
Introducción
En comparación con la arquitectura monolítica o SOA anterior, los componentes utilizados para construir la arquitectura de microservicios han cambiado, por lo que las ideas para analizar y diseñar soluciones de arquitectura de recuperación ante desastres de alta disponibilidad también han cambiado. Este artículo analiza varios problemas comunes en la implementación de la arquitectura de microservicios. .Análisis de soluciones de recuperación ante desastres y alta disponibilidad.
Sobre el Autor
Liu Guanjun es el jefe del Grupo de Arquitectura del Centro de Middleware de la Nube de Tencent y un ingeniero experto con
15 años de experiencia en la industria de TI. Su primer trabajo fue en el Laboratorio de IBM China y una vez se desempeñó como Director de I+D de middleware de mainframe de IBM. Actualmente, es ingeniero experto en Tencent Cloud y jefe del equipo de arquitectura del centro de middleware, responsable del equipo de arquitectura del centro de productos de middleware y del trabajo de preventa de los productos de la plataforma PaaS. Se han obtenido un total de 16 autorizaciones de patente. Tiene una amplia experiencia en procesamiento de transacciones, servicios web, microservicios, colas de mensajes y arquitectura bancaria, y ha brindado soporte a muchos clientes grandes y medianos en el país y en el extranjero.
Descripción general
En comparación con la arquitectura SOA, la arquitectura de microservicios utiliza un enfoque descentralizado para organizar las aplicaciones comerciales. La comunicación entre servicios no necesita pasar por el bus. La lógica del enrutamiento del servicio se envía a cada microservicio para que se complete por sí solo. Por otro lado, la arquitectura de microservicios también es inseparable de los componentes centralizados para implementar funciones como la gobernanza de servicios, la implementación y el monitoreo de aplicaciones. El diseño de soluciones de recuperación ante desastres de alta disponibilidad, como el modo de espera activo y el multiactivo en escenarios de microservicios, requiere consideración integral.
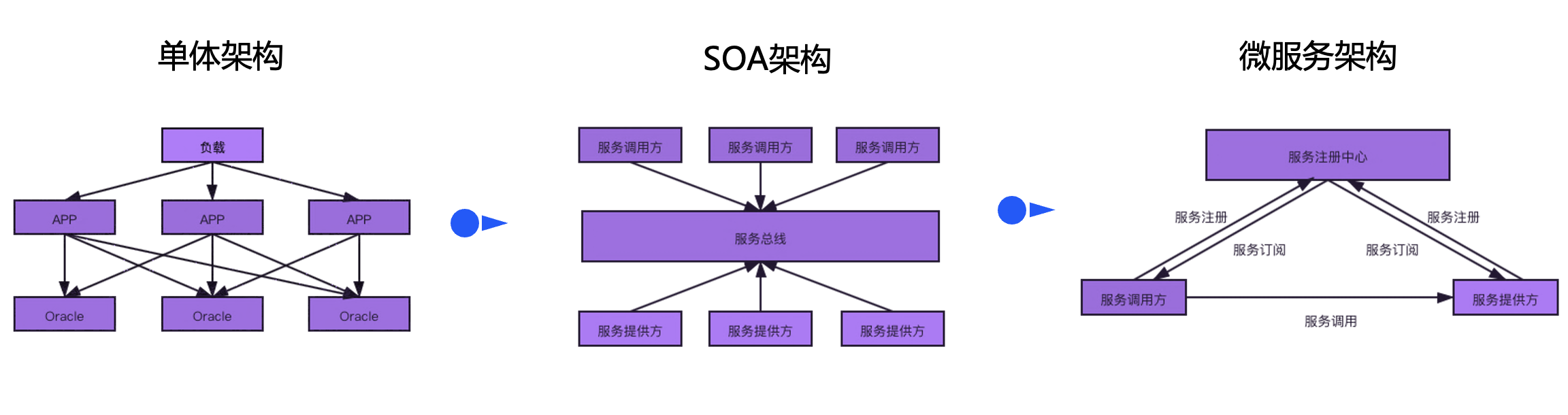
Antes de analizar una arquitectura compleja de recuperación ante desastres, primero debemos definir claramente el problema, desmantelar el problema, descomponer el subproblema y discutirlo por separado desde diferentes dimensiones para obtener una conclusión clara. Cuando hablamos de modos de alta disponibilidad, como activo-en espera y activo-activo, los diferentes modos de alta disponibilidad tienen diferentes significados para componentes como aplicaciones, bases de datos y centros de registro, pero cada componente está relacionado entre sí. En opinión del autor, un componente completo de arquitectura de microservicios contiene tres dimensiones:
- Capa de control y gestión de microservicios: debido a la complejidad que aporta la arquitectura distribuida, es necesario introducir componentes de soporte distribuido relevantes
- Componente de gestión del ciclo de vida de la aplicación : Responsable del lanzamiento, la reversión, el escalado elástico y la conmutación por error de la aplicación. La arquitectura de microservicio tiene requisitos más altos para las capacidades de implementación y operación y mantenimiento, y requiere que la empresa automatice las instalaciones de entrega. Estos componentes tienen relativamente poco impacto en el tiempo de funcionamiento del negocio.
