ENet: una arquitectura de red neuronal profunda para la segmentación semántica en tiempo real
Este artículo presenta ENet, la red de segmentación de imágenes más rápida actual, utilizando una gran cantidad de trucos.
Resumen
En los dispositivos de borde, la potencia de cálculo en tiempo real es importante, y la desventaja de las redes neuronales profundas para esta tarea es que requieren muchos cálculos de punto flotante y tienen tiempos de ejecución prolongados, lo que dificulta su usabilidad.
- Este artículo presenta ENet, una novedosa arquitectura de red neuronal profunda para redes neuronales eficientes, creada específicamente para tareas que requieren operación de baja latencia.
- ENet es 18 veces más rápido, requiere 75 veces menos flops, tiene 79 veces menos parámetros y proporciona una precisión similar o mayor que los modelos existentes.
introducción
- La clasificación espacial original y la arquitectura de segmentación fina para imágenes: SegNet o red totalmente convolucional se basan en VGG16, pero estas arquitecturas son modelos muy grandes diseñados para clasificación de clases múltiples, por lo que estos modelos tienen una gran cantidad de parámetros y una red de razonamiento de tiempo larga. .
- ENET Nueva arquitectura de red neuronal optimizada para una inferencia rápida y alta precisión
estructura de red
módulo de cuello de botella en ENet
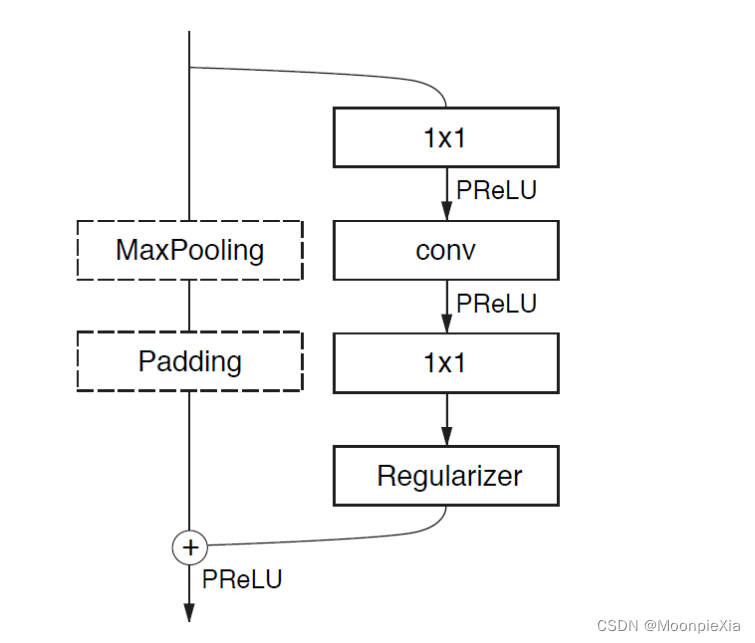
El de la izquierda es secundario, el de la derecha es primario.
cinco etapas
Inicializar el módulo
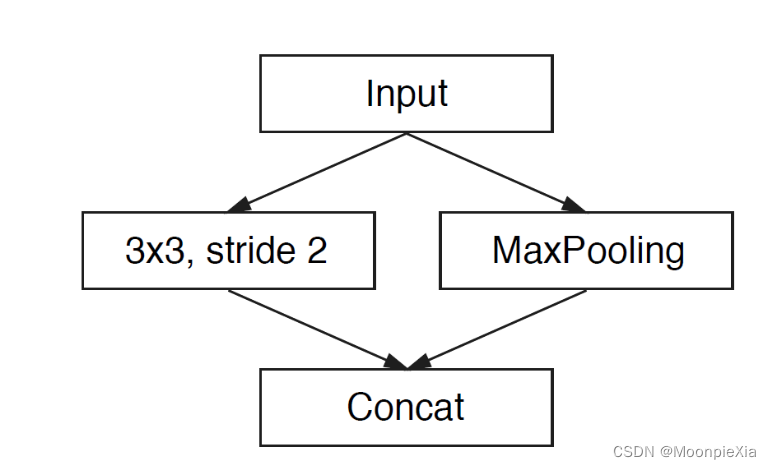
A la izquierda, se utilizan trece núcleos de convolución para la operación de convolución, y a la derecha está MaxPooling, y finalmente se obtienen tres canales, y los resultados de ambos lados se concatenan para fusionar canales, lo que puede reducir el espacio de almacenamiento.
