1 データベースチューニングの対策
1.1 調整目標
节省系统资源システムがより大きな負荷に対応できるように、できるだけ多くのことを行います。(スループットの向上)- 合理的な構造設計とパラメータ調整により、ユーザーの操作性を向上させます
响应的速度。(より速い応答) - システムのボトルネックを軽減し、MySQL データベースの全体的なパフォーマンスを向上させます。
1.2 チューニングの問題を特定する方法
どうやって判断するのか?一般に、次のようないくつかの方法があります。
- ユーザーの声(主なもの)
- ログ解析(メイン)
- サーバーリソースの使用状況の監視
- データベースの内部状態監視
- 他の
アクティブなセッションの監視に加えて、なども監視でき、事务データベースの稼働状況をより包括的に把握できます。锁等待
1.3 寸法とチューニング手順
チューニングする必要があるオブジェクトはデータベース管理システム全体であり、これには SQL クエリだけでなく、データベースのデプロイメント構成、アーキテクチャなどが含まれます。この観点から見ると、私たちの考え方の次元は SQL の最適化に限定されません。以下の手順で整理していきます。
ステップ 1: 適切な DBMS を選択する
ステップ 2: テーブル設計を最適化する
ステップ 3: 論理クエリを最適化する
ステップ 4: 物理クエリの最適化.
物理クエリの最適化とは、論理クエリの最適化を決定した後、コスト モデルを計算することにより、物理最適化テクノロジ (インデックスなど) を使用して
、可能なさまざまなアクセス パスを推定し、最低コストの実行を見つけることです。メソッド、実行計画として。在这个部分中,我们需 要掌握的重点是对索引的创建和使用。
ステップ 5: Redis または Memcached をキャッシュとして使用する
SQL 自体の最適化に加えて、クエリ効率を向上させるために外部の助けを求めることもできます。
データはデータベースに保存されているため、ビジネス ロジックの操作のためにデータベース層からデータを取得してメモリに配置する必要があり、ユーザー数が増加すると、頻繁なデータ クエリによってデータベース リソースが大量に消費されます。よく使用されるデータをメモリに直接配置すると、クエリの効率が大幅に向上します。
Key-Value ストレージ データベースは、この問題の解決に役立ちます。
一般的に使用されるキーと値のストレージ データベースには Redis と Memcached があり、どちらもデータをメモリに保存できます。
ステップ 6: ライブラリレベルの最適化
1. 読み取りと書き込みの分離
2. データの断片化
ただし、分割によりデータベースのパフォーマンスは向上しますが、メンテナンスと使用コストも増加することに注意してください。
2 MySQLサーバーの最適化
2.1 サーバーハードウェアの最適化
服务器的硬件性能直接决定着MySQL数据库的性能。ハードウェアのパフォーマンスのボトルネックは、MySQL データベースの実行速度と効率を直接決定します。パフォーマンスのボトルネックに対するハードウェア構成を改善すると、MySQL データベースのクエリと更新の速度が向上します。(1) 配置较大的内存(2) 配置高速磁盘系统(3) 合理分布磁盘I/O(4)配置多处理器
2.2 MySQL パラメータの最適化
-
innodb_buffer_pool_size: このパラメータは、Mysql データベースの最も重要なパラメータの 1 つであり、InnoDB のタイプを示します表和索引的最大缓存。索引数据単にキャッシュするだけではありません表的数据。この値が大きいほど、クエリが高速になります。ただし、この値が大きすぎると、オペレーティング システムのパフォーマンスに影響します。 -
key_buffer_size: を意味します索引缓冲区的大小。必要なのはインデックス バッファだけです线程共享。インデックス バッファを増やすと、(すべての読み取りと複数の書き込みに対して) インデックスの処理が向上します。もちろん、値が大きいほど良いのですが、そのサイズはメモリのサイズに依存します。この値が大きすぎると、オペレーティング システムが頻繁にページを変更し、システムのパフォーマンスが低下します。のメモリを備えたサーバーの場合、このパラメータはまたは4GBに設定できます。256M384M -
