この記事は、シンガポール国立大学の馬天白教授のチームとバイトダンスのインフラストラクチャ・コンピューティング・ストリーミング・コンピューティング・チームがトップ国際データベースおよびデータ管理カンファレンスVLDBで共同発表した論文「StreamOps: ストリーミング・サービスのためのクラウドネイティブ・ランタイム管理」を解釈しています。 2023. 「ByteDance」は、何万もの Flink ストリーミング タスク管理の実践に基づいて ByteDance によって抽出されたストリーミング タスクのランタイム管理および制御ソリューションを導入しており、これにより、実行中のトラフィックや動作環境の変化によって露出されるさまざまなタイプの操作が効果的に解決されます。ストリーミング ジョブ: NoOps ベースのコア機能を促進するには、管理するために手動介入が必要になる場合がある問題が必要です。超大規模ストリーミングジョブの管理をサポートし、自動拡張・縮小、低速ノードの自動移行、遅延・障害のインテリジェント診断などの機能を提供し、プラグインによる機能拡張も可能です。StreamOps は Bytedance 内で大規模に検証されており、毎日コンピューティング リソースを 15% 節約し、遅いノードを 1 日に約 1,000 回効果的に移行し、手動オンコールを 75% 削減し、超高速ストリーミング タスクのメンテナンス コストを大幅に削減します。 - 大規模なシナリオ。

論文リンク: https://www.vldb.org/pvldb/vol16/p3501-mao.pdf。
導入
近年、ストリームコンピューティングは大規模なリアルタイムデータ処理や意思決定に広く使用されています。ByteDance は、ストリーミング コンピューティング処理エンジンとして Flink を選択しており、毎日数万の Flink ジョブが内部クラスターで実行され、ピーク時のトラフィックは 1 秒あたり 90 億個のデータに達します。ストリーミング ジョブは数日以上実行されることが多いため、ワークロードと動作環境は時間の経過とともに変化する傾向があります。Byte 内のストリーミング処理のピーク期とトラフ期のトラフィックの差は平均 4 ~ 5 倍であり、根底にあるリソースの混雑やマシン モデルの違いなどの問題に常に直面しています。