Análisis de los datos campaña presidencial patrocinado por los Estados Unidos
Este artículo proviene de laboratorio de la nube Ali Tianchi caso la dirección original
de análisis de datos de autoaprendizaje estudiantes Wang aprender sobre su propia escritura de nuevo, analizar de nuevo, hacer su propio código y los resultados son los siguientes
bibliotecas 1. El análisis de los datos de importación relacionados con Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
2. Visión general de Carga de Datos y
2.1 ya que una sola de datos es demasiado grande, hemos dividido en tres fuentes de datos fila 0-50w, fila 50-100W, 100w + OK
#数据读取
data_01=pd.read_csv(r'H:\阿里云\2012美国总统竞选赞助数据分析\data_01.csv')
data_02=pd.read_csv(r'H:\阿里云\2012美国总统竞选赞助数据分析\data_02.csv')
data_03=pd.read_csv(r'H:\阿里云\2012美国总统竞选赞助数据分析\data_03.csv')
2.2 Visualización de datos:
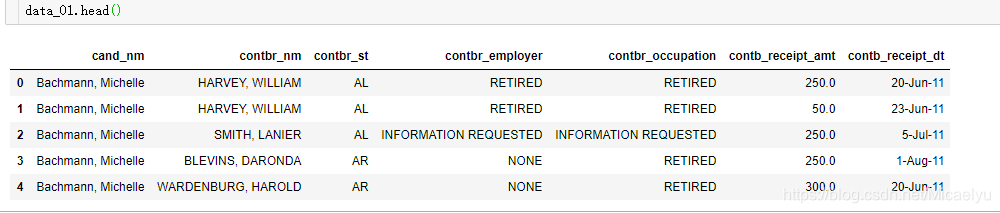 data_01 terminó de leer las primeras cinco líneas
data_01 terminó de leer las primeras cinco líneas
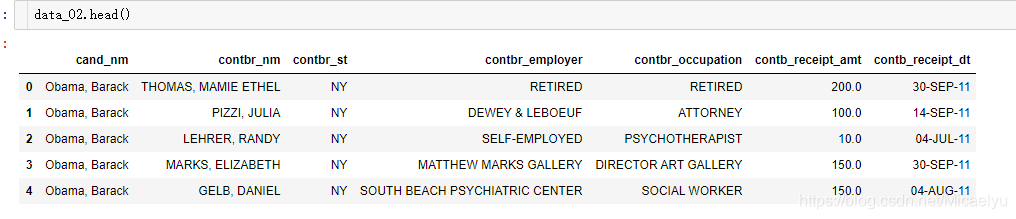
Cinco data_02 terminado de leer antes de
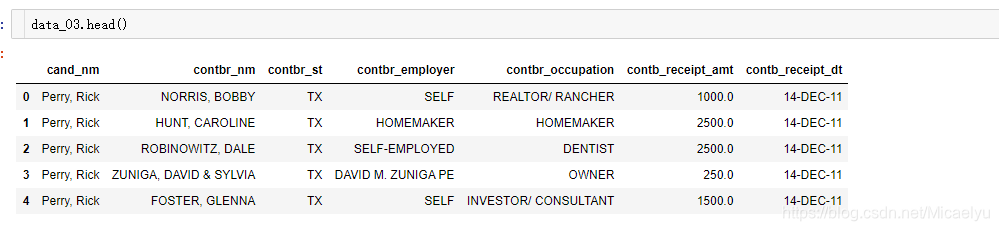 la lectura se terminó primero cinco data_03
la lectura se terminó primero cinco data_03
2.3 de combinación de datos (data_01, data_02, data_03)
data=pd.concat([data_01,data_02,data_03])
data.head()
2.4 Visualización de datos de información, incluyendo el nombre del tipo de datos de cada campo, el número de no vacío, el campo
data.info()
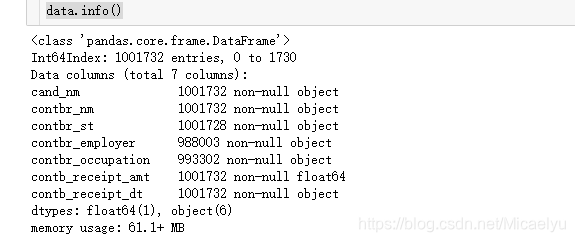
Podemos ver un poco menos contbr_employer cantidad y contbr_occupation campo de dos columnas, lo que indica que hay un valor nulo
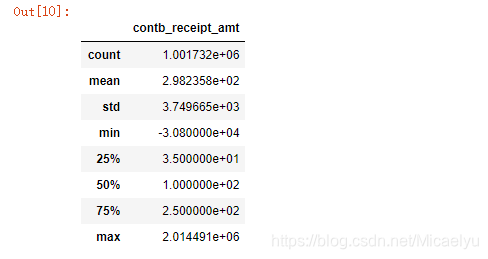
Resumen 2.5 a datos de vista
data.describe()
2.6 Procesamiento de los valores perdidos
