Introducir
Este blog es parcial a la teoría e introducirá algunos conocimientos:
- Introducción al índice
- Principio de indexación
- Estructura de datos del índice (árbol binario—> árbol binario balanceado—> árbol B—> árbol B +)
- Índice agrupado e índice auxiliar
- Gestión de índices MySQL
- Sintaxis para crear y eliminar índices
- Prueba después de la creación del índice (cambio en la velocidad de la consulta)
- Cómo usar el índice correctamente
- De vuelta a la mesa
- Índice de cobertura
- Índice conjunto
- Coincidencia de prefijo más a la izquierda
- Índice de empuje hacia abajo
- Optimización de consultas MySQL: explicar
- Los pasos básicos de la optimización lenta de consultas
- Gestión de registros lenta
1. Introducción al índice
1. ¿Qué es un índice?
- Un índice es una estructura de datos que ordena los valores de una o más columnas en una tabla de base de datos . El uso de un índice puede acceder rápidamente a información específica en una tabla de base de datos.
- Indexar una base de datos es como crear una tabla de contenido para un libro.
2. ¿Por qué debería haber un índice?
- Optimice la eficiencia de la consulta de datos
Los datos de la base de datos generalmente se almacenan en el disco. En comparación con la memoria, la velocidad de acceso del disco es más lenta. El índice es una estructura de datos que puede ayudar a la base de datos a encontrar datos del disco rápidamente.
- Nota: Una vez creado el índice, se reducirá la eficiencia de agregar, eliminar y modificar
Aunque se reducirá, el sistema de aplicación general tiene una relación de lectura-escritura de aproximadamente 10: 1, y las operaciones de inserción y las operaciones de actualización generales rara vez tienen problemas de rendimiento. Las consultas más frecuentes y más propensas a tener problemas siguen siendo algunas consultas complejas. Operación , por lo que la optimización de la declaración de consulta es obviamente la máxima prioridad
3. ¿Es mejor crear más índices para la tabla?
- En la mayoría de los casos, sabemos que los índices pueden mejorar la eficiencia de las consultas, pero demasiados índices también afectarán la eficiencia de la aplicación. Cómo agregar es la clave
- En el diseño de una aplicación, demasiados o muy pocos índices en los datos causarán la eficiencia de la aplicación, por lo que necesitamos encontrar un equilibrio
- Cuando la tabla tiene una gran cantidad de datos, la velocidad de creación del índice será muy lenta y el rendimiento de la escritura también se reducirá considerablemente.
4. ¿Cuándo se debe agregar el índice?
- Cualquier software tiene sus puntos brillantes para atraer usuarios. Detrás de los puntos brillantes están los datos calientes. Sin lugar a dudas, los desarrolladores deben agregar índices a los campos correspondientes con anticipación en el proceso de desarrollo de software para los campos de la base de datos correspondiente de datos calientes. , En lugar de esperar el software para conectarse y dejar que el DBA encuentre el sql de consulta lenta antes de procesar
la razón :
1. Un software que es lento afectará la experiencia del usuario, pero hay muchas razones para la lentitud. No puede determinar de inmediato que es el problema de SQL. Cuando localiza el problema de SQL, ha pasado mucho tiempo y el problema no se ha resuelto a tiempo.
2. La mayoría de los administradores de bases de datos son administradores de administración en lugar de desarrollo, por lo que incluso si el administrador de bases de datos ve SQL de consulta lenta en el registro, será difícil analizar la razón de la lentitud porque no comprende el negocio.
