
この記事は、Volcano Engine のシニア R&D エンジニアである Shao Wei が QCon Global Software Development Conference で行った講演に基づいています。スピーカー|Shao Weiのスピーチタイム|2023年5月QCon広州
1.背景
Byte は 2016 年からサービスをクラウドネイティブ サービスに変換し始めました。現在、Byte のサービス システムには主に 4 つのカテゴリが含まれています。従来のマイクロサービスは主に Golang に基づく RPC Web サービスであり、プロモーション検索サービスはよりパフォーマンスの高い従来の C++ サービスです。要件に加えて、機械学習、ビッグデータ、さまざまなストレージ サービスもあります。
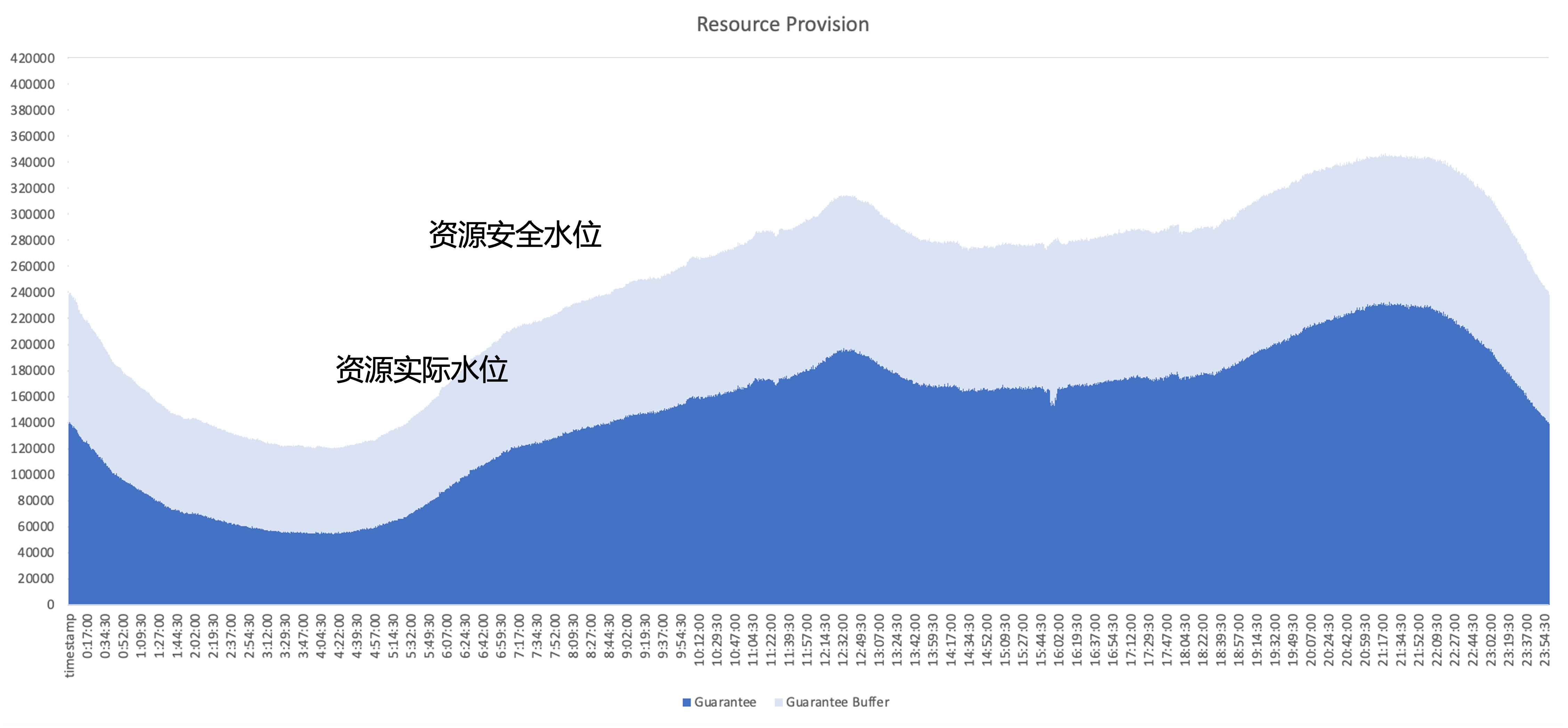
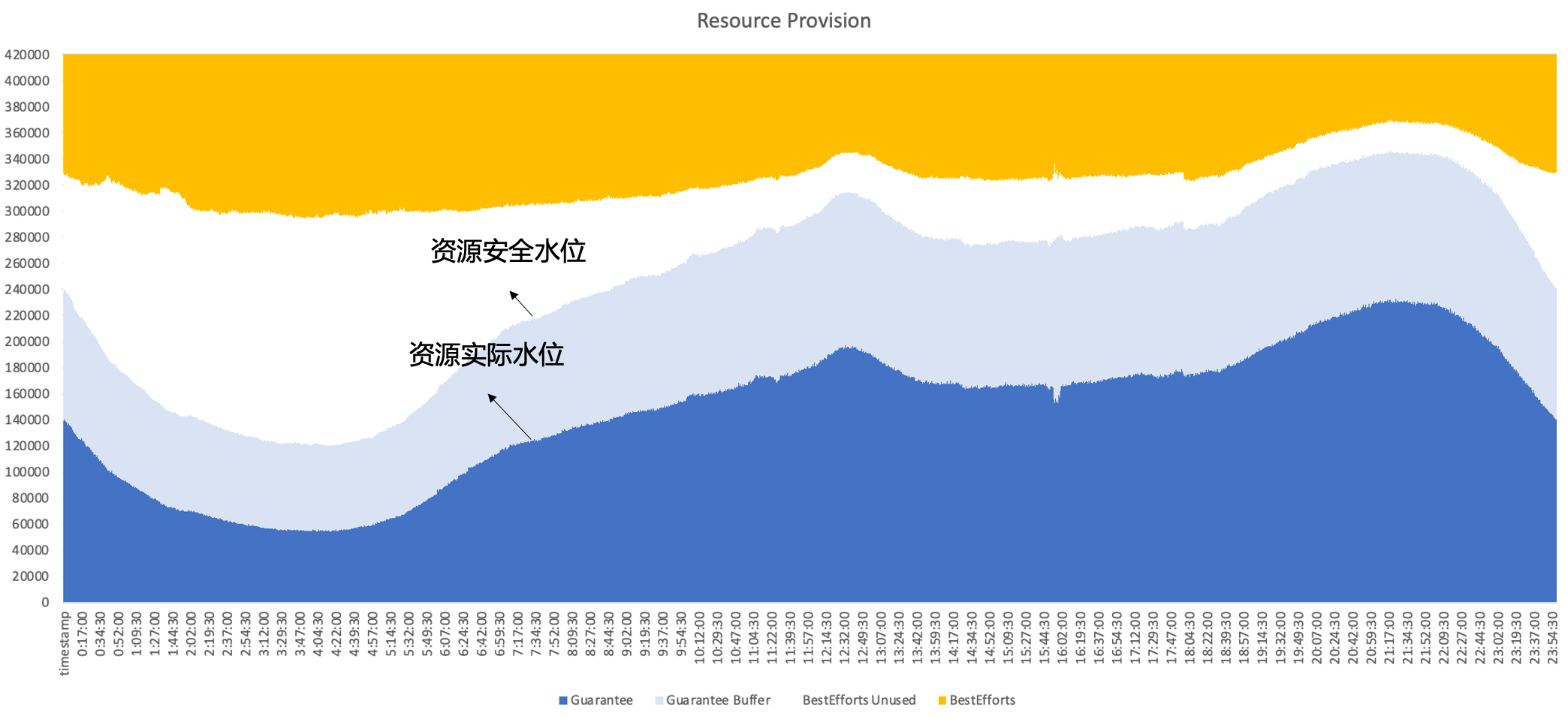
クラウドネイティブ化後に解決すべき中心的な問題は、クラスタのリソース利用効率をいかに向上させるかということです。典型的なオンラインサービスのリソース使用量を例にとると、濃い青色の部分がビジネスで実際に使用されるリソースの量です。 、水色の部分はビジネスエリアが提供するセキュリティバッファーであり、バッファーエリアを増やしても、申請されているもののビジネスで使用されていないリソースがまだ多くあります。したがって、最適化の焦点は、アーキテクチャの観点からこれらの未使用のリソースを可能な限り利用することです。
資源管理計画
Byte は社内でいくつかの異なるタイプのリソース管理ソリューションを試しました。
- リソースの運用: 企業がリソースの利用状況を定期的に管理し、リソースの適用管理を促進する問題は、運用と保守の負担が大きく、利用の問題を解決できないことです。
- 動的なオーバーブッキング: システム側でビジネス リソースの量を評価し、割り当てを積極的に削減します。問題は、オーバーブッキング戦略が必ずしも正確ではなく、実行リスクにつながる可能性があることです。
- 動的なスケーリング: 問題は、オンライン サービスのみをスケーリングの対象とした場合、オンライン サービスのトラフィックのピークと谷が似ているため、1 日を通して使用率を完全に改善できないことです。
したがって、最終的に Byte は、同じノード上でオンラインとオフラインを同時に実行するハイブリッド展開を採用し、オンラインとオフラインのリソース間の補完的な特性を最大限に活用して、最終的には次のような効果を達成できると期待しています。つまり、二次販売はオンラインです。未使用のリソースはオフラインのワークロードで十分に埋められ、リソースの使用効率を 1 日を通して高いレベルに維持できます。
