1. ¿Qué es la alta disponibilidad?
La alta disponibilidad HA (alta disponibilidad) es uno de los factores que se deben considerar en el diseño de la arquitectura de un sistema distribuido, generalmente se refiere a reducir el tiempo en que el sistema no puede brindar servicios a través del diseño.
Suponiendo que el sistema siempre puede brindar servicios, decimos que la disponibilidad del sistema es del 100%.
Si el sistema no puede brindar servicios por cada 100 unidades de tiempo que ejecuta, decimos que la disponibilidad del sistema es del 99%.
El objetivo de alta disponibilidad de muchas empresas es cuatro nueves, que es del 99,99%, lo que significa que el tiempo de inactividad anual del sistema es de 8,76 horas.
La página de inicio de búsqueda de Baidu es reconocida en la industria como un sistema con excelentes garantías de alta disponibilidad. La gente incluso juzga la "conectividad de la red" en función de si se puede acceder a www.baidu.com
2. Cómo garantizar una alta disponibilidad del sistema
Todos sabemos que los puntos únicos son enemigos de la alta disponibilidad del sistema. Los puntos únicos son a menudo el mayor riesgo y enemigo de la alta disponibilidad del sistema. Deberíamos tratar de evitar los puntos únicos en el proceso de diseño del sistema. Metodológicamente, el principio de garantía de alta disponibilidad es el de "clustering", o "redundancia": hay un solo punto, y si el servicio falla, el servicio se verá afectado; si hay un respaldo redundante, si falla, no habrá Habrá otras copias de seguridad que puedan hacerse cargo.
Para garantizar una alta disponibilidad del sistema, el principio básico del diseño de la arquitectura es: la redundancia.
Tener redundancia no es suficiente, cada vez que ocurre una falla, se requiere una intervención manual para restaurarla, lo que inevitablemente aumentará la inservibilidad del sistema. Por lo tanto, la alta disponibilidad del sistema a menudo se logra mediante la " conmutación por error automática ".
A continuación, veamos cómo garantizar la alta disponibilidad del sistema mediante redundancia + conmutación por error automática en una arquitectura de Internet típica .
3. Arquitectura en capas común de Internet

Las arquitecturas distribuidas de Internet comunes son las anteriores, divididas en:
(1) Capa de cliente : la persona que llama típica es una aplicación de navegador o aplicación móvil
(2) Capa de proxy inverso : entrada al sistema, proxy inverso
(3) Capa de aplicación del sitio : implemente la lógica central de la aplicación y devuelva html o json
(4) Capa de servicio : si se realiza la servitización, existirá esta capa
(5) Capa de caché de datos : el caché acelera el acceso al almacenamiento
(6) Capa de base de datos : almacenamiento de datos solidificados en la base de datos
La alta disponibilidad de todo el sistema se logra de manera integral mediante redundancia + conmutación por error automática en cada capa.
4. Práctica de arquitectura de alta disponibilidad en capas
4.1 Alta disponibilidad de [Capa de cliente->Capa de proxy inverso]

La alta disponibilidad desde la [Capa de cliente] a la [Capa de proxy inverso] se logra mediante la redundancia de la capa de proxy inverso. Tome nginx como ejemplo: hay dos nginx, uno proporciona servicios en línea y el otro es redundante para garantizar una alta disponibilidad. Una práctica común es mantener activa la detección de supervivencia y la misma IP virtual proporciona servicios.

Conmutación por error automática : cuando nginx cuelga, keepalived puede detectarlo, realizar una conmutación por error automáticamente y migrar automáticamente el tráfico a Shadow-nginx. Dado que se utiliza la misma IP virtual, este proceso de conmutación es transparente para la persona que llama.
4.2 Alta disponibilidad de [capa de proxy inverso -> capa de sitio]

La alta disponibilidad desde [capa de proxy inverso] a [capa de sitio] se logra mediante la redundancia en la capa de sitio. Suponiendo que la capa de proxy inverso es nginx, se pueden configurar múltiples backends web en nginx.conf y nginx puede detectar la viabilidad de múltiples backends.

Conmutación por error automática : cuando el servidor web se bloquea, nginx puede detectarlo, realizar una conmutación por error automáticamente y migrar automáticamente el tráfico a otros servidores web. Nginx completa automáticamente todo el proceso y es transparente para la persona que llama.
4.3 Alta disponibilidad de [capa de sitio -> capa de servicio]

La alta disponibilidad desde [capa de sitio] a [capa de servicio] se logra mediante la redundancia en la capa de servicio. El "grupo de conexiones de servicio" establecerá múltiples conexiones con servicios descendentes, y cada solicitud seleccionará "al azar" una conexión para acceder al servicio descendente.