2. Principio del índice
1. El principio de indexación
- Filtre los resultados finales reduciendo continuamente el alcance de los datos que desea consultar
Por ejemplo, comprar un billete de tren ( sin índice ): si no hay un software de pedido de billetes de tren 12360, hay miles de trenes delante de nosotros. Las condiciones para elegir cuál incluyen el tipo de tren, la salida y el destino, la hora, etc. Debes comparar tus criterios de selección uno por uno. Si tienes suerte, el primer tren que buscas es el tren que buscas. Si no tienes suerte, el milésimo tren que estás buscando
Agregar índice : ahora solo tenemos que seleccionar el tren de alta velocidad en el software 12360, podemos filtrar los trenes que no son trenes de alta velocidad y limitar el alcance de la consulta; ingrese el punto de inicio y el punto final, y reducir el alcance de la consulta; ingrese la hora nuevamente, el alcance se reduce y finalmente se encuentra La cantidad de trenes que necesita ha cambiado de una cantidad no fija de consultas a una pequeña cantidad fija de consultas
2. E / S de disco y lectura anticipada
- Retraso de I \ O
Retardo de E / S = tiempo de búsqueda medio + tiempo de retardo medio (generalmente 9 ms) -> Ejemplo: Suponiendo que la velocidad actual del eje (disco) del disco duro es 7200 / min, que es 120 / s, entonces se necesitan 1 / 120≈ 8ms, la mitad un círculo es de 4 ms (asumiendo que se necesita medio círculo para encontrar los datos)
Aproximadamente 9ms es muy corto para nosotros, pero para una máquina de 500 MIPS, puede ejecutar 500 millones de instrucciones por segundo . En otras palabras , puede ejecutar 400,000 instrucciones en un tiempo de ejecución de IO , y la base de datos es fácilmente 100,000 millones. Incluso decenas de millones de datos, cada vez 9 milisegundos, esto es simplemente un desastre
- Pre-lectura
Teniendo en cuenta que la E / S de disco es una operación muy costosa, el sistema operativo de la computadora ha realizado algunas optimizaciones. Cuando una E / S, no solo los datos de la dirección del disco actual, sino también los datos adyacentes también se leen en el búfer de memoria, debido a la El principio de lectura previa nos dice que cuando una computadora accede a los datos de una dirección, también se accederá rápidamente a los datos adyacentes. Los datos leídos por cada IO se denominan página. La cantidad de datos en una página específica está relacionada con el sistema operativo, generalmente 4k u 8k, es decir, cuando leemos los datos en una página, solo ocurre un IO. Esta teoría es muy útil para el diseño de los datos del índice. estructura.
3. Estructura de datos del índice
La estructura de datos del índice es un árbol B + , y el árbol B + evoluciona de un árbol de ordenamiento binario a un árbol binario balanceado, luego a un árbol B y finalmente a un árbol B +. Aquí hay una breve introducción:
1. Árbol de ordenación binaria (árbol de búsqueda binaria)
- El nodo superior se llama nodo raíz y el nodo sin nodos secundarios se llama nodo hoja (la fila inferior)
Para una columna de números: 5, 6, 7, 8, 9, 10

- Si necesitamos encontrar el nodo con clave = 9, primero compare 9 con el nodo raíz, que es mayor que el nodo raíz, y luego mire a la derecha; continúe comparando con el 10 a la derecha, que es menor que, luego mira a la izquierda y encuentra exactamente nueve
Usando el árbol de ordenamiento binario, solo necesitamos 3 veces para encontrar los datos coincidentes; si buscamos uno por uno en la columna numérica, necesitamos 5 veces para encontrar
2. Árbol binario equilibrado (árbol AVL)
- Se puede decir que el árbol binario equilibrado es una versión mejorada del árbol de ordenación binaria, y es un árbol de ordenación binario especial.
