

A medida que la industria SaaS crece rápidamente, se necesitan arquitecturas dinámicas y adaptables para manejar la afluencia de datos en tiempo real. Aquí se explica cómo construirlos.
Traducido de Cómo construir una arquitectura de plataforma escalable para datos en tiempo real , autora Christina Lin.
La industria del software como servicio (SaaS) está mostrando un crecimiento imparable, y se espera que el tamaño del mercado alcance los 317.555 millones de dólares en 2024 y casi se triplique hasta los 1.22887 millones de dólares en 2032 . Este crecimiento pone de relieve la creciente necesidad de estrategias de datos mejoradas y sólidas. Esta tendencia está impulsada por el creciente volumen, velocidad y diversidad de datos generados por las empresas y la integración de la inteligencia artificial.
Sin embargo, este panorama creciente trae consigo varios desafíos importantes, como la gestión del tráfico pico, la transición del procesamiento de transacciones en línea (OLTP) al procesamiento analítico en línea (OLAP) en tiempo real, garantizar el autoservicio y el desacoplamiento, y volverse independiente de la nube y multidisciplinario. despliegue de la región. Para abordar estos desafíos se requiere un marco arquitectónico sofisticado que garantice una alta disponibilidad y mecanismos sólidos de conmutación por error sin comprometer el rendimiento del sistema.
La arquitectura de referencia de este artículo detalla cómo crear una plataforma de datos escalable, automatizada y flexible para respaldar la creciente industria de SaaS. Esta arquitectura respalda las necesidades técnicas de procesamiento de datos a gran escala y, al mismo tiempo, se alinea con las necesidades comerciales de agilidad, rentabilidad y cumplimiento normativo.
Desafíos técnicos de los servicios SaaS con uso intensivo de datos
A medida que la demanda de servicios y volúmenes de datos continúa creciendo, surgen varios desafíos comunes en la industria SaaS.
Manejar los picos y las ráfagas de tráfico es fundamental para asignar recursos de manera eficiente para hacer frente a patrones de tráfico variables. Esto requiere aislar cargas de trabajo, escalar durante las cargas de trabajo pico y reducir los recursos informáticos durante las horas de menor actividad, evitando al mismo tiempo la pérdida de datos.
Mantener OLTP en tiempo real para OLAP significa admitir sin problemas OLTP, que gestiona grandes volúmenes de transacciones rápidas con un enfoque en la integridad de los datos, y sistemas OLAP que admiten conocimientos analíticos rápidos. Este soporte dual es fundamental para respaldar consultas analíticas complejas y mantener el máximo rendimiento. También juega un papel clave en la preparación de conjuntos de datos para el aprendizaje automático (ML).
Habilitar el autoservicio y el desacoplamiento requiere dotar a los equipos de capacidades de autoservicio para crear y gestionar temas y clústeres sin depender en gran medida de un equipo de TI central. Esto acelera el desarrollo al tiempo que permite desacoplar aplicaciones y servicios y lograr una escalabilidad independiente.
Promover el agnosticismo y la estabilidad de la nube permite la agilidad y la capacidad de operar en diferentes entornos de nube como AWS , Microsoft Azure o
Cómo construir una arquitectura compatible con SaaS
Para abordar estos desafíos, las grandes empresas de SaaS a menudo adoptan un marco arquitectónico que implica ejecutar múltiples clústeres que abarcan múltiples regiones y son administrados por un plano de control desarrollado a medida. El diseño del plano de control mejora la flexibilidad de la infraestructura subyacente al tiempo que simplifica la complejidad de las aplicaciones conectadas a ella.
Si bien esta estrategia es fundamental para una alta disponibilidad y un mecanismo de conmutación por error sólido, también puede volverse demasiado compleja para mantener el rendimiento uniforme y la integridad de los datos en un clúster distribuido geográficamente, y mucho menos sin afectar el rendimiento o introducir latencia. Los desafíos de aumentar o reducir los recursos. surgir.