Nivel 1
Pertenece a la etapa del codificador e incluye cinco cuellos de botella; el primer cuello de botella reduce la resolución de la entrada, seguido de cuatro cuellos de botella repetidos.
etapa 2-3
Perteneciente a la etapa del codificador, la botella 2.0 de la etapa 2 se muestra negativamente, seguida de una convolución atroz o convolución descompuesta, la etapa 3 no se muestra negativamente y las demás son iguales.
etapa 4-5
Pertenece a la etapa decodificadora. Relativamente simple, un muestreo ascendente configura dos cuellos de botella ordinarios
- La arquitectura del modelo no utiliza sesgos en ninguna proyección, lo que reduce las llamadas al kernel y las operaciones de almacenamiento.
- La norma por lotes se utiliza en cada operación de convolución.
- La etapa del codificador utiliza relleno y agrupación máxima para reducir la resolución.
- El decodificador utiliza una separación máxima con convolución de orificios para completar el muestreo ascendente
Introducir el codificador
-
Botella disminuidaCuello
- El tamaño de la imagen reducida pasa a ser 128 x 128
- Entonces la operación de convolución conv es una operación de convolución ordinaria, asimétrica significa convolución descompuesta y Dilatada es una convolución hueca.
- Cada cuello de botella primero reducirá la dimensión y luego aumentará la dimensión después de la operación de convolución.
- Cada capa convolucional va seguida de una norma por lotes y operaciones PReLU
-
Las líneas auxiliares incluyen operaciones de agrupación máxima y relleno. La agrupación máxima es responsable de extraer información de contexto.
- el relleno es responsable de llenar el canal y luego logra la fusión residual posterior y realiza la operación PReLU después de la fusión
-
Cuello de botella sin muestreo reducido
- La línea principal consta de tres capas convolucionales.
- El primero es la reducción de dimensionalidad 1x1.
- Entonces hay tres circunvoluciones.
- Finalmente, la dimensión cruda.
- Lote de normas PReLU
varios trucos
-
Para reducir las llamadas al kernel y las operaciones de almacenamiento, la arquitectura de red del autor no utiliza sesgos, solo pesos.
-
Resolución del mapa de características
- Al reducir la resolución de una imagen se pierde información de características
- Utilice la convolución de huecos para expandir el campo receptivo y recopilar más información.
-
Reducción de resolución temprana
- Procesar imágenes con tamaños relativamente grandes consumirá muchos recursos informáticos
- El modelo de inicialización de ENet reducirá en gran medida el tamaño de la entrada, porque la información visual es altamente redundante en el espacio y se puede comprimir en una representación más eficiente.
-
Tamaño del decodificador
- El codificador y el decodificador del autor no son simétricos en espejo. La mayor parte de la red implementa el codificador y una pequeña parte implementa el decodificador. El codificador realiza principalmente el procesamiento y filtrado de información, mientras que el codificador aumenta la muestra de la salida del codificador y afina los detalles.
-
Operaciones no lineales
- Generalmente, es mejor utilizar ReLU y Batch Norm antes de la capa convolucional, pero usar ReLU en ENet reduce la precisión.
- ENet tiene muy pocas capas, así que use PReLU
-
Cambios de dimensionalidad que preservan la información.
- En la fase de inicialización, el autor utiliza 3 * 3 CNN y maxpolling para realizar operaciones paralelas y luego realiza operaciones de contacto en el mapa de características. El autor descubrió que el tiempo de aceleración es diez veces
-
convolución factorizada
- Divida el núcleo de convolución n × n en n × 1 y 1 × n (propuesto por Inception V3). Puede reducir eficazmente la cantidad de parámetros y mejorar el campo receptivo del modelo.
-
convolución dilatada
-
Abandono espacial
- El abandono ordinario establecerá aleatoriamente esta parte de los elementos en 0, y SpatialDropout establecerá aleatoriamente todos los elementos en esta parte del área en 0
abandono escolar normal
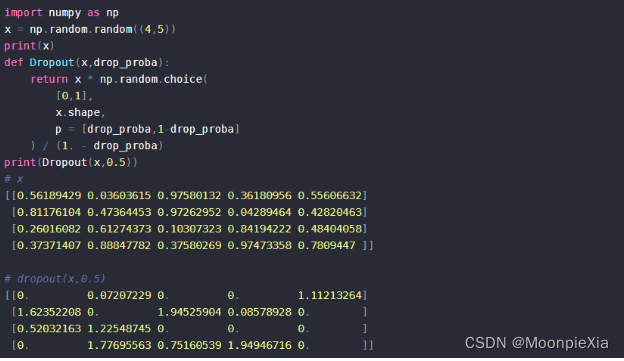
Abandono espacial: el abandono ordinario establecerá de forma aleatoria e independiente algunos elementos en cero, mientras que SpatialDropout1D establecerá aleatoriamente todos los ceros en una latitud específica.