- Componente de gobernanza de servicios : Responsable de las capacidades de gobernanza distribuida, como el descubrimiento de registros de servicios, la configuración de servicios y el enrutamiento de servicios. El componente más conocido es el centro de registro de servicios. El centro de registro es responsable de realizar comprobaciones de estado de los servicios y eliminar instancias anormales en de manera oportuna. Por lo tanto, en el modo de recuperación ante desastres, los requisitos de red son relativamente altos. Si la red es inestable, fácilmente conducirá a controles de estado inexactos. Las notificaciones frecuentes de cambios de instancias de servicio a gran escala afectarán la estabilidad del sistema.
- Componente de monitoreo : Responsable de recopilar los tres componentes principales de la observabilidad: seguimiento, registro y métricas. La capa inferior a menudo usa ES o una base de datos de series de tiempo. Dado que la cantidad de datos solicitados por este componente es relativamente grande, el costo del tráfico de la red debería tener en cuenta a la hora de planificar y desplegar.
-
Capa de aplicación: la aplicación debe ser lo más apátrida posible para reducir la dificultad de implementación.
-
Capa de datos: en la actualidad, la mayoría de las aplicaciones utilizan bases de datos relacionales. El nivel técnico actual de las bases de datos relacionales no puede admitir múltiples instancias y múltiples escrituras, por lo que solo podemos discutir los modos activo y en espera de la base de datos. El punto clave es la automatización de los activos. y conmutación en espera y datos. El retraso de la replicación reduce el RTO y el RPO de la recuperación de fallas, respectivamente.
Principal y respaldo en la misma ciudad.
Active-Standby en la misma ciudad a menudo se implementa en AZ duales, y la distancia entre las AZ debe cumplir con los requisitos reglamentarios. En la AZ dual, solo una AZ principal proporciona servicios al mundo exterior y la otra AZ en espera se utiliza como respaldo, lo que a menudo solo requiere la implementación de una pequeña cantidad de recursos.
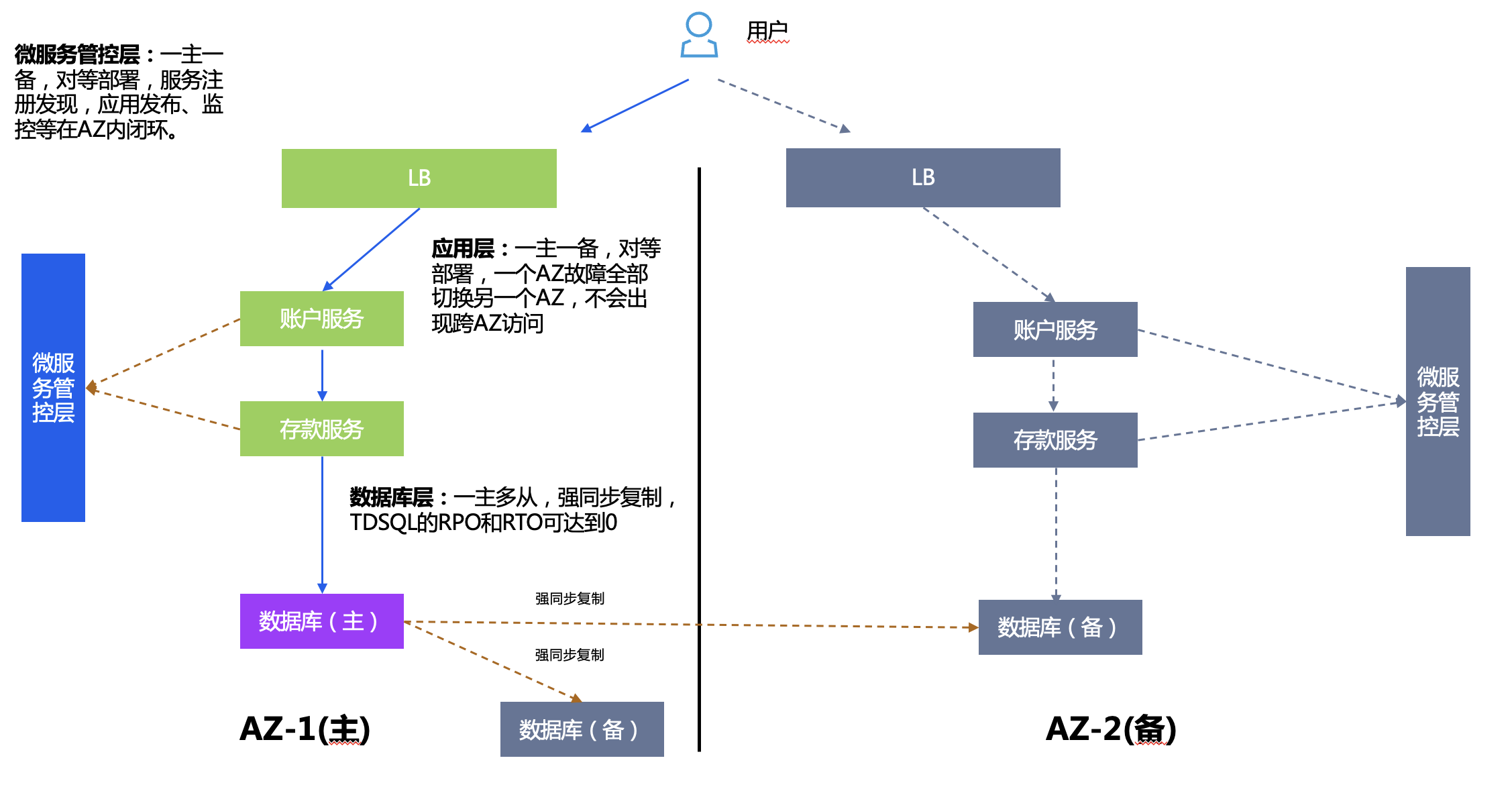
Plan de empleo:
- Capa de control y gestión de microservicios: TSF tiene un maestro y un respaldo, el registro y descubrimiento de servicios, el lanzamiento de aplicaciones, el monitoreo, etc., están todos en un circuito cerrado en AZ.
