レート リミッタは非常に基本的なネットワーク パケット処理機能であり、さまざまなネットワーク要素デバイスで広く使用されており、トラフィック スケジューリング、ネットワーク セキュリティ、およびその他の分野で重要な役割を果たしています。一般的な速度リミッターは、トークン バケットに基づいて実装されます. トークン バケットの原理はよく知られていますが、実際にはいくつかの課題と共通の問題も発見されています. この記事では、過去 2 年間の速度リミッターの最適化における Bytedance システムおよびテクノロジー エンジニアリング チーム (STE チームと呼ばれる) のいくつかの調査を要約し、読者向けのいくつかの経験と教訓をまとめています。
Token Bucket Rate Limiter の基本原則
ネットワーク パケット処理を作成するすべてのエンジニアは、基本的なトークン バケット速度リミッタを作成したことがあると思います。トークン バケットはわかりやすい説明です.一定量のトークンを保持できるバケットがあることが想像できます.データ パケットがリリースされるたびに,一定量のトークンが消費されます.データ パケットがリリースされるかどうかは、トークン バケットに依存しません。 内のトークンの数。

図 1 トークン バケットの図
たとえば、トークン バケットの制限が PPS (1 秒あたりのパケット数) である場合、トークンがデータ パケットを表すと想定します。次に、PPS を 300K/s に制限する速度リミッターは、毎秒 300K のトークンを生成します。このレート リミッタを通過するデータ パケットはすべてトークンを消費し、トークンが消費されて 0 になると、パケットは破棄されます。
\(P_t \)が到着時間が\(t\)であるパケットを表し 、トークン バケット上のデータ パケットの通過時間が \(t' \)であると仮定する と、この期間中にトークン バケットが生成されます。トークンの数は次のとおりです。
\((t - t') * レート\)
トークン バケット内の残りのトークン バケットの数は\(T \)であり、 \(P_t \)が到着する と 、トークン バケット内のトークンは次のようになります。
\((t - t') * 率 + T\)
トークン バケットには容量があり、トークン バケットの容量を\(バースト\)とすると、上記の式の値がトークン バケットの容量を超える可能性があり、上記で計算された値が この制限を超える場合、トークンの数は\ (バースト \)に等しい 。
このとき、データ パケット \(P_t\) を通過させる必要があるため、1 トークンを消費する必要があるため、トークン バケットのタイムスタンプを \(t' \)に更新し 、それに応じてトークン バケット内のトークンの数を更新します。上の計算に。生成されたトークンの数が消費を超えることが計算によって判明した場合、データ パケットは解放されますが、そうでない場合、データ パケットは破棄される必要があります。
一部の人々は、トークン バケットの容量が制限されている理由、および最大容量が \(Burst\)と名付けられている理由を疑問に思うかもしれ ません。これは実際には、トークン バケットが特定の時間枠でレートが制限値を超えることを実際に許可しているためです。例として 300Kpps 速度リミッターを取り上げます。 \(Burst\) が 300K に等しく、現在のトークン バケットがいっぱいであると仮定すると、この時点で、300K パケットが 100 ミリ秒以内に到達したとしても、トークン バケットはすべてのデータ パケットを解放します (トークン バケット内のトークンの数が十分であるため)、この 100 ミリ秒内で、実際の速度は 300Kpps ではなく 3Mpps です。名前が示すように、実際にはトークン バケットの容量によって、許容されるバースト レートが制限されます。