table_cache: を意味します同时打开的表的个数。この値が大きいほど、同時に開くことができるテーブルの数が増えます。物理メモリが大きいほど、設定も大きくなります。デフォルトは 2402 ですが、512 ~ 1024 に調整するのが最善です。同時に開くテーブルが多すぎるとオペレーティング システムのパフォーマンスに影響を与えるため、値が大きいほど良いです。 -
query_cache_size: を意味します查询缓冲区的大小。これは MySQL コンソールで確認できます。Qcache_lowmem_prunes の値が非常に大きい場合は、バッファリングが不十分であることが多いため、Query_cache_size の値を増やす必要があることを示します。Qcache_hits の値が非常に大きい場合は、クエリ バッファは非常に頻繁に使用されます。値が小さい場合は効率に影響するため、キャッシュをクエリしないことを検討できます。値が非常に大きい場合は、Qcache_free_blocks が多数あることを示します。バッファ内のフラグメント。MySQL8.0以降は無効です。このパラメータは、query_cache_type と組み合わせて使用する必要があります。 -
query_cache_type値が 0 の場合、すべてのクエリはクエリ キャッシュを使用しません。ただし、query_cache_type=0 を指定しても、MySQL は query_cache_size で設定されたキャッシュ メモリを解放しません。SQL_NO_CACHEquery_cache_type=1 の場合、 SELECT SQL_NO_CACHE * FROM tbl_name などのクエリ ステートメントで指定されていない限り、すべてのクエリはクエリ キャッシュを使用します。- query_cache_type=2 の場合、クエリはキーワードがクエリ ステートメントで使用されている場合にのみ
SQL_CACHEクエリ キャッシュを使用します。クエリ キャッシュを使用すると、クエリの速度が向上します。この方法は、変更操作がほとんどなく、同じクエリ操作が頻繁に実行される状況にのみ適しています。
-
sort_buffer_size: はそれぞれを意味します需要进行排序的线程分配的缓冲区的大小。このパラメータの値を増やすと、ORDER BY操作の速度が向上しますGROUP BY。デフォルト値は 2097144 バイト (約 2MB) です。約 4GB のメモリを搭載したサーバーの場合、推奨設定は 6 ~ 8M で、接続数が 100 の場合、割り当てられるソート バッファの合計サイズは 100 × 6 = 600MB になります。 -
join_buffer_size = 8M:联合查询操作所能使用的缓冲区大小sort_buffer_size と同様に、このパラメータに対応する割り当てられたメモリも各接続に排他的であることを示します。 -
read_buffer_size: を意味します每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节)。このバッファは、スレッドがテーブルからレコードを連続的に読み取る場合に必要です。SET SESSION read_buffer_size=n は、このパラメータの値を一時的に設定できます。デフォルトは 64K ですが、4M に設定できます。 -
innodb_flush_log_at_trx_commit: は、何时将缓冲区的数据写入日志文件ログ ファイルをディスクに書き込みます。このパラメータは innoDB エンジンにとって非常に重要です。このパラメータには 0、1、2 の 3 つの値があります。このパラメータのデフォルト値は 1 です。- の値は、データがログ ファイルに書き込まれ、ログ ファイルがディスクに書き込まれる頻度を
0示します。每秒1次各トランザクションのコミットによって、以前の操作はトリガーされません。このモードは最も高速ですが、安全性が低く、mysqld プロセスがクラッシュすると、直前の 1 秒間のすべてのトランザクション データが失われます。 - 値が の場合、データをログ ファイルに書き込み、同期のためにログ ファイルをディスクに書き込むことを
1意味します。每次提交事务时このモードは最も安全ですが、最も遅くなります。なぜなら、トランザクションの送信やトランザクション外の命令では、ログをハードディスクに書き込む (フラッシュする) 必要があるからです。 - 値が の場合、データをログ ファイルに書き込み、ログ ファイルをディスクに書き込むこと