de data.info (), podemos ver que contbr_employer, contbr_occupation tienen una pequeña cantidad de valores perdidos, nos llenamos de no previsto
data['contbr_employer'].fillna('not provided',inplace=True)
data['contbr_occupation'].fillna('not provided',inplace=True)
2.7 Ver valores perdidos
data[data['contbr_employer'].isnull()]
data[data['contbr_occupation'].isnull()]
data.info()
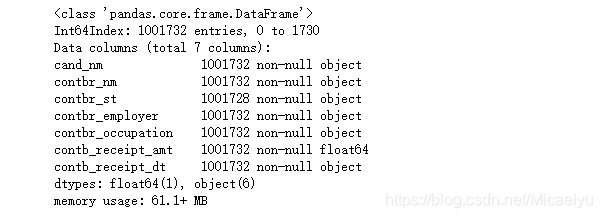
Se puede ver, tiene valores no faltan
2.8 a datos de vista en un candidato presidencial que tiene
print('共有{}位候选人,分别是'.format(len(data['cand_nm'].unique())))
data['cand_nm'].unique()

2.9 por los motores de búsqueda y otras formas de llegar a la afiliación a un partido de cada candidato a presidente, los diccionarios de establecimiento partes, nombre de los candidatos como una afiliación a un partido clave como el valor correspondiente
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
2,10 mapa por la función de mapeo, una información de la parte del aumento del partido almacena
data['party']=data['cand_nm'].map(parties)#其中map的映射情况
#查看两个党派的情况
data['party'].value_counts()
 # Se puede ver más Republicano (GOP) para aceptar el patrocinio de la cantidad total, el número de patrocinadores demócrata (Partido Demócrata) para conseguir un poco más
# Se puede ver más Republicano (GOP) para aceptar el patrocinio de la cantidad total, el número de patrocinadores demócrata (Partido Demócrata) para conseguir un poco más
2.11 vistazo a la hoja de datos
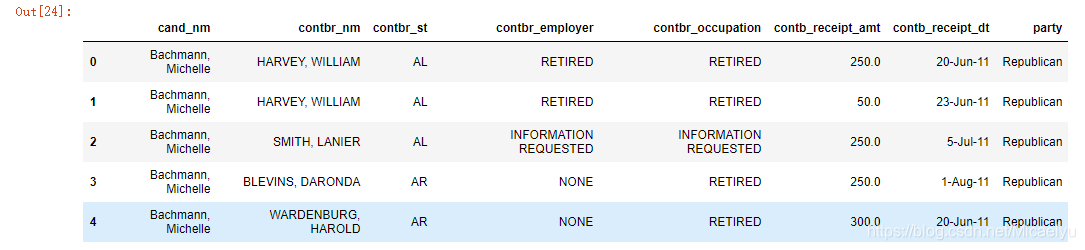
donde cada campo significado conocido
cand_nm - nombres de los candidatos para aceptar donaciones
contbr_nm - el nombre del donante
contbr_st - Estado del donante
contbr_employer - empresa del donante