Además, ciertos escenarios pueden requerir que los datos se aíslen dentro de un clúster específico por razones de cumplimiento o seguridad. Para ayudarle a construir una arquitectura robusta y flexible que evite estas complejidades, le explicaré algunas sugerencias.
1. Establecer una base estable
Un desafío importante para los servicios SaaS es la asignación de recursos para manejar diversos patrones de tráfico, incluidas consultas en línea de alta frecuencia y gran volumen, inserción de datos e intercambio de datos internos.
Convertir el tráfico en procesos asincrónicos es una solución común que permite un escalamiento más eficiente y una asignación rápida de recursos informáticos. Las plataformas de transmisión de datos como Apache Kafka son ideales para gestionar eficientemente cantidades masivas de datos. Pero gestionar una plataforma de datos distribuidos como Kafka conlleva su propia serie de desafíos. El sistema de Kafka es conocido por su complejidad técnica, ya que requiere gestionar la coordinación, sincronización y escalamiento del clúster, así como protocolos adicionales de seguridad y recuperación. Desafíos en Kafka
La máquina virtual Java (JVM) en Kafka también puede provocar picos de latencia impredecibles, principalmente debido al proceso de recolección de basura de la JVM. Administrar la asignación de memoria de la JVM y ajustar los requisitos de alto rendimiento de Kafka es notoriamente tedioso y puede afectar la estabilidad general del broker Kafka.
Otro obstáculo es la gestión de la política de datos de Kafka. Esto incluye la gestión de políticas de retención de datos, la compresión de registros y la eliminación de datos, al mismo tiempo que se equilibran los costos de almacenamiento, el rendimiento y el cumplimiento hasta cierto punto.
En resumen, gestionar eficazmente sistemas basados en Kafka en un entorno SaaS es complicado. Como resultado, muchas empresas de SaaS están recurriendo a alternativas de Kafka que proporcionan transmisión de datos altamente escalable sin la necesidad de dependencias externas como JVM o ZooKeeper.
2. Habilite la transmisión de datos de autoservicio
Existe una demanda creciente de soluciones de autoservicio que permitan a los desarrolladores crear temas desde el desarrollo hasta la producción. El servicio de infraestructura o plataforma debe proporcionar una solución con control centralizado, proporcionar detalles de inicio de sesión y automatizar la rápida creación e implementación de recursos en varias plataformas y etapas.
Esto plantea la necesidad de un plano de control, que se presenta en muchas formas. Algunos planos de control solo se utilizan para gestionar el ciclo de vida de un clúster o tema y asignar permisos en la plataforma de streaming. Otros planos de control añaden una capa de abstracción al virtualizar objetivos y ocultar detalles de la infraestructura a usuarios y clientes.