このような変更は、データのバックログやさまざまな障害などのさまざまな実行時の問題を引き起こし、その結果、頻繁な手動介入が必要になったり、無駄が生じる過剰なリソース予約が必要になったりします。ストリーム コンピューティングの急速な成長に伴い、これらのランタイムの問題を自動的に解決するためのランタイム管理および制御システムが緊急に必要になっています。ただし、ByteDance のようなシナリオでストリーミング ジョブのランタイム管理サービスを設計するのは困難です。サービスは、クラスター レベルですべてのストリーミング ジョブを均一に管理し、効果的な管理および制御戦略を使用できるほど十分にスケーラブルである必要があります。さまざまなランタイムの問題を解決するには、また、新しい実行時の問題に対する新しい管理および制御戦略を開発するには、優れたスケーラビリティも必要です。
上記の課題に対応して、この記事では、大規模なシナリオにおけるユーザー ストリーミング タスクのメンテナンス コストを効果的に削減できる、クラウド ネイティブに基づくストリーミング タスク ランタイム管理および制御システム StreamOps を提案します。StreamOps は、ストリーミング ジョブとは独立して実行され、大規模なストリーミング ジョブを均一に管理する軽量でスケーラブルな管理および制御システムとして設計されています。新しい管理および制御戦略の迅速な構築をサポートするために、管理および制御戦略プログラミング パラダイムの層を抽象化します。Byte 内部の長期実践経験に基づいて、ストリーミング タスクの自動拡張および縮小、低速ノードの自動移行、および遅延/障害のインテリジェントな診断 3 つのコア管理および制御戦略。この記事では、StreamOps の設計時に行った設計上の決定と関連する経験を紹介し、StreamOps の効果を検証するために社内の実稼働環境で実験を実施します。
SteamOpsの概要
上の図は、StreamOps の全体的なアーキテクチャとワークフローを示しています。主に次の 3 つのコンポーネントが含まれています。
-
コントロール プレーン サービス: クラスター レベルのストリーミング ジョブを管理するための、水平方向にスケーラブルなステートレス サービスです。ストリーミング ジョブとは独立してデプロイされ、コントロール プレーンとストリーミング コンピューティング エンジンを分離して、柔軟性とスケーラビリティを向上させます。
-