2を意味します。このモードは 0 よりも高速かつ安全です。オペレーティング システムがクラッシュするかシステムの電源がオフになった場合にのみ、直前の 1 秒間のすべてのトランザクション データが失われる可能性があります。每次提交事务时每隔1秒 innodb_log_buffer_size: これは InnoDB ストレージ エンジン用です事务日志所使用的缓冲区。パフォーマンスを向上させるために、情報は最初に Innodb ログ バッファにも書き込まれます。innodb_flush_log_trx_commit パラメータで設定された対応する条件が満たされると (またはログ バッファがいっぱいになると)、ログはファイルに書き込まれます (またはログ バッファに同期されます)。ディスク)。
- の値は、データがログ ファイルに書き込まれ、ログ ファイルがディスクに書き込まれる頻度を
-
max_connections: は を意味し允许连接到MySQL数据库的最大数量、デフォルト値は です151。ステータス変数 connection_errors_max_connections がゼロではなく、増加し続ける場合は、データベース接続数が最大許容値に達したため、接続リクエストが失敗し続けていることを意味します。この場合、max_connections の値を増やすことを検討できます。Linux プラットフォームでは、500 ~ 1000 の接続をサポートするのは、パフォーマンスの良いサーバーであれば難しくありませんが、サーバーのパフォーマンスに基づいて評価し、設定する必要があります。この接続数は不是越大越好、これらの接続がメモリ リソースを浪費するためです。接続が多すぎると、MySQL サーバーがフリーズする可能性があります。 -
back_log: に使用されます控制MySQL监听TCP端口时设置的积压请求栈大小。MySql 接続数が max_connections に達すると、新しいリクエストはスタックに保存され、特定の接続がリソースを解放するのを待ちます。スタックの数は back_log です。待機中の接続数が back_log を超えると、接続リソースは付与されません. エラーが報告されます。バージョン 5.6.6 より前のデフォルト値は 50 で、それ以降のバージョンのデフォルト値は 50 + (max_connections / 5) です。Linux システムの場合は、512 未満の整数に設定することをお勧めしますが、最大値は超えません900。データベースが短期間に大量の接続要求を処理する必要がある場合は、back_log の値を適切に増やすことを検討できます。 -
thread_cache_size:线程池缓存线程数量的大小、クライアントの切断後に現在のスレッドをキャッシュし、新しい接続要求を受信したときに新しいスレッドを作成せずに迅速に応答します。これにより、特に短い接続を使用するアプリケーションの場合、接続作成の効率が大幅に向上します。パフォーマンスを向上させるために、このパラメータの値を増やすことができます。デフォルトは 60 ですが、120 に設定できます。
スレッド プールのサイズは、次の MySQL ステータス値によって適切に調整できます。mysql> show global status like 'Thread%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 2 | | Threads_connected | 1 | | Threads_created | 3 | | Threads_running | 2 | +-------------------+-------+ 4 rows in set (0.01 sec)Threads_cached がどんどん少なくなっても、Threads_connected が減らず、Threads_created が増加し続ける場合、thread_cache_size のサイズを適切に増やすことができます。
-
wait_timeout: を指定します一个请求的最大连接时间。メモリが 4GB 程度のサーバーの場合、5 ~ 10 に設定できます。 -
interactive_timeout: 接続を閉じる前にサーバーがアクションを待機する秒数を示します。
my.cnf の参照構成は次のとおりです。
[mysqld]
ポート = 3306
サーバー ID = 1
ソケット = /tmp/mysql.sock
