ヒント: 記事を作成した後、目次を自動的に生成できます。生成方法は、右側のヘルプドキュメントを参照してください。
序文
疲労は人間の表情に大きく分けて「あくび」「まばたき」「うなずき」の3種類が現れます。この実験では、顔の向き、位置、瞳孔の向き、目の開閉度、まばたきの回数、瞳孔の収縮率などのデータからスタートし、これらのデータを用いてドライバーの集中力をリアルタイムに算出し、ドライバーの疲労や疲労の有無を分析します。安全に関する注意喚起をタイムリーに行います。
1. 背景
(1) 環境構築
件名が使用する環境構成: python3.9.13+cuda11.3+anaconda3
必要なライブラリ:
pip インストール numpy
pip インストール matplotlib
pip installl imutils
pip インストール scipy
pip インストール dlib
その中で、dlibのダウンロード方法(この記事ではpy3.9バージョンのダウンロードのみを提供します)
最初にインストールする
pip インストール cmake
pip インストールブースト
dlib-19.23.0-cp39-cp39-win_amd64.whlをダウンロード
ダウンロード後、対応するフォルダで実行します(これは皆さんご存知でしょう(私は環境ディレクトリのbackagesフォルダに置きました))
pip install dlib-19.23.0-cp39-cp39-win_amd64.whl
其他版本dlibでダウンロード
(2) オープンソースデータセットのダウンロード
Shape_predictor_68_face_landmarks.dat
(3) あくび疲労検知の原理
dlib 顔認識の 68 個の特徴点の検出に基づいて、口の顔のランドマークのインデックスが取得され、opencv を通じてビデオ ストリームがグレースケール化されて、人間の口の位置情報が検出されます。
顔特徴点検出は dlib を使用します。dlib には、dlib.get_frontal_face_detector() と dlib.shape_predictor(predictor_path) という 2 つの主要な関数があります。
前者は、HOG ピラミッドを使用して顔領域の境界 (境界) を検出する組み込みの顔検出アルゴリズムです。
後者は、領域内の特徴点を検出し、これらの特徴点の座標を出力するために使用され、適切に動作するには、事前にトレーニングされたモデル (ファイル パス メソッドを通じて渡される) が必要です。
オープンソースモデルのshape_predictor_68_face_landmarks.datを使用すると、68個の特徴点の座標を取得でき、それらを接続すると図のような効果が得られます(赤はHOGピラミッド検出の結果、緑はshape_predictorの結果、のみ)同じ器官の特徴が点で接続されます)。

その動作であくびが発生する限り、それは「疲労」として分類されました。
68 顔の特徴マップ ラマーク:

口には主に 6 つの参照点があります。
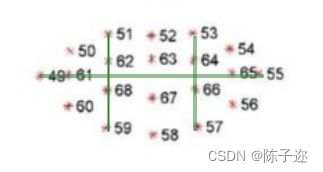
あくびは口を使って縦座標51、59、53、57と横座標49、55を計算することで目の開き具合を計算することができます。例: 1/2*[(y51+y53)-(y59+y57)]/(x55-x49) 口を開けるかどうかを判断する点の距離と開く時間を判断し、あくびをしているかどうかを判断します。閾値は妥当な値である必要があり、多くの実験を行った結果、通常の話し声やハミングと区別できる必要があります。
目と同様の方法で口のユークリッド距離を求めます。