Anteriormente explicamos que el árbol de clasificación binaria se puede usar para encontrar datos rápidamente; sin embargo, si el árbol de clasificación binario anterior se construye así:
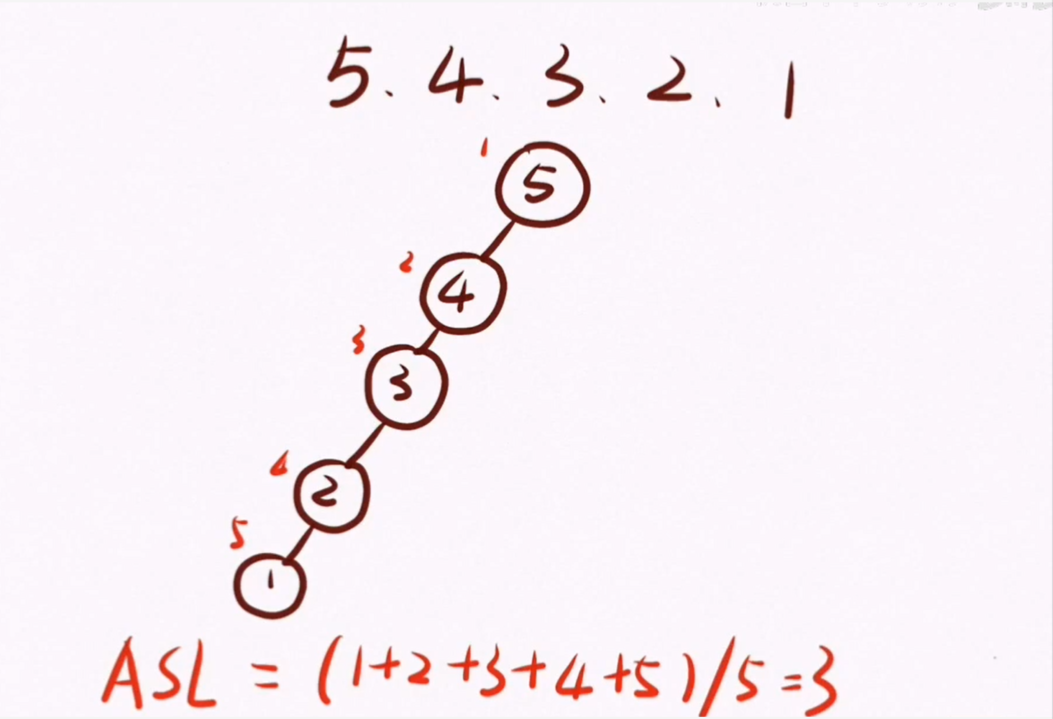
La duración media de la búsqueda es de 3, si ajustamos la secuencia de palabras clave
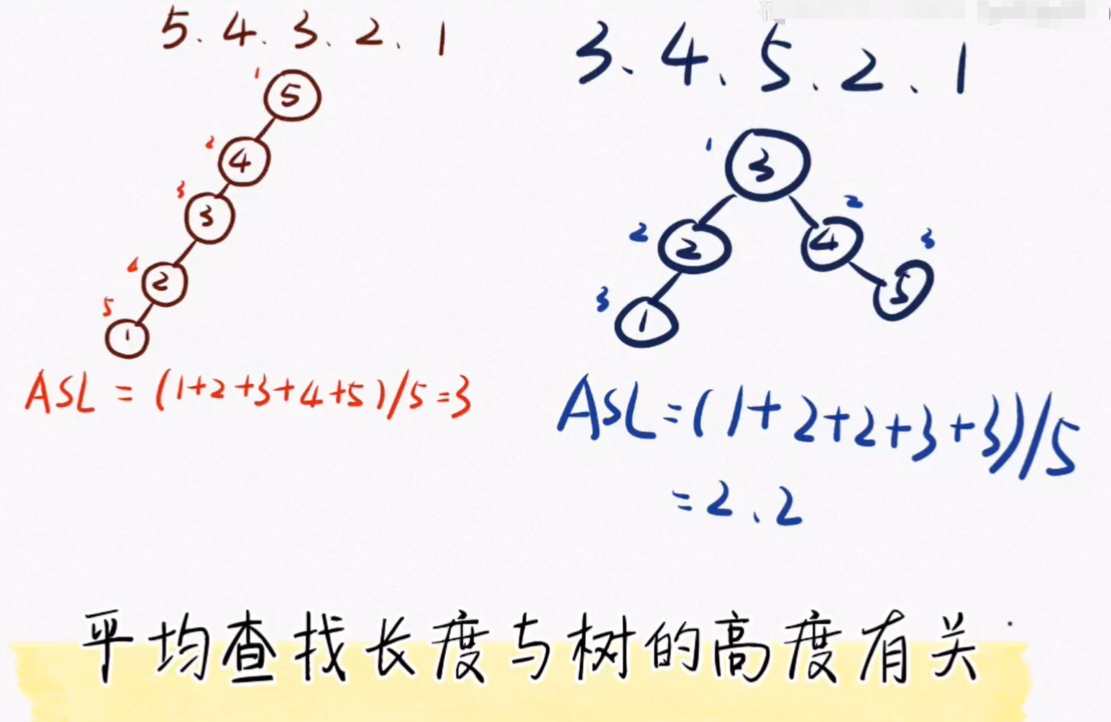
Después del ajuste, la longitud de búsqueda promedio es 2.2. De lo anterior podemos ver que la longitud de búsqueda promedio está relacionada con la altura del número. Cuanto menor sea la longitud de búsqueda promedio, más rápida será la velocidad de búsqueda, por lo que deberíamos hacer este árbol como lo más corto posible.
