正規化に使用します。
出力空間を 1 を中心とする空間にマッピングする正規化係数であり、トレーニングを安定させます。最後に、ログスペース関数を正規化に使用します。
5)トリック
なし
4. 結果

上の図から、アンカーベースと比較して、アンカーフリー アルゴリズムはターゲットの規模に対してより堅牢であり、アンカーのサイズを苦労して設計する必要がないことがわかります。
次に AP と AR の比較です。
1) FoveaBoxとRetinaNetの比較

2) ASFA(CVPR2019)との比較
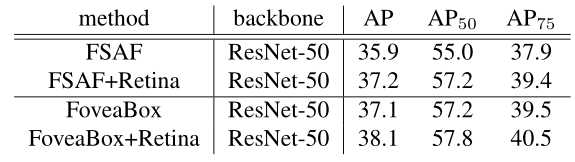
3) 他のSOTA手法との比較(coco test-dev)

F、CenterNet (ポイントとしてのオブジェクトはオープンソースです)
1. 主な貢献
1) このアルゴリズムにより、非効率的で複雑なアンカー操作が削除され、検出アルゴリズムのパフォーマンスがさらに向上します。
2) このアルゴリズムは、ヒートマップ上でフィルタリング操作を直接実行するため、時間のかかる NMS 後処理操作が不要になり、アルゴリズム全体の実行速度がさらに向上します。
3) このアルゴリズムは 2D ターゲット検出だけでなく、簡単な変更で 3D ターゲット検出や人物キーポイント検出などの他のタスクにも適用でき、汎用性が優れています。
2. 主なアイデア

CenterNet は、ターゲット検出問題を中心点予測問題に変換します。つまり、ターゲットはターゲットの中心点によって表され、ターゲットの長方形フレームは、ターゲット中心点のオフセットと幅を予測することによって取得されます。
このモジュールには、中心点ヒートマップ ブランチ、中心点オフセット ブランチ、およびターゲット サイズ ブランチを含む 3 つのブランチが含まれています。
1) ヒートマップ ブランチには C チャネルが含まれており、各チャネルにはカテゴリが含まれており、ヒートマップ内の白く明るい領域はターゲットの中心点の位置を示します。
2) 中心点オフセット ブランチは、プールされた低ヒートマップ上の点を元の画像にマッピングすることによって生じるピクセル エラーを補うために使用されます。
3) ターゲット サイズ ブランチは、ターゲット長方形の w と h の偏差値を予測するために使用されます。
CenterNet ネットワークの推論フェーズの実装手順は次のとおりです。
ステップ 1 - 画像を入力し、画像サイズを 512*512 に処理して、ネットワークの入力として使用します。
ステップ 2 - ネットワークの順計算を実行すると、サイズ [1,80,128,128] のヒートマップ、サイズ [1,2,128,128] のサイズ予測、サイズ [1,2,128,128] のオフセット予測、という 3 つの出力が生成されます。
ステップ 3 - ヒートマップはシグモイド関数を渡して範囲を 0 から 1 にし、ヒートマップ上で最大プーリング操作を実行します (カーネルは 3 に設定され、ストライドは 1 に設定され、パッドは 1 に設定されます。このステップは実際にリピートボックスを実行しています フィルタリングは、将来的に NMS 操作が必要なくなる重要な理由でもあります 結局のところ、3✖️3 サイズのカーネルと特徴マップと入力画像間の stride=4 は、12✖️ ごとに相当します入力画像内の 12 サイズの領域。中心点が繰り返されることはありません。このアイデアは非常にシンプルで効果的です)。次に、ヒートマップに基づいて最高スコアを持つ上位 K 点を選択します (デフォルトの K=100 により、最も信頼性の高い 100 個の予測ボックスの中心点が決定されます。このステップでは、特定の繰り返しボックスも削除されます)。信頼度のしきい値を設定でき、しきい値よりも高い値のみを出力します。
ステップ 4 - 出力サイズ予測値とオフセットを通じて予測ボックスのサイズを決定します。取得された予測フレーム情報はすべて 128✖️128 サイズの特徴マップ上にあるため、最後に予測フレーム情報が入力画像にマッピングされて、最終的な予測結果が得られます。
3. 具体的な内容
1)入力
512*512
入力画像を 512*512 サイズにカットする必要があります。
つまり、長辺を 512 に拡大縮小し、短辺を 0 で埋めます
。具体的な効果は次の図に示されています。元の画像の W>512 であるため、 、元の画像の H<512 のため、直接 512 にスケーリングされます。したがって、それに対して 0 補数演算を実行します。

2)バックボーン
論文では、Hourglass、ResNet、DLA の 3 つのネットワーク アーキテクチャを試し、各ネットワーク アーキテクチャの精度とフレーム レートは次のとおりです。
アップコンボリューション層を備えた Resnet-18:28.1% coco および 142 FPS
DLA-34:37.4% COCOAP および 52 FPS
Hourglass-104:45.1% COCOAP および 1.4 FPS

3)首と頭
このモジュールには、中心点ヒートマップ ブランチ、中心点オフセット ブランチ、およびターゲット サイズ ブランチを含む 3 つのブランチが含まれています。
ヒートマップ グラフ ブランチには C チャネルが含まれており、各チャネルにはカテゴリが含まれており、ヒートマップ内の白く明るい領域はターゲットの中心点の位置を示します。
中心点オフセット ブランチは、プールされた低ヒートマップ上の点を元の画像にマッピングすることによって生じるピクセル エラーを補うために使用されます。
ターゲット サイズ ブランチは、ターゲット長方形の w および h 偏差値を予測するために使用されます。
a. ヒートマップは分類情報を表し、カテゴリごとに個別のヒートマップが生成されます。各ヒートマップでは、特定の座標にターゲットの中心点が含まれる場合、キー ポイントがターゲットに生成され、ガウス円が使用されます (予測されたコーナー ポイントが中心点の特定の半径 r 以内にある限り) 、長方形のボックスと gt_bbox の間の IoU が 0.7 より大きい場合、これらの点の値を 0 の値ではなくガウス分布値に設定します。) キー ポイント全体を表すため、次の図に具体的な詳細を示します。 。

ヒートマップを生成する具体的な手順は次のとおりです。
ステップ 1 - 入力画像を 512*512 のサイズにスケーリングし、画像に対して R=4 のダウンサンプリング操作を実行して、サイズ 128*128 のヒートマップ画像を取得します。
ステップ 2 - 入力画像内のボックスを 128*128 サイズのヒートマップにスケールし、ボックスの中心点の座標を計算し、切り捨て演算を実行して、それを点として定義します。
ステップ 3 - ターゲット ボックスのサイズに従ってガウス円の半径 R を計算します。ガウス円の半径の決定は、主にターゲット ボックスの幅と高さに依存します。実際には、通常、IOU=0.7 が使用されます。 、つまり下図ではoverlap=0.7 臨界値として3つの場合の半径をそれぞれ計算し、その最小値をガウスカーネルの半径Rとする 具体的な実装内容は図に示す下:
(1) ケース 1 - 予測ボックス pred_bbox には gt_bbox ボックスが含まれており、下図の最初のケースに対応し、IoU 式全体を展開した後、二元一次方程式を解く問題になります。
(2) Case 2-gt_bbox には予測ボックス pred_bbox box が含まれており、下図の 2 番目のケースに相当し、IoU 式全体を展開した後、2 値一次方程式を解く問題になります。
(3) 状況 3-gt_bbox と予測ボックス pred_bbox が重なっている。下図の 3 番目の状況に対応し、IoU 式全体を拡張した後、2 値一次方程式を解く問題になります。

ステップ 4 - サイズ 128*128 のヒートマップ上で、中心点として point を使用し、半径 R を使用してガウス値を計算します。点における値が最大となり、半径 R が増加するにつれて値は減少します。

上図はサンプルで、左側がトリミング後の512512サイズの入力画像、右側がガウス演算後に生成された128128サイズのヒートマップ画像を示しています。画像には 2 匹の猫が含まれているため、これら 2 匹の猫は同じカテゴリに属しているため、同じヒートマップ上に 2 つのガウス円が生成され、ガウス円のサイズは長方形のボックスのサイズに関係します。
4)損失関数
全体的な損失は 3 つの部分で構成されます。L k はヒートマップの中心点の損失を表し、Loff はターゲットの中心点のオフセット損失を表し、L size はターゲットの長さと幅の損失関数を表します。

a. ヒートマップ損失関数

N は、入力イメージ内のターゲットの数とヒートマップ内のキー ポイントの数です。上式の
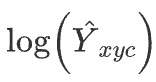 と は
と は
 クロスエントロピー損失関数であり、
は
クロスエントロピー損失関数であり、
は
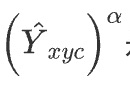 焦点損失項目であり、
これらの位置にあるオブジェクトの境界ボックスの中心は非常に近いため、半径範囲内の損失を抑制します。
焦点損失項目であり、
これらの位置にあるオブジェクトの境界ボックスの中心は非常に近いため、半径範囲内の損失を抑制します。
b.オフセット損失関数
このうち、O^p~はネットワークが予測したオフセット値、pは画像の中心点の座標、Rはヒートマップの倍率、p~はスケーリング後の中心点の近似整数座標を表します。 、プロセス全体は L1 損失を使用して、正のサンプル ブロックのオフセット損失を計算します。バックボーン ネットワークによって出力される特徴マップの空間解像度は、元の入力画像の 4 分の 1 であるため。つまり、出力特徴マップ上の各ピクセルは元の画像の 4x4 領域に対応し、大きな誤差が生じるため、偏った損失値が導入されます。
目標中心点 p が (125, 63) であるとすると、入力画像サイズが 512*512、スケーリング スケール R=4 であるため、スケーリングされた 128x128 サイズの中心点の座標は (31.25, 15.75) となります。整数座標 (31 , 15) に対するオフセット値は (0.25, 0.75) です。
c. ターゲットの長さと幅の損失関数
このうち、N はキーポイントの数を表し、Sk はターゲットの実際のサイズを表し、S ^ pk は予測サイズを表し、プロセス全体は L1 損失を使用して陽性サンプル ブロックの長さと幅の損失を計算します。
5)トリック
a. 2 つのオブジェクトのヒート マップ間に交差がある場合、その点の値が最大になります。
b. 2 つのオブジェクトの中心点が一致する場合、計算は解決されませんが、論文評価セット (ココ データ セット) では、このケースは 0.1% のみを占めます。
4. 結果

