
要約:YOLOv5に基づく疲労運転検知システムは、深層学習技術を利用して、一般的な運転写真、動画、リアルタイム動画から疲労行動を検知し、目を閉じる、あくびをした結果を認識し、記録・保存することで交通事故を未然に防ぎます。この論文では、疲労運転検出システムの実装原理を詳細に紹介し、Python の実装コード、トレーニング データ セット、およびPyqtのUIインターフェイスを提供します。インターフェイスでは、検出と認識のためにさまざまな写真やビデオを選択でき、画像内の複数のターゲットを認識して分類できます。The blog post provides a complete Python code and usage tutorial, which is expected to see a初心者向け. 完全なコードリソースファイルについては、記事の最後にあるダウンロードリンクにアクセスしてください. このブログ投稿のカタログは次のとおりです。
記事ディレクトリ
➷記事の最後にある、関連するすべての完全なコード ファイルのダウンロード ページにジャンプするには、クリックしてください☇
YOLOv5に基づく疲労運転検知システムのデモと紹介 (Python+フレッシュインターフェース+データセット)
序文
疲労運転とは、運転者が長時間連続して運転した後の心理的能力や生理的メカニズムの変化を指し、運転技術の低下として客観的に表れるもので、眠気、無反応、手足の脱力感、不注意、能力の低下などを示します。判断する。不完全な統計によると、交通事故の 50% はドライバーの無意識が原因であり、それが交通事故につながります。
ドライバーの疲労状態をリアルタイムで検知することは、安全運転の要であり、ドライバーの疲労状態をリアルタイムで検知し、車両を運転する際に早期に警告を発する必要があります。視覚的特徴に基づくドライバーの疲労状態検出方法は、主にカメラを使用して運転状態のドライバーの顔の特徴をリアルタイムで収集し、視覚と画像処理に基づく方法を使用して、ドライバーの目、口、頭を取得します。 . 内部エリア情報などの特性情報。最後に、抽出したドライバーのまばたき回数やあくびなどの特徴を特定の判別法で分析し、ドライバーの疲労状態を検出します。ターゲット検出の方向への現在の深層学習方法の詳細な適用により、YOLOv5に基づくターゲット検出方法には、適用の可能性と適用の見通しがあります。
YOLOv5に基づく疲労運転検出システムは、深層学習技術を適用して、ドライバーの安全運転の監視と分析を容易にするために、目を閉じる、あくびなどの一般的な行動を含む、一般的な運転プロセスに存在する可能性のある疲労運転行動を検出します。ユーザー管理; カメラによってキャプチャされた写真、ビデオ、およびリアルタイムの写真について、システムは写真内の疲労運転行動を検出できます; システムは結果の記録、表示、および保存をサポートし、各検出の結果はテーブル。これに関して, これはブロガーによって設計されたインターフェースです. 同じスタイルのシンプルなスタイル, 機能は写真、ビデオ、カメラの認識と検出にも対応できます. 気に入っていただければ幸いです. 初期のインターフェースは次のとおりです. :