実際には、トークンバケットは実装が簡単で効率が高いという特徴があり、多くのシナリオでは、速度リミッターは基本的にトークンバケットと同義です。
既存の問題
特定のプロジェクト期間中に、次の 3 つの問題が発生しました。
1. 精度の問題
実際のエンジニアリングでは、時間測定単位は実際にはシステムによって制限されています. たとえば、タイムスタンプはマイクロ秒 (us) で、各計算間の時間差はわずか 1 ~ 2us です. 次に、PPS=300K の速度リミッターが一度に計算され、生成されるトークンは 0.3 であり、整数演算では簡単に無視されます。最終的な結果は、実際の制限は 300K/秒であり、最終的な効果は 250Kpps のトラフィックのみが許可されるということです。精度が低すぎて、効果が理想的ではありません。
このソリューションも比較的単純で、データ パケットによって消費されるトークンの量は 1 ではなく 1000 になる可能性があります。このように、1us であっても、トークン バケットによって生成されるトークンの数は 0.3 ではなく 300 であり、精度が保証されます。しかし、このとき、トークンの数が 1000 倍に増えたため、新しい問題が発生し、トークン バケットの深さが 32 ビットをオーバーフローするかどうかを考慮する必要があります。オーバーフローすると、他の奇妙な問題が発生します。
2. カスケード補償問題

図 2 速度リミッタのカスケード補償
複数の速度リミッターがカスケードされている場合、補償トークンが必要であることが実際にわかっています。たとえば、速度リミッター A の場合、このパケットは解放され、A のトークンを消費します。レート リミッタ B の場合、B にトークンがないため、このパケットは破棄されます。この時点で、パケットは失われます。すると、この時点で A のトークンは無駄に消費されます。つまり、トークンが消費され、パケットは失われます。正確な速度制限効果を得るには、速度リミッター A のトークンを補正する必要があります。図 2 に示すように。
カスケード補償は、複数の速度リミッターを相互に結合させ、コードの記述がより面倒になります。速度リミッター A と速度リミッター B の速度制限値が近く、両方にパケット損失がある場合、カスケード補償の欠如が精度に深刻な影響を与えることが実際にわかりました。ただし、速度制限値が離れている場合、精度への影響はそれほど大きくありません。
3. TCP はパケット損失の影響を受けやすい
トークン バケットにキャッシュがないため、レートが制限値を超えると、パケット ロスが発生します。TCP プロトコルはパケット損失に非常に敏感で、パケット損失が発生すると、TCP はより積極的にレートを調整します。トークン バケットの機能により、TCP トラフィックに適用されると 100Mbps に制限されることがよくあります.実際には、一定のパケット損失により TCP が送信ウィンドウを継続的に縮小するため、最大で 80Mbps までしか実行できません.
vSwitch を使用する場合、一般的な仮想ネットワーク カードでは TSO (TCP Segmentation Offload) の最適化が有効になっているため、BPS (Bits Per Second) のレート制限が TCP で特に大きく失われます。ホスト パケットは非常に大きく、1 つのパケットは 64K バイトになる場合があります.このような大きなケースでは、意図的にいくつかのパケットを失うと、TCP レートへの影響が非常に明白になります.