Skip-locking #MySQL の外部ロックを回避し、エラーの可能性を減らし、安定性を高めます。
Skip-name-resolve #MySQL による外部接続での DNS 解決の実行を禁止します。このオプションを使用すると、MySQL が DNS 解決を実行するのにかかる時間を短縮できます。ただし、このオプションをオンにすると、すべてのリモート ホストの接続認証で IP アドレスを使用する必要があることに注意してください。そうしないと、MySQL が接続リクエストを正常に処理できなくなります。
back_log = 384 key_buffer_size = 256M
max_allowed_packet = 4M
thread_stack = 256K
table_cache = 128K
sort_buffer_size = 6M
read_buffer_size = 4M
read_rnd_buffer_size=16M
join_buffer_size = 8M
myisam_sort_buffer_size = 64M
table_cache = 512
thread_cache _size = 64
query_cache_size = 64M
tmp_table_size = 256M
max_connections = 768
max_connect_errors = 10000000
wait_timeout = 10
thread_concurrency = 8 #このパラメータの値は、サーバー 2 の論理 CPU の数です。この例では、サーバーには 2 つの物理 CPU があり、各物理 CPU は HT ハイパースレッディングをサポートしているため、実際の値は 4 です。 2=8
stopnetworking #MySQL の TCP/IP 接続を完全にオフにするには、このオプションをオンにします。WEB サーバーがリモート接続を通じて MySQL データベース サーバーにアクセスする場合は、このオプションをオンにしないでください。そうしないと、通常の接続ができなくなります。
table_cache=1024
innodb_Additional_mem_pool_size=4M #デフォルトは 2M
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=2M #デフォルトは 1M
innodb_thread_concurrency=8 #サーバーの数と同じ数の CPU を設定します。デフォルト値 8 を使用することをお勧めします
tmp_table_size=64M #デフォルトは 16M ですが、64 ~ 256 に調整し、thread_cache_size
=120
query_cache_size=32M
多くの状況では、特定の状況の詳細な分析が必要です。
3 データベース構造の最適化
3.1 分割テーブル: ホット データとコールド データの分離
例 1 :会员members表メンバーのログイン認証情報を保存する このテーブルには、ID、名前、パスワード、住所、電話番号、個人の説明フィールドなど、多くのフィールドがあります。住所、電話番号、個人的な説明などのフィールドは一般的には使用されないため、これらの一般的ではないフィールドは別のテーブルに分解できます。このテーブルに members_detail という名前を付けます。テーブルには member_id、住所、電話番号、説明などのセグメントがあります。このようにして、メンバーシップ テーブルは と の 2 つのテーブルに分割されmembers表ますmembers_detail表 。
これら 2 つのテーブルを作成する SQL ステートメントは次のとおりです。
CREATE TABLE members (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(50) DEFAULT NULL,
password varchar(50) DEFAULT NULL,
last_login_time datetime DEFAULT NULL,
last_login_ip varchar(100) DEFAULT NULL,
PRIMARY KEY(Id)
);
CREATE TABLE members_detail (
Member_id int(11) NOT NULL DEFAULT 0,
address varchar(255) DEFAULT NULL,