カテゴリを検出するときのインターフェイスのスクリーンショット (画像をクリックして拡大) は以下のとおりです。これは、画面内の複数のカテゴリを識別し、カメラまたはビデオの検出を有効にすることもできます。
詳しい機能デモ効果はブロガーのBステーション動画か次項のアニメデモを参考に いいなと思った友達はいいね、フォロー、ブックマークお願いします!システム UI インターフェースの設計負荷は比較的大きく、インターフェースの美化は慎重に作成する必要があります. 提案や意見がある場合は、以下にコメントして交換することができます.
1.効果のデモンストレーション
アニメーションを通して認識効果を見てみましょう. システムの主な機能は, 写真, ビデオとカメラ画像で疲労運転行動を認識することです. 認識結果はインターフェースと画像に視覚的に表示されます, 複数の顔表示オプション機能とデモ効果は以下の通りです。
(1) システム紹介
関連文献を調べたところ、人間の表情の疲労には大きく分けて、あくび(口を開けてその状態を比較的長時間維持する)、まばたき(または少し目を閉じる、このときまばたきの回数が増える、点滅速度が遅くなる)など ここでは、YOLOv5 を使用してこれらのデータ機能を識別し、ドライバーの疲労運転行動をリアルタイムで分析し、タイムリーな安全リマインダーを作成します。
(2) 技術的特徴
(1) YOLO v5 アルゴリズムを実装し、モデルを 1 つのキーで切り替えて更新できます
(2) 写真、ビデオ、その他の画像で疲労運転行動を検出します (3)
カメラ監視、ポータブル ディスプレイ、記録と保存;
(4) ユーザーのログイン、登録、検出結果の可視化をサポート;
(5) トレーニング データ セットとコードを提供し、モデルを再トレーニングします。
(3) ユーザー登録・ログイン画面
下の図に示すシステム ログイン インターフェイスでは、ユーザー名とパスワードを入力してログインおよび登録できます。入力が正しければ、メイン インターフェイスに入ることができます。

(4) 画像認識を選択
システムは認識対象の画像ファイルを選択することができます.画像選択ボタンアイコンをクリックして画像を選択すると,すべての顔認識結果が表示されます.ドロップダウンボックスから単一の結果を確認して,特定の疲労ドライバーを具体的に判断することができます. この機能のインターフェース表示を下図に示します。

(5) 映像認識効果表示
ビデオで疲労運転状況を特定したい場合は、ビデオボタンをクリックして検出するビデオを選択できます。システムは自動的にフレームごとにビデオを分析して顔を認識し、疲労運転の結果を記録します。右下隅の表では、効果は次の図に示すとおりです。

(6) カメラ検知効果表示
実際のシーンで、デバイスのカメラを使用してリアルタイムの画像を取得し、画像内の疲労運転行動を特定する必要がある場合は、カメラ ボタンをクリックすると、システムは準備完了状態になります. システムは実際の画像を表示します. -time イメージを実行し、イメージ内のドライバーの検出を開始します。次の図を表示します。

2.疲労運転検知
(1) 疲労運転データセット
ここで使用する疲労運転データ セットには、トレーニング データ セットに 656 枚の写真、検証セットに 188 枚の写真、テスト セットに 94 枚の写真、合計 938 枚の写真が含まれています。

