Tabla de contenido
- árbol negro rojo
- árbol B
- árbol+b
-
- 1. Características del árbol B+
- La diferencia entre el árbol B+ y el árbol B
- ¿Por qué la base de datos utiliza árboles B+ en lugar de árboles B y árboles rojo-negro?
-
- 1. Primero, hablemos de por qué los árboles rojo-negros no funcionan:
- 2. Primero hablemos de la diferencia entre el árbol b y el árbol b+:
- El principio de localidad y lectura anticipada del disco.
- 3. Hablemos de por qué el árbol b no es tan bueno como el árbol b+:
- Análisis de desempeño del índice B-/B+
árbol negro rojo
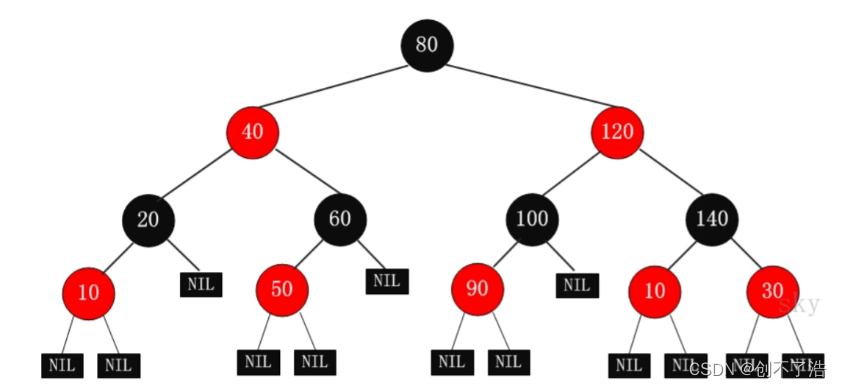
1 Características del árbol rojo-negro
- Cada nodo es negro o rojo.
- El nodo raíz es negro.
- Cada nodo de hoja (NIL) es negro. [Nota: ¡El nodo hoja aquí se refiere al nodo hoja que está vacío (NIL o NULL)!
- Si un nodo es rojo, sus hijos deben ser negros.
- Todos los caminos desde un nodo hasta sus descendientes contienen la misma cantidad de nodos negros. [Esto se refiere a la ruta al nodo hoja] La altura de un árbol rojo-negro que contiene n nodos internos es O (log (n)).
2 escenarios de uso de árboles rojo-negros
Los árboles rojo-negros utilizados en Java incluyen TreeSet y HashMap de JDK1.8.
Pero surge la pregunta: ¿por qué utilizar árboles rojo-negro? La inserción y eliminación de árboles rojo-negro debe cumplir las cinco características anteriores y realizar operaciones muy complejas.
Motivo:
El árbol rojo-negro es un árbol equilibrado y sus definiciones y reglas complejas tienen como objetivo garantizar el equilibrio del árbol. Si el árbol no garantiza su equilibrio será como se muestra a continuación: Obviamente se convertirá en una lista enlazada.
El objetivo principal de garantizar el equilibrio es reducir la altura del árbol, porque el rendimiento de búsqueda del árbol depende de la altura del árbol . Por lo tanto, cuanto menor sea la altura del árbol, mayor será la eficiencia de la búsqueda.
Es por eso que existen árboles binarios, árboles binarios de búsqueda, etc., el propósito de varios tipos de árboles.
árbol B
Descripción general
Árbol B, aquí B significa equilibrio (es decir, equilibrio), el árbol B es un árbol de búsqueda autoequilibrado de múltiples vías (el árbol B es un árbol de búsqueda equilibrado de múltiples vías), similar a un árbol binario equilibrado ordinario. con una
diferencia Un árbol B permite que cada nodo tenga más nodos secundarios. La siguiente figura es un diagrama simplificado de un árbol B.
