従来のエンタープライズ データ アプリケーションでは、企業は複数のシステムを使用し、データはさまざまなストレージ デバイスに分散されています. データ分析の要件は多くの場合、クロスデータベースであり、レイクまたはウェアハウスに入るデータの分析は、セキュリティ上の問題を引き起こしたり、パフォーマンスに影響を与えたりする可能性があります.ビジネスシステムの。企業は、柔軟で高速で、運用と保守のコストが低いデータ統合方法を必要としているため、データ フェデレーション アーキテクチャが存在します。この記事では、データ フェデレーション アーキテクチャについて紹介します。

— データフェデレーションの概要 —
従来のエンタープライズ データ アプリケーションでは、このようなジレンマがしばしば発生します: 企業は複数のシステムを使用し、データはさまざまなデータ ストアに分散しており、データ分析要件は多くの場合データベース間であり、このような要件を解決するには 2 つの方法があります。1 つは、まずデータ統合 (ETL) を実行して、分析の前にデータ レイクまたはデータ ウェアハウスにデータを統合することです. これは一般的に、要件が比較的明確であり、ストック システムを新しいデータ プラットフォームに移行できるビジネス シナリオに適しています. 他の企業の場合、プラットフォーム構築の段階的な特性により、需要が急速に変化している場合や、さまざまな理由でストック システムを直接移行できない場合があり、ETL に基づくソリューションをレイクに再導入する必要があります。柔軟性が低く、プロセスが複雑であるという欠点があるため、企業は、データ フェデレーション アーキテクチャである、より柔軟で高速なデータ統合方法を必要としています。

データ フェデレーションは、「データ アイランド」の問題を解決し、長い従来の ETL プロセスと高い開発および運用および保守コストの問題を回避します. 柔軟性とリアルタイム パフォーマンスを必要とするデータ収集、または異種データがある場合に適用できます。ソース処理シーン。
- 仮想運用データベース (ODS)
仮想オペレーショナル データ ストレージ (ODS) を通じて、オペレーショナル データ統合ビューを構築し、データの変更が ODS に迅速に反映され、フェデレーション データ ソースは特定の分析要件に従って柔軟に増減できるため、いくつかの軽い要件を満たすことができます。短期間のデータ分析、またはリアルタイムの柔軟なダッシュボード アプリケーション。
- データ ステージング エリアを構築する
データ フェデレーションを使用してデータ ステージング エリアを構築すると、本番システムからデータ ウェアハウスに入る大量のデータのスナップショットをマージして、本番システムでのデータ レプリケーションの干渉を大幅に減らすことができます。データ転送領域でのデータ変更のリアルタイム保存により、完全なデータ変更情報を記録できます。
- データ ウェアハウスの拡張
企業がデータ ウェアハウスを展開した後、問題が発生します。一方では、企業全体が 1 つのデータ ウェアハウスのみを使用する可能性は低く、他方で、企業にはまだ、どのデータ ウェアハウスにも格納されていない大量のデータが残っています。統合された視点を構築する必要があります。データ フェデレーションとフェデレーテッド コンピューティングは、すべてのエンタープライズ データ ウェアハウスと散在するデータの統一された視点を提供し、フォーマットを変換したりデータを移動したりすることなく、データの移動と変換のコストを削減します。
- 異種プラットフォームの移行
異種プラットフォームの移行プロセスでフェデレーテッド コンピューティングを使用すると、データ移行や異種プラットフォームの構文の非互換性などの問題を考慮することなく、移行プロセスをよりスムーズにすることができます. 新しいアプリケーションに影響を与えずにデータ ソースの構成を変更します.