グローバル ストレージ: ジョブ インジケーター、ログ、および管理および制御ポリシーの決定に必要なその他のデータと、コントロール プレーン サービス自体のステータス データを保存します。
-
ランタイム管理トリガー: 各ストリーミング ジョブには、コントロール プレーン サービスにリクエストを送信して管理操作をトリガーするためのランタイム管理トリガーが装備されています。リクエストは、定期的に、特定の条件が満たされたときに、または手動でトリガーできます。
全体的なワークフローは次のとおりです。
-
単一のストリーミング ジョブは、トリガー ポリシーに基づいて、コントロール プレーン サービスに対する管理および制御操作をトリガーします。
-
リクエストを受信した後、コントロール プレーン サービスは、ジョブ インジケーターや管理および制御ポリシー自体のステータスなどのデータをグローバル ストレージから取得し、管理および制御ポリシーを決定します。
-
管理および制御戦略が決定を下した後、ストリーミング ジョブの実行中に構成の変更を開始するか、ユーザーにアラーム リマインダーを発行します。
コントロールプレーンサービス
StreamOps は、ポリシーとメカニズムの分離の設計原則を採用し、制御プロセス全体を制御戦略と制御メカニズムの 2 つの部分に分割します。ガバナンス戦略は責任あるモデルの決定に焦点を当てており、実装は発見、診断、解決の 3 つのステップを抽象化した共通のプログラミング パラダイムによって定義されます。管理および制御メカニズムは、外部システムとの対話、インデックス取得の実行、および決定に基づく制御変更操作の実行を担当します。一般的なインデックス取得および制御変更メカニズムはカプセル化されており、再利用できます。以上の対策により、新たな管理・制御戦略を低コストで拡張・導入することが可能となります。
制御戦略

上図は、管理および制御戦略の意思決定の全体的なプロセスを示しています。管理および制御戦略は、ストリーミング ジョブの実行時に最初にインジケーターと構成情報をインジケーター コレクターから取得し、次に検出の 3 段階のプロセスに従います。診断、インジケーターと構成情報を取得するための解決、決定が行われ、最終的に実行のためにストリーミング ジョブ構成チェンジャーに渡されます。一般的な実行メカニズムには、拡張と縮小、ノードの移行、またはユーザーが手動で処理できるようにする単純なアラームの送信などが含まれます。
制御機構
1. 指標の収集
