1つは、HashMapのデータ構造です。
HashMap<String,String> map=new HashMap();
map.put("1","Kobe");
これらの2行のコードは、データがHashMapに保存されていることを示しています。これはまた、データをHashMapに効率的に保存するにはどうすればよいかという疑問を提起します。
この質問から始めて、最初にHashMapの基礎となるデータ構造を理解する必要があります。
HashMap:配列+リンクリスト[単一リンクリスト] +赤黒ツリーJDK1.8
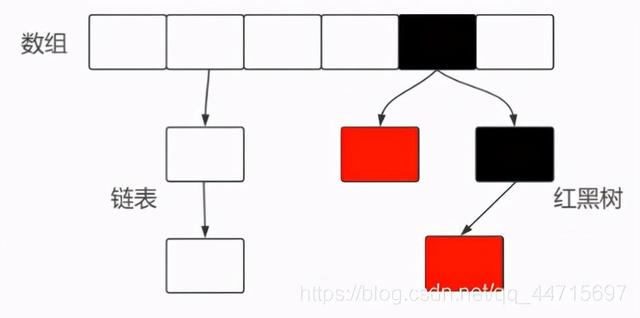
HashMapは、キーと値のペア(key、value)を格納するためのコンテナであることがわかっています。上の図から、キーまたは値を各小さなグリッドに配置する必要がありますか、それとも格納する必要がありますか?
ソースコードを読んだら、[key、value]をカプセル化するためにここでオブジェクト指向のアイデアが採用されていることがわかります。
class Node{
private String key;
private String value;
}
それぞれの小さなグリッドは新しいノードであることがわかります。それらを詳細に実装する場合は、ノードに基づいてわずかな変更を加えるだけで済みます。
Node[] table=new Node[24]; //表示数组
class Node{
private String key; //表示单项链表
private String value;
Node next;
}
class TreeNode entends Node{ //红黑树的伪码表示
parent;
left;
right;
}
二、ハッシュ関数と衝突
データを取得してHashMapに格納するには、配列インデックスの添え字内のキーと値で構成されるNodeオブジェクトの位置を決定する必要があります。
場所を取得したい場合は、次のものが必要です。
- 配列の長さ長さ
- 整数を取得[0 ----長さ-1]
(1)最初に使用することを考えるかもしれません
Random.nextInt(length);
しかし、これは2つの問題を引き起こします。
- ランダムな繰り返しの可能性が高すぎる
- 検索時に根拠がない
(2)この状況を考慮して、hashCodeは次のとおりです。
- 整数を取得
int hash = key.hashCode() ——> 32位的0和1组成的整数
如果我们用一个例子来表示:“1”.hashCode 有可能会超过存储范围
- この整数の範囲を制御する
这时就需要控制整形的hash值的范围:hash%length = 需要的范围
しかし、これでも特定の問題が発生します。hash = key.hashCode();で、keyの値が31、47などの場合、モジュロ16(hash%16)の後に得られる結果はすべて1であるため、Nodeオブジェクトは同じ位置に移動する可能性があります。性別が大きくなり、ストレージリソースが大幅に浪費されます。
インデックスの結果ができるだけ繰り返されないようにするには、計算形式を変更する必要があります:ハッシュと長さ-1

得られた結果も0から15の間であり、これはモジュロ操作によって得られた結果と同じです。
しかし、それでも、異なるハッシュ値は同じインデックスを生成する可能性があります:

このとき、元のハッシュ値の下位16ビットと上位16ビットに対してXOR演算を実行する必要があります。

ハッシュ関数:key.hashCode()の上位16ビットと下位16ビットに対して排他的OR演算を実行します。これにより、最終的なハッシュ値の最後の数ビットが重複する可能性が以前よりもはるかに低くなります。
ハッシュ衝突
hash&(n-1)では、インデックスの結果が繰り返される場合、それは衝突を意味します。

