- 1. 非構造化データとは
- 2. 非構造化データ分析
- 3. 文書画像の分析と前処理
- 正しいグラフィックスオフセット
- モアレを除去する
- 4. 反射を除去する
- 反射原理
- 画像の反射を除去するPythonメソッド
- 5. レイアウト解析と文書復元
- 5.1 物理レイアウトと論理レイアウト
- 5.2 レイアウト要素の検査
- 5.3 文書の復元
- 5.4 文書復元の適用
- 6. 全体のまとめ
1. 非構造化データとは
非構造化データとは、テキスト、画像、動画、音声など、決まった形式やルールがないデータのことを指します。情報技術の急速な発展に伴い、非構造化データの重要性がますます高まっています。主な理由は次のとおりです。
ソーシャル メディアとデジタル コンテンツの成長: ソーシャル メディアとデジタル コンテンツの人気に伴い、人々が日常生活で生成する非構造化データの量は増加し続けています。たとえば、人々がソーシャル メディアを通じて投稿する写真、投稿、コメントなどは非構造化データです。
ビッグデータ時代の到来: ビッグデータ時代の到来により、組織や企業はビジネス目標を達成するためにより多くのデータを処理および分析する必要があり、非構造化データには多くの場合、新たな機会や価値をもたらす有用な情報が含まれています。
人工知能と機械学習の開発: 人工知能と機械学習はトレーニングと学習に大量のデータを必要としますが、非構造化データはより多様で現実的なデータを提供し、アルゴリズムが将来の傾向と動作をよりよく理解し、予測するのに役立ちます。
人々はより包括的なデータ分析を必要としています : 非構造化データには豊富な情報が含まれているため、より完全かつ包括的なデータ分析が可能になり、組織が顧客、市場、ビジネスをより深く理解するのに役立ちます。
2. 非構造化データ分析
構造化データの取得には、ETLのみが必要です(抽出 > 変換 > ロード)。しかし、非構造化データを扱うのは非常に困難です。なぜ難しいのでしょうか? トマトが例を示します。

非構造化データ収集のシーンピット:
- さまざまなシーンとフォーマット
- 取得機器の不確実性
- ユーザーニーズの多様化
- 文書の画質が大幅に低下する
- テキスト検出とレイアウト解析が難しい
- 無制限のテキスト認識率が低い
- 構造化知能についての理解が不十分
3.文書画像の分析と前処理
次にトマトが実際の事例を紹介します。

まず左の写真ですが、曲がり、影、モアレ、不鮮明などの問題を抱えています。機械はもちろん、肉眼でも識別することは困難です。
しかし、パニックにならないでください。解決策はあります。詳細な手順は次のとおりです。
正しいグラフィックスオフセット

変形した画像の場合、アルゴリズムはオフセットを計算し、変形補正を実行し、最後にエッジを塗りつぶして修復されたグラフィックを取得します。
モアレを除去する
モアレは、画像キャプチャ デバイス (カメラなど) のセンサー アレイと撮影対象の細部の間の干渉効果によって発生します。

- 背景抽出モジュール
- 干渉除去モジュール
- 情報融合モジュール
モアレを除去するには、次のPythonコードを使用できます。
import cv2
import numpy as np
def remove_moire(image):
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用傅里叶变换将图像转换到频域
f = np.fft.fft2(gray)
fshift = np.fft.fftshift(f)
# 创建一个高斯滤波器来过滤掉高频噪声
rows, cols = gray.shape
crow, ccol = rows // 2, cols // 2 # 中心位置
gauss_filter = np.zeros((rows, cols), np.float32)
radius = 20 # 半径越小,过滤越强烈。
for i in range(rows):
for j in range(cols):
distance = (i - crow) ** 2 + (j - ccol) ** 2
gauss_filter[i, j] = np.exp(-distance / (2 * radius ** 2))
# 将高斯滤波器应用于频域图像
filtered_fshift = fshift * gauss_filter
# 使用傅里叶逆变换将图像转换回空间域,并返回结果
filtered_f = np.fft.ifftshift(filtered_fshift)
filtered_image = np.fft.ifft2(filtered_f)
filtered_image = np.abs(filtered_image)
return filtered_image.astype(np.uint8)使用方法:
image = cv2.imread('input_tomato.jpg')
filtered_image = remove_moire(image)
cv2.imshow('Filtered Image', filtered_image)
cv2.waitKey(0)input_Tomato.jpgは、処理する画像ファイル名です。コードを実行すると、モアレが除去された画像が表示されます。
もちろん、上記の例はオープンソースに基づいてモアレを除去する方法と効果を示しています。 valse2023で Hehe Informationのデモンストレーション効果を実現するには、オープンソースのPythonパッケージだけを使用するだけでは十分ではありません。
4. 反射を除去する
反射原理
私も小学生の頃、夜に一人で勉強していましたが、特に最前列に座っていた生徒には、照明の反射で黒板がこのように見えていたかもしれません。