- Capa de aplicación: hay un maestro y un respaldo para las aplicaciones. El centro de respaldo contiene todas las aplicaciones lógicas en el centro principal y la cantidad de copias de las aplicaciones se puede reducir.
- Capa de base de datos: un maestro y varios esclavos, replicación sincrónica sólida, RPO y RTO usando TDSQL pueden llegar a 0 y las aplicaciones se pueden cambiar sin ningún conocimiento.
Análisis de anomalías de la capa de aplicación.
Analice varios escenarios anormales en la capa de aplicación:
1. Fallo de una sola instancia de microservicio: los microservicios deben implementarse con varias instancias y pueden ser tolerantes a fallas en una única zona de disponibilidad.
2. Todas las instancias de un determinado microservicio fallan. Hay dos posibles razones.
- Hay un problema con el código de la aplicación en sí: revierta la aplicación o corríjala.
- Todas las instancias físicas de un determinado microservicio fallan: utilice la antiafinidad del nodo de capa IaaS para implementar instancias lo más dispersas posible entre bastidores.
3. Todas las instancias en toda la zona de disponibilidad fallan: en este caso, la zona de disponibilidad de respaldo se habilita en su totalidad y se cambia el tráfico de usuarios.
Gestión de microservicios y análisis de anomalías de la capa de control.
La capa de control y gestión de microservicios de TSF se puede dividir en dos niveles:
- Componentes en tiempo de lanzamiento: afectan principalmente la función de lanzamiento de la aplicación. La falla del componente afecta el lanzamiento y la reversión de la aplicación, pero no afecta el funcionamiento de la aplicación. Los propios componentes de TSF no tienen estado y se pueden implementar en múltiples instancias sin afectar el funcionamiento de la aplicación. La capa inferior se basa en la implementación maestro-esclavo de la base de datos MySQL, que se puede implementar en las zonas de disponibilidad de forma independiente para evitar puntos únicos de falla.
- Componentes de tiempo de ejecución: divididos en dos niveles
- Componentes de monitoreo y registro: todas las fallas afectan la recopilación de datos de monitoreo, pero no afectan el funcionamiento de la aplicación. El componente en sí no tiene estado y se puede implementar en múltiples instancias. El ES/Redis subyacente es una base de datos no relacional y se puede implementar en modo activo/en espera/fragmentación. Se puede implementar en AZ de forma independiente para evitar puntos únicos de falla.
- Centro de registro de servicios: la falla afecta el registro de nuevos servicios y la entrega de configuración. TSF ha diseñado un mecanismo de almacenamiento en caché localmente en la aplicación. Cuando el centro de registro no está disponible, la aplicación aún puede iniciar llamadas entre servicios. Los componentes se implementan mediante un clúster de cónsul, con un modo maestro y varios esclavos.
Para un análisis en profundidad de la alta disponibilidad en el extremo de control de TSF, consulte la siguiente serie de artículos especiales.
Análisis de anomalías de la capa de base de datos.
Dado que la base de datos es un punto único, puede ocurrir un único punto de inactividad en una única zona de disponibilidad. En caso de falla, se puede cambiar al nodo de respaldo en la misma zona de disponibilidad o en la misma ciudad. Similar al sistema one-master -Modo multiesclavo de TDSQL, TDSQL también puede implementar una conmutación por error de IP automática. La aplicación no lo sabe.
Servicios en vivo activos en la misma ciudad.
Todos los sistemas comerciales del usuario se ejecutan en dos centros de datos al mismo tiempo y brindan servicios a los usuarios al mismo tiempo. Cuando un sistema de aplicación en una AZ tiene un problema, hay una aplicación en otra AZ para continuar brindando servicios.