telephone varchar(255) DEFAULT NULL,
description text
);
メンバーの基本情報または詳細情報を照会する必要がある場合は、メンバーの ID を使用して照会できます。メンバーの基本情報と詳細情報を同時に表示する必要がある場合は、 members テーブルと members_detail テーブルを組み合わせてクエリを実行できます。クエリ ステートメントは次のとおりです。
SELECT * FROM members LEFT JOIN members_detail on members.id =
members_detail.member_id;
この分解により、テーブルのクエリ効率が向上します。多くのフィールドを含むテーブルや、使用頻度が低い一部のフィールドの場合、この分解を通じてデータベースのパフォーマンスを最適化できます。
3.2 中間テーブルの追加
例 1 :学生信息表およびの SQL ステートメントは班级表次のとおりです。
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
ここには、学生の名前 (name)、学生のクラス名 (className)、および学生のクラス モニター (monitor) を使用して学生情報を頻繁にクエリする必要があるモジュールがあります。この状況に基づいてテーブルを作成できますtemp_student。temp_student テーブルには、学生名 (stu_name)、学生クラス名 (className)、および学生クラス モニター (monitor) 情報が格納されます。テーブルを作成するステートメントは次のとおりです。
CREATE TABLE `temp_student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stu_name` INT NOT NULL ,
`className` VARCHAR(20) DEFAULT NULL,
`monitor` INT(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
次に、学生情報テーブルとクラス テーブルから関連情報をクエリし、一時テーブルに保存します。
insert into temp_student(stu_name,className,monitor)
select s.name,c.className,c.monitor
from student as s,class as c
where s.classId = c.id
将来的には、毎回結合クエリを実行することなく、学生名、クラス名、およびクラス モニターを temp_student テーブルから直接クエリできるようになります。これにより、データベースのクエリ速度が向上します。
3.3 冗長フィールドの追加
データベース テーブルを設計するときは、パラダイム理論の規則に従い、冗長なフィールドを可能な限り削減して、データベース設計を洗練されたエレガントに見せるようにする必要があります。ただし、冗長フィールドを合理的に追加すると、クエリ速度が向上します。
テーブルの正規化の程度が高くなるほど、テーブル間の関係が多くなり、結合クエリが必要となる状況が増えます。特にデータ量が多く、頻繁に接続が必要な場合は、効率を上げるために冗長フィールドを追加して接続を減らすことも検討できます。
3.4 データ型の最適化
ケース 1: 整数型データで最適化します。
これは、整数型のフィールドに遭遇したときに使用できますINT 型。その理由は、INT 型のデータは値の範囲が十分に大きいため、値の範囲を超えるデータを気にする必要がないからです。初めてプロジェクトを開始するときは、まずシステムの安定性を確保する必要があるため、フィールド タイプを設計するだけで問題ありません。ただし、データ量が多い場合、データ型の定義はシステム全体の実行効率に大きな影響を与えます。
非负型データ (自動インクリメント ID、整数 IP など)の場合は、最初に符号なし整数型を使用してUNSIGNED格納する必要があります。unsigned は、同じバイト数でも、signed よりも保存される値の範囲が広いためです。たとえば、 tinyint は -128 ~ 127 で署名され、0 ~ 255 で署名されないため、記憶域スペースが 2 倍になります。