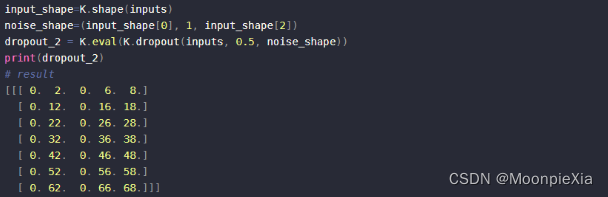
Acerca de la convolución atroz
- El tamaño del núcleo de convolución es 3 x 3 zancadas = 1 r = 2, y r se denomina factor de expansión. Cuando r = 1, significa que no hay espacio entre los elementos del núcleo de convolución, es decir, la diferencia de posición entre dos elementos adyacentes es 1, que es una convolución normal.
- Aquí r = 2 significa que hay un espacio entre cada elemento del núcleo de convolución y la diferencia de posición entre dos elementos adyacentes es 1
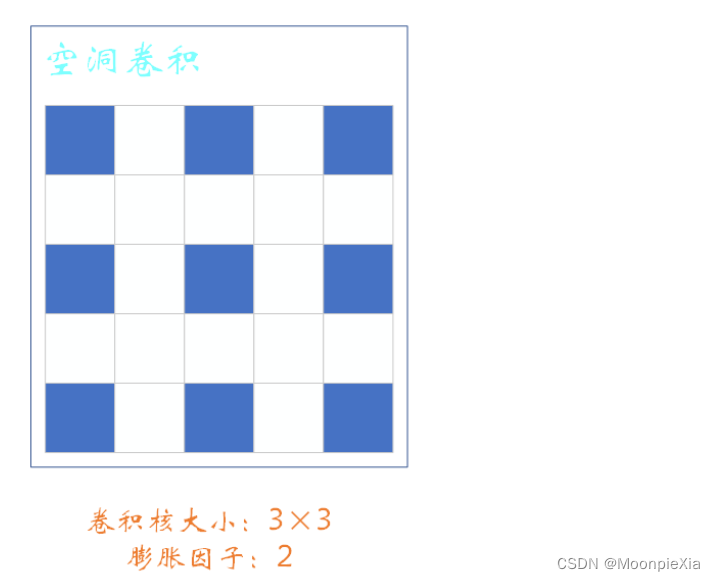
¿Por qué utilizar convolución dilatada?
Expanda el campo receptivo. El campo receptivo se refiere al tamaño de píxel de la imagen original correspondiente a un píxel del mapa de características.
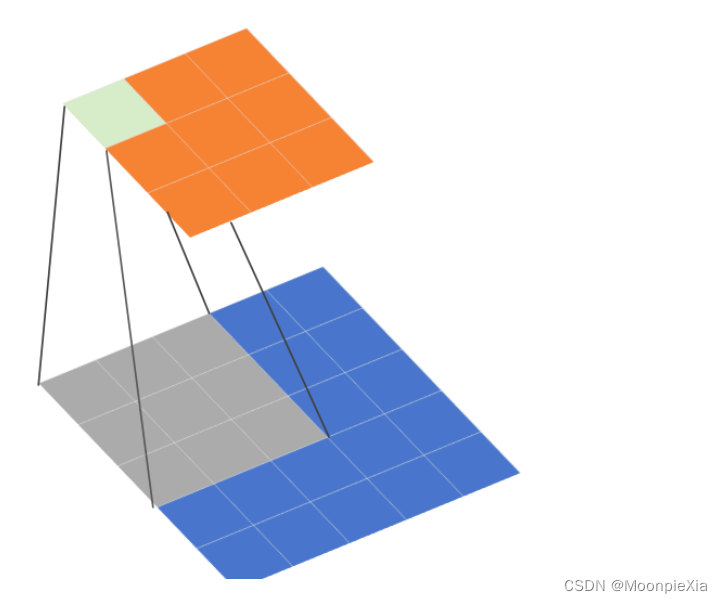
- Una razón clave para utilizar la convolución de huecos es aumentar el campo receptivo, de modo que pueda funcionar mejor en objetos de gran escala en tareas de detección y segmentación.
- El defecto de la convolución del agujero se refleja principalmente en la existencia del efecto de cuadrícula.