強い光源が滑らかな表面を照らす場合、通常、写真の効果は理想的ではありません。それでもパニックにならないでください。Scanning Almighty King は Hehe Information の主要製品の 1 つです。他の人がどのようにやっているかを学びましょう。
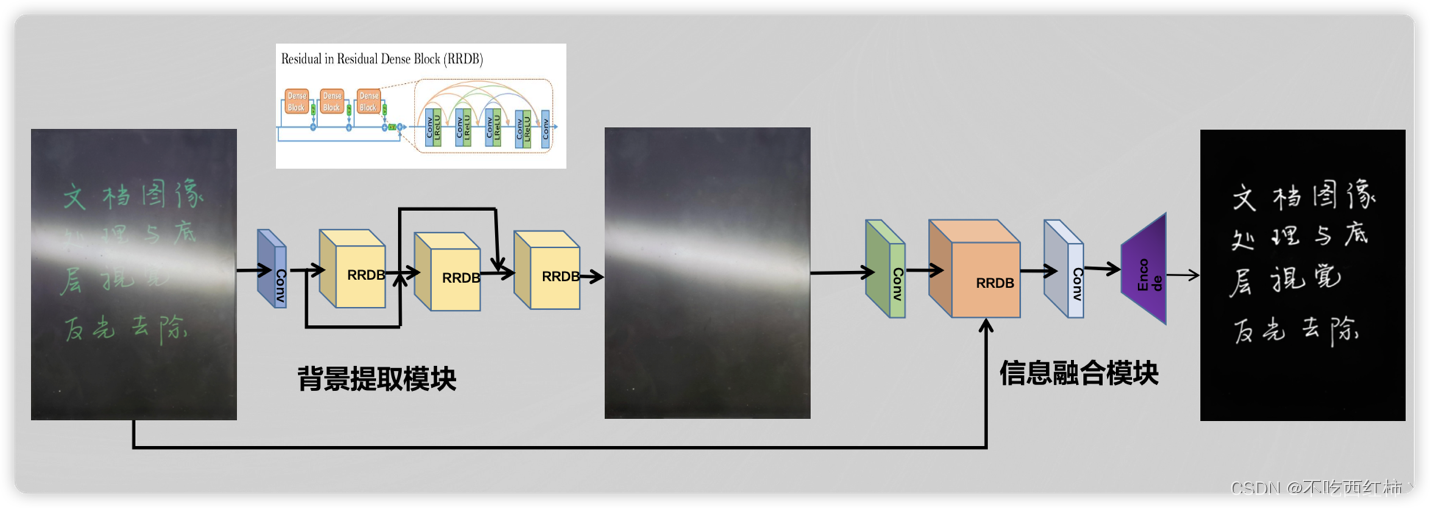
反射防止の原理は、画像強調技術によって反射領域を縮小または除去することであり、主に次の手順が含まれます。
- 画像を読み取り、グレースケール画像に変換します。
- ガウス フィルターを使用して画像を滑らかにし、ノイズを除去します。
- Sobel 演算子を使用してエッジを検出します。
- 検出されたエッジについては、ハフ変換を使用して直線を識別します。
- 各線と水平線の間の角度を計算し、それらを回転して水平に戻します。
- 回転した画像を適切にトリミングして、黒い境界線を除去します。
画像の反射を除去するPythonメソッド
オープンソース方式では、Hehe Information (スキャナー全能王) のような専門的な効果を得ることができません。
import cv2
import numpy as np
def remove_glare(image):
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 平滑处理
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blurred, 50, 200)
# 检测直线
lines = cv2.HoughLines(edges, 1, np.pi / 180, 100)
# 计算角度并旋转回水平方向
angles = []
for line in lines:
rho, theta = line[0]
angle = theta * 180 / np.pi
angles.append(angle)
median_angle = np.median(angles)
rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
rotated = cv2.rotate(rotated, cv2.ROTATE_90_CLOCKWISE)
if median_angle > 0:
rotated = cv2.rotate(rotated, cv2.ROTATE_180)
# 裁剪图像
gray_rotated = cv2.cvtColor(rotated, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray_rotated, 1, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
x,y,w,h = cv2.boundingRect(contours[0])
cropped = rotated[y:y+h,x:x+w]
return cropped上記は、私が独学で発見したオープンソースのPythonメソッドです。効果は平均的で、非ヒーヒーな情報のデモンストレーションは非常に優れています。
5.レイアウト解析と文書復元
5.1物理レイアウトと論理レイアウト
ここで、トマトはレイアウト分析という非常に重要な概念を最初に紹介します。
- 物理的なレイアウトとは、物、人、または組織の場所、形状、サイズなどの実際の存在を指します。
- 論理レイアウトとは、因果関係、論理関係など、これらの物理要素間に確立される関係や接続を指します。
簡単に言えば、物理レイアウトは要素間の位置と属性を強調し、論理レイアウトは要素間の相互作用と接続を強調します。2 つの異なるボードで問題やトピックを分析することで、それらをより完全に理解し、さまざまな角度から解決策を見つけることができます。
5.2レイアウト要素の検査
レイアウト解析を行うには、まずレイアウト要素の検出を行います。エラーテキスト、ウォーターマーク、QRコードなど
5.3文書の復元
最初の 2 つのステップ (物理レイアウト分析、論理レイアウト分析) のバージョンAIアルゴリズム分析とレイアウト要素の識別チェックを通じて、ドキュメントを復元できます。