上の表は、COCO 検証セットでの CenterNet ターゲット検出の精度と速度を示しています。行 1 は、Hourglass-104 をベンチマーク ネットワークとして使用すると 40.4 AP を取得できるだけでなく、14FPS の速度も取得できることを示しています。行 2 は、DLA-34 をベンチマーク ネットワークとして使用して取得された AP と FPS を示しています。行 3 と行 4線は、COCO 検証セットに対する ResNet-101 および ResNet-18 ベンチマーク ネットワークの影響を示しています。観察を通じて、DLA-34 に基づくベンチマーク ネットワークが精度と速度の間のトレードオフを達成できることがわかります。
高密度検出の概要に基づく
FSAF、FCOS、FoveaBox の類似点と相違点:
1. どちらもマルチスケールのターゲット検出に FPN を使用します。
2. 分類と回帰は両方とも、処理のために 2 つのサブネットワークに分離されます。
3. 分類と回帰は両方とも、密な予測を通じて実行されます。
4. FSAF と FCOS の回帰は 4 つの境界までの距離を予測しますが、FoveaBox の回帰は座標変換を予測します。
5. FSAF はオンライン機能選択を通じてより適切な機能を選択し、パフォーマンスを向上させます FCOS は中心性ブランチを通じて低品質の bbox を排除することでパフォーマンスを向上させます FoveaBox はターゲットの中心領域のみを予測することでパフォーマンスを向上させます
(DenseBox、YOLO) と (FSAF、FCOS、FoveaBox) の類似点と相違点:
1. 分類と回帰は両方とも、密な予測を通じて実行されます。
2. (FSAF、FCOS、FoveaBox) はマルチスケール ターゲット検出に FPN を使用しますが、(DenseBox、YOLO) はシングルスケール ターゲット検出のみを備えています。
3. (DenseBox、FSAF、FCOS、FoveaBox) は分類と回帰を 2 つのサブネットワークに分離することによって取得されますが、(YOLO) 分類と位置は均一に取得されます。
以下はキーポイント推定に基づくアンカーフリー検出です。
A. CornerNet (オープンソース)
1. 主な貢献
1) 左上と右下のヒートマップを設計し、左上と右下の可能性が最も高いポイントを見つけ出し、ブランチを使用して埋め込みベクトルを出力し、左上と右下の判断に役立てます。間の一致関係。
2) コーナープーリングの提案 検出タスクの変更のため、従来のプーリング方法はこのネットワークフレームワークにはあまり適していません。(後述)
2. 主なアイデア

ネットワークには 2 つのブランチがあり、1 つのブランチは左上隅を予測し、もう 1 つは右下隅を予測します。
各ブランチには 3 つのラインがあり、ヒートマップはどのポイントがコーナー ポイントである可能性が最も高いかを予測し、埋め込みは主に各ポイントが属するターゲットを予測します (オブジェクトの左上隅と右下隅を一致させる方法を解決します)。最終的なオフセットは次のとおりです。ポイントの位置に使用される値が修正されます。
検出コーナー部分では、CornerNet は左上隅と右下隅にそれぞれ対応する 2 つのヒート マップを生成します。ヒート マップは、グラフ内のコーナー ポイントのさまざまなカテゴリの位置を表現し、各コーナー ポイントに信頼度スコアを付けることができます。さらに、埋め込みベクトルとオフセットが生成されます。埋め込みベクトルは、上部の 2 つのコーナーを確認するために使用されます。左隅と右下隅 ポイントが同じオブジェクトに属しているかどうかに関係なく、オフセットによってコーナー ポイントの位置が微調整されます。ターゲット候補フレームを生成する段階では、ヒートマップからランキング上位 k 位の左上隅と右下隅を選択し、一対の隅の間の埋め込みベクトル間の距離を計算します。事前に設定されたしきい値を超えると、これら 2 つの点は同じオブジェクトに属するとみなされ、角の 2 点に基づいてバウンディング ボックスが生成され、同時に 2 つの角の点のスコアに基づいて平均スコアが次のように計算されます。バウンディングボックスのスコア。
3. 具体的な内容
1)入力
511 × 511 (4 倍ダウンサンプリング後の出力は 128*128)
2)バックボーン
砂時計ネットワーク (変更済み、事前トレインなし)
3)首と頭
ヒートマップ ブランチ (予測カテゴリ)、オフセット ブランチ (洗練されたコーナー オフセット)、エンベディング ブランチ (上下のコーナーのマッチング)、コーナー プーリングの 4 つの部分に分かれています。
a. ヒートマップとペナルティ削減戦略
各ヒートマップには C 個のチャネルがあります。ここで、C は BG カテゴリを除くカテゴリの数です。ヒートマップは gt 位置で最大の値を持ち、gt 位置に近づくほどヒートマップの値は大きくなります。実装ではガウス関数を構築します。中心は gt 位置であり、この中心から離れるほど減衰が大きくなります。つまり、次のようになります。

シグマは半径の 1/3 であり、半径の計算方法は、形成された bbox と GT の iou の最小値が 0.3 より大きくなるようにすることです。
b. オフセット分岐
著者が予測したフィートマップの入力サイズは元の画像の入力サイズと異なります。ダウンサンプリング係数を n とすると、元の位置 (x, y) からフィーチャ マップへの対応する位置は ([x/n ], [y/n ]), ここで [ ] は丸め操作を表します。元の画像位置に再マッピングするとき、間違いなく一定の誤差が発生します。オフセット ルートはこれに基づいて位置を修正します。収束ターゲットは次のように表されます。 :
c. ブランチの埋め込み
このブランチの主な機能はコーナーをグループ化することです。作成者は 1 次元の埋め込みを使用します...つまり、1、2、3 などの異なるターゲットに異なる ID を割り当てます。その後、予測するときに、埋め込み値が左上隅と右下隅の値は非常に近いです。たとえば、一方が 1.2 でもう一方が 1.3 の場合、これら 2 つは同じターゲットに属する可能性が高く、両者の間に大きなギャップがある場合は、 1.2 と 2.3、つまり一般に、これらは 2 つの異なる目標です。このような予測を達成するには、次の 2 つのことを行う必要があります。
同じターゲットの 2 つの角によって予測される埋め込み値は、可能な限り近くなければなりません
-
さまざまなターゲットによって予測される埋め込み値は、可能な限り遠く離れている必要があります
d. コーナープーリング
一般的に使用される最大プーリングは通常、現在の位置を中心とし、そのサイズは 3x3 カーネルであり、受容野は自然に現在の位置を中心とします。しかし、コーナーの検出は、このような正方形の受容野よりも、単一方向の情報が重要です...左上を例にとると、水平方向の右と垂直下方向の 2 方向の情報が重要になります。このため、著者はコーナープーリングを提案します。その原理は次のとおりです。

たとえば、特徴マップのサイズが 10x10 で、点が (2,1) である場合、左上隅のプーリングは (2,1) から (2,10) までの線上の最大値を計算します。と (2,1) をライン (10,1) 上の最大値に重ね合わせます。実際の計算では逆算で実現できますが、模式図は以下のようになります。

上図の例として、2,1,3,0,2 の場合、最後の 2 は変更されず、最後から 2 番目は max(0,2)=2 となるため、2,2 が得られます。次に、最後から 2 番目は max(3,2)=3...というようになります。
個人的には 1 次元の最大プーリングによるものだと感じています。式は次のとおりです。

さらに、著者は resnet の残差構造をベースとして Backbone の予測構造と最終予測を変更しました. 具体的な方法は、最初の 3x3 畳み込み演算を変更することです. 最終的な予測構造は次のとおりです:

4)損失関数
ヒートマップ ブランチ (予測カテゴリ)、エンベディング ブランチ (上下のコーナー ポイントのマッチング)、オフセット ブランチ (洗練されたコーナー ポイントのオフセット) の 3 つの部分に分かれています。
a.ヒートマップ

ここで、p は予測値、y は実際の値であり、この関数は焦点損失に基づいて修正されます。
b. オフセット分岐

c. ブランチの埋め込み

このうち、etk と ebk は左上と右下の 2 つの分岐によって予測されたエンベディング、ek は 2 つの平均値、Lpull の役割は同じターゲットの予測値に近づけることです。 Lpush の役割 さまざまなターゲットのエンベディング値をさらにプッシュすることです。
全体の損失額は以下の通りです。
ここで、ハイパーパラメータ: アルファとベータは 0.1、ガンマは 1 です。
5)トリック
4. 結果
テスト中、ヒートマップの非最大値を抑制するために 3x3 の最大プーリングが使用され、ヒートマップ上の最初の 100 件の結果が取得され、L1 距離に従って照合されます。照合は各カテゴリ間で行われることに注意してください。 , 異なるカテゴリや L1 距離は通常考慮されません。著者の最終的な実験結果は次のとおりです。

一段法では非常に好成績ですが、二段法も多い戦いです。
B. CenterNet (オープンソース)
この centerNet は CornerNet の改良版であることに注意してください。元の論文は CenterNet: Keypoint Triplets for Object Detection と呼ばれています。
1. 主な貢献
中心点とコーナー点の情報を充実させるために 2 つの方法が提案されています。
センタープーリング: ブランチ内の中心キーポイントを予測します。中央プーリングは、オブジェクト内で中央のキー ポイントをより識別しやすくして、候補ボックスをフィルタリングするのに役立ちます。
Cascade Corner プーリング: CornerNet Corner プーリングに基づいて、Corner は内部情報を認識する機能を備えています。
2. 主なアイデア

1) 画像の特徴を抽出するバックボーンとして Hourglass を使用します。
2) Cascade Corner Pooling モジュールを使用して画像のコーナー ヒートマップを抽出し、CornerNet と同じメソッドを使用して左上隅と右下隅に従ってオブジェクトの境界ボックスを取得します。すべての境界ボックスは中央エリアを定義します (詳細は後述 - 首と頭の紹介)

3) センター プーリング モジュールを使用して画像の中心ヒートマップを抽出し、中心マップに従ってすべてのオブジェクトの中心点を取得します。
具体的には: 中央ヒートマップでは、ヒートマップの応答値に従って、上位 k 個の中央キーポイントを選択し、対応するオフセット マップを使用してこれらのキーポイントを微調整し、より正確なキーポイントの位置を取得します。
4) オブジェクトの中心点を使用して、2) で抽出した境界ボックスをさらにフィルタリングします: ボックスの中央領域に中心点がない場合、ボックスは信頼できないとみなされます。中心点がこの中心にある場合は、ボックスは信頼できないと見なされます。境界ボックスは保持され、その bbox のスコアは 3 点の平均になります。
3. 具体的な内容
1)入力
544*511 (4 倍ダウンサンプリング後の特徴マップは 128*128)
2)バックボーン
砂時計
3)首と頭
ここでは、センター プーリング、カスケード コーナー プーリング、センター エリア設定の概念に注意する必要があります。
a.センタープーリング
オブジェクトの絶対的な幾何学的中心によって伝えられる情報は、必ずしも最も正確であるとは限りません。たとえば、人間の認識では、顔は重要な情報源ですが、ターゲット全体としての人間の中心点は顔上にありません。 。この問題を解決するために、より豊富な視覚情報を取得するためのセンター プーリングが提案されています。
以下の図はCenter poolingのプロセスを示したもので、具体的な方法はネットワークバックボーン経由で特徴マップを取得し、それが中心点であるかどうかをピクセル単位で確認し、その最大値を求めるというものです。このような操作を通じて、中心プーリングは中心点をより適切に見つけるのに役立ちます。
備考: そのブランチは、埋め込みブランチが切り取られていること、ヒートマップがカテゴリの数であること、オフセット フィーチャ マップが 2 つのレイヤーであることを除いて、CornerNet のブランチに似ています。