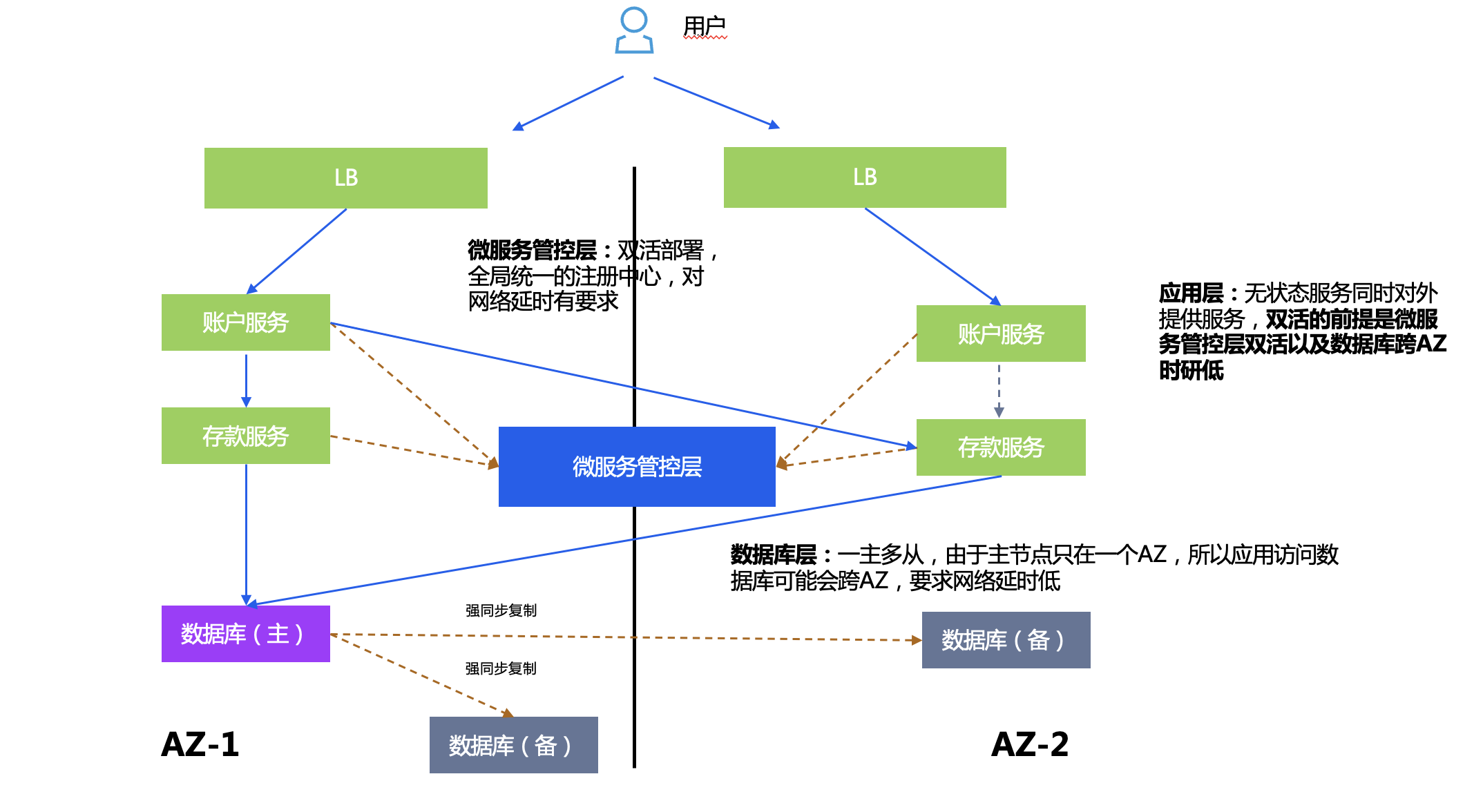
Plan de empleo:
- Capa de control y gestión de microservicios: implementación activa-activa de TSF, tiene un centro de registro unificado globalmente y tiene requisitos de latencia de red.
- Capa de base de datos: un maestro y varios esclavos. Dado que el nodo maestro está solo en una AZ, el acceso de las aplicaciones a la base de datos puede cruzar las AZ. Por lo tanto, se requiere una baja latencia de red entre las AZ para reducir el consumo de rendimiento causado por la distorsión de los datos.
- Capa de aplicación: los servicios sin estado brindan servicios al mundo exterior al mismo tiempo. La premisa de activo-activo es que la capa de control y administración de microservicios es activo-activo y la latencia entre AZ de la base de datos es baja.
El modo de implementación de alta disponibilidad de la capa de base de datos sigue siendo un maestro y varios esclavos, y no se realizará ningún análisis de excepción en la capa de base de datos más adelante.
Análisis de anomalías de la aplicación.
Analice varios escenarios anormales en la capa de aplicación:
1. Toda la AZ está inactiva: utilice tecnologías como GSLB o cross-AZ LB para cambiar a otra IP. Al mismo tiempo, esta capa de capacidades puede lograr el equilibrio de carga.
2. Recuperación ante desastres para llamadas entre microservicios: TSF admite el enrutamiento más cercano dentro de AZ y llamadas entre AZ cuando las instancias dentro de AZ no están disponibles.
Gestión de microservicios y análisis de anomalías de la capa de control.
Actualmente, TSF implementa el cambio automático de componentes como el centro de registro a otra AZ basado en VIP entre AZ (proporcionados por los clientes o TCS/TCE). Cuando falla una sola AZ, la aplicación cambia automáticamente el extremo de control de otra AZ sin ningún conciencia.
Dos plazas y tres centros
Tres centros en dos lugares están construidos sobre la base de activo-activo en la misma ciudad + recuperación remota de desastres, y tienen alta disponibilidad y capacidades de respaldo de desastres.El centro remoto de recuperación de desastres se refiere al establecimiento de un centro de respaldo de recuperación de desastres en un ciudad remota para centros duales Copia de seguridad de datos. Cuando los centros duales fallan debido a desastres naturales u otras razones, el centro remoto de recuperación de desastres puede utilizar los datos de copia de seguridad para restaurar el negocio.
La arquitectura general es una combinación de activo-activo y activo-en espera en la misma ciudad.