contbr_occupation - donantes carrera
contb_receipt_amt - cantidad de la donación (US $)
contb_receipt_dt - cerrada contribuciones hasta la fecha
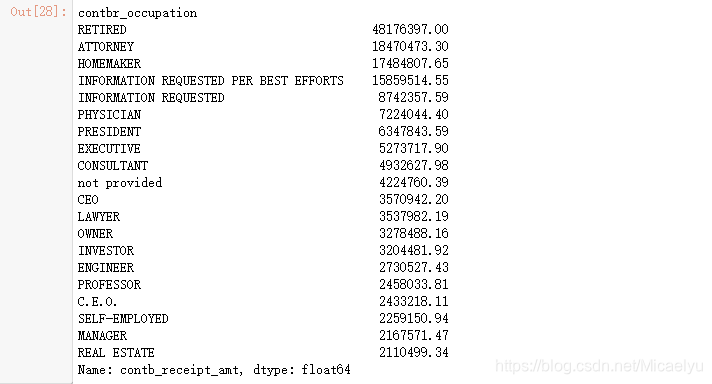
2.12 Ordenar: seguir su resumen de la carrera de la cantidad total del pedido de patrocinio, de acuerdo con el resumen del trabajo, calcular la cantidad total de patrocinio, exposición antes de los 20, se encontró una gran cantidad de la misma profesión, pero no es más que la misma expresión, tales como el CEO y director general, tanto es un profesional
data.groupby('contbr_occupation')['contb_receipt_amt'].sum().sort_values(ascending=False)[:20]
2.13 utilizando la función de conversión de datos: Ocupación y análisis de la información del empleador
muchas ocupaciones implican el mismo tipo básico de trabajo, de limpieza tales datos (donde el uso inteligente de dict.get Permite ninguna asignación de la ocupación que se deje "de ")
#建立一个职业对应字典,把相同职业的不同表达映射为对应的职业,比如把C.E.O.映射为CEO
occupation_map = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',
}
# 如果不在字典中,返回x
f = lambda x: occupation_map.get(x, x)
data.contbr_occupation = data.contbr_occupation.map(f)
#data.contbr_occupation相当于上面语句中的x
#data.contbr_occupation返回的结果与occupation_map中的键进行映射,如果相同返回对应的值,如果不同返回默认值
#contbr_occupation – 捐赠人职业
data.contbr_occupation.head()
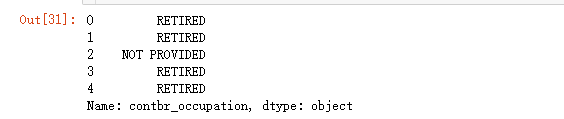
Del mismo modo, una información de conversión similar para los empleadores
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
}
# If no mapping provided, return x
f = lambda x: emp_mapping.get(x, x)
data.contbr_employer = data.contbr_employer.map(f)
Aquí le mostramos dict.get uso ()
dict_data ={1:'one',2:'two',3:'three',4:'four'}
print(dict_data.get(1))
print(dict_data.get(3))