最初の改善: ポート レンディング バックプレッシャー スピード リミッター
実際には、カスケード補償フィードバックの問題は存在しますが、それほど顕著ではないことがわかりました.その理由は、一般的なカスケード速度リミッターの速度制限値が非常に異なるためです.たとえば、単一のネットワークカードの速度と機械全体の速度には一般的に大きなギャップがあり、精度の問題が発生するのは簡単ではありません。最も深刻な問題は、TCP パケット損失の影響を受けやすいため、レート制限された帯域幅に到達できず、ユーザー エクスペリエンスに影響することです。図 3 に示すように、TCP RTT の増加に伴い、実際に達成可能な帯域幅は明らかに減少します。
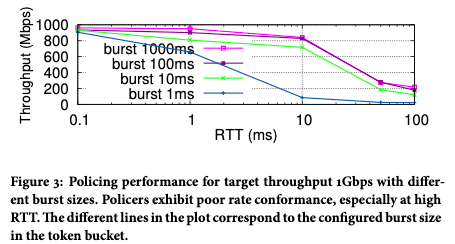
図 3 トラフィックが 1Gbps レート リミッタを通過した後、実際に取得されるレート
バックプレッシャは、TCP がパケット損失に敏感であるという問題の改善です。最初にデザインしたときは、実は特定のシーンを狙っていました。仮想マシンの仮想ネットワーク カードの速度が制限されています。また、私たちのレート リミッターは、たまたま、各ネットワーク カードに特定のレート リミッターがあることです。
各仮想ネットワーク カードには複数のキューがあり、vSwitch はこれらのキューを継続的にポーリングして、送信するデータ パケットを取得します。これらのキューは、基本的にパケットのバッファです。実際、バック プレッシャーは、これらのキューのポーリングを停止または遅延させ、データ パケットをキューに蓄積させ、ゲスト カーネルにプレッシャーをフィードバックするという目的を達成することです。これにより、ゲスト カーネルの TCP スタックが輻輳を感知して送信リズムを調整します。
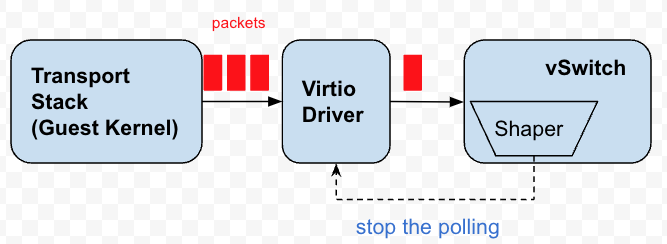
図4 背圧速度リミッタ
背圧速度リミッターを設計したとき、最終的な実装に影響を与える制限がありました。
仮想マシンの仮想ネットワーク カードは Peek 機能を提供しません。つまり、vSwitch はデータ パケットを Peek するだけで、実際にデータ パケットをキューから取り出しません。この制限により、「借りる」という考え方が採用されました。両方ともポーリングを開始する許可時点を設定します. 現在の時間が許可時点を超えると, トークンが十分かどうかに関係なく, キュー内のすべてのデータ パケットが一度に送信されます.問題ありませんが、トークンが十分でない場合は、将来からトークンを借用することを検討し、逆に将来のタイムスタンプを計算すると、このタイムスタンプの前に、vSwitch は仮想ネットワーク カードのポーリングを停止します。
ローン方式は、仮想マシン キューからデータ パケットをコピーすることを避けるために、最初はパフォーマンスを考慮してのみ提案されましたが、トークンが十分ではなく、破棄する必要があることがわかりました。捨てたくないので、単純にトークンを未来に送ります。
この設計を今振り返ってみると、Peek と比較して、実際には長所と短所があります。
1) 毎回借りられるトークンの量は制御不能です。これは、公平性の問題につながる可能性があります。エレファントストリームはローン資格を取得し続けますが、小さなストリームは餓死する傾向があります. スピードリミッターの競争では、一方が有利になると、支配的な当事者が有利になり続けます.
2) ピークよりもオーバーヘッドが少ない単純なタイムスタンプ比較。データ パケットを覗くことができれば、ローン メカニズムはなく、ポーリングを停止する可能性はありません. 代わりに、仮想キューに移動して毎回チェックしますが、オーバーヘッドは少し高くなります.