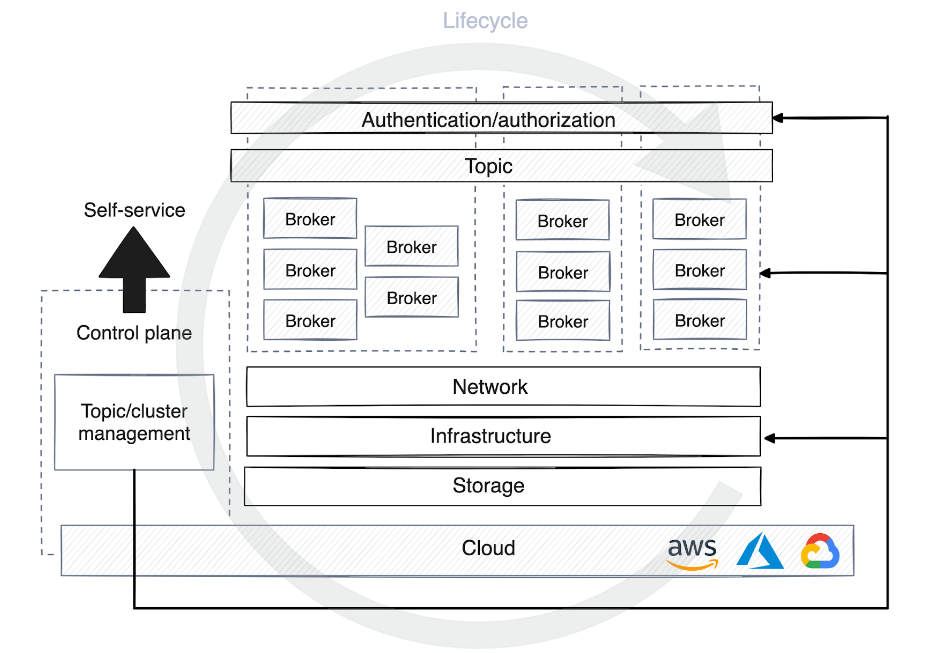
Cuando un tema se registra en el plano de control de la plataforma de datos de autoservicio, se aplican diferentes estrategias de optimización de recursos informáticos según la etapa del entorno. En el desarrollo, los temas a menudo comparten grupos con otros procesos, se enfatiza menos la retención de datos y la mayoría de los datos se descartan en unos pocos días.
Sin embargo, en producción, la asignación de recursos debe planificarse cuidadosamente en función del volumen de tráfico. Esta planificación incluye determinar la cantidad de particiones para los consumidores, establecer políticas de retención de datos, decidir la ubicación de los datos y considerar si necesita un clúster dedicado para casos de uso específicos.
Para el plano de control, resulta muy útil automatizar el proceso de gestión del ciclo de vida de la plataforma de streaming. Esto permite que el plano de control depure agentes de forma autónoma, supervise las métricas de rendimiento e inicie o detenga el reequilibrio de particiones para mantener la disponibilidad y estabilidad de la plataforma a escala.
3. Soporte en tiempo real para OLTP y OLAP
El cambio del procesamiento por lotes al análisis en tiempo real hace que la integración de los sistemas OLAP en la infraestructura existente sea crítica. Sin embargo, estos sistemas suelen manejar grandes cantidades de datos y requieren modelos de datos complejos para un análisis multidimensional en profundidad.
OLAP se basa en múltiples fuentes de datos y, dependiendo de la madurez de la empresa, generalmente hay un almacén de datos o un lago de datos para almacenar los datos, así como canales de procesamiento por lotes que se ejecutan periódicamente (generalmente todas las noches) para mover datos desde las fuentes de datos. . Este proceso fusiona datos de varios sistemas OLTP y otras fuentes, un proceso que puede volverse complejo a la hora de mantener la calidad y coherencia de los datos.