- 異種データ分析
企業は、データ フェデレーションの機能を使用して、クロス構造化データ、非構造化データまたは半構造化データの分析を実現できます。データ フェデレーションとフェデレーテッド コンピューティングは、データ取得やプラットフォームの移行などを最適化する上で大きな価値がありますが、全能ではありません。一方では、データの統合ビューをすばやく実装できるため、多くの企業がデータ ガバナンスを無視しており、その結果、フェデレーション プロセス 一方、データ フェデレーションはビジネス用のデータ アーキテクチャを事前に設計しないため、頻繁に使用される固定形式のデータ要件のパフォーマンスのために、データ レイク、データ ウェアハウスなどを提供することが最善です。したがって、データ ガバナンスや ETL などの手法を完全に放棄することはできず、これらを組み合わせて適用し、企業内のより広範なデータ管理の問題を解決する必要があります。データ フェデレーションは、まだ頻繁に進化しているデータ要件や、アドホック開発シナリオなどの進化するエンタープライズ データ開発要件をより解決します。
— データ フェデレーション アーキテクチャの簡単な分析 —
技術アーキテクチャの観点から、データ フェデレーション テクノロジは、さまざまな既存のデータ ソースにフェデレーテッド コンピューティング エンジンを追加することによって統一されたデータ ビューを提供し、開発者がフェデレーテッド コンピューティング エンジンを通じて異種データを一様にクエリおよび分析することをサポートします。開発者は、データの物理的な場所、データ構造、操作インターフェイス、ストレージ容量などの問題を考慮することなく、1 つのシステムで同種または異種のデータにアクセスして分析できます。データ フェデレーション アーキテクチャは、主に次のようないくつかの重要なアーキテクチャ上の利点を企業データ管理にもたらします。
- 仮想化されたデータ統合: 従来の ETL と比較して、データ フェデレーションは仮想統合のみを実行します。これにより、大量のデータをより迅速かつ低コストで統合し、データ統合の速度を向上させ、いくつかの革新的なデータ サービスを迅速に探索できます。
- 一部の複雑な株式システムでは、企業の既存の投資を保護するために、システムを可能な限り変更せずにクロスデータベースのデータ分析機能を提供できます。
- 開発者がデータを柔軟に検索して使用できるのは便利です。ユーザーはデータ ソースの場所と構造を認識する必要がなく、データ ソース システムを変更する必要がなく、データ処理の柔軟性が向上します。
- 統一されたデータセキュリティ管理と制御を実現できます:コピーではなく仮想ビューを介して統合され、統一されたセキュリティ制御がデータフェデレーションプラットフォームで行われるため、統一されたデータエクスポートセキュリティ制御を実現し、データ漏洩のリスクを軽減できますデータのコピー、特にデータ レイクへのデータのインポートに適していない一部のビジネス システムの分析に適しており、静的データと動的データのセキュリティを確保します。
- 不要なデータ移動の排除: 使用頻度の低いデータについては、データ フェデレーション アーキテクチャが使用されている場合、データのこの部分を毎日データ レイクに統合する必要はなく、実際の分析需要があるときにデータ分析が実行されます。 、不要なデータ移動を減らします。
- アジャイルなデータ サービス プロビジョニングとポータル機能: データ フェデレーション機能を使用すると、企業はそれに基づいてデータ サービス ポータルをさらに開発し、ユーザーがデータをより柔軟に使用できるようにする開発ツールとサービス ツールを提供できます。