3) 逆に、ピーク機能がある場合は、最初にキュー内のデータ パケットのバックログを確認し、キューが一定量のデータ パケットを蓄積するのを待ってから、次のバッチを送信するためのタイムスタンプを計算することもできます。 data packet. ポーリングを停止します。これは、バッチを増やしてパフォーマンスを向上させるのに適しています。
バックプレッシャ レート リミッタは仮想マシンのネットワーク カード キューをバックプレッシャするため、仮想マシンの送信データ パケットのみを制限できますが、仮想マシンの受信方向のトラフィックを制限することはできません。これは、物理ネットワーク カードのデータ パケットをバックプレッシャできないためです. 物理ネットワーク カードのデータ パケットは、異なる仮想ネットワーク カードに送信される可能性があります. 各ネットワーク カードの速度制限値は異なります. 正確な速度を計算することはできません時点. 時点より前にパケットをポーリングする必要はありません。さらに、物理ネットワーク カードのキューがいっぱいになると、パケットのみが失われ、仮想マシン ネットワーク カードのキューがいっぱいになると、TCP プロトコル スタックにバックプレッシャがかかる可能性があり、両者の影響は異なります。
したがって、インバウンド トラフィックの制限に関しては、タイムスタンプを許可するという考えを継続します。現在の時間が許容時間を超えた場合はすべてのパケットが解放され、そうでない場合はすべてのパケットが破棄されます。
2 番目の改善: カルーセル速度リミッター
Carousel speed limiter は、Google が SIGCOMM 17' に関する論文で提案した速度制限アルゴリズム [2] です. 実際、この考え方も非常に単純で、データ パケットごとに送信されたタイムスタンプを計算するというものです. 現在のタイムスタンプがタイムスタンプが発行されると、タイム ラウンドでキャッシュされます。つまり、パケット損失の代わりに、データ パケットが遅延されて送信されます。
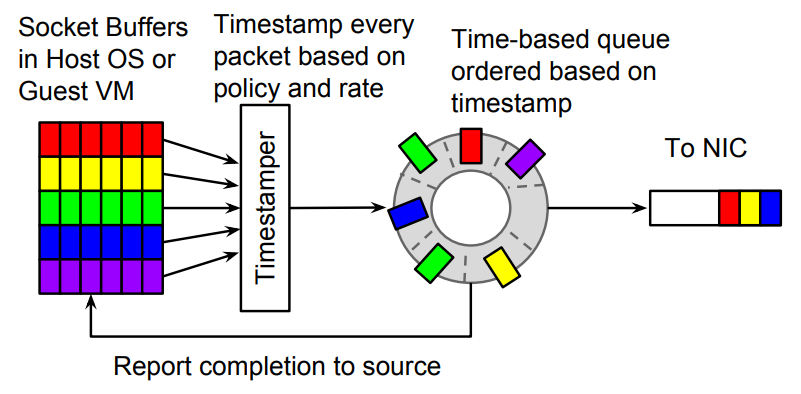
図 5 カルーセル速度リミッター
このアルゴリズムの基本原理に基づいて、OVS-DPDK に同様の速度リミッターを実装しました.アルゴリズムのパラメーターを決定するプロセスには多くの詳細があります.たとえば、ポーリングの時間粒度は 1us ですか、10us ですか? 実際に使用されているスピードリミッターの速度域は?300Kppsですか、それとも3Mppsですか?これらはアルゴリズムのパラメータ設定を直接決定し、多くの詳細については説明しません。
Carousel の最大の利点の 1 つは、キャッシュの導入です。タイム ホイールの本質はキャッシュであり、TCP トラフィックに明らかな利点がありますが、同時に、タイム ホイールは仮想マシンのインバウンド トラフィックをバックプレッシャできないという問題も解決し、すべてのトラフィックを統合することができます。ワンタイムホイール。3 番目の利点は、少し予想外かもしれませんが、データ パケットが失われるのではなく遅延するため、カスケード補償の必要性がある程度なくなることです。パケット損失がない場合、カスケード補償は必要ありません。
以下の図は、iperf ツールを使用して仮想マシンのインおよびアウト方向を 100 秒間テストし、10Gbps の速度制限の下で古いバック プレッシャー スピード リミッターと新しいカルーセル スピード リミッターを使用した場合の比較効果を示しています。