print(dict_data.get(5))
print(dict_data.get(5,'notfound'))
salida

# 字典的get方法
# 如:list.get(k,d) 其中 get相当于一条if...else...语句,参数k在字典中,字典将返回list[k];如果参数k不在字典中则返回参数d,如果K在字典中则返回k对应的value值
# l = {5:2,3:4}
# print l.get(3,0)返回的值是4;
# Print l.get(1,0)返回值是0
3.1 Los datos de detección
de patrocinio incluye un reembolso (contribución negativa), con el fin de simplificar el análisis, hemos limitado conjunto de datos única contribución positiva
data = data[data['contb_receipt_amt']>0]

3.2 vista de cada candidato a la cantidad total de patrocinio, contb_receipt_amt - cantidad donada (US $), cand_nm - nombres de los candidatos a aceptar donaciones
data.groupby('cand_nm')['contb_receipt_amt'].sum().sort_values(ascending=False)

Como se puede ver de lo anterior, el objetivo básico de patrocinio entre Obama, Romney, con el fin de enfocar mejor la competencia entre los dos, se seleccionaron los datos sub-conjunto de estos dos candidatos para su posterior análisis
3.3 seleccionar a los candidatos para Obama, Romney un subconjunto de los datos
data_vs = data[data['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])].copy()
#data['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])返回的是一个bool类型的值
# data[bool]返回的是具体的数据,所有为true的数据
#data.copy()把返回的数据进行复制
data_vs.head()
3.4 datos discretos, datos discretos con un corte
bins = np.array([0,1,10,100,1000,10000,100000,1000000,10000000])
labels = pd.cut(data_vs['contb_receipt_amt'],bins)
labels.head()

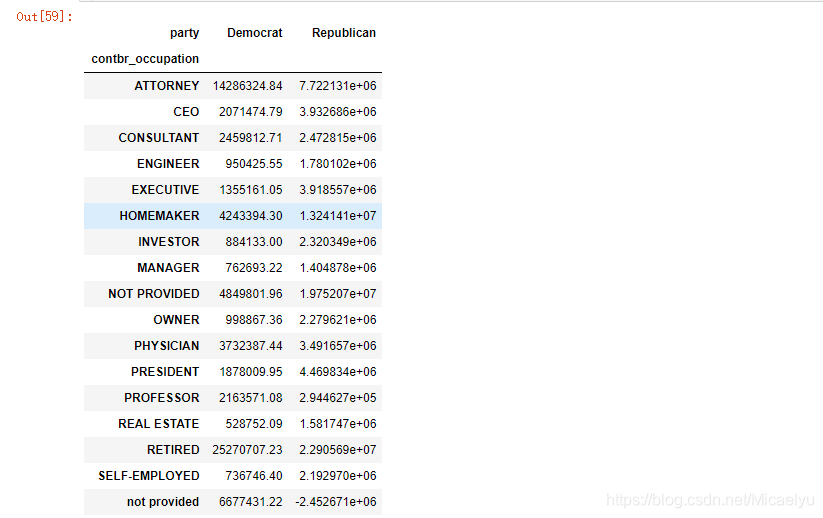
3.6 Parte de conformidad con, la cantidad de ocupación de resumen de patrocinio, la operación es similar a Excel en la tabla dinámica, una función de suma de polimerización
by_occupation = data.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='party',aggfunc='sum')
