Directorio de artículos
1. Índice de la base de datos
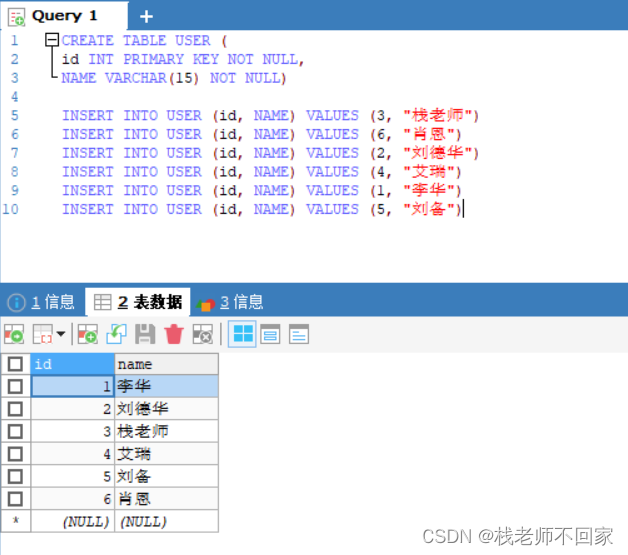
El propósito de la indexación es mejorar la velocidad de consulta de los datos, lo que equivale a numerar los datos. Al buscar datos, los datos correspondientes se pueden encontrar rápidamente mediante la numeración. El índice utiliza la estructura de datos B + Tree.
Cuando los datos se insertan desordenados, se ordenarán automáticamente en orden ascendente según la identificación. Esto se debe a que la clave principal tiene su propio índice:
2. Estructura del índice de árbol B +
La estructura interna del almacenamiento de datos es similar a la forma de una lista vinculada y se asocian diferentes datos mediante punteros. El primer bit es el índice, el segundo bit son los datos y el tercer bit es el puntero sucesor (que apunta al siguiente nodo).

Después de todo, es similar a una lista vinculada: cuando la cantidad de datos es grande, la velocidad de consulta de esta estructura sigue siendo muy lenta, entonces, ¿cómo lo resuelve MySQL?
Existe un concepto de página en MySQL, que es equivalente a paginar datos.Almacene parte de los datos en una página, primero verifique la página y luego los datos.Equivale a una gestión de clasificación.

Cada página puede almacenar 16 KB de datos, lo que equivale a establecer un directorio de nivel superior para los datos. Al buscar, primero busque el directorio grande y luego busque los datos específicos.
MYSQL también proporciona un directorio de consulta rápida para páginas, de modo que pueda saber claramente en qué página se encuentran los datos que desea consultar y luego ir directamente a esa página para encontrarlos.
多一层目录可提高数据查询的效率!
Saque el índice y el puntero posterior del primer dato de cada página y colóquelos en el directorio de la página.1P primera página, 3P segunda página, 5P tercera página.
Al consultar datos, primero encontrará su página, y la página depende del rango en el que se encuentre la identificación. Por ejemplo, los datos con id = 4 están en la segunda página (porque 3 <id <5). Después de encontrar la página, ingrese a la página para buscar datos específicos.
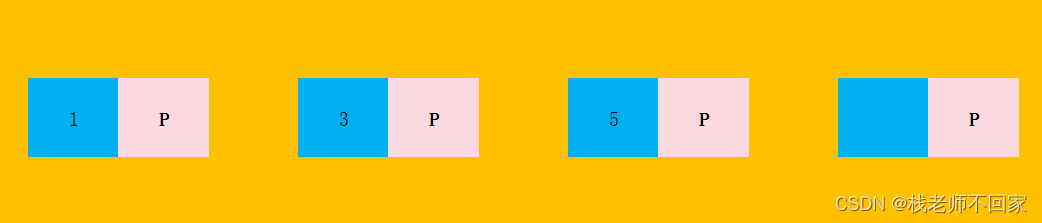
Este directorio también tiene capacidad, por lo que también abriremos el directorio de la segunda y enésima página. Un directorio de páginas también puede almacenar 16 KB de datos. Si hay datos masivos, habrá muchos directorios de páginas, por lo que la consulta será relativamente lenta.
Para mejorar la eficiencia de las consultas, MYSQL agrega otra capa de directorios al directorio de la página.
Con el mismo método, el primer elemento (índice y puntero) de cada directorio de páginas todavía se extrae y se almacena en el directorio de nivel superior.
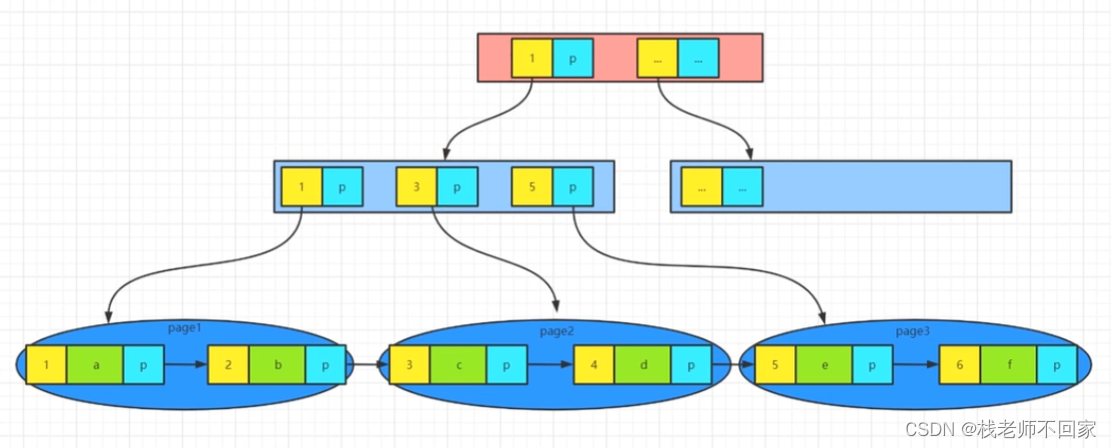
一般来说三层目录就足够了,要查找一个数据的时候,就从最上面一层一层分级查找,而这种结构就叫做 B+Tree!
Suponiendo que el espacio de un registro es de 32 bytes, entonces los datos que se pueden almacenar en una unidad en el nivel inferior son 16 * 1024/32 = 512 piezas; el segundo nivel solo necesita registrar id y p, suponiendo que sea
6 bytes, entonces una unidad puede almacenar Los datos son 16 * 1024/6 = 2730 piezas;
los datos almacenados en cada unidad de la tercera capa son los mismos que los de la segunda capa, que son 2730 piezas.
Por lo tanto, el número total de elementos de datos que se pueden almacenar es la multiplicación de las tres capas de datos: 512 * 2730 * 2730 = 3,8 mil millones.