横軸は時間 (秒)、縦軸はスループット (Gbps) です。つまり、1 秒あたりの iperf によって報告される現在のスループット パフォーマンスです。受信トラフィックが 500Mbps 増加したことがわかります。10Gbpsにかなり近い。
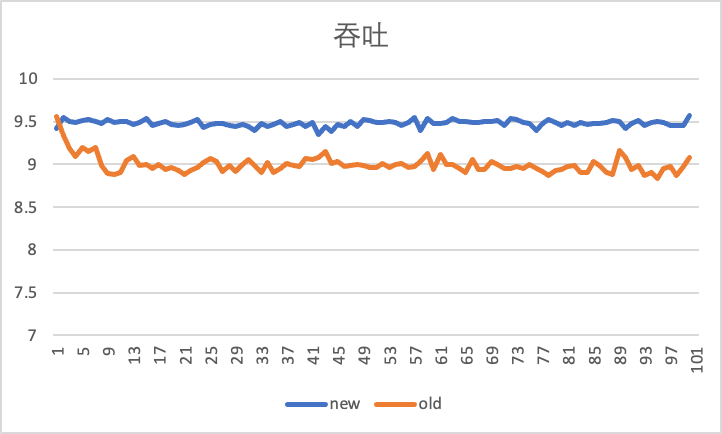
アウトバウンド スループット パフォーマンスでは、カルーセル速度リミッターがより安定していることがわかります。

これらの改善の原因は、TCP トラフィックに対するキャッシュの平滑化効果にあります。
今後の改善点とまとめ
1.さらなる改善
貸与機構の背圧速度制限に基づき、速度制限値が大きい場合、貸与による過送信データパケットが全体の速度制限ジッターに与える影響は限定的です。たとえば、速度制限が 1G の場合、特定の瞬間に少数のパケットがオーバー送信された場合、速度制限のジッタへの影響は比較的小さくなります。ただし、速度制限値が小さい場合 (5Mbps など)、複数のデータ パケットをオーバー送信した場合の影響は比較的大きくなります。このとき、仮想マシンのポートのポーリングをタイムスタンプで制御することで ON-OFF 効果が生まれ、仮想マシンから見るとアウトバウンド トラフィックのパス上にゲートが開いているように見えます。しばらくして、しばらく閉じます。
ただし、これは仮想マシンの送信側から見たものに過ぎず、受信側のタイム ホイールの調整により、レートは比較的安定します。送信側で比較的安定したエクスペリエンスを実現するには、バック プレッシャの効果を改善して、過剰送信の可能性を減らす必要があります。
また、ポート粒度に基づく速度制限は、制御ポートをポーリングすることで実現できますが、ポートよりも粒度が小さい速度制限については、バックプレッシャーを実現することは容易ではありません。よりきめの細かいバック プレッシャーを実現するために、Google は virtio の機能を使用して、カルーセル上で OOO 完了 (アウト オブ オーダー完了) をサポートし、PicNIC の論文 [3] でよりきめの細かいバック プレッシャーを実現しました。最適化されたスピードリミッターはアイデアを提供します。
2.アクティブな速度制限(ECNまたはTCPウィンドウオプションの変更に基づく)
vSwitch で TCP ウィンドウを追跡および変更し、小さなウィンドウをネゴシエートして、より安定した TCP スループットを得ることができます。同時に、仮想マシンの内部に直接的または間接的にフィードバックされるか、vSwitch のポーリング頻度に影響を与える vSwitch で ECN マークも感知できます。
3. ロック機構の改良
上記の速度リミッターの改善はすべてネットワークを対象としています. システムにマルチコアが存在するため, 速度リミッターの粒度は多くの場合スレッドにまたがります. ロックフリーの速度リミッターを設計する方法も検討する価値のある方向性です. .
4. まとめ
現在のアルゴリズムが実際のシーンにますます関連するようになっていることは、速度リミッターの改善履歴からもわかります。アルゴリズムはもはや単なる独立したコンポーネントではなく、実際のオペレーティング システムや製品機能とますます密接に結びついています。
参考文献
[1] eBPF でのトラフィック ポリシング: トークン バケット アルゴリズムの適用
[2] カルーセル: エンド ホストでのスケーラブルなトラフィック シェーピング、SIGCOMM 2017。
[3] PicNIC: 予測可能な仮想化 NIC、SIGCOMM 2019