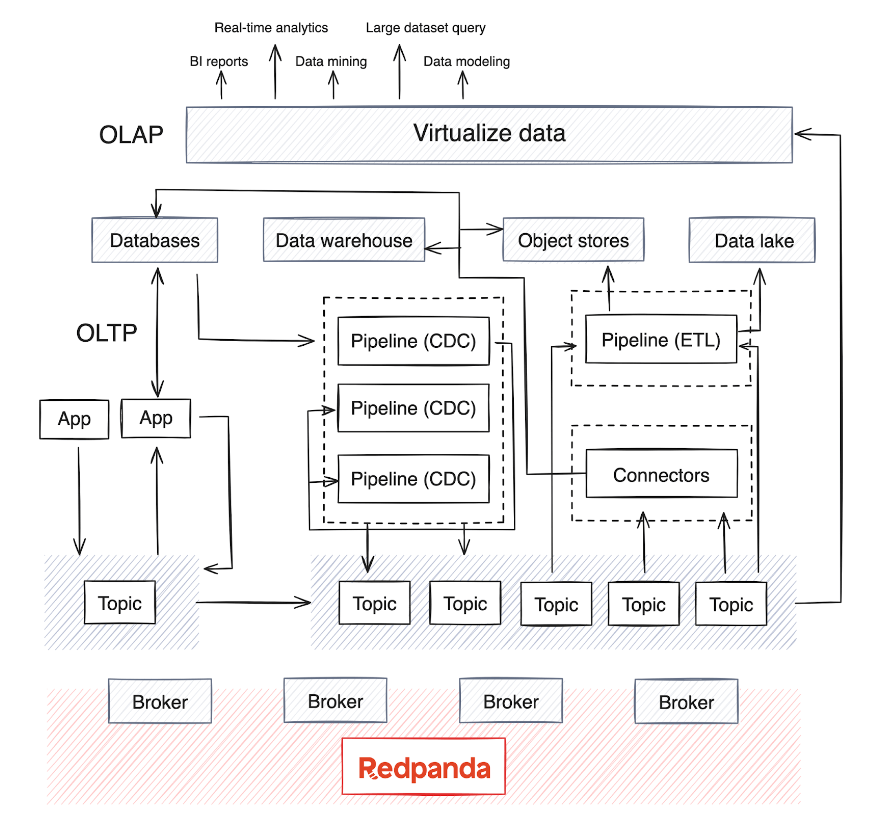
Hoy en día, OLAP también integra modelos de IA con grandes conjuntos de datos. La mayoría de los motores de procesamiento de datos distribuidos y las bases de datos de transmisión ahora admiten el consumo, la agregación, el resumen y el análisis en tiempo real de datos de transmisión desde fuentes como Kafka o Redpanda. Esta tendencia ha llevado al aumento de canalizaciones de extracción, transformación, carga (ETL) y extracción, carga y transformación (ELT) para datos en tiempo real, así como canalizaciones de captura de datos modificados (CDC) que transmiten registros de eventos desde bases de datos.
Las canalizaciones en tiempo real, normalmente implementadas en Java , Python o Golang, requieren una planificación cuidadosa. Para optimizar el ciclo de vida de estos ductos, las empresas de SaaS están incorporando la gestión del ciclo de vida de los ductos en sus planos de control para optimizar el monitoreo y la alineación de recursos.
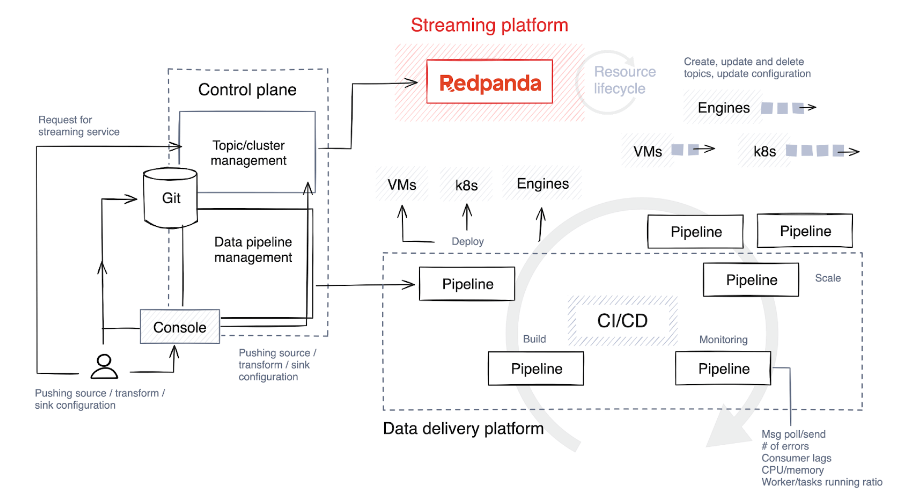
4. Comprender (y optimizar) el ciclo de vida del canal de datos
El primer paso es elegir una pila de tecnología y determinar el nivel de libertad y personalización que disfrutarán los usuarios que crean canalizaciones. Lo ideal sería permitirles seleccionar diversas tecnologías para diferentes tareas e implementar barreras de seguridad para limitar la construcción y expansión de tuberías.