2. バイトハイブリッド展開の開発経緯
Byte Cloud がネイティブになるにつれて、さまざまな段階でのビジネス ニーズと技術的特性に基づいて適切なハイブリッド 導入ソリューションを選択し、そのプロセスでハイブリッド システムを反復し続けます。
2.1 フェーズ 1: オフライン タイムシェアリング ミキシング
最初の段階では主に、オンラインとオフラインのタイムシェアリングのハイブリッド展開が行われます。
- オンライン: この段階では、ユーザーはビジネス指標に基づいて水平スケーリング ルールを構成できます。たとえば、早朝にビジネス トラフィックが減少し、ビジネスが一部のインスタンスを積極的に縮小する場合、システムはリソースを実行します。インスタンスの収縮に基づいて bing パッキングを実行すると、マシン全体が解放されます。
- オフラインの場合: この段階では、オフライン サービスはスポット タイプのリソースを大量に入手でき、その供給が不安定であるため、コストの一定の割引を受けることができます。同時に、オンラインの場合は、未使用のリソースをオフラインに販売することができます。コストに対して一定のリベートを得る。
このソリューションの利点は、複雑な単一マシン側の分離メカニズムを必要とせず、技術的な実装が比較的簡単であることですが、次のような問題もあります。
- 変換効率は高くなく、Bing パッキング処理中に断片化などの問題が発生する可能性があります。
- オフライン エクスペリエンスも良くない可能性があります。オンライン トラフィックが時々変動すると、オフライン ユーザーが強制的に強制終了され、リソースが大きく変動する可能性があります。
- 実際の運用では、通常、ビジネスは比較的保守的な弾力性のあるポリシーを構成するため、リソース改善の上限が低くなります。
2.2 フェーズ 2: Kubernetes/YARN の共同デプロイメント
上記の問題を解決するために、第 2 段階に入り、1 つのノード上でオフラインとオンラインを実行することを試みました。
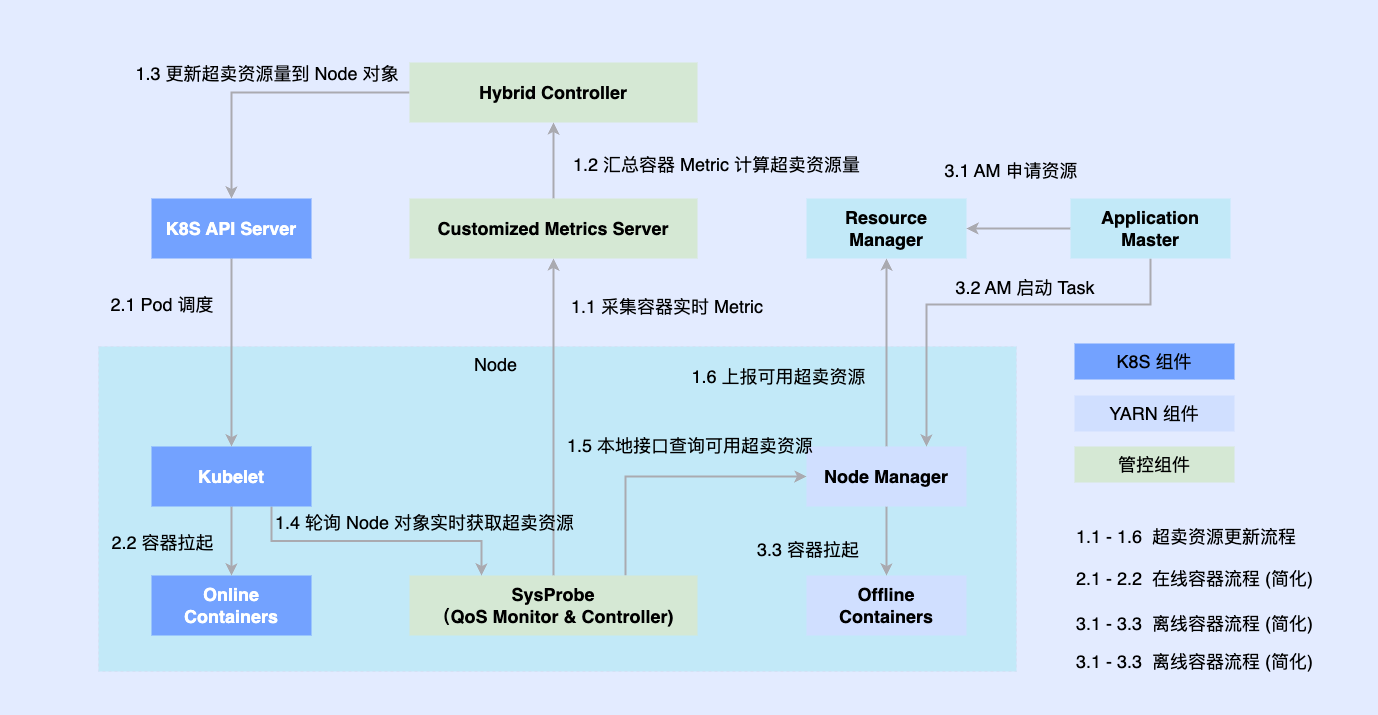
オンライン部分は以前に Kubernetes に基づいてネイティブに変換されていたため、ほとんどのオフライン ジョブは依然として YARN に基づいて実行されます。ハイブリッド デプロイメントを促進するために、単一マシン上にサードパーティ コンポーネントを導入して、オンラインとオフラインに調整されるリソースの量を決定し、それらを同時に Kubelet や Node Manager などのスタンドアロン コンポーネントに接続します。オンラインとオフラインのワークロードはノードにスケジュールされ、それらはまた、調整コンポーネントによって両方のワークロードのリソース割り当てを非同期的に更新します。