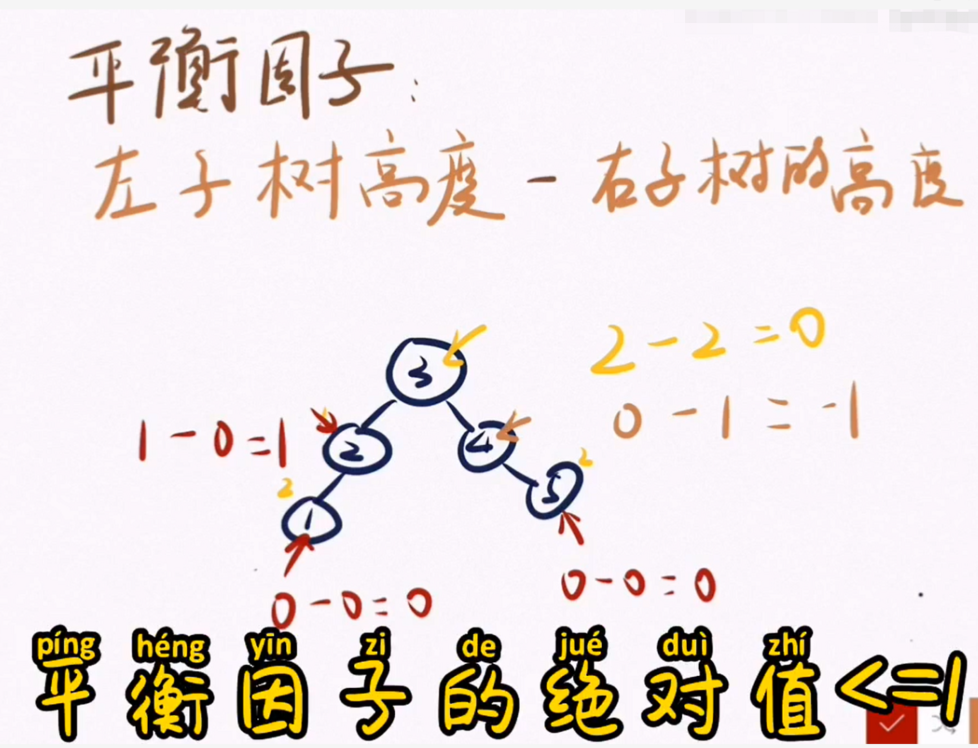
- ¿Cómo juzgar si un árbol binario es un árbol binario equilibrado?
Aquí se introduce el concepto de factor de equilibrio. La altura del subárbol izquierdo menos la altura del subárbol derecho es el factor de equilibrio. El valor absoluto del factor de equilibrio es menor o igual a uno es un árbol binario equilibrado, y mayor que uno es un árbol binario desequilibrado. Como se muestra en la figura siguiente, el factor de equilibrio es 4. Árbol binario desequilibrado

Ajustemos la secuencia de palabras clave, el valor absoluto de cada factor de balance de subnúmeros es menor o igual a 1, entonces este es un árbol binario balanceado
3. Árbol B (árbol equilibrado) árbol de búsqueda equilibrada multicanal
- Sabemos que cada nodo del árbol binario balanceado solo puede almacenar un valor clave y datos
¿Qué pasa si queremos almacenar grandes cantidades de datos? Es concebible que haya muchos nodos en el árbol binario, y la altura será extremadamente alta. Cuando busquemos datos, también realizaremos muchas E / S de disco, y nuestra eficiencia en la búsqueda de datos será extremadamente baja.