計算エンジン自体のインジケーターに加えて、ストリーミング ジョブの管理と制御によく使用されるインジケーター情報には、MQ 側のデータ ソース関連のインジケーターと K8s 側のリソース関連のインジケーターも含まれており、ByteDance は 3 種類のインジケーターをすべて内部的にキャッシュします。中央の時系列データベースを通じて。StreamOps は内部時系列データベース システムに接続されており、管理および制御戦略は必要に応じてさまざまな種類の指標に対して豊富なクエリ操作を実行できます。
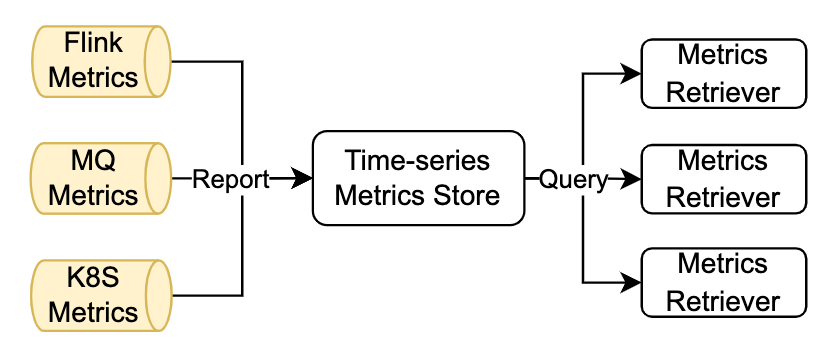
2. ストリーミング ジョブの実行時の構成の変更
ジョブの構成変更は再起動することで完了できますが、これはユーザーへの影響が大きくなります。変更に関しては、まず API を使用してジョブのホット アップデートを高速化します。さらに、分析の結果、このタイプの操作には最適化の余地がたくさんあることがわかりました。まず、リソースの変更を伴う操作では大部分の時間がかかります。リソースの適用に費やされます。ステータスの小さいジョブの場合、最高で 70% に達することがあります。一連のリソース事前適用メカニズムが実装され、StreamOps に接続されます。大規模な状態のタスクでは、状態の回復にほとんどの時間が費やされますが、RocksDB の DB マージとプルーニングのメカニズムが最適化され、全体の状態回復時間が 10 倍高速化されました。全体的な最適化の後、全体的な停止時間は完全な再起動に必要な数分から数秒に短縮され、ユーザーの影響をほとんど受けなくなりました。
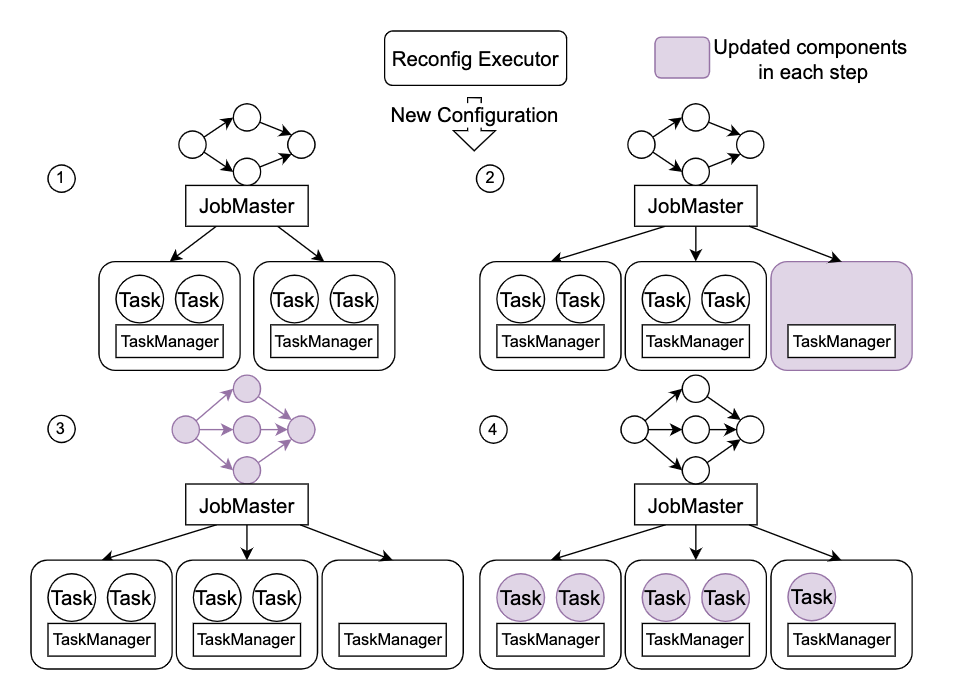
中核となる管理および制御戦略の実施
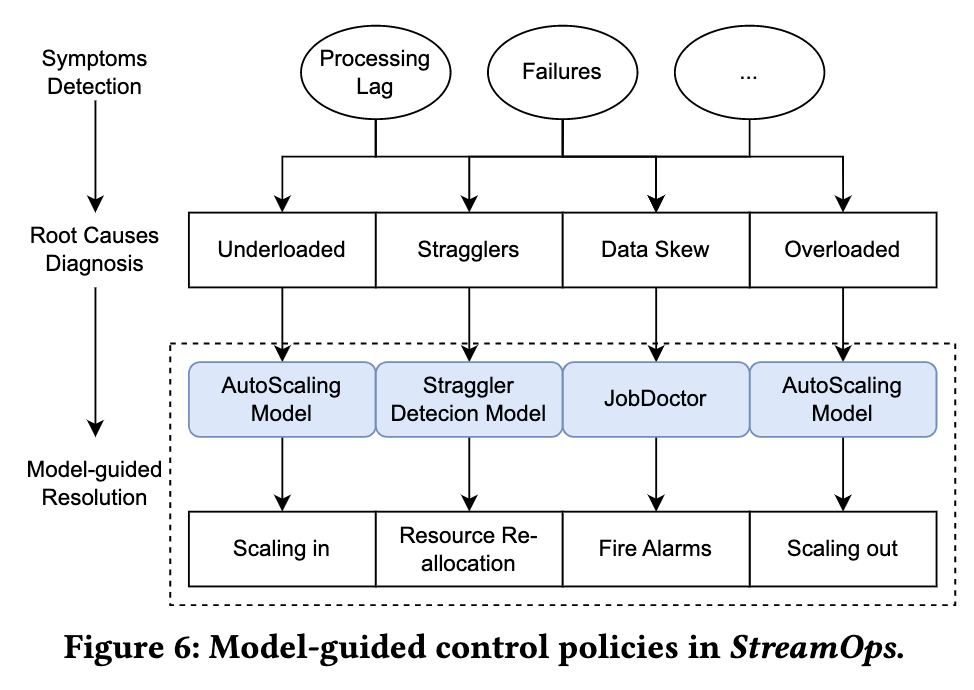
StreamOps のコア管理および制御戦略の目標は次のとおりです: 1. ジョブの処理が受信データ速度に確実に対応し、メッセージ バックログとランタイム例外の問題を解決すること; 2. クラスター リソースの使用率を向上させ、コストを削減すること。Byte の実稼働環境では、メッセージ バックログには 2 つの主な理由があることがわかりました: 全体的なリソースの不足と負荷の不均衡です。負荷の不均衡は、実行効率とデータ スキューが遅いマシン (遅いノード) に細分化されます。実行時例外にはさまざまな原因があり、多くの場合、計算エンジン内からは解決できません。したがって、StreamOps は、上の図に示すように、3 つの主要な管理および制御戦略を実装します。