この計画により、コロケーション機能の予備蓄積は完了し、実現可能性を検証することができますが、まだいくつかの問題があります
- 2 つのシステムは非同期で実行されるため、オフライン コンテナは管理と制御をバイパスすることしかできず、中間リンクで競合が発生し、リソースが過剰に失われます。
- オフライン ワークロードを単純に抽象化することで、複雑な QoS 要件を記述することができなくなります
- オフライン メタデータが断片化すると、極端な最適化が困難になり、グローバルなスケジューリングの最適化を達成できなくなります。
2.3 フェーズ 3: 統合スケジュールとオフラインでの混合展開
第 2 段階での問題を解決するために、第 3 段階では統合されたオフライン ハイブリッド展開を完全に実現しました。
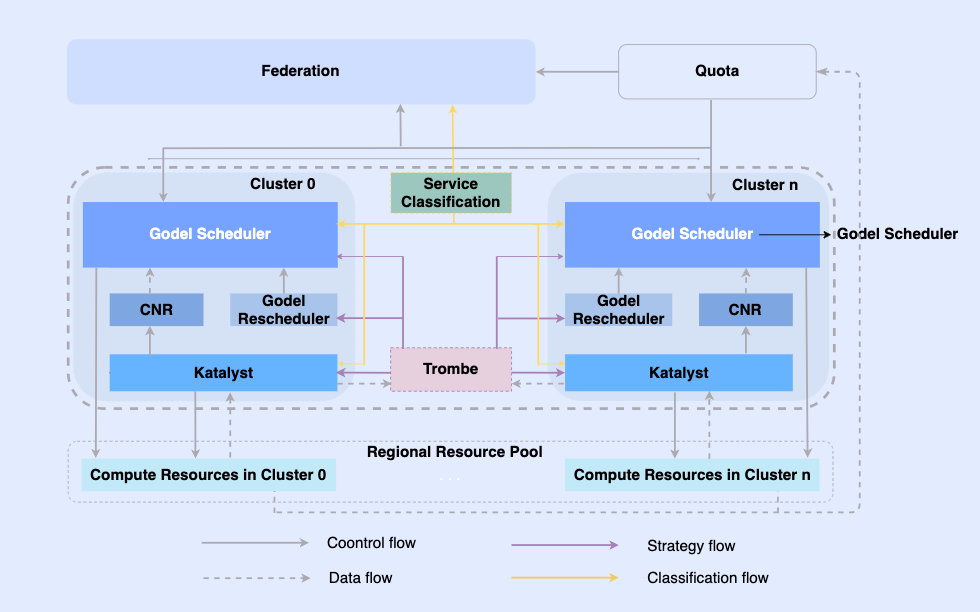
オフライン ジョブをクラウドネイティブにすることで、同じインフラストラクチャ上でジョブをスケジュールし、リソースを管理できるようになります。このシステムの最上位層は、マルチクラスタ リソース管理を実現する統合リソース フェデレーションであり、単一クラスタ内に中央の統合スケジューラとスタンドアロンの統合リソース マネージャがあり、これらが連携してオフラインの統合リソース管理機能を実現します。 。
このアーキテクチャでは、Katalyst がコアのリソース管理および制御層として機能し、単一マシン側でのリアルタイムのリソース割り当てと推定の実現を担当します。次のような特徴があります。
- 抽象化の標準化: オフライン メタデータをオープンにし、QoS 抽象化をより複雑かつ豊富にし、ビジネス パフォーマンス要件をより適切に満たします。
- 管理と制御の同期: 管理と制御のポリシーは、コンテナの起動時に発行され、起動後のリソース調整の非同期修正を回避すると同時に、ポリシーの自由な拡張をサポートします。
- インテリジェントな戦略: サービス ポートレートを構築することで、リソースの需要を事前に感知し、よりスマートなリソース管理および制御戦略を実装できます。
- 運用と保守の自動化: 統合デリバリーにより、運用と保守の自動化と標準化が実現します。
3. Katalystシステムの導入
Katalyst は、もともと触媒を意味する英語の catalyst の最初の文字が K に変更されたもので、Kubernetes システムで実行されているすべての負荷に対して、より強力な自動リソース管理機能を提供できることを意味します。