最終判定:
加重採点:目とあくびの特徴による融合判定(得点、曖昧表現)
(4) メインコードの考え方
あくび検出、つまり内側の輪郭を検出するための、口の開き具合と口の開いた時間を組み合わせた二重閾値法。
あくびはあくびが発生したフレーム数、N は 1 分間の総フレーム数、しきい値は 10% に設定されます。Freq>10% の場合、深いあくび、または少なくとも 2 回連続した浅いあくびとみなされます。この時点で疲労リマインダーが表示されます。
Step1:提取帧图像检测人脸,嘴部粗定位进行肤色分割;
Step2:嘴部精确定位,获取嘴部特征值K1,若k1大于阈值T1,则Step3,;否则K2=K1/2,count=0回到step1,检测下一帧。
Step3:提取嘴部内轮廓特征值K2,若K2大于阈值T2,则Step4,否则count=0,返回Step1,检测下一帧。
Step4:统计哈欠特征count=count+1,当count超过阈值且下一帧的哈欠特征消失,保存count到Yawn,Yawn(i)=count,count=0(count清0)回到Step1,否则的话也直接转回Step1。
Step5:分析完1min内所有图像,计算哈欠特征总数,按照计算Freq值,超过阈值则发出疲劳提醒。(推荐阈值为0.1)
# -*- coding: utf-8 -*-
# import the necessary packages
from scipy.spatial import distance as dist
from imutils.video import FileVideoStream
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np # 数据处理的库 numpy
import argparse
import imutils
import time
import dlib
import cv2
def eye_aspect_ratio(eye):
# 垂直眼标志(X,Y)坐标
A = dist.euclidean(eye[1], eye[5])# 计算两个集合之间的欧式距离
B = dist.euclidean(eye[2], eye[4])
# 计算水平之间的欧几里得距离
# 水平眼标志(X,Y)坐标
C = dist.euclidean(eye[0], eye[3])
# 眼睛长宽比的计算
ear = (A + B) / (2.0 * C)
# 返回眼睛的长宽比
return ear
def mouth_aspect_ratio(mouth):
A = np.linalg.norm(mouth[2] - mouth[9]) # 51, 59
B = np.linalg.norm(mouth[4] - mouth[7]) # 53, 57
C = np.linalg.norm(mouth[0] - mouth[6]) # 49, 55
mar = (A + B) / (2.0 * C)
return mar
# 定义两个常数
# 眼睛长宽比
# 闪烁阈值
EYE_AR_THRESH = 0.2
EYE_AR_CONSEC_FRAMES = 3
# 打哈欠长宽比
# 闪烁阈值
MAR_THRESH = 0.5
MOUTH_AR_CONSEC_FRAMES = 3
# 初始化帧计数器和眨眼总数
COUNTER = 0
TOTAL = 0
# 初始化帧计数器和打哈欠总数
mCOUNTER = 0
mTOTAL = 0
# 初始化DLIB的人脸检测器(HOG),然后创建面部标志物预测
print("[INFO] loading facial landmark predictor...")
# 第一步:使用dlib.get_frontal_face_detector() 获得脸部位置检测器
detector = dlib.get_frontal_face_detector()
# 第二步:使用dlib.shape_predictor获得脸部特征位置检测器
predictor = dlib.shape_predictor('D:/myworkspace/JupyterNotebook/fatigue_detecting/model/shape_predictor_68_face_landmarks.dat')
# 第三步:分别获取左右眼面部标志的索引
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
(mStart, mEnd) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
# 第四步:打开cv2 本地摄像头
cap = cv2.VideoCapture(0)
# 从视频流循环帧
while True:
# 第五步:进行循环,读取图片,并对图片做维度扩大,并进灰度化
ret, frame = cap.read()
frame = imutils.resize(frame, width=720)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 第六步:使用detector(gray, 0) 进行脸部位置检测
rects = detector(gray, 0)
# 第七步:循环脸部位置信息,使用predictor(gray, rect)获得脸部特征位置的信息
for rect in rects:
shape = predictor(gray, rect)
# 第八步:将脸部特征信息转换为数组array的格式
shape = face_utils.shape_to_np(shape)
# 第九步:提取左眼和右眼坐标
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
# 嘴巴坐标
mouth = shape[mStart:mEnd]
# 第十步:构造函数计算左右眼的EAR值,使用平均值作为最终的EAR
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
ear = (leftEAR + rightEAR) / 2.0
# 打哈欠
mar = mouth_aspect_ratio(mouth)
# 第十一步:使用cv2.convexHull获得凸包位置,使用drawContours画出轮廓位置进行画图操作
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
mouthHull = cv2.convexHull(mouth)
cv2.drawContours(frame, [mouthHull], -1, (0, 255, 0), 1)
# 第十二步:进行画图操作,用矩形框标注人脸
left = rect.left()
top = rect.top()
right = rect.right()
bottom = rect.bottom()
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 3)
'''
分别计算左眼和右眼的评分求平均作为最终的评分,如果小于阈值,则加1,如果连续3次都小于阈值,则表示进行了一次眨眼活动
'''
# 第十三步:循环,满足条件的,眨眼次数+1
if ear < EYE_AR_THRESH:# 眼睛长宽比:0.2
COUNTER += 1
else:
# 如果连续3次都小于阈值,则表示进行了一次眨眼活动
if COUNTER >= EYE_AR_CONSEC_FRAMES:# 阈值:3
TOTAL += 1
# 重置眼帧计数器
COUNTER = 0
# 第十四步:进行画图操作,同时使用cv2.putText将眨眼次数进行显示
cv2.putText(frame, "Faces: {}".format(len(rects)), (10, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "Blinks: {}".format(TOTAL), (150, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "COUNTER: {}".format(COUNTER), (300, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (450, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
'''
计算张嘴评分,如果小于阈值,则加1,如果连续3次都小于阈值,则表示打了一次哈欠,同一次哈欠大约在3帧
'''
# 同理,判断是否打哈欠
if mar > MAR_THRESH:# 张嘴阈值0.5
mCOUNTER += 1
cv2.putText(frame, "Yawning!", (10, 60),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
else:
# 如果连续3次都小于阈值,则表示打了一次哈欠
if mCOUNTER >= MOUTH_AR_CONSEC_FRAMES:# 阈值:3
mTOTAL += 1
# 重置嘴帧计数器
mCOUNTER = 0
cv2.putText(frame, "Yawning: {}".format(mTOTAL), (150, 60),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "mCOUNTER: {}".format(mCOUNTER), (300, 60),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "MAR: {:.2f}".format(mar), (480, 60),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# 第十五步:进行画图操作,68个特征点标识
for (x, y) in shape:
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
print('嘴巴实时长宽比:{:.2f} '.format(mar)+"\t是否张嘴:"+str([False,True][mar > MAR_THRESH]))
print('眼睛实时长宽比:{:.2f} '.format(ear)+"\t是否眨眼:"+str([False,True][COUNTER>=1]))
# 确定疲劳提示
if TOTAL >= 50 or mTOTAL>=15:
cv2.putText(frame, "SLEEP!!!", (100, 200),cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
# 按q退出
cv2.putText(frame, "Press 'q': Quit", (20, 500),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (84, 255, 159), 2)
# 窗口显示 show with opencv
cv2.imshow("Frame", frame)
# if the `q` key was pressed, break from the loop
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头 release camera
cap.release()
# do a bit of cleanup
cv2.destroyAllWindows()