データ フェデレーションの技術アーキテクチャ図を上に示します. 重要なポイントは、統合された SQL クエリ エンジンを実装することです. これにより、複数の同種または異種の自律的なデータ ソースをフェデレーションできます. ユーザーは、ストレージを気にすることなく、フェデレーション システムのどこでもデータを自由にクエリできます.データの場所、SQL 言語の種類、または実際のデータ ソース システムのストレージ容量。上の図に示すように、アーキテクチャは、統合されたメタデータ管理、統合されたクエリ処理インターフェイス、統合された開発および運用および保守ツール、および統合されたセキュリティ管理を含む、上記のコア機能を実現するために 4 つの側面の統合を実現する必要があります。
- 統一されたメタデータ管理
メタデータ管理モジュールは、同種および異種の各データ ソースの抽象的な全体像を構築し、統合されたデータ ソース接続管理とメタデータ情報管理を提供する必要があります. 後続のビジネス開発層は、この集中メタデータ管理モジュールを使用して、さまざまなデータ ソースからデータを取得するだけで済みます.データベース. 異なるデータベースごとに異なる接続の詳細を管理する必要のないメタデータ情報。
- データ ソース接続モジュール
データ フェデレーション プラットフォームを通じて、開発者はデータベース インスタンス間で仮想接続を構築し、通常は DBLink に似た SQL 拡張機能を使用して、現在のデータベースでクロスデータベース アクセスを実現できます。このレイヤーは、データ ソースへのアクセスを管理します. 従来のデータ ソースの接続とビッグ データ プラットフォームの接続の両方をサポートします. 構造化データと非構造化データ アクセスの両方をサポートするように設計するのが最適です. DBLink の構文例は次のとおりです. 後続の開発者は、dblink のテーブル名を直接使用して、異なるデータ ソースのデータ テーブルにアクセスしたり、1 つの SQL で複数のテーブルにアクセスしたりすることもできます。
| CREATE DATABASE LINK <link_name> CONNECT TO <jdbc_username> IDENTIFIED BY '<jdbc_password>' USING '<jdbc_URL>' with '<jdbc_driver>';CREATE EXTERNAL TABLE <table_name> (col_dummy string) STORED AS DBLINK WITH DBLINK <link_name> TBLPROPERTIES ('dblink.table.name'=<ref_table_name>); |
- メタ情報管理モジュール
各データベースのメタデータは、ビジネスの運用に伴って継続的に変化するため、データ フェデレーション モジュールは、テーブル フィールドの追加または削除、タイプの変更など、データの変更をタイムリーに取得する必要もあります。したがって、メタデータ管理各データ ソースから取得する必要があるこの機能を提供するモジュールは、メタデータを取得して一元管理し、データ ソースへのクエリを通じて最新のメタデータを取得および維持することで、プラットフォーム間のメタデータの一貫性を確保します。ライフサイクル。
- 統合クエリ処理インターフェース
このモジュールは、データ アナリスト向けのサービス ポータルを提供します。主に、統一された標準 SQL ステートメントを使用したクロスプラットフォーム データ処理と、SQL レビュー、データ アプリケーションなど、企業がそれに基づいて提供できるいくつかのデータ ポータル管理機能が含まれます。複数のデータベースを一元的に処理するため、技術的な要求が比較的高く、複数のデータベースのデータ型への対応やSQL方言の違いに加え、SQLの性能も非常に重要な技術要素です。
- フェデレーテッド クエリ SQL エンジン レイヤー
統一された構文解析レイヤーとして、SQL 命令を解析します。そのコアは、SQL コンパイラ、オプティマイザー、およびトランザクション管理ユニットであり、さまざまな基盤となるプラットフォームや差別化された API に基づくビジネス開発を必要とせずに、開発者により良いデータベース エクスペリエンスを提供することを保証し、オプティマイザーによって生成されます。最終的にコンピューティング エンジン層にプッシュされます。開発者にとって、SQL エンジン層は標準の JDBC/ODBC/REST インターフェイスをサポートする必要があります。
- フェデレーテッド クエリ コンピューティング エンジン レイヤー
一部の SQL 操作では、複数のデータベースのデータを操作し、相関分析を実行する必要があります. したがって、コンピューティング エンジン層は、異なるデータベースからエンジンにデータをロードし、さまざまなデータ操作を実行できる必要があります. これには、コンピューティング エンジンが以下に基づいている必要があります。分散コンピューティングと同時に、各データベースのデータ型の違いを効果的に解決する必要があります。たとえば、異なるデータベースでは、文字列の左右にスペースがある場合、varchar などの型の処理が異なり、trim 関数の動作もわずかに異なります。いくつかのデータベースの/Numericも異なり、これらの型システムの違いは異なります.これは非常に大きな処理の複雑さをもたらし、コンピューティングエンジンのコア機能でもあります. もう 1 つの重要な機能は、パフォーマンスの最適化に関連しています. 複数のリモート データベースが関与するため、従来のデータベースとは異なり、フェデレーテッド コンピューティング エンジンは、データ結果のキャッシュとリモート データベースへのコンピューティング プッシュダウンという 2 つの典型的な SQL 最適化をサポートする必要があります。
- データ結果 キャッシュ層
フェデレーテッド コンピューティング エンジンは、結果セットのクエリ頻度を自動的にカウントします。ホットな結果セットと中間キャッシュ データ セットの場合、基礎となるデータベースの結果セットをフェデレーテッド コンピューティング プラットフォームにキャッシュまたは同期することを選択し、クエリ プロセス中に最適なクエリ パスを選択します。クエリのパフォーマンスを最適化します。