3.1 Katalystシステムの概要
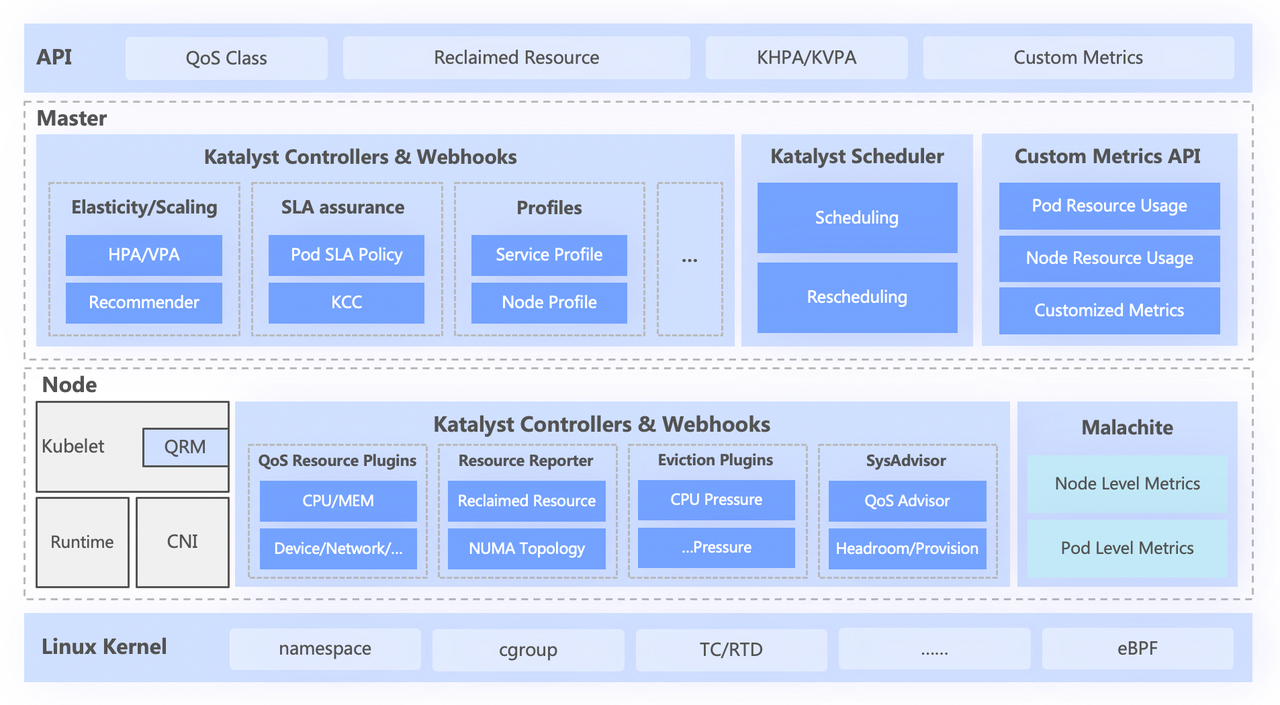
Katalyst システムは大きく 4 つの層に分かれています。
- トップレベルの標準 API は、ユーザーのさまざまな QoS レベルを抽象化し、豊富なリソース表現機能を提供します。
- 中央層は、統合スケジューリング、リソースの推奨、サービス ポートレートの構築などの基本機能を担当します。
- スタンドアロン層には、自社開発のデータ監視システムと、リソースのリアルタイムの割り当てと動的な調整を担当するリソース アロケータが含まれています。
- 最下層はバイトカスタマイズされたカーネルで、カーネル パッチと基礎となる分離メカニズムを強化することで、オフライン実行時の単一マシンのパフォーマンスの問題を解決します。
3.2 抽象的な標準化: QoS クラス
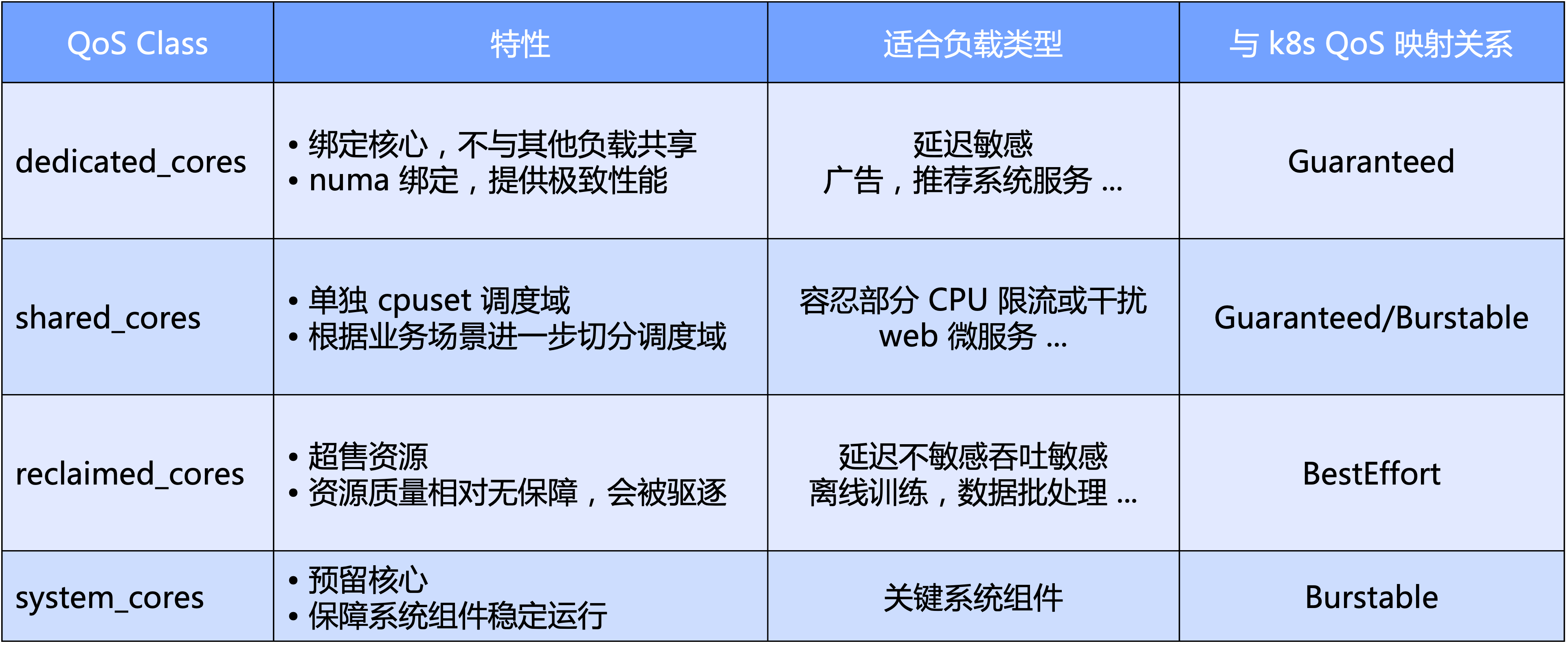
Katalyst QoS はマクロとミクロの両方の観点から解釈できます
- マクロ レベルでは、Katalyst は CPU の主要な側面に基づいて標準 QoS レベルを定義します。具体的には、QoS を 4 つのカテゴリに分類します。排他的、共有、リサイクル、および主要なシステム コンポーネント用に予約されたシステム タイプです。
- ミクロな観点から見ると、Katalyst の最終的な期待は、ワークロードの種類に関係なく、ハードカットによってクラスターを分離する必要なく、同じノード上のプールで実行でき、それによってリソース トラフィックの効率とリソース使用率が向上することです。効率。
QoS に基づいて、Katalyst は、CPU コアに加えて他のリソース要件を表現するための豊富な拡張機能拡張も提供します。
- QoS 強化: NUMA/ネットワーク カード バインディング、ネットワーク カード帯域幅割り当て、IO 重みなどの多次元リソースに対するビジネス要件の拡張表現。
- ポッドの強化: ビジネスのパフォーマンスに対する CPU スケジューリング遅延の影響など、さまざまなシステム指標に対するビジネスの感度の表現を拡張します。
- ノードの機能強化: ネイティブ TopologyPolicy を拡張することで、複数のリソース ディメンション間のマイクロ トポロジの組み合わせた要求を表現します。
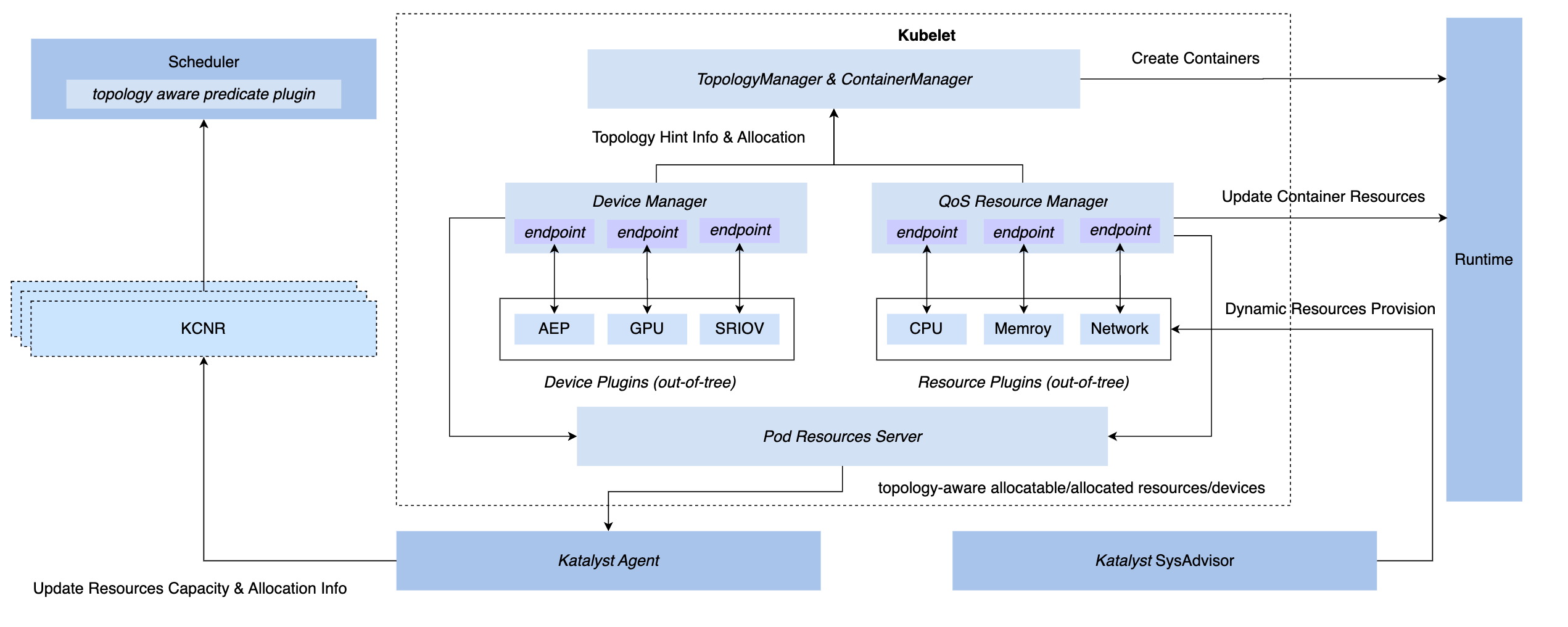
3.3 管理と制御の同期: QoS リソース マネージャー