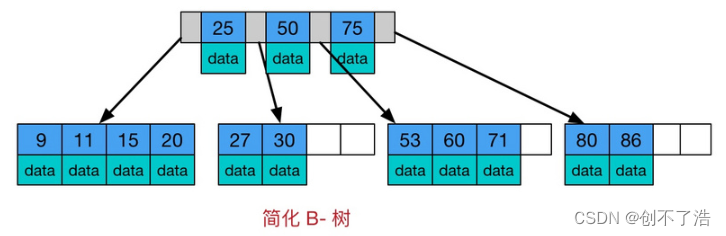
Características del árbol 1B
Wikipedia define un árbol B como "En informática, un árbol B es una estructura de datos similar a un árbol que puede almacenar datos, ordenarlos y permitir una complejidad temporal O (log n). Una estructura de datos que realiza búsquedas, lecturas secuenciales, inserciones y eliminaciones. Un árbol B, en resumen, es un árbol de búsqueda binario en el que un nodo puede tener más de 2 nodos secundarios. A diferencia de un árbol de búsqueda binario autoequilibrado, un árbol B es El sistema optimiza la lectura y "Operaciones de escritura de grandes bloques de datos. El algoritmo del árbol B reduce el proceso intermedio experimentado al localizar registros, acelerando así el acceso. Se utiliza comúnmente en bases de datos y sistemas de archivos".
Las condiciones para que se cumpla un árbol B de orden m:
每个节点至多有m棵子树
根节点除外,其它每个分支节点至少有【m/2】棵子树
根节点至少有两棵子树(除非B树只包含一个节点)
所有叶子节点在同一层上,B树的叶子节点可以看成一种外部节点,不包含任何信息。
有j个孩子的非叶结点恰好有j-1个关键码,关键码按递增次序排列。
B 树又叫平衡多路查找树。
La siguiente imagen es un árbol B de orden M = 4.
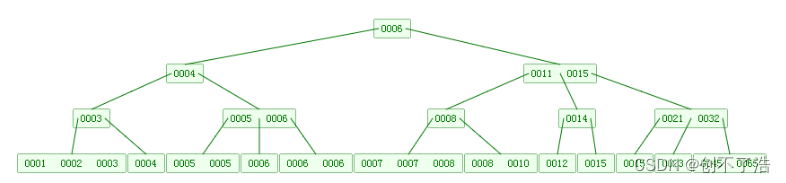
Puede ver que el árbol B es una extensión del árbol 2-3. Permite que un nodo tenga más de 2 elementos.
Las operaciones de inserción y equilibrio del árbol B son muy similares a las del árbol 2-3, por lo que no las introduciremos aquí. Lo siguiente es insertar en el árbol B uno por uno.
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
Vea este enlace para ver la animación.
Enlace original: https://www.yycoding.xyz/post/2014/3/29/introduce-b-tree-and-b-plus-tree
2. Escenarios de uso del árbol B
Los árboles B se utilizan principalmente para indexar sistemas de archivos.
Entonces aquí surge la pregunta: ¿Por qué usar el árbol B? ¿No son buenos los árboles rojo-negros?
Motivo:
en comparación con los árboles binarios y los árboles rojo-negro, los árboles B tienen más subárboles, lo que significa más rutas. Más subárboles significa que cuanto menor sea la altura del número y mayor será la eficiencia de la búsqueda. Por supuesto, si hay demasiadas rutas , puede convertirse en una matriz ordenada (como se muestra a continuación). Entonces, por supuesto, es imposible hacer que el número de caminos sea infinito.

¿Por qué aparecen estructuras de datos como los árboles B?
Hay muchos árboles binarios equilibrados que se utilizan tradicionalmente para la búsqueda, como árboles AVL, árboles rojo-negro, etc. Estos árboles proporcionan un rendimiento de consulta muy bueno en circunstancias normales , pero fallan cuando los datos son muy grandes. La razón es que cuando la cantidad de datos es muy grande, la memoria no es suficiente, la mayoría de los datos solo se pueden almacenar en el disco y solo los datos requeridos se cargan en la memoria. En términos generales, el tiempo de acceso a la memoria es de aproximadamente 50 ns, mientras que el tiempo de acceso al disco es de aproximadamente 10 ms. La diferencia de velocidad es de casi 5 órdenes de magnitud y el tiempo de lectura del disco supera con creces el tiempo de comparación de datos en la memoria. Esto muestra que el programa estará bloqueado en el disco IO la mayor parte del tiempo. Entonces, ¿cómo mejoramos el rendimiento del programa? Reducir el número de E/S de disco. Los árboles binarios equilibrados, como los árboles AVL y los árboles rojo-negro, no pueden "atender" los discos por diseño.