実現方法:
コーナープーリングと組み合わせることで、以下の図aに示すように、たとえば水平方向の最大値を選択したい場合、左プーリングと右プーリングを接続するだけで簡単に実装できます。

b.カスケードコーナープーリング
コーナーはコーナー ポイントでもあり、通常は実際のオブジェクトとは関係ありません。コーナー プーリングは、コーナーの位置を決定するために垂直方向と水平方向の最大値を見つけることを目的としています。ただし、境界には非常に敏感であり、 「見る」コーナー 「オブジェクト」内部の情報はカスケードコーナープーリングです。最初に境界に沿って最大値を見つけ、次に最大値の方向に「覗いて」内部最大値を見つけます。上の図 b に示すように。
c. 中央エリア
中央領域のサイズ設定は重要です。たとえば、小さな境界ボックスの場合、中心領域が小さくなるほど、多くの正の例が負の例として判断されるため、再現率 (再現率) は低くなります。大きな境界ボックスの場合、中心領域が大きくなり、多くの負の例が正の例として判断されるため、精度は低くなります。そこで、この論文では、バウンディング ボックスのサイズに適応し、大きなバウンディング ボックス内に比較的小さな中心領域を生成するスケールを意識した中心領域を提案します。これにより、適合率 (精度) を効果的に向上させることができます。同様に、小さな境界ボックス内に比較的大きな中央領域を生成すると、再現率 (再現率) を効果的に向上させることができます。

このうち、tlx、tlyは左上コーナーの座標、brx、bryは右下コーナーの座標、ctlx、ctlyは中央エリアの左上コーナーの座標、cbrx、cbryはコーナーの座標です。中央エリアの右下隅。n は奇数で中心領域のサイズを決定しますが、中心領域の決定方法は非常に簡単で、bbox を 9 分割 (n=3) または 25 分割 (n=5) するだけです。著者は、bbox のサイズが 150 より大きい場合は n が 5 になり、150 未満の場合は n が 3 になると述べています。最終的なグラフィック効果は次のとおりです。塗りつぶされた四角形は境界ボックスを表し、影付きの部分は中央領域を表します。

4)損失関数
このうち、最初の 2 つは、焦点損失を使用して、それぞれコーナー点と中心点によって引き起こされる損失を検出するものであり、対応する後部は、CornerNer に似ており、プルとプッシュを使用してコーナー点を正確に分類します。 L1 損失を使用してコーナーとセンターの位置を微調整します。損失の具体的な意味は原文では言及されていません。主にコーナーネットの改善です。コーナーネットを参照してください。
ハイパーパラメータ設定: α、β、γ=0.1、0.1、1。
5)トリック
4. 結果
効果は非常に優れており、アンカーフリー方式やワンステージ方式の中で最も優れています。

C. ExtremeNet (オープンソース)
1. 主な貢献
角点の代わりに極点を検出し、幾何学的関係の組み合わせを通じて直接検出結果を取得することが提案されています。
次の問題を解決します。
1) ボトムアップ検出方式では、CornerNet と比較して、検出されるコーナーがターゲットの外側に位置することが多く、検出が困難になります。
2) ラベル付けの難しさ: 極値ポイントの手動ラベル付けは、監視フレームのラベル付けより簡単で時間もかかりません。
2. 主なアイデア
CornerNetに基づく改善手法は、物体の4つの極値点(極点)と1つの中心点を予測し、それらを幾何学的分布に従って組み合わせ、極値点から予測フレームを構築し、予測結果を取得します。

3. 具体的な内容
1)入力
511*511
2)バックボーン
砂時計-104
(実際、ネットワークの計算は非常に大きく、同じ条件下で 256x256 の入力で約 140T、ResNet50 は約 8T となり、全体の速度も非常に遅くなります。)
3)首と頭
予測ヘッドが 4 つの極と中心点に対応する 5 つの H*W ヒート マップを出力した後、各ヒート マップのチャネル数はオブジェクト カテゴリの数に対応する C になります。
さらに、予測は 4 つの極に対応する 2 つのチャネルで 4 つのオフセット出力を生成します。これらは、極座標でのサンプリング精度の損失を微調整するために使用されます。これはクラスに依存せず、中心点を微調整する必要はありません。
中心グループ化プロセスを使用して、4 つの極と中心点をグループ化します。


4)損失関数
ExtremeNet の損失計算も、CornerNet のいくつかのプラクティスに従い、CornerNet の埋め込みプロセスを使用せずに、焦点損失変形の分類損失とダウンサンプリングによって引き起こされる位置精度の損失を計算します。


5)
裏技
a. トレーニングサンプルの生成
COCO データセットはトレーニングに使用されます。直接の極ラベルがないため、セグメント化されたマスク ラベルが使用され、極が計算され、その極がトレーニングに使用されます。
(ExtremeNet のトレーニング データ セットは、通常のターゲット検出データ セットと一致していません。または、トレーニング データに含まれる情報が多く、つまり、極の方が角よりも多くの意味情報を持っています。実用的な観点から、手動ラベル付けの効率は高くなります)ポールの高さはコーナーの高さよりも高く、それでも使用上の利点があります。)
b.
ゴーストボックスの抑制
極の組み合わせは網羅的なプロセスであり、極と中心点の間の座標関係にのみ基づいて決定されるため、偽陽性の結果が生じます。たとえば、同じカテゴリの小物が 3 つ並んでいる場合、座標計算後、左側のオブジェクトの左極と右側のオブジェクトの右極が中央のオブジェクトの中心点として計算され、より高い応答性 3 つの小さなオブジェクトを備えた長いオブジェクト。

抑制方法は、
ターゲットボックスに含まれるすべてのターゲットボックスのスコアの合計が、
ターゲットボックス自体のスコアの
3倍を超える 場合、ターゲットボックス自体のスコアを2で割ります。
-
ここでの 3 回は下限であり、それより多くのオブジェクト (5 つなど) が含まれている場合も抑制されます。
-
2 で除算すると、大きな予測フレームのスコアが減少し、後続の NMS プロセスで大きなターゲット フレームを除外できます。
c.
エッジ集約 (現時点では理解されていません)
極を予測する際のもう 1 つの問題は、オブジェクトに座標軸に平行な辺がある場合、設計によれば、その辺全体の点が極応答を持つはずであることです。問題は、各点の応答が比較的低い可能性があることです。 、または特定の角度を回転した後の唯一の極よりも低いエッジ集約は、平行エッジの応答を強化して予測効果を向上させることを目的としています。

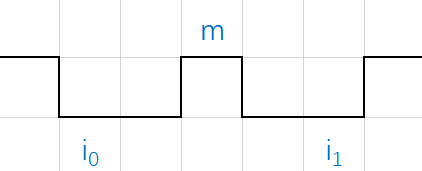

4. 結果
アブレーション実験の結果:

-
このうち、1行目は標準のExtremeNet、2行目のマルチスケールは入力画像のマルチスケール拡張です。
-
2 番目の部分では、Center グループ化が削除されると、結合プロセスが CornerNet と同様の Embedding に置き換えられ、パフォーマンスが 2.1% mAP 低下します。
-
エッジの集約とゴーストの除去は、大きなオブジェクトの場合により顕著ですが、小さなオブジェクトにはほとんど影響しません。
-
3 番目の部分はエラー分析で、予測結果をグランド トゥルースに置き換えます。中心を置き換えた後の改善は特に大きくなく、中心特徴の抽出に問題がないことを示しています。極値の置き換えと中心点の置き換えを同時に行った結果、大幅な改善がもたらされました。これは、極値の抽出と極値の中心点の結合のプロセスにまだ多くの改善の余地があることを示しています。
他のターゲット検出フレームワークとの比較:

参考リンク:
6. 13種類のアンカーフリーまとめ:
https://bbs.cvmart.net/articles/442/zhong-bang-13-pian-ji-yu-anchor-free-de-mu-biao-jian-ce-ファンファ
9、yolov1:
https://zhuanlan.zhihu.com/p/70387154
10. yolov1 損失関数;
https://blog.csdn.net/qq_38236744/article/details/106724596
16、feveabox:
https://zhuanlan.zhihu.com/p/63190983
17、feveabox:
https://zhuanlan.zhihu.com/p/68075721
18. Centernet (点としてのオブジェクト) の詳細:
https://blog.csdn.net/WZZ18191171661/article/details/113753991
19. センターネット (点としてのオブジェクト) の詳細:
https://mp.weixin.qq.com/s/hlc1IKhKLh7Zmr5k_NAykw
20. Centernet (点としてのオブジェクト) の詳細:
https://zhuanlan.zhihu.com/p/66048276
21. Centernet (点としてのオブジェクト) によるガウス カーネル半径の説明:
https://zhuanlan.zhihu.com/p/96856635
22、コーナーネット:
https://zhuanlan.zhihu.com/p/44449116
23、 cornetNet:
https://arxiv.org/abs/1808.01244
24、コーナーネット:
https://zhuanlan.zhihu.com/p/53407590
26、センターネット:
https://zhuanlan.zhihu.com/p/66326413
27、センターネット:
https://zhuanlan.zhihu.com/p/60072845
28、エクストリームネット:
https://zhuanlan.zhihu.com/p/117597564
29、エクストリームネット:
https://zhuanlan.zhihu.com/p/57254154
1. アンカーフリーの概要
1. まずアンカーが何であるかを知る必要があります (これには、より高速な rcnn、YOLO V2 以降や SSD などの一次検出器などの第 2 段階を理解する必要があります)。
従来、ターゲット検出は通常、候補フレームの分類と回帰としてモデル化されていましたが、候補領域の生成方法の違いに応じて、2 段階 (2 段階) の検出と 1 段階 (1 段階) の検出に分けられました。前者の候補ボックスは、RPN (地域推奨ネットワーク) ネットワークを通じて提案を生成し、特定の特徴マップ上の各位置に異なるサイズとアスペクト比の事前ボックス (アンカー) を生成します。以下に示すように:
2. なぜアンカーを放棄してアンカーフリーにするのか
1) アンカーの設定(アスペクト比、スケールサイズ、アンカーの数)を手動で設計する必要があり、データセットごとに異なる設計が必要であり、非常に面倒です。
2) Anchor のマッチング機構により、極端なスケール (極端に大きいオブジェクトや極端に小さいオブジェクト) のマッチング頻度が中程度のサイズのオブジェクトに比べて低くなり、DNN が学習中にこれらの極端なサンプルをうまく学習することは容易ではありません。
3) 膨大な数のアンカーにより、サンプリングプロセスに関わる深刻な不均衡の問題が発生しますが、実際には、Focal loss と同様の戦略は安定しておらず、サンプリングに多くのピットが存在します。
4) アンカーの数が膨大であり、アンカーごとに IOU の計算が必要となるため、膨大な計算能力が消費され、効率が低下します。
3. アンカーの方向は自由です
最も初期のアンカーフリーモデルであるはずのYOLOアルゴリズムにまで遡ることができ、最近のアンカーフリー手法は主に密予測と キーポイント推定
に基づく
2種類に分けられます 。
4. アンカーフリーの限界
現時点では、見栄えの良い結果を得るために、論文では実験の一部の詳細を隠したり、不公平な比較を行ったりしています (バックボーン ネットワークで砂時計を使用して他の人の resnet を比較するなど)。
5. アンカーフリープロジェクトの推奨
YOLOV5 の導入により、私たちはアンカーフリーの考え方を主に理解しており、エンジニアリング アプリケーションでは主に次のことを試すことができます。
1) centerNet (オブジェクトとしてのポイントバージョン)
2) ExtremeNet (回帰境界ボックスを極値点に変更)
2. アンカーフリーの解釈
以下の構成で紹介します
×、×××
1. 主な貢献
2. 主要なアイデア
3. 具体的な内容
1)入力
2)バックボーン
3)首と頭
4)損失関数
5)トリック
4. 結果
A. 密集ボックス (Baidu IDL および Horizon、2015 年 9 月)
1. 主な貢献
1) FCN をターゲット検出に導入すると、優れた効率と精度を達成できます。エンドツーエンドのマルチタスクターゲット検出フレームワークです。
2) DenseBox のマルチタスク学習にターゲットランドマークの測位を導入すると、検出精度がさらに向上します。
3) 顔検出では、DenseBox は MALF と KITTI で優れた結果を達成しました。
2. 主要なアイデア
上に示すように:
1) 画像ピラミッドを使用し、CNN を入力し、特徴マップ上の bbox + 分類スコアを直接予測します (つまり、5 層の特徴マップ: 4 層は Bbox 回帰を表し、1 層はバイナリ分類顔スコアを表します)
2) DenseBox の NMS ステップを除いて、モデル全体は完全な畳み込み演算であり、完全に接続された層はなく、領域提案生成ステップは必要ありません。
3) 画像はダウンサンプリング + アップサンプリング (双一次補間) されます。これはセグメンテーション ネットワーク FCN と同様です。
3. 具体的な内容
1)入力
a. トレーニング段階
元の画像には背景が多すぎるため、トレーニングではあまり意味のない背景領域の計算と判断に時間がかかります。そのため、トリミングされた画像パッチを使用して DenseBox トレーニングに参加することは、トリミングされた画像パッチには顔が含まれており、十分な背景情報があれば十分です。
具体的な操作: DenseBox トレーニングは、画像セグメンテーション手法のようなものです。まず、元の画像から画像パッチを切り抜き、次にサイズを 240 x 240 に変更します。画像の中心には、高さ約 50 の顔 gt bbox が含まれていますpix; この操作は実装が簡単で、元のイメージ + gt イメージからパッチをトリミングするのと同じですが、このパッチは顔がパッチの中心にあることを確認する必要があり、gt bbox のサイズは 50 x になります。サイズ変更後は 50 になるため、トリミングのサイズを指定する特定のパッチのサブエリアを実行する必要があります。均等な比率で計算します。栗を例にします。元の画像の顔の gt bbox が 80 x 80 であることを確認する必要があります。サイズ変更後の顔のスケールが 50 x 50 の場合、元のイメージでトリミングする必要があるパッチのサブエリアは 240 x 80 / 50 = 384、つまり 384 x 384 のサブエリアになります。
b. テスト段階
画像ピラミッドを使用する
2)バックボーン
VGG19 のネットワーク パラメータの最初の 12 層を多重化した、合計 16 層の畳み込み演算。
3)首と頭
Conv 4-4 の後には 4 つの 1 x 1 conv レイヤーが続きます。図 3 からわかるように、実際には 2 つのブランチに分割されています: 2 つの 1 x 1 conv レイヤーは最後に顔分類スコア計算用の 1 チャネルの特徴マップを出力します。他の 2 つの 1 x 1 conv レイヤーは、顔 bbox 回帰の計算に使用される 4 チャネルの特徴マップを出力します。conv 3-4 と conv 4-4 の特徴マップの特徴が融合され、連結が行われます。下位層の特徴マップ上の特徴にはターゲットのより局所的な詳細が含まれているため、ターゲットの局所領域を判断しやすくなりますが、高レベルの特徴マップ上の特徴はより大きな受容野を持っているため、 、より多くの音声情報とコンテキスト情報が含まれており、ターゲットの全体的な情報を認識するのが簡単です; conv 3-4 の受容野は 48 x 48 であり、顔の gt bbox スケールとほぼ同じです。 conv 4-4 は 118 x 118 なので、より多くのグローバル情報 + コンテキスト情報を統合できます。また、conv 4-4 の特徴マップのスケールは conv3-4 のスケールの半分です (プール 3 の操作が多くなります)。連結する場合は、conv 4-4 の双線形アップサンプリングを実行して、両方のスケールが同じであることを確認する必要があります。要素ごとの加算ではなく連結のみであるため、チャネル数が同じであることを確認する必要はありません。
4)損失
a. 分類損失、特徴マップ上のピクセル単位の L2 損失。
著者は、DenseBox の L2 損失パフォーマンスは非常に優れており、ヒンジ損失、クロスエントロピー損失などは試していないと述べました。
b. bbox 回帰損失は、特徴マップ上のピクセル単位の L2 損失でもあります。
4)トリック
a. 陽性サンプルと陰性サンプルを定義する
各ミニバッチ反復では、正のサンプルと負のサンプルの数は大きく異なり、負のサンプルが大部分を占めます。これらの負のサンプルがトレーニングに使用される場合、最終的な損失は多数の負のサンプルに偏ることになります。同時に、
分類境界上の曖昧な陽性サンプルと陰性サンプルがトレーニングされた場合
、モデルは貴重な情報を学習できず、パフォーマンスも低下します。
最終的な機能マップでは次のようになります。
肯定的なサンプル: ラベル ボックスの中心点 (個人的な理解と中心点は円の中心であり、ラベル ボックスの高さは一定の比率を持っています。たとえば、半径 0.3 の円内の点)。
陰性サンプル: 上記の陽性サンプルの外側の点。
無視サンプル: ネガティブ サンプルのピクセル (x, y)。その近くの 2 ピクセル距離以内にポジティブ サンプル ピクセルがある場合、そのピクセルは無視されたサンプルとみなされます。
b. 困難なサンプル採掘
ミニバッチでは、最初にすべてのサンプルが順方向演算を実行され、すべてのピクセル出力が式 (1) の損失に従って降順にソートされ、上位 1% が困難なネガティブ サンプルとして選択され、すべてのポジティブ サンプル (ポジティブ ラベルが付けられます)ピクセル) が保持され、ポジティブ サンプルとネガティブ サンプルの比率を 1:1 に制御します。すべてのネガティブ サンプルの半分は、ハード ネガティブ サンプル (つまり、残りの上位 99% のネガティブ サンプル) からのランダム サンプリングから取得され、残りの半分はサンプリングから取得されます。上位 1% からハードネガティブ; ミニバッチでは、サンプルが選択されているかどうかを識別するために Fsel = 1 に設定します (ポジティブ サンプル + 困難なネガティブ サンプル + ランダムに選択されたネガティブ サンプル)
ポジティブ サンプル: 入力 240 x 240 ピクセルのパッチ、パッチの中心位置には特定のスケール範囲 (約 50 x 50 ピクセル) 内のポジティブ サンプルが含まれており、各パッチにはポジティブ サンプルの近くにいくつかのネガティブ サンプルが含まれる場合があります。ネガティブ サンプル: ランダム パッチ : 画像からランダムなスケールでパッチをランダムにトリミングし (トレーニング画像からランダムなスケールでパッチをランダムにトリミング)、その後 240 x 240 ピクセルのパッチ入力ネットワークにサイズ変更します。トレーニング中に、ランダム パッチのネガティブ サンプルに対するポジティブ サンプルの比率が決まります。 1:1です。
c. データの拡張
ポジティブパッチとネガティブパッチの左右をランダムに反転、25 ピクセルの変換、スケール変換 [0.5、1.25]。
B.ヨロ V1
1. 主な貢献
1 段階の高速なエンドツーエンドのトレーニング
