環境への準備:
事前にインストールされているpycharm
は、[ファイル]-> [設定]-> [プロジェクト]-> [プロジェクトインタープリター]を開きます。
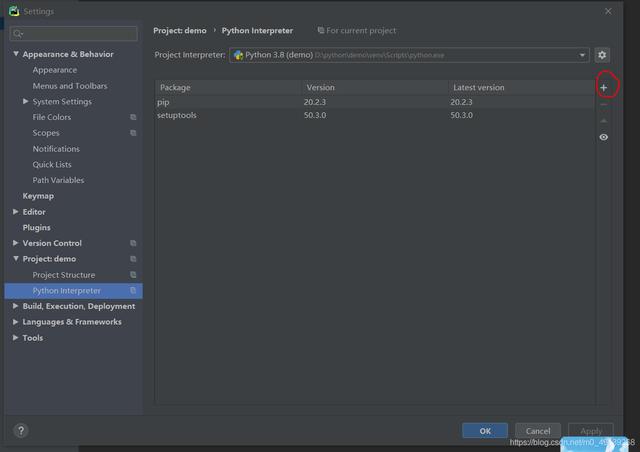
プラス記号(写真の赤い円内)をクリックします
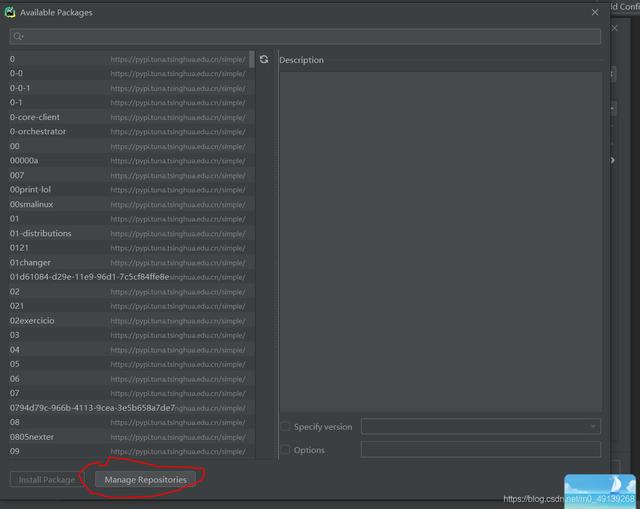
赤い丸のボタンをクリックしてください
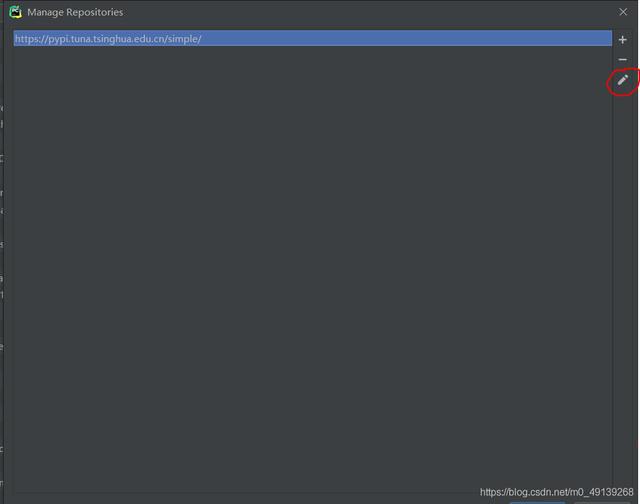
最初のリンクを選択し、鉛筆をクリックして、元のリンクを次のように置き換えます(ここで置き換えられています):
https ://pypi.tuna.tsinghua.edu.cn/simple/
[OK]をクリックした後、requests-htmlと入力し、Enterキーを押して
選択します。リクエスト後に[パッケージのインストール]をクリックします-html

インストールが成功するのを待ち、閉じます
Webページのソースコードを解析する
コンテンツの例:
特定のブロガーのすべての記事から目的のコンテンツをクロールします。
背景の例:
ブロガーのすべての記事(https://me.csdn.net/weixin_44286745)から、各記事のタイトル、時間、および読み取り量を取得します。
- HTMLSessionメソッドをrequests_htmlにインポートし、そのオブジェクトを作成します
requests_htmlからimportHTMLSession session = HTMLSession() 123
- get requestを使用して、Webサイトをクロールし、ページのソースコードを取得します。
html = session.get( "https://me.csdn.net/weixin_44286745")。html 12
- すべての記事を検索
allBlog = html.xpath( "// dl [@ class = 'tab_page_list']") 1
- Webサイトのホームページを入力します(この例では:https://me.csdn.net/weixin_44286745)
- 記事の空白部分を右クリックして、この記事のラベルを見つけます
- 他の記事と同じように操作してから、すべての記事に共通のタグを見つけます(ここでのすべての記事のクラスは「my_tab_page_con」です)
- xpathは、htmlのさまざまなタグと属性をトラバースして、必要な情報を見つけて抽出できます。
- タイトル、閲覧量、日付を取得するためのWebページ分析。
allBlogのfori:
title = i.xpath( "dl / dt / h3 / a")[0] .text
views = i.xpath( "// div [@ class = 'tab_page_b_l fl']")[0] .text
date = i.xpath( "// div [@ class = 'tab_page_b_r fr']")[0] .text
print(title + '' + views + '' + date)
12345
Web分析:
- 複数の記事があるため、forループを使用して個別に取得され、上記のコードはすべての記事を取得しているため、私は記事を意味します
- 記事のタイトルを取得するコードの2行目は、記事の取得と似ています。タイトルにマウスを置き、右クリックして確認します。記事にはタイトルが1つしかないため、絶対パスを使用してラベルごとにタイトル位置レイヤーに移動できます。
- xpathが返すのはリストです。最初のリストが必要なので、添え字を追加する必要があり(リストには要素が1つしかない)、出力するのはテキストなので、textがテキストを取得します。
- 読み取り量と時間も繰り返し操作です
- 相対パスまたは絶対パスを使用できます。通常、相対パスが使用され、形式はコードに基づいてモデル化されます。
- コードの5行目は、記事に関する情報が取得されるたびに出力され、トラバース後にすべての情報を取得できます。
完全なコード:
fromrequests_htmlインポートHTMLSession
セッション= HTMLSession()
html = session.get( "https://me.csdn.net/weixin_44286745")。html
allBlog = html.xpath(" // dl [@ class = 'tab_page_list'] " )
for i in allBlog:
title = i.xpath( "dl / dt / h3 / a")[0] .text
views = i.xpath( "// div [@ class = 'tab_page_b_l fl']")[0 ] .text
date = i.xpath( "// div [@ class = 'tab_page_b_r fr']")[0] .text
print(title + '' + views + '' + date)
1234567891011121314
記事の写真など、他のものを自分でクロールして、自分で試してみてください。!!
つづく
html経由でリクエスト
完全なプロジェクトコードを入手するには、ここをクリックしてください