El tiempo para un acceso a la memoria, un acceso al disco duro SSD y un acceso aleatorio al disco duro SATA es de aproximadamente decenas de nanosegundos, decenas de microsegundos y decenas de milisegundos, respectivamente.
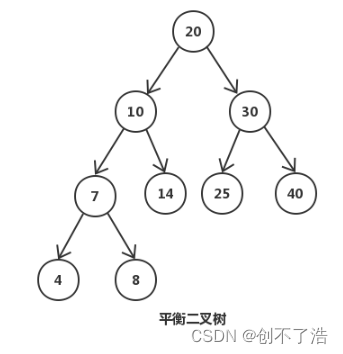
La imagen de arriba es un árbol binario balanceado simple. El árbol binario balanceado se mantiene mediante rotación, y la rotación es una operación en todo el árbol. Si parte del árbol se carga en la memoria, la operación de rotación no se puede completar. En segundo lugar, la altura de un árbol binario equilibrado es relativamente grande como log n (la base es 2), por lo que los nodos lógicamente cercanos pueden en realidad estar muy lejos y la lectura anticipada del disco no se puede utilizar bien (el principio de localidad), por lo que Este tipo de árbol binario equilibrado se encuentra en la base de datos y se pasan las selecciones del sistema de archivos.
El principio de localidad espacial: si se accede a una determinada ubicación en la memoria, también se accederá a las ubicaciones cercanas.
Veamos el diseño del árbol B desde la perspectiva de "abastecer" el disco.
La eficiencia de la indexación depende de la cantidad de IO del disco. La indexación rápida debe reducir efectivamente la cantidad de IO del disco. ¿Cómo indexar rápidamente? El principio de indexación es en realidad limitar continuamente el rango de búsqueda, tal como usualmente usamos un diccionario para buscar palabras: primero buscamos la primera letra para reducir el rango, luego la segunda letra, y así sucesivamente. Un árbol binario equilibrado divide el rango en dos intervalos cada vez. Para ser más rápido, el árbol B divide el rango en varios intervalos cada vez. Cuantos más intervalos, más rápidos y precisos serán los datos de posicionamiento. Entonces, si los nodos son rangos de intervalos, cada nodo será más grande. Por lo tanto, al crear un nuevo nodo, solicite directamente espacio del tamaño de una página (la unidad de almacenamiento en disco se divide en bloques, generalmente de 512 bytes). Disk IO lee varios bloques a la vez, lo que llamamos una página. El tamaño específico depende de el sistema operativo, generalmente 4k, 8k o 16k), la asignación de memoria de la computadora está alineada por páginas, de modo que un nodo solo necesita una IO.
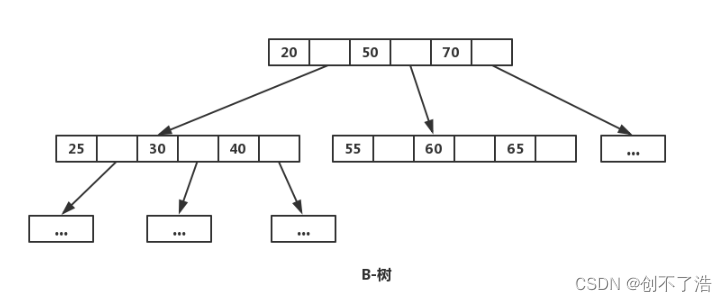
La imagen de arriba es un árbol B simplificado. Los beneficios de múltiples bifurcaciones son muy obvios. Reduce efectivamente la altura del árbol B, que es log n con una base grande. El tamaño de la base está relacionado con el número de Nodos secundarios del nodo. Generalmente, un árbol B: la altura del árbol es de aproximadamente 3 pisos. Cuanto menor sea el número de capas, más preciso será el rango determinado por cada área de nodo y más rápido se reducirá el rango (definitivamente es mucho más rápido que las búsquedas de nivel profundo en árboles binarios). Como se mencionó anteriormente, un nodo necesita realizar IO una vez, por lo que el número total de IO se reduce a registrar n veces. Cada nodo del árbol B tiene n secuencias ordenadas (a1, a2, a3 ... an), y los nodos secundarios del nodo se dividen en n + 1 intervalos para la indexación (X1 <a1, a2 <X2 <a3, … , an+1 < Xn < anXn+1 > an).