K8s システムで同期管理および制御機能を実現するには、CRI 層の挿入、OCI 層、および Kubelet 層の 3 つのフック方法があります。最終的に、Katalyst は Kubelet 側で管理および制御を実装することを選択しました。ネイティブのデバイス マネージャーと同じレベルで QoS リソース マネージャーを実装するには、このプログラムの利点は次のとおりです。
- 許可段階で傍受を実装すると、後続のステップで制御を達成するために秘密の手段に依存する必要がなくなります。
- メタデータを Kubelet に接続し、標準インターフェースを介して単一マシンのマイクロトポロジー情報をノード CRD に報告し、スケジューラーとのドッキングを実現します。
- このフレームワークに基づいて、カスタマイズされた管理および制御のニーズに合わせてプラグイン可能なプラグインを柔軟に実装できます。
3.4 インテリジェントな戦略: サービスのポートレートとリソースの見積もり
通常、サービス P99 遅延やダウンストリーム エラー率などのビジネス インジケーターを使用してサービス ポートレートを構築することを選択する方が直感的です。しかし、通常、ビジネス指標はシステム指標に比べて取得が難しく、複数のフレームワークが存在する場合でも、それらが生成するビジネス指標の意味はまったく同じではありません。これらの指標に強く依存すると、制御の実装全体が非常に複雑になります。
したがって、最終的なリソース制御またはサービスのポートフォリオは、ビジネス指標ではなくシステム指標に基づくことを望んでいます。最も重要なのは、ビジネスが最も懸念しているシステム指標を見つける方法です。私たちのアプローチは、一連のオフラインを使用することです。ビジネス指標とシステム指標を発見するためのパイプライン。たとえば、図のサービスでは、コア ビジネス指標は P99 遅延であることがわかり、最も相関の高いシステム指標は CPU スケジューリング遅延であることがわかり、サービスのリソース供給を調整し続けます。目標は、CPU のスケジューリングを可能な限り遅らせることです。
Katalyst は、サービス ポートレートに基づいて、CPU、メモリ、ディスク、ネットワークの豊富な分離メカニズムを提供し、必要に応じてカーネルをカスタマイズして、より強力なパフォーマンス要件を提供します。ただし、これらの手段は、必ずしも適用できるわけではありません。ビジネスを遂行する過程において、分離は目的ではなく手段であることを強調する必要があります。特定のニーズとシナリオに基づいて、さまざまな分離ソリューションを選択する必要があります。
3.5 運用保守の自動化: 多次元の動的構成管理