- Para resolver esta desventaja del árbol binario balanceado, deberíamos encontrar un árbol balanceado que pueda almacenar múltiples valores clave y datos en un solo nodo, es decir, árbol B
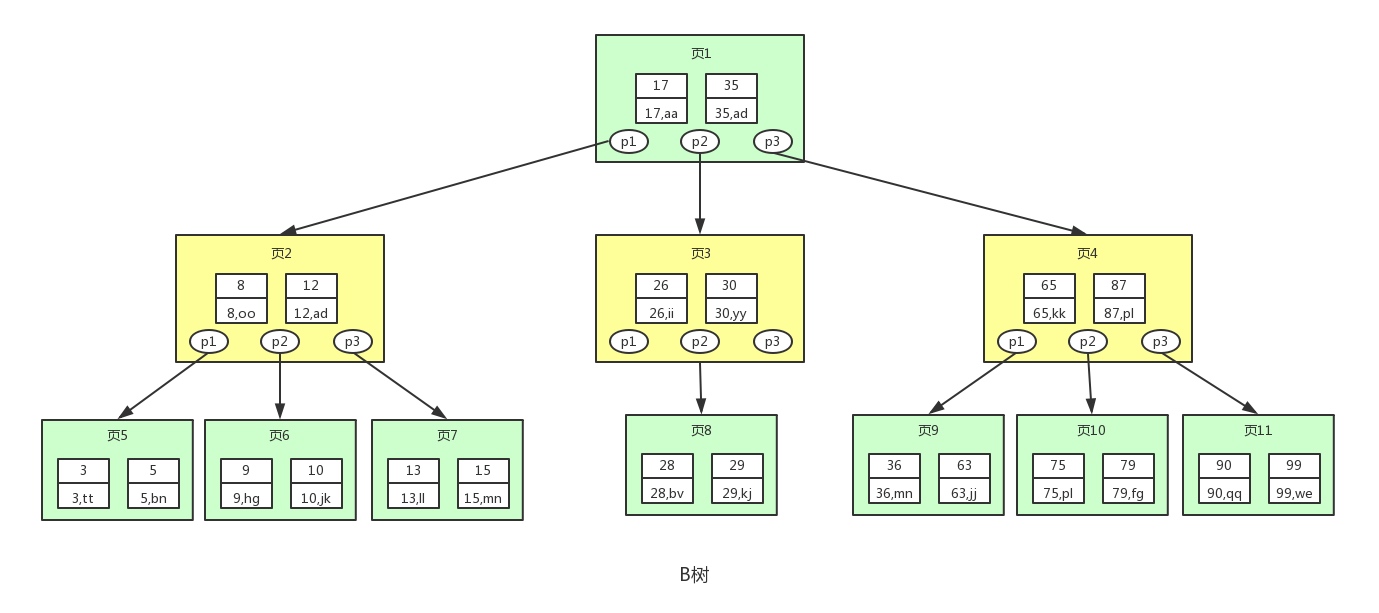
Como se puede ver en la figura anterior, en comparación con el árbol binario balanceado, cada nodo (el nodo en el árbol B se llama página) almacena más claves y datos, y cada nodo tiene más. El árbol B en la figura anterior es un árbol B de 3 órdenes y la altura será muy baja. Según esta función, la cantidad de veces que se leen los datos de búsqueda del árbol B desde el disco será pocas y la eficiencia de la búsqueda de datos será mucho mayor que la de un árbol binario balanceado.
Suponiendo que cada nodo puede almacenar dos valores (lo que no significa que solo se puedan almacenar dos), encontramos 75:
- Primero compare con la página 1, busque el puntero p3 en el lado derecho de 35 y ubíquelo en la página 4
- En comparación con el índice de la página 4, entre 65 y 87, busque el puntero p2 y ubíquelo en la página 10.