La siguiente es una breve descripción de las etapas involucradas en el ciclo de vida de la tubería.
Construir y probar
El código fuente se envía a un repositorio de Git, ya sea directamente por los desarrolladores de canalizaciones o mediante herramientas personalizadas en el plano de control. Luego, este código se compila en código binario o en un programa ejecutable utilizando un lenguaje como C++, Java o C#. Después de la compilación, el código se empaqueta en un artefacto, un proceso que también puede implicar agrupar dependencias autorizadas y archivos de configuración.
Luego, el sistema ejecuta pruebas automatizadas para verificar el código. Durante las pruebas, el plano de control crea temas temporales específicamente para este propósito y estos temas se destruyen tan pronto como se completa la prueba.
desplegar
Los artefactos se implementan en máquinas virtuales (como Kubernetes ) o bases de datos de transmisión, según la pila de tecnología. Algunas plataformas ofrecen enfoques más creativos para las estrategias de lanzamiento, como implementaciones azules/verdes, que permiten una reversión rápida y minimizan el tiempo de inactividad. Otra estrategia es la versión canary, donde se aplica una nueva versión solo a una pequeña porción de los datos, reduciendo así el impacto de posibles problemas.
Las desventajas de estas estrategias son que las reversiones pueden resultar desafiantes y puede resultar difícil aislar los datos afectados por la nueva versión. A veces es más sencillo realizar una versión completa y revertir todo el conjunto de datos.
Expandir
Muchas plataformas admiten el escalado automático, como ajustar la cantidad de instancias en ejecución según el uso de la CPU, pero el nivel de automatización varía. Algunas plataformas proporcionan esta funcionalidad de forma nativa, mientras que otras requieren configuración manual, como establecer el número máximo de tareas paralelas o procesos de trabajo por trabajo.
Durante la implementación, el plano de control proporciona configuraciones predeterminadas basadas en la demanda anticipada, pero continúa monitoreando de cerca las métricas. Luego asigna recursos adicionales al tema escalando la cantidad de procesos, tareas o instancias de trabajo según sea necesario.
monitor
Monitorear las métricas correctas en su canalización y mantener la observabilidad son formas principales de detectar problemas tempranamente. A continuación se presentan algunas métricas clave que debe monitorear de manera proactiva para garantizar la eficiencia y confiabilidad de su proceso de procesamiento de datos.
Indicadores de recursos
- El uso de CPU y memoria es fundamental para comprender cómo se consumen los recursos.
- La E/S de disco es importante para evaluar la eficiencia de las operaciones de almacenamiento y recuperación de datos.
Rendimiento y latencia
- Los registros de entrada/salida miden la velocidad de procesamiento de datos por segundo.
- Los registros procesados por segundo representan la potencia de procesamiento del sistema.
- La latencia de un extremo a otro es el tiempo total que lleva desde la entrada de datos hasta la salida, lo cual es fundamental para el rendimiento del procesamiento en tiempo real.
Contrapresión e histéresis
- Estos ayudan a identificar cuellos de botella en el procesamiento de datos y prevenir posibles ralentizaciones.