最終的には右端の画像の内容をWORDまたはEXCEL版に復元することができました。
6. 全体のまとめ
完全な処理プロセスは6 つのステップに分かれています: 画像入力- >ドキュメント抽出- >指除去- >モアレ除去 - >変形補正 - >画像強調

上記の処理プロセスは、アルゴリズムに興味のある友人が自分で勉強することができます。
ドキュメントを救出するために強力な機能を使用したい場合は、アプリケーション マーケットで検索できます: Scan Almighty King。このソフトウェアの基本的な原理は上記の内容です。CS Scan Almighty King は、120 か国で無料の効率化アプリケーションです。App Storeでダウンロードすると、リーダーボードのトップになります。

画像出典:無錫ビジョンと学習若手学者シンポジウム-合和情報スピーチ
Shanghai Hehe Information Technology Co., Ltd. は、業界をリードする人工知能およびビッグデータ技術企業であり、インテリジェントなテキスト認識と商用ビッグデータ、 Cエンドおよび商業ビッグデータの分野におけるコア技術を世界の企業と個人に提供することに尽力しています。Bエンド製品および業界ソリューション: 革新的なデジタルおよびインテリジェント サービスをユーザーに提供します。
もちろん、インテリジェントな文書処理は上記の内容だけでなく、他にも多くの内容があります。VALSE 2023 Wuxi Vision and Learning Young Scholars Symposiumで「言語の認識と理解」に関する 素晴らしいスピーチをしてくださったHehe Information に感謝します。トマトさんはそれを聞いてとても刺激を受けました 以下の写真はカンファレンスでのINTSIG Hehe 情報の共有です。

インテリジェントな文書処理には、セグメントごとに実際には多くの挑戦的で興味深い点があります。一緒に探索しましょう~