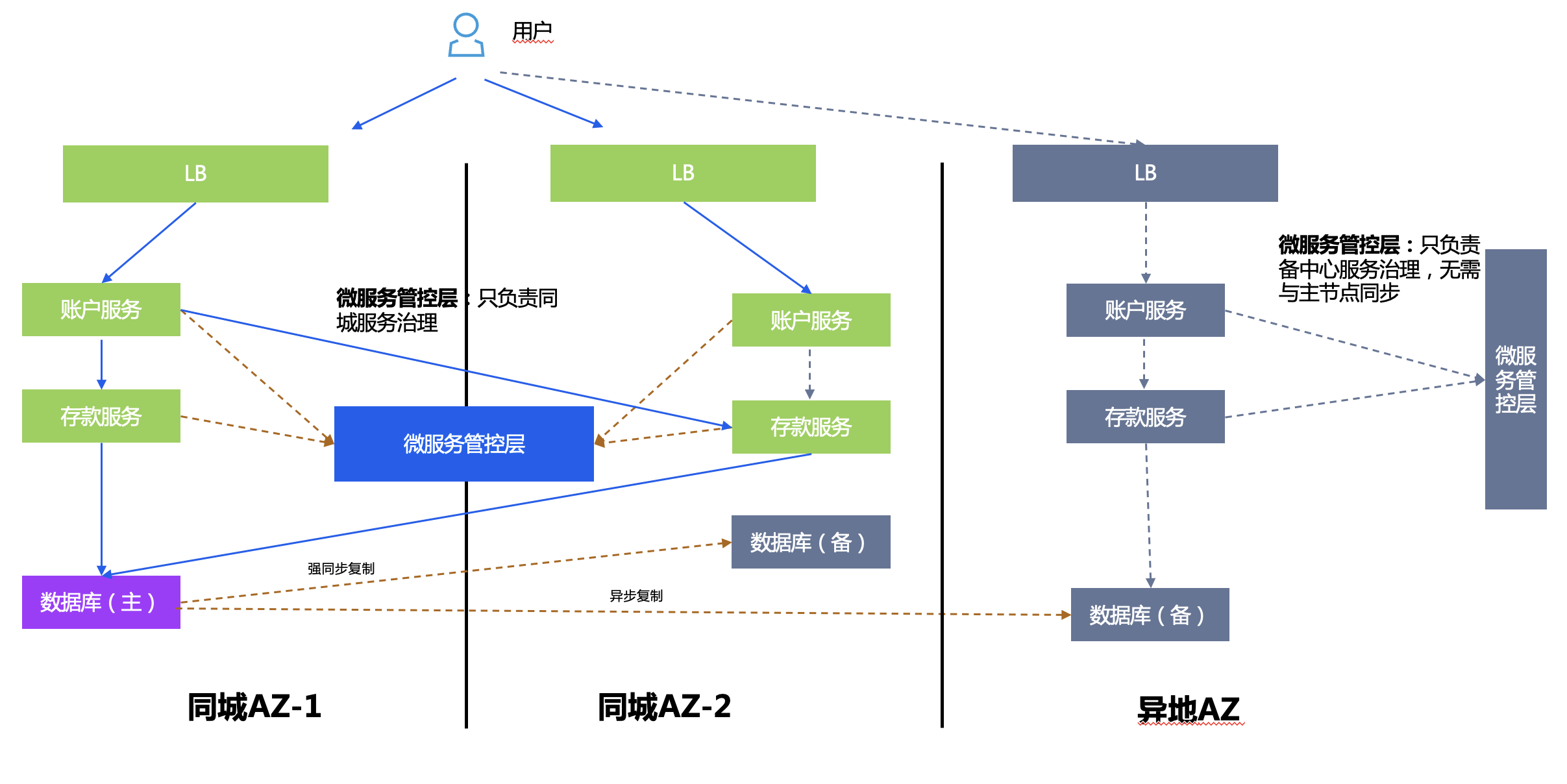
Plan de empleo:
- Capa de control y gestión de microservicios: despliegue activo-activo en la misma ciudad, recuperación ante desastres en ubicaciones remotas, no es necesario sincronizar sus respectivos datos y solo son responsables de la gestión y control de sus propios servicios.
- Capa de base de datos: un maestro y varios esclavos, fuerte sincronización TDSQL en la misma ciudad y replicación asincrónica en diferentes lugares.
- Capa de aplicación: el servicio sin estado proporciona servicios al mundo exterior al mismo tiempo. Después de que falla el centro principal, la ruta de ingreso se cambia al centro de respaldo remoto.
Vive más en un lugar diferente
La premisa de la actividad múltiple en diferentes lugares es que la arquitectura puede realizar tres centros en dos lugares, la fragmentación horizontal se realiza a nivel de base de datos y las aplicaciones comerciales están vinculadas a fragmentos de bases de datos en grupos. La multiactividad en ubicaciones remotas puede reducir el alcance de las fallas a un solo fragmento y reducir la complejidad de la base de datos. Esta arquitectura se utiliza generalmente para bancos/compañías de seguros nacionales con cantidades muy grandes de datos.
Las soluciones se dividen en dos tipos: respaldo mutuo remoto y unificación, que se presentan por separado a continuación.
Preparación remota
El nivel de la base de datos se divide horizontalmente en dos fragmentos de instancia; por ejemplo, se puede dividir en norte y sur por región.