各画像は、画像タグ情報、画像内の疲労運転のバウンディング ボックスを提供し、データ セットを解凍して次の図を取得します。

(2) ネットワーク構造
Yolov5 ネットワーク構造は、Input、Backbone、Neck、および Prediction で構成されています。Yolov5 の入力部分はネットワークの入力端であり、モザイク データ拡張メソッドを使用して、入力データをランダムにトリミングし、それらをつなぎ合わせます。バックボーンは Yolov5 が特徴を抽出するネットワークの一部であり、特徴抽出機能はネットワーク全体のパフォーマンスに直接影響します。Yolov5 の Backbone は、以前の Yolov4 と比較して、新しいフォーカス構造を提案しました。フォーカス構造は、画像をスライスし、W (幅) と H (高さ) の情報をチャネル空間に転送することで、情報を失うことなく 2 倍のダウンサンプリング操作が実行されるようにします。
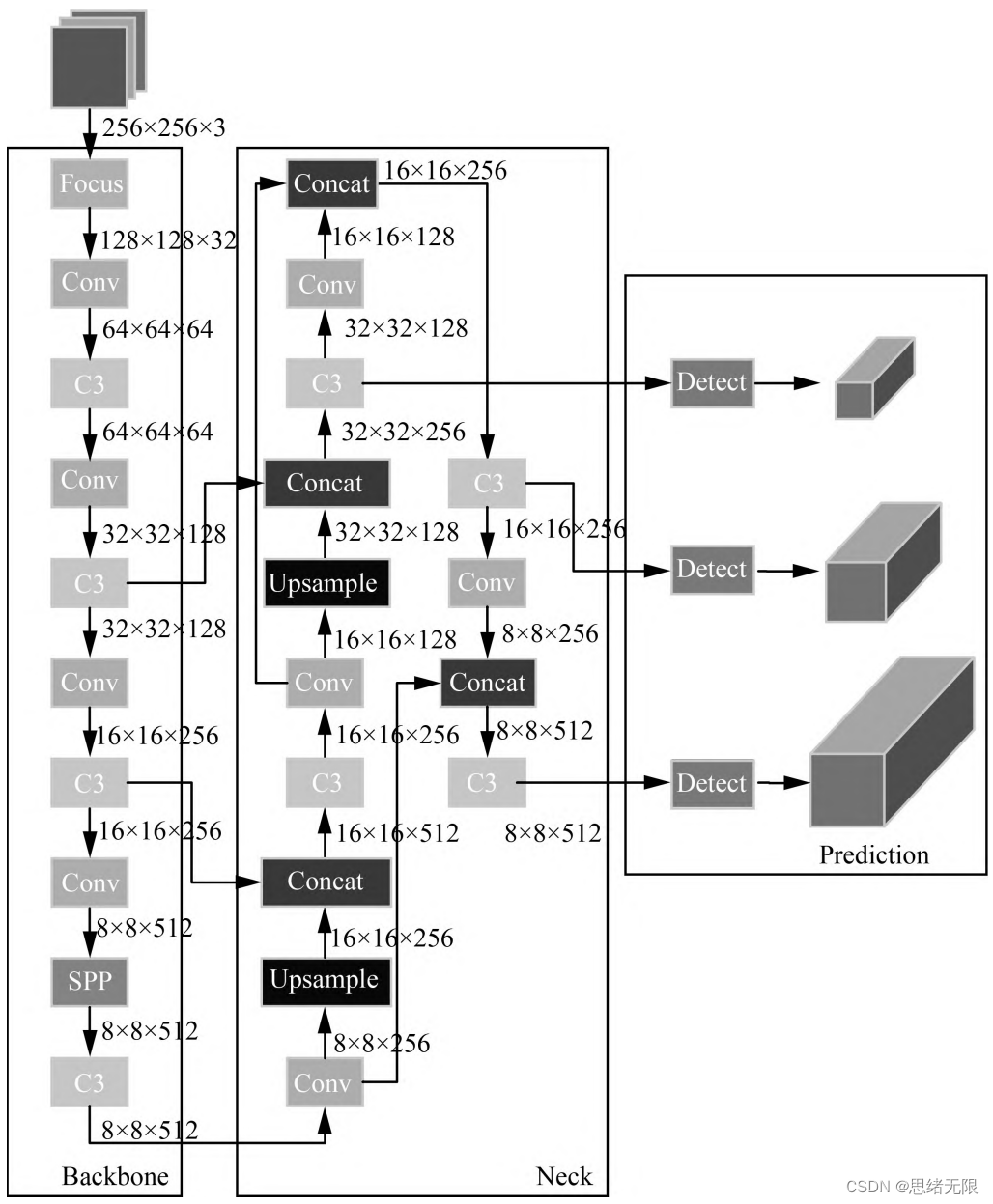
(3) 研修プロセス
ネットワーク トレーニング データ量が多いため、実験中はデータを複数のバッチに分割します. 各バッチには一定数の画像が含まれます. 順方向および逆方向の伝播の後、適切なエラーでネットワークをトレーニングするためにネットワーク パラメータが更新されます. テストでは、ネットワークによって画像が認識され、得られた認識精度に基づいてネットワークの実現可能性が検証されます。
上記で紹介したデータセットを処理した後、ラベルファイルはYOLOv5トレーニングに必要なラベル形式に変換されます.このデータセットに基づいて、train.pyに必要なパラメータを設定し、モデルトレーニング用のスクリプトを実行します.トレーニングプロセスは下図のようにターミナルが表示されます。

深層学習では、通常、損失関数の減少曲線を通じてモデルのトレーニング状況を観察します。YOLOv5 トレーニングには、主に、長方形ボックス損失 (box_loss)、信頼損失 (obj_loss)、および分類損失 (cls_loss) の 3 つの側面の損失が含まれます. モデルのトレーニング曲線を下の図に示します.