#过滤掉赞助金额小于200W的数据
over_2mm = by_occupation[by_occupation.sum(1)>2000000]
over_2mm
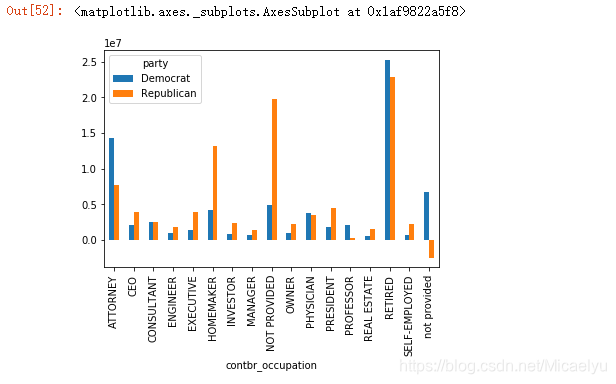
3.7 Dibujo
over_2mm.plot(kind='bar')
3.8 basada en la ocupación y empleador de la transferencia de paquetes de información
que se van a ver en la inversión más alta profesional y los empleadores Obama y Romney total. Nótese que este uso inteligente de dict.get, permite que ninguna asignación de la ocupación que ser "a través de"
def get_top_amounts(group,key,n=5):
#传入groupby分组后的对象,返回按照key字段汇总的排序前n的数据
totals = group.groupby(key)['contb_receipt_amt'].sum()
return totals.sort_values(ascending=False)[:n]
grouped = data_vs.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_occupation',n=7)
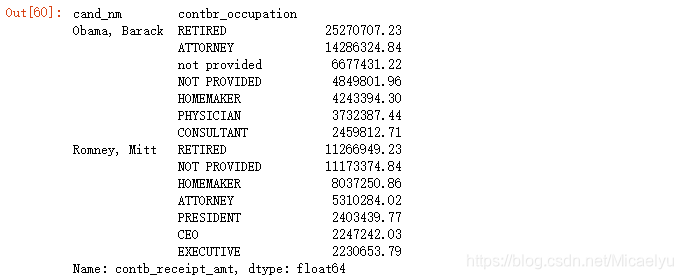
3.9 De manera similar, los get_top_amounts uso () análisis y procesamiento de empleador
grouped.apply(get_top_amounts,'contbr_employer',n=10)
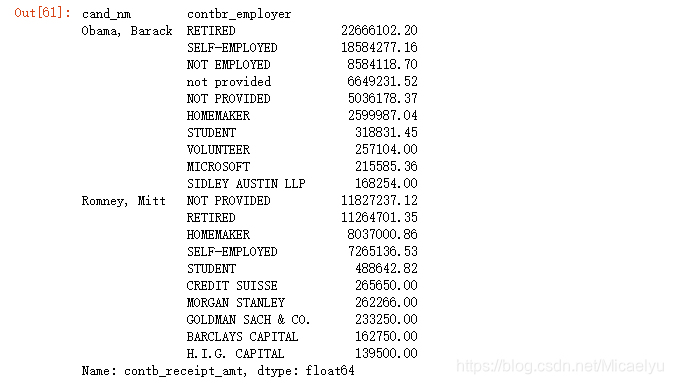
3.10labels con el patrocinio de la serie antes de que la cantidad discreta
grouped_bins = data_vs.groupby(['cand_nm',labels])
grouped_bins.size().unstack(0)
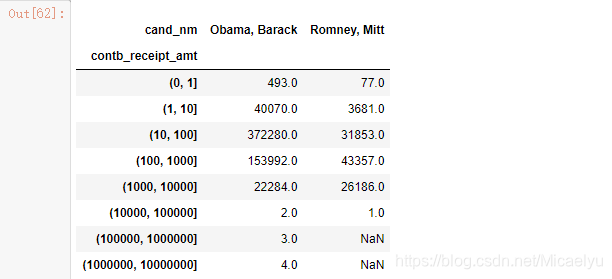
3.11 A continuación, nos cuenta la cantidad de patrocinio para cada región
bucket_sums=grouped_bins['contb_receipt_amt'].sum().unstack(0)
bucket_sums
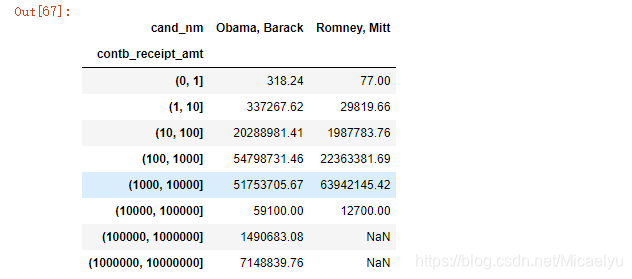
Spots un pequeño experimento
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data11=DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['street1','street2']),columns=pd.Index(['one','two','three']))
print(data11)
print('-----------------------------------------\n')
data2=data11.stack()
data3=data2.unstack()
print(data2)
print('-----------------------------------------\n')