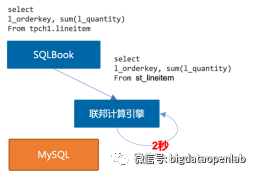
例として、上記の SQL クエリを見てみましょう。MySQL データベースはデータの統計分析が苦手で、1,000 万レコードの lineitem テーブルの集計操作に約 200 秒かかることは誰もが知っています。ただし、フェデレーテッド コンピューティング エンジンを使用すると、コンピューティング エンジンは、複数のクエリ履歴レコードに基づいてテーブルが複数回統計的に分析されていることを検出し、MySQL から st_lineitem にデータを永続化します。 st_lineitem を使用します。分散コンピューティング エンジンは統計分析に優れているため、後続のクエリは連合コンピューティング エンジンを通過し、パフォーマンスも桁違いに向上し、元の MySQL データベースのリソース消費も大幅に削減されます。

- リモートデータベースへのデータプッシュダウン
他のアドホック統計分析シナリオでは、ソース データベースのすべてのデータがフェデレーション コンピューティング エンジンに読み込まれると、大量のデータ IO とネットワーク IO が発生し、パフォーマンスが低下する可能性があります。このタイプの SQL クエリの実行計画の一部をリモート データベースで直接実行できる場合、計算エンジンは、実行計画を策定する際に基になるデータベースの演算子をプッシュ ダウンすることを選択でき、各リモート データベースは基本的な計算を完了します。を実行し、最後に結果をフェデレーテッド コンピューティング レイヤーに集約して統合計算を実行し、クエリのパフォーマンスを最適化します。

簡単な例で言えば、MySQL と Oracle のデータベースから従業員数が特定の値未満の従業員数を見つける必要がある場合、集計とプッシュダウンの最適化がない場合、開発者が統計 SQL を送信した後、フェデレーテッド コンピューティング エンジンは取得する必要があります Oracle と Oracle の両方で、数千万のデータの全量が計算のためにコンピューティング エンジンにロードされます。フェデレーテッド コンピューティング エンジンを開きます)。ただし、コンピューティング エンジンがリモート データベースへのプッシュダウン コンピューティングをサポートしている場合、データの移行はほとんど必要なく、パフォーマンスは数百秒から数十秒に向上します。

- 統合セキュリティ管理
データ フェデレーションは各データベースをビジネス ユーザーに公開するため、データが公開されると、より多くのデータ リスクが公開されるため、データの認証、監査、承認、およびデータの暗号化を保護するために、よりきめ細かいデータ セキュリティ保護機能が必要です。 、感度低下、機密性の分類、およびその他の機能により、保存、送信、および処理中のデータのセキュリティを確保します。
- 統一された権限管理
データフェデレーションセキュリティレイヤーは、関連する権限管理と複数のデータベースの許可された使用のための統一されたユーザーモジュールを提供する必要があります.メタ情報マッピング(外部作成)により、データベーステーブルレベルの権限制御と同じ経験を持つ連合データソース権限制御を提供します. 、およびきめ細かいユーザーレベルの行および列レベルの権限制御機能を提供します。このように、計算プロセス中に機密データが漏洩しないように、コンパイル中に元のテーブル -> ビューに対するクエリ制限が提供されると近似できます。
- SQL 動的監査
SQL 監査とは、ビジネス SQL がプラットフォームに送信されると、ユーザーのディメンションやビジネスを送信した行動に応じて、プラットフォームが機密性の高いクエリ (機密性の高いフィールドに相当するクエリなど) をブロックまたは最適化できることを意味します。またはカスタムの監査ルール 提案に対処します。理解しやすいように、次の表に示すように、いくつかの典型的な DML レビュー ルールと対応するルールの説明を示します。
| 監査ルールの説明 | 監査規則の論理式 |
| Delete と Update を含む DML ステートメントには Where 条件が必要です | (sql.type = 'DELETE' または sql.type = 'UPDATE') および !sql.hasWhere |
| 単一テーブル クエリの ES テーブルと Hyperbase テーブル。条件ステートメントと集計がない場合は、SQL に limit ステートメントを追加するように求める必要があります。 | sql.type = 'select' および sql.joinNum = 0 および (sql.from.tableType = 'es' または sql.from.tableType = 'hyperbase') および sql.where = null および !sql.hasUdaf |
| SQL ステートメントでの UNION ALL の回数が多すぎます | (sql.type = 'select' および sql.unionallNum > 100) または (sql.type = 'insert' および sql.select.unionallNum > 100) |
| SQL ステートメントに JOIN が多すぎます | (sql.type = 'select' および sql.joinNum > 100) または (sql.type = 'insert' および sql.select.joinNum > 100) |
| データ オブジェクトを削除しない | sql.type = 'dropdatabase' または sql.type = 'droptable' |
| 禁止insert overwrite | sql.type = 'insert' および sql.isOverwrite |
| テーブル作成ステートメントを確認し、パーティションの数にバケットの数を掛けると、数が制限を超えることはありません; 数が制限を超えると、調整と最適化を求めるプロンプトが表示されます | sql.type = 'createtable' および sql.partNum * sql.bucketNum > 3 |
| テーブルを作成するときは、テーブル名に文字、数字、アンダースコア以外のデータ形式を使用しないでください | sql.type = 'createtable' および !(sql.tableName ~ '^[a-zA-Z0-9_]+$') |
開業に伴い、大企業はSQL監査に対する需要が比較的大きく、多くの企業は独自のSQLオープンおよび監査プラットフォームを持っており、オープンソースコミュニティにもいくつかの対象を絞ったソリューションがあります。全体的なアーキテクチャは、以下の図のアーキテクチャを参照できます。DSL 言語の最も規則的な定義と、関連する SQL 監査操作 (ブロックや最適化の提案など) を完了するための対応するパーサーが含まれます。