すべてのリソースがリソース プール システムの下にあることが望ましいですが、大規模な運用環境では、すべてのノードをクラスターに配置することは不可能です。また、クラスターには CPU マシンと GPU マシンの両方を含めることができます。ただし、コントロール プレーンは可能です。共有されますが、データ プレーンでは特定の分離が必要です。ノード レベルでは、グレースケール検証のためにノードのディメンション構成を変更する必要があることが多く、その結果、同じノードで実行されているさまざまなサービスの SLO に違いが生じます。
これらの問題を解決するには、ビジネスの展開中にノードのさまざまな構成がサービスに与える影響を考慮する必要があります。この目的を達成するために、Katalyst は標準配信用の動的構成管理機能を提供し、自動化された方法でさまざまなノードのパフォーマンスと構成を評価し、これらの結果に基づいてサービスに最適なノードを選択します。
4. Katalyst コロケーション アプリケーションと事例分析
このセクションでは、Byte の内部事例に基づいたベスト プラクティスをいくつか紹介します。
4.1 活用効果
Katalyst の導入効果に関しては、Byte の内部ビジネス慣行に基づいて、単一クラスター内の四半期サイクル中にリソースを比較的高い状態に維持でき、リソース使用率も毎日のさまざまな時間帯で比較的高いレベルを示します。安定した分散と同時に、クラスター内のほとんどのマシンの使用率も比較的集中しており、ハイブリッド展開システムはすべてのノードで比較的安定して実行されます。
| リソース予測アルゴリズム | 再資源化率 | 日レベルの平均 CPU 使用率 | 日レベルのピーク CPU 使用率 |
|---|---|---|---|
| 使用量固定バッファ | 0.26 | 0.33 | 0.58 |
| K-means クラスタリング アルゴリズム | 0.35 | 0.48 | 0.6 |
| システムインジケーター PID アルゴリズム | 0.39 | 0.54 | 0.66 |
| システム指標モデル推定 + PID アルゴリズム | 0.42 | 0.57 | 0.67 |
4.2 実践: オフラインでのセンスレスアクセス
第 3 段階に入ると、クラウドネイティブな変革をオフラインで実行する必要があります。変換には主に 2 つの方法があり、1 つは K8s システムに既に存在するサービスの場合、もう 1 つは YARN アーキテクチャに基づいてサービスを直接接続する場合です。 , フレームワークの完全な変革はビジネスにとって非常にコストがかかり、理論的にはすべてのビジネスの段階的なアップグレードにつながりますが、これは明らかに理想的な状態ではありません。