print(data3)
Resultados:
 El uso de la pila función, los datos del índice de la fila [ 'uno', 'dos' , 'tres'] en un índice de la columna (segunda capa), dará una serie jerárquica (data2), utilizando la función de desapilamiento, el índice de la fila de transición esméctica segundo índice data2 (el valor predeterminado se puede cambiar), a su vez obtiene trama de datos (Data3)
El uso de la pila función, los datos del índice de la fila [ 'uno', 'dos' , 'tres'] en un índice de la columna (segunda capa), dará una serie jerárquica (data2), utilizando la función de desapilamiento, el índice de la fila de transición esméctica segundo índice data2 (el valor predeterminado se puede cambiar), a su vez obtiene trama de datos (Data3)
este experimento demostró una pila función principal y la función de desapilamiento
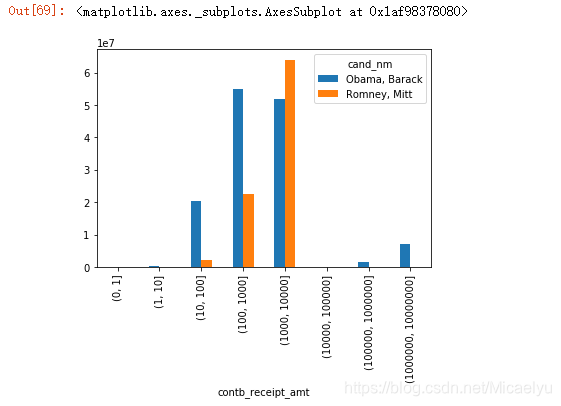
3.12Obama, Romney cada sección de la cantidad total de patrocinio
bucket_sums.plot(kind='bar')
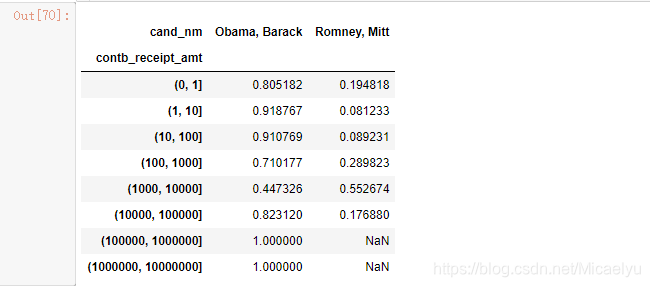
3,13 calculada para cada intervalo de dos candidatos reciben la proporción de la cantidad total de patrocinio
normed_sums = bucket_sums.div(bucket_sums.sum(axis=1),axis=0)
normed_sums
3,14 utilizando el histograma, especificados apilados = True apilados para completar el mayor porcentaje figura
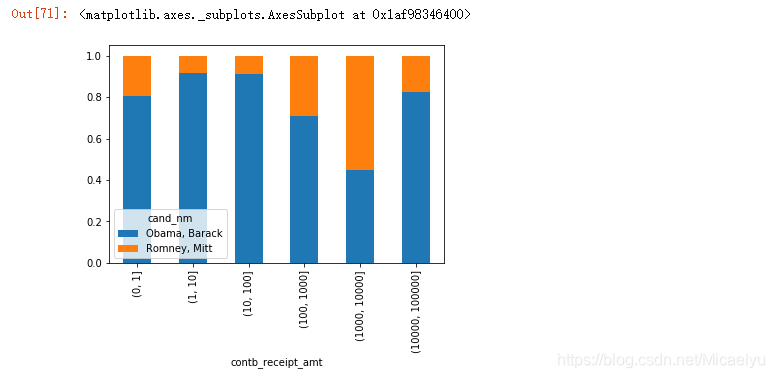 se puede ver, una pequeña relación de patrocinio, número y cantidad obtenida Romney Obama mucho
se puede ver, una pequeña relación de patrocinio, número y cantidad obtenida Romney Obama mucho
3,15 Nombre del patrocinador de acuerdo con los tiempos de cálculo recuento de paquetes de patrocinio repetidas la mayor parte de las primeras 20 personas
data.groupby('contbr_nm')['contbr_nm'].count().sort_values(ascending=False)[:20]