- 機密データの動的な感度低下
データベース テーブルの行および列レベルのアクセス許可とは異なり、機密データの動的な感度低下では、データのコンテンツ セキュリティを確保する必要があります。これは、アクセス許可制御と組み合わせた、よりビジネス レベルのデータ セキュリティ保護です。結果の正確性を確保するために、実際のデータ計算がクエリ計算フェーズで使用され、機密データが漏洩しないように出力中に動的な感度低下のみが実行されることに注意してください。データ脱感作の有効性を確保するために、データ フェデレーション エンジンは、グローバル テーブルとフィールド リネージ グラフを維持する必要があります。これにより、データ リネージに基づいてグローバル センシティブ ルール送信機能が改善され、より機密性の高いデータ テーブルを使用できるようになります。これらのテーブルは、構成可能な自動機密データ識別と感度低下を提供します。
- 運用・保守の一元管理
インフラストラクチャのサポートに加えて、フェデレーテッド コンピューティングの実装には、上位レベルのデータ開発ツールのサポートも必要であり、データ フェデレーションと連携して、データの取得、処理、および価値の実現に至る完全なプロセスを実現します。データ ソース全体のデータ セキュリティもサポートする必要があります。開発管理および運用および保守ツールには、通常、データ開発、管理、および運用および保守ツール プラットフォームが含まれており、企業はフェデレーテッド コンピューティングをより効率的に使用して、内部データ サービス レイヤーとデータ ビジネス バリュー レイヤーを構築できます。
— プレスト与トリノ —
Presto (または PrestoDB) は、あらゆるサイズのデータに対する高速な分析クエリのためにゼロから設計されたオープン ソースの分散 SQL クエリ エンジンです。Hadoop Distributed File System (HDFS)、Amazon S3、Cassandra、MongoDB、HBase などの非リレーショナル データ ソースと、MySQL、PostgreSQL、Amazon Redshift、Microsoft SQL Server、Teradata などのリレーショナル データ ソースの両方をサポートしています。Presto は、データを別の分析システムに移動することなく、データが保存されている場所にクエリを実行できます。クエリの実行は、純粋にメモリベースのアーキテクチャで並行して実行され、ほとんどの結果が数秒で返されます。Presto はもともと、Facebook のデータ ウェアハウスでインタラクティブな分析クエリを実行するためのプロジェクトであり、基盤となるデータ ストレージは HDFS クラスターに基づいています。Presto を構築する前に、Facebook は 2008 年に作成および公開された Apache Hive を使用していました。しかし、ビジネス負荷の増加と対話型分析の必要性により、Hive は対話型クエリに必要な高いパフォーマンスを満たすことができません。2012 年、Facebook Data Infrastructure Group は、ペタバイト規模ですばやく実行できるインタラクティブなクエリ システムである Presto を構築しました。今日、Presto は、Facebook やその他の組織からの多数の貢献により、Hadoop での対話型クエリの一般的な選択肢となっています。Presto の Facebook バージョンは、Presto DB としても知られる企業の内部ニーズを解決することを目的としています。その後、Presto の何人かが、Presto SQL という名前のより一般的な Presto ブランチを作成するために出てきました。バージョン番号は、バージョン 345 のように xxx で除算されます。このオープン ソース バージョンは、より一般的なバージョンでもあります。少し前に、Facebook の Presto とよりよく区別するために、Presto SQL はその名前を Trino プロジェクトの歴史である Trino に変更しました。