-
自動拡大・縮小:ジョブ全体のリソース割り当て不足・過剰問題を解決します。
-
遅いノードの自動移行: 実行効率が遅いマシンによって引き起こされるメッセージ バックログを解決します。
-
インテリジェントな診断: データ スキューやランタイム異常など、コンピューティング エンジン内からは解決できないことが多い問題に対して診断と提案を提供します。
自動伸縮

DS2[1]モデルをベースに、バイトに適した自動伸縮モデルを拡張・実装しました 全体的な意思決定プロセスは上記の通りです。このモデルでは、ジョブのメッセージバックログやオペレータの負荷状況などを総合的に考慮して拡張・縮小操作が必要かどうかを判断し、拡張・縮小の際には過去の期間のワークロード状況も考慮し、深刻なデータスキューやジョブ実行などの異常事態を排除します。エラーを回避するための失敗。処理プロセス中に、ジョブのホット アップデート、RocksDB DB マージ、クリッピング アクセラレーションなどのメカニズムと組み合わせることで、ダウンタイムがほぼゼロの高速リカバリを実現できます。
遅いノードの自動移行

環境内で実行されているマシンの数が少ないことが原因でノードが遅いという問題については、検出モデルはアルゴリズムを通じて定期的な状況を排除し、ジョブ トポロジ内でマシンの集約率が高い異常に遅いノードを選別し、移行して復元することができます。処理プロセス中に、ノードのブロッキングやリソースの事前適用などの最適化手法が使用され、処理をより速く、より安定させます。
インテリジェントな診断
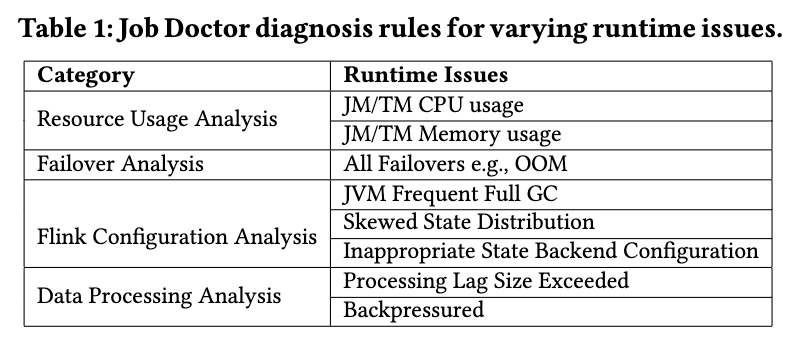
同時に、StreamOps はインテリジェントな診断 (Job Doctor) システムを実装し、ユーザーと運用保守担当者が分析して使用できる視覚化プラットフォームを提供します。主に、リソース使用量の分析と提案、実行例外収集の分析と提案、Flink 構成の分析と提案、ボトルネック処理の分析と提案の 4 種類の診断ルールを扱います。ユーザーは独立した検出を実行でき、システムも定期的な検査を実行し、ユーザーに警告を送信し、対応する処理の提案を提供します。
実験結果
コントロールプレーンの全体的な効果