シナリオ 2: テキスト タイプまたは整数タイプのフィールドを使用できますが、整数タイプを使用することを選択する必要があります。
テキスト型データと比較して、大きな整数は占有する記憶領域が少なくなる傾向があるため、アクセスおよび比較する際に占有するメモリ領域が少なくなります。したがって、両方が使用可能な場合は、クエリ効率を向上させることができる整数型を使用するようにしてください。例: IP アドレスを整数データに変換します。
ケース 3: TEXT および BLOB データ型の使用を避ける
ケース 4: ENUM タイプの使用を避ける
ケース 5: TIMESTAMP を使用して時刻を保存する
ケース 6: 正確な浮動小数点数を格納するには、FLOAT および DOUBLE の代わりに DECIMAL を使用します。
つまり、大量のデータを扱うプロジェクトに直面した場合、リソースの効率を最大限に活用して最適なシステムを実現するには、ビジネス ニーズを十分に理解することを前提として、データの種類を合理的に最適化する必要があります。
3.5 レコードの挿入速度の最適化
1. MyISAM エンジン テーブル:
① インデックス作成を無効にする
② 一意性チェックを無効にする
③一括挿入を利用する
insert into student values(1,'zhangsan',18,1);
insert into student values(2,'lisi',17,1);
insert into student values(3,'wangwu',17,1);
insert into student values(4,'zhaoliu',19,1);
1 つの INSERT ステートメントを使用して複数のレコードを挿入する状況は次のとおりです。
insert into student values
(1,'zhangsan',18,1),
(2,'lisi',17,1),
(3,'wangwu',17,1),
(4,'zhaoliu',19,1);
2番目のケースの挿入速度は、1番目のケースよりも速い。
④LOAD DATA INFILEを使って一括インポートする
2. InnoDB エンジン テーブル:
① 一意性チェックを無効にする
② 外部キー チェックを無効にする
③ 自動送信を無効にする
3.6 非 null 制約の使用
フィールドを設計するとき、ビジネスで許可されている場合は、可能な限り非 null 制約を使用することをお勧めします。
3.7 分析表、チェックリスト、最適化表
1. 分析表
MySQL には ANALYZE TABLE ステートメント分析テーブルが用意されており、ANALYZE TABLE ステートメントの基本構文は次のとおりです。
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name]…
デフォルトでは、MySQL サービスは ANALYZE TABLE ステートメントを binlog に書き込み、スレーブ サービスがマスター/スレーブ アーキテクチャでデータを同期できるようにします。パラメータ LOCAL または NO_WRITE_TO_BINLOG を追加して、バイナリログへのステートメントの書き込みをキャンセルできます。
を使用してテーブルを分析するプロセス中にANALYZE TABLE、データベース システムはテーブルにテーブルを自動的に追加します只读锁。分析中はテーブル内のレコードのみを読み取ることができ、更新や挿入はできません。ANALYZE TABLE ステートメントは、InnoDB および MyISAM タイプのテーブルを分析できますが、ビューに対して動作することはできません。
ANALYZE TABLE 分析後の統計結果にはcardinality、テーブル内の特定のキーが存在する列の一意の値の数をカウントする の値が反映されます。该值越接近表中的总行数,则在表连接查询或者索引查询时,就越优先被优化器选择用。つまり、インデックス列のカーディナリティ値とテーブル内のデータの総数の差が大きければ、インデックスがクエリ条件として使用される場合でも、ストレージ エンジンがクエリ時にそのカーディナリティを使用する可能性は低くなります。例で検証してみましょう。カーディナリティは、SHOW INDEX FROM テーブル名を通じて表示できます。
2. チェックリスト