この問題を解決するために、Byte は Yodel の接着層を参照します。つまり、ビジネス アクセスは依然として標準の Yarn API を使用しますが、この接着層では、基礎となる K8s セマンティクスとインターフェイスし、ユーザーのリソース要求を抽象化します。ポッドやコンテナの説明のようなもの。この方法により、より成熟した K8s テクノロジーを最下位レベルで使用してリソースを管理し、オフラインのクラウドネイティブ変革を達成し、同時にビジネスの安定性を確保することができます。
4.3 実践: リソース運用ガバナンス
コロケーション プロセス中に、ビッグ データとトレーニング フレームワークを適応および変換し、さまざまな再試行、チェックポイント、グレーディングを実行して、これらのビッグ データとトレーニング ジョブをコロケーション リソース プール全体に適用した後、使用感はそれほど悪くありません。
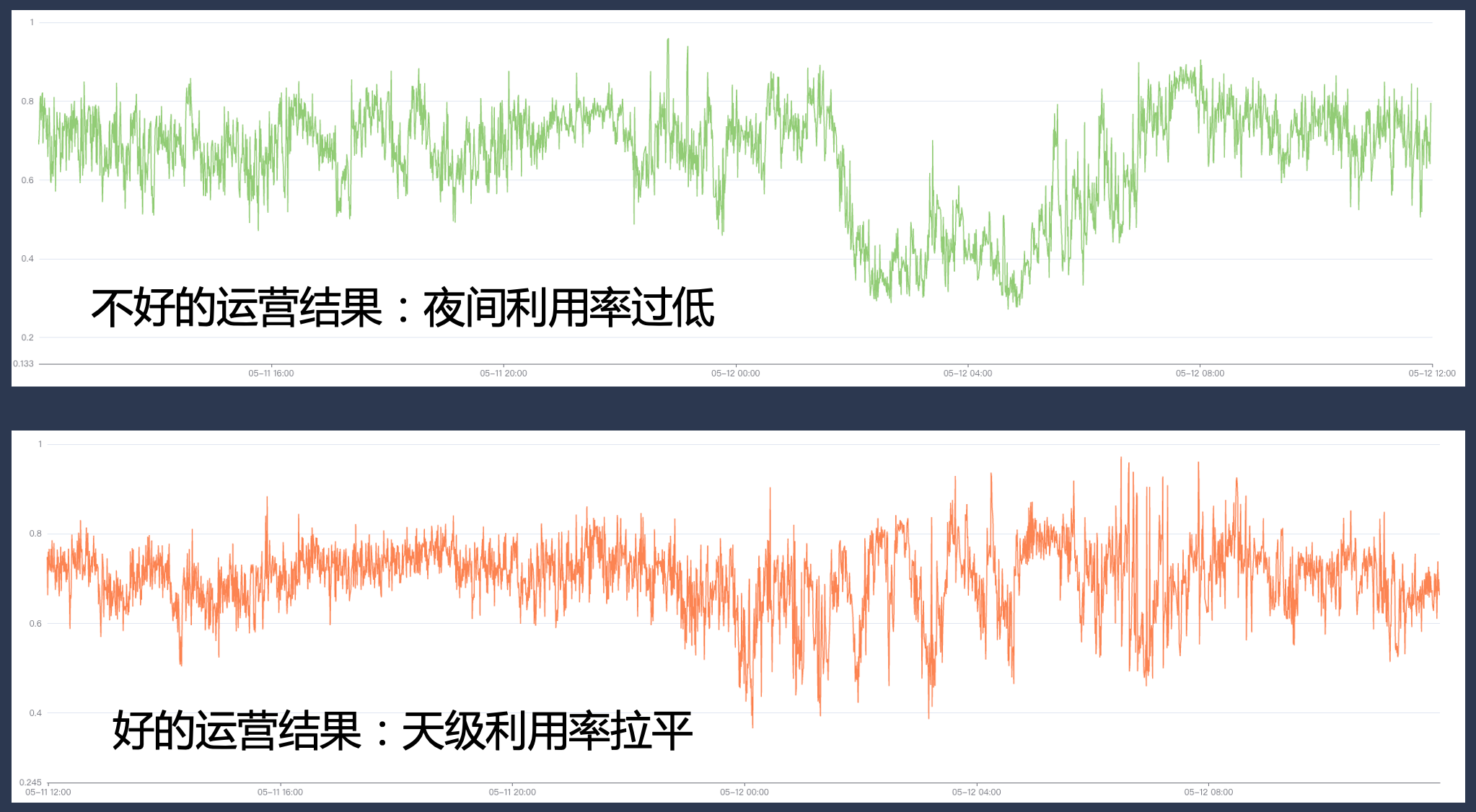
同時に、システム内のリソース商品、ビジネス分類、運用ガバナンス、およびクォータ管理に関する完全な基本機能を備えている必要があります。運用が適切でないと、特定のピーク時間帯には使用率が非常に高くても、他の時間帯にはリソースのギャップが大きくなり、使用率が期待を下回ってしまう可能性があります。
4.4 実践: 資源効率の改善を最大限に高める
サービスポートフォリオを構築する際には、システム指標を用いて管理・制御を行いますが、オフライン分析による静的なシステム指標ではビジネス側の変化にリアルタイムに追随することができず、一定期間内の業績の変化を分析する必要があります。静的な値を調整する時間です。
この目的を達成するために、Katalyst はシステム メトリクスを微調整するためのモデルを導入します。たとえば、CPU スケジューリングの遅延が x ミリ秒である可能性があると考え、一定期間後にビジネス目標の遅延が y ミリ秒である可能性があることをモデルを通じて計算すると、より適切に評価するために目標の値を動的に調整できます。ビジネスのパフォーマンス。
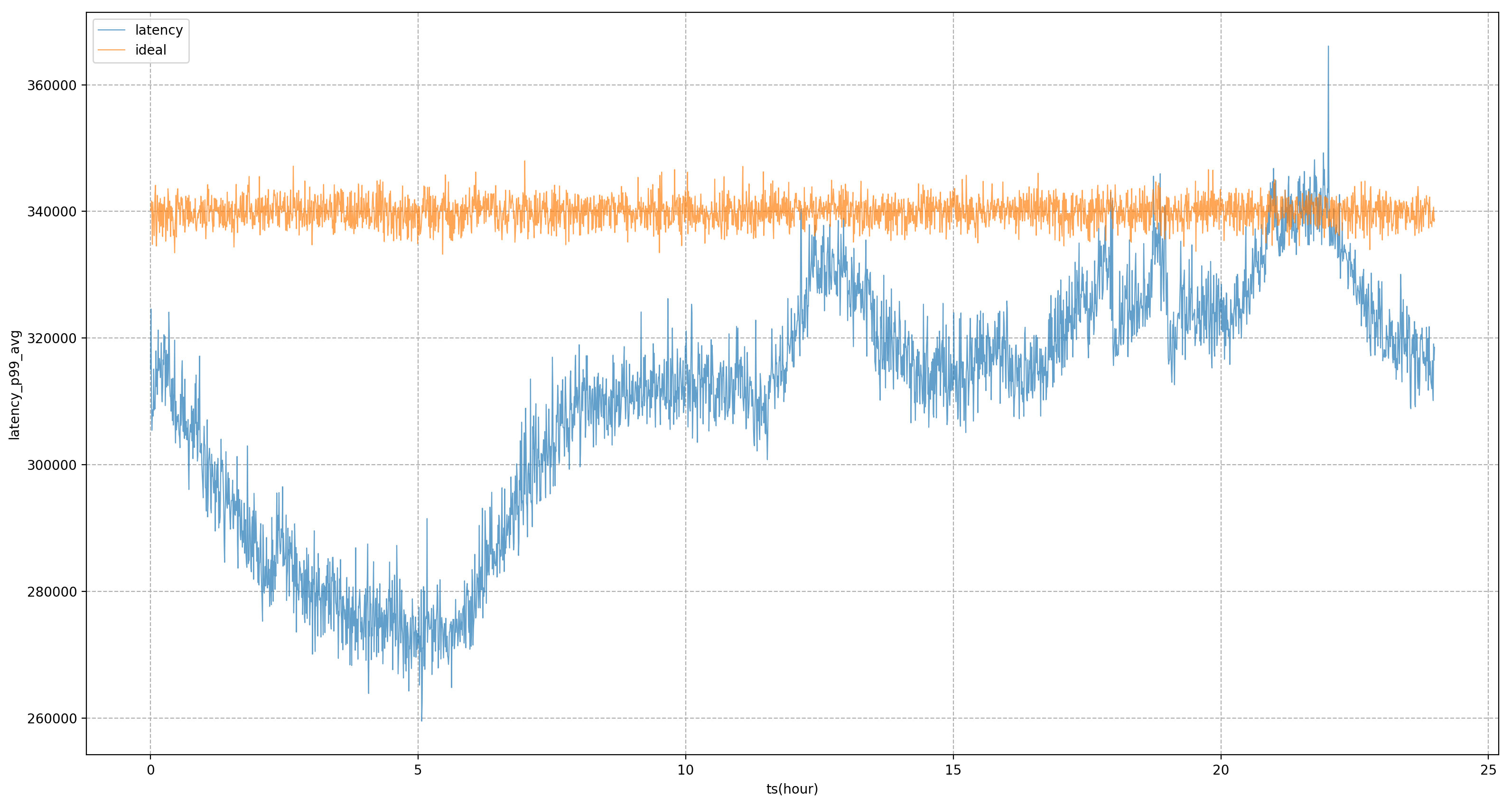
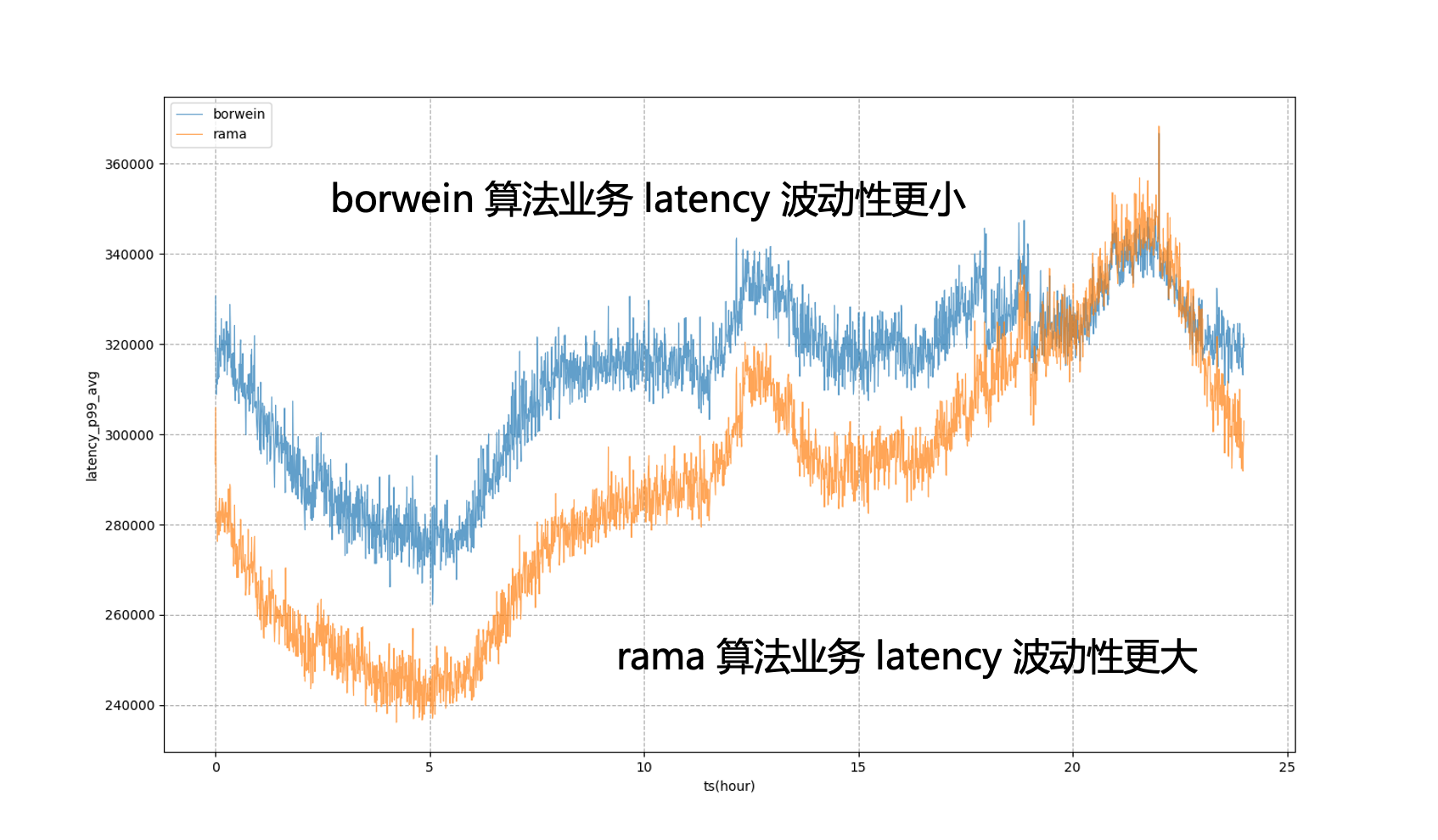
たとえば、次の図では、静的なシステム目標を完全に規制に使用すると、ビジネス P99 は激しい変動状態になります。これは、夕方以外のピーク時間帯にビジネス リソースの使用量をこれ以上絞り込むことができないことを意味します。極限状態でビジネスに近づける モデル導入後は夕方のピーク時間帯に許容できる量となり、ビジネスの遅延がより安定し、業績を比較的安定したレベルに平準化できることがわかります。一日を通してリソースのメリットを享受できます。