Comentario: Cada nodo del árbol B almacena múltiples valores. A diferencia del árbol binario, donde un nodo tiene un valor, el árbol B le da a cada nodo un rango pequeño. Cuando hay más intervalos, la búsqueda es más rápida. Por ejemplo, si hay números del 1 al 100, el árbol binario solo se puede dividir en dos rangos a la vez, 0-50 y 51-100, mientras que el árbol B se divide en cuatro rangos: 1-25, 25-50, 51 - 75, 76-100 pueden filtrar tres cuartas partes de los datos de una sola vez. Entonces el árbol B como árbol múltiple es más rápido.
árbol+b
Hay muchas variantes de B-Tree, la más común de las cuales es B+Tree. Por ejemplo, MySQL comúnmente usa B+Tree para implementar su estructura de índice.
En comparación con B-Tree, B+Tree tiene las siguientes diferencias:
El límite del puntero para cada nodo es 2d en lugar de 2d+1.
Los nodos internos no almacenan datos, sólo claves; los nodos hoja no almacenan punteros.
1. Características del árbol B+
1 El nodo medio de k subárboles contiene k elementos (k-1 elementos en el árbol B). Cada elemento no almacena datos y solo se usa para indexación. Todos los datos se almacenan en nodos hoja.
2 Todos los nodos hoja contienen información sobre todos los elementos y punteros a registros que contienen estos elementos, y los propios nodos hoja están vinculados en orden ascendente según el tamaño de las palabras clave.
3 Todos los elementos del nodo intermedio existen en los nodos secundarios al mismo tiempo y son los elementos más grandes (o más pequeños) entre los elementos del nodo secundario.
La diferencia entre el árbol B+ y el árbol B
El árbol B+ es una variante del árbol B- y también es un árbol de búsqueda multidireccional, sus diferencias con el árbol B- son:
- Todas las palabras clave se almacenan en nodos hoja, nodos internos (los nodos que no son hoja no almacenan datos reales)
- Se agregó un puntero de cadena a todos los nodos de hoja.
¿Por qué la base de datos utiliza árboles B+ en lugar de árboles B y árboles rojo-negro?
1. Primero, hablemos de por qué los árboles rojo-negros no funcionan:
El árbol rojo-negro debe almacenarse en la memoria, la tabla de la base de datos es demasiado grande y no se puede almacenar.
Incluso si encuentra una manera de guardar el árbol rojo-negro en el disco duro, buscar un nodo en el árbol rojo-negro requiere en la mayoría de los niveles logN, y cada nivel es una página de memoria (aunque solo desea encontrar un nodo , el disco duro debe leer una página a la vez) ..), entonces habrá un total de logN IO veces, ¡lo cual no puede hacer daño!
Por lo tanto, debemos considerar reducir la cantidad de capas de árbol para reducir la cantidad de IO y acelerar la eficiencia de consultar y modificar la base de datos. Tanto los árboles by b+ cumplen con esta propiedad. Cada uno de sus nodos tiene muchos hijos (de decenas a miles). ), por lo que todo el árbol La altura se puede reducir muy bajo.
Por ejemplo, si hay 100000000 datos y cada nodo tiene 1000 hijos, entonces registre 1000 (100000000) <3, ¡3 niveles son suficientes para almacenarlos!
2. Primero hablemos de la diferencia entre el árbol b y el árbol b+:
Todos los nodos del árbol b son nodos de datos, pero solo los nodos hoja del árbol b + son nodos de datos . Los nodos no hoja (internos) solo desempeñan un papel de guía y no almacenan datos reales.
Todos los nodos de datos del árbol b + están en el nivel más bajo (nivel de nodo hoja) y los nodos adyacentes están conectados mediante listas vinculadas.
Nota: El tiempo para leer datos de un disco no es muy diferente entre leer un byte, leer 10 bytes y leer una página, esto se debe a que la mayor parte del tiempo de búsqueda en el disco se dedica a la búsqueda y la rotación básicamente no requiere mucho tiempo. .
Diagrama de estructura simplificada del disco.