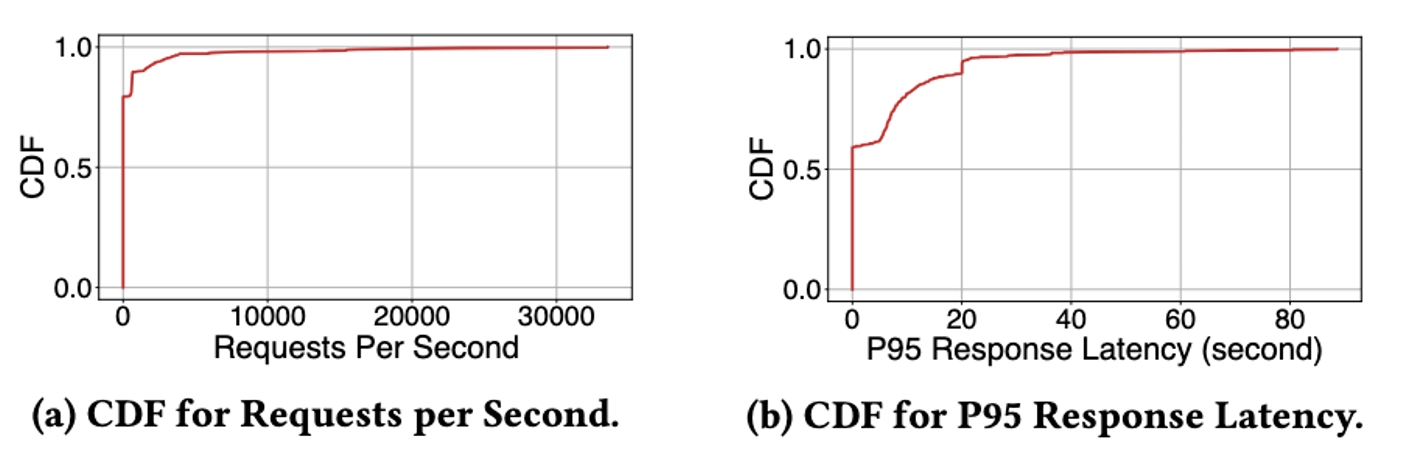
まず、クラスター レベルでの大規模な運用管理とジョブの制御機能に対する StreamOps の評価を示します。ストレス テストのために実稼働環境に 50 ノードで構成される StreamOps クラスターをデプロイし、各ノードは 16 コア CPU と 32 GB のメモリで構成されました。以下の図からわかるように、StreamOps は 1 秒あたり最大 33,000 リクエストで 60 秒以内に P95 の応答時間を達成でき、システムが優れたスケーラビリティを備えていることを示しています。
自動伸縮効果
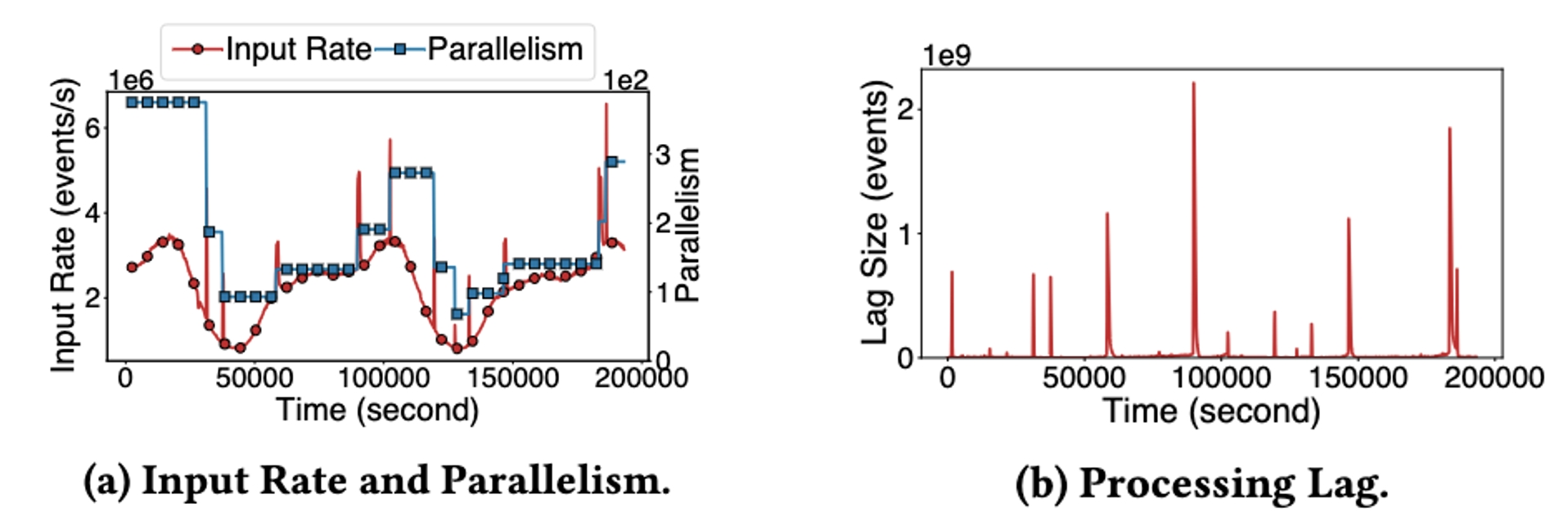
トラフィック量の多い本番ジョブにおける自動拡張・自動縮小の実行効果を示しています。図aはジョブ流入率によるジョブ並列度の変化、図bは期間中のメッセージバックログの変化を示しています。StreamOps はジョブの流入率に応じて効果的にスケールアップおよびスケールダウンでき、CPU リソースの少なくとも 60% を節約できることがわかります。もちろん、拡張と縮小自体がメッセージの一時的な蓄積を引き起こすこともわかります。そのため、各ジョブはより詳細な方法でパラメータを調整して、拡張と縮小のコストと自動拡張と自動拡張の感度を比較検討できます。収縮。
遅いノードの自動移行の影響
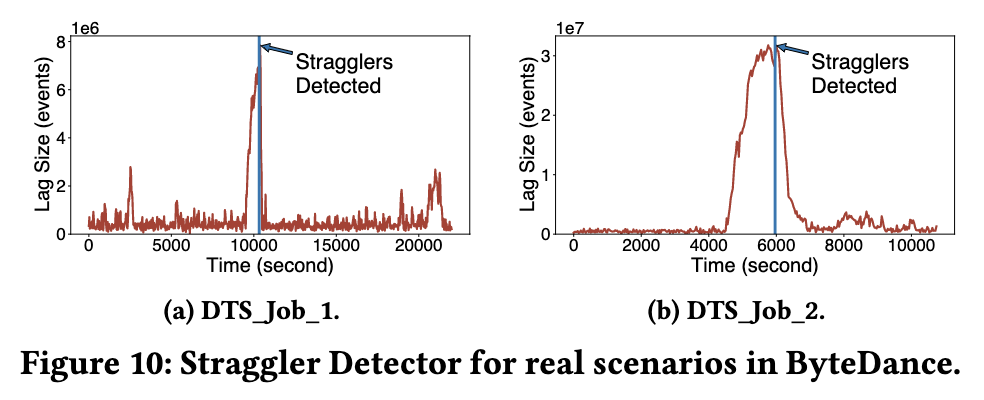
以下の図は、低速ノードの影響を受け、メッセージ バックログが発生した Byte 内の 2 つの代表的な運用ジョブを示しています。StreamOps は低速ノードを正確に特定して自動的に移行することができ、低速ノードによって引き起こされるメッセージ バックログの問題を効果的に解決できます。
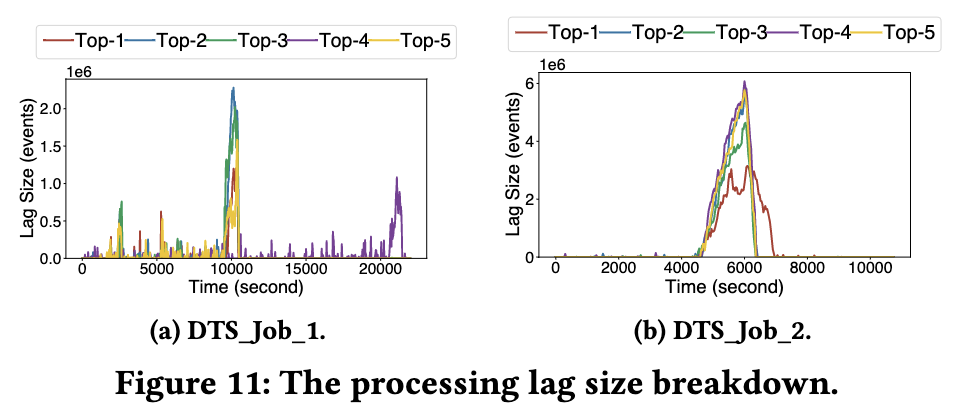
次の図は、上記 2 つのジョブの上位 5 つのバックログのパーティションと対応するバックログをさらに示しています。メッセージ バックログの 80% 以上が上位 5 つのパーティションに集中していることがわかります。パーティションが遅いノードで実行されている StreamOps これらの遅いノードが正確に特定され、移行後にバックログが実際に解決されました。
インテリジェントな診断効果
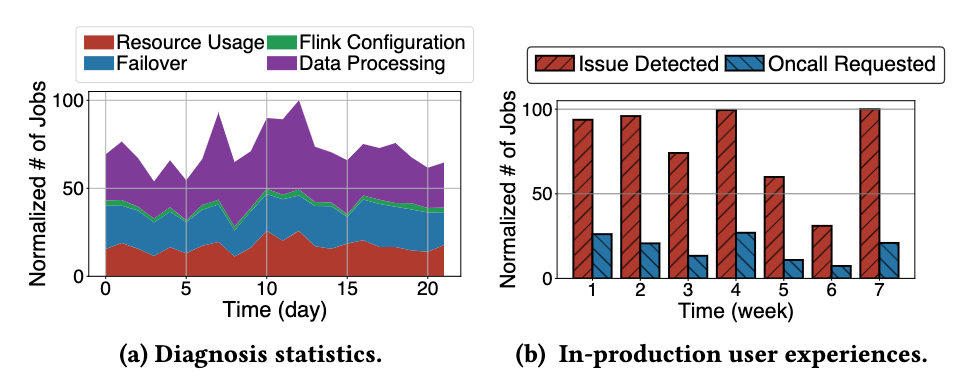
