ブースティング方法については多くの研究が行われており、多くのアルゴリズムが提案されています。最も代表的なのは AdaBoost アルゴリズム (AdaBoost アルゴリズム) です。
改善方法は、弱学習アルゴリズムから開始し、繰り返し学習して一連の弱識別器 (基本識別器とも呼ばれます) を取得し、これらの弱識別器を組み合わせて強識別器を形成することです。
ブースティング手法については、答える必要がある 2 つの質問があります: 1 つは各ラウンドでトレーニング データの重みまたは確率分布を変更する方法、もう 1 つは弱分類器を結合して強分類器にする方法です。最初の質問に関して、AdaBoost のアプローチは、前のラウンドの弱分類器によって誤分類されたサンプルの重みを増やし、正しく分類されたサンプルの重みを減らすことです。このようにして、正しく分類されなかったデータは、重みが増加するため、次のラウンドで弱分類器からより多くの注目を集めるようになります。したがって、分類問題は一連の弱分類器による「分割統治」です。2番目の弱判別器の組み合わせについては、AdaBoostでは加重多数決方式を採用しています。具体的には、分類誤り率が小さい弱分類器の重みを大きくして投票における役割を大きくし、分類誤り率が大きい弱分類器の重みを小さくして投票における役割を小さくします。 。

アルゴリズムの説明:
N 個の入力データがあり、各データは重みパラメータ wi に対応し、N 個のトレーニング データと N 個の重みパラメータ i∈1-n が存在します。このセットを D と表記します。m は、m 番目のラウンドの反復を指します (m ∈ 1-M)。G は分類子を表します。
(1) では、まずすべての値パラメータ w を同じに設定します。値は 1/N です。セットはD1です。
AdaBoost は基本分類器を繰り返し学習し、m=1,2,...,M の各ラウンドで次の 2 ~ 4 のステップを順番に実行します。
ステップ(2)では、各ラウンドの重み分布Dmの学習データセットで学習して基本識別器を求め、識別器Gm(Xi)で訓練データXiを識別する。
結果 G(xi) = {+1, -1} と、m 回目の分類器 Gm によって分類された実際の結果 yi によると、
一般に、通常得られる損失関数は ですが 、ここでは各 Xi が重み付けされているため、実際の誤差は次のように記録されるはずです。
、ここでは各 Xi が重み付けされているため、実際の誤差は次のように記録されるはずです。
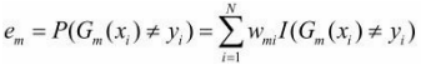
ステップ (3) では、エラーを使用して、現在の分類器がどのような重みを与えるかを計算できます。
その係数を次のように計算します。

ここでの対数は自然対数です。
これにより、ホイールのモデルが作成されます。

ステップ (4) では、モデルの係数 am を使用して、次のラウンド m+1 の各入力データ Xi の重み係数 W(m+1,i) をトラバースして計算できます。


次のラウンドのデータ重みのセットを取得します。
![]()
このようにして、M がラウンドするまで、次のサイクルのステップ (2) にスキップできます。
ステップ(5):
最後に、これらの M ラウンドで取得された各弱分類器に重み am が乗算され、線形結合されて、最終的な統合分類器モデルが得られます。
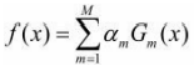
したがって、最終的な分類子は次のようになります。

場合:
例 8.1 表 8.1 に示すトレーニング データがあるとします。弱分類器が x<v または x>v によって生成されると仮定すると、そのしきい値 v により、分類器のトレーニング データ セットでの分類誤り率が最も低くなります。AdaBoost アルゴリズムを使用して、強力な分類器を学習します。

ほどく:
(1) 重量配分の初期化
W1 = 1/10 = 0.1

(2) 最初のラウンドでは、m=1 の場合
1. 重み分布が D1 であるトレーニング データでは、しきい値 v が 2.5 のときに分類誤り率が最も低くなるため、基本的な分類器は次のようになります。
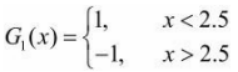
トレーニング データセットの G1(x) のエラー率
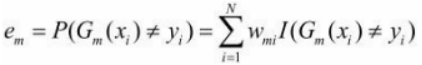
![]()
2. G1(x) の係数を計算します。

3. トレーニング データ Xi の重み分布を更新します。

分類子sign[f 1(x)]には、トレーニング データセット上に誤って分類されたポイントが 3 つあります。
(3) 第 2 ラウンド m=2 の場合:
1. 重み分布 D2 のトレーニング データでは、しきい値 v が 8.5 で、基本分類器が次の場合に分類誤り率が最も低くなります。

2. トレーニング データ セットの G2(x) の誤り率 e2 は 0.2143 です。
3. a2=0.6496を計算します。
4. トレーニング データの重み分布を更新します。

分類器sign[f 2(x)]には、トレーニング データセット上に誤って分類されたポイントが 3 つあります。
(4) 第 3 ラウンド m=3 の場合:
1. 重み分布 D3 のトレーニング データでは、しきい値 v が 5.5 で、基本分類器が次の場合に分類誤り率が最も低くなります。

2. トレーニング サンプル セットの G3(x) の誤り率 e3 は 0.1820 です。
3. a3=0.7514を計算します。
4. トレーニング データの重み分布を更新します。
![]()
それで、以下を取得してください:
![]()
トレーニング データ セット上の分類子sign[f 3(x)] の誤分類された点の数は 0 です。
(5) したがって、最終的な分類子は次のようになります。
![]()