Tasa de error
- Las tasas de error de seguimiento ayudan a mantener la integridad de los datos y la confiabilidad del sistema
5. Mejorar la confiabilidad, la redundancia y la resiliencia
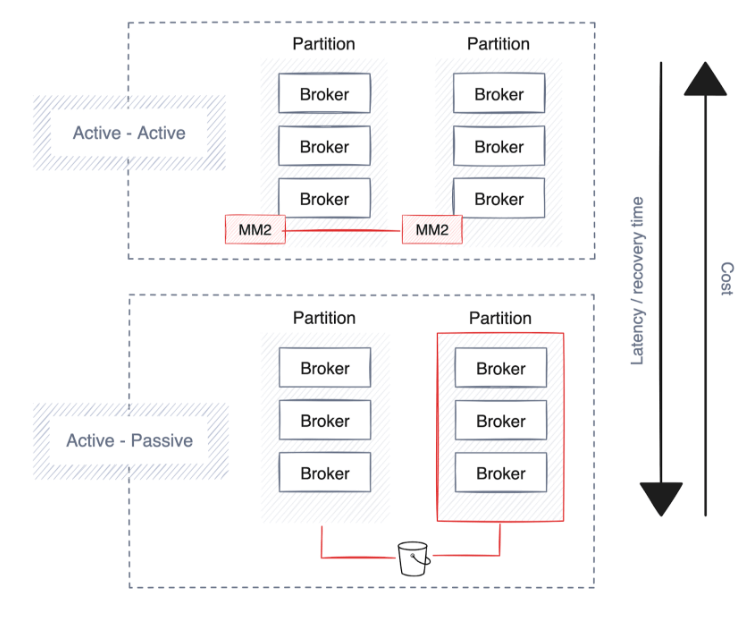
Las empresas dan prioridad a la alta disponibilidad, la recuperación ante desastres y la resiliencia para mantener operaciones continuas durante las interrupciones. La mayoría de las plataformas de transmisión de datos ya cuentan con sólidas salvaguardias y estrategias de implementación integradas, principalmente mediante la extensión de clústeres a través de múltiples particiones, centros de datos y zonas de disponibilidad independientes de la nube.
Sin embargo, implica compensaciones, como una mayor latencia, una posible duplicación de datos y mayores costos. A continuación se ofrecen algunas sugerencias a la hora de planificar la alta disponibilidad, la recuperación ante desastres y la resiliencia.
Alta disponibilidad
Un proceso de implementación automatizado gestionado por el plano de control desempeña un papel clave a la hora de establecer una estrategia sólida de alta disponibilidad . Esta estrategia garantiza que las canalizaciones, los conectores y las plataformas de transmisión se distribuyan estratégicamente entre zonas o particiones de disponibilidad según el proveedor de la nube o el centro de datos.

Es fundamental que las plataformas de datos distribuyan todas las canalizaciones de datos en múltiples zonas de disponibilidad (AZ) para reducir el riesgo. La continuidad se respalda mediante la ejecución de copias redundantes de canalizaciones en diferentes zonas de disponibilidad para mantener el procesamiento de datos ininterrumpido en caso de que falle la partición.
Las plataformas de transmisión subyacentes a la arquitectura de datos deberían hacer lo mismo y replicar automáticamente los datos en múltiples zonas de disponibilidad para mejorar la resiliencia. Soluciones como Redpanda pueden automatizar la distribución de datos entre particiones, mejorando la confiabilidad y la tolerancia a fallas de la plataforma.
Sin embargo, considere los posibles costos asociados del ancho de banda de la red, teniendo en cuenta la ubicación de sus aplicaciones y servicios. Por ejemplo, mantener las tuberías cerca de los almacenes de datos puede reducir la latencia y los gastos generales de la red y, al mismo tiempo, reducir los costos.
recuperación de desastres
Una recuperación de fallas más rápida conlleva costos más altos debido a una mayor replicación de datos, lo que genera una mayor sobrecarga de ancho de banda y requiere una configuración siempre activa (activa-activa), lo que duplica el uso de hardware. No todas las tecnologías de transmisión ofrecen esta funcionalidad, pero las plataformas de nivel empresarial como Redpanda admiten copias de seguridad de datos y metadatos de clústeres en el almacenamiento de objetos en la nube.
elasticidad
Además de la alta disponibilidad y la recuperación ante desastres, algunas empresas globales requieren estrategias de implementación regional para garantizar que su almacenamiento y procesamiento de datos cumplan con regulaciones geográficas específicas. En cambio, las empresas que desean compartir datos en tiempo real entre diferentes regiones con una administración mínima a menudo crean un clúster compartido que permite a los agentes replicar y distribuir datos entre regiones.