2. 主要なアイデア
完全な畳み込みネットワークを通じて、入力画像は 7*7*30 テンソルにマッピングされます。7*7 は、画像全体が 7*7 グリッドに分割されていることを意味し、各グリッドは 2 つの事前選択ボックスで設定されます (トレーニングは可能です)。進化の考え方については、以下の左図に示すように、30 は右図に示すように各位置のエンコーディングです。
20 のオブジェクト分類の確率: YOLO は 20 の異なるオブジェクト (人、鳥、猫、車、椅子など) の認識をサポートします。
2 つの境界ボックスの位置: 各境界ボックスには、その位置を表す 4 つの値 (Center_x、Center_y、幅、高さ) が必要です。
2 つの境界ボックスの信頼度: 境界ボックス内のオブジェクトの確率 * 境界ボックスとオブジェクトの実際の境界ボックスの間の IOU。グリッドにオブジェクトが含まれていない場合、信頼度のラベルは 0 です。オブジェクトが含まれている場合、信頼度のラベルは、予測フレームと実際のオブジェクト フレームの IOU 値になります。
3. 具体的な内容
1)インアウト
入力は元の画像であり、唯一の要件はそれを 448*448 に拡大縮小することです。主な理由は、YOLO のネットワークでは、畳み込み層が最後に 2 つの全結合層に接続されており、全結合層は入力として固定サイズのベクトルを必要とするためです。
2)バックボーン
ダークネット
3)
首と頭
上の 2 つの図に示すように、合計 49*2=98 の候補領域があり、2 つの境界ボックスのサイズと形状は事前設定されておらず、各境界ボックスのオブジェクト出力の予測はありません。これは、オブジェクトの 2 つの境界ボックスを予測し、比較的正確な方を選択することのみを意味します。正確には教師ありアルゴリズムではありませんが、進化的アルゴリズムのようなものです。1 枚の写真で最大 49 個のオブジェクトを検出できます。オブジェクトの境界ボックスの中心位置を計算し、その中心位置がどのグリッドに該当するかを計算し、そのグリッドに対応する出力ベクトル内のオブジェクトのカテゴリ確率が 1 であり、これがオブジェクトの予測に関与します。オブジェクトの他のグリッドは 0 に設定されます (オブジェクトの予測には関与しません)。
4)
損失関数
5)裏技
a. 中心点の座標値を直接返すのではなく、格子点の左上隅の座標を基準とした相対的な変位値を返します。
b. 各格子点は 2 つ以上の長方形のボックスを予測します. 損失関数の計算では, 実物体に最も近いボックスの損失のみが計算され, 残りのボックスは補正されません. 著者は 2 つのボックスを予測しました.格子点のサイズやアスペクト比、またはいくつかのカテゴリが段階的に分割され、全体の再現率が向上します。
c. 推論中、オブジェクトのカテゴリ予測の最大値 p に予測ボックスの最大値 c を乗算した値を、出力予測オブジェクトの信頼度として使用します。
C、FCOS (完全畳み込み 1 段階物体検出はオープンソースになっています)
1. 主な貢献
1) 重複点の解決方法: FPN 階層化 + 同じレイヤーが重複する属性領域を持つ最小のボックスを使用します
2) ピクセル単位の低品質フレームを解決する方法: 中心性戦略を提案 (本質は YOLOV1 の予測対象と同じであると個人的に考えています)
2. 主要なアイデア
FPNを使用して特徴マップ上のすべての点を実行します:分類の予測+位置回帰+中心かどうか(個人的には本質はYOLOV1の予測対象と実際には同じであると考えています)
3. 具体的な内容
1)入力
特別な要件はありません
2)バックボーン
特別なことは何もありません。実験では resnext-32x8d-101-fpn などを試しました。
3)首と頭
a. 上の図 2 に示すように、FPN ネイティブ実装とは若干異なることに注意してください。
FCOS は、バックボーンによって出力された C3、C4、および C5 特徴マップを使用し、P3、P4、および P5 を水平合成します。P6 と P7 は、ステップ サイズ 2 の畳み込み層を介して P5 と P6 によって取得されます。最終的な特徴マップはすべて合計 5 であり、ダウンサンプリング倍数はそれぞれ 8、16、32、64、および 128 です。
b.label は分類 + 回帰で構成されます。
位置 (x, y) が与えられた場合、その点が GT 境界ボックス内にある場合、その位置は正の例として識別され、カテゴリ ラベル c* がそれに付けられます。それ以外の場合、c*=0 は背景を意味します。さらに、この位置 (x, y) に対して、回帰の対象として 4 次元ベクトル t = (l*, t*, r*, b* ) を与えます。(l*、t*、r*、b* は、点から境界ボックスの左 (左)、上 (上)、右 (右)、下 (下) までの距離をそれぞれ表します)。下の図。
回帰ターゲットはほぼすべて正のサンプルであるため、exp() 関数を使用して回帰ターゲットを (0, ∞) にマップします。これには、境界ボックスの認識が向上するという利点があります。
与えられた画像に対して、各位置のカテゴリ スコア Px, y と位置回帰予測 t (x, y) が FCOS によって取得され、px, y > 0.05 の位置が正の例として選択されます。
アンカー ベースの方法では、アンカー ボックスを選択するときに、GT との IOU 比が考慮され、しきい値を超えたものは正のサンプルとなります。違いは、FCOS がトレーニング回帰にできるだけ多くの前景サンプルを使用できることです。
c. 重複領域処理
最初のケース (特徴マップの同じレイヤー内): 小さな領域を持つ境界ボックスを回帰ターゲットとして選択します。これにより、不鮮明なサンプルを大幅に減らすことができます。
2 番目のケース (FPN による異なるレイヤーのフィーチャ マップ): 異なるレイヤーのフィーチャ マップを使用して、異なるサイズのオブジェクトを検出します。
具体的な方法:
位置が max(l∗, t∗, r∗, b∗) > mi または max(l∗, t∗, r∗, b∗) < mi-1 を満たす場合、その位置は負のサンプルとして設定されるため、もう境界ボックスを回帰する必要はありません。ここで mi は、特徴レベル i が後退するために必要な最大距離です。この作品ではm2、m3、m4、m5、m6、m7を0、64、128、256、512、∞に設定しています。
d.中心性
FPN を使用した後も、ネットワークの効果と最先端のターゲット検出アルゴリズムの間にはまだギャップがあり、分析の結果、低品質の検出フレームが原因であることが判明しまし
た
。
畳み込みニューラル ネットワークでは、特徴マップ上の点が受容野の中心に対応するため、現在の人物を予測するには、図 5 のオレンジ色の点が 2 つの緑の点よりも優れているはずです。次に、2 つの緑色の点は低品質予測点と呼ばれます。中心性とはグリーンポイントの重みを抑えることです。まず中心性の計算式を見てください。
式によれば、点がグラウンド トゥルースの中心に近いほど、中心性の値は高くなります。しかし、ここで新たな問題が発生します. 中心性を取得するには 2 つの方法があります. 1: 予測値 l*, r*, t*, b* に従って直接中心性を計算する; 2: 中心を返すラベル値 l、r、t、b に従って、ness 値を個別に指定してブランチをトレーニングします。図 4 のネットワーク構造から、著者が方法 2 を採用したことがわかります。実際、著者は 2 つの方法を比較しました。
結果が最終決定権を持ちます。つまり、単一の中心性回帰ブランチが mAP を改善します。
4)損失関数
UnitBox の論文では、カテゴリ損失関数は焦点損失を使用し、回帰損失関数は IOU 損失を使用します。
コードを確認すると、実際には BCEloss を使用する中心性損失関数ブランチがありますが、ラベルはワンホット エンコーディングのバイナリ分類ラベルではなく、上記の中心性に対して計算されます。
5)トリック
なし
4. 結果
論文内の比較実験結果:
図 8 FCOS 精度比較
少なくとも、FCOS の精度は古い古典的なアルゴリズム Faster R-CNN を超えていることがわかります。
FCOSのパフォーマンス
速度の具体的な値については論文では詳しく言及されていませんが、上記の数値は論文の公式 Web サイトのコードから引用したものであり、マシンによっては値が若干異なる可能性があります。推論速度は2段階のFaster R-CNNほど速くはありませんが、基本的にリアルタイム性能を満たしています。mAP は Faster R-CNN を大幅に上回っています。
D、 FSAF(シングルショット物体検出用の特徴選択的アンカーフリーモジュール)
1. 主な貢献
FPN を使用する現在のターゲット検出とグラウンド トゥルースおよびアンカーのアイデアのマッチングでは、主に自動マッチング方法を提供する iou または階層メカニズムに依存しています。
2. 主要なアイデア
FPN の各レイヤーを使用してインスタンスを検出してみて、どのレイヤーの検出結果がこのインスタンスの損失が最小であるか、このレイヤーがこのインスタンスの検出に最適であるかを確認します。
3. 具体的な内容
1)入力
解決策は必要ありません
2)バックボーン
著者はresnext-101を実験してみた
3)
首と頭
a. 支店構造
FSAF モジュールを使用すると、各インスタンスが FPN 内の最適なフィーチャ レイヤーを自動的に選択できます。このモジュールでは、フィーチャ選択の基準が元のインスタンスのサイズからインスタンスのコンテンツに変更され、自動モデル学習が実現され、FPN で最適なフィーチャ レイヤーを選択できます。 FPN。
FSAF は RetinaNet を基本構造として使用し、元の分類サブネットおよび回帰サブネットと並行して FSAF ブランチを追加するため、元の構造を変更することなく完全なエンドツーエンドのトレーニングを実現できます。FSAF には、図に示すように、分類 (シグモイド関数を使用) とボックス回帰の 2 つのブランチも含まれており、これらはターゲットのカテゴリと座標値を予測するために使用されます。
b. バベル定義
最初: ターゲット (インスタンス)、そのカテゴリが
lable = c であり、
境界ボックスの座標が であると 仮定し
ます。(x, y) はターゲットの中心座標です。
(w, h) はオブジェクトの幅と高さです。
2 番目: FPN におけるこのターゲットの
フィーチャ レイヤー投影の座標は です
。ここで、 は です
。
3 番目: 定義投影の有効なターゲット フレーム座標は です
。つまり、図 3 の「car」クラスの白い領域です。ここで、
式の は です
。
4 番目: 定義投影の無視されたターゲット フレームの座標は です
。つまり、図 3 の「car」クラスの灰色の領域です。ここで
、式の は です
。
クラス出力: クラス出力はアンカーベースのブランチを備えた並列構造です。その次元は W×H×K、K はカテゴリの総数 (背景カテゴリを含む必要があります)、クラス出力には合計 K 個の特徴マップがあります。このターゲットのカテゴリを c (図では自動車カテゴリ) とすると、クラス出力のラベル次元は W×H×K のテンソルとなり、K 特徴量のうち c 番目の特徴マップの定義となります。マップは図 3 の「car」クラスにあります。白い領域は
定義値 1 の正のターゲット領域、灰色の領域は無視される領域、つまり
勾配逆伝播は実行されません。黒の領域は定義
値 0 の負のターゲット領域です。使用される関数は Focal Loss です。
ボックス出力: ボックス出力はアンカーベースのブランスを備えた平行構造で、その寸法は W×H×4 で、4 はオフセットを表します。オフセットの意味を説明するための例を示します。ボックス出力のラベルは 有効領域
内のピクセル のもので
、4 つの次元の値は です 。
ここで、 は上、左を基準とした ピクセル位置です。 図 4 に示すように、それぞれ、下、および右です。さらに、S =4.0 です。使用される損失関数は IoU Loss です。
ピクセル点で
、予測されたオフセットが
、 まで の距離が
、 予測された 左上隅と右下隅の座標がそれぞれと の 場合、予測されたバウンディング ボックスの座標はそれぞれ と と と で乗算さ れ ます 。
3)損失関数