4.5 演習: 単一マシンの問題を解決する
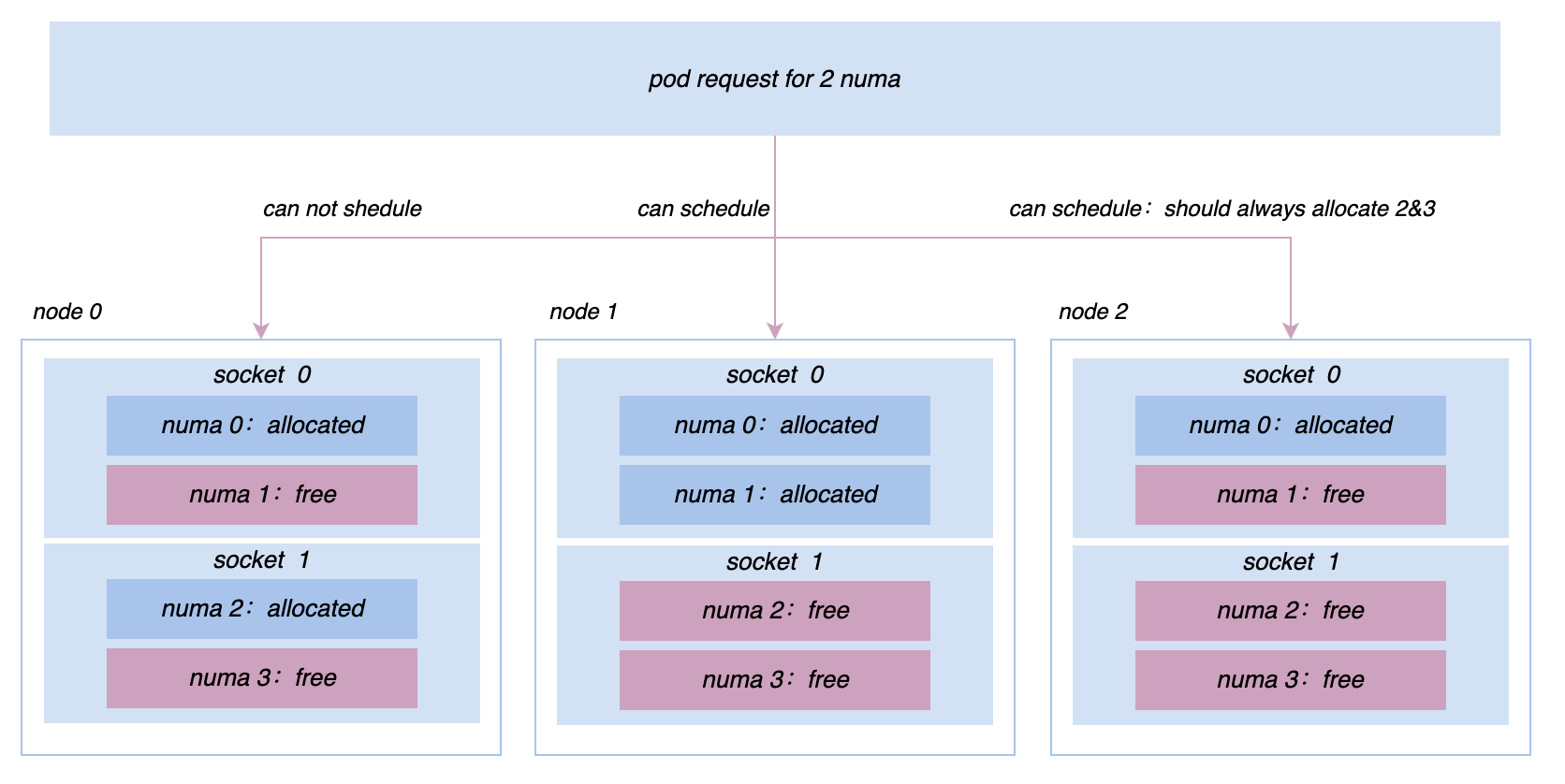
コロケーションを推進する過程で、今後もオンラインおよびオフラインのパフォーマンスに関するさまざまな問題や、マイクロトポロジ管理の要求に直面することになります。たとえば、当初はすべてのマシンが cgroup V1 に基づいて管理および制御されていましたが、V1 の構造により、システムはこの問題を解決するために非常に深いディレクトリ ツリーを移動し、大量のカーネル モード CPU を消費する必要がありました。クラスター全体のノードを cgroup V1 に切り替えています。cgroup V2 アーキテクチャでは、プロモーション検索などのサービスのリソースをより効率的に分離して監視できるため、より優れたパフォーマンスを追求するには、より複雑なアフィニティを実装する必要があります。ソケット/NUMA レベルでの反アフィニティ戦略など。これらのより高度なリソース管理要件は、Katalyst でより適切に実現できます。
5 まとめと展望
Katalyst は正式にオープンソース化され、バージョン v0.3.0 がリリースされており、今後も反復にさらに多くのエネルギーを投資していきます。コミュニティは、リソース分離、トラフィック プロファイリング、スケジューリング戦略、柔軟な戦略、異種デバイス管理などの機能とシステム強化を構築していきます。 、誰もがこのプロジェクトに注目し、参加し、フィードバックを提供することを歓迎します。
仲間のニワトリがDeepin-IDE を 「オープンソース」化し、ついにブートストラップを達成しました。 いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた Tencent Cloud の 4 月 8 日の障害レビューと状況説明 RustDesk リモート デスクトップ起動の再構築 Web クライアント WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始 TIOBE 4 月リスト: PHPは史上最低値に落ち、 FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし 、Google は大規模なコード モデル CodeGemma をリリースしました 。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツールカンファレンスのスピーチビデオ: Katalyst: Bytedance Cloud Native Cost Optimization Practice | QCon Guangzhou 2023