Presto と Trino はどちらも、データを保存する機能を持たない単なる分散コンピューティング エンジンです. さらに、コミュニティは多くのデータベース コネクタの適応を行っているため、オープン ソース ソリューションでのデータ フェデレーション クエリにより適したエンジンです. Trino では、ストレージとコンピューティングの分離の中核は、コネクタ ベースのアーキテクチャです。コネクタは、任意のデータ ソースにアクセスするためのインターフェイスを Trino に提供します。図 2 に示すように、各コネクタは、基になるデータ ソースのテーブル ベースの抽象化を提供します。Trino で使用できるデータ型を使用してデータをテーブル、列、および行で表すことができる限り、コネクタを作成し、クエリ エンジンがデータをクエリ処理に使用できます。現在サポートされているコネクタには、Hive、Iceberg、MySQL、PostgreSQL、Oracle、SQL Server、ClickHouse、MongoDB などがあります。

前の章で紹介したように、ユニファイド コンピューティング エンジンはデータ フェデレーション システムの重要なコアであり、柔軟なアドホック クエリを提供し、優れたパフォーマンスを実現する方法も Presto の重要な設計目標です。Presto は主に Coordinator と Worker に分けられ、Coordinator は主に SQL タスクのコンパイルと Worker への計算タスクの送信を担当し、Worker は主にリモート データ ストレージからのデータのプルと対応するデータ計算の実行を担当します。Presto は Java 言語に基づいて開発されているため、JVM の実行効率は基盤となる言語ほどではありません.これによって引き起こされるパフォーマンスの問題を解決するために、Presto もコード生成技術 (コード生成) を使用して生成します。分析パフォーマンスを向上させるために、基盤となるエンジンによって直接実行されるバイトコード。

Presto は、コンピューティングでディスクベースではなくメモリベースのデータ計算を使用します。つまり、データ計算プロセスのデータは主にメモリにキャッシュされます。計算過程で避けられないメモリ拡張の問題により、Worker プロセスがクラッシュする可能性があるため、Presto ではメモリ管理は非常に重要な技術です。Presto は、メモリ全体を 3 つのメモリ プール、つまりシステム プール、予約済みプール、および一般プールに分割します。システム プールは、システムで使用するために予約されています。たとえば、データがマシン間で転送される場合、バッファはメモリ内に維持されます。メモリのこの部分は、システムの名前でマウントされます。デフォルトでは、メモリ領域の 40% がシステム用に予約されています。使用。予約済みプールと一般プールは、クエリ ランタイム メモリの割り当てに使用されます。ほとんどのクエリは一般プールを使用します。予約済みプールのスペースは、マシン上で実行されるクエリが使用する最大スペースに相当し、デフォルトはスペースの 10% です。分散実行計画の連合分析のためのもう 1 つのコア サポート機能. Presto は、計算モデルにパイプライン コンピューティング モデルを採用しています. 実行計画は、複数のステージにコンパイルされます. 各ステージは、データ シャッフルを必要としないコンピューティング タスクのコレクションです. タスク各ステージのタスクを並列化して複数のタスクに分割して並列実行するほか、互いに依存しないステージ同士も並列実行できるため、分散コンピューティングエンジンの同時実行能力をフルに活用してパフォーマンスを向上させることができます。

一般的に言えば、統一されたメタデータ管理とクエリ インターフェイス レベルでは、Presto と Trino の両方が非常に優れたアーキテクチャと明確なコード構造を備えており、それらに基づく二次開発プロジェクトにより適しています。ただし、オープンソース コミュニティはエンタープライズ レベルの管理ニーズに十分な注意を払っていないため、どちらのコミュニティにも、統合されたデータ セキュリティ制御と運用および保守管理ツールをサポートする優れた機能モジュールが不足しています。したがって、完全なデータフェデレーション分析システムを実装する場合、必要な機能を補完および改善するために、二次開発または商用ソフトウェアの導入が必要になります。— まとめ —この記事では、データ フェデレーションのアーキテクチャと事例を紹介します. データ フェデレーションは、「データ アイランド」の問題を解決し、長い従来の ETL プロセスに起因する開発および運用および保守コストの問題を回避します。これは、データ収集に柔軟性とリアルタイムの要件があるシナリオ、または異種データ ソース処理シナリオがあるシナリオに適用できます。