a. アンカーベースのアルゴリズムでは、通常、ターゲットのサイズは指定されたフィーチャ レイヤーに割り当てられますが、FSAF モジュールはターゲットの内容に基づいて最適なフィーチャ レイヤーを選択します。番目のフィーチャ レイヤーに割り当てられた分類損失と位置推定損失は次のとおりです。
ここで、 は有効領域の画素数です。
次に、最適な予測ターゲットを持つフィーチャ レイヤーが次の式によって取得されます。つまり、結合損失関数が最小になります。
b. アンカーなしのブレースとアンカーベースのブレースを組み合わせるにはどうすればよいですか?
推論では、FSAF は予測結果を分岐単独で出力することも、元のアンカーベースの分岐と同時に予測結果を出力することもできます。両方が存在する場合、2 つのブランチの出力結果が結合され、NMS を使用して最終的な予測結果が得られます。トレーニングではマルチタスクロスが使用されます。つまり、式は次のとおりです。
重み係数は 0.5 です。
5)トリック
なし
4. 結果
E、フィーベアボックス
1. 主な貢献
多くの考え方は fcos と FSAF に似ているため、違いは、回帰ではターゲットの中心から 4 つの側面までの距離を直接学習するのではなく、予測された座標と実際の座標の間のマッピング関係を学習することです。
2. 主要なアイデア
オブジェクトの存在確率とグラウンド トゥルース ボックスの座標を直接学習します (事前選択ボックスは生成されません)。主に次の 2 つの支店を通じて行われます。
クラス依存のセマンティック グラフがオブジェクトとして存在する確率を予測する
中心点とフレーム座標の間のマッピング関係を予測する
3. 具体的な内容
1) 入力
画像の解像度に特別な要件はありません。
2)バックボーン
主にretina netと比較し、バックボーンはResNet101とResNext101を試してみました。
3)首と頭
a. RetinaNet との公平な比較を行うために、著者は、ピラミッドの層数と入力画像の解像度がまったく同じネットワーク構造、つまり ResNet+FPN の構造を使用しまし
た
。
b. Bbox に一致
FPN の各層が特定の範囲内のバウンディング ボックスを予測すると仮定し、各特徴ピラミッドには基本領域、つまり 32*32 ~ 512*512 があるため、次のように表され、 と設定され
ます
。l=3 のとき、全体の面積は 1024=32*32 になります。ただし、各レイヤーを特定のオブジェクト スケールに応答させるために、FoveaBox は 次のように 各ピラミッド レイヤー
L の有効範囲を計算します。これは、このスケール範囲を制御するために使用されます (私の理解では、エリア マッチングに依存しています)。
実験の結果、著者は制御係数が 2 のときが最適な状況であることを発見しました。
c. ポジティブ領域とネガティブ領域の決定
まず、予測分類のサブネットワークを見てみましょう。その出力は一連のピラミッド型ヒートマップであり、各ヒートマップのサイズは HxW、次元は K (K はカテゴリの数) です。指定されたグラウンド トゥルース ボックスが (x1,y1,x2,y2) である場合、まずそれをターゲット ピラミッドにマッピングします。つまり、次のようになります。
陽性サンプル領域(中心窩)は、DenseBox の設定と同じ、元の領域の減衰領域として設計されています。この設定の理由は、意味領域の重なりを防ぐためです。その中には
スケーリング係数が含まれており、陽性サンプル領域の各セルには対応するカテゴリ ラベルが割り当てられます。負のサンプルの場合、負のサンプル領域を生成するための倍率も設定します
。セルが割り当てられていない場合、無視領域はバックプロパゲーションに参加しません。この設定は FSAF に非常に似ています。サンプル間の不均衡のため、焦点損失を使用して最適化します。中心窩面積の計算式は次のとおりです。
下図に示すように、ズーム率を設定することにより、プラス領域とマイナス領域、無視される領域に分割されます。特徴マップ全体に比べて正のサンプル領域の割合が比較的小さく、トレーニング中に正のサンプルと負のサンプルのバランスが崩れるため、分類損失は焦点損失であることがわかります。
4)損失関数
分類 + 回帰損失の使用 (境界予測)
a. 分類損失
分類には焦点損失が使用されており、具体的な実装ペーパーでは言及されていませんが、推測では、各クラス (分類ブランチの各特徴マップ、正と負に注目し、領域を無視) が 2 つのカテゴリに分けられ、その場合は sigmod が使用されます。
b. 回帰分岐
次に、単純な L1 損失が最適化に使用されます。ここで、 は
出力空間を 1 を中心とする空間にマッピングする正規化係数であり、トレーニングを安定させます。最後に、ログスペース関数を正規化に使用します。
5)トリック
なし
4. 結果
上の図から、アンカーベースと比較して、アンカーフリー アルゴリズムはターゲットの規模に対してより堅牢であり、アンカーのサイズを苦労して設計する必要がないことがわかります。
次に AP と AR の比較です。
1) FoveaBoxとRetinaNetの比較
2) ASFA(CVPR2019)との比較
3) 他のSOTA手法との比較(coco test-dev)
F、CenterNet (ポイントとしてのオブジェクトはオープンソースです)
1. 主な貢献
1) このアルゴリズムにより、非効率的で複雑なアンカー操作が削除され、検出アルゴリズムのパフォーマンスがさらに向上します。
2) このアルゴリズムは、ヒートマップ上でフィルタリング操作を直接実行するため、時間のかかる NMS 後処理操作が不要になり、アルゴリズム全体の実行速度がさらに向上します。
3) このアルゴリズムは 2D ターゲット検出だけでなく、簡単な変更で 3D ターゲット検出や人物キーポイント検出などの他のタスクにも適用でき、汎用性が優れています。
2. 主要なアイデア
CenterNet は、ターゲット検出問題を中心点予測問題に変換します。つまり、ターゲットはターゲットの中心点によって表され、ターゲットの長方形フレームは、ターゲット中心点のオフセットと幅を予測することによって取得されます。
このモジュールには、中心点ヒートマップ ブランチ、中心点オフセット ブランチ、およびターゲット サイズ ブランチを含む 3 つのブランチが含まれています。
1) ヒートマップ ブランチには C チャネルが含まれており、各チャネルにはカテゴリが含まれており、ヒートマップ内の白く明るい領域はターゲットの中心点の位置を示します。
2) 中心点オフセット ブランチは、プールされた低ヒートマップ上の点を元の画像にマッピングすることによって生じるピクセル エラーを補うために使用されます。
3) ターゲット サイズ ブランチは、ターゲット長方形の w と h の偏差値を予測するために使用されます。
CenterNet ネットワークの推論フェーズの実装手順は次のとおりです。
ステップ 1 - 画像を入力し、画像サイズを 512*512 に処理して、ネットワークの入力として使用します。
ステップ 2 - ネットワークの順計算を実行すると、サイズ [1,80,128,128] のヒートマップ、サイズ [1,2,128,128] のサイズ予測、サイズ [1,2,128,128] のオフセット予測、という 3 つの出力が生成されます。
ステップ 3 - ヒートマップはシグモイド関数を使用して範囲を 0 から 1 にし、ヒートマップ上で最大プーリング操作を実行します (カーネルは 3 に設定され、ストライドは 1 に設定され、パッドは 1 に設定されます、このステップでは)は実際にはリピートボックスを実行しています フィルタリングは、将来的に NMS 操作が必要なくなる重要な理由でもあります 結局のところ、3✖️3 サイズのカーネルと特徴マップと入力画像間の stride=4 は、12 ごとに相当します✖️入力画像内の 12 サイズの領域。中心点が繰り返されることはありません。このアイデアは非常にシンプルで効果的です)。次に、ヒートマップに基づいて最高スコアを持つ上位 K 点を選択します (デフォルトの K=100 により、最も信頼性の高い 100 個の予測ボックスの中心点が決定されます。このステップでは、特定の繰り返しボックスも削除されます)。信頼度のしきい値を設定でき、しきい値よりも高い値のみを出力します。
ステップ 4 - 出力サイズ予測値とオフセットによって予測ボックスのサイズを決定します。取得された予測フレーム情報はすべて 128✖️128 サイズの特徴マップ上にあるため、最後に予測フレーム情報が入力画像にマッピングされて、最終的な予測結果が得られます。
3. 具体的な内容
1)入力
512*512
入力画像を 512*512 サイズにカットする必要があります。
つまり、長辺を 512 に拡大縮小し、短辺を 0 で埋めます
。具体的な効果は次の図に示されています。元の画像の W>512 であるため、 、元の画像の H<512 のため、直接 512 にスケーリングされます。したがって、それに対して 0 補数演算を実行します。
2)バックボーン
論文では、Hourglass、ResNet、DLA の 3 つのネットワーク アーキテクチャを試し、各ネットワーク アーキテクチャの精度とフレーム レートは次のとおりです。
アップコンボリューション層を備えた Resnet-18:28.1% coco および 142 FPS
DLA-34:37.4% COCOAP および 52 FPS
Hourglass-104:45.1% COCOAP および 1.4 FPS
3)首と頭
このモジュールには 3 つのブランチが含まれており、具体的には、中心点ヒートマップ ブランチ、中心点オフセット ブランチ、およびターゲット サイズ ブランチが含まれます。
ヒートマップ グラフ ブランチには C チャネルが含まれており、各チャネルにはカテゴリが含まれており、ヒートマップ内の白く明るい領域はターゲットの中心点の位置を示します。
中心点オフセット ブランチは、プールされた低ヒートマップ上の点を元の画像にマッピングすることによって生じるピクセル エラーを補うために使用されます。
ターゲット サイズ ブランチは、ターゲット長方形の w および h 偏差値を予測するために使用されます。
a. ヒートマップは分類情報を表し、カテゴリごとに個別のヒートマップが生成されます。各ヒートマップでは、特定の座標にターゲットの中心点が含まれる場合、キー ポイントがターゲットに生成され、ガウス円が使用されます (予測されたコーナー ポイントが中心点の特定の半径 r 以内にある限り) 、長方形のボックスと gt_bbox の間の IoU が 0.7 より大きい場合、これらの点の値を 0 の値ではなくガウス分布値に設定します。) キー ポイント全体を表すため、次の図に具体的な詳細を示します。 。
ヒートマップを生成する具体的な手順は次のとおりです。
ステップ 1 - 入力画像を 512*512 のサイズにスケーリングし、画像に対して R=4 のダウンサンプリング操作を実行して、サイズ 128*128 のヒートマップ画像を取得します。
ステップ 2 - 入力画像内のボックスを 128*128 サイズのヒートマップにスケールし、ボックスの中心点の座標を計算し、切り捨て演算を実行して、それを点として定義します。
ステップ 3 - ターゲット ボックスのサイズに従ってガウス円の半径 R を計算します。ガウス円の半径の決定は、主にターゲット ボックスの幅と高さに依存します。実際には、通常、IOU=0.7 が使用されます。 、つまり下図ではoverlap=0.7 臨界値として3つの場合の半径をそれぞれ計算し、その最小値をガウスカーネルの半径Rとする 具体的な実装内容は図に示す下:
(1) ケース 1 - 予測ボックス pred_bbox には gt_bbox ボックスが含まれており、下図の最初のケースに対応し、IoU 式全体を展開した後、二元一次方程式を解く問題になります。
(2) Case 2-gt_bbox には予測ボックス pred_bbox box が含まれており、下図の 2 番目のケースに相当し、IoU 式全体を展開した後、2 値一次方程式を解く問題になります。
(3) 状況 3-gt_bbox と予測ボックス pred_bbox が重なっている。下図の 3 番目の状況に対応し、IoU 式全体を拡張した後、2 値一次方程式を解く問題になります。
ステップ 4 - サイズ 128*128 のヒートマップ上で、中心点として point を使用し、半径 R を使用してガウス値を計算します。点での値が最大となり、半径 R が増加するにつれて値は減少します。