- Compare con el índice de la página 10, busque el 75
4.B + árbol
- El árbol B + es una optimización adicional del árbol B
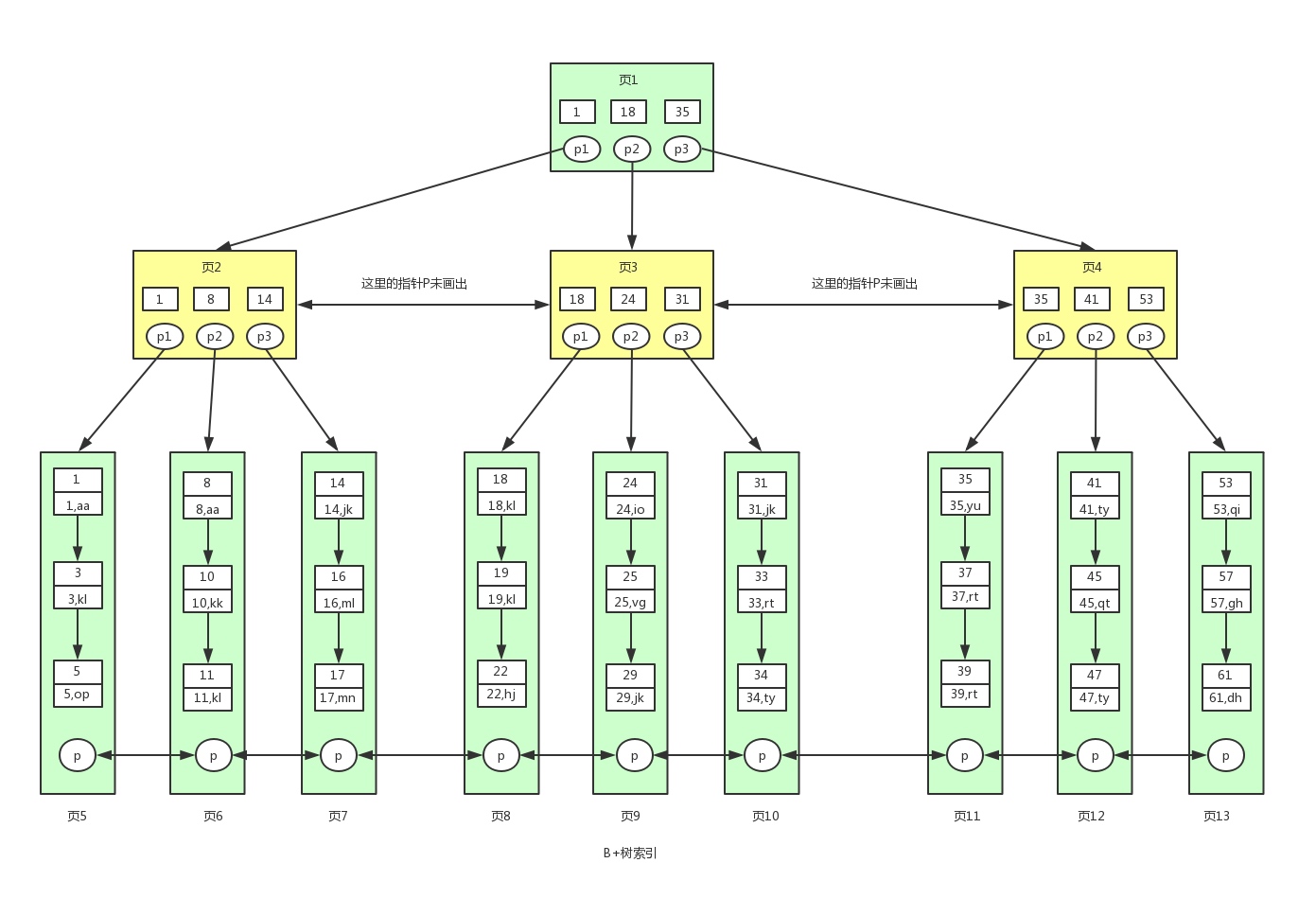
- A través de la figura anterior, comparemos la diferencia entre el árbol B + y el árbol B:
Los nodos de árbol B + no hoja no almacenan datos, solo valores clave , mientras que los nodos de árbol B no solo almacenan valores clave, sino que también almacenan datos
La razón de esto es que el tamaño de página en la base de datos es fijo y el tamaño de página predeterminado en InnoDB es 16 KB. Si los datos no se almacenan, se almacenarán más valores clave, el orden del árbol correspondiente (el árbol del nodo hijo del nodo) será más grande, el árbol será más corto y más grueso, de modo que podamos encontrar los datos para el disco El número de IO se reducirá nuevamente y la eficiencia de la consulta de datos será más rápida
El orden del árbol B + es igual al número de valores clave. Si un nodo de nuestro árbol B + puede almacenar 1000 valores clave, entonces el árbol B + de 3 capas puede almacenar 1000 × 1000 × 1000 = mil millones de datos.