Conmutación por error automática : cuando el servicio cuelga, el grupo de conexiones de servicio puede detectarlo, realizar una conmutación por error automáticamente y migrar automáticamente el tráfico a otros servicios. Todo el proceso lo completa automáticamente el grupo de conexiones y es transparente para la persona que llama. (Entonces El grupo de conexiones de servicio en el cliente RPC es un componente básico muy importante).
4.4 Alta disponibilidad de [Capa de servicio>Capa de caché]

La alta disponibilidad desde la [capa de servicio] a la [capa de caché] se logra mediante la redundancia de los datos almacenados en caché.
Hay varias formas de implementar la redundancia de datos en la capa de caché: la primera es utilizar la encapsulación del cliente y el servicio para leer o escribir dos veces el caché.

La capa de caché también puede resolver el problema de alta disponibilidad de la capa de caché a través de un clúster de caché que admita la sincronización maestro-esclavo .
Tome Redis como ejemplo. Redis naturalmente admite la sincronización maestro-esclavo. Redis también tiene oficialmente un mecanismo centinela para realizar la detección de supervivencia de Redis.

Después de hablar sobre la alta disponibilidad del caché, quiero decir una cosa más aquí. Las empresas no necesariamente tienen requisitos de "alta disponibilidad" para el caché. Más escenarios de uso del caché son para "acelerar el acceso a los datos": poner parte de los datos en el caché Aquí, si el caché se bloquea o no funciona, puede ir a la base de datos de back-end para recuperar los datos.
Para este tipo de escenario empresarial que permite "pérdida de caché", las recomendaciones para la arquitectura de caché son:

Encapsule el caché kv en un clúster de servicios y configure un proxy ascendente (el proxy puede usar la redundancia del clúster para garantizar una alta disponibilidad). El backend del proxy se divide horizontalmente en varias instancias de acuerdo con la clave a la que accede el caché. cada instancia no está completa Alta disponibilidad.

La instancia de caché cuelga y está protegida : cuando una instancia dividida horizontalmente cuelga, la capa de proxy devuelve directamente un error de caché. En este momento, el bloqueo de la caché también es transparente para la persona que llama. Se reducen las instancias de fragmentación horizontal de claves y no se recomienda repetir el hash, ya que esto puede causar fácilmente inconsistencias en los datos almacenados en caché.
4.5 Alta disponibilidad de [capa de servicio>capa de base de datos]
En la mayoría de las tecnologías de Internet, la capa de base de datos utiliza una arquitectura de "sincronización maestro-esclavo, separación de lectura y escritura", por lo que la alta disponibilidad de la capa de base de datos se divide en dos categorías: "alta disponibilidad de lectura de base de datos" y "alta disponibilidad de escritura de base de datos". .
Alta disponibilidad de [Capa de Servicio>Capa de Base de Datos "Lectura"]

La alta disponibilidad desde [capa de servicio] hasta [lectura de base de datos] se logra mediante la redundancia de la base de datos de lectura.
Dado que la base de datos de lectura es redundante, en términos generales, hay al menos 2 bases de datos esclavas. El "grupo de conexiones de la base de datos" establecerá múltiples conexiones a la base de datos de lectura y cada solicitud se enrutará a estas bases de datos de lectura.

Conmutación por error automática : cuando la biblioteca de lectura se bloquea, db-connection-pool puede detectarlo, realizar una conmutación por error automáticamente y migrar automáticamente el tráfico a otras bibliotecas de lectura. El grupo de conexiones completa automáticamente todo el proceso y la persona que llama es transparente (por lo que el grupo de conexiones de bases de datos en DAO es un componente básico muy importante).
[Capa de servicio>Capa de base de datos "escribir"] alta disponibilidad
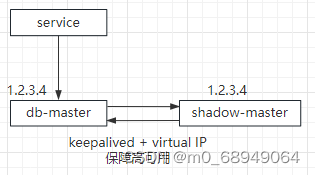
La alta disponibilidad desde la [capa de servicio] hasta la [escritura de la base de datos] se logra mediante la redundancia de la base de datos de escritura.
Tomando MySQL como ejemplo, puede configurar dos sincronizaciones maestras duales de MySQL, una para proporcionar servicios en línea y la otra para proporcionar redundancia para garantizar una alta disponibilidad. Una práctica común es mantener activa la detección de supervivencia y la misma IP virtual proporciona servicios. .

Conmutación por error automática : cuando la biblioteca de escritura se bloquea, keepalived puede detectarlo, realizar una conmutación por error automáticamente y migrar automáticamente el tráfico a shadow-db-master. Dado que se utiliza la misma IP virtual, este proceso de conmutación es muy perjudicial para la persona que llama. Sea transparente .