上図はサンプルで、左側がトリミング後の512512サイズの入力画像、右側がガウス演算後に生成された128128サイズのヒートマップ画像を示しています。画像には 2 匹の猫が含まれているため、これら 2 匹の猫は同じカテゴリに属しているため、同じヒートマップ上に 2 つのガウス円が生成され、ガウス円のサイズは長方形のボックスのサイズに関係します。
4)損失関数
全体的な損失は 3 つの部分で構成されます。L k はヒートマップの中心点の損失を表し、Loff はターゲットの中心点のオフセット損失を表し、L size はターゲットの長さと幅の損失関数を表します。
a. ヒートマップ損失関数
N は、入力イメージ内のターゲットの数とヒートマップ内のキー ポイントの数です。上式の
と は
クロスエントロピー損失関数であり、
は
焦点損失項目であり、
これらの位置にあるオブジェクトの境界ボックスの中心は非常に近いため、半径範囲内の損失を抑制します。
b.オフセット損失関数
このうち、O^p~はネットワークが予測したオフセット値、pは画像の中心点の座標、Rはヒートマップの倍率、p~はスケーリング後の中心点の近似整数座標を表します。 、プロセス全体は L1 損失を使用して、正のサンプル ブロックのオフセット損失を計算します。バックボーン ネットワークによって出力される特徴マップの空間解像度は、元の入力画像の 4 分の 1 であるため。つまり、出力特徴マップ上の各ピクセルは元の画像の 4x4 領域に対応し、大きな誤差が生じるため、偏った損失値が導入されます。
目標中心点 p が (125, 63) であるとすると、入力画像サイズが 512*512、スケーリング スケール R=4 であるため、スケーリングされた 128x128 サイズの中心点の座標は (31.25, 15.75) となります。整数座標 (31 , 15) に対するオフセット値は (0.25, 0.75) です。
c. ターゲットの長さと幅の損失関数
このうち、N はキーポイントの数を表し、Sk はターゲットの実際のサイズを表し、S ^ pk は予測サイズを表し、プロセス全体は L1 損失を使用して陽性サンプル ブロックの長さと幅の損失を計算します。
5)トリック
a. 2 つのオブジェクトのヒート マップが交差する場合、その点の値が最大になります。
b. 2 つのオブジェクトの中心点が一致する場合、計算は解決されていませんが、論文評価セット (ココ データ セット) では、このケースは 0.1% しか占めていません。
4. 結果
上の表は、COCO 検証セットでの CenterNet ターゲット検出の精度と速度を示しています。行 1 は、Hourglass-104 をベンチマーク ネットワークとして使用すると 40.4 AP を取得できるだけでなく、14FPS の速度も取得できることを示しています。行 2 は、DLA-34 をベンチマーク ネットワークとして使用して取得された AP と FPS を示しています。行 3 と行 4線は、COCO 検証セットに対する ResNet-101 および ResNet-18 ベンチマーク ネットワークの影響を示しています。観察を通じて、DLA-34 に基づくベンチマーク ネットワークが精度と速度の間のトレードオフを達成できることがわかります。
高密度検出の概要に基づく
FSAF、FCOS、FoveaBox の類似点と相違点:
1. どちらもマルチスケールのターゲット検出に FPN を使用します。
2. 分類と回帰は両方とも、処理のために 2 つのサブネットワークに分離されます。
3. 分類と回帰は両方とも、密な予測を通じて実行されます。
4. FSAF と FCOS の回帰は 4 つの境界までの距離を予測しますが、FoveaBox の回帰は座標変換を予測します。
5. FSAF はオンライン機能選択を通じてより適切な機能を選択し、パフォーマンスを向上させます FCOS は中心性ブランチを通じて低品質の bbox を排除することでパフォーマンスを向上させます FoveaBox はターゲットの中心領域のみを予測することでパフォーマンスを向上させます
(DenseBox、YOLO) と (FSAF、FCOS、FoveaBox) の類似点と相違点:
1. 分類と回帰は両方とも、密な予測を通じて実行されます。
2. (FSAF、FCOS、FoveaBox) はマルチスケール ターゲット検出に FPN を使用しますが、(DenseBox、YOLO) はシングルスケール ターゲット検出のみを備えています。
3. (DenseBox、FSAF、FCOS、FoveaBox) は分類と回帰を 2 つのサブネットワークに分離することによって取得されますが、(YOLO) 分類と位置は均一に取得されます。
以下はキーポイント推定に基づくアンカーフリー検出です。
A. CornerNet (オープンソース)
1. 主な貢献
1) 左上と右下のヒートマップを設計し、左上と右下の可能性が最も高いポイントを見つけ出し、ブランチを使用して埋め込みベクトルを出力し、左上と右下の判断に役立てます。間の一致関係。
2) コーナープーリングの提案 検出タスクの変更のため、従来のプーリング方法はこのネットワークフレームワークにはあまり適していません。(後述)
2. 主要なアイデア
ネットワークには 2 つのブランチがあり、1 つのブランチは左上隅を予測し、もう 1 つは右下隅を予測します。
各ブランチには 3 つのラインがあり、ヒートマップはどのポイントがコーナー ポイントである可能性が最も高いかを予測し、埋め込みは主に各ポイントが属するターゲット (オブジェクトの左上隅と右下隅を一致させる方法を解決)、および最終的なオフセットを予測します。点の位置を補正するために使用されます。
検出コーナー部分では、CornerNet は左上隅と右下隅にそれぞれ対応する 2 つのヒート マップを生成します。ヒート マップは、グラフ内のコーナー ポイントのさまざまなカテゴリの位置を表現し、各コーナー ポイントに信頼度スコアを付けることができます。さらに、埋め込みベクトルとオフセットが生成されます。埋め込みベクトルは、上部の 2 つのコーナーを確認するために使用されます。左隅と右下隅 ポイントが同じオブジェクトに属しているかどうかに関係なく、オフセットによってコーナー ポイントの位置が微調整されます。ターゲット候補フレームを生成する段階では、ヒートマップからランキング上位 k 位の左上隅と右下隅を選択し、一対の隅の間の埋め込みベクトル間の距離を計算します。事前に設定されたしきい値を超えると、これら 2 つの点は同じオブジェクトに属するとみなされ、角の 2 点に基づいてバウンディング ボックスが生成され、同時に 2 つの角の点のスコアに基づいて平均スコアが次のように計算されます。バウンディングボックスのスコア。
3. 具体的な内容
1)入力
511 × 511 (4 倍ダウンサンプリング後の出力は 128*128)
2)バックボーン
砂時計ネットワーク (変更済み、事前トレインなし)
3)首と頭
ヒートマップ ブランチ (予測カテゴリ)、オフセット ブランチ (洗練されたコーナー オフセット)、エンベディング ブランチ (上下のコーナーのマッチング)、コーナー プーリングの 4 つの部分に分かれています。
a. ヒートマップとペナルティ削減戦略
各ヒートマップには C 個のチャネルがあります。ここで、C は BG カテゴリを除くカテゴリの数です。ヒートマップは gt 位置で最大の値を持ち、gt 位置に近づくほどヒートマップの値は大きくなります。これを実現するには、ガウス関数を構築します。中心は gt 位置であり、この中心から離れるほど減衰が強くなります。つまり、次のようになります。
シグマは半径の 1/3 であり、半径の計算方法は、形成された bbox と GT の iou の最小値が 0.3 より大きくなるようにすることです。
b. オフセット分岐
著者が予測したフィートマップの入力サイズは元の画像の入力サイズと異なります。ダウンサンプリング係数を n とすると、元の位置 (x, y) からフィーチャ マップへの対応する位置は ([x/n ], [y/n ]), ここで [ ] は丸め操作を表します。元の画像位置に再マッピングするとき、間違いなく一定の誤差が発生します。オフセット ルートはこれに基づいて位置を修正します。収束ターゲットは次のように表されます。 :
c. ブランチの埋め込み
このブランチの主な機能はコーナーをグループ化することです。作成者は 1 次元の埋め込みを使用します...つまり、1、2、3 などの異なるターゲットに異なる ID を割り当てます。その後、予測するときに、埋め込み値が左上隅と右下隅の値は非常に近いです。たとえば、一方が 1.2 でもう一方が 1.3 の場合、これら 2 つは同じターゲットに属する可能性が高く、両者の間に大きなギャップがある場合は、 1.2 と 2.3、つまり一般に、これらは 2 つの異なる目標です。このような予測を達成するには、次の 2 つのことを行う必要があります。
同じターゲットの 2 つの角によって予測される埋め込み値は、可能な限り近くなければなりません
-
さまざまなターゲットによって予測される埋め込み値は、可能な限り遠く離れている必要があります
d. コーナープーリング
一般的に使用される最大プーリングは通常、現在の位置を中心とし、そのサイズは 3x3 カーネルであり、受容野は自然に現在の位置を中心とします。しかし、コーナーの検出は、このような正方形の受容野よりも、単一方向の情報が重要です...左上を例にとると、水平方向の右と垂直下方向の 2 方向の情報が重要になります。このため、著者はコーナー プーリングを提案します。原理は次のとおりです。
たとえば、特徴マップのサイズが 10x10 で、点が (2,1) である場合、左上隅のプーリングは (2,1) から (2,10) までの線上の最大値を計算します。と (2,1) をライン (10,1) 上の最大値に重ね合わせます。実際の計算では逆算で実現できますが、模式図は以下のようになります。
上図の例として、2,1,3,0,2 の場合、最後の 2 は変更されず、最後から 2 番目は max(0,2)=2 となるため、2,2 が得られます。次に、最後から 2 番目は max(3,2)=3...というようになります。
個人的には 1 次元の最大プーリングによるものだと感じています。式は次のとおりです。
さらに、著者は resnet の残差構造をベースとして Backbone の予測構造と最終予測を変更しました. 具体的な方法は、最初の 3x3 畳み込み演算を変更することです. 最終的な予測構造は次のとおりです:
4)損失関数
ヒートマップ ブランチ (予測カテゴリ)、エンベディング ブランチ (上下のコーナー ポイントのマッチング)、オフセット ブランチ (洗練されたコーナー ポイントのオフセット) の 3 つの部分に分かれています。
a.ヒートマップ
ここで、p は予測値、y は実際の値であり、この関数は焦点損失に基づいて修正されます。
b. オフセット分岐
c. ブランチの埋め込み
このうち、etk と ebk は左上と右下の 2 つの分岐によって予測されたエンベディング、ek は 2 つの平均値、Lpull の役割は同じターゲットの予測値に近づけることです。 Lpush の役割 さまざまなターゲットのエンベディング値をさらにプッシュすることです。
全体の損失額は以下の通りです。
ここで、ハイパーパラメータ: アルファとベータは 0.1、ガンマは 1 です。
5)トリック
4. 結果
テスト中、ヒートマップの非最大値を抑制するために 3x3 の最大プーリングが使用され、ヒートマップ上の最初の 100 件の結果が取得され、L1 距離に従って照合されます。照合は各カテゴリ間で行われることに注意してください。 , 異なるカテゴリや L1 距離は通常考慮されません。著者の最終的な実験結果は次のとおりです。
一段法では非常に好成績ですが、二段法も多い戦いです。
B. CenterNet (オープンソース)
この centerNet は CornerNet の改良版であることに注意してください。元の論文は CenterNet: Keypoint Triplets for Object Detection と呼ばれています。
1. 主な貢献
中心点とコーナー点の情報を充実させるために 2 つの方法が提案されています。
センタープーリング: ブランチ内の中心キーポイントを予測します。中央プーリングは、オブジェクト内で中央のキー ポイントをより識別しやすくして、候補ボックスをフィルタリングするのに役立ちます。
Cascade Corner プーリング: CornerNet Corner プーリングに基づいて、Corner は内部情報を認識する機能を備えています。