図 a は、一定期間にわたって StreamOps を使用して毎日診断に成功したさまざまな種類のランタイム問題の数を示しています。図 b は、1 週間以内に毎日診断に成功した問題の数と、診断の使用後に手動のオンコール処理を入力し続けた問題の数の比較を示しています。これまでは、実行時の問題が発生した場合、ユーザーは通常、手動オンコールを直接開始していましたが、インテリジェントな診断にアクセスすることで、手動オンコールの数が効果的に減少していることがわかります。
要約する
この記事では、クラウド ネイティブに基づくストリーミング タスク ランタイム管理および制御システムである StreamOps を提案します。大規模なストリーミングジョブを効率的かつ均一に管理できるよう、ストリーミングジョブとは独立した独立したステートレスサービスとして実装しています。全体的な管理および制御プロセスを 2 つの部分、つまり戦略と外部システムとの対話のための一般的なメカニズムに分割し、戦略部分を発見、診断、解決策の 3 段階のユニバーサル プログラミング パラダイムに抽象化することが提案されています。制御を低コストで迅速に実装できます。自動拡張と縮小、低速ノードの自動移行、インテリジェントな遅延/障害診断という 3 つの主要な管理および制御戦略を実装しており、運用実践におけるメッセージ バックログ、ランタイム障害、リソースの浪費の問題点を解決し、検証されています。 ByteDance の社内制作環境での効率性と有効性。
引用
[1] https://www.usenix.org/conference/osdi18/presentation/kalavri
著者情報:
ByteDance インフラストラクチャ エンジニアの Chen Zhanghao 氏は次のように述べています。ストリーミング コンピューティングの専門家、Apache Flink コントリビューター。イリノイ大学アーバナシャンペーン校で修士号を取得し、卒業後はストリームコンピューティングに関する研究開発に従事。
Zhang Yifan、ByteDance インフラストラクチャ エンジニア。杭州電子科学技術大学で修士号を取得したストリーミング コンピューティングの専門家で、かつては NetEase に勤務していましたが、現在は ByteDance でストリーミング コンピューティング システムとサービスの研究開発にフルタイムで取り組んでいます。