一般的には、再現率再現率と精度精度を使用します. p と r の 2 つの指標は、単にモデルの品質を 1 つの角度から判断するだけです. ターゲット検出のパフォーマンスを総合的に評価するために、一般的に平均平均密度マップを使用してモデルをさらに評価します。良いか悪いか。異なる信頼しきい値を設定することにより, 異なるしきい値の下でモデルによって計算された p 値と r 値を得ることができます. 一般に, p 値と r 値は負の相関があります. 描画後, 次の図を得ることができます.曲線が示されています。

(4) 予測プロセス
トレーニングが完了すると、最良のモデルが得られます. 次に、フレーム画像を予測用のネットワークに入力して、予測結果を取得します. 予測メソッド (predict.py) 部分のコードは次のとおりです。
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
予測結果を取得した後, フレーム画像でターゲットをフレーミングすることができます. 以下は, ビデオファイルを読み込んでそれを検出するスクリプトです. 最初に, 画像データは前処理され、検出のために予測するために送信されます.マークされたフレームが計算され、図に表示されます。
if __name__ == '__main__':
# video_path = 0
video_path = "./UI_rec/test_/疲劳驾驶检测.mp4"
# 初始化视频流
vs = cv2.VideoCapture(video_path)
(W, H) = (None, None)
frameIndex = 0 # 视频帧数
try:
prop = cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
# print("[INFO] 视频总帧数:{}".format(total))
# 若读取失败,报错退出
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
fourcc = cv2.VideoWriter_fourcc(*'XVID')
ret, frame = vs.read()
vw = 850
vh = 500
print("[INFO] 视频尺寸:{} * {}".format(vw, vh))
output_video = cv2.VideoWriter("./results.avi", fourcc, 20.0, (vw, vh)) # 处理后的视频对象
# 遍历视频帧进行检测
while True:
# 从视频文件中逐帧读取画面
(grabbed, image) = vs.read()
image = cv2.resize(image, (850, 500))
# 若grabbed为空,表示视频到达最后一帧,退出
if not grabbed:
print("[INFO] 运行结束...")
output_video.release()
vs.release()
exit()
# 获取画面长宽
if W is None or H is None:
(H, W) = image.shape[:2]
img0 = image.copy()
img = letterbox(img0, new_shape=imgsz)[0]
img = np.stack(img, 0)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
pred, useTime = predict(img)
det = pred[0]
p, s, im0 = None, '', img0
if det is not None and len(det): # 如果有检测信息则进入
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸
number_i = 0 # 类别预编号
detInfo = []
for *xyxy, conf, cls in reversed(det): # 遍历检测信息
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# 将检测信息添加到字典中
detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])
number_i += 1 # 编号数+1
label = '%s %.2f' % (names[int(cls)], conf)
# 画出检测到的目标物
plot_one_box(image, xyxy, label=label, color=colors[int(cls)])
# 实时显示检测画面
cv2.imshow('Stream', image)
output_video.write(image) # 保存标记后的视频
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# print("FPS:{}".format(int(0.6/(end-start))))
frameIndex += 1
実行結果は下図の通りで、歩行者と信頼度が図中にマークされており、予測速度が速いです。このモデルに基づいて、インターフェイスを備えたシステムにパッケージ化し、インターフェイスで写真、ビデオ、またはカメラを選択してから、検出のためにモデルを呼び出すことができます。