MySQL ではステートメントを使用してCHECK TABLEテーブルをチェックできます。CHECK TABLE ステートメントは、InnoDB および MyISAM タイプのテーブルのエラーをチェックできます。CHECK TABLE ステートメントは、実行中にテーブルに読み取り専用ロックも追加します。
MyISAM タイプのテーブルの場合、CHECK TABLE ステートメントはキーワード統計も更新します。さらに、CHECK TABLE は、ビュー定義で参照されているテーブルが存在しないなど、ビューにエラーがあるかどうかもチェックできます。このステートメントの基本的な構文は次のとおりです。
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {
QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
このうち、tbl_name はテーブル名で、オプション パラメータには QUICK、FAST、MEDIUM、EXTENDED、
CHANGED の 5 つの値があります。各オプションの意味は次のとおりです。
QUICK: ラインをスキャンしたり、接続不良をチェックしたりしません。
FAST: 正しく閉じられていないテーブルのみをチェックします。
CHANGED: 前回のチェック以降に変更されたテーブルと、適切に閉じられていないテーブルのみをチェックします。
中: 行をスキャンして、切断された接続が有効であることを確認します。各行のキーワード チェックサムを計算し、計算された
チェックサムを使用してこれを検証することもできます。
拡張: 各行のすべてのキーワードに対して包括的なキーワード検索を実行します。これにより、テーブルの一貫性が 100% 保証されますが、
時間がかかります。
オプションは、MyISAM タイプのテーブルに対してのみ有効であり、InnoDB タイプのテーブルには有効ではありません。例:
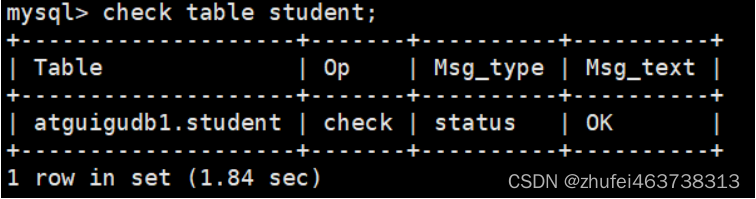
このステートメントは、チェック対象のテーブルに関する複数行の情報を生成する場合があります。最後の行にはステータスの Msg_type 値があり、通常は Msg_text が OK です。OK でない場合は、通常、修復する必要があります。OK であれば、テーブルはすでに最新の状態になっています。テーブルはすでに最新であるため、ストレージ エンジンはテーブルをチェックする必要がありません。
3. テーブルを最適化する
方法 1: テーブルを最適化する
MySQL ではステートメントを使用してOPTIMIZE TABLEテーブルを最適化します。ただし、OPTILMIZE TABLE ステートメントは、 type のフィールド
VARCHAR、BLOBまたはtable 内のフィールドのみを最適化できますTEXT。テーブルでこれらのフィールドのデータ型が使用されている場合、删除テーブルのデータの大部分を読み取った場合、または可変長行を含むテーブル (VARCHAR を含むテーブル) に多くの変更を加えた場合は、OPTIMIZE TABLE を使用する必要があります更新。、BLOB、または TEXT 列)を使用して、未使用の領域を再利用し、データ ファイルを整理します碎片。
OPTIMIZE TABLE ステートメントは、InnoDB タイプと MyISAM タイプのテーブルの両方に有効です。このステートメントは、実行中にテーブルにも追加されます只读锁。
OPTILMIZE TABLE ステートメントの基本構文は次のとおりです。
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
LOCAL | NO_WRITE_TO_BINLOG キーワードの意味は、バイナリ ログに書き込まないことを指定する分析テーブルの意味と同じです。

実行後、Msg_textが表示されます
'numysql.SYS_APP_USER', 'optimize', 'note', 'テーブルは最適化をサポートしていないため、代わりに再作成と分析を実行します'
その理由は、サーバー上の MySQL が InnoDB ストレージ エンジンであるためです。
最適化されていますか? 公式サイトをご覧ください!
https://dev.mysql.com/doc/refman/8.0/en/optimize-table.html