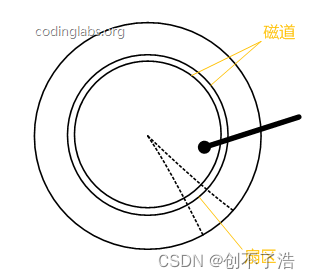
El disco está dividido en una serie de anillos concéntricos, siendo el centro del círculo el centro del disco. Cada anillo concéntrico se llama pista y todas las pistas con el mismo radio forman un cilindro. La pista se divide en pequeños segmentos a lo largo de la línea del radio. Cada segmento se denomina sector y cada sector es la unidad de almacenamiento más pequeña del disco. En aras de la simplicidad, asumimos a continuación que el disco tiene sólo un plato y un cabezal.
Cuando es necesario leer datos del disco, el sistema pasará la dirección lógica de los datos al disco y el circuito de control del disco traducirá la dirección lógica a una dirección física de acuerdo con la lógica de direccionamiento, es decir, determinará qué pista y sector los datos a leer están encendidos. Para poder leer los datos de este sector es necesario colocar el cabezal magnético sobre el sector, para lograr esto el cabezal magnético debe moverse para alinearse con la pista correspondiente, este proceso se llama búsqueda.
El principio de localidad y lectura anticipada del disco.
Debido a las características del medio de almacenamiento, la velocidad de acceso al disco en sí es mucho más lenta que la de la memoria principal y, junto con el consumo de movimiento mecánico, la velocidad de acceso al disco suele ser una centésima parte de la de la memoria principal. Por lo tanto, para mejorar la eficiencia, es necesario minimizar el número de discos E/S. Para lograr este objetivo, el disco a menudo no lee estrictamente según demanda, sino que lee por adelantado cada vez. Incluso si solo se necesita un byte, el disco comenzará desde esta posición y leerá secuencialmente una cierta longitud de datos hacia atrás en el memoria. La base teórica para hacer esto es el famoso principio de localidad en informática:
Cuando se utiliza un dato, los datos cercanos generalmente se utilizan inmediatamente.
Los datos necesarios durante la ejecución del programa suelen estar concentrados.
Debido a que las lecturas secuenciales de disco son muy eficientes (sin tiempo de búsqueda, muy poco tiempo de giro), la lectura anticipada puede mejorar la eficiencia de E/S para programas con localidad.
La longitud de lectura anticipada es generalmente un múltiplo entero de la página. Las páginas son bloques lógicos de memoria administrada por computadora. El hardware y los sistemas operativos a menudo dividen la memoria principal y las áreas de almacenamiento en disco en bloques consecutivos del mismo tamaño. Cada bloque de almacenamiento se llama página (en muchos sistemas operativos, el tamaño de la página suele ser 4k). Datos de intercambio de memoria principal y disco en unidades de páginas. Cuando los datos que leerá el programa no están en la memoria principal, se activará una excepción de falla de página. En este momento, el sistema enviará una señal de lectura al disco y el disco encontrará la posición inicial de los datos. y lea una o más páginas al revés, cargue en la memoria, luego regrese de manera anormal y el programa continúa ejecutándose.
Los principios detallados de los discos se pueden encontrar aquí: Estructura de datos y principios de algoritmo detrás de los índices MySQL
3. Hablemos de por qué el árbol b no es tan bueno como el árbol b+:
1 Los nodos internos del árbol B almacenan datos reales. Por ejemplo, un nodo es una página de 4096 bytes y cada dato tiene 128 bytes. Entonces un nodo solo puede almacenar 32 elementos de datos y el número máximo de correspondientes Los nodos secundarios son 33, lo que obviamente no es suficiente. Los nodos internos del árbol b+ solo se utilizan como guías y solo se almacena un número entero, 4096/4=1024 elementos de datos. De esta manera, cada nodo del árbol b + tiene más hijos y la altura de todo el árbol es menor, lo que aumenta en gran medida la eficiencia de la consulta.
2 Los nodos hoja del árbol b+ están conectados mediante listas vinculadas, lo cual es adecuado para consultas de rango porque las páginas adyacentes se pueden leer directamente. Pero b-tree no puede hacer esto.
Análisis de desempeño del índice B-/B+