Generalmente, el nodo raíz reside en la memoria , por lo que generalmente solo necesitamos 2 E / S de disco para encontrar mil millones de datos.
Un árbol b + de 3 niveles puede representar millones de datos. Si solo se necesitan dos IO para encontrar millones de datos, la mejora del rendimiento será enorme. Si no hay un índice, cada elemento de datos tendrá un IO, por lo que la necesidad total Millones de IO, obviamente el costo es muy, muy alto
- Dos propiedades del árbol B +
- El campo de índice debe ser lo más pequeño posible: el tamaño del bloque de disco es el tamaño de una página de datos, que es fijo. Si el espacio ocupado por el elemento de datos es menor, el número de elementos de datos es mayor, la altura de el árbol es más bajo, el IO que se ha consultado Menos veces. Es por eso que cada elemento de datos, es decir, el campo de índice debe ser lo más pequeño posible, por ejemplo, int ocupa 4 bytes, que es la mitad menos que bigint8 bytes. Esta es la razón por la que el árbol b + requiere que los datos reales se coloquen en los nodos hoja en lugar de en los nodos internos. Una vez colocados en los nodos internos, los elementos de datos del bloque de disco se reducirán considerablemente y la disminución dará como resultado menos datos que se pueden almacenar en cada capa. Debido a que el bloque de disco es fijo, el nivel aumenta, lo que conduce al aumento del árbol. El aumento del árbol significa que el número de IO para encontrar los datos subyacentes aumenta, lo que resulta en un disminución significativa en la velocidad de la consulta
- La característica de coincidencia más a la izquierda del índice: cuando el elemento de datos del árbol b + es una estructura de datos compuesta, como (nombre, edad, sexo), el número b + se crea en el orden de izquierda a derecha para construir el árbol de búsqueda. Por ejemplo, cuando (Zhang Tres, 20, F) Al buscar datos como este, el árbol b + comparará el nombre primero para determinar la siguiente dirección de búsqueda. Si el nombre es el mismo, entonces compare la edad y el sexo por turnos, y finalmente obtenga los datos recuperados. Pero cuando (20, F) Cuando aparecen tales datos sin nombre, el árbol b + no sabe qué nodo verificar a continuación, porque el nombre es el primer factor de comparación al construir el árbol de búsqueda, y primero debe buscar por nombre para conocer el siguiente paso. Por ejemplo, al buscar datos como (Zhang San, F), el árbol b + puede usar el nombre para especificar la dirección de búsqueda, pero falta la siguiente edad del campo, por lo que solo puede encontrar todos los datos con el nombre igual a Zhang San, y luego hacer coincidir el género. Son los datos de F. Esta es una propiedad muy importante, es decir, la característica de coincidencia más a la izquierda del índice
5. Resuma las ventajas del árbol B +
- Sobre la base del árbol binario, el árbol binario balanceado y el árbol B, se realiza una mayor optimización. Solo los nodos hoja contienen datos reales, lo que significa que la altura del árbol B + es la más baja bajo la premisa de la misma cantidad de datos.
- Los nodos hoja de B + están todos ordenados, lo que significa que en la consulta de rango, el árbol B + es más rápido que el árbol B. Una vez que se encuentra un nodo hoja, no hay necesidad de buscar desde la raíz del árbol.