2. 主要なアイデア
1) 画像の特徴を抽出するバックボーンとして Hourglass を使用します。
2) Cascade Corner Pooling モジュールを使用して画像のコーナー ヒートマップを抽出し、CornerNet と同じメソッドを使用して左上隅と右下隅に従ってオブジェクトの境界ボックスを取得します。すべての境界ボックスは中央エリアを定義します (詳細は後述 - 首と頭の紹介)
3) センター プーリング モジュールを使用して画像の中心ヒートマップを抽出し、中心マップに従ってすべてのオブジェクトの中心点を取得します。
具体的には: 中央ヒートマップでは、ヒートマップの応答値に従って、上位 k 個の中央キーポイントを選択し、対応するオフセット マップを使用してこれらのキーポイントを微調整し、より正確なキーポイントの位置を取得します。
4) オブジェクトの中心点を使用して、2) で抽出した境界ボックスをさらにフィルタリングします: ボックスの中央領域に中心点がない場合、ボックスは信頼できないとみなされます。中心点がこの中心にある場合は、ボックスは信頼できないと見なされます。境界ボックスは保持され、その bbox のスコアは 3 点の平均になります。
3. 具体的な内容
1)入力
544*511 (4 倍ダウンサンプリング後の特徴マップは 128*128)
2)バックボーン
砂時計
3)首と頭
ここでは、センター プーリング、カスケード コーナー プーリング、センター エリア設定の概念に注意する必要があります。
a.センタープーリング
オブジェクトの絶対的な幾何学的中心によって伝えられる情報は、必ずしも最も正確であるとは限りません。たとえば、人間の認識では、顔は重要な情報源ですが、ターゲット全体としての人間の中心点は顔上にありません。 。この問題を解決するために、より豊富な視覚情報を取得するためのセンター プーリングが提案されています。
以下の図はCenter poolingのプロセスを示したもので、具体的な方法はネットワークバックボーン経由で特徴マップを取得し、それが中心点であるかどうかをピクセル単位で確認し、その最大値を求めるというものです。このような操作を通じて、中心プーリングは中心点をより適切に見つけるのに役立ちます。
備考: そのブランチは、埋め込みブランチが切り取られていること、ヒートマップがカテゴリの数であること、オフセット フィーチャ マップが 2 つのレイヤーであることを除いて、CornerNet のブランチに似ています。
実現方法:
コーナープーリングと組み合わせることで、以下の図aに示すように、たとえば水平方向の最大値を選択したい場合、左プーリングと右プーリングを接続するだけで簡単に実装できます。
b.カスケードコーナープーリング
コーナーはコーナー ポイントでもあり、通常は実際のオブジェクトとは関係ありません。コーナー プーリングは、コーナーの位置を決定するために垂直方向と水平方向の最大値を見つけることを目的としています。ただし、境界には非常に敏感であり、 「見る」コーナー 「オブジェクト」内部の情報はカスケードコーナープーリングです。最初に境界に沿って最大値を見つけ、次に最大値の方向に「覗いて」内部最大値を見つけます。上の図bに示すように。
c. 中央エリア
中央領域のサイズ設定は重要です。たとえば、小さな境界ボックスの場合、中心領域が小さくなるほど、多くの正の例が負の例として判断されるため、再現率 (再現率) は低くなります。大きな境界ボックスの場合、中心領域が大きくなり、多くの負の例が正の例として判断されるため、精度は低くなります。そこで、この論文では、バウンディング ボックスのサイズに適応し、大きなバウンディング ボックス内に比較的小さな中心領域を生成するスケールを意識した中心領域を提案します。これにより、適合率 (精度) を効果的に向上させることができます。同様に、小さな境界ボックス内に比較的大きな中央領域を生成すると、再現率 (再現率) を効果的に向上させることができます。
このうち、tlx、tlyは左上コーナーの座標、brx、bryは右下コーナーの座標、ctlx、ctlyは中央エリアの左上コーナーの座標、cbrx、cbryはコーナーの座標です。中央エリアの右下隅。n は奇数で中心領域のサイズを決定しますが、中心領域の決定方法は非常に簡単で、bbox を 9 分割 (n=3) または 25 分割 (n=5) するだけです。著者は、bbox のサイズが 150 より大きい場合は n が 5 になり、150 未満の場合は n が 3 になると述べています。最終的なグラフィック効果は次のとおりです。塗りつぶされた四角形は境界ボックスを表し、影付きの部分は中央領域を表します。
4)損失関数
このうち、最初の 2 つは、焦点損失を使用して、それぞれコーナー点と中心点によって引き起こされる損失を検出するものであり、対応する後部は、CornerNer に似ており、プルとプッシュを使用してコーナー点を正確に分類します。 L1 損失を使用してコーナーとセンターの位置を微調整します。損失の具体的な意味は原文では言及されていません。主にコーナーネットの改善です。コーナーネットを参照してください。
ハイパーパラメータ設定: α、β、γ=0.1、0.1、1。
5)トリック
4. 結果
効果は非常に優れており、アンカーフリー方式やワンステージ方式の中で最も優れています。
C. ExtremeNet (オープンソース)
1. 主な貢献
角点の代わりに極点を検出し、幾何学的関係の組み合わせを通じて直接検出結果を取得することが提案されています。
次の問題を解決します。
1) ボトムアップ検出方式では、CornerNet と比較して、検出されるコーナーがターゲットの外側に位置することが多く、検出が困難になります。
2) ラベル付けの難しさ: 極値ポイントの手動ラベル付けは、監視フレームのラベル付けより簡単で時間もかかりません。
2. 主要なアイデア
CornerNetに基づく改善手法は、物体の4つの極値点(極点)と1つの中心点を予測し、それらを幾何学的分布に従って組み合わせ、極値点から予測フレームを構築し、予測結果を取得します。
3. 具体的な内容
1)入力
511*511
2)バックボーン
砂時計-104
(実際、ネットワークの計算は非常に大きく、同じ条件下で 256x256 の入力で約 140T、ResNet50 は約 8T となり、全体の速度も非常に遅くなります。)
3)首と頭
予測ヘッドが 4 つの極と中心点に対応する 5 つの H*W ヒート マップを出力した後、各ヒート マップのチャネル数はオブジェクト カテゴリの数に対応する C になります。
さらに、予測は 4 つの極に対応する 2 つのチャネルで 4 つのオフセット出力を生成します。これらは、極座標でのサンプリング精度の損失を微調整するために使用されます。これはクラスに依存せず、中心点を微調整する必要はありません。
中心グループ化プロセスを使用して、4 つの極と中心点をグループ化します。
4)損失関数
ExtremeNet の損失計算も、CornerNet のいくつかのプラクティスに従い、CornerNet の埋め込みプロセスを使用せずに、焦点損失変形の分類損失とダウンサンプリングによって引き起こされる位置精度の損失を計算します。
5)
裏技
a. トレーニングサンプルの生成
COCO データセットはトレーニングに使用されます。直接の極ラベルがないため、セグメント化されたマスク ラベルが使用され、極が計算され、その極がトレーニングに使用されます。
(ExtremeNet のトレーニング データ セットは、通常のターゲット検出データ セットと一致していません。または、トレーニング データに含まれる情報が多く、つまり、極の方が角よりも多くの意味情報を持っています。実用的な観点から、手動ラベル付けの効率は高くなります)ポールの高さはコーナーの高さよりも高く、それでも使用上の利点があります。)
b.
ゴーストボックスの抑制
極の組み合わせは網羅的なプロセスであり、極と中心点の間の座標関係にのみ基づいて決定されるため、偽陽性の結果が生じます。たとえば、同じカテゴリの小物が 3 つ並んでいる場合、座標計算後、左側のオブジェクトの左極と右側のオブジェクトの右極が中央のオブジェクトの中心点として計算され、より高い応答性 3 つの小さなオブジェクトを備えた長いオブジェクト。
抑制方法は、
ターゲットボックスに含まれるすべてのターゲットボックスのスコアの合計が、
ターゲットボックス自体のスコアの
3倍を超える 場合、ターゲットボックス自体のスコアを2で割ります。
-
ここでの 3 回は下限であり、それより多くのオブジェクト (5 つなど) が含まれている場合も抑制されます。
-
2 で除算すると、大きな予測フレームのスコアが減少し、後続の NMS プロセスで大きなターゲット フレームを除外できます。
c.
エッジ集約 (現時点では理解されていません)
極を予測する際のもう 1 つの問題は、オブジェクトに座標軸に平行な辺がある場合、設計によれば、その辺全体の点が極応答を持つはずであることです。問題は、各点の応答が比較的低い可能性があることです。 、または特定の角度を回転した後の唯一の極よりも低いエッジ集約は、平行エッジの応答を強化して予測効果を向上させることを目的としています。
4. 結果
アブレーション実験の結果:
-
このうち、1行目は標準のExtremeNet、2行目のマルチスケールは入力画像のマルチスケール拡張です。
-
2 番目の部分では、Center グループ化が削除されると、結合プロセスが CornerNet と同様の Embedding に置き換えられ、パフォーマンスが 2.1% mAP 低下します。
-
エッジの集約とゴーストの除去は、大きなオブジェクトの場合により顕著ですが、小さなオブジェクトにはほとんど影響しません。
-
3 番目の部分はエラー分析で、予測結果をグランド トゥルースに置き換えます。中心を置き換えた後の改善は特に大きくなく、中心特徴の抽出に問題がないことを示しています。極値の置き換えと中心点の置き換えを同時に行った結果、大幅な改善がもたらされました。これは、極値の抽出と極値の中心点の結合のプロセスにまだ多くの改善の余地があることを示しています。
他のターゲット検出フレームワークとの比較:
参考リンク:
6. 13種類のアンカーフリーまとめ:
https://bbs.cvmart.net/articles/442/zhong-bang-13-pian-ji-yu-anchor-free-de-mu-biao-jian-ce-ファンファ
9、yolov1:
https://zhuanlan.zhihu.com/p/70387154
10. yolov1 損失関数;
https://blog.csdn.net/qq_38236744/article/details/106724596
16、feveabox:
https://zhuanlan.zhihu.com/p/63190983
17、feveabox:
https://zhuanlan.zhihu.com/p/68075721
18. Centernet (点としてのオブジェクト) の詳細:
https://blog.csdn.net/WZZ18191171661/article/details/113753991
19. センターネット (点としてのオブジェクト) の詳細:
https://mp.weixin.qq.com/s/hlc1IKhKLh7Zmr5k_NAykw
20. Centernet (点としてのオブジェクト) の詳細:
https://zhuanlan.zhihu.com/p/66048276
21. Centernet (点としてのオブジェクト) によるガウス カーネル半径の説明:
https://zhuanlan.zhihu.com/p/96856635
22、コーナーネット:
https://zhuanlan.zhihu.com/p/44449116
23、 cornetNet:
https://arxiv.org/abs/1808.01244
24、コーナーネット:
https://zhuanlan.zhihu.com/p/53407590
26、センターネット:
https://zhuanlan.zhihu.com/p/66326413
27、センターネット:
https://zhuanlan.zhihu.com/p/60072845
28、エクストリームネット:
https://zhuanlan.zhihu.com/p/117597564
29、エクストリームネット:
https://zhuanlan.zhihu.com/p/57254154