ここに画像の説明を挿入しますop2:length-1-> 01111このフォーム。このフォームでない場合、op1の終了値が1または0のどちらであっても、最終的な計算結果は0になり、繰り返しの可能性が高くなります。 。
インデックスは実際にはop1に依存します。これは、op2の最初の桁を除いて、他の桁はすべて1であるためです。これは、アレイのサイズが10000-1 = 0111(2の累乗)でなければならないことも意味します。
三、置くプロセス
新しいHashMapを作成するときは、そこにデータを格納する必要があります。置くときは、キー値のハッシュ(hash(key))を要求する必要があります。ここでのハッシュは、後で位置を決定するときに使用します。ハッシュ関数を完了し、いくつかの変数を維持した後、特定のプットプロセスを開始できます。
- ノード配列が初期化されているかどうかを確認します。初期化されていない場合は、初期化する必要があります。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
resize()メソッドの初期化
newCap = DEFAULT_INITIAL_CAPACITY; //默认数组大小16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //16*0.75=12 扩容标准
Node<K,V> newTab = (Node<K,V>[])new Node[newCap]; //数组初始化
2.ハッシュ関数で得られたハッシュ結果に基づいて、ノードノードの添え字の位置を計算し、データの保存を開始します。
ノードノードの計算された添え字位置が1の場合、元々位置1にノードノードがあるかどうかを判断します。そうでない場合は、Nodeオブジェクトを直接作成し、配列内のその位置に配置します。位置1に要素がある場合、次の3つのケースに分けられます。(1)キー値が同じで、値の値が直接置き換えられる(2)キー値が同じでなく、リンクされたリストで保存される(3)キー値が同じでない場合は、赤と黒を押します。ツリーストレージ
else {
Node<K,V> e; K k;
//key值相同,直接替换value值
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e=p;
//key值不相同,按链表的方式进行存储
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//key值不相同,按链表的方式进行存储 ————> 循环遍历当前链表,直到找到当前链表的最后一个节点,next==null,将new出来的Node放到最后节点的后面
for (int binCount = 0; ; ++binCount){
if ((e = p.next) == null){
p.next = newNode(hash, key, value, null);
//但凡新增加一个节点,就检查长度有没有超过8
if (binCount >= TREEIFY_THRESHOLD - 1)
//链表转红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
注:リンクリストの長さが8を超えると、赤黒ツリーに変換されます。赤黒ツリーのノードが6未満の場合は、リンクリストに変換されます。
第四に、HashMapの拡張
アレイのサイズがストレージ要件を満たせない場合は、HashMapを拡張する必要があります。
拡張の方法は、新しい配列を作成し、古い配列の[リンクされたリスト、赤黒の木]を新しい配列に移行することです。
注:容量を拡張するときは、拡張が2の倍数(16 —> 32など)であることを確認してください。これは、2の累乗の法則に準拠しています。
そして、どのような状況で拡張が発生しますか?
配列のサイズが16の場合、データ構造全体のノード数が16 * 0.75 = 12を超えると、拡張が発生します。
//源码中的0.75就是负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
if (++size > threshold) //扩容标准,这里的threshold就是16*0.75
resize(); //功能:初始化/扩容
//这里的MAXIMUM_CAPACITY是2^30,如果老数组大于这个数,就不需要扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果没有超过,就将老数组大小向右位移一位
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
//而这时使用的是新的数组,所以扩容标准也增加一倍,为24
newThr = oldThr << 1;
これらの2つのパラメーターを取得すると、新しい配列を作成できます。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
次に、古いアレイのノードを新しいアレイに移行する必要があります。
- 古い配列のインデックスをループします
- 現在の添え字の位置に要素があるかどうかを判断し、要素がある場合にのみ移行する価値があります
- 添え字の位置に要素があり、その下に要素がない場合
- 以下に要素があり、赤黒の木の形をしている場合
- 以下に要素があり、それらがリンクされたリスト形式である場合
if (oldTab != null) {
//循环遍历老的数组的下标
for(int j = 0;j < oldCap; ++j) {
Node<K,V> e;
//判断当前下标位置有没有元素,有元素才值得迁移
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果下标位置有元素,并且下面没有元素
if (e.next == null)
//得到Node节点再新数组下标的位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//如果下面有元素,并且是红黑树形式
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, lotail = null;
Node<K,V> hiload = null,hiTail = null;
Node<K,V> next;
//如果下面有元素,并且是链表形式
do {
next = e.next;
//老数组链表中i位置的Node节点,会保存到新数组中对应的i位置
if ((e.hash &oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//老数组链表中i位置的Node节点,会保存到新数组中对应的i+oldCap位置 1+16=17
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j+oldCap] = hiHead;
}
}
}
}
}
5、スレッドの安全性
マルチスレッド実行操作とシングルスレッド実行操作では、最終的なデータに一貫性がありません。これはスレッドのセキュリティの問題です。スレッドの安全性を確保したい場合、このスレッドには、原子性、可視性、順序という3つの主要なプロパティが必要です。
方法:このスレッドの操作が完了した場合、または異常に終了した場合にのみ、他のスレッドが出入りできます。putプロセスでsynchronizedキーワードを追加できます。ただし、これにより各スレッドにロックが発生し、効率が大幅に低下します。現時点では、hashtableまたはConcurrentHashMapを使用でき、ここではあまり拡張しないでください。
元のリンク:http://m6z.cn/6s8bYq
この記事が役に立ったと思われる場合は、転送してフォローしてサポートを受けることができます