ブロガーはシステム全体で詳細なテストを実施し、最終的に、ブログ投稿のデモ部分、完全な UI インターフェイス、テスト画像ビデオ、コード ファイル、および Python オフラインの表示である、スムーズでさわやかなインターフェイスを備えたバージョンを開発しました。依存関係パッケージ (インストールと実行は簡単ですが、自分で環境を構成することもできます) はすべてパッケージ化されてアップロードされており、興味のある友人はダウンロード リンクから入手できます。

ダウンロードリンク
ブログ投稿に含まれる完全なプログラム ファイル (下の図に示すように、テスト用の写真、ビデオ、 py、UIファイルなどを含む) を入手したい場合は、それらがパッケージ化され、ブロガーの Bread Multi にアップロードされています。 -platform. 参照用のブログとビデオを参照してください. 関連するすべてのファイルを同時にパッケージ化し、クリックして実行します. 完全なファイルのスクリーンショットは次のとおりです:

フォルダ配下のリソースは以下のように表示されます. また, Python のオフライン依存パッケージも以下のリンクで提供されています. 読者は, Anaconda と Pycharm ソフトウェアを正しくインストールした後, オフライン依存パッケージをプロジェクトディレクトリにコピーしてインストールすることができます.デモンストレーションは私の B ステーション ビデオでも見ることができます: Win11 はソフトウェアを最初からインストールし、深層学習プロジェクトを実行する環境を構成し、Python 環境構成チュートリアルのために Win10 で pycharm と anaconda を使用します。
注: このコードは Pycharm+Python3.8 で開発されており、テスト後に正常に実行できます. 実行中のインターフェイスのメイン プログラムは runMain.py と LoginUI.py です. テスト画像スクリプトは testPicture.py を実行できます.ビデオ スクリプトは testVideo.py を実行できます。プログラムがスムーズに実行されるようにするには、requirements.txt に従って Python 依存関係パッケージのバージョンを構成してください。Python バージョン: 3.8。他のバージョンは使用しないでください。詳細については、requirements.txt ファイルを参照してください。
完全なリソースには、データ セットとトレーニング コードが含まれています. 環境の構成と、インターフェイスでテキスト、写真、ロゴなどを変更する方法については、ビデオを参照してください. プロジェクトの完全なファイルをダウンロードするには、参照ブログを参照してください.投稿するか、ビデオの紹介を参照してください: ➷➷ ➷
参考ブログ記事: https: //zhuanlan.zhihu.com/p/615310050
参考動画デモンストレーション:https://www.bilibili.com/video/BV1bL411k7Wj/
オフライン依存ライブラリのダウンロード リンク: https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (抽出コード: oy4n)
インターフェイスでテキスト、アイコン、および背景画像を変更する方法:
Qt Designer では、インターフェイスのさまざまなコントロールと設定を完全に変更してから、ui ファイルを py ファイルに変換して、インターフェイスを呼び出して表示できます。インターフェイスのテキスト、アイコン、および背景画像のみを変更する必要がある場合は、ConfigUI.config ファイルで直接変更できます. 手順は次のとおりです: (1) UI_rec/tools/ConfigUI.config ファイルを開きます
.文字化けがありますので、GBKコードを選択して開いてください。
(2) インターフェイスのテキストを変更する必要がある場合は、変更したい文字を選択して、自分の文字に置き換えます。
(3) 背景やアイコンなどを変更する必要がある場合は、画像のパスを変更するだけです。たとえば、元のファイルの背景画像は次のように設定されています。
mainWindow = :/images/icons/back-image.png
background2.png という名前の独自の画像 (UI_rec/icons/ フォルダーにあります) に変更できます。背景画像は、このアイテムを次のように設定することで変更できます。
mainWindow = ./icons/background2.png
結論
ブロガーの能力には限りがあるため、ブログ投稿に記載されている方法をテストしたとしても、抜けがあることは避けられません。次の改訂版がより完璧で厳密な方法ですべての人に提示できるように、間違いを熱心に指摘していただければ幸いです。同時に、それを達成するためのより良い方法があれば教えてください。