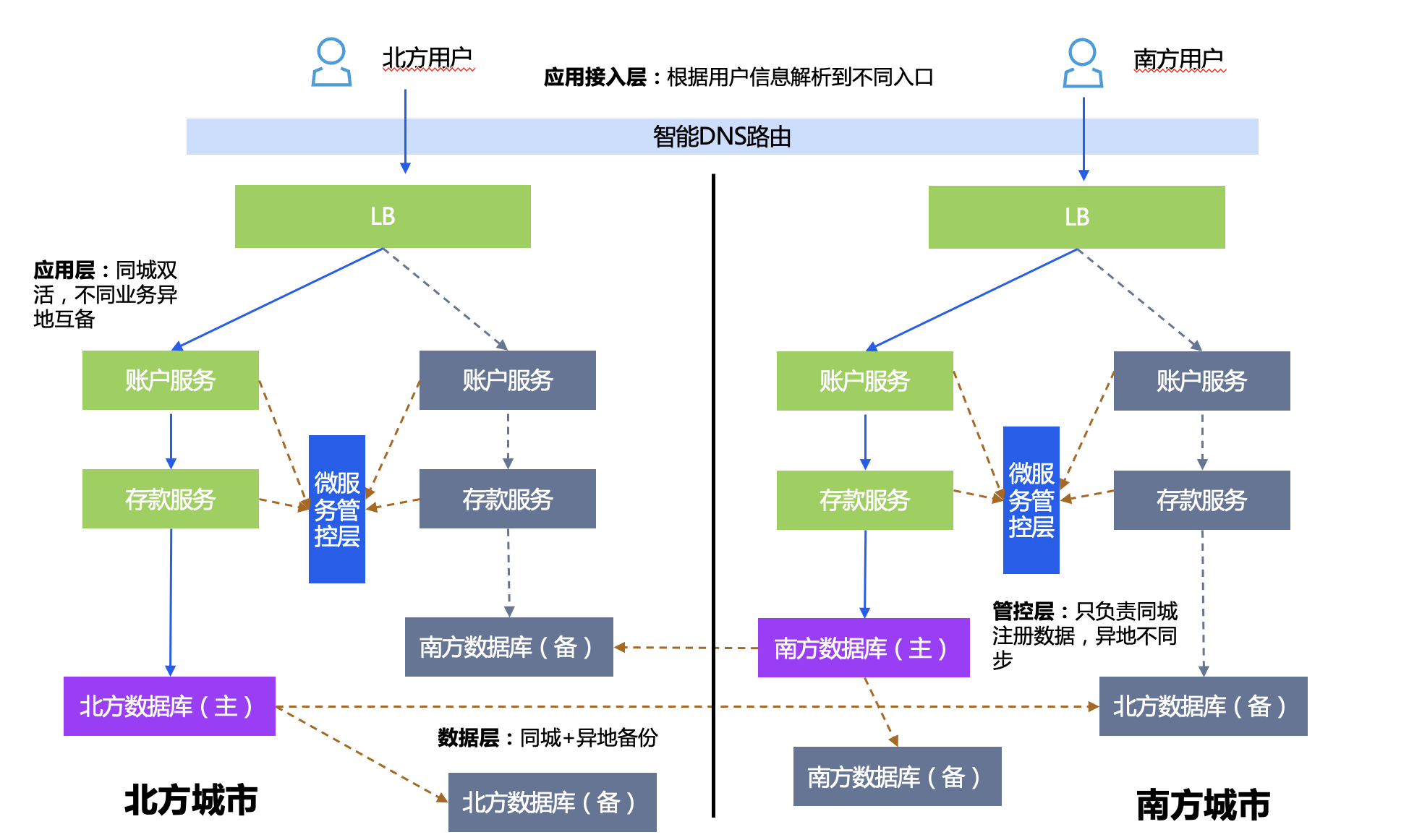
Plan de empleo:
- Capa de control y gestión de microservicios: atiende servicios activo-activo en la misma ciudad, pero no interoperables en diferentes lugares.
- Capa de aplicación: las aplicaciones con diferentes fragmentos de datos están activas-activas en ubicaciones remotas, las aplicaciones con los mismos fragmentos de datos están activas-activas en la misma ciudad y se proporciona recuperación remota ante desastres.
- Capa de base de datos: la fragmentación de datos tiene un maestro y varios esclavos, y diferentes fragmentos se replican en diferentes ubicaciones.
Estrategia de cambio de recuperación ante desastres: si toda la ciudad del sur falla, se realizará DNS en la entrada para cambiar la IP de acceso de los usuarios del sur al norte.
unificación
Generalmente, si la cantidad de datos es demasiado grande y simplemente usar el modo de fragmentación de la base de datos no puede resolver el problema, puede considerar usar una arquitectura unificada. Primero, aclare la definición de unidad. Una unidad es una unión lógica de un grupo de recursos informáticos y un grupo de recursos de datos. Los puntos clave del diseño incluyen:
1. Fragmentación: considere el volumen y el negocio, seleccione una estrategia de partición y trate de evitar llamadas entre unidades.
2. Diseño de unidades de implementación: considere el diseño de recuperación ante desastres, vincule unidades a fragmentos de bases de datos, tenga unidades activas-activas en la misma ciudad e implemente unidades de recuperación ante desastres en ubicaciones remotas.