MyISAM では、このテーブルが最初に分析され、次に関連する MySQL データファイルが並べ替えられて、未使用のスペースが再利用されます。InnoDB では、再利用されたスペースは Alter テーブルによって単純に整理されます。最適化中に MySQL は一時テーブルを作成し、最適化が完了すると元のテーブルは削除され、一時テーブルの名前が元のテーブルに変更されます。
注: ほとんどのセットアップでは、OPTIMIZE TABLE を実行する必要はまったくありません。可変長行への更新が多数ある場合でも
、更新を頻繁に実行する必要はなく、週に 1 回または月に 1 回、特定のテーブルに対してのみ実行するだけで済みます。
3.8 概要
上記の方法にはすべて長所と短所があります。例えば:
- 記憶域スペースを節約するためにデータ型を変更する場合は、データが値の範囲を超えることができないことを考慮する必要があります。
- 冗長フィールドを追加するときは、データの一貫性を確保することを忘れないでください。
- 大きなテーブルを分割すると、クエリによって新しい接続が追加されることになり、追加のオーバーヘッドと運用および保守コストが増加します。
したがって、実際のビジネス ニーズに基づいて検討する必要があります。
4 大規模なテーブルの最適化
4.1 クエリの範囲を制限する
データ範囲を制限する条件のないクエリ ステートメントは禁止されています。たとえば、ユーザーが注文履歴を照会する場合、
1 か月の範囲内で制御できます。
4.2 読み取り/書き込みの分離
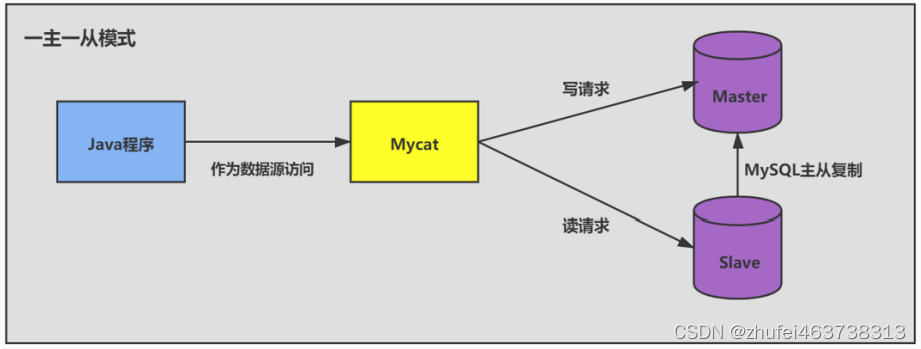
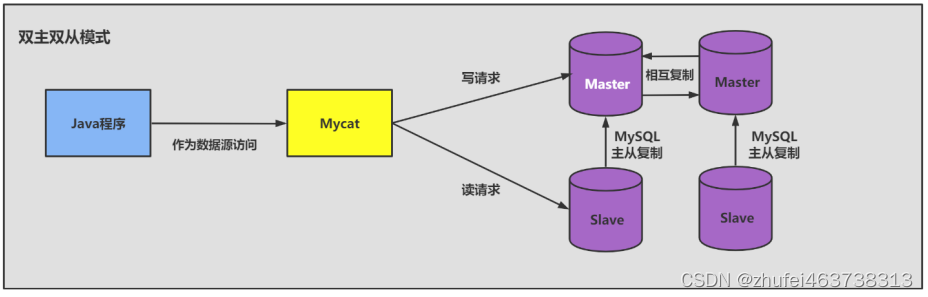
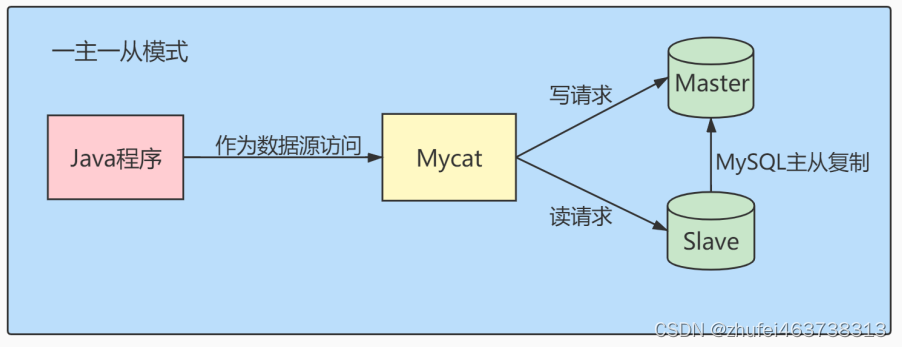
従来のデータベース分割スキームでは、マスター データベースが書き込みを担当し、スレーブ データベースが読み取りを担当します。
- 1 つのマスターと 1 つのスレーブ モード:
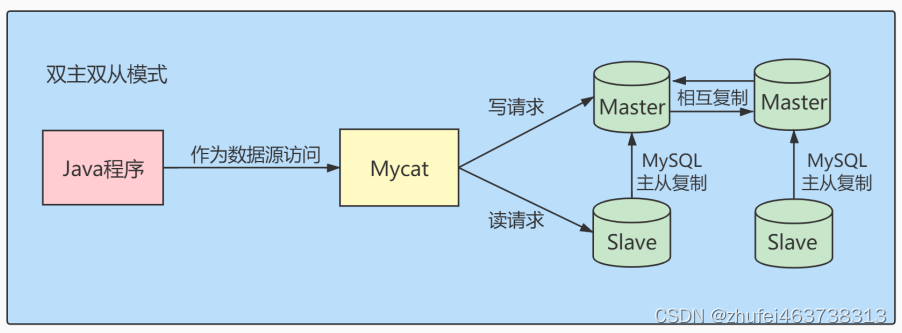
- デュアルマスターデュアルスレーブモード:
4.3 垂直分割
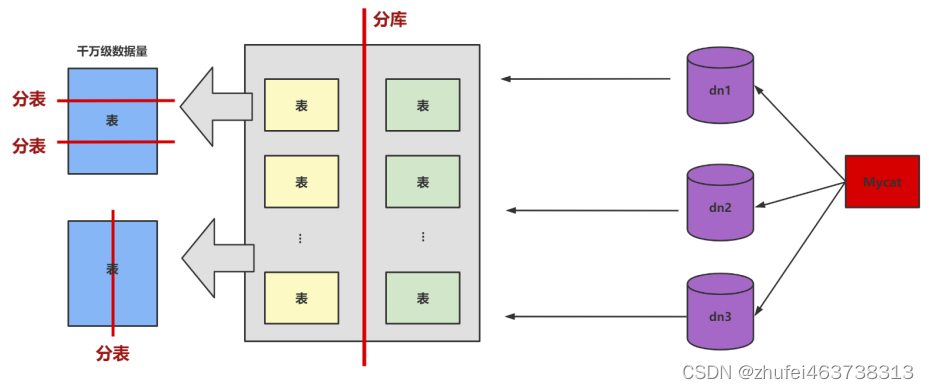
データの規模が千万级上記を超えると、単一のデータベース サーバーへのアクセス負荷を軽減するために、データベースを複数の部分に分割し、それらを異なるデータベース サーバーに配置する必要が生じることがあります。

垂直拆分的优点: 列データを小さくし、クエリ中に読み取られるブロック数を減らし、I/O 回数を減らすことができます。さらに、垂直に分割するとテーブルの構造が簡素化され、メンテナンスが容易になります。
垂直拆分的缺点: 主キーが冗長になり、冗長列を管理する必要があり、JOIN 操作が発生します。さらに、縦割りが問題をさらに複雑にします。
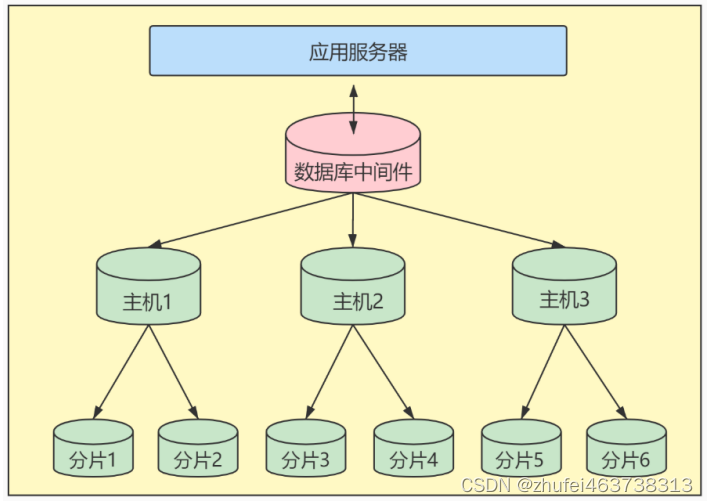
4.4 水平分割
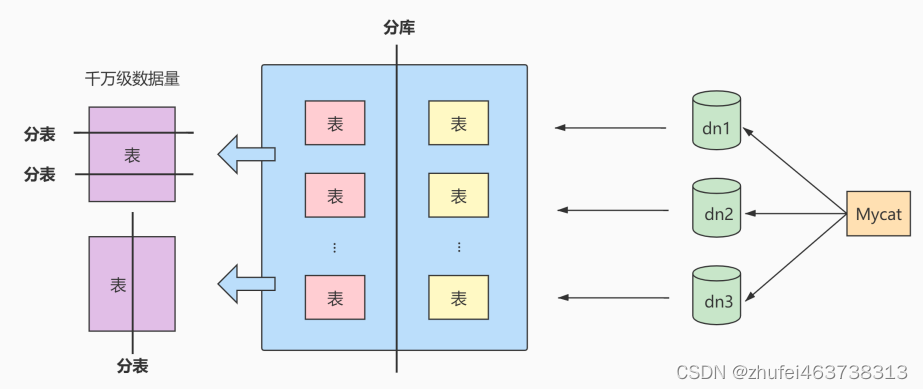
以下に、データベースシャーディングの 2 つの一般的なソリューションを示します
客户端代理。分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现Dangdang の Sharding-JDBC と Alibaba の TDDL は、一般的に使用される 2 つの実装です。
中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。私たちが今話している Mycat、360 の Atlas、NetEase の DDB などはすべてこのアーキテクチャの実装です。
5. その他のチューニング戦略
5.1 サーバーステートメントのタイムアウト処理
MySQL 8.0 で設定でき服务器语句超时的限制、ユニットに到達できます毫秒级别。中断された実行ステートメントが設定されたミリ秒数を超えると、サーバーはクエリにほとんど影響を与えないトランザクションまたは接続を終了し、クライアントにエラーを報告します。
サーバー ステートメントのタイムアウト制限を設定するには、システム変数 MAX_EXECUTION_TIME を設定します。デフォルトでは、MAX_EXECUTION_TIME の値は 0 であり、時間制限がないことを意味します。例えば:
SET GLOBAL MAX_EXECUTION_TIME=2000;
SET SESSION MAX_EXECUTION_TIME=2000; #指定该会话中SELECT语句的超时时间