4.1str convertir DataTime
podemos usar una variedad de métodos analíticos representación de fecha to_datetime. Analiza el formato de fecha estándar (tales como ISO8601) muy rápidamente. Podemos especificar una fecha específica de análisis de formatos, tales como pd.to_datetime (serie, format = '% Y% m% d')
data_vs['time'] = pd.to_datetime(data_vs['contb_receipt_dt'])
data_vs['time'].head()
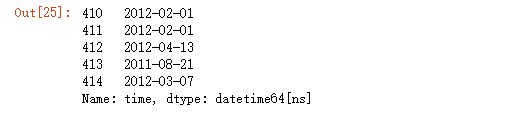
4.2 tiempo que el índice
data_vs.set_index('time',inplace=True)
data_vs.head()
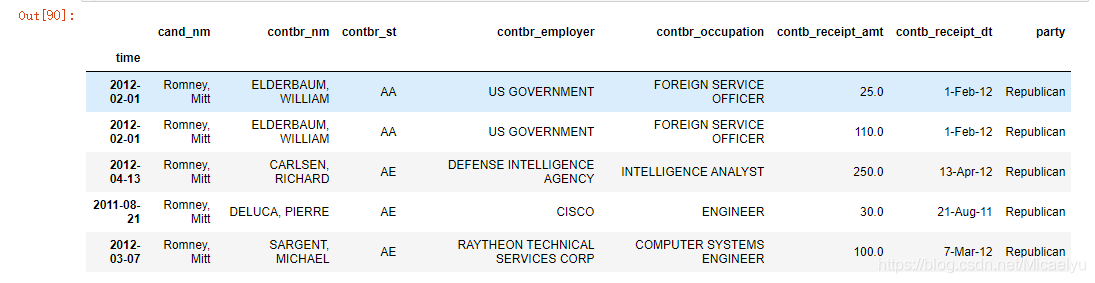
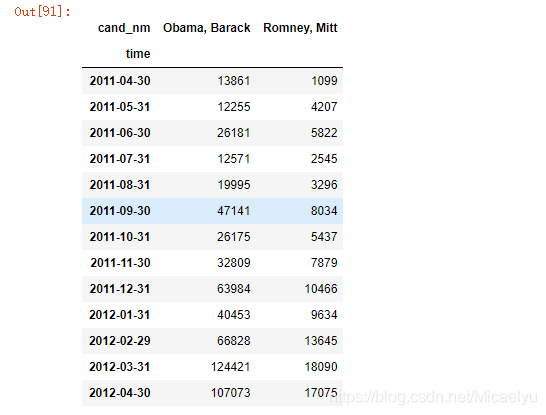
4,3 remuestreo y la conversión de frecuencia
Remuestreo (remuestreo) se refiere a la frecuencia de la serie de tiempo se convierte en la frecuencia del otro proceso. Los datos de alta frecuencia a una frecuencia baja, llamada reducción de muestreo (muestreo descendente), volver a muestrear el paquete de datos a continuación, llamar a las funciones de agregado. Aquí convertimos la frecuencia de diaria a mensual, son de alta frecuencia de baja frecuencia de muestreo de roll-off.
vs_time = data_vs.groupby('cand_nm').resample('M')['cand_nm'].count()
vs_time.unstack(0)
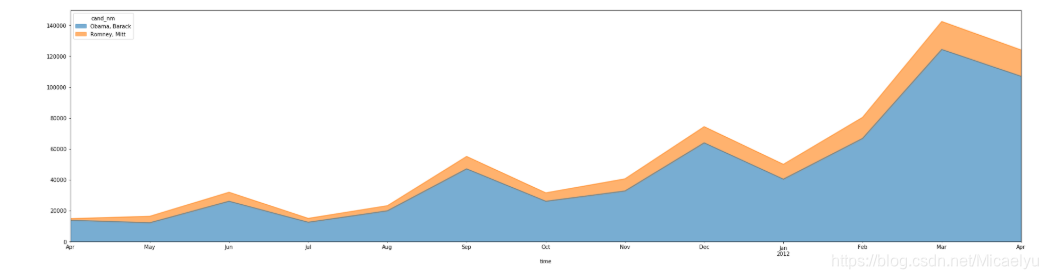
4.4 Utilizamos un gráfico de áreas a abril 11 --12 de abril de los dos candidatos a aceptar artículos de patrocinio a ser un contraste se puede ver, cuanto más cerca de las elecciones, más patrocinamos el gran entusiasmo, Obama en cada período están ocupadas absolutamente ventaja
fig1, ax1=plt.subplots(figsize=(32,8))
vs_time.unstack(0).plot(kind='area',ax=ax1,alpha=0.6)
plt.show()
En este artículo el código en mi cuenta de GitHub en: enlace de la cuenta de github
https://github.com/michael-wy/data-analysis