Sin embargo, este enfoque genera importantes costos de red y latencia, ya que los datos se transfieren continuamente a las siguientes particiones. Para aliviar el tráfico de datos, la recuperación de seguidores indica al consumidor de datos que lea datos de la partición de seguidores geográficamente más cercana.
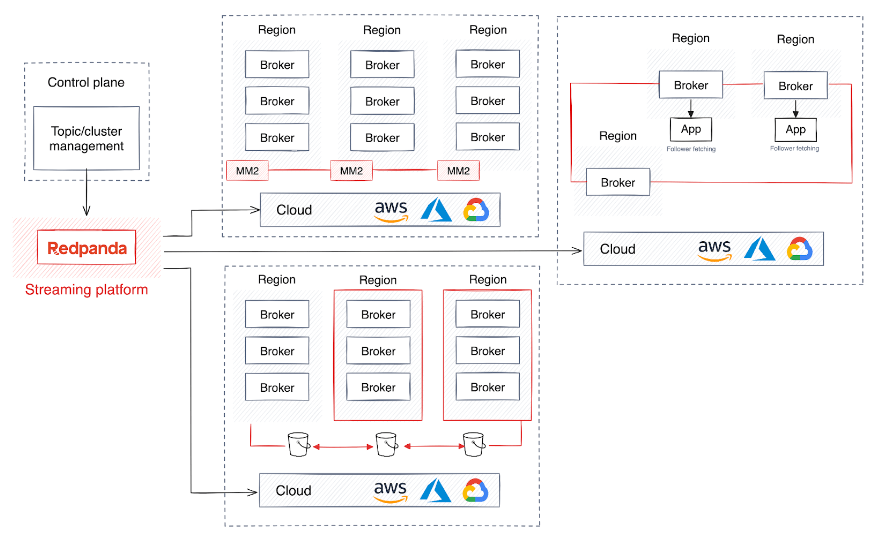
Además, ampliar los clústeres para el reabastecimiento de datos mejora el equilibrio de carga entre los centros de datos. Esta escalabilidad es fundamental para gestionar volúmenes de datos y tráfico de red crecientes, lo que ayuda a las empresas a escalar sin sacrificar el rendimiento o la confiabilidad.
en conclusión
A medida que las empresas se transforman a través de la transformación digital, los datos en tiempo real se vuelven cada vez más críticos para guiar la toma de decisiones. Esto implica extraer conocimientos más profundos de conjuntos de datos masivos , permitir pronósticos más precisos, optimizar los procesos automatizados de toma de decisiones y brindar servicios más personalizados, todo mientras se optimizan los costos y las operaciones.
Una opción es adoptar una arquitectura de referencia que incluya una plataforma de transmisión de datos escalable como Redpanda , un reemplazo plug-and-play de Kafka implementado en C++. Permite a las empresas evitar el tiempo real al facilitar un escalamiento fluido, una API de administración que admite la automatización del ciclo de vida , almacenamiento por niveles para reducir los costos de almacenamiento , réplicas de lectura remota para simplificar la configuración de clústeres rentables de solo lectura y una distribución geográfica perfecta. complejidad del procesamiento.
Con la tecnología adecuada, los proveedores de SaaS pueden mejorar sus servicios, mejorar la experiencia del cliente y aumentar su ventaja competitiva en el mercado digital. Las estrategias futuras deberían continuar optimizando estos sistemas para lograr una mayor eficiencia y adaptabilidad para que las plataformas SaaS puedan prosperar en un mundo basado en datos.
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuroEste artículo se publicó por primera vez en Yunyunzhongsheng ( https://yylives.cc/ ), todos son bienvenidos a visitarlo.