3. Enrutamiento: TSF brinda la capacidad de calcular reglas unificadas en la entrada de la puerta de enlace o la entrada del servicio, teñir las solicitudes y enrutar solicitudes posteriores a la misma unidad de acuerdo con las condiciones, y llamarlas a través de la puerta de enlace al cruzar las unidades.

Plan de empleo:
- Capa de control y gestión de microservicios: debido a que la puerta de enlace puede estar unificada, se requiere un centro de registro de servicios global.
- Capa de aplicación: cada región contiene todos los fragmentos de unidades. Las aplicaciones con diferentes fragmentos de datos pueden estar activas en diferentes lugares. Las aplicaciones con el mismo fragmento de datos pueden estar activas en la misma ciudad y tener recuperación remota ante desastres.
- Capa de base de datos: la fragmentación de datos tiene un maestro y varios esclavos, y diferentes fragmentos se replican en diferentes ubicaciones.
Análisis de excepción unitaria:
- Conmutación por error de toda la región: todo el tráfico se cambia a otra región.
- Conmutación por error de una sola unidad en una región: además de los problemas con el código de la aplicación en sí, las unidades están físicamente desplegadas en varios centros de la misma ciudad, por lo que es básicamente imposible que todas las unidades de una ciudad dejen de funcionar.
Múltiples actividades en ubicaciones remotas basadas en la unificación.
Aclaración del concepto de vidas múltiples en diferentes lugares:
- Origen del problema: Otra consideración central en la arquitectura unificada es facilitar la realización de múltiples actividades en diferentes lugares. Existe un problema ampliamente criticado en la arquitectura tradicional local activa-activa y remota de recuperación ante desastres, que es que los recursos remotos de recuperación ante desastres en realidad no sirven al negocio la mayor parte del tiempo. Una vez adquiridos e implementados, permanecen inactivos durante un tiempo. Durante mucho tiempo, como un guerrero que no ha estado en batalla durante mucho tiempo, es un desperdicio de la paga militar del país. Para mejorar la utilización de los recursos, muchos clientes, especialmente los clientes financieros, están buscando una estructura multiactiva en diferentes ubicaciones, de modo que los recursos en ubicaciones remotas puedan compartir parte del tráfico y procesar el negocio con normalidad.
- Aquí debemos prestar atención a la correcta comprensión del concepto de vivir en diferentes lugares. La multiactividad en diferentes lugares no significa que todos los servicios (incluidas todas las aplicaciones y todos los datos) puedan residir en la región A y la región B al mismo tiempo (los dos lugares están separados por cientos de kilómetros y cumplen con los requisitos normativos de recuperación ante desastres); más bien , significa que algunas empresas procesan en la región A y parte del mismo se procesa en la región B. Ninguna región está completamente inactiva. Porque el primer enfoque es demasiado caro tanto en términos de tecnología como de coste económico.
- La unificación admite múltiples actividades en diferentes ubicaciones: bajo la arquitectura de unificación, dado que los datos se fragmentan y se procesan en unidades, se procesan diferentes unidades en diferentes regiones. Naturalmente, se logra el objetivo mencionado anteriormente de realizar múltiples actividades en diferentes lugares y aprovechar al máximo los recursos de la máquina. Si bien cada región maneja negocios en unidades separadas, también sirve como centro de recuperación de desastres para brindar capacidades remotas de recuperación de desastres para aplicaciones y datos a otras unidades remotas.
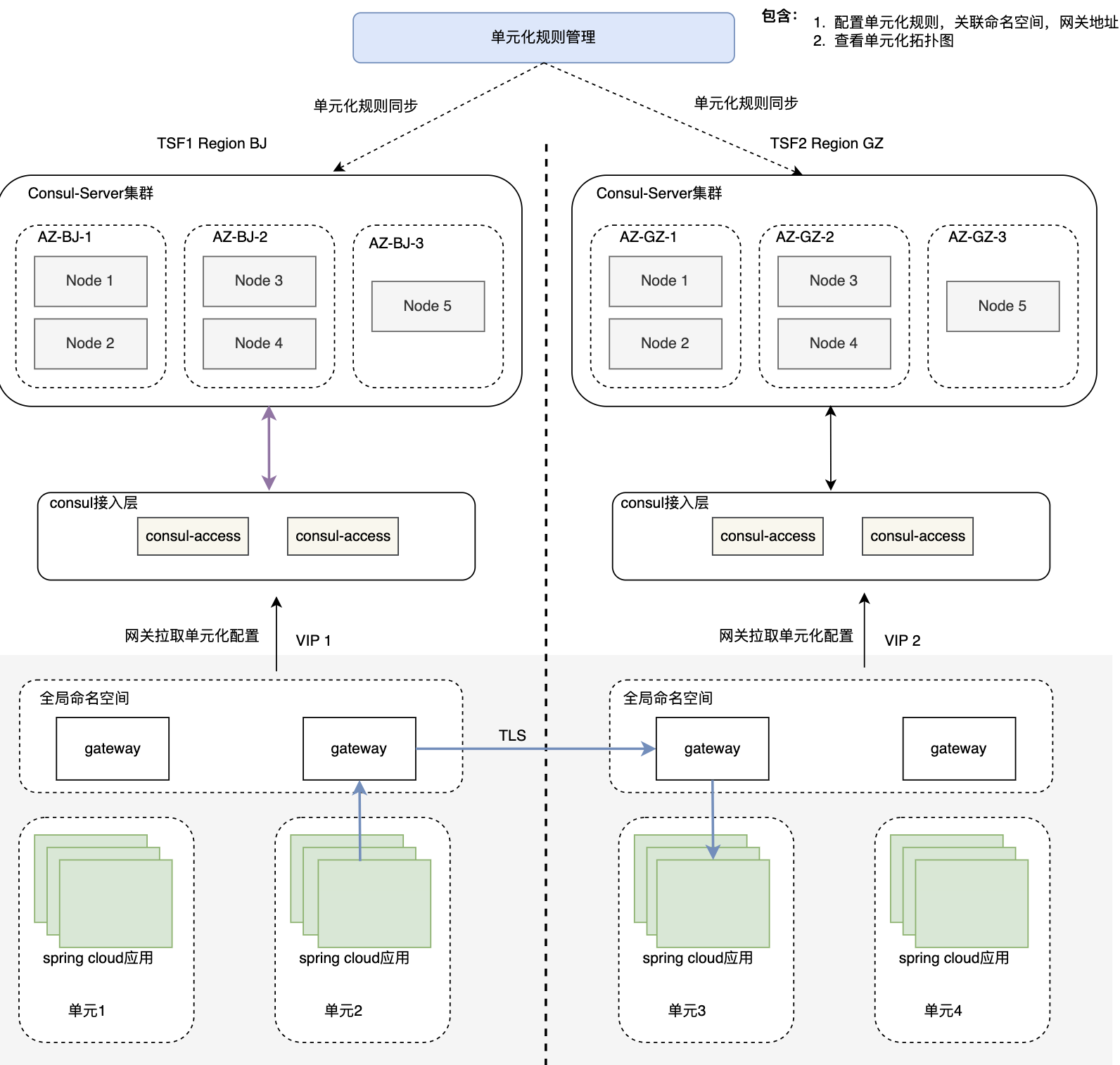
En la actualidad, los productos de TSF han logrado capacidades de unificación. Al mismo tiempo, para lograr la demanda de unificación y multiactividad remota, TSF ha implementado la capacidad de descubrimiento mutuo y acceso mutuo de múltiples clústeres interregionales en la última versión. , como se muestra en la siguiente figura.
- El principio de implementación no se basa en un centro de registro global interregional, porque el centro de registro actual de TSF sigue siendo Consul y el clúster de Consul está en modo CP. El modo CP tiene altos requisitos en cuanto al retraso de la sincronización de la información y el El clúster Consul solo se puede implementar con alta disponibilidad de múltiples nodos en la misma ciudad, no se puede implementar de forma remota. Por lo tanto, el acceso remoto actual de TSF adopta el modo de direccionamiento de la puerta de enlace de la unidad. La puerta de enlace de la unidad busca otra puerta de enlace de la unidad donde se encuentra el servicio remoto y luego la lleva al centro de registro de Consul del clúster según Consul Access (frontal sin estado). capa final) Obtenga nodos de servicio para lograr acceso a servicios entre regiones. La ventaja de reenviar a través de la puerta de enlace es que la unidad está bien sellada, el enlace de acceso es claro y los problemas se pueden rastrear fácilmente; la desventaja es que aumenta el número de saltos de servicio y el tiempo de respuesta.
- En el futuro, el centro de registro de TSF se integrará en el centro de registro de Polaris, que es un centro de registro en modo AP basado en un método maestro-esclavo de base de datos para almacenar información, y puede servir mejor como un centro de registro global interregional.
Resumir
Lo anterior se basa en la arquitectura de microservicios y analiza las soluciones de alta disponibilidad de cada capa. El diseño de la arquitectura de alta disponibilidad de cada capa es complementario entre sí. La falta de capacidades de cualquier capa bajo cada solución de alta disponibilidad puede no lograr el objetivo deseado. . TSF ha implementado varias arquitecturas de alta disponibilidad presentadas anteriormente en clientes de diversas industrias en el pasado y ha acumulado una rica experiencia. En general, el diseño arquitectónico es una cuestión de hacer concesiones. No existe una solución perfecta. Por un lado, se debe seguir el principio de simplicidad. Cuanto más simple sea el diseño arquitectónico, más fácil será de implementar y menor será la operación. y la complejidad del mantenimiento, y menor será el costo. Por otro lado, debe basarse en la situación real. Las demandas, como los requisitos regulatorios, el estado de implementación, el volumen de datos comerciales, etc., se combinan con condiciones objetivas para seleccionar un adecuado solución.
Lei Jun anunció la arquitectura completa del sistema ThePaper OS de Xiaomi, diciendo que la capa inferior ha sido completamente reestructurada. Yuque anunció la causa de la falla y el proceso de reparación el 23 de octubre. Nadella, CEO de Microsoft: Abandonar Windows Phone y el negocio móvil fue una decisión equivocada Las tasas de uso de Java 11 y Java 17 excedieron el acceso de Hugging Face a Java 8. La interrupción de la red de Yuque duró aproximadamente 10 horas y ahora ha vuelto a la normalidad. Oracle lanzó extensiones de desarrollo de Java para Visual Studio Code . La Administración Nacional de Datos oficialmente Musk reveló : Done mil millones si Wikipedia pasa a llamarse "Enciclopedia Weiji